The records show that Palantir is actively working on the technical infrastructure underpinning the Trump administration’s mass deportation efforts which could soon impact U.S. citizens.#News
L'altro giorno durante il lungo lunghissimo viaggio dal Salento a Roma stavo ascoltando l'ultimo album de La Nina, Furèsta, e devo dire molto bello. Credo nessuno possa affermare il contrario, neanche quelli che detestano l'autotuner, che pure figura qua e là tra le tracce 🤣
Ma non è di questo che volevo parlare, bensì del fatto che dopo La Nina l'algoritmo malefico mi ha suggerito di ascoltare una canzone di Enzo Avitabile. Io gli ho dato retta, e poi ho rilanciato e dato seguito, e così una canzone via l'altra mi sono ritrovato a sentirmi buona parte della discografia di questo artistone, che è piuttosto ampia tra l'altro, ma tanto il viaggio era lungo lunghissimo, e quindi presa bene totale 😋 Non che non lo conoscessi, lo conoscevo già, però insomma, una cosa è conoscere un artista altra cosa è spararsi tutta la sua discografia in un'unica botta senza soluzione di continuità 😅 E devo dire che mi è piaciuto molto. Soprattutto le sue cose più mediterranee, un po' meno in versione soul, funk e quella roba lì, dove comunque pure è fortissimo, al pari dei colleghi Pino Daniele, Senese etc.etc. Ma è proprio quando ritorna alla sua musica ancestrale che secondo me riesce a rendere al meglio la sua poetica. In effetti "poesia" è la parola che più si addice alle sue canzoni, sia nei testi che nelle atmosfere. Ma non quella finta poesia fatta di testi enigmatici e incomprensibili, tipici di tanta produzione autorale Italiana che vuole darsi un tono di mistero. No, la sua poesia è fatta di parole semplici, quasi povere, eppure molto emozionanti, come è tipico della poesia popolare. Stesso discorso per la musica, fatta per lo più di arpeggi di corde e frasi ripetitive e ostinate di un sassofono soprano che fa il verso a strumenti ancestrali come la ciaramella e simili. Una musica senza tempo e ricca di suggestioni che si presta a diventare colonna sonora di film, tanto quanto ad andare a braccetto di tanti altri stili, dal rap al pop, dal jazz alla musica africana. E in effetti infinite sono state le sue collaborazioni con artisti sia italiani che internazionali, da Bob Geldof a Manu Dibango passando per, Raiz, Guè, Giorgia e tanti altri:
Ho sentito certi live suoi veramente pazzeschi. A questo punto spero di riuscire a vederlo dal vivo qualche volta. Voi l'avete mai visto?! Immagino che spacca vero?! 😋
Carlo loved Halo and programming, but he loved God more. I went to see him, lying under glass in his Nikes for eternity, at a church in Assisi. #influencers
@Privacy Pride Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/casumarz… Un mio caro amico ha un'inconsueta passione per i siti delle amministrazioni locali: li visita spesso annotando valanghe di vizi e alcune rare virtù, ci torna periodicamente per assaporare l'immutabile squallore della standardizzazione ben coniugata
Con l’intensificarsi delle tensioni geopolitiche e l’adozione di tecnologie avanzate come l’intelligenza artificiale e il Web3 da parte dei criminali informatici, comprendere i meccanismi dell’underground cybercriminale di lingua russa diventa un vantaggio cruciale.
Milano, 14 aprile 2025 – Trend Micro, leader globale di cybersecurity, presenta “The Russian-Speaking Underground”, l’ultima ricerca dedicata all’underground cybercriminale di lingua russa, l’ecosistema che ha dato forma alla criminalità informatica globale negli ultimi dieci anni.
In un contesto caratterizzato da minacce informatiche in continua evoluzione, la ricerca offre uno sguardo unico e approfondito sui principali trend che stanno rimodellando l’economia sommersa: dagli effetti a lungo termine della pandemia alle conseguenze delle violazioni di massa e dei ransomware a doppia estorsione, fino all’esplosione di tecnologie accessibili come l’intelligenza artificiale e il Web3, senza dimenticare la crescente esposizione dei dati biometrici. Man mano che criminali informatici e professionisti della sicurezza diventano sempre più sofisticati, nuovi strumenti, tattiche e modelli di business alimentano livelli senza precedenti di specializzazione all’interno delle comunità clandestine. L’underground cybercriminale di lingua russa si distingue per la sua struttura organizzativa: forte collaborazione tra attori e profonde radici culturali, con propri codici etici, rigidi processi di selezione e complessi sistemi reputazionali.
“Non si tratta di un semplice marketplace, ma di una vera e propria società strutturata di cybercriminali, in cui lo status, la fiducia e l’eccellenza tecnica determinano la sopravvivenza e il successo”. Afferma Vladimir Kropotov, co-autore della ricerca e Principal Threat Researcher at Trend Micro.
“L’underground di lingua russa ha sviluppato una cultura distintiva, che unisce competenze tecniche di altissimo livello a rigidi codici di condotta, sistemi di fiducia basati sulla reputazione e un livello di collaborazione paragonabile a quello delle organizzazioni legittime”, ha aggiunto Fyodor Yarochkin, co-autore e Principal Threat Researchers at Trend Micro. “Non è solo una rete di criminali, ma una comunità resiliente e interconnessa, che si è adattata alla pressione globale e continua a influenzare l’evoluzione della criminalità informatica”.
La ricerca Trend Micro approfondisce le principali attività criminali, tra cui schemi di ransomware-as-a-service, campagne di phishing, brute forcing degli account e monetizzazione delle risorse Web3 rubate. Sono stati esaminati in dettaglio anche i servizi di intelligence gathering, sfruttamento della privacy e convergenza tra i domini cyber e fisici.
“I cambiamenti geopolitici hanno trasformato rapidamente l’underground cybercriminale”, conclude Vladimir. “I conflitti politici, l’ascesa dell’hacktivismo e i cambiamenti nelle alleanze hanno minato la fiducia e rimodellato le forme di collaborazione, favorendo nuovi legami con altri gruppi, compresi attori di lingua cinese. Le conseguenze di queste azioni si riflettono anche nell’Unione Europea, e sono in crescita”.
Con l’aumento delle tensioni geopolitiche e l’adozione di tecnologie sempre più avanzate come l’intelligenza artificiale e il Web3 da parte dei criminali informatici, comprendere i meccanismi dell’underground di lingua russa rappresenta un vantaggio cruciale come mai prima d’ora.
Il report di Trend Micro “The Russian-Speaking Underground” – il cinquantesimo della sua serie di ricerche sui mercati underground cybercriminali di tutto il mondo, iniziata oltre 15 anni fa – fornisce informazioni fondamentali e un contesto storico senza pari a team di intelligence sulle minacce, leader delle organizzazioni, Forze dell’Ordine e professionisti della sicurezza informatica, incaricati di proteggere le infrastrutture critiche, le risorse aziendali e la sicurezza nazionale.
Ulteriori informazioni sono disponibili a questo link
Trend Micro Trend Micro, leader globale di cybersecurity, è impegnata a rendere il mondo un posto più sicuro per lo scambio di informazioni digitali. Con oltre 30 anni di esperienza nella security, nel campo della ricerca sulle minacce e con una propensione all’innovazione continua, Trend Micro protegge oltre 500.000 organizzazioni e milioni di individui che utilizzano il cloud, le reti e i più diversi dispositivi, attraverso la sua piattaforma unificata di cybersecurity. La piattaforma unificata di cybersecurity Trend Vision One™ fornisce tecniche avanzate di difesa dalle minacce, XDR e si integra con i diversi ecosistemi IT, inclusi AWS, Microsoft e Google, permettendo alle organizzazioni di comprendere, comunicare e mitigare al meglio i rischi cyber. Con 7.000 dipendenti in 65 Paesi, Trend Micro permette alle organizzazioni di semplificare e mettere al sicuro il loro spazio connesso. www.trendmicro.com
vedo che nel mondo il bullismo impera... e che la dottrina trump pervade felicemente (per alcuni) tutto il mondo... quanta aria di libertà e di rispetto per la persona.
With vector network analyzers, the commercial offerings seem to come in two flavors: relatively inexpensive but limited capabilities, and full-featured but scary expensive. There doesn’t seem to be much middle ground, especially if you want something that performs well in the microwave bands.
Unless, of course, you build your own vector network analyzer (VNA). That’s what [Henrik Forsten] did, and we’ve got to say we’re even more impressed by the results than we were with his earlier effort. That version was not without its problems, and fixing them was very much on the list of goals for this build. Keeping the build affordable was also key, which resulted in some design compromises while still meeting [Henrik]’s measurement requirements.
The Bill of Materials includes dual-channel broadband RF mixer chips, high-speed 12-bit ADCs, and a fast FPGA to handle the torrent of data and run the digital signal processing functions. The custom six-layer PCB is on the large side and includes large cutouts for the directional couplers, which use short lengths of stripped coaxial cable lined with ferrite rings. To properly isolate signals between stages, [Henrik] sandwiched the PCB between a two-piece aluminum enclosure. Wisely, he printed a prototype enclosure and lined it with aluminum foil to test for fit and function before committing to milling the final version. He did note some leakage around the SMA connectors, but a few RF gaskets made from scraps of foil and solder braid did the trick.
This is a pretty slick build, especially considering he managed to keep the price tag at a very reasonable $300. It’s more expensive than the popular NanoVNA or its clones, but it seems like quite a bargain considering its capabilities.
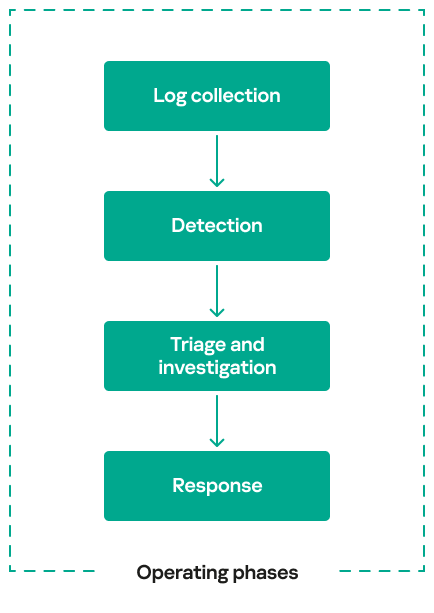
Security operations centers (SOCs) exist to protect organizations from cyberthreats by detecting and responding to attacks in real time. They play a crucial role in preventing security breaches by detecting adversary activity at every stage of an attack, working to minimize damage and enabling an effective response. To accomplish this mission, SOC operations can be broken down into four operating phases:
Each of these operating phases has a distinct role to play, and well-defined processes or procedures ensure a seamless handover of findings from one phase to the next. In practice, SOC processes and procedures at each operational phase often require continuous improvement over time.
Assessment observations: Common SOC issues
During our involvement in SOC technical assessments, adversary emulations, and incident response readiness projects across different regions, we evaluated each operating phase separately. Based on our assessments, we observed common challenges, weak practices, and recurring issues across these four key SOC capabilities.
Log collection
There are three main issues we have observed at this stage:
Lack of visibility coverage based on the MITRE DETT&CT framework – customers do not practice maintaining a visibility coverage matrix. Instead, they often maintain log source data as an Excel or similar spreadsheet that is not easily tracked. This means they don’t have a systematic approach to what data they are feeding into the SIEM and which TTPs can be detected in their environment. And in most cases, maintaining a continuous visibility matrix is also a challenge because log sources may disappear over time for a variety of reasons: agent termination, changes in log destination settings, device (e.g., firewall) replacement. This only leads to the degradation of the log visibility matrix.
Inefficient use of data for correlation – in many cases, relevant data is available to detect threats, but there are no correlation rules in place to leverage it for threat detection.
Correlation exists, but lacks the necessary data fields – while some rule sets are properly configured with the right logic to detect threats, the required data fields from log sources are missing, preventing the rules from being triggered. This critical issue can only be detected through a data quality assessment.
Detection
At this stage, we have seen the following issues during assessment procedures:
Over-reliance on vendor-provided rules – many customers rely heavily on the default rule sets in their SIEM and only tune them when alerts are triggered. Since the default content is not optimized, it often generates thousands of alerts. This reactive approach leads to excessive alert fatigue, making it difficult for analysts to focus on truly meaningful alerts.
Lack of detection alignment with the threat profile – the absence of a well-defined organizational threat profile prevents customers from focusing on the threats that are most likely to target them. Instead, they adopt a scattered approach to detection, like shooting in the dark rather than prioritizing relevant threats.
Poor use of threat intelligence feeds – we have encountered cases where endpoint logs do not contain file hash data. The log sources only provide filenames or file paths, but not the actual hash values, making it difficult for the SOC to correlate threat intelligence (TI) feeds that rely on file hashes. As a result, TI feeds are not operational because the required data field is not ingested into the SIEM.
Analytics deployment errors – one of the most challenging issues we see is when a well-designed detection rule is deployed incorrectly, causing threat detection to fail despite having the right analytics in place. We have found that there is no structured process for reviewing and validating rule deployments.
Triage and investigation
The most typical issues at this stage are:
Lack of a documented triage procedure – analysts often rely on generic, high-level response playbooks sourced from the internet, especially from unreliable sources, which slows or hinders the process of qualifying alerts as potential incidents. Without a structured triage procedure, they spend more time investigating each case instead of quickly assessing and escalating threats.
Unattended alerts – we also observed that many alerts were completely ignored by analysts. This likely stems from either a lack of skill in linking multiple alerts into a single incident, or analysts being swamped with high-severity alerts, causing them to overlook other relevant alerts.
Difficulty in correlating alerts – as noted in the previous observation, one of the biggest challenges is linking related alerts into a single incident. The lack of alert correlation makes it harder to see the full attack pattern, leading to disorganized alert diagnosis.
Default use of alert severity – SIEM default rules don’t take into account the context of the target system. Instead, they rely on the default severity in the rule, which is often set randomly or based on an engineer’s opinion without a clear process. This lack of context makes it harder to investigate and properly assess alerts.
Response
The challenges of the final operating phase are most often derived from the issues encountered in the previous stages.
Challenges in incident scoping – as mentioned earlier, the inability to properly correlate alerts leads to a fragmented understanding of attack patterns. This makes it difficult to see the bigger picture, resulting in inefficient incident handling and misjudged response efforts.
Increase in unnecessary escalations – this issue is particularly common in MSSP environments, where a lack of understanding of baseline behavior causes analysts to escalate benign cases. Without proper context, normal activities are mistaken for threats, resulting in wasted time and effort.
With these ongoing challenges, chaos will continue in SOC operations. As organizations adopt new security tools such as CASB and container security, both of which generate valuable detection data, and as digital transformation introduces even more technology, security operations will only become more complex, exacerbating these issues.
Taking the right and impactful approach
Enhancing SOC operations requires evaluating each operating phase from an investment perspective, with the detection phase having the greatest impact because it directly affects data quality, threat visibility, incident response efficiency, and the overall effectiveness of the SOC analyst. Investing in detection directly influences all the other operating phases, making it the foundation for improving all operating phases. The detection operating phase must be handled through a dedicated program that ensures log collection is purpose-driven, collecting only the data fields necessary for detection rather than unnecessarily driving up SIEM costs. This focused approach helps define what should be ingested into the SIEM while ensuring meaningful threat visibility.
Strengthening detection reduces false positives and false negatives, improves true positive rates, and enables the identification of attacker activity chains. A documented triage and investigation process streamlines the work of analysts, improving efficiency and reducing response time. Furthermore, effective incident scoping, guided by accurate detection of the cyber kill chain, enables a faster and more precise response. By prioritizing investment in detection and managing it through a structured approach, organizations can significantly improve SOC performance and resilience against evolving threats. This article focuses solely on SIEM-based detection management.
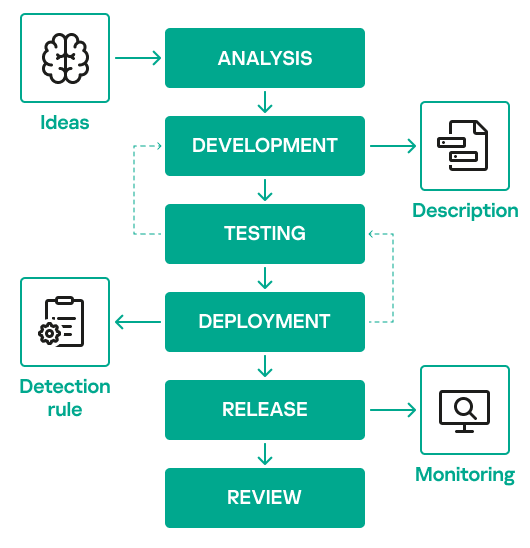
Detection engineering program
Before diving into the program-level approach, we will first present the detection engineering lifecycle that forms the foundation of the proposed program. The image below shows the stages of this lifecycle.
The detection engineering lifecycle shown here is typically followed when building detections, but its implementation often lacks well-defined processes or a dedicated team. A structured program must be put in place to ensure that the SOC’s investment and efforts in detection engineering are used efficiently.
When we talk about a program, it should be built on the following key elements:
A dedicated team responsible for driving the program
Well-defined processes and procedures to ensure consistency and effectiveness
The right tools to integrate with workflows, facilitate output handovers, and enable feedback loops across related processes
Meaningful metrics to measure the overall performance of the program.
We will discuss these performance measurement metrics in the final section of the article.
Team supporting detection engineering program
The key idea behind having a dedicated team is to take full control of the detection engineering (DE) lifecycle, from analysis to release, and ensure accountability for the program’s success. In a traditional SOC setup, deployment and release are often handled by SOC engineers. This can lead to deployment errors due to potential differences in the data models used by DE and SOC teams (raw log data vs. SIEM-optimized data), as well as deployment delays due to the SOC team being overloaded with other tasks. This, in turn, can indirectly impact the work of the detection team. However, the one responsibility that does not fall under the DE team is log onboarding. Since this process requires coordination with other teams, it should continue to be managed by SOC engineers to keep the DE team focused on its core objectives.
The DE team should start with at least three key roles:
The size of the team depends on factors related to the program’s objectives. For example, if the goal is to build a certain number of detection rules per month, the number of detection engineers required will vary accordingly. Similarly, if a certain number of rules need to be tested and deployed within a week, the team size must be adjusted to meet that demand.
The Detection Engineering Lead should communicate with SOC leadership to set the right expectations by outlining what goals can realistically be achieved based on the size and capacity of the DE team. A dedicated Detection QA role can be established as the need for testing, deployment, and release of detections grows.
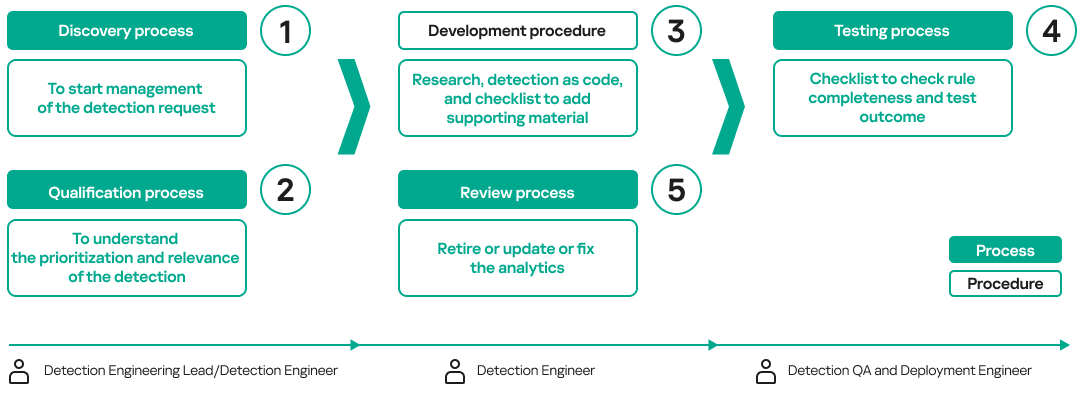
Process and procedures
Well-defined workflows, supported by structured processes and procedures, must be established to streamline detection engineering operations. The following image illustrates the necessary processes and procedures, along with the roles responsible for executing each workflow:
During the qualification process, the Detection Engineering Lead or Detection Engineer may discover that the data source needed to develop a detection is not available. In such cases, they should follow the log management process to request onboarding of the required data before proceeding with detection research and development. The testing process typically checks that the rule works by ensuring that the SIEM triggers an alert based on the required data fields.
Lastly, a validation process that is not part of the detection engineering lifecycle must be incorporated into the detection engineering program to assess its overall effectiveness. Ideally, this validation should be conducted by individuals outside the DE lifecycle or by an external service provider.
Proper planning is required that incorporates threat intelligence and an updated threat profile. In addition, the validation process should generate reports that outline:
What is working well
Areas that need improvement
Detection gaps identified
Tools
An essential element of the DE lifecycle is the use of tools to streamline processes and improve efficiency. Key tools include:
Ticketing platform – efficiently manages workflows, tracks progress from ticket creation to closure, and provides time-based metrics for monitoring.
Rules repository – platform for managing detection queries and code, supporting Detection-as-Code, using a unified rule format such as SIGMA, and implementing code development best practices in detection engineering, including features such as version control and change management.
Centralized knowledge base – dedicated space for documenting detection rules, descriptions, research notes, and other relevant information. See the best practices section below for more details on centralized documentation.
Communication platform – facilitates collaboration among DE team members, integrates with the ticketing system, and provides real-time notification of ticket status or other issues.
Lab environment – virtualized setup, including SIEM and relevant data sources, tools to simulate attacks for testing purposes. The core function of the lab is to test detection rules prior to release.
Best practices in detection engineering
Several best practices can significantly enhance your detection engineering program. Based on our experience, implementing these best practices will help you effectively manage your rule set while providing valuable support to security analysts.
Rule naming convention
When developing analytics or a rule, adhering to a proper naming convention provides a concrete framework. A rule name like “Suspicious file drop detected” may confuse the analyst and force them to dig deeper to understand the context of the alert that was triggered. It would be better to give a rule a name that provides complete context at first glance, such as “Initial Access | Suspicious file drop detected in user directory | Windows – Medium”. This example makes it easy for the analyst to understand:
At what stage of the attack the rule is triggered. In this case, it is Initial Access as per MITRE / Kill Chain Model.
Where exactly the file was dropped. In this case, the user directory was the target, which may mean that this probably involved user interaction, which is another sign that the attack was probably detected at an early stage.
What platform was attacked. In this case, it is Windows, which can help the analyst to quickly find the machine that triggered the alert.
Lastly, an alert priority can be set, which helps the analyst to prioritize accordingly. For this to work properly, SIEM’s priority levels should be aligned with the rule priorities defined by the detection engineering team. For example, a high priority in SIEM should correspond to a high-priority alert.
A consistent rule naming structure can help the detection engineering team to easily search, sort and manage existing rules, avoid creating duplicates with different names, etc.
The naming structure doesn’t necessarily have to look like the example above. The whole idea of this best practice is to find a good naming convention that not only helps the SOC analyst, but also makes managing detection rules easier and more convenient.
For example, while the rule name “Audit Log Deletion” gives a basic idea of what is happening, a more effective name would be: [High] – Audit Log Deletion in Internal Server Farm – Linux - Defense Evasion (1070.002). This provides better context, making it much more useful to the SOC team, and more keywords for the DE team to find this particular rule or filter rules if necessary.
Centralized knowledge base
Once a rule is created after thorough research, the detection team should manage it in a centralized platform (a knowledge base). This platform should not only store the rule name and logic, but also other key details. Important elements to consider:
Rule name/ID/description – rule name, unique ID, and a brief description of the rule.
Rule type/status – provides insight into the rule type (static, correlated, IoC-based, etc.) and the status (experimental, stable, retired, etc.).
Severity and confidence – seriousness of the threat triggering this rule and the likelihood of a true positive.
Research notes – possible public links, threat reports, used as a basis for creating the rule.
Data components used to detect the behavior – list of source and data fields used to detect activity.
Triage steps – provides steps to investigate the alert.
False positives – provides options where the alert could show false positive behavior.
Tags (CVE, Actors, Malware, etc.) – provide more context if the detection is linked to a behavior or artifact, specific to any APT group, or malware.
Make sure this centralized documentation is accessible to all SOC analysts.
Contextual tagging
As covered in the previous best practice, tags provide a great value in understanding the attack chain. That’s why we want to highlight them as a separate best practice.
The tags attached to the above detection rule are the result of the research done on the behavior of the attack when writing the detection rule. They help the analyst gain more context at the time the rule is triggered. In the example above, the analyst may suspect a potential initial access attempt related to QakBot or Black Basta ransomware. This also helps in reporting to security leadership that the SOC team successfully detected the initial ransomware behavior and was able to thwart the attack in the early stages of the kill chain.
Triage steps
A good practice is to include triage (or investigation steps) in detection rule documentation. Since the DE team has spent a lot of time understanding the threat, it is very important to document the precursors and possible next steps the attacker can take. The SOC analyst can quickly review these and provide incident qualification with confidence.
For the rule from the previous section, “Initial Access | Suspicious LNK files dropped in download folder | Windows – Medium”, the triage procedure is shown below.
MITRE has a project called the Technique Inference Engine, which provides a model for understanding other techniques an attacker is likely to use based on observed adversary behavior. This tool can be useful for both DE and SOC teams. By analyzing the attacker’s path, organizations can improve alert correlation and enhance scoping of incident/threats.
Baselining
Understanding the infrastructure and its baseline operations is a must, as it helps reduce the false positive rate. The detection engineering team must learn the prevention policies (to de-prioritize detection if already remediated), learn about the technologies deployed in the infrastructure, understand the network protocols being used and user behavior under normal circumstances.
For example, to detect T1480.002: Execution Guardrails: Mutual Exclusion sub-technique, MITRE recommends monitoring a “file creation” data component. According to the MITRE Data Sources framework, data components are possible actions with data objects and/or data objects statuses or parameters that may be relevant for threat detection. We discussed them in more detail in our detection prioritization article.
A simple rule for detecting such activity is to monitor lock file creation events in the /var/run folder, which stores temporary runtime data for running services. However, if you have done the baselining and found that the environment uses containers that also create lock files to manage runtime operations, you can filter out container-linked events to avoid triggering false positive alerts. This filter is easy to apply, and overall detection can be improved by baselining the infrastructure you are monitoring.
Finding the narrow corridors
Some indicators, such as file hashes or software tools are easy to change, while others are more difficult to replace. Detections based on such “narrow corridors” tend to have high true positive rates. To pursue this, detection should focus primarily on behavioral indicators, ensuring that attackers cannot easily evade detection by simply changing their tools or tactics. Priority should be given to behavior-based detection over tool-specific, software-dependent, or IoC-driven approaches. This aligns with the Pyramid of Pain model, which emphasizes detecting adversaries based on their tactics, techniques, and procedures (TTPs) rather than easily replaceable indicators. By prioritizing common TTPs, we can effectively identify an adversary’s modus operandi, making detection more resilient and impactful.
Universal rules
When planning a detection program from scratch, it is important not to ignore the universal threat detection rules that are mostly available in SIEM by default. Detection engineers should operationalize them as soon as possible and tune them according to feedback received from SOC analysts or what they have learned about the organization’s infrastructure during baselining activity.
Universal rules generally include malicious behavior associated with applications, databases, authentication anomalies, unusual remote access behavior, and policy violation rules (typically to monitor compliance requirements).
Some examples include:
Windows firewall settings modification detected
Use of unapproved remote access tools
Bulk failed database login attempts
Performance measurement
Every investment needs to be justified with measurable outcomes that demonstrate its value. That is why communicating the value of a detection engineering program requires the use of effective and actionable metrics that demonstrate impact and alignment with business objectives. These metrics can be divided into two categories: program-level metrics and technical-level metrics. Program-level metrics signal to security leadership that the program is well aligned with the company’s security objectives. Technical metrics, on the other hand, focus on how operational work is being carried out to maximize the detection engineering team’s operational efficiency. By measuring both program-level metrics and technical-level metrics, security leaders can clearly show how the detection engineering program supports organizational resilience while ensuring operational excellence.
Designing effective program-level metrics requires revisiting the core purpose for initiating the program. This approach helps identify metrics that clearly communicate success to security leadership. There are three metrics that can be very effective to measure the success at program level.
Time to Detect (TTD) – this metric is calculated as the time elapsed from the moment an attacker’s initial activity is observed until the time it is formally detected by the analyst. Some SOCs consider the time the alert is triggered on the SIEM as the detection time, but that is not really an actionable metric to consider. The time the alert is converted into a potential incident is the best option to consider for detection time by SOC analysts.
Although the initial detection of activity occurs at t1 (alert triggered), when malicious activity occurs, a series of events must be analyzed before qualifying the incident. This is why t3 is required to correctly qualify the detection as a potential threat. Additional metrics such as time to triage (TTT), which establishes how long it takes to qualify the incident, and time to investigate (TTI), which describes how long it takes to investigate the qualified incident, can also come in handy.
Time to detect compared to time to triage and time to investigate metrics
Signal-to-Noise Ratio (SNR) – this metric indicates the effectiveness of detection rules by measuring the balance between relevant and irrelevant information. It compares the number of true positive detections (correct alerts for real threats) to the number of false positives (incorrect or misleading alerts).
Where:
True positives: instances where a real threat is correctly detected False positives: incorrect alerts that do not represent real threats
A high SNR indicates that the system is generating more meaningful alerts (signal) compared to noise (false positives), thereby enhancing the efficiency of security operations by reducing alert fatigue and focusing analysts’ attention on genuine threats. Improving SNR is crucial to maximizing the performance and reliability of a detection program. SNR directly impacts the amount of SOC analyst effort spent on false positives, which in turn influences alert fatigue and the risk of professional burnout. Therefore, it is a very important metric to consider.
Threat Profile Alignment (TPA) – this metric evaluates how well detections are aligned with known adversarial tactics, techniques, and procedures (TTPs). This metric measures this by determining how many of the identified TTPs are adequately covered by unique detections (unique data components).
Total TTPs identified – this is the number of known adversarial techniques relevant to the organization’s threat model, typically derived from cyber threat intelligence threat profiling efforts Total TTPs covered with at least three unique detections (where possible) – this counts how many of the identified TTPs are covered by at least three distinct detection mechanisms. Having multiple detections for a given TTP enhances detection confidence, ensuring that if one detection fails or is bypassed, others can still identify the activity. Team efforts supporting the detection engineering program must also be measured to demonstrate progress. These efforts are reflected in technical-level metrics, and monitoring these metrics will help justify team scalability and address productivity challenges. Key metrics are outlined below:
Time to Qualify Detection (TTQD) – this metric measures the time required to analyze and validate the relevance of a detection for further processing. The Detection Engineering Lead assesses the importance of the detection and prioritizes it accordingly. The metric equals the time that has elapsed from when a ticket is raised to create a detection to when it is shortlisted for further research and implementation.
Time to Create Detection (TTCD) – this tracks the amount of time required to design, develop and deploy a new detection rule. It highlights the agility of detection engineering processes in responding to evolving threats.
Detection Backlog – the backlog refers to the number of pending detection rules awaiting review or consideration for detection improvement. A growing backlog might indicate resource constraints or inefficiencies.
Distribution of Rules Criticality (High, Medium, Low) – this metric shows the proportion of detection rules categorized by their criticality level. It helps in understanding the balance of focus between high-risk and lower-risk detections.
Detection Coverage (MITRE) – detection coverage based on MITRE ATT&CK indicates how well the detection rules cover various tactics, techniques, and procedures (TTPs) in the MITRE ATT&CK framework. It helps identify coverage gaps in the defense strategy. Tracking the number of unique detections that cover each specific technique is highly recommended, as it provides visibility into the threat profile alignment – a program level metric. If unique detections are not being built to detect gaps and the coverage is not increasing over time, it indicates an issue in the detection qualification process.
Share of Rules Never Triggered – this metric tracks the percentage of detection rules that have never been triggered since their deployment. It may indicate inefficiencies, such as overly specific or poorly implemented rules, and provides insight for rule optimization.
There are other relevant metrics, such as the proportion of behavior-based rules in the total set. Many more metrics can be derived from a general understanding of the detection engineering process and its purpose to support the DE program. However, program managers should focus on selecting metrics that are easy to measure and can be calculated automatically by available tools, minimizing the need for manual effort. Avoid using an excessive number of metrics, as this can lead to a focus on measurement only. Instead, prioritize a few meaningful metrics that provide valuable insight into the program’s progress and efforts. Choose wisely!
Eric Andersen – Blue River – Live in Tokyo 2012 freezonemagazine.com/articoli/… Per l’occasione di questo “momento Andersen” sono andato a rispolverare Today Is the Highway (1965) e, dopo sessant’anni, guardare il viso sorridente di Eric così come compariva sulla cover del suo album di debutto, con il berrettino di lana calato in testa, bavero alzato della pesante giacca in uno stile marinaio – mise che tradisce […] L'articolo Eric Andersen –
@Informatica (Italy e non Italy 😁) Con la pubblicazione di tre determinazioni cruciali, l’ACN ha di fatto dato il via alla seconda fase attuativa e operativa della NIS2. Un salto qualitativo nell’approccio alla cyber sicurezza nazionale che introduce un sistema formale di
@Notizie dall'Italia e dal mondo Nel caso dell'ultimo studente arrestato ieri negli Stati Uniti, il segretario di stato Rubio ha dichiarato che le proteste minacciando l'obiettivo di politica estera degli Stati Uniti di "risolvere il conflitto di
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁) I dazi di Trump potrebbero avere un impatto economico di 1 miliardo di dollari all'anno sulle aziende americane che producono macchinari per i semiconduttori, come Applied Materials e Lam Research, già
Today, April 16th, 2025, we are proudly celebrating 15 remarkable years since the founding of Pirate Parties International. On this very day in 2010 Pirates from around the world gathered in Brussels for a 3 day conference which established an international office for Pirate parties around the world.
As we celebrate our birthday, we’re reminded of the collective strength of our global movement. Over the years, PPI has grown into a vibrant community with members in over 40 countries. We are intercontinental. We are recognized by the UN. We have helped members get elected to parliaments in numerous countries. We are represent an international voice advocating for digital freedom, transparency, and human rights in the digital age.
To all our members, supporters, and friends worldwide: Thank you for being part of this incredible journey.
@Informatica (Italy e non Italy 😁) Un giro di forniture parallele aggira le sanzioni occidentali e porta i semiconduttori in Cina e Russia. Ecco come funziona. L'articolo Così si contrabbandano i microchip sotto restrizione proviene da Guerre di Rete.
EDRi member Panoptykon Foundation supports activists and attorney-at-law Artur Kula to demand that the four biggest telecom companies in Poland delete data stored for the purpose of law enforcement in the 12 months prior. They want to challenge the current unlawful data retention regime in Poland.
@Notizie dall'Italia e dal mondo Si è concluso il IX vertice della Comunità degli Stati americani e caraibici, l'organismo che rappresenta ancora una forte spina nel fianco per l'imperialismo Usa. L'articolo Celac, in Honduras il vertice ai pagineesteri.it/2025/04/16/ame…
I “relatori speciali” delle Nazioni Unite, esperti indipendenti che si occupano di controllare categorie specifiche di diritti all’interno dei paesi, hanno inviato una nuova comunicazione al governo italiano invitandolo ad abrogare il decreto Sicurezza (lo avevano già fatto a dicembre, quando ancora molte norme di questo decreto dovevano essere approvate all’interno di un disegno di legge). Tra le norme problematiche del “decreto Sicurezza” segnalate dall’ONU c’è proprio il reato di rivolta in carcere e nei CPR, definito «restrizione inutile e sproporzionata del diritto di protesta pacifica e di espressione» delle persone detenute.
Canzoni per fantasmi freezonemagazine.com/articoli/… Alive in the superunknown First it steals your mind And then it steals your soul (Soundgarden, «Superunknown», 1994) Quando ero una ragazzina, non c’erano ancora i video musicali, però avevamo i 33 giri. Compravo un album (spesso di nascosto, perché i miei genitori trovavano discutibile il mio vizio di sputtanare i pochi soldi che […] L'articolo Canzoni per fantasmi proviene da FREE ZONE MAGAZIN Alive in the
What has the EDRis network been up to over the past two weeks? Find out the latest digital rights news in our bi-weekly newsletter. In this edition: Challenging data retention regime in Poland, Ljubljana’s municipal surveillance, and more!
During a Ljubljana municipal council debate on CCTV transparency, several concerning points were raised regarding the Slovenian capital's network of over 500 surveillance cameras and the methods employed to assess their effectiveness in preventing crime. The discussion revealed that the entire system relies heavily on trust in the authorities, without any substantial data to support the cameras' effectiveness or a clear rationale for their widespread deployment.
1) hai scritto Nicola Zingaretti, ma probabilmente intendevi Luca Zingaretti 2) non pubblicare solo i link, ma riporta il titolo del post e un breve riassunto.
A questo proposito, hai provato a utilizzare gli strumenti di Friendica per ripubblicare i post del tuo blog sul tuo account Friendica? Puoi dare un'occhiata al link seguente: informapirata.it/2024/07/25/w-…
Una interessante spaccato storico sulle modalità di pubblicazione adottate, partendo da Hubzilla e Pterotype a #Ghost e #Wordpress con i suoi fantastici Plugin
ho sperimentato l'integrazione del mio progetto di pubblicazione di notizie con il Fediverse per quasi cinque anni. Ci sono stati diversi esperimenti, errori e momenti di insegnamento che mi hanno portato dove sono oggi. Voglio parlare di alcune delle cose che ho provato e del perché queste cose sono state importanti per me.
I wrote up an article on my personal (Ghost-powered!) blog about some of the work I’ve been doing to integrate our news publication at We Distribute into the #Fediverse.
This is the culmination of years and years of experiments, and we’re almost to a point where most of our ideas have been realized.
By the way, we take this opportunity to let @Sean Tilley and @Alex Kirk know that we tried the "Enable Mastodon Apps" plugin with #RaccoonforFriendica, which is an app developed for Friendica by @Dieguito 🦝 but is also compatible with Mastodon, but also allows you to write in simplified HTML with a very functional toolbar.
Well, it was wonderful to write formatted texts and with links from Raccoon for Friendica, even if I haven't managed to get the mentions to work yet.
Unfortunately, even if Raccoon allows you to publish posts with inline images, it can only do so with Friendica, while with the simple Mastodon API this is not possible.
This week is a bit of a shorter Report, it’s a relatively quieter news week and some other work is taking up most of my attention this week. Still, there is a PeerTube roadmap for 2025, some more updates on how FediForum is moving forward and more.
The News
Framasoft has published their PeerTube roadmap for 2025. Last year, PeerTube’s big focus was on the consumer, with the launch of the PeerTube apps. This year, PeerTube’s improvement is on instance administrators. The organisation will work on building a set-wizard, making it easier for new instance admins to get started and configure the platform. Framasoft will also work on further customisation for instances, allowing admins to further tune how the instance looks for the end-users. There is also a lot of work being done on video channels, with the new features being the ability to transfer ownership of a channel, as well as having channels that are owned by multiple accounts. Framasoft also mentions they are working on shared lists of blocked accounts and instances, where admins can share information with other admins on which instances to block. And now that PeerTube is available on Android and iOS, other new platforms that PeerTube will come to is tablets and Android TVs.
The planned FediForum for early April was cancelled at the last minute. A group of attendees held the Townhall event that was held in its place to discuss how to move forward, and listen to people’s perspectives. The notes of the FediForum Townhall have now been published. Last week, the FediForum account posted: “Planned next steps: another townhall likely next week, and a rescheduled & adapted FediForum in May.” The organisers posted a survey for attendees on how to move forward as well. Jon Pincus has an extensive article, “On FediForum (and not just FediForum)” that places the entire situation of why FediForum was cancelled, in its larger context.
PieFed now allows people to limit who can DM them. By default only people on the same instance can receive DMs from each other. The Piefed/Lemmy/Mbin network has seen a rise on spam DMs which send gore images, and this is a helpful way of dealing with this harassment.
IFTAS wrote about how they are continuing their mission. The organisation recently had to wind down most of their high-profile projects due to a lack of funding. This is not the end of the entire organisation however, as IFTAS will continue with their Moderator Needs Assessment, the CARIAD domain observatory, which provides insight in the most commonly blocked domains and more, as well as the IFTAS Connect community for fediverse moderators.
A master’s thesis on the fediverse, which looks at the user activity and governance structures, with the main finding: “The findings reveal that instance size and active engagement—such as frequent posting and interacting with others—are the strongest predictors of user activity, while technical infrastructure plays a more supportive role rather than a determining one. Governance structures, such as moderation practices and community guidelines, show a weaker but positive correlation with user activity.”
Sean Tilley from WeDistribute writes how his work on ‘Integrating a News Publication Into the Fediverse’. Tilley has over a decade of experimentation on building journalistic outlets on fediverse platforms, and in this article he reflects on all the different case studies he has done over the years, and where WeDistribute is headed next.
Building a blog website on Lemmy. This personal website uses Lemmy as a backend for a personal blogging site, where the site is effectively a Lemmy client that looks like a blogging site.
That’s all for this week, thanks for reading! You can subscribe to my newsletter to get all my weekly updates via email, which gets you some interesting extra analysis as a bonus, that is not posted here on the website. You can subscribe below:
I membri dello staff tecnico erano allarmati da ciò che gli ingegneri del DOGE facevano quando veniva loro concesso l'accesso, in particolare quando notavano un picco nei dati in uscita dall'agenzia. È possibile che i dati includessero informazioni sensibili su sindacati, cause legali in corso e segreti aziendali – dati che quattro esperti di diritto del lavoro hanno dichiarato a NPR che non dovrebbero quasi mai uscire dall'NLRB e che non hanno nulla a che fare con l'aumento dell'efficienza del governo o con la riduzione della spesa.
L’attacco russo di domenica scorsa nella città ucraina di Sumy continua a essere oggetto di un’accesa campagna di propaganda occidentale, in particolare europea, nel tentativo di sfruttare l’evento per complicare ancora di più i negoziati in corso tr…
@Politica interna, europea e internazionale Dopo numerosi rinvii, è approdato alla Camera il decreto bollette, il provvedimento del governo che prevede una dotazione di circa 3 miliardi di euro, oltre la metà dei quali destinati a finanziare il bonus per le famiglie. Il decreto è stato criticato dai
Customs and Border Protection released more documents last week that show which AI-powered tools that agency has been using to identify people of interest.#News
Sono lieto di annunciare che Lunedì 21 Aprile nella cornice più ampia delle celebrazioni per il 2078° compleanno della #CittàEterna avrò l'onore presso il #Campidoglio di inaugurare artisticamente una intera giornata di spettacoli dedicati a #Roma e ai suoi grandi artisti, partendo dalla mia interpretazione cantata dei sonetti romaneschi di #GiuseppeGioachinoBelli, per passare poi a #Petrolini (omaggiato da Enoch Marella), #GabriellaFerri (con lo spettacolo a cura della mia amata #GiuliaAnanìa), e molte altre cose ancora, con momento culminante il concerto de #IlMuroDelCanto. Presentazione di questa bella iniziativa e programma completo qui:
Non è troppo complicato capire quali “aggiustamenti” si stiano imponendo alla nuova strategia commerciale statunitense, meno semplice è prevedere dove Si allunga la lista dei prodotti e dei settori produttivi che vengono "momentaneamente esentati" da…
Rilanciare la produzione dei vascelli della US Navy, sostenere l’impiego di manodopera locale e riportare gli Stati Uniti sul podio delle potenze cantieristiche mondiali. Questo, in poche parole, è il piano di Donald Trump per quanto
@Notizie dall'Italia e dal mondo La lettera di Egidia Beretta al figlio per il 14esimo anniversario della sua uccisione L'articolo VITTORIO ARRIGONI. Egidiahttps://pagineesteri.it/2025/04/15/mediterraneo/vittorio-arrigoni-egidia-beretta-la-tua-presenza-e-piu-viva-e-vicina-che-mai/
l'europa non è assente. quella vera. quella che non apprezza la classica politica russa dei colpi di stato e dei governi fantoccio. putin: dimettiti: sei vecchio, brutto e cattivo. e porti solo il male.
 - Collegamento all'originale")













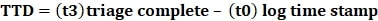

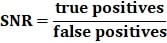

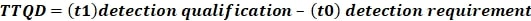
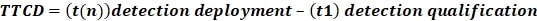














Signor Amministratore ⁂
in reply to alessandro tenaglia • •Due osservazioni:
1) hai scritto Nicola Zingaretti, ma probabilmente intendevi Luca Zingaretti
2) non pubblicare solo i link, ma riporta il titolo del post e un breve riassunto.
A questo proposito, hai provato a utilizzare gli strumenti di Friendica per ripubblicare i post del tuo blog sul tuo account Friendica?
Puoi dare un'occhiata al link seguente: informapirata.it/2024/07/25/w-…