🍀 ThePrivacyPost è un account di servizio gestito direttamente dagli amministratori di Poliverso e pubblica notizie provenienti da diversi siti, blog, account del fediverso e alcuni contenuti originali. 🩸 Se apprezzi questo servizio, prendi in considerazione la possibilità di effettuare una donazione a Poliverso. Puoi scegliere due canali:
Why is software created using public funds not released as #FreeSoftware? 👀
We want legislation requiring that publicly financed software developed for the public sector be made publicly available under a Free Software licence. If it is public money, it should be public code as well. 🚀
On April 1, 2024, the Future of Privacy Forum filed comments to the Office of Management and Budget (OMB) in response to the agency’s Request for Information on how privacy impact assessments (PIAs) may mitigate privacy risks exacerbated by AI and ot…
Pro-Russian Voice of Europe back online from Kazakhstan https://poliverso.org/display/0477a01e-4b8a102a-7f1d4190fe4019e7 Pro-Russian Voice of Europe back online from KazakhstanThe outlet Voice of Europe, allegedly involved in a pro-Russian propaganda network, has restarted operations, hosted in Kazakhstan after it was sanctioned by the Czech Republic last month, Euractiv’s data shows.euractiv.com/section/global-eu…
Pro-Russian Voice of Europe back online from Kazakhstan
The outlet Voice of Europe, allegedly involved in a pro-Russian propaganda network, has restarted operations, hosted in Kazakhstan after it was sanctioned by the Czech Republic last month, Euractiv’s data shows.
Grok 1.5V: Il modello che vuole comprendere la realtà come un essere umano https://poliverso.org/display/0477a01e-f239cff5-ce62b5230720adec Grok 1.5V: Il modello che vuole comprendere la realtà come un essere umano La società xAI di Elon Musk ha introdotto https://x.ai/blog/grok-1.5v il suo primo modello multimodale, Grok 1.5 Vision (Grok-1.5V). Il modello è progettato per competere con OpenAI e ha la capacità di analizzare testi, documenti, grafici, diagrammi, screenshot e fotografie.Nel
Grok 1.5V: Il modello che vuole comprendere la realtà come un essere umano
La società xAI di Elon Musk ha introdotto il suo primo modello multimodale, Grok 1.5 Vision (Grok-1.5V). Il modello è progettato per competere con OpenAI e ha la capacità di analizzare testi, documenti, grafici, diagrammi, screenshot e fotografie.
Nel novembre 2023, la società ha rilasciato la prima versione del suo modello Grok e a marzo xAI ha reso pubblici l’architettura e i pesi del modello base. Il nuovo modello multimodale Grok 1.5 Vision è arrivato appena un mese dopo.
Secondo il sito web dell’azienda, Grok 1.5V è in grado di connettere il mondo fisico e quello digitale. Il modello può, ad esempio, convertire un’immagine del diagramma di flusso in codice Python o calcolare il contenuto calorico di un prodotto da un’etichetta nutrizionale.
Può anche creare una fiaba basata sul disegno di un bambino o spiegare perché un particolare meme è divertente.
Il modello non solo intrattiene, ma svolge anche compiti pratici: converte le tabelle in formato CSV, aiuta a correggere gli errori nel codice e fornisce anche suggerimenti per la ristrutturazione della casa in base alle immagini fornite. I risultati dei test hanno mostrato che Grok 1.5V supera significativamente gli altri modelli AI. Confronto delle prestazioni di vari compiti Grok 1.5V con altri modelli Inoltre, xAI ha introdotto un nuovo benchmark, RealWorldQA, che valuta la capacità di comprendere il mondo reale in termini spaziali. Il nuovo benchmark RealWorldQA è progettato per valutare le capacità di base di comprensione del mondo reale dei modelli multimodali.
Anche se molti dei compiti del benchmark sembrano semplici per gli esseri umani, sono impegnativi per i modelli AI. La prima versione di RealWorldQA presenta oltre 700 immagini con domande e risposte verificabili, comprese immagini di veicoli anonimizzate e altri scenari del mondo reale.
Elon Musk, in una recente intervista, ha espresso l’opinione che entro la fine del 2025 l’intelligenza artificiale sarà più intelligente di qualsiasi essere umano. Tutti gli occhi sono ora puntati sui miglioramenti che la sua azienda apporterà allo sviluppo dell’intelligenza artificiale nei prossimi mesi. xAI sta inoltre pianificando miglioramenti significativi in altri settori come audio, voce e video.
Il modello Grok 1.5 Vision sarà presto disponibile per il test da parte degli utenti esistenti.
Israele Iran, Ucraina Russia: Benvenuti nell’AI-War. Quando uccidere è solo questione di Silicio https://poliverso.org/display/0477a01e-4a91b526-8a7307999beeadb5 Israele Iran, Ucraina Russia: Benvenuti nell’AI-War. Quando uccidere è solo questione di Silicio Lo sapevamo. Dietro al bello di CHAT GPT e Midjourney, il potenziamento continuo di robotica e AI, progetti classificati venivano realizzati in tutto il mondo.Droni autonomi, sistemi di controllo e di pianificazione delle operazioni e
Israele Iran, Ucraina Russia: Benvenuti nell’AI-War. Quando uccidere è solo questione di Silicio
Lo sapevamo. Dietro al bello di CHAT GPT e Midjourney, il potenziamento continuo di robotica e AI, progetti classificati venivano realizzati in tutto il mondo.
Droni autonomi, sistemi di controllo e di pianificazione delle operazioni e chissà quale altra diavoleria bolliva in pentola all’interno delle agenzie militari di questo pianeta.
Ora è il momento di togliere il sipario: benvenuti nella Guerra AI.
L’intelligenza artificiale sta svolgendo un ruolo importante, e secondo alcuni molto preoccupante, nella guerra di Israele a Gaza, con recenti rapporti investigativi che suggeriscono che l’esercito israeliano ha avviato un programma di intelligenza artificiale capace di prendere di mira migliaia di attivisti di Hamas nei primi giorni della guerra, e potrebbe aver avuto un ruolo nelle uccisioni sconsiderate e imprecise, nella distruzione dilagante e nelle migliaia di vittime civili.
L’esercito di occupazione israeliano respinge categoricamente questa affermazione, mentre un rapporto del sito web americano business insider fornisce uno sguardo terrificante su dove potrebbe portare la nuova guerra.
Un futuro terrificante
“La decisione di uccidere un essere umano è una decisione molto importante”, ha detto a BI Mick Ryan, un maggiore generale e stratega australiano in pensione che si concentra sugli sviluppi della guerra.
All’inizio di questo mese, un’indagine congiunta della rivista +972 e Local Call ha rivelato che le forze di occupazione israeliane stavano utilizzando un programma di intelligenza artificiale chiamato “Lavender” per creare obiettivi sospetti per Hamas nella Striscia di Gaza, citando interviste con sei ufficiali anonimi dell’intelligence israeliana.
Il rapporto sostiene che l’IDF faceva molto affidamento su Lavender e trattava essenzialmente le informazioni su chi dovesse essere ucciso “come se fosse una decisione umanitaria”, dicono le fonti.
Una volta che un palestinese veniva collegato ad Hamas e veniva determinata l’ubicazione della sua casa, l’IDF ha effettivamente approvato la decisione della macchina, hanno detto le fonti. Gli ci sono voluti solo pochi secondi per esaminarla lui stesso.
L’indagine congiunta ha scoperto che la rapidità degli attacchi israeliani ha fatto ben poco per cercare di ridurre al minimo i danni ai civili nelle vicinanze. Lo scorso autunno sono venuti alla luce i dettagli del programma Gospel di Israele, rivelando che il progremma aveva aumentato la capacità di identificare obiettivi mirati, da circa 50 all’anno a più di 100 al giorno.
Interrogato sul rapporto, l’IDF ha rinviato il report con una dichiarazione “qualsiasi altra accusa dimostra una mancanza di conoscenza sufficiente delle operazioni dell’esercito di occupazione israeliano.”
Kobbi Shoshani, Console Generale di Israele a Mumbai (rappresentante ufficiale dello Stato di Israele nel Maharashtra, Gujarat, Madhya Pradesh e Goa), ha descritto il sistema come un database di controllo “progettato per aiutare l’analisi umana, non per sostituirla”, ma ci sono comunque dei rischi potenziali di falsi positivi, come in qualsiasi altro software ai, solo che in questo caso non è l’etichettatura di un prodotto, è la vita delle persone.
La diffusione dell’intelligenza artificiale in guerra si è ampliata
Israele non è l’unico paese che esplora il potenziale dell’intelligenza artificiale in guerra. Questa ricerca è accompagnata da una maggiore attenzione all’uso di sistemi senza pilota, come il mondo vede sempre più spesso in Ucraina e altrove, le preoccupazioni sui robot assassini non sono più solo fantascienza
“Proprio come l’intelligenza artificiale sta diventando più comune nel nostro lavoro e nella nostra vita personale, lo è anche nella nostra guerra”, ha detto a BI Peter Singer, un esperto di guerra del futuro presso il think tank New America, spiegando che “stiamo vivendo un nuovo rivoluzione industriale.” Proprio come con la recente meccanizzazione, il nostro mondo sta cambiando, sia in meglio che in peggio.
L’intelligenza artificiale si sta evolvendo più velocemente degli strumenti necessari per tenerla sotto controllo, e gli esperti hanno affermato che i rapporti sull’uso militare da parte di Israele sollevano una serie di preoccupazioni che sono da tempo al centro del dibattito sull’intelligenza artificiale nella guerra futura.
Molti paesi, tra cui Stati Uniti, Russia e Cina, hanno dato priorità all’implementazione di programmi di intelligenza artificiale nei loro eserciti, e al progetto americano Maven, che dal 2017 ha fatto grandi passi avanti per aiutare le forze sul terreno vagliando enormi quantità di informazioni. Tuttavia, la tecnologia si è spesso sviluppata più velocemente di quanto i governi riescano a tenere il passo.
econdo Ryan, la tendenza generale “è che la tecnologia e i requisiti del campo di battaglia stanno andando oltre la considerazione delle questioni legali ed etiche relative all’applicazione dell’intelligenza artificiale in guerra”. Gli attuali sistemi governativi e burocratici possono fare in modo che le politiche su queste questioni non possano tenere il passo, ha detto, aggiungendo che “potrebbero non riuscire mai a tenere il passo.” Lo scorso novembre, durante una conferenza delle Nazioni Unite, diversi governi hanno espresso preoccupazione sulla necessità di nuove leggi per regolamentare l’uso dei programmi killer autonomi, ovvero macchine guidate dall’intelligenza artificiale coinvolte nel prendere decisioni per uccidere gli esseri umani.
Ma alcuni paesi, soprattutto quelli attualmente all’avanguardia nello sviluppo e nell’implementazione di queste tecnologie, si sono mostrati riluttanti a imporre nuove restrizioni e, in particolare, Stati Uniti, Russia e Israele sono sembrati particolarmente riluttanti a sostenere nuove leggi internazionali in materia.
Saremo responsabili nell’uso militare dell’intelligenza artificiale!
“Molti militari hanno detto: ‘Fidati di noi, saremo responsabili di questa tecnologia’”, ha detto a BI Paul Scharre, un esperto di armi autonome presso il Center for a New American Security. Ma in assenza di supervisione, è improbabile che molte persone si fideranno dell’uso dell’intelligenza artificiale da parte di Alcuni paesi, come Israele, hanno poca fiducia nel fatto che i militari utilizzeranno sempre le nuove tecnologie in modo responsabile.
Un programma come Lavender, secondo quanto riferito, non sembra fantascienza ed è del tutto in linea con il modo in cui gli eserciti globali mirano a utilizzare l’intelligenza artificiale, ha detto Paul Scharre. e prendere decisioni su quali obiettivi attaccare. “Obiettivi come carri armati o pezzi di artiglieria”, ha detto a BI.
Il passo successivo è trasferire tutte queste informazioni in un piano di targeting, associarle ad armi o piattaforme specifiche e quindi agire effettivamente in base al piano.
Ci vuole molto tempo e, nel caso di Israele, c’è probabilmente il desiderio di sviluppare molti obiettivi molto rapidamente, ha detto Paul Scharre. Gli esperti hanno espresso preoccupazione sull’accuratezza di questi programmi di targeting dell’intelligenza artificiale. Utilizzare una varietà di canali di informazione, come i social media e l’uso del telefono, per fissare i propri obiettivi.
Nel rapporto +972 Magazine and Local Calls, le fonti affermano che il tasso di precisione del 90% del programma è considerato accettabile. Il problema evidente è il restante 10%, che rappresenta un sacco di errori considerando la portata della guerra aerea israeliana e la sua significatività.
L’intelligenza artificiale impara continuamente, nel bene e nel male, e con ogni utilizzo questi programmi acquisiscono conoscenza ed esperienza che poi utilizzano per prendere decisioni future. Con un tasso di precisione del 90%, osserva il rapporto, l’apprendimento automatico di Lavender può migliorare le informazioni corrette e sbagliate uccidendo vite umane.
Consentire all’intelligenza artificiale di prendere decisioni in guerra
Le guerre future potrebbero vedere l’intelligenza artificiale lavorare a fianco degli esseri umani per elaborare enormi quantità di dati e suggerire potenziali linee d’azione nel vivo della battaglia, ma ci sono molte possibilità che potrebbero inasprire tale partnership. I dati raccolti potrebbero essere troppi da elaborare o comprendere per gli esseri umani. Se un programma di intelligenza artificiale elabora enormi quantità di informazioni per preparare un elenco di potenziali obiettivi, potrebbe raggiungere un punto in cui gli esseri umani si sentiranno rapidamente sopraffatti e incapaci di contribuire in modo significativo al processo decisionale.
Esiste anche la possibilità di agire troppo rapidamente e fare ipotesi basate sui dati, aumentando la probabilità di errori, hanno scritto su tale questione nell’ottobre 2023 il consigliere militare e del gruppo armato del CICR Robin Stewart e il consigliere legale Georgia Hinds.
“Uno dei vantaggi militari dichiarati dell’intelligenza artificiale è l’aumento del ritmo decisionale che offre all’utente rispetto al suo avversario. Aumentare il ritmo spesso porta a rischi aggiuntivi per i civili, motivo per cui le tecnologie che riducono il ritmo, così come “pazienza tattica”, vengono utilizzati per ridurre le vittime civili.“ Nel loro tentativo di muoversi rapidamente, gli umani possono togliere le mani dal volante e fidarsi ciecamente dell’intelligenza artificiale con poca supervisione, secondo il rapporto della rivista 972+ e Local Calls. Infatti gli obiettivi vengono esaminati dall’IA per soli 20 secondi, di solito solo per assicurarsi che l’aspirante assassino fosse maschio, prima di autorizzare il colpo.
Rapporti recenti sollevano seri interrogativi sulla misura in cui le persone sono “in loop” durante il processo decisionale. Secondo Singer, è anche “un possibile esempio di ciò che a volte è noto come ‘distorsione della macchina’”, una situazione in cui “un essere umano inganna se stesso facendogli credere che, poiché una macchina ha fornito la risposta, deve essere corretta”. Quindi, l’essere umano potrebbe alle lunghe non fare il suo lavoro e fidarsi ciecamente delle macchine.
A ottobre, il segretario generale delle Nazioni Unite António Guterres e il capo del Comitato internazionale della Croce Rossa, Mirjana Spoljaric, hanno lanciato un appello congiunto affinché gli eserciti “devono agire ora per mantenere il controllo umano sull’uso della forza” in combattimento. “Il controllo umano sulle decisioni sulla vita e sulla morte deve essere mantenuto. La presa di mira degli esseri umani da parte delle macchine è una linea etica che non dobbiamo oltrepassare”, hanno affermato. “Il diritto internazionale deve vietare alle macchine capacità di uccidere senza l’intervento umano .”
L’altra faccia dell’intelligenza artificiale
Ma anche se ci sono dei rischi, l’intelligenza artificiale potrebbe avere molti vantaggi militari, come aiutare gli esseri umani a elaborare un’ampia gamma di dati e fonti per consentire loro di prendere decisioni informate, oltre a fornire una varietà di opzioni su come gestire le situazioni.
Una significativa collaborazione “human-in-the-loop” può essere vantaggiosa, ma alla fine spetta all’essere umano mantenere la fine di quella relazione. in altre parole, mantenere il potere e il controllo sull’intelligenza artificiale. Siamo padroni delle macchine, sia che si voli su un aereo, si guidi una nave o un carro armato, ma con molti di questi sistemi autonomi e nuovi algoritmi.
Molti eserciti non sono preparati per una simile trasformazione. Come hanno scritto Ryan e Clint Henot in un commento per War on the Rocks all’inizio di quest’anno, “Nel prossimo decennio, le imprese militari potrebbero realizzare una situazione in cui i sistemi senza pilota superano in numero gli esseri umani”.
“Attualmente, le tattiche, l’addestramento e i modelli di leadership delle organizzazioni militari sono progettati per istituzioni militari che sono principalmente umane, e questi umani esercitano uno stretto controllo sulle macchine”, hanno scritto.
“Cambiare l’istruzione e la formazione per preparare gli esseri umani a interagire con le macchine – e non solo a usarle – è un’evoluzione culturale necessaria ma difficile”, hanno affermato. Ma questo è ancora un lavoro in corso per molti militari.
Cosa ci riserverà il futuro? Difficile dirlo.
Sicuramente senza una corretta regolamentazione delle AI ad uso militare ci saranno molte più guerre per via del fatto che gli eserciti non saranno più faccia a faccia uno contro l’altro. Ma l’uso indiscriminato delle armi autonome porterà a molte vittime civili per via di quel 10% che abbiamo analizzato prima.
Germania in Prima Linea Contro le Minacce Informatiche: Nasce il CIR, l’Unità Speciale dell’Esercito! https://poliverso.org/display/0477a01e-3140bd1e-70b6d172cac28798 Germania in Prima Linea Contro le Minacce Informatiche: Nasce il CIR, l’Unità Speciale dell’Esercito! In risposta alle crescenti minacce informatiche, la Germania ha annunciato la creazione di un’unità informatica specializzatahttps://www.bmvg.de/de/aktuelles/bundeswehr-der-zeitenwende-kriegstuechtig-sein-um-abzuschrecken-5765386
Germania in Prima Linea Contro le Minacce Informatiche: Nasce il CIR, l’Unità Speciale dell’Esercito!
In risposta alle crescenti minacce informatiche, la Germania ha annunciato la creazione di un’unità informatica specializzata all’interno delle sue forze armate. La decisione è stata annunciata dal ministro della Difesa tedesco Boris Pistorius.
Il nuovo Cyber and Information Domain Service (CIR) diventerà il quarto dipartimento indipendente dell’esercito tedesco, insieme alle forze di terra, alla marina e all’aeronautica. Tutti i tipi di truppe saranno subordinate ad un unico centro di coordinamento del comando operativo della Bundeswehr. Il progetto di riorganizzazione dell’esercito viene chiamato “Struttura della Bundeswehr”.
Il compito principale della nuova unità è combattere le minacce ibride, comprese le operazioni di disinformazione e influenza, nonché svolgere compiti tattici nel campo della guerra informatica.
Boris Pistorius ha sottolineato che la creazione del CIR ha lo scopo di adattare le forze armate tedesche alla mutevole situazione geopolitica. Inoltre, il Ministro della Difesa ha indicato la necessità di aumentare il bilancio della difesa tedesco di 7,06 miliardi di dollari nel 2025 al fine di raggiungere l’obiettivo di spesa per la difesa della NATO pari al 2% del PIL.
Heat-set inserts are pretty cool, but you would be missing out if you're not trying what the woodworkers have in stock! Also, were my tests skewed previously...
The usual way to put a durable threaded interface into a 3D print is to use a heat-set insert, but what about other options? [Thomas Sanladerer] evaluates a variety of different threaded inserts, none of which are actually made with 3D printing in mind but are useful nevertheless.
There are a number of other easily-available threaded inserts, including the rivnut (or rivet nut), chunky hex socket threaded inserts intended for wood and furniture, heli-coils or helical inserts (which resemble springs), self-tapping threaded inserts (also sold as thread adapters), and T-nuts or prong nuts. They all are a bit different, but he measures each one and gives a thorough rundown on how they perform, as well as offering his thoughts on what works best.
[Thomas] only tests M5 fasteners in this video, so keep that in mind if you get ideas and go shopping for new hardware. Some of the tested inserts aren’t commonly available in smaller sizes. Self-tapping threaded inserts, for example, are available all the way down to M2, but the hex socket threaded inserts don’t seem to come any smaller than M4.
Building a Tape Echo In A Coke Can Tape Player That Doesn’t Really Work https://poliverso.org/display/0477a01e-4314bfc7-e8719aacc9521618 Building a Tape Echo In A Coke Can Tape Player That Doesn’t Really Work Back in the 1990s, you could get a tape player shaped like a can of Coca Cola. [Simon the Magpie] scored one of these decks and decided to turn it into a tape echo effect instead. https://www.youtube.com/watch?v=bKU9rQnIBCE It didn’t work so well, but the concept is a compelling one. You
Found a really silly little coca cola cassette player and decided to try and use for a tape echo. Needs a bit of work but overall I think I am on to somethin...
Building a Tape Echo In A Coke Can Tape Player That Doesn’t Really Work
Back in the 1990s, you could get a tape player shaped like a can of Coca Cola. [Simon the Magpie] scored one of these decks and decided to turn it into a tape echo effect instead. It didn’t work so well, but the concept is a compelling one. You can see the result in the video below.
The core of the effect is a tape loop, which [Simon] set up to loop around a pair of hacked-up cassette shells. This allows him to place one half of the loop in the Coca-Cola cassette player and the other half in a more conventional desktop tape deck. A 3D-printed bracket allows the two decks and the tape loop to be assembled into one complete unit.
The function is simple. The desktop tape deck records onto the loop, with the Coca-Cola unit then playing back that section of tape a short while later. Hey, presto — it’s a tape delay! It’s super lo-fi, though, and the tape loop is incredibly fragile.
There’s some charm in the warbly, weird sounds coming out of the Coca-Cola tape player. [Simon] turns this to his advantage and drops an incredibly catchy avant-garde pop hook with great results. It reminds us of some great DIY hardware we saw many years ago. We’ve been seeing a lot of tape echos lately, but we don’t know why.
Compaq Portable III is More Than Meets the Eye https://poliverso.org/display/0477a01e-54926ebb-29851f337bb17581 Compaq Portable III is More Than Meets the Eye The Compaq Portable III hails from the 386 era — in the days before the laptop form factor was what we know today. It’s got a bit of an odd design, but a compelling one, and the keyboard is pretty nifty, too. [r0r0] found one of these old-school machines and decided it was well worth refitting it to give it some https://hackaday.io/proje
The Compaq Portable III hails from the 386 era — in the days before the laptop form factor was what we know today. It’s got a bit of an odd design, but a compelling one, and the keyboard is pretty nifty, too. [r0r0] found one of these old-school machines and decided it was well worth refitting it to give it some modern grunt.
The Portable III ended up scoring a mini-ITX build, with an AMD Ryzen 7 3700X and an AMD RX580 GPU. Cramming all this into the original shell took some work, like using a vertical riser to fit in the GPU. Hilariously, the RGB RAM sticks are a little bit wasted when the enclosure is closed.
For the purists out there, you’ll be relieved to know the machine’s original plasma display was dead. Thus, a larger modern LCD was fitted instead. However, [r0r0] did play around with software to emulate the plasma look just for fun.
It’s funny to think you could once score one of these proud machines for free at a swap meet.
FPF CEO Jules Polonetsky thanked FPF’s Board Chair and Founder Chris Wolf, who served for 15 years, and welcomed FPF’s new Board Chair, Alan Raul. Three leading data protection regulators lauded FPF’s effectiveness in supporting their work, in the U.
Plasma Cutter on the Cheap Reviewed https://poliverso.org/display/0477a01e-c6473b73-d602eb1fbbda3356 Plasma Cutter on the Cheap Reviewed If you have a well-equipped shop, it isn’t unusual to have a welder. Stick welders have become a commodity and even some that use shield gas are cheap if you don’t count buying the bottle of gas. But plasma cutters are still a bit pricey. Can you get one from China for under $300? Yes. Do you want one that cheap? https://www.youtube.com/watch?v=X-peLKTniwQ
If you have a well-equipped shop, it isn’t unusual to have a welder. Stick welders have become a commodity and even some that use shield gas are cheap if you don’t count buying the bottle of gas. But plasma cutters are still a bit pricey. Can you get one from China for under $300? Yes. Do you want one that cheap? [Metal Massacre Fab Shop] answers that question in the video below.
First impressions count, and having plasma misspelled on the unit (plasme) isn’t promising. The instructions were unclear, and some of the fittings didn’t make him happy, so he replaced them with some he had on hand. He also added some pipe tape to stop any leaking.
The first test was a piece of quarter-inch steel at 35 amps. The machine itself is rated to 50 amps. Sparks ensued, and with a little boost in amperage, it made a fair-looking cut. At 50 amps, it was time to try a thicker workpiece. It made the cut, although it wasn’t beautiful. The leaking regulator and the fact that he can’t run the compressor simultaneously as the cutter didn’t help.
From the look of it, for light duty, this would be workable with a little practice and maybe some new fittings. Unsurprisingly, it probably isn’t as capable as a professional unit. Still could be very handy to have.
3D Printing a Cassette Is Good Retro Fun https://poliverso.org/display/0477a01e-9907b710-f32194c0da636210 3D Printing a Cassette Is Good Retro Fun The cassette is one of the coolest music formats ever, in that you could chuck them about with abandon and they’d usually still work. [Chris Borge] recently decided to see if he could recreate these plastic audio packages himself, with great success. https://www.youtube.com/watch?v=o0a3_SLwcNMHe kicked off his project by printing some examples of an
Double the plastic waste per unit of outdated media with this one weird trick.Patreon: https://www.patreon.com/ChrisBorge/membershipParts: https://www.printa...
The cassette is one of the coolest music formats ever, in that you could chuck them about with abandon and they’d usually still work. [Chris Borge] recently decided to see if he could recreate these plastic audio packages himself, with great success.
He kicked off his project by printing some examples of an open source cassette model he found online. The model was nicely accurate to the original Compact Cassette design, but wasn’t exactly optimized for 3D printing. It required a great deal of support material and wasn’t easy to customize.
[Chris] ended up splitting the model into multiple components, which could then be assembled with glue later. He then set about customizing the cassette shells with Minecraft artwork. Details of the artwork are baked into the model at varying heights just 1/10th of the total layer height. This makes it easy to designate which sections should be printed with which filament during his multi-colored print. And yet, because the height difference is below a full layer height, the details all end up on the same layer to avoid any ugly gaps between the sections. From there, it’s a simple matter of transferring over the mechanical parts from an existing cassette tape to make the final thing work.
It’s a neat trick, and the final results are impressive. [Chris] was able to create multicolored cassettes that look great. It’s one of the better uses we’ve seen for a multi-colored printer. This would be an epic way to customize a mixtape for a friend!
Chatcontrol: i ministri dell'Unione Europea non vogliono la scansione indiscriminata dei messaggi. Ma solo per sé stessi e per i loro amici!
Secondo l'ultima bozza della controversa proposta di regolamento UE sugli abusi sessuali sui minori, trapelata dalla testata giornalistica francese Contexte.com, i ministri degli Interni dell'UE vogliono esentarsi dal controllo della chat e dalla scansione collettiva dei messaggi privati
Secondo l’ultima bozza della controversa proposta di regolamento UE sugli abusi sessuali sui minori, trapelata dalla testata giornalistica francese Contexte.com…
Last time, we’ve used a logic analyzer to investigate the ID_SD and ID_SC pins on a Raspberry Pi, which turned out to be regular I2C, and then we hacked hotplug into the Raspberry Pi camera c…
Last time, we looked into using a logic analyzer to decode SPI signals of LCD displays, which can help us reuse LCD screens from proprietary systems, or port LCD driver code from one platform to another! If you are to do that, however, you might find a bottleneck – typically, you need to capture a whole bunch of data and then go through it, comparing bytes one by one, which is quite slow. If you have tinkered with Pulseview, you probably have already found an option to export decoded data – all you need to do is right-click on the decoder output and you’ll be presented with a bunch of options to export it. Here’s what you will find:
Whether on the screen or in an exported file, the decoder output is not terribly readable – depending on the kind of interface you’re sniffing, be it I2C, UART or SPI, you will get five to ten lines of decoder output for every byte transferred. If you’re getting large amounts of data from your logic analyzer and you want to actually understand what’s happening, this quickly will become a problem – not to mention that scrolling through the Pulseview window is not a comfortable experience.
The above output could look like this: 0x22: read 0x01 ( DEV_ID) = 0x91 (0b10010001). Yet, it doesn’t, and I want to show you how to correct this injustice. Today, we supercharge Pulseview with a few external scripts, and I’ll show you how to transfer large amounts of Sigrok decoder output data into beautiful human-readable transaction printouts. While we’re at it, let’s also check out commandline sigrok, avoiding the Pulseview UI altogether – with sigrok-cli, you can easily create a lightweight program that runs in the background and saves all captured data into a text file, or shows it on a screen in realtime!
Oh, and while we’re here, I’d like to show you a pretty cool thing I’ve found on Aliexpress! These are tiny FX2 boards with the same logic analyzer schematic, so they work with the FX2 open-source firmware and Sigrok – but they’re much smaller, have USB-C connectors instead of cable struggle that is miniUSB, and are often even cheaper than the ‘plastic case’ FX2 analyzers we’ve gotten used to. In addition to that, since you can see the exposed PCB, unlike with the ‘plastic case’ analyzers, you know whether you’re getting input buffers or not!
Boiling It Down
As an example, let’s consider a capture of the I2C bus of the Pinecil soldering iron. On this bus, there’s three I2C devices – a 96×16 OLED screen at the address 0x3c, an accelerometer at 0x18, and the FUSB302B USB-PD PHY at 0x22. The FUSB302B is a chip that we remember from the USB-C low-level PD communication articles where we built our own PD trigger board. I could only have written those articles because I got the logic analyzer captures, processed them into transaction printouts, and used those to debug my PD code – now, you get to learn how to use such captures for your benefit, too.
If you open the above files in Pulseview – you will see a whole bunch of I2C traces. I wanted to zone in on the FUSB302, naturally – accelerometer and OLED communications are also interesting but weren’t my focus. You will also see that there’s a protocol decoder called “I2C filter” attached. Somehow, it’s been remarkably useless for me whenever I try to use it, not filtering out anything at all. No matter, though – right click on the I2C decoder output row (the one that shows decoded bytes and events), click “Export all annotations for this row”, pick a filename, then open the file in a text editor.
The view you get is a bit overwhelming – we get 22,000 lines of text, which is nowhere near the kind of data you could feasibly read through. Of course, most of that is LCD transfer data, and there’s a fair bit of accelerometer querying, too – you want to filter out both of these if you want to only see the FUSB302 transactions. Nevertheless, it’s a good start – you get a text file that contains all the activity happening on the I2C bus, it’s just too much text to read through on your own.
Here’s an example line: 2521783-2521834 I²C: Address/data: Address write: 30. This is very easy to process, if you take a closer look at it! Each line describes an I2C event, and it starts with two timestamps – event start and event end, separated by - . Then, we get three more values, separated by spaces – decoder name, decoder event type, and the decoder event itself. This output format can be changed in Pulseview settings, if you’re so inclined, however, you can easily parse it as-is. For this format, we can simply split the string by space (not splitting further than three spaces), getting a timestamp, decoder name, decoder output type and decoder event.
I’ll be using Python for parsing, but feel free to translate the code into anything that works for you. Here’s a bit of Python that reads our file line-by-line and puts the useful parts of every line into variables: with open('decoded.txt', 'r') as f: line = f.readline() while line: line = line.strip() if not line: # empty line terminates the loop, use `continue` to ignore empty lines instead break # ignoring decoder name and decoder output type - they don't change in this case tss, _, _, d = line.split(' ', 3) [ "do something with this data" ] line = f.readline() # get a new line and rerun the loop body
Parsing lines of text into event data is simple enough – from there, we need to group events into I2C transactions. As you can see, a transaction starts with a Start event, which we can use as a marker to separate different transactions within all the events we get. We can do the usual programming tactic – go through the events, have one “current transaction” list that we add new events to, and an “all transactions so far” list where we put transactions we’ve finished processing.
The plan is simple – in the same loop, we look at the event we get, and if it’s not a Start event, whether it’s a write/read/ACK/NACK bit event, or Stop/Start repeat event, we simply put it into the “current transaction” list. If we get a new Start event, we consider this “current transaction” list finished and add it to our list of received transactions, then start a new “current transaction” list. While we’re at it, we can also parse address and data bytes – we receive them as strings and we need to parse them as hex digits, unless you change the I2C decoder to output something else.
Here’s a link to the relevant code section. I could talk more about what it does, for instance, it filters out the FUSB302 transfers by the address, but I’d like to cut to the chase and show the input lines compared to the output transaction list. You can get this output if you run python -i parse.py and enter tr[0] in the REPL: >>> tr [0]['start', 34, 'wr', 'ack', 'wr', 1, 'ack', 'start repeat', 34, 'rd', 'ack', 'rd', 145, 'nack', 'stop']
Now, this is a proper I2C transaction! All of these elements are things we can visually discern in the Pulseview UI. Mind you, this code is tailored towards the FUSB302 transaction parsing, but it should not be hard to modify it so that it singles out and parses accelerometer or OLED transactions instead. From here, it’s almost enough to simply concatenate the transaction list elements and get a semi-human-readable transaction, but let’s not stop our ambitions here – the FUSB302 has documentation available, and we can get to a perfectly readable decoding of what the code actually does!
I’ve scrolled through the datasheet, and put together a Python dictionary with a register address-name mapping. Using that, we can easily go through transactions, mapping them to specific register reads and writes, and convert the raw transaction data into lines of text that clearly tell us – first, we write this byte to SWITCHES0 register, then we write a this byte into POWER register, and so on. Here’s the code I wrote to make verbose transactions – and it helps you turn logic analyzer captures into Python code!
Say, you’re writing a replacement open-source firmware for something you own, or perhaps you’re poking around copying the implementation of some protocol for your own purposes, like I copied the Pinecil’s PD implementation to help me debug my own PD code. Here’s the cool part – you can translate this kind of output into your own high-level code near-instantly, to the point where you can even modify this decoding script to output Python or C code! This is just like decompiling, except you get a language of your choice, and a human-readable description of the code’s external behaviour, which is often what you actually want.
Here’s how a verbose transaction list looks: [34, '0x22', 1, '0x01 ( DEV_ID)', 'rd', [145], '0x91 (0b10010001)']. And, this is how I can format such a transactions, using a helper function included in the code I’ve linked: >>> tr_as_upy(transactions[0]) i2c.readfrom_mem(0x22, 0x1) # rd: DEV_ID 0x91 (0b10010001) >>> tr_as_upy(transactions[1]) i2c.writeinto_mem(0x22, 0xc, b'\x01') # wr RESET: 0x01 (0b00000001)
Such code allows you to rapidly reverse-engineer proprietary and open-source devices, while getting a good grasp on what is it specifically that they do. What more, with such a decoder, you can also write a protocol decoder for Sigrok so that you can easily access it from Pulseview! For instance, if you’re capturing reads/writes for an I2C EEPROM, there’s an I2C EEPROM decoder in Sigrok that you can add – and, there’s never enough Sigrok decoders, so adding your own decoder to the pile is a wonderful contribution to the open-source logic analysis software that everybody knows and loves.
Going Further With Commandline
This decoding approach gives you the most control over your output data, which massively helps if you have to process large amounts of it. You can also debug intricate problems like never before. For instance, I’ve had to help someone debug a web-based ESP8266 flasher that can’t flash particular kinds of firmware images properly, and for that, I’m capturing the UART data being transferred between the PC and the ESP8266.
There’s a problem with such capturing, too – during flashing, the UART baudrate changes, with the bootloader baudrate being 76800, the flashing baudrate being 468000, and the software baudrate being 115200. As a result, you can’t pull off the usual trick where you connect a USB-UART adapter’s RX pin to your data bus and have it stream data to a serial terminal window on your monitor. Well, with granular control over how you process data captured by the logic analyzer, you don’t have to bother with that! Bytes received at 76800 marked in orange, bytes received at 11500 marked in greed; the exact commandline visible in the screenshot, too! The idea is – you connect a logic analyzer to the data bus, and stack two UART decoders onto the same pin! Each decoder is going to throw error messages whenever the current signal is on a different baudrate than the decoder’s expected one. Now, Sigrok being a reasonably modular and open-source project, you can absolutely write a UART decoder for Sigrok that works with multiple baudrates. If you’re like me and don’t want to do that, you can also go the lazy way about it and mash the output of two decoders together in realtime, using error messages as guidance on where the switch occured!
For this kind of purpose, having realtime and text-only processing of Sigrok-produced data is more than enough. Thankfully, the FX2 analyzers let you capture data indefinitely, and Sigrok commandline lets you stack protocol decoders that will then run in realtime! So, I’ve made a script that you can pipe sigrok-cli output into, which compares decoder output to figure out which baudrate is currently being used, and outputs data from the decoder with the least faults. The code’s missing a smarter buffering algo, so the switching-between-baudrates moment is a bit troublesome, as you can see in the screenshot, but it’s working otherwise!
With this Sigrok commandline approach, you gain one more logic analyzer superpower! Since FX2 analyzers let you capture data indefinitely, streaming it to your PC as it is captured, a commandline decoder lets you wire up a FX2 analyzer to a Pi Zero – so you can build a tiny device capturing and decoding a data bus 24/7. Set the FX2 and Pi Zero combo near whatever you’re trying to tap into, run sigrok, have it save data with timestamps onto an SD card, and you can collect weeks of bus activity data easily! This is the kind of capability I wish I had when I was tasked with reverse-engineering a special piece of industrial machinery, controlled over CAN and using a semi-proprietary communication algorithm; having lots of data seriously helps in such scenarios and I was struggling to capture enough.
If you’d rather keep to low-depth GUI experiments, this kind of parsing is useful too – Sigrok protocol decoders are written in Python, which means you can also take your Python output-parsing code and turn it into Pulseview-accessible protocol decoder reasonably easily. All in all, this kind of experimentation lets you squeeze as much as possible out of even the cheapest logic analyzers out there. In the next article, I’d like to go more in-depth through other kinds of logic analyzers we have available – especially all the the cheap options. Given that Sigrok has recently merged the PR with support for the Pi Pico, there’s a fair bit you can get beyond what the FX2-based analyzers have to offer!
Analyzing the Code From The Terminator’s HUD https://poliverso.org/display/0477a01e-0272215f-cf433ff2eb8c1f11 Analyzing the Code From The Terminator’s HUD The T1000, also known as the Terminator, was like some kind of non-giving up robot guy. The robot assassin viewed the world through a tinted view with lines of code scrolling by all the while. It was cinematic shorthand to tell the audience they were looking through the eyes of a machine. Now, a YouTuber called [Open Source] has analyzed
The T1000, also known as the Terminator, was like some kind of non-giving up robot guy. The robot assassin viewed the world through a tinted view with lines of code scrolling by all the while. It was cinematic shorthand to tell the audience they were looking through the eyes of a machine. Now, a YouTuber called [Open Source] has analyzed that code.
The video highlights one interesting finds, concerning graphics seen in the T-1000’s vision. They appear to match the output of various code listings and articles in Nibble Magazine, specifically its September 1984 issue. One example spotted was a compass rose, spawned from an Apple Basic listing. it was a basic quiz to help teach children to understand the compass. Another graphic appears to be cribbed from the same issue in the MacPaint Patterns section.
The weird thing is that the original film came out in October 1984 — just a month after that article would have hit the news stands. It suggests perhaps someone involved with the movie was also involved or had access to an early copy of Nibble Magazine — or that the examples in the magazine were just rehashed from some other earlier source.
Code that regularly flickers in the left of the T-1000s vision is just 6502 machine code. It’s apparently just a random hexdump from an Apple II’s memory. At other times, there’s also 6502 assembly code on screen which includes various programmer comments still intact. There’s even some code cribbed from the Apple II DOS 3.3 RAM Disk driver.
It’s neat to see someone actually track down the background of these classic graphics. Hacking and computers are usually portrayed in a fairly unrealistic way in movies, and it’s no different in The Terminator (1984). Still, that doesn’t mean the movies aren’t fun!
Addio influenza e controllo. La Cina in 3 anni eliminerà i chip stranieri dai sistemi di telecomunicazione
La settimana scorsa, le autorità cinesi hanno ordinato ai tre maggiori colossi delle telecomunicazioni del Paese – China Telecom, China Mobile e China Unicom – di eliminare completamente i semiconduttori statunitensi dalle loro apparecchiature nei prossimi tre anni. Gli operatori dovranno fornire progetti per la graduale sostituzione di questi chip con analoghi nazionali.
Questa decisione, presa dal Ministero cinese dell’Industria e dell’Information Technology, non è di buon auspicio per Intel e AMD , poiché il mercato cinese rappresentava rispettivamente il 27% e il 15% dei ricavi delle società nel 2023.
Questo ordine è stata la risposta della Cina alla decisione della Federal Communications Commission statunitense di cinque anni fa. Questo quando l’organizzazione ha vietato l’uso dei prodotti Huawei e ZTE nelle reti di telecomunicazioni americane. La ragione di ciò era il timore che queste apparecchiature potessero contenere backdoor per lo spionaggio, perché secondo le leggi cinesi, le aziende locali sono obbligate a trasferire qualsiasi informazione alle autorità. Tuttavia, Huawei ha più volte dichiarato che non permetterà mai che i suoi prodotti vengano utilizzati per tali scopi e rispetta rigorosamente le leggi dei paesi in cui opera.
Tuttavia, non è ancora chiaro se verrà fornito sostegno finanziario agli operatori di telecomunicazioni cinesi per compensare i costi di sostituzione dei chip stranieri con quelli nazionali.
Come ha dimostrato l’esperienza americana con l’abbandono delle apparecchiature Huawei, questo processo può essere molto costoso. Sebbene la Federal Communications Commission abbia stanziato 1,9 miliardi di dollari ai produttori, le aziende hanno richiesto oltre 5,6 miliardi di dollari in più.
La scadenza del 2027 per completare la transizione ai chip cinesi è solo un passo negli sforzi in corso da parte della Cina per ridurre la propria dipendenza dalla tecnologia americana. Alla fine dell’anno scorso, Pechino ha anche pubblicato un elenco di 18 processori approvati per l’uso nel paese. Questo elenco non includeva chip Intel e AMD, invece, c’erano chip cinesi compatibili con x86 sviluppati da Shanghai Zhaoxin basati su tecnologie della taiwanese VIA.
La Cina ha accelerato la sua mossa per sostituire la tecnologia occidentale con la propria a causa delle restrizioni statunitensi sull’accesso alla tecnologia avanzata dei processori di intelligenza artificiale e alle apparecchiature per la produzione di chip.
Nonostante le sfide, le aziende cinesi, tra cui Huawei e SMIC, hanno fatto progressi nella creazione di chip ad alte prestazioni. Questa settimana Huawei ha annunciato che costruirà un centro di ricerca e sviluppo vicino a Shanghai che svilupperà le proprie attrezzature per produrre componenti per comunicazioni wireless, apparecchiature di rete e smartphone.
Come spesso abbiamo riportato su queste pagine, l’effetto delle sanzioni statunitensi sta alimentando una corsa alla tecnologia proprietaria sia in Russia che in Cina, portando le due superpotenze ad una loro autonomia nel mondo tecnologico. La Cyber-politica e la sicurezza nazionale oggi è un elemento imprescindibile per ogni regione dello scacchiere geopolitico moderno e solo il tempo potrà fornirci una chiara indicazione se la politica statunitense basata sulle “sanzioni”, avviata ormai da anni porterà un vantaggio o uno svantaggio strategico.
Va da se che ad oggi, l'”autonomia tecnologica” e le “tecnologie domestiche” sono diventati un argomento di importante discussione a livello politico sia in Cina che in Russia, quando altri paesi non sanno neppure l’esistenza del concetto.
Nice initiative 👏 👏 "For that, end-users should be able to run Free Software on their devices and use services independently of the control exercised by device manufacturers, vendors, and platforms." https://deviceneutrality.org/#principles
Gli Hacker rubano 40 TB di dati dal server del Dipartimento IT di Mosca
Secondo gli specialisti di Data Leakage & Breach Intelligence (DLBI), il gruppo di hacker di DumpForums ha annunciato di aver violato il server del Dipartimento di tecnologia dell’informazione di Mosca (mos[.]ru/dit/).
Gli aggressori affermano di aver rubato circa 40 TB di dati.
Nel loro canale Telegram, il gruppo ha riferito che l’hacking sarebbe avvenuto un anno fa e per tutto questo tempo erano stati sulla rete DIT, poiché tutti i tentativi di bloccare il loro accesso erano stati invani. “Durante la nostra permanenza, siamo riusciti ad hackerare tutte le risorse tecniche del DIT, a scaricare 40 TB di database di varie risorse di Mosca tra cui: EMIAS, IS UDRVS, Portale del sindaco di Mosca, SUDIR e altri. Tutte le informazioni ricevute sono state elaborate, quindi tutto il necessario è stato estratto e lo stiamo già utilizzando per lavorare su altri obiettivi”, ha affermato DumpForums.
Per confermare le loro parole, gli hacker hanno pubblicato un dump con la tabella utente (cwd_user) della risorsa interna jira.cdp.local.
DLBI scrive che la tabella contiene 335.586 righe, tra cui:
Nome utente;
Cognome;
indirizzo email (288.395 indirizzi nel dominio @mos.ru);
data di registrazione e aggiornamento anagrafico (dal 24/05/2019 al 20/06/2023);
identificatori interni.
I ricercatori notano inoltre che, secondo i loro dati, qualche tempo fa in una vendita chiusa è apparso un dump con i dati presumibilmente zdrav.mos[.]ru, datati settembre 2023.
I rappresentanti del DIT Mosca non hanno ancora commentato le dichiarazioni degli hacker
Una backdoor sui firewall di Palo Alto è stata utilizzata dagli hacker da marzo
Come avevamo riportato in precedenza, un bug critico è stato rilevata all’interno dei firewall di Palo Alto. Degli sconosciuti hanno sfruttato con successo per più di due settimane una vulnerabilità0-day nei firewall di Palo Alto Networks, hanno avvertito gli esperti di Volexity.
Il bug su Palo Alto Firewall
Il problema è identificato come CVE-2024-3400 (punteggio CVSS 10) è una vulnerabilità di command injection che consente agli aggressori non autenticati di eseguire codice arbitrario con privilegi di root. Per utilizzarlo non sono richiesti privilegi speciali o interazione con l’utente.
Secondo il produttore, tutti i dispositivi che eseguono PAN-OS versioni 10.2, 11.0 e 11.1 che hanno il gateway GlobalProtect e la telemetria abilitati sono vulnerabili a CVE-2024-3400. Altre versioni di PAN-OS, firewall cloud e dispositivi Panorama e Prisma Access non sono interessate dal problema.
Attualmente sono già stati rilasciati hotfix per PAN-OS 10.2.9-h1, PAN-OS 11.0.4-h1, PAN-OS 11.1.2-h3 e versioni successive di PAN-OS. Nel prossimo futuro sono previste anche patch per altre versioni utilizzate di frequente. Le relative date di rilascio esatte possono essere trovate nel bollettino sulla sicurezza dedicato al problema.
“Palo Alto Networks è consapevole dello sfruttamento di questo problema. Stiamo monitorando lo sfruttamento iniziale di questa vulnerabilità, chiamata Operazione MidnightEclipse, perché crediamo con assoluta certezza che gli exploit conosciuti che abbiamo esaminato fino ad oggi siano limitati a un singolo aggressore”, ha affermato Palo Alto Networks.
Chi sta sfruttando la vulnerabilità e installando backdoor
Secondo gli analisti di Volexity che hanno scoperto la vulnerabilità, gli hacker sfruttano CVE-2024-3400 da marzo di quest’anno e introducono una backdoor personalizzata nei sistemi delle vittime per penetrare nelle reti interne delle aziende e rubare dati.
Volexity segue gli aggressori con il nome in codice UTA0218 e afferma che gli attacchi sono chiaramente legati a “hacker governativi”, ma non è ancora riuscita a collegare l’attività degli aggressori a un paese specifico o ad altri gruppi di hacker.
“Volexity ritiene che sia molto probabile che UTA0218 sia un aggressore sponsorizzato dallo stato in base alle risorse necessarie per sviluppare e sfruttare questo tipo di vulnerabilità, al tipo di vittime prese di mira e alle capacità dimostrate durante l’installazione della backdoor Python e il successivo accesso a reti di vittime”, dicono i ricercatori.
Volexity afferma di aver notato l’exploit il 10 aprile 2024 e di aver notificato l’exploit a Palo Alto Networks. Il giorno successivo Volexity ha scoperto uno “sfruttamento identico” dello stesso problema sulla rete di un altro cliente. In questi casi, il problema veniva sfruttato per creare reverse shell e scaricare payload aggiuntivi.
Ulteriori indagini hanno rivelato che gli aggressori avevano sfruttato CVE-2024-3400 almeno dal 26 marzo, ma hanno distribuito il payload solo il 10 aprile. Secondo i ricercatori, uno dei principali payload degli aggressori è un malware Upstyle personalizzato, sviluppato appositamente per PAN-OS e che funge da backdoor per l’esecuzione di comandi sui dispositivi compromessi.
La backdoor viene installata utilizzando uno script Python che crea un file di configurazione del percorso in /usr/lib/python3.6/site-packages/system.pth. Questo file è la backdoor Upstyle; monitora i registri di accesso del server web per estrarre comandi codificati base64 per l’esecuzione.
L’installazione della backdoor Upstyle
“I comandi da eseguire vengono generati richiedendo una pagina web inesistente con un modello specifico. Il compito della backdoor è analizzare il registro degli errori del server web (/var/log/pan/sslvpn_ngx_error.log) per questo modello, trasformare e decodificare i dati aggiunti all’URI inesistente e quindi eseguire il comando risultante. Successivamente, i risultati del comando vengono aggiunti al file CSS, che fa parte del firewall (/var/appweb/sslvpndocs/global-protect/portal/css/bootstrap.min.css)”, spiegano gli esperti. Oltre alla backdoor descritta, i ricercatori hanno osservato gli aggressori installare payload aggiuntivi per avviare reverse shell, estrarre dati di configurazione PAN-OS, eliminare registri e distribuire uno strumento di tunneling chiamato GOST.
In uno degli attacchi, ad esempio, gli hacker sono entrati nella rete interna dell’azienda per rubare file riservati in Windows, tra cui “il database di Active Directory (ntds.dit), i dati DPAPI e i registri degli eventi di Windows (Microsoft-Windows-TerminalServices-LocalSessionManager% 4.evtx operativo)”. Gli aggressori hanno anche rubato file di Google Chrome e Microsoft Edge su alcuni dispositivi presi di mira, inclusi credenziali e cookie.
Remembering Peter Higgs and the Gravity of His Contributions to Physics https://poliverso.org/display/0477a01e-2f2fae60-8a44bc7f47e51195 Remembering Peter Higgs and the Gravity of His Contributions to Physics There are probably very few people on this globe who at some point in time haven’t heard the term ‘Higgs Boson’ zip past, along with the term ‘God Particle’. As during the 2010s the scientists at CERN were trying to find evidence for the existence of this scalar boson and with it
Remembering Peter Higgs and the Gravity of His Contributions to Physics
There are probably very few people on this globe who at some point in time haven’t heard the term ‘Higgs Boson’ zip past, along with the term ‘God Particle’. As during the 2010s the scientists at CERN were trying to find evidence for the existence of this scalar boson and with it evidence for the existence of the Higgs field that according to the Standard Model gives mass to gauge bosons like photons, this effort got communicated in the international media and elsewhere in a variety of ways.
Along with this media frenzy, the physicist after whom the Higgs boson was named also gained more fame, despite Peter Higgs already having been a well-known presence in the scientific community for decades by that time until his retirement in 1996. With Peter Higgs’ recent death after a brief illness at the age of 94, we are saying farewell to one of the big names in physics. Even if not a household name like Einstein and Stephen Hawking, the photogenic hunt for the Higgs boson ended up highlighting a story that began in the 1960s with a series of papers.
Breaking Symmetry
Much of what we can observe around us is based around symmetry, whether it’s our own bodies, plants or planets. Yet the question that should be asked here is: symmetrical on what level? A tree branch is symmetrical, up till where it branches off, and its trunk is symmetrical except where it’s not. Similarly, our own bodies like to break symmetry so that we only have one liver and one heart, despite having two eyes and two brain hemispheres, generally speaking. This breaking of symmetry is something that can be observed on any level, including that of the Universe itself on a fundamental level.
When the Universe first came into existence, for a brief moment it would have existed in perfect symmetry in its high energy state, but as we can observe today this state did not persist. Rather than maintain this perfect state of symmetry, something caused this symmetry to spontaneously break and separate into areas of distinct mass. These areas would coalesce into nebulae, stars and ultimately the galaxies courtesy of which we are able to contemplate our place in the Universe today. Figuring out the exact nature of the symmetry breaking that led to this was the topic of much discussion among particle physicists during the 20th century.
Essentially, what could cause the continuous symmetry across spacetime to break? Of most importance here is gauge symmetry, which gives rise to the strong, weak and electromagnetic forces. The strong interaction is explained by quantum chromodynamics using the quark model. The weak (W and Z bosons) and electromagnetic (photons) forces are unified in the electroweak interaction, but these particles require an additional mechanism for their formation. Initially the Standard Model predicted the W and Z bosons to have no rest mass, while in reality they have quite significant masses. To resolve this, the Higgs mechanism was introduced, which involved the Higgs field and a short-lived scalar boson particle that had no spin, no charge, but a significant mass which could be imparted on gauge bosons by breaking electroweak symmetry.
Three Papers
The ‘Sombrero Potential’ as seen with the Higgs mechanism. A fascinating aspect of the Higgs mechanism’s history is that the symmetry breaking aspect behind it was practically simultaneously explored by three different teams of physicists during the early 1960s and published in Physical Review Letters in 1964. The first article was by François Englert and Robert Brout, titled Broken Symmetry and the Mass of Gauge Vector Mesons. The second was by Peter W. Higgs and titled Broken Symmetries and the Masses of Gauge Bosons. Finally, the third paper was by Gerald Guralnik, Carl Hagen and Tom Kibble (GHK), and titled Global Conservation Laws and Massless Particles.
Although these papers sound incredibly similar, they each propose a different approach to how mass could arise in vector gauges without breaking gauge invariance, i.e. the Lagrangian field of the system remains unchanged under local transformations (invariant Lagrangian). The basic theory behind spontaneous symmetry breaking had been published by Yoichiro Nambu in 1960, which led to this being worked into a mechanism which could resolve the mass-less W and Z boson conundrum. Of these, the Higgs and GHK papers contained the equations for a hypothetical field which would become known as the Higgs field, along with the newly proposed scalar boson. Here another major difference is that in the Higgs paper the scalar boson has a large mass, while in the GHK paper it is massless, akin to the Nambu-Goldstone boson quasi-particle proposed by Yoichiro Nambu.
After these papers, both Steven Weinberg and Abdus Salam showed independently from each other in 1967 how the Higgs mechanism could break the electroweak symmetry, leading to the formulation of the Standard Model as we know it today. It also cleared the way for figuring out an experiment that could provide evidence for the existence of the Higgs field, using the mass of its associated boson.
Collision Debris
How do you detect a sub-atomic particle? The answer is clearly to build the biggest scientific instruments known to man, as it wasn’t until the Large Hadron Collider (LHC) with its 27 kilometer circumference finished construction in 2008 that humankind had a particle collider with enough energy behind it to conclusively test for the existence of the Higgs boson. With the first collisions in 2010, the race was on to detect this elusive scalar boson with its suspected massive mass. The only snag was that this boson was expected to exist so briefly that any detector used would only be able to detect its decay products.
Each decay process creates what is called a ‘decay channel’, which is effectively a particular signature. Because of how rarely a Higgs boson was thought to form, many collisions would be required for the two main particle detectors at the LHC (ATLAS and CMS) to collect enough of these signatures to establish with some certainty (typical five sigma rule) that the channels detected were indeed from this new boson. With the amount of data generated from each collision and the two particle detectors this was akin to searching for a needle in a haystack.
Then in 2012 the five sigma confidence level was reached and exceeded, leading to the aforementioned media frenzy, as many had caught on that something monumental was about to happen in the world of particle physics with potentially far-reaching consequences. As the Higgs boson’s ~125 GeV/c2 mass was announced, the world had mostly moved on already, beyond understanding that the ‘god particle’ had been found. Yet to particle physicists this was a monumental event, even if many of those present during the days in the 1960s and 1970s when these predictions were laid were no longer around to witness it.
The Standard Model was now complete, other than the minor niggle of this ‘gravity’ thing and what might be gravitons.
Beyond The Physics
To Peter Higgs, the field of particle physics was much of his life, though he also enjoyed hiking and was outspoken in a number of areas. It was at the UK’s Campaign for Nuclear Disarmament (CND) that he met fellow activist Jody Williamson whom he’d end up marrying. He also was a member of Greenpeace and identified as an atheist, more interested in reality of science than any kind of ideology of dogma. This led him to quit CND as soon as they began to campaign against nuclear power (“a really bad mistake”) and similarly with Greenpeace when they began to oppose genetically engineered organisms (GMO). Calling their actions ‘hysterical’, he had to resign his membership.
This made it rough on him when the term ‘god particle’ began to buzz around. The term itself seems to come from Leon M. Lederman’s book The God Particle, due to how the Higgs boson is so elusive and yet essential to the very existence of the Universe and everything in it. Without the Higgs field and mechanism there would be no galaxies, no planets or suns, or life to wonder at its place in it all. As this name led to many confusing the scalar boson with something religiously profound, including evidence for the existence of one’s favorite deity or deities, it really rubbed Peter Higgs the wrong way.
With the subsequent years after the discovery of the Higgs boson even more details about it were filled in, cementing the Higgs mechanism’s place in the Standard Model and gave Peter Higgs the knowledge that his theories had indeed been correct, an honor which he shared with other physicists involved in the decades-long discovery. Although he won’t be around to see what comes next, it are the efforts from scientists like Peter Higgs which will inspire future generations of scientists for centuries to come.
How Do You Make A Repairable E-Reader https://poliverso.org/display/0477a01e-6c897fa5-8653596ebc98e811 How Do You Make A Repairable E-Reader Mobile devices have become notorious for their unrepairability, with glued-together parts and impossible-to-reach connectors. So it’s refreshing to see something new in that field from the e-book reader brand Kobo in the form of a partnership with iFixit to ensure that their new reader line can be https://goodereader.com/blog/kobo-ereader-news/new-kobo-e
Mobile devices have become notorious for their unrepairability, with glued-together parts and impossible-to-reach connectors. So it’s refreshing to see something new in that field from the e-book reader brand Kobo in the form of a partnership with iFixit to ensure that their new reader line can be fixed.
Naturally, we welcome any such move, not least because it disproves the notion that portable devices are impossible to make with repairability in mind. However, the linked article is especially interesting because it includes a picture of a reader, and its cover has been removed. We’re unsure whether or not this is one of the new ones, but it’s still worth looking at it with reparability eyes. Just what have they done to make it easier to repair?
The first thing which strikes us is that the screws securing the board are larger than on many devices and positioned for easy access. Then the battery connector isn’t the tiny snap-in connector we’re used to seeing on phones, but wires and an easy-to-use small two-pin plug. The digitiser and screen cables remain flexible PCB connectors, but despite finding those flip-up latches to be fragile at best, we’re guessing there’s little alternative to be found there.
We hope that these readers will be successful enough that other manufacturers may take up the idea and even that it might educate the public that such a thing is possible.
Il software open source è così integrato nella nostra vita che sarebbe difficile pensare ad un mondo senza di esso. Scopriamo la sua storia in questo articolo.
La backdoor XZ Utils è ora embedded in altri software. Ora anche su Rust liblzma-sys
Una nuova scoperta dei ricercatori del Phylum fa luce su un grave problema di sicurezza che affligge la comunità open source. A quanto pare, il pacchetto liblzma-sys, ampiamente utilizzato dagli sviluppatori Rust. E’ stato divulgato con file di test dannosi relativi alla backdoor nello strumento di compressione dati XZ Utils ampiamente trattata recentemente.
Con oltre 21.000 download, liblzma-sys offre agli sviluppatori Rust l’accesso all’implementazione liblzma, una libreria che fa parte di XZ Utils. La versione 0.3.2 di questo pacchetto era interessata.
Secondo la pagina del numero di GitHub aperta il 9 aprile, “l’attuale distribuzione (v0.3.2) su Crates.io contiene file di test per XZ che includono una backdoor“. Stiamo parlando dei file “tests/files/bad-3-corrupt_lzma2.xz” e “tests/files/good-large_compressed.lzma”.
A seguito di una divulgazione responsabile, questi file dannosi sono stati rimossi da liblzma-sys nella versione 0.3.3, rilasciata il 10 aprile. Allo stesso tempo, la versione precedente del pacchetto è stata completamente rimossa dal registro di Crates.io.
Come hanno spiegato i ricercatori di Snyk, sebbene i file di test dannosi siano stati caricati nel repository principale liblzma-sys, a causa della mancanza di istruzioni di compilazione dannose, non sono mai stati richiamati o eseguiti.
La backdoor in XZ Utils è stata scoperta per la prima volta alla fine di marzo di quest’anno. Andres Freund, ingegnere di Microsoft, ha identificato commit dannosi nell’utilità della riga di comando XZ.
Queste “manomissioni” interessavano le versioni 5.6.0 e 5.6.1 rilasciate a febbraio e marzo. XZ Utils è un pacchetto popolare integrato in molte distribuzioni Linux.
Secondo una ricerca di SentinelOne e Kaspersky Lab, le modifiche al codice sorgente miravano a bypassare gli strumenti di autenticazione SSH per l’esecuzione di codice in modalità remota. Questo potrebbe consentire agli aggressori di assumere il controllo del sistema.
Abbiamo riportato che dietro l’introduzione della backdoor in XZ Utils c’era un certo Jia Tang. L’identità potrebbe essere stata inventata e utilizzata da uno dei gruppi di hacker sponsorizzati dalla Cina o da qualsiasi altro paese con i propri interessi.
La scoperta di file dannosi in liblzma-sys è stato uno sviluppo importante che ha impedito conseguenze gravi sia per gli sviluppatori che per gli utenti. Tuttavia, questo incidente ha dimostrato ancora una volta la vulnerabilità dei popolari progetti open source. Oltre ad attacchi mirati da parte di aggressori che cercano di introdurre codice dannoso nella catena di fornitura del software.
In September of 2022, multiple security news professionals wrote about and confirmed the leakage of a builder for Lockbit 3 ransomware. In this post we provide the analysis of the builder and recently discovered builds.
Using the LockBit builder to generate targeted ransomware
The previous Kaspersky research focused on a detailed analysis of the LockBit 3.0 builder leaked in 2022. Since then, attackers have been able to generate customized versions of the threat according to their needs. This opens up numerous possibilities for malicious actors to make their attacks more effective, since it is possible to configure network spread options and defense-killing functionality. It becomes even more dangerous if the attacker has valid privileged credentials in the target infrastructure, possibly obtained from data leaks.
In a recent incident response engagement, we faced this exact scenario: the adversary was able to get the administrator credential in plain text. They generated a custom version of the ransomware, which used the aforementioned account credential to spread across the network and perform malicious activities, such as killing Windows Defender and erasing Windows Event Logs in order to encrypt the data and cover its tracks.
In this article, we revisit the LockBit 3.0 builder files and delve into the adversary’s steps to maximize impact on the network. In addition, we provide a list of preventive activities that can help network administrators to avoid this kind of threat.
Revisiting the LockBit 3.0 builder files
The LockBit 3.0 builder has significantly simplified creating customized ransomware. The image below shows the files that constitute it. As we can see, keygen.exe generates public and private keys used for encryption and decryption. After that, builder.exe generates the variant according to the options set in the config.json file.
LockBit builder files
This whole process is automated with the Build.bat script, which does the following: IF exist Build (ERASE /F /Q Build\*.*) ELSE (mkdir Build) keygen -path Build -pubkey pub.key -privkey priv.key builder -type dec -privkey Build\priv.key -config config.json -ofile Build\LB3Decryptor.exe builder -type enc -exe -pubkey Build\pub.key -config config.json -ofile Build\LB3.exe builder -type enc -exe -pass -pubkey Build\pub.key -config config.json -ofile Build\LB3_pass.exe builder -type enc -dll -pubkey Build\pub.key -config config.json -ofile Build\LB3_Rundll32.dll builder -type enc -dll -pass -pubkey Build\pub.key -config config.json -ofile Build\LB3_Rundll32_pass.dll builder -type enc -ref -pubkey Build\pub.key -config config.json -ofile Build\LB3_ReflectiveDll_DllMain.dll The config.json file allows enabling impersonation features (impersonation) and defining accounts to impersonate (impers_accounts). In the example below, the administrator account was used for impersonation. The configuration also allows enabling the encryption of network shares (network_shares), killing Windows Defender (kill_defender), and spreading across the network via PsExec (psexec_netspread). After a successful infection, the malicious sample can delete Windows Event Logs (delete_eventlogs) to cover its tracks.
Custom configuration
Besides this, the builder allows the attacker to choose which files, in which directories, and in which systems they do not want to encrypt. If the attacker knows their way around the target infrastructure, they can generate malware tailored to the specific configuration of the target’s network architecture, such as important files, administrative accounts, and critical systems. The images below show the process of generating customized ransomware according to the above configuration, and the resulting files. As we can see, LB3.exe is the main file. This is the artifact that will be delivered to the victim. The builder also generates LB3Decryptor.exe for recovering the files, as well as several different variants of the main file. For example, LB3_pass.exe is a password-protected version of the ransomware, while the reflective DLL can be used to bypass the standard operating system loader and inject malware directly into memory. The TXT files contain instructions on how to execute the password-protected files.
Creation of a customized LockBit version
Generated LockBit files
When we executed this custom build on a virtual machine, it performed its malicious activities and generated custom ransom note files. In real-life scenarios, the note will include details on how the victim should contact the attackers to obtain a decryptor. It is worth noting that negotiating with the attackers and paying ransom should not be an option. Besides the ethical issues involved, there is doubt whether a tool for recovering the files will ever be provided.
Custom ransom note
However, as we generated the ransomware sample and a corresponding decryptor ourselves in a controlled lab environment, we were able to test if the latter actually worked. We tried to decrypt our encrypted files and found out that if the decryptor for the sample was available, it was indeed able to recover the files, as shown in the image below.
LB3Decryptor execution
That said, we must once again underscore that even a correctly working decryptor is no guarantee that the attackers will play fair.
The recent LockBit takedown and custom LockBit builds
In February 2024, the international law enforcement task force Operation Cronos gained visibility into LockBit’s operations after taking the group down. The collaborative action involved law enforcement agencies from 10 countries, which seized the infrastructure and took control of the LockBit administration environment. However, a few days after the operation, the ransomware group announced that they were back in action.
The takedown operation allowed LEAs to seize the group’s infrastructure, obtain private decryption keys and prepare a decryption toolset based on a known-victim ID list obtained by the authorities. The check_decryption_id utility checks if the ransom ID enabled for the victim is on the list of known decryption keys:
check_decryption_id.exe execution
The check_decrypt tool assesses decryptability: while there is a possibility that the files will be recovered, the outcome of the process depends on multiple conditions, and this tool just checks which of these conditions are met in the systems being analyzed. A CSV file is created, listing files that can be decrypted and providing an email address to reach out to for further instructions on restoring the files:
check_decrypt.exe execution
This toolset caught our attention because we had investigated several cases relating to the LockBit threat. We normally recommend that our customers save their encrypted critical files and wait for an opportunity to decrypt them with the help of threat researches or artifacts seized by the authorities, which is merely a matter of time. We ran victim IDs and encrypted files analyzed by our team through the decryption tool, but most of them showed the same result:
Testing the tool on a victim ID obtained by our team
The check_decrypt also confirmed that it was not possible to decrypt the files by using the database of known keys:
Testing the check_decrypt.exe tool on encrypted files
Our analysis and previous research confirmed that files encrypted with a payload generated with the help of the leaked LockBit builder could not be decrypted with existing decryption tools, essentially because the independent groups behind these attacks did not share their private keys with the RaaS operator.
Geography of the leaked LockBit builder-based attacks
Custom LockBit builds created with the leaked builder were involved in a number of incidents all over the world. These attacks were most likely unrelated and executed by independent actors. The leaked builder apparently has been used by LockBit ransomware competitors to target companies in the Commonwealth of Independent States, violating the group’s number one rule to avoid compromising CIS nationals. This triggered a discussion on the dark web, where LockBit operators tried to explain that they had nothing to do with these attacks.
In our incident response practice, we have come across ransomware samples created with the help of the leaked builder in incidents in Russia, Italy, Guinea-Bissau, and Chile. Although the builder provides a number of customization options, as we have shown above, most of the attacks used the default or slightly modified configuration. However, one incident stood out.
A real-life incident response case involving a custom LockBit build
In a recent incident response engagement, we faced a ransomware scenario involving a LockBit sample built with the leaked builder and featuring impersonation and network spread capabilities we had not seen before. The attacker was able to exploit an internet-facing server that exposed multiple sensitive ports. Somehow, they were able to obtain the administrator password – we believe that it may have been stored in plain text inside a file, or that the attacker may have used social engineering. Then, the adversary generated custom ransomware using the privileged account they had access to. Our team was able to obtain the relevant fields present in the config.json file that the attacker used: "impersonation": true, "impers_accounts": "Administrator:************", "local_disks": true, "network_shares": true, "running_one": false, "kill_defender": true, "psexec_netspread": true, "delete_eventlogs": true, As we can see, the custom version has the ability to impersonate the administrator account, affect network shares, and spread easily across the network via PsExec.
Moreover, it is configured to run more than once on each host. One of the first steps that the executable does when started is check for, and create, a unique mutex based on a hash sum of the ransomware public key in the format: “Global\%.8x%.8x%.8x%.8x%.8x”. If the running_one flag is set to true in the configuration and the mutex is already present in the operating system, the process will exit.
In our case, the configuration allowed concurrent executions of several ransomware instances on the same host. This behavior, combined with the use of configuration flags for automatic network propagation with high-privileged domain credentials, led to an uncontrolled avalanche effect: each host that got infected then started trying to infect other hosts on the network, including those already infected. From an incident response point of view, this means finding evidence, if available, of different origins for the same threat. See below the evidence found on one host of remote service creation by PsExec with authentication completed from multiple infected hosts.
Remote service creation by PsExec
Although this evidence was present in the infected systems, most of the logs had been deleted by the ransomware immediately after the initial infection. Because of that, it was not possible to determine how the attacker was able to gain access to the server and to the administrator password. The remote service creation logs remained because when the malware was performing lateral movement on the network, it generated new logs, which it did not delete, and which were helpful in detecting its spread across the infrastructure.
Event logs cleared
By analyzing some of the traces that were not erased on the initial affected server, we identified compressed Gzip data in a memory stream. The data was encoded in Base64. After decoding and decompression, we found evidence of the use of Cobalt Strike. We were able to identify the C2 server used by the attacker to communicate with the affected machine and promptly sent this indicator to the customer for blacklisting.
We also spotted the use of the SessionGopher script. This tool uses WMI to extract saved session information for remote desktop access tools, such as WinSCP, PuTTY, FileZilla, and Microsoft Remote Desktop. This is accomplished by querying HKEY_USERS for PuTTY, WinSCP, and Remote Desktop saved sessions. In Thorough mode, the script can identify .ppk, .rdp, and .sdtid files in order to extract private keys and session information. It can be run remotely by using the -iL option followed by the list of computers. The -AllDomain flag allows running it against all AD-joined computers. As shown in the image below, the script can easily extract saved passwords for remote connections. The results can be exported to a CSV file for later use.
Password extraction using SessionGopher
Although SessionGopher is designed for collecting stored credentials, it was not the tool used by the attackers for initial credential dumping. Instead, they employed SessionGopher to collect additional credentials and services in the infrastructure at a later stage.
Once we identified the C2 domains and some other IP addresses related to the attacker and extracted details about the impersonated accounts and tools implemented for automatic deployment, the customer changed all affected users’ credentials and configured security controls to avoid PsExec execution, thus stopping the infection. Monitoring network and user account activities allowed us to identify the infected systems and isolate them for analysis and recovery.
This case shows an interesting combination of techniques used to gain and maintain access to the target network, as well as encrypt important data and impair defenses. Below are the TTPs identified for this scenario.
Ransomware attacks can be devastating, especially if the attackers manage to get hold of high-privileged credentials. Measures for mitigating the risk of such an attack may vary depending on the technology used by the company. However, there are certain infrastructure-agnostic techniques:
Disabling unused services and ports to minimize the attack surface
Keeping all systems and software up to date
Conducting regular penetration tests and vulnerability scanning to identify vulnerabilities and promptly apply appropriate countermeasures
Adopting regular cybersecurity training, so that employees are aware of cyberthreats and ways to avoid them
Making backups frequently and testing them
Conclusion
Our examination of the LockBit 3.0 builder files shows the alarming simplicity with which attackers can craft customized ransomware, as evidenced by a recent incident where adversaries exploited administrator credentials to deploy a tailored ransomware variant. This underscores the need for robust security measures capable of mitigating this kind of threat effectively, as well as adoption of a cybersecurity culture among employees.
Kaspersky products detect the threat with the following verdicts:
Waveform Generator Teardown is Nearly Empty https://poliverso.org/display/0477a01e-1e1051c6-3de90470076aef89 Waveform Generator Teardown is Nearly Empty We always enjoy [Kerry Wong’s] insightful teardowns, and recently, he opened up a UTG1042X arbitrary waveform generator. Getting inside was a bit of a challenge since there were no visible screws. Turns out, they were under some stickers. We always dislike that because it is very difficult to get the unit to go back together.Once open, the
We always enjoy [Kerry Wong’s] insightful teardowns, and recently, he opened up a UTG1042X arbitrary waveform generator. Getting inside was a bit of a challenge since there were no visible screws. Turns out, they were under some stickers. We always dislike that because it is very difficult to get the unit to go back together.
Once open, the case reveals it is almost completely empty. The back panel has a power supply, and the front panel has all the working circuitry. The box seems to be for holding the foot and preventing the device from getting lost on your bench.
The power supply is unremarkable. There are a few odd output voltages. The main board is a bit more interesting, especially after removing the heat sink.
There are two channels, but the board isn’t laid out, with a lot of segregation between the two channels. That makes sense with the output sections clustered together and the digital section with the CPU, FPGA, and the DAC in close proximity.
The other side of the board connects to a very simple display board. It would be interesting to compare this to a circa-1980s AWG, which would have been far more complicated.
Perché il Piracy Shield non funziona e come sarebbe dovuto essere implementato https://poliverso.org/display/0477a01e-f28edcb6-f5af39e5cf4f6adf Perché il Piracy Shield non funziona e come sarebbe dovuto essere implementato Nell’era digitale, la gestione della proprietà intellettuale e la lotta contro la pirateria online rappresentano sfide cruciali per i regolatori, le industrie creative e i fornitori di servizi internet. Il “Piracy Shield”, un’iniziativa dell’Autorità per le Garanzie nelle
Perché il Piracy Shield non funziona e come sarebbe dovuto essere implementato
Nell’era digitale, la gestione della proprietà intellettuale e la lotta contro la pirateria online rappresentano sfide cruciali per i regolatori, le industrie creative e i fornitori di servizi internet. Il “Piracy Shield”, un’iniziativa dell’Autorità per le Garanzie nelle Comunicazioni (AGCOM), rappresenta un tentativo significativo di affrontare il problema della pirateria digitale in Italia. Questo strumento è stato ideato per identificare e bloccare l’accesso ai siti web che violano i diritti di proprietà intellettuale, sfruttando tecnologie di filtraggio degli “FQDN e degli indirizzi IP” (citando testualmente AGCOM).
Nonostante le sue nobili intenzioni, il Piracy Shield ha suscitato non poche controversie e dibattiti riguardo la sua efficacia e le implicazioni per la libertà di espressione e il diritto alla privacy. In questo articolo tecnico-scientifico, si intende esplorare e discutere le ragioni per cui il Privacy Shield non ha raggiunto pienamente i suoi obiettivi, mettendo in luce le difficoltà tecniche, legali e etiche incontrate.
Sarà inoltre illustrato come, attraverso un approccio innovativo basato sulla configurazione di record CNAME, sia possibile distinguere tra servizi legittimi e illeciti associati allo stesso indirizzo IPv4. Questa dimostrazione pratica non solo evidenzierà le potenzialità di tali tecniche, ma anche come esse potrebbero essere integrate efficacemente in un framework rinnovato per la lotta alla pirateria, suggerendo modifiche e migliorie al sistema attuale del Piracy Shield.
Le Content Delivery Network
Le Content Delivery Networks (CDN) sono infrastrutture distribuite di server progettate per ottimizzare la consegna di contenuti web agli utenti finali. Le CDN migliorano la velocità e l’affidabilità di accesso ai dati riducendo la distanza fisica tra il server e l’utente, distribuendo il contenuto su diversi server posizionati in varie località geografiche.
Funzionamento delle CDN
Quando un utente accede a un sito web che utilizza una CDN, la richiesta di dati non viene inviata direttamente al server principale del sito, ma viene reindirizzata al server della CDN più vicino all’utente. Questo server “edge” contiene copie dei contenuti del sito, come file HTML, immagini, video e altri tipi di dati. Grazie a questa architettura, il tempo di caricamento delle pagine si riduce notevolmente, migliorando l’esperienza dell’utente e riducendo il carico sui server centrali.
Mascheramento dell’IP reale
Un effetto importante dell’uso delle CDN è il mascheramento dell’indirizzo IP pubblico reale del server di origine dei contenuti. Quando un servizio online adotta una CDN, gli indirizzi IP visibili al pubblico sono quelli dei server della rete CDN. Questo significa che l’IP percepito come fonte del servizio è in realtà quello della CDN, non del server originale. Questo ha implicazioni per la sicurezza, la privacy e la gestione del traffico, ma può anche complicare alcune operazioni di controllo e filtraggio del contenuto.
Implicazioni per il filtraggio di contenuti
Se un’autorità come AGCOM implementa misure per bloccare l’accesso a contenuti ritenuti illegali (come quelli piratati) mediante il filtraggio degli indirizzi IP attraverso strumenti come il Piracy Shield, si potrebbero verificare problemi significativi. Poiché un singolo indirizzo IP di una CDN può essere utilizzato per trasmettere i contenuti di numerosi servizi diversi, il blocco di quell’IP potrebbe avere l’effetto collaterale di interrompere l’accesso a servizi legittimi e non solo a quelli illegali. Questo scenario potrebbe portare a interruzioni di servizio per utenti che non sono coinvolti nella fruizione di contenuti piratati.
Facciamo chiarezza con un esempio pratico
Per comprendere meglio come funziona la navigazione su internet e l’interazione con una Content Delivery Network (CDN), prendiamo come esempio il processo di collegamento a un sito web, come “www.libero.it”. Questo esempio ci permetterà di osservare come, durante la navigazione, il nome di dominio inizialmente richiesto possa in realtà essere servito da un dominio completamente diverso, come “d31d9gezsyt1z8.cloudfront.net”, che appartiene a una CDN.
DNS Query
Il processo inizia quando l’utente digita “www.libero.it” nel browser. Il browser deve risolvere questo nome di dominio in un indirizzo IP per poter stabilire una connessione. Questo avviene tramite una richiesta DNS (Domain Name System).
Il browser consulta i server DNS configurati (tipicamente forniti dal provider di servizi internet o specificati manualmente dall’utente) per ottenere l’indirizzo IP associato al nome di dominio. (Si vede evidenziata la richiesta)
Ricezione della risposta DNS
I server DNS eseguono la ricerca e, una volta trovato l’indirizzo IP, lo restituiscono al browser. Se il dominio è ospitato su una CDN, l’IP restituito sarà quello di uno dei server edge della CDN più vicino all’utente, non l’IP del server originale di “libero.it”. (Si vede evidenziata la risposta)
Apertura della connessione (Handshake)
Con l’indirizzo IP in mano, il browser inizia un handshake TCP con il server al fine di stabilire una connessione affidabile. Questo include la sincronizzazione dei numeri di sequenza per garantire che i pacchetti di dati vengano inviati e ricevuti in ordine. Durante l’handhsake il client invia un segmento SYN , il server risponde con un SYN + ACK , il client termina l’handshake con un ACK. (Si vede in figura nella riga evidenziata l’inizio dell’handshake verso la CDN di libero)
Negoziazione TLS (Transport Layer Security)
Dopo aver stabilito una connessione TCP, il browser inizia una negoziazione TLS per assicurare che la comunicazione sia sicura e criptata. Questo processo inizia con l’invio del “ClientHello”, che include la versione di TLS supportata, i metodi di cifratura proposti, e altri dettagli necessari per la sicurezza.
Il server risponde con un “ServerHello”, che conferma i dettagli della crittografia che sarà utilizzata, seleziona un metodo di cifratura tra quelli proposti dal client e prosegue con l’invio dei certificati, la verifica della chiave, e la conferma finale di inizio della cifratura.
Comunicazione sicura
Una volta completata la negoziazione TLS, tutte le trasmissioni successive tra il browser e il server sono completamente criptate. Il browser può ora richiedere le risorse web da “www.libero.it”, che in realtà potrebbero essere servite dal dominio della CDN, come “d31d9gezsyt1z8.cloudfront.net”.
Questo esempio mostra come, nella pratica, un sito che l’utente intende visitare possa essere effettivamente distribuito attraverso una rete CDN, rendendo il nome del dominio CDN visibile nelle comunicazioni di rete, anche se l’utente potrebbe non essere immediatamente consapevole di tale fatto.
Considerazioni
Questa architettura farà in modo che www.libero.it avrà una serie di IP associati all’ASN di cloudfront che vengono usati per far funzionare la CDN. Questi IP saranno associati non solo a www.libero.it ma anche a molti altri FQDN (Altre web app) che usano la CDN. Ricordiamo che questi servizi vengono distinti fra loro grazie ai record CNAME che puntano a FQDN univoci come questo: d31d9gezsyt1z8.cloudfront.net.
Dimostrazione del problema
Con l’esempio precedente abbiamo quindi dimostrato che quando un servizio è integrato ad una CDN la corrispondenza servizio – IP non è più della cardinalità 1:1 , ma bensì N:1. Quindi se viene filtrato un indirizzo IP, N servizi vengono oscurati, pur non essendo tutti illegali. Lo abbiamo visto con l’esempio precedente in cui libero viene deliberatamente associato a diversi IP, condivisi con altri servizi della CDN cloudFront.
Infatti una delle CDN che ha lamentato proprio questo problema è la nota Cloudflare che ha emesso un comunicato ad alcuni suoi clienti, esortandoli all’invio di una lettera di richiamo alla stessa AGCOM chiedendo di annullare l’ingiusto provvedimento.
Non si può quindi pensare di bloccare il traffico IP semplicemente filtrando un indirizzo IPv4/IPv6.
Come si potrebbe procedere
Per affrontare efficacemente le sfide poste dal filtraggio di contenuti attraverso indirizzi IP in un ambiente dove sono ampiamente utilizzate le Content Delivery Networks (CDN), è essenziale adottare metodi più sofisticati che prendano in considerazione le peculiarità tecniche delle CDN stesse. Una strategia più mirata e meno suscettibile di causare danni collaterali può essere implementata analizzando in dettaglio le proprietà di rete associate agli indirizzi IP, in particolare l’Autonomous System Number (ASN).
Analisi dell’ASN
Prima di procedere al blocco di un indirizzo IP sospettato di veicolare contenuti piratati, è cruciale determinare a quale sistema autonomo appartiene quel determinato IP. Se l’IP è associato all’ASN di una CDN nota, questo indica che potrebbe essere utilizzato per servire una moltitudine di clienti e servizi, molti dei quali legittimi. Il blocco diretto di tali IP potrebbe quindi interrompere l’accesso a servizi legittimi, causando interruzioni non necessarie e potenzialmente estese.
Blocco basato su FQDN della CDN
Invece di bloccare indiscriminatamente gli indirizzi IP, si dovrebbe valutare l’opzione di filtrare specifici Fully Qualified Domain Names (FQDN) direttamente legati a contenuti illeciti. Un metodo più mirato consiste nell’analizzare i record CNAME, che collegano un FQDN a un altro dominio, spesso usato per identificare contenuti specifici all’interno di una CDN.
Il sistema attuale del Piracy Shield già applica il blocco agli FQDN e agli indirizzi IP, ma non estende questo trattamento ai FQDN univoci usati dalle CDN. Ad esempio, bloccando il dominio pubblico www.libero.it ed i suoi indirizzi IP, si impedisce anche l’accesso agli IP come 18.66.196.87, 18.66.196.23, 18.66.196.13 e 18.66.196.59. Tali indirizzi, associati a una CDN, vengono utilizzati anche da altri servizi che sarebbero ingiustamente bloccati.
Soluzione proposta
Quando viene rilevato che un servizio usa una CDN, la strategia corretta sarebbe quella di bloccare esclusivamente gli FQDN specifici alla CDN, come d31d9gezsyt1z8.cloudfront.net e www.libero.it, senza intervenire sugli indirizzi IP.
In questo modo gli altri servizi che usano la CDN non saranno bloccati.
Conclusioni
Adottando queste pratiche migliorate, AGCOM e altre autorità simili potrebbero ottimizzare le loro strategie di enforcement senza suscitare controversie legate a interruzioni di servizio ingiustificate o a violazioni dei diritti alla privacy e alla libertà di espressione. Questo equilibrio tra l’efficacia del blocco e il rispetto per i diritti degli utenti è essenziale per mantenere la fiducia nel regolamento digitale e nella protezione della proprietà intellettuale nel contesto globale e interconnesso di oggi.
Perché il Privacy Shield non funziona e come sarebbe dovuto essere implementato https://poliverso.org/display/0477a01e-aaafc80a-163ffb4529a15f23 Perché il Privacy Shield non funziona e come sarebbe dovuto essere implementato Nell’era digitale, la gestione della proprietà intellettuale e la lotta contro la pirateria online rappresentano sfide cruciali per i regolatori, le industrie creative e i fornitori di servizi internet. Il “Privacy Shield”, un’iniziativa dell’Autorità per le Garanzie nelle
Perché il Privacy Shield non funziona e come sarebbe dovuto essere implementato
Nell’era digitale, la gestione della proprietà intellettuale e la lotta contro la pirateria online rappresentano sfide cruciali per i regolatori, le industrie creative e i fornitori di servizi internet. Il “Privacy Shield”, un’iniziativa dell’Autorità per le Garanzie nelle Comunicazioni (AGCOM), rappresenta un tentativo significativo di affrontare il problema della pirateria digitale in Italia. Questo strumento è stato ideato per identificare e bloccare l’accesso ai siti web che violano i diritti di proprietà intellettuale, sfruttando tecnologie di filtraggio degli “FQDN e degli indirizzi IP” (citando testualmente AGCOM).
Nonostante le sue nobili intenzioni, il Privacy Shield ha suscitato non poche controversie e dibattiti riguardo la sua efficacia e le implicazioni per la libertà di espressione e il diritto alla privacy. In questo articolo tecnico-scientifico, si intende esplorare e discutere le ragioni per cui il Privacy Shield non ha raggiunto pienamente i suoi obiettivi, mettendo in luce le difficoltà tecniche, legali e etiche incontrate.
Sarà inoltre illustrato come, attraverso un approccio innovativo basato sulla configurazione di record CNAME, sia possibile distinguere tra servizi legittimi e illeciti associati allo stesso indirizzo IPv4. Questa dimostrazione pratica non solo evidenzierà le potenzialità di tali tecniche, ma anche come esse potrebbero essere integrate efficacemente in un framework rinnovato per la lotta alla pirateria, suggerendo modifiche e migliorie al sistema attuale del Privacy Shield.
Le Content Delivery Network
Le Content Delivery Networks (CDN) sono infrastrutture distribuite di server progettate per ottimizzare la consegna di contenuti web agli utenti finali. Le CDN migliorano la velocità e l’affidabilità di accesso ai dati riducendo la distanza fisica tra il server e l’utente, distribuendo il contenuto su diversi server posizionati in varie località geografiche.
Funzionamento delle CDN
Quando un utente accede a un sito web che utilizza una CDN, la richiesta di dati non viene inviata direttamente al server principale del sito, ma viene reindirizzata al server della CDN più vicino all’utente. Questo server “edge” contiene copie dei contenuti del sito, come file HTML, immagini, video e altri tipi di dati. Grazie a questa architettura, il tempo di caricamento delle pagine si riduce notevolmente, migliorando l’esperienza dell’utente e riducendo il carico sui server centrali.
Mascheramento dell’IP reale
Un effetto importante dell’uso delle CDN è il mascheramento dell’indirizzo IP pubblico reale del server di origine dei contenuti. Quando un servizio online adotta una CDN, gli indirizzi IP visibili al pubblico sono quelli dei server della rete CDN. Questo significa che l’IP percepito come fonte del servizio è in realtà quello della CDN, non del server originale. Questo ha implicazioni per la sicurezza, la privacy e la gestione del traffico, ma può anche complicare alcune operazioni di controllo e filtraggio del contenuto.
Implicazioni per il filtraggio di contenuti
Se un’autorità come AGCOM implementa misure per bloccare l’accesso a contenuti ritenuti illegali (come quelli piratati) mediante il filtraggio degli indirizzi IP attraverso strumenti come il Privacy Shield, si potrebbero verificare problemi significativi. Poiché un singolo indirizzo IP di una CDN può essere utilizzato per trasmettere i contenuti di numerosi servizi diversi, il blocco di quell’IP potrebbe avere l’effetto collaterale di interrompere l’accesso a servizi legittimi e non solo a quelli illegali. Questo scenario potrebbe portare a interruzioni di servizio per utenti che non sono coinvolti nella fruizione di contenuti piratati.
Facciamo chiarezza con un esempio pratico
Per comprendere meglio come funziona la navigazione su internet e l’interazione con una Content Delivery Network (CDN), prendiamo come esempio il processo di collegamento a un sito web, come “www.libero.it”. Questo esempio ci permetterà di osservare come, durante la navigazione, il nome di dominio inizialmente richiesto possa in realtà essere servito da un dominio completamente diverso, come “d31d9gezsyt1z8.cloudfront.net”, che appartiene a una CDN.
DNS Query
Il processo inizia quando l’utente digita “www.libero.it” nel browser. Il browser deve risolvere questo nome di dominio in un indirizzo IP per poter stabilire una connessione. Questo avviene tramite una richiesta DNS (Domain Name System).
Il browser consulta i server DNS configurati (tipicamente forniti dal provider di servizi internet o specificati manualmente dall’utente) per ottenere l’indirizzo IP associato al nome di dominio. (Si vede evidenziata la richiesta)
Ricezione della risposta DNS
I server DNS eseguono la ricerca e, una volta trovato l’indirizzo IP, lo restituiscono al browser. Se il dominio è ospitato su una CDN, l’IP restituito sarà quello di uno dei server edge della CDN più vicino all’utente, non l’IP del server originale di “libero.it”. (Si vede evidenziata la risposta)
Apertura della connessione (Handshake)
Con l’indirizzo IP in mano, il browser inizia un handshake TCP con il server al fine di stabilire una connessione affidabile. Questo include la sincronizzazione dei numeri di sequenza per garantire che i pacchetti di dati vengano inviati e ricevuti in ordine. Durante l’handhsake il client invia un segmento SYN , il server risponde con un SYN + ACK , il client termina l’handshake con un ACK. (Si vede in figura nella riga evidenziata l’inizio dell’handshake verso la CDN di libero)
Negoziazione TLS (Transport Layer Security)
Dopo aver stabilito una connessione TCP, il browser inizia una negoziazione TLS per assicurare che la comunicazione sia sicura e criptata. Questo processo inizia con l’invio del “ClientHello”, che include la versione di TLS supportata, i metodi di cifratura proposti, e altri dettagli necessari per la sicurezza.
Il server risponde con un “ServerHello”, che conferma i dettagli della crittografia che sarà utilizzata, seleziona un metodo di cifratura tra quelli proposti dal client e prosegue con l’invio dei certificati, la verifica della chiave, e la conferma finale di inizio della cifratura.
Comunicazione sicura
Una volta completata la negoziazione TLS, tutte le trasmissioni successive tra il browser e il server sono completamente criptate. Il browser può ora richiedere le risorse web da “www.libero.it”, che in realtà potrebbero essere servite dal dominio della CDN, come “d31d9gezsyt1z8.cloudfront.net”.
Questo esempio mostra come, nella pratica, un sito che l’utente intende visitare possa essere effettivamente distribuito attraverso una rete CDN, rendendo il nome del dominio CDN visibile nelle comunicazioni di rete, anche se l’utente potrebbe non essere immediatamente consapevole di tale fatto.
Considerazioni
Questa architettura farà in modo che www.libero.it avrà una serie di IP associati all’ASN di cloudfront che vengono usati per far funzionare la CDN. Questi IP saranno associati non solo a www.libero.it ma anche a molti altri FQDN (Altre web app) che usano la CDN. Ricordiamo che questi servizi vengono distinti fra loro grazie ai record CNAME che puntano a FQDN univoci come questo: d31d9gezsyt1z8.cloudfront.net.
Dimostrazione del problema
Con l’esempio precedente abbiamo quindi dimostrato che quando un servizio è integrato ad una CDN la corrispondenza servizio – IP non è più della cardinalità 1:1 , ma bensì N:1. Quindi se viene filtrato un indirizzo IP, N servizi vengono oscurati, pur non essendo tutti illegali. Lo abbiamo visto con l’esempio precedente in cui libero viene deliberatamente associato a diversi IP, condivisi con altri servizi della CDN cloudFront.
Infatti una delle CDN che ha lamentato proprio questo problema è la nota Cloudflare che ha emesso un comunicato ad alcuni suoi clienti, esortandoli all’invio di una lettera di richiamo alla stessa AGCOM chiedendo di annullare l’ingiusto provvedimento.
Non si può quindi pensare di bloccare il traffico IP semplicemente filtrando un indirizzo IPv4/IPv6.
Come si potrebbe procedere
Per affrontare efficacemente le sfide poste dal filtraggio di contenuti attraverso indirizzi IP in un ambiente dove sono ampiamente utilizzate le Content Delivery Networks (CDN), è essenziale adottare metodi più sofisticati che prendano in considerazione le peculiarità tecniche delle CDN stesse. Una strategia più mirata e meno suscettibile di causare danni collaterali può essere implementata analizzando in dettaglio le proprietà di rete associate agli indirizzi IP, in particolare l’Autonomous System Number (ASN).
Analisi dell’ASN
Prima di procedere al blocco di un indirizzo IP sospettato di veicolare contenuti piratati, è cruciale determinare a quale sistema autonomo appartiene quel determinato IP. Se l’IP è associato all’ASN di una CDN nota, questo indica che potrebbe essere utilizzato per servire una moltitudine di clienti e servizi, molti dei quali legittimi. Il blocco diretto di tali IP potrebbe quindi interrompere l’accesso a servizi legittimi, causando interruzioni non necessarie e potenzialmente estese.
Blocco basato su FQDN della CDN
Invece di bloccare indiscriminatamente gli indirizzi IP, si dovrebbe valutare l’opzione di filtrare specifici Fully Qualified Domain Names (FQDN) direttamente legati a contenuti illeciti. Un metodo più mirato consiste nell’analizzare i record CNAME, che collegano un FQDN a un altro dominio, spesso usato per identificare contenuti specifici all’interno di una CDN.
Il sistema attuale del Privacy Shield già applica il blocco agli FQDN e agli indirizzi IP, ma non estende questo trattamento ai FQDN univoci usati dalle CDN. Ad esempio, bloccando il dominio pubblico www.libero.it ed i suoi indirizzi IP, si impedisce anche l’accesso agli IP come 18.66.196.87, 18.66.196.23, 18.66.196.13 e 18.66.196.59. Tali indirizzi, associati a una CDN, vengono utilizzati anche da altri servizi che sarebbero ingiustamente bloccati.
Soluzione proposta
Quando viene rilevato che un servizio usa una CDN, la strategia corretta sarebbe quella di bloccare esclusivamente gli FQDN specifici alla CDN, come d31d9gezsyt1z8.cloudfront.net e www.libero.it, senza intervenire sugli indirizzi IP.
In questo modo gli altri servizi che usano la CDN non saranno bloccati.
Conclusioni
Adottando queste pratiche migliorate, AGCOM e altre autorità simili potrebbero ottimizzare le loro strategie di enforcement senza suscitare controversie legate a interruzioni di servizio ingiustificate o a violazioni dei diritti alla privacy e alla libertà di espressione. Questo equilibrio tra l’efficacia del blocco e il rispetto per i diritti degli utenti è essenziale per mantenere la fiducia nel regolamento digitale e nella protezione della proprietà intellettuale nel contesto globale e interconnesso di oggi.
A Buggy Entry in the Useless Robot Category https://poliverso.org/display/0477a01e-84a9bbb2-8cd7988d8fef3ce5 A Buggy Entry in the Useless Robot Category No one loves a useless robot more than we do here at Hackaday. But if anyone does it might be [ARC385] with her Bug Bite Bot https://www.instructables.com/Bug-Bite-Bot/.A true engineering marvel, [ARC385]’s bug bot extinguishes the candle on its own little birthday cupcake. Yup. That’s it! Even more peculiar, (and to be fair, somewhat
No one loves a useless robot more than we do here at Hackaday. But if anyone does it might be [ARC385] with her Bug Bite Bot.
A true engineering marvel, [ARC385]’s bug bot extinguishes the candle on its own little birthday cupcake. Yup. That’s it! Even more peculiar, (and to be fair, somewhat fittingly) before her bug releases its less-than-crushing bite, it plays itself a little Happy Birthday jingle. Seems legit.
If you choose to build this little bug yourself, you’ll be happy to know that the electronics on this build are pretty straightforward. Servo motors control the pincers and a photoresistor detects the flame. [ARC385] tried using a flame sensor instead of the photoresistor, but mentioned she couldn’t get consistent performance at her required sensing distance. She also mentions that you’ll probably need to calibrate the photoresistor to ambient light if for whatever reason you choose to embark on this build yourself.
[ARC385] did a pretty good job with the laser-cut plywood to construct the bug, but using plywood adds a few more question marks to this already puzzling build. She even mentioned having to modify the pincers so they wouldn’t catch fire trying to extinguish the candle.
Would be cool if the candle could rekindle itself, but we can’t possibly support making this hack even more of a fire hazard than it already is.
0day SMS/Image per Android e iOS in vendita. Scopriamo il mondo di questi preziosi e rari exploit
All’interno di un noto forum underground, dove si scambiano informazioni e strumenti illegali, è emersa una minaccia significativa per la sicurezza informatica: uno zero-dayexploit che colpisce i dispositivi iOS e Android.
Tale minaccia – da quanto riportato dal criminale informatico nel forum, attivo sul forum da due mesi – ha un payload capace di prendere il controllo dei device utilizzando un exploit Image/SMS. Pertanto si configura come una importante minaccia informatica, anche se occorre comprendere se si tratta di Scam.
Qualora questo exploit risulti reale, si può considerare particolarmente pericoloso e altamente prezioso per coloro che operano nel mondo dell’intelligence e nei tool di spionaggio. Annuncio nel forum underground Beach Forums (fonte Red Hot Cyber) Il prezzo richiesto per tale exploit non è al momento conosciuto, anche se i prezzi per questo genere di falle di sicurezza raggiungono prezzi astronomici, fino ad arrivare a 9 milioni di dollari, come recentemente riportato relativamente ai listini di Crowdfense.
Scopriamo perché questi exploit sono così preziosi
Ancora non sappiamo se questo 0day sia autentico e funzionante.
Ma cosa rendono questi zero-day così temibili?
Innanzitutto, la loro capacità di infiltrarsi nei sistemi operativi più diffusi al mondo: iOS e Android. Questi due sistemi operativi dominano il mercato dei dispositivi mobili e sono utilizzati da miliardi di persone in tutto il mondo, rendendo qualsiasi vulnerabilità in essi una minaccia significativa per la sicurezza delle informazioni personali e sensibili degli utenti.
Ma cosa rende questi zero-day così preziosi per i criminali informatici?
Il loro possibile utilizzo è armare strumenti di intelligence, come ad esempio il noto Pegasus dell’Israeliana NSO Group. Pegasus è un software spia, noto per il suo utilizzo da parte di governi e agenzie di intelligence per monitorare e sorvegliare gli individui per prevenire il crimine. L’inclusione di un nuovo zero-day exploit all’interno di strumenti come Pegasus aumenta enormemente la loro efficacia e la loro capacità di eludere le difese informatiche.
Ma dove si vendono questi preziosi 0day?
La vendita di questa tipologia di exploit può avvenire nei mercati neri (come in questo caso), oppure attraverso i broker zeroday. Si tratta di intermediari tra i ricercatori di sicurezza e le aziende interessate al loro acquisto come i più famosi Zerodium e Crowfense. Bounty program di Zerodium Tali bug di sicurezza vengono acquistati da quelle aziende denominate PSOA (Public Sector Offensive Actor), le quali approvvigionano questi potenti exploit per poterli utilizzare all’interno dei loro tool di spionaggio, che poi vengono venduti ad agenzie governative, come appunto l’NSO Group.
Ma la NSO Group e solo la punta dell’iceberg di questo business. Esistono moltissime aziende che effettuano questo mestiere, per citarne alcune possiamo riportare Sourgum, Finfisher, Rayzone, Gamma international, Verint, RCS Lab, Intellexa, ecc… ed ecc…
Pertanto la NSO Group ha portato all’attenzione il fenomeno degli spyware, ma il mercato è altamente florido e tecnologicamente molto avanzato.
Quanto è semplice rilevare questo genere di falle di sicurezza?
Rilevare un bug di sicurezza che possa controllare un terminale iOS può essere estremamente difficile per diversi motivi:
Complessità del Sistema Operativo: iOS o Android sono sistemi operativi complessi con molti strati di sicurezza e protezione integrati. I bug di sicurezza possono sfruttare vulnerabilità in uno qualsiasi di questi strati, rendendo difficile individuare il punto esatto di ingresso.
Varietà di Dispositivi e Versioni: iOS è utilizzato su una vasta gamma di dispositivi Apple, ognuno con le proprie specifiche hardware e software. Questo aumenta la complessità del rilevamento dei bug di sicurezza poiché devono essere testati su molteplici dispositivi e versioni del sistema operativo.
Costante Evoluzione: Apple e Google rilasciano regolarmente aggiornamenti di sistema operativo per correggere le vulnerabilità di sicurezza. Tuttavia, i creatori di malware continuano a cercare nuove vulnerabilità e metodi per aggirare le misure di sicurezza aggiornate.
Complessità dei Bug Stessi: Alcuni bug di sicurezza possono essere molto complessi e difficili da individuare, specialmente se coinvolgono interazioni complesse tra software e hardware o se sfruttano vulnerabilità poco note.
Crescente Livello di Abilità degli Attaccanti: Gli attaccanti che cercano di sfruttare i bug di sicurezza sono spesso altamente competenti e possono utilizzare tecniche sofisticate per nascondere le proprie attività e aggirare le contromisure di sicurezza.
In sintesi, rilevare un bug di sicurezza che possa controllare un terminale iOS o Android può essere estremamente difficile data la complessità dei sistemi operativi e la varietà di dispositivi e versioni.
Alert! Falso sito Notepad++ potrebbe mettere a rischio la tua sicurezza online? https://poliverso.org/display/0477a01e-8e31d776-30a1320c15ef83e7 Alert! Falso sito Notepad++ potrebbe mettere a rischio la tua sicurezza online? Gli sviluppatori del progetto Notepad++ stanno tentando di chiudere un popolare sito che finge di essere Notepad++ e ora stanno chiedendo aiuto alla comunità.Sebbene il sito fake attualmente indirizza i visitatori alla pagina di download ufficiale di Notepad++, si teme che
Alert! Falso sito Notepad++ potrebbe mettere a rischio la tua sicurezza online?
Gli sviluppatori del progetto Notepad++ stanno tentando di chiudere un popolare sito che finge di essere Notepad++ e ora stanno chiedendo aiuto alla comunità.
Sebbene il sito fake attualmente indirizza i visitatori alla pagina di download ufficiale di Notepad++, si teme che possa rappresentare una minaccia in futuro. Ad esempio, potrebbe iniziare a distribuire versioni di software dannoso o spam (intenzionalmente o a seguito di hacking).
Gli autori di Notepad++ stanno cercando di ottenere la chiusura di notepad[.]plus, che utilizza il marchio del progetto e riesce a occupare posizioni elevate nei motori di ricerca, insieme al vero sito ufficiale del progetto – notepad-plus-plus.org. “Ho ricevuto numerosi reclami via e-mail, social media e forum riguardanti un sito che rappresenta una chiara minaccia per la nostra comunità”, ha scritto Don Ho, sviluppatore di Notepad++. — Alcuni utenti credono erroneamente che questo sia il sito Web ufficiale di Notepad++. Questa confusione porta a frustrazione e potenziali rischi per la sicurezza”.
Allo stesso tempo, in fondo al sito notepad[.]plus è possibile trovare un chiaro disclaimer, in cui si afferma che si tratta di un “sito di fan non ufficiale” che non è in alcun modo associato al progetto. Sebbene il sito reindirizzi i visitatori alla pagina di download ufficiale di Notepad++ situata su notepad-plus-plus.org, secondo lo sviluppatore, può ingannare gli utenti ignari e costringerli a seguire collegamenti che generano entrate per gli amministratori delle risorse.
Ho ritiene che il vero scopo di questo “sito parassitario” sia deviare il traffico dal sito legittimo Notepad++, potenzialmente “compromettendo la sicurezza degli utenti e minando l’integrità della comunità”.
Lo sviluppatore ha incoraggiato gli utenti a segnalare questo sito tramite uno speciale modulo web di Google Safebrowsing attraverso il quale vengono accettate segnalazioni di malware. Alcuni sviluppatori non erano d’accordo con il messaggio di Ho. Ad esempio, Robby Zambito scrive in Mastodon : “Onestamente non capisco. Il post di [Ho] è pieno di linguaggio molto forte… Ma sono andato sul sito e davvero non ci vedo nulla di sbagliato. Anche i pulsanti di download reindirizzano al sito [reale] di Notepad++ e non distribuiscono alcun software malevolo. [Gli sviluppatori] affermano che questo sito “rappresenta una minaccia per la comunità”… Ma questa è la comunità. Sembra più una minaccia al loro controllo sul supporto software, il che non mi sembra un grosso problema.”
Unpacking the EU’s crackdown on Big Tech https://poliverso.org/display/0477a01e-692ae253-d2ff84bff5478e10 Unpacking the EU’s crackdown on Big TechThe European Commission is ramping up its oversight of major tech firms. Google’s parent company Alphabet, META, Tiktok, and Apple are all in the Commission's crosshairs. But experts say that fines might not be enough to halt bad behaviour.euractiv.com/section/digital/p…
The European Commission is ramping up its oversight of major tech firms. Google’s parent company Alphabet, META, Tiktok, and Apple are all in the Commission's crosshairs. But experts say that fines might not be enough to halt bad behaviour.
Voice Control for a Vintage Heathkit Radio https://poliverso.org/display/0477a01e-d32ed475-7d428746da71dbb7 Voice Control for a Vintage Heathkit Radio Most modern ham rigs have a voice activated transmission (VOX) mode, although we don’t know many people who use it often. When a transmitter is in VOX mode, it starts transmitting when you talk, and then, when you pause for a second or two, the transmitter turns off. Many old ham transmitters, though, didn’t support VOX, so Heathkit sold the
Most modern ham rigs have a voice activated transmission (VOX) mode, although we don’t know many people who use it often. When a transmitter is in VOX mode, it starts transmitting when you talk, and then, when you pause for a second or two, the transmitter turns off. Many old ham transmitters, though, didn’t support VOX, so Heathkit sold the VX-1 “electronic voice control” to add VOX to older transmitters. [Jeff Tranter] shows us inside a clean-looking unit.
These devices were sold from 1958 to 1960 and used tubes and a selenium rectifier. The device is connected between the microphone and the transmitter. It also sat between the receiver and the speaker to mute audio while transmitting. The original unit had a screw terminal to connect to the outside world, and some of the screws had live line voltage on them. The unit [Jeff] examines is modified to have phono jacks along with a few other repairs.
The wiring looks like a tube radio. Tubes are above the chassis, and point-to-point wiring is underneath. There is also an unusual sealed selenium rectifier. [Jeff] shows how the device works using just a receiver. A few minor repairs were needed.
Hackaday Links: April 14, 2024 https://poliverso.org/display/0477a01e-a3c05e08-9f999b75db98fdc5 Hackaday Links: April 14, 2024 The Great American Eclipse v2.0 has come and gone, sadly without our traveling to the path of totality as planned; family stuff. We did get a report from friends in Texas that it was just as spectacular there as expected, with the bonus of seeing a solar flare off the southwest limb of the disk at totality. Many people reported seeing the same thing https://qz.com/20
Quartz is a guide to the new global economy for people who are excited by change. We cover business, finance, economics, technology, lifestyle, and leadership.
The Great American Eclipse v2.0 has come and gone, sadly without our traveling to the path of totality as planned; family stuff. We did get a report from friends in Texas that it was just as spectacular there as expected, with the bonus of seeing a solar flare off the southwest limb of the disk at totality. Many people reported seeing the same thing, which makes us a bit jealous — OK, a lot jealous. Of course, this presented an opportunity to the “Well, ackchyually” crowd to point out that there were no solar flares or coronal mass ejections at the time, so what people saw wasn’t an exquisitely timed and well-positioned solar flare but rather a well-timed and exquisitely positioned solar prominence. Glad we cleared that up. Either way, people in the path of totality saw the Sun belching out gigatons of plasma while we had to settle for 27% totality.
The eclipse also presented plenty of hacking opportunities for YouTubers in our community. Matthias Wandel went to great lengths on short notice to build a solar tracker for photographing the eclipse, while Gabe Emerson from “saveitforparts” threw his little radiotelescope rig in the car and drove down to totality to listen to the Sun during the eclipse. Jeff Geerling brought three generations along for his eclipse party, which resulted in some wonderful photographs and rubbing elbows with Destin from “Smarter Every Day.” Also interesting is this analysis of internet traffic during the eclipse by content delivery concern Cloudflare — or is that Cloudprominence? — which shows remarkable dips in internet use during totality. The dips tracked across the continent from Mexico to Canada and lined up perfectly with the Moon’s shadow.
In non-eclipse news, someone crunched the numbers on the forces involved when the MV Dali rammed into the Francis Scott Key Bridge in Baltimore, and — wow! Taking into account the mass of the loaded container ship and its change in speed during the collision, the vessel imparted something like 26 million pounds of force on the bridge. If our calculations are correct, that’s over 115 million newtons, which, as the article notes, is equivalent to 66 fully loaded semi trucks crashing into the bridge at highway speed all at once. No wonder it collapsed like it was made of toothpicks. Perhaps the most interesting thing we learned from this article was that there’s a standard reference value for the force exerted on a bridge abutment by a truck crash, and it’s 400,000 pounds.
Git is one of those things that’s so incredibly useful and so tightly integrated into our culture that it’s hard to remember what we did for source control before it came onto the scene. But source control goes way, way back, perhaps further than you realize, as this series of articles on source control systems documents. This article is the first of four parts and focuses primarily on SCCS and RCS. We were surprised to learn that source management only became a thing in the 70s when video terminals and magnetic mass storage became more ubiquitous. We’re looking forward to the second part, which covers the bad old days of CVS, SourceSafe, and ClearCase, which is where we first fell down the source control rabbit hole.
And finally, we wanted to share this fascinating video on the unlikely origins of the first desktop computer: the guidance computer of the Minuteman I ICBM. In 1962, computers filled entire rooms, but the Autonetics D-17B came in at a mere 28 kilos, a remarkable accomplishment in computer miniaturization. About 800 of the general-purpose digital computers were fielded, and when the Minuteman I gave way to other, more capable ICBMs, the decommissioned computers were distributed free of charge to universities and other institutions. The chief obstacle to putting one of these machines to work seems to have been coming up with a power supply, but once that was accomplished, a “Minuteman Computer Users Group” stood ready to help you get going.
Alla scoperta del SOAR: Security Orchestration, Automation and Response https://poliverso.org/display/0477a01e-4da24d82-2a758a06a4047513 Alla scoperta del SOAR: Security Orchestration, Automation and Response Negli ultimi anni, il mondo della cybersecurity ha assistito a una trasformazione epocale con l’introduzione di nuove tecnologie e metodologie volte a contrastare le sempre più sofisticate minacce informatiche.Tra queste, un ruolo fondamentale è giocato dal SOAR, acronimo che sta per
Alla scoperta del SOAR: Security Orchestration, Automation and Response
Negli ultimi anni, il mondo della cybersecurity ha assistito a una trasformazione epocale con l’introduzione di nuove tecnologie e metodologie volte a contrastare le sempre più sofisticate minacce informatiche.
Tra queste, un ruolo fondamentale è giocato dal SOAR, acronimo che sta per Security Orchestration, Automation and Response. Si tratta di un approccio integrato alla gestione della sicurezza informatica che unisce orchestrazione, automazione e risposta.
Cos’è il SOAR?
Il SOAR è una piattaforma software progettata per automatizzare e orchestrare le attività legate alla sicurezza informatica, consentendo alle organizzazioni di gestire in modo efficiente e coordinato le minacce alla sicurezza. Questa tecnologia unisce tre componenti chiave:
Orchestrazione: Consente di coordinare e gestire le attività di sicurezza informatica attraverso l’automazione dei processi, la distribuzione delle risorse e la sincronizzazione delle azioni tra sistemi e applicazioni;
Automazione: Utilizza algoritmi e regole predefinite per eseguire automaticamente operazioni di sicurezza, riducendo al minimo il coinvolgimento umano e accelerando la risposta agli incidenti;
Risposta: Fornisce agli operatori di sicurezza strumenti e procedure per rispondere prontamente agli eventi di sicurezza, analizzare le minacce e implementare misure correttive.
Come funziona il SOAR?
Il SOAR integra diverse fonti di dati provenienti da dispositivi di sicurezza, log di sistema, feed di intelligence sulle minacce e altre fonti pertinenti. Utilizzando queste informazioni, la piattaforma identifica e classifica gli eventi di sicurezza, determinando la gravità e l’impatto di ciascuno.
Una volta identificata una potenziale minaccia, il SOAR avvia un processo di risposta automatizzato o semi-automatizzato. Questo può includere l’isolamento dei dispositivi infetti, l’applicazione di patch di sicurezza, l’avvio di indagini digitali per determinare l’origine dell’attacco e altre azioni volte a mitigare i rischi per la sicurezza.
Vantaggi del SOAR
L’implementazione di una soluzione SOAR offre numerosi vantaggi alle organizzazioni:
Migliore efficienza operativa: Automatizzando le attività ripetitive e riducendo il tempo di risposta agli incidenti, il SOAR consente agli operatori di sicurezza di concentrarsi su compiti ad alto valore aggiunto.
Maggiore visibilità: Integrando e analizzando dati provenienti da varie fonti, il SOAR fornisce una visione completa delle minacce alla sicurezza, consentendo alle organizzazioni di identificare e rispondere prontamente agli eventi critici.
Risposta rapida agli incidenti: Grazie alla sua capacità di risposta automatizzata, il SOAR consente alle organizzazioni di affrontare tempestivamente le minacce alla sicurezza, riducendo al minimo l’impatto degli attacchi informatici.
Conclusioni
Il SOAR rappresenta una risorsa fondamentale per le organizzazioni impegnate nella difesa contro le minacce informatiche sempre più sofisticate e diffuse. Integrando orchestrazione, automazione e risposta, questa tecnologia offre un approccio integrato alla gestione della sicurezza informatica, consentendo alle organizzazioni di migliorare l’efficienza operativa, aumentare la visibilità sulle minacce e rispondere prontamente agli incidenti.
Investire in una soluzione SOAR è essenziale per garantire una protezione efficace contro le minacce informatiche e mantenere la sicurezza dei dati e dei sistemi informativi.
Porting Modern Windows Applications to Windows 95 https://poliverso.org/display/0477a01e-a6b25031-1198403058d0728d Porting Modern Windows Applications to Windows 95 Windows 95 was an amazing operating system that would forever transform the world of home computing, setting the standard for user interaction on a desktop and quite possibly was the OS which had the longest queue of people lining up on launch day to snag a boxed copy. This raises the question of why we still don’t write software
Windows 95 was an amazing operating system that would forever transform the world of home computing, setting the standard for user interaction on a desktop and quite possibly was the OS which had the longest queue of people lining up on launch day to snag a boxed copy. This raises the question of why we still don’t write software for this amazing OS, because ignoring the minor quibbles of ‘security patches’ and ‘modern hardware compatibility’, it’s still has pretty much the same Win32 API as supported in Windows 11, plus it doesn’t even spy on you, or show you ads. This line of reasoning led [MattKC] recently to look at easy ways to port modern applications to Windows 95.
In the video, the available options are ticked off, starting with straight Win32 API. Of course, nobody writes for the Win32 API for fun or to improve their mental well-being, and frameworks like WxWidgets and QuteQt have dropped support for Windows 9x and generally anything pre-Win2k for years now. The easiest option therefore might be Microsoft’s .NET framework, which in its (still supported) 2.0 iteration actually supports Windows 98 SE, or basically within spitting distance of running it on the original Win95.
An interesting point here is that .NET was never released for Windows 95 by Microsoft, which raises the question of whether there’s such a crucial difference between Windows 95 and 98 that would prevent the .NET framework from running on the former. As [Matt] finds out during his investigation, the answer seems to be mostly that Microsoft never bothered to fully test .NET on Win95 due to the low marketshare of Win95, ergo this just throws up an error message about an unsupported OS.
In order to get around this, [Matt] had to write his own .NET installer, which first led him down a maddening rabbit hole of the internals of the .NET runtime and its installer. That resolved running the custom installer on Windows 98, but even with custom function wrappers [Matt] was left with a series of exceptions to debug and resolve, including an SSE2-related one due to lack of SSE2 support in Windows 95. All of this without access to the JIT debugger that’d exist on Win98 and newer.
Eventually he did get it working, however, with the results available on the GitHub project page. Since backporting .NET 2.0 was so much fun, he next embarked on backporting .NET Framework version 3.5 as well, opening another series of .NET applications for running on an OS that’s now nearly thirty years old. Even if a practical use case is hard to make, it’s absolutely a fascinating in-depth look at what has changed over the past decades, and what we may have gained, and lost.
Danish Vintage LRC Meter Reveals Inside https://poliverso.org/display/0477a01e-b12f1689-18d55690825431dd Danish Vintage LRC Meter Reveals Inside Modern test equipment is great, but there’s something about a big meter with a swinging needle and a mirror for parallax correction that makes a device look like real gear. [Thomas] shows us a Danish LCR https://www.youtube.com/watch?v=mG_4iejJFC8meter (or, as it says on the front, an RLC meter). The device passes AC through the component and uses
another fantastic Radiometer unit passed thru my lab, quite modern for its time, imagine this one is from about 1974, it still works very accurate, and a ver...
Modern test equipment is great, but there’s something about a big meter with a swinging needle and a mirror for parallax correction that makes a device look like real gear. [Thomas] shows us a Danish LCR meter (or, as it says on the front, an RLC meter). The device passes AC through the component and uses that to determine the value based on the setting of a range switch. It looks to be in great shape and passed some quick tests. Have a look at it in the video below.
An outward inspection shows few surprises, although there is an odd set of terminals on the back labeled DC bias. This allows you to provide a DC voltage in case you have a capacitor that behaves differently when the capacitor has a DC voltage across it. Block diagram for the MM2 The circuit can measure — as the name implies — resistance, inductance, and capacitance. The manual shows a nice block diagram if you want to understand what’s going on.
Physically opening it up was a bit of a puzzle. That older gear was often well-constructed. Inside are some nice PCBs, a lot of transistors, and beautiful wiring harnesses. Someone took their time building this unit, and it shows.
Usually, when you see gear like this, it is a bridge, and you have to zero the meter, but not so with the MM2. These days, you are likely to use a microcontroller to measure the charge and discharge rate.
The BBC Micro, Lovingly Simulated in VR https://poliverso.org/display/0477a01e-98960b63-805f15bc0c7c525e The BBC Micro, Lovingly Simulated in VR The BBC Micro was many peoples’ first exposure to home computing, and thanks to [Dominic Pajak], you can fire up this beloved hardware in WebXR https://xr.bbcmic.ro/. Is it an emulator? Yes, but it’s also much more than that.The machine, the CRT, the keycaps, and even the sounds of the original keypresses are all brought to life as accurately as
The BBC Micro was many peoples’ first exposure to home computing, and thanks to [Dominic Pajak], you can fire up this beloved hardware in WebXR. Is it an emulator? Yes, but it’s also much more than that.
The machine, the CRT, the keycaps, and even the sounds of the original keypresses are all brought to life as accurately as possible. The result is not just an emulator. It’s a lovingly-made BBC Micro simulator you can use with a VR headset. Or just use your browser and type on your real keyboard if you like.
Virtual BBC Micro, complete with hand tracking and passthrough video. This all started with [Dominic]’s previous project of VirtualBeeb, a web-based interactive model of a fully functional BBC Micro, complete with all the sights and sounds of the original hardware. [Dominic] later worked to bring it into 3D with the help of WebXR, aided by the rapid advancement of VR hardware and the excellent resources and functionality of Three.js, upon which the project was built.
[Dominic] shares the whole journey in a fascinating blog post that talks not just about creating a high-fidelity simulated BBC Micro but also what it was like to port it to a true 3D experience.
It’s a fantastic project that pays homage to a truly influential piece of vintage computing, so brush up on BBC Basic to deepen your appreciation. The BBC Micro, after all, was more than just a computer from the 80s. It was an integral part of the UK’s Computer Literacy Project, and in the 80s there was a realization that this was going to affect everyone. Wondering what that was like? Browse those broadcasts online and soak it all in.
Dump a Code Repository as a Text File, For Easier Sharing with Chatbots https://poliverso.org/display/0477a01e-3065cbb3-7cb3aff30b6a1661 Dump a Code Repository as a Text File, For Easier Sharing with Chatbots Some LLMs (Large Language Models) can act as useful programming assistants when provided with a project’s source code, but experimenting with this can get a little tricky if the chatbot has no way to download from the internet. In such cases, the code must be provided by either pasting it
Dump a Code Repository as a Text File, For Easier Sharing with Chatbots
Some LLMs (Large Language Models) can act as useful programming assistants when provided with a project’s source code, but experimenting with this can get a little tricky if the chatbot has no way to download from the internet. In such cases, the code must be provided by either pasting it into the prompt or uploading a file manually. That’s acceptable for simple things, but for more complex projects, it gets awkward quickly.
To make this easier, [Eric Hartford] created github2file, a Python script that outputs a single text file containing the combined source code of a specified repository. This text file can be uploaded (or its contents pasted into the prompt) making it much easier to share code with chatbots.
It’s becoming increasingly clear that these tools represent more of an evolution than a revolution, and there are useful roles chatbots can play in programming. Some available chatbots have coding in mind. Others do not. But hackers being hackers we naturally want to experiment for ourselves regardless of a product’s intended uses, and a tool like this makes it easier to do that. Just remember their work — for now — is often at the intern level.
A Slew Of AI Courses To Get Yourself Up to Speed https://poliverso.org/display/0477a01e-5148b971-3c17bfb9bc4fa4cf A Slew Of AI Courses To Get Yourself Up to Speed When there’s a new technology, there’s always a slew of people who want to educate you about it. Some want to teach you to use their tools, some want you to pay for training, and others will use free training to entice you to buy further training. Since AI is the new hot buzzword, there are plenty of free classes from reputable
When there’s a new technology, there’s always a slew of people who want to educate you about it. Some want to teach you to use their tools, some want you to pay for training, and others will use free training to entice you to buy further training. Since AI is the new hot buzzword, there are plenty of free classes from reputable sources. The nice thing about a free class is that if you find it isn’t doing it for you, there’s no penalty to just quit.
Surprisingly, Google hasn’t been as successful with AI, but it does have some longer and possibly more technical topics in its Google Cloud Skills Boost program. There are actually several “paths” with AI content, such as “Generative AI for Developers.” If you prefer Amazon, they have a training center with many free courses, including those on AI topics like Foundations of Prompt Engineering. Of course, you can expect these offerings will center on what a great idea the Google systems or the Amazon systems are. Can’t blame them for that.
They are all, of course, playing catchup to OpenAI. If you prefer to see what classes they offer, you can check out their partner DeepLearning.ai. Many other vendors have training here, also.
If you want something more rigorous, edX has a plethora of AI classes ranging from Harvard’s CS50 introduction class that uses Python (see the almost 12-hour video below) to offerings from IBM, Google, and others. These are typically free, but you have to pay if you want grading and a certificate or college credit. Microsoft also offers a comprehensive 12-week study program.
Naturally, there are more. The good news if you have choices. The bad news is that it is probably easy to make the wrong choice. Do you have any you’ve taken that you’d recommend or not recommend? Leave us a comment!
We are always amazed at how much you can learn online if you are structured and disciplined about it. There is no shortage of materials from very reputable schools available.
Tutti su Marte! 1000 Starship su Marte entro 20 anni, Parola di Elon Musk https://poliverso.org/display/0477a01e-bd660881-9f841567bcb73511 Tutti su Marte! 1000 Starship su Marte entro 20 anni, Parola di Elon Musk “…rimanere sulla Terra per sempre, e fin quando non ci sarà qualche estinzione. L’alternativa è diventare una civiltà spaziale e una specie multi-planetaria” ha riportato recentemente il magnate Elon Musk.Il fondatore di SpaceX, Elon Musk, ha condiviso i https://youtu.be/v9lAGmWhcZM
The goal of SpaceX is to build the technologies necessary to make life multiplanetary. This is the first time in the 4-billion-year history of Earth that it’...
Tutti su Marte! 1000 Starship su Marte entro 20 anni, Parola di Elon Musk
“…rimanere sulla Terra per sempre, e fin quando non ci sarà qualche estinzione. L’alternativa è diventare una civiltà spaziale e una specie multi-planetaria” ha riportato recentemente il magnate Elon Musk.
Il fondatore di SpaceX, Elon Musk, ha condiviso i piani per creare una società autosufficiente su Marte. Dopo il successo del terzo volo di prova della Starship il mese scorso, il prossimo, il quarto, è previsto per maggio.
Uno degli obiettivi chiave dei test nel 2024 è tentare di intercettare il primo stadio del razzo al momento del lancio. Musk ha osservato che le missioni su Marte richiederanno sei voli di rifornimento per il secondo stadio del razzo Starship per garantire carburante sufficiente. SpaceX prevede di intercettare i razzi non appena sarà possibile farli atterrare in sicurezza su piattaforme virtuali nell’oceano.
Inoltre ha condiviso la sua visione per la colonizzazione di Marte durante un discorso presso la struttura Starbase di SpaceX a Boca Chica, Texas. Musk prevede che il razzo Starship di SpaceX, insieme a una riduzione significativa dei costi di lancio, possa un giorno permettere spedizioni di migliaia di astronavi verso Marte contemporaneamente.
Il fondatore di SpaceX ha ribadito il suo obiettivo di colonizzare Marte per trasformare l’umanità in una specie multi-planetaria, prevedendo che le prime colonie sorgeranno entro 20 anni. Musk ha delineato anche i progressi del razzo Starship, prevedendo un rapido sviluppo e una spinta totale al decollo di 10.000 tonnellate. Inoltre, ha discusso di una flotta di Starship con varianti per Terra, Luna e Marte, progettando di utilizzare le navi smantellate come fonte di materiali da costruzione per i coloni. Le sue visioni includono anche la possibilità di centrali nucleari su Marte.
In preparazione per una missione su Marte, i siti di atterraggio dovrebbero essere scelti il più a bassa altitudine possibile per fornire una sufficiente moderazione atmosferica e situati vicino all’equatore di Marte per massimizzare l’utilizzo dell’energia solare.
Inoltre, Musk ha condiviso i piani per utilizzare il secondo stadio della Starship nel 2025 e ha menzionato il test del trasferimento di carburante da nave a nave il prossimo anno. Sono stati inoltre presentati dettagli sul motore Raptor 3 e sulle nuove varianti di Starship, tra cui Starship 3 che costa meno per volo rispetto al Falcon 1 grazie alla sua completa riutilizzabilità e al design semplificato, riducendo potenzialmente il costo di messa in orbita fino a 2 milioni di dollari.
Per le missioni sulla Luna della NASA, la Starship sarà dotata di gambe di atterraggio, ma senza valvole o scudo termico, il che la renderà inadatta al ritorno sulla Terra. Musk ritiene che la maggior parte delle persone che vanno su Marte non torneranno sulla Terra, ma l’obiettivo a lungo termine del programma Starship è rendere possibile tale viaggio.
SpaceX prevede di costruire un numero significativamente maggiore di navi rispetto ai booster, poiché la maggior parte delle navi verrà utilizzata su Marte per l’estrazione di risorse.
La società sta inoltre costruendo nuove torri di lancio in Florida e Texas per garantire la continuità dei test nonostante possibili incidenti.





Confronto delle prestazioni di vari compiti Grok 1.5V con altri modelli







")
There are a number of other easily-available threaded inserts, including the rivnut (or rivet nut), chunky hex socket threaded inserts intended for wood and furniture, heli-coils or helical inserts (which resemble springs), self-tapping threaded inserts (also sold as thread adapters), and T-nuts or prong nuts. They all are a bit different, but he measures each one and gives a thorough rundown on how they perform, as well as offering his thoughts on what works best.












Oh, and while we’re here, I’d like to show you a pretty cool thing I’ve found on Aliexpress! These are tiny FX2 boards with the same logic analyzer schematic, so they work with the FX2 open-source firmware and Sigrok – but they’re much smaller, have USB-C connectors instead of cable struggle that is miniUSB, and are often even cheaper than the ‘plastic case’ FX2 analyzers we’ve gotten used to. In addition to that, since you can see the exposed PCB, unlike with the ‘plastic case’ analyzers, you know whether you’re getting input buffers or not!
If you open the above files in Pulseview – you will see a whole bunch of I2C traces. I wanted to zone in on the FUSB302, naturally – accelerometer and OLED communications are also interesting but weren’t my focus. You will also see that there’s a protocol decoder called “I2C filter” attached. Somehow, it’s been remarkably useless for me whenever I try to use it, not filtering out anything at all. No matter, though – right click on the I2C decoder output row (the one that shows decoded bytes and events), click “Export all annotations for this row”, pick a filename, then open the file in a text editor.
I’ve scrolled through the datasheet, and put together a Python dictionary with a register address-name mapping. Using that, we can easily go through transactions, mapping them to specific register reads and writes, and convert the raw transaction data into lines of text that clearly tell us – first, we write this byte to SWITCHES0 register, then we write a this byte into POWER register, and so on. Here’s the code I wrote to make verbose transactions – and it helps you turn logic analyzer captures into Python code!
Bytes received at 76800 marked in orange, bytes received at 11500 marked in greed; the exact commandline visible in the screenshot, too!


 #FSFE is committed to ensuring that everyone can install and run #FreeSoftware on any device! 🚀
#FSFE is committed to ensuring that everyone can install and run #FreeSoftware on any device! 🚀




When the Universe first came into existence, for a brief moment it would have existed in perfect symmetry in its high energy state, but as we can observe today this state did not persist. Rather than maintain this perfect state of symmetry, something caused this symmetry to spontaneously break and separate into areas of distinct mass. These areas would coalesce into nebulae, stars and ultimately the galaxies courtesy of which we are able to contemplate our place in the Universe today. Figuring out the exact nature of the symmetry breaking that led to this was the topic of much discussion among particle physicists during the 20th century.
The ‘Sombrero Potential’ as seen with the Higgs mechanism.

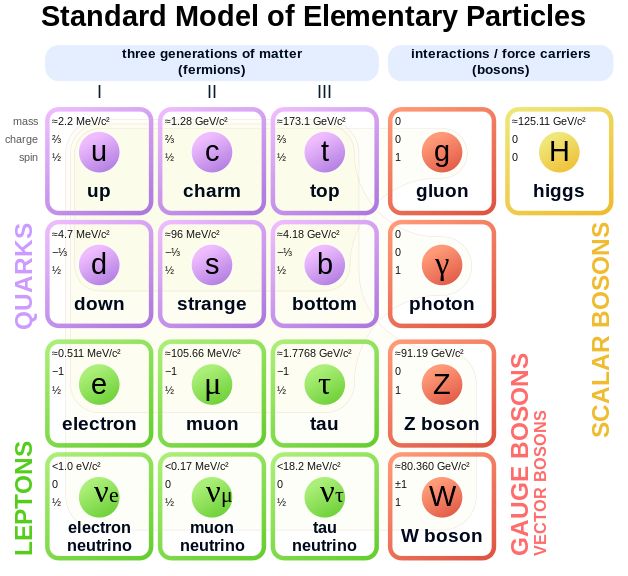








































Annuncio nel forum underground Beach Forums (fonte Red Hot Cyber)
Bounty program di Zerodium







Block diagram for the MM2

Virtual BBC Micro, complete with hand tracking and passthrough video.




dapgo
in reply to Free Software Foundation Europe • • •"For that, end-users should be able to run Free Software on their devices and use services independently of the control exercised by device manufacturers, vendors, and platforms." https://deviceneutrality.org/#principles
Device Neutrality
Device Neutrality