 - Collegamento all'originale")
Assessing SIEM effectiveness

A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
Methodology for assessing SIEM effectiveness
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
- Composition and scope of connected data sources
- Coverage of data sources
- Data flows from existing sources
- Correctness of data normalization
- Detection logic operability
- Detection logic accuracy
- Detection logic coverage
- Use of contextual data
- SIEM technical integration into SOC processes
- SOC analysts’ handling of alerts in the SIEM
- Forwarding of alerts, security event data, and incident information to other systems
- Deployment architecture and documentation
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
- Issues with detection logic due to incorrect data normalization. A correlation rule with the condition
deviceCustomString1 not contains <string>triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts. - When analyzing coverage for a specific source type, we discovered that the SIEM was only monitoring 5% of all such sources deployed in the infrastructure. However, extending that coverage would increase system load and storage requirements. Therefore, besides connecting additional sources, it would be necessary to scale resources for specific modules (storage, collectors, or the correlator).
The effectiveness assessment consists of several stages:
- Collect and analyze documentation, if available. This allows assessing SIEM objectives, implementation settings (ideally, the deployment settings at the time of the assessment), associated processes, and so on.
- Interview system engineers, analysts, and administrators. This allows assessing current tasks and the most pressing issues, as well as determining exactly how the SIEM is being operated. Interviews are typically broken down into two phases: an introductory interview, conducted at project start to gather general information, and a follow-up interview, conducted mid-project to discuss questions arising from the analysis of previously collected data.
- Gather information within the SIEM and then analyze it. This is the most extensive part of the assessment, during which Kaspersky experts are granted read-only access to the system or a part of it to collect factual data on its configuration, detection logic, data flows, and so on.
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
Issues arising from SIEM operations
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
- Performance issues, meaning operational errors in various system components. These problems are typically resolved by technical support, but to prevent them, it is worth periodically checking system health status.
- Efficiency issues – when the system functions normally but seemingly adds little value or is not used to its full potential. This is usually due to the customer using the system capabilities in a limited way, incorrectly, or not as intended by the developer.
- Detection issues – when the SIEM is operational and continuously evolving according to defined processes and approaches, but alerts are mostly false positives, and the system misses incidents. For the most part, these problems are related to the approach taken in developing detection logic.
Key observations from the assessment
Event source inventory
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
- High Priority – sources associated with:
- Remote access provision
- External services accessible from the internet
- External perimeter
- Endpoint operating systems
- Information security tools
- Medium Priority – sources associated with:
- Remote access management within the perimeter
- Internal network communication
- Infrastructure availability
- Virtualization and cloud solutions
- Low Priority – sources associated with:
- Business applications
- Internal IT services
- Applications used by various specialized teams (HR, Development, PR, IT, and so on)
Monitoring data flow from sources
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
- Checking collector health. Find the status of collectors (see the support website for the steps to do this in Kaspersky SIEM) and identify those with a status of
Offline,Stopped,Disabled, and so on. - Checking the event flow. In Kaspersky SIEM, this can be done by gathering statistics using the following query (counting the number of events received from each collector over a specific time period):
SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Event source coverage
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM [code]eventsGROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)[/code]SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM [code]eventsGROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)[/code]
We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Retaining raw data
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
Normalization
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
- The event flow is not being normalized at all.
- Events are only partially normalized – this is particularly relevant for custom, non-out-of-the-box normalizers.
- The normalizer being used only parses headers, such as
syslog_headers, placing the entire event body into a single field, this field most often beingMessage. - An outdated default normalizer is being used.
How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
- First, check which normalizers supplied with the SIEM the organization uses and whether their versions are up to date. In our assessments, we frequently encounter auditd events being normalized by the outdated normalizer,
Linux audit and iptables syslog v2for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source. - Execute the query:
SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Detection logic coverage
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
- The name of the detection logic. With a standardized approach to naming correlation rules, the name can indicate the associated source or at least provide a brief description of what it detects.
- The use of fields within the rules, such as
DeviceVendor,DeviceProduct(another argument for including these fields in the normalizer),Name,DeviceAction,DeviceEventCategory,DeviceEventClassID, and others. These can help identify the actual source.
Excessive alerts generated by the detection logic
One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
Lack of integration with indicators of compromise
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
- At the data source level. Some sources, such as NGFWs, add this information to events involving relevant objects.
- At the SIEM native functionality level. For example, Kaspersky SIEM integrates with CyberTrace indicators, which add object reputation information at the moment of processing an event from a source.
- At the detection logic level. Information about IoCs is stored in various active lists, and correlation rules match objects against these to enrich the event.
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
The SIEM is not kept up to date
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
Other issues with SIEM implementation and operation
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
- Mismatch between license capacity and actual SIEM load. The problem is almost always the absence of events from sources, rather than an incorrect initial assessment of the organization’s needs.
- Lack of user rights management within the system (for example, every user is assigned the administrator role).
- Poor organization of customizable SIEM resources (rules, normalizers, filters, and so on). Examples include chaotic naming conventions, non-optimal grouping, and obsolete or test content intermixed with active content. We have encountered confusing resource names like
[dev] test_Add user to admin group_final2. - Use of out-of-the-box resources without adaptation to the organization’s infrastructure. To maximize a SIEM’s value, it is essential at a minimum to populate exception lists and specify infrastructure parameters: lists of administrators and critical services and hosts.
- Disabled native integrations with external systems, such as LDAP, DNS, and GeoIP.
Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
Conclusion
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.

La mente e le password: l’Effetto “Louvre” spiegato con una password pessima
Nella puntata precedente (La psicologia delle password. Non proteggono i sistemi: raccontano le persone), abbiamo parlato di come le password, oltre a proteggere i sistemi, finiscano per raccontare le persone.
Questa volta facciamo un passo in più: proviamo a capire perché ci affezioniamo proprio a quelle peggiori e perché cambiarle produce spesso l’effetto opposto a quello desiderato.
Paris…
Il punto di partenza è un episodio di cronaca: all’interno di una combolist circolata in ambienti criminali è comparsa una coppia di credenziali che associava un indirizzo istituzionale del Louvre a una password sorprendentemente coerente con il contesto: paris – e le sue inevitabili reincarnazioni.
Partiamo dalla fine: la combo è stravecchia e la password è stata cambiata da anni.
Il riflesso mentale che l’ha prodotta, purtroppo, no.
Ed è proprio quel riflesso che vale la pena osservare.

Paris – e ciò che puntualmente le cresce intorno – non nasce da distrazione né da superficialità.
Nasce perché ha senso. Il Louvre è a Parigi, l’account riguarda il Louvre, e il cervello umano fa ciò che sa fare meglio quando lo sforzo richiesto è minimo: prende il contesto e lo trasforma in soluzione. Non cerca sicurezza, ma coerenza.
La password smette di essere una chiave e diventa qualcosa che “torna”, che non disturba, che non richiede memoria né attrito.
È qui che l’aneddoto smette di essere cronaca e diventa psicologia. Una password costruita così non viene percepita come debole, ma come nostra. L’abbiamo assemblata partendo da ciò che conosciamo, e questo basta a renderla affidabile ai nostri occhi.
È l’Effetto IKEA applicato alla sicurezza: tendiamo a dare più valore a ciò che abbiamo costruito noi, anche quando è fragile.
Il problema emerge nel momento successivo, quando entra in scena il rito del Cambia Password. Se quella parola non è solo una stringa ma un piccolo equilibrio mentale, cambiarla non è un’operazione tecnica. È una rinuncia.
E la mente, davanti a una perdita, non reagisce creando qualcosa di nuovo: reagisce cercando continuità. La forma resta, cambiano i dettagli. Le varianti si moltiplicano, la sicurezza molto meno.
Il sistema chiede complessità. La mente risponde con riconoscibilità.
L’Effetto IKEA (perché difendiamo le password peggiori)
C’è un motivo se una password come paris resiste più a lungo di quanto dovrebbe.
Non è tecnico. È affettivo.
In psicologia si chiama Effetto IKEA: tendiamo a dare più valore agli oggetti che abbiamo costruito noi, anche quando sono fragili, storti o palesemente migliorabili. Non perché siano migliori, ma perché raccontano il tempo e il ragionamento che ci abbiamo messo dentro.
Montare un mobile traballante e difenderlo con orgoglio è un comportamento perfettamente umano. Fare lo stesso con una password lo è ancora di più.
Una password costruita a partire dal contesto – un luogo, un ruolo, un’associazione evidente – non viene vissuta come una scelta debole. Viene vissuta come una scelta “pensata”. L’abbiamo fatta noi, ha un senso, la riconosciamo al volo. E questo basta a farla sembrare affidabile, anche quando non lo è.
Il paradosso è che l’Effetto IKEA funziona meglio proprio dove dovrebbe fallire. Più una password è semplice, leggibile, coerente, più diventa familiare. E più diventa familiare, più facciamo fatica a metterla in discussione.
Non la valutiamo come una chiave. La trattiamo come un oggetto personale.
E quando un sistema ci suggerisce di sostituirle, la reazione istintiva non è migliorare, ma conservare: tenere la forma, aggiustare i bordi, cambiare il minimo indispensabile per poter dire di aver obbedito.
L’Effetto IKEA non ci rende ingenui. Ci rende coerenti con noi stessi.
Ed è proprio questa coerenza, così utile nella vita quotidiana, che nel digitale diventa prevedibile.
Un esempio minimo
Pensiamo a un mobile IKEA.
Lo monti la sera, quando tutti ti guardano. Segui le istruzioni, più o meno. A un certo punto manca una vite. Oppure ce n’è una di troppo, che resta lì sul tavolo a fissarti.
Il mobile alla fine sta in piedi. Un po’ storto. Un’anta non chiude perfettamente.
La famiglia lo guarda in silenzio.
Qualcuno chiede: “È normale?”
E a quel punto difenderlo diventa inevitabile.
Con le password succede la stessa cosa.
Una password costruita a partire dal contesto nasce spesso così: qualcosa manca, qualcosa avanza, ma “funziona”. Non è elegante, non è robusta, ma è nostra. Ci abbiamo messo le mani, il tempo, il ragionamento minimo necessario per farla stare in piedi.
Ed è questo l’Effetto IKEA applicato alla sicurezza: non diamo valore a una password perché è solida, ma perché l’abbiamo assemblata noi, anche se traballa.
E quando qualcuno ci dice che va cambiata, la prima reazione non è rifarla. È difenderla. O, al massimo, stringere meglio una vite.
Cambia Password (il rito che promette ordine)
A questo punto entra in scena il rito.
Quello che tutti conoscono e nessuno ama: Cambia Password.
Arriva puntuale, come una circolare aziendale o una notifica che non puoi ignorare. Non chiede se la password sia stata compromessa. Non chiede se ci sia stato un problema. Chiede solo di cambiarla. Perché è scaduta. Perché lo dice la policy. Perché si fa così.
E non chiede una password qualsiasi.
- La vuole lunga.
- Con numeri.
- Con simboli.
- Con maiuscole.
Non quelli che vuoi tu, quelli giusti.
E possibilmente abbastanza diversa dalle ultime.
A quel punto la password smette definitivamente di essere una chiave e diventa un oggetto da ricordare. Un peso cognitivo.
Ed è qui che scatta il vero ragionamento, quello che nessuna policy contempla:
“Se devo ricordarmela, allora tanto vale usarla per tutto.”
- Social.
- App.
- Account secondari.
- Il supermercato.
Qualsiasi cosa non sembri vitale in quel momento.
Non lo facciamo per incoscienza, ma per economia.

La password diventa un investimento. Se è complessa, la ammortizzo. Se mi costa memoria, la riuso. E così quella stessa stringa comincia a girare, a depositarsi, a comparire dove non dovrebbe.
Prima o poi finisce in una combolist. Non perché qualcuno abbia colpito il sistema giusto, ma perché l’ho portata io in giro abbastanza a lungo.
E infatti la nostra amata paris…
A quel punto non c’è rito che tenga.
Non è più una password.
È un souvenir digitale.

Il sistema crede di aver introdotto complessità.
La mente ha introdotto superficie di attacco.
E quando un design confonde la fatica con la sicurezza, il risultato non è protezione.
È solo un’altra vite stretta sullo stesso mobile storto.
Prossima puntata
Nella prossima puntata faremo un altro passo avanti.
Lasceremo perdere per un momento le password e guarderemo il problema dal punto di vista del design.
Perché c’è un’idea sbagliata, molto diffusa, secondo cui la sicurezza dovrebbe essere comoda, fluida, invisibile.
E invece funziona quasi sempre al contrario.
Parleremo di attrito, di sistemi che si fanno sentire, di autenticazioni che “rompono le palle” – francesismo improprio, ma dopo paris ce lo possiamo concedere – perché stanno facendo il loro lavoro.
Se finora il problema sembrava l’utente, la prossima volta toccherà chiedersi se non sia il progetto ad aver sbagliato bersaglio.
Parleremo anche di come si può ridurre il peso cognitivo senza abbassare la sicurezza: usando passphrase e costruendo password che funzionano davvero per chi le deve usare.
Continua…
L'articolo La mente e le password: l’Effetto “Louvre” spiegato con una password pessima proviene da Red Hot Cyber.
HackerHood di RHC scopre una privilege escalation in FortiClient VPN
L’analisi che segue esamina il vettore di attacco relativo alla CVE-2025-47761, una vulnerabilità individuata nel driver kernel Fortips_74.sys utilizzato da FortiClient VPN per Windows. Il cuore della problematica risiede in una IOCTL mal gestita che permette a processi user-mode non privilegiati di interagire con il kernel, abilitando una primitiva di scrittura arbitraria di 4 byte.
La falla è stata individuata il 31 gennaio 2025 da Alex Ghiotto, membro della community di Hackerhood. Sebbene la patch correttiva sia stata integrata già a settembre 2025 con il rilascio della versione 7.4.4,
Fortinet ha formalizzato la vulnerabilità solo il 18 novembre 2025 con la pubblicazione del bollettino ufficiale FG-IR-25-112.
Questo caso studio risulta particolarmente interessante per valutare l’efficacia delle moderne mitigazioni di sistema: l’exploit si basa infatti sul reperimento dell’indirizzo kernel del token di processo, un’operazione resa complessa a partire da Windows 11 24H2. In quest’ultima versione, l’accesso a tali informazioni tramite NtQuerySystemInformation richiede ora il privilegio SeDebugPrivilege, innalzando significativamente i requisiti necessari per un attacco efficace da parte di utenti non amministratori.

Analisi Tecnica della CVE-2025-47761
Fortips_74.sys è un driver kernel utilizzato da alcune soluzioni Fortinet, tra cui FortiClientVPN. Nel corso dell’analisi del driver è emersa una vulnerabilità successivamente identificata e corretta come CVE‑2025‑47761. L’obiettivo di questo articolo è descrivere il processo di analisi che ha portato alla sua individuazione e comprenderne le principali implicazioni di sicurezza. La vulnerabilità consente una scrittura arbitraria di 4 byte in un indirizzo controllato dall’utente. Questo comportamento può causare un crash del sistema oppure essere sfruttato per ottenere una completa escalation dei privilegi.
Interagire col Driver
Quando si analizza un driver alla ricerca di una potenziale escalation dei privilegi, la prima domanda fondamentale è: chi può interagirci?
Se anche utenti non privilegiati possono aprire un handle, allora vale la pena approfondire.
In questo caso, il primo passo è osservare chi può interagire con Fortips_74.sys.
Usando WinObj, si nota immediatamente che il driver non imposta permessi restrittivi: questo attira subito l’attenzione.
Una vista più tecnica delle DACL è possibile dal kernel tramite WinDBG
Il driver Fortips_74 crea infatti un device kernel senza definire DACL personalizzate, affidandosi al security descriptor di default. In pratica, qualunque processo nel sistema può aprire un handle verso il driver, compresi quelli a basso livello di integrità (come i processi sandboxati dei browser).
(Su quest’ultimo punto ammetto di non aver effettuato un controllo formale per conferma.)
Analizzando le DACL, risulta che SYSTEM e gli amministratori abbiano accesso completo, ma anche gli altri utenti possono comunque comunicare con il driver, seppur con permessi limitati.
Questo comportamento rende il driver troppo socievole: chiunque può comunicare tramite IOCTL, e in assenza di controlli adeguati il dispatch deve essere gestito in modo estremamente rigoroso per evitare vulnerabilità.


Dispatch delle IOCTL
Prima di entrare nei dettagli specifici del driver Fortips, è utile un breve ripasso.
Le IOCTL (Input/Output Control) permettono ai processi user-mode di inviare comandi specifici ai driver.
In Windows, la funzione DeviceIoControl consente di:
- passare un handle al device
- specificare un codice IOCTL
- fornire buffer di input/output
In sostanza, è il modo per dire:
“Esegui questa operazione con questi dati.”
Analizzando le IOCTL del driver, una in particolare risulta sospetta: 0x12C803.
Questa IOCTL utilizza METHOD_NEITHER, il più pericoloso tra i metodi previsti da Windows: il kernel passa puntatori user‑mode direttamente al driver senza alcuna validazione.
È quindi responsabilità totale del driver verificare:

- validità del puntatore
- accessibilità
- dimensione prevista
Se queste verifiche mancano, l’attaccante può passare puntatori arbitrari, inducendo il driver a leggere/scrivere memoria a cui non dovrebbe accedere.
Tramite questo tool è possibile confermare che il driver utilizza direttamente la IOCTL di tipo METHOD_NEITHER.
Il driver utilizza direttamente il UserBuffer fornito dal chiamante per scrivere l’output, senza alcuna copia o validazione preventiva. Questo significa che un processo user‑mode può passare un puntatore arbitrario, che il driver userà come destinazione dei dati. Senza controlli adeguati, basta un indirizzo malizioso per trasformare un semplice output in una scrittura arbitraria in kernel‑mode, con ovvie implicazioni di sicurezza.

Analisi della funzione vulnerabile
Seguendo il flusso del buffer, la funzione copia il contenuto del buffer user-mode in un buffer locale sullo stack. I primi 24 byte (0x18) vengono interpretati come:

- ULONGLONG Code
- ULONGLONG Size
- ULONGLONG Buffer
Il campo Size non è rilevante in questa catena, mentre Code e Buffer sì.
Per raggiungere il ramo vulnerabile, Code deve essere 0x63.

Dopo la copia preliminare in un buffer locale, il driver salta nella condizione interessata.
A questo punto, uVar7 viene impostato a 4.
Qui si trova il cuore della vulnerabilità:
il driver copia 4 byte da un buffer non inizializzato all’indirizzo specificato dall’utente tramite la IOCTL.
Non vi è alcun controllo o sanitizzazione.
Poiché la sorgente dei dati è stack-junk, la vulnerabilità si traduce in una arbitrary 4-byte write.
Specificando ad esempio l’indirizzo kernel della struttura _TOKEN, è possibile ottenere una privilege escalation.
Nel mio PoC, ho modificato il token per abilitare il privilegio SeDebugPrivilege, quindi ho avviato un cmd come SYSTEM.

Avvio del driver
Per ridurre l’interazione necessaria da parte dell’utente, ho analizzato il meccanismo con cui FortiClient avvia il servizio IPSec.
Il processo principale utilizza una Named Pipe per gestire la comunicazione IPC, inviando un buffer alla pipe
\\Device\\NamedPipe\\FC_{6DA09263-AA93-452B-95F3-B7CEC078EB30}.
All’interno del buffer sono presenti diversi campi, tra cui il nome del tunnel IPSec da inizializzare.Questa chiamata risulta sufficiente ad avviare il driver, anche senza privilegi amministrativi, condizione essenziale per la vulnerabilità.
Nella versione FortiClient VPN 7.4.3.1790 è inoltre possibile creare un profilo IPSec completamente fittizio, utilizzando parametri arbitrari. Nel mio caso, per la fase di test, ho impostato un gateway remoto come “google.it”, un comportamento diverso da quanto indicato da Fortinet nel bollettino ufficiale della CVE.


Proof of Concept
Video Player
Restrizioni
Come già accennato, lo sfruttamento di questa vulnerabilità si basa sulla possibilità di ottenere l’indirizzo kernel del token associato al processo, così da poterne manipolare i privilegi. A partire da Windows 11 24H2 questo non è più possibile da un processo con Integrity Level medio tramite la tradizionale chiamata NtQuerySystemInformation, poiché ora per accedere a tali informazioni è richiesto il privilegio SeDebugPrivilege, normalmente non disponibile agli utenti non amministratori.
Nel mio proof-of-concept ho sfruttato la vulnerabilità [url=https://www.redhotcyber.com/en/cve-details/?cve_id=CVE-2025-53136]CVE-2025-53136[/url], che tramite una race condition consente di ottenere il leak dell’indirizzo del _TOKEN. In questo modo il PoC rimane funzionante fino alla correzione della vulnerabilità prevista per gli aggiornamenti di agosto/settembre 2025.
Al di fuori di questo caso specifico, per sfruttare la vulnerabilità su un sistema completamente aggiornato sarebbe necessario disporre di un ulteriore bug in grado di fornire il leak dell’indirizzo richiesto, poiché le protezioni introdotte nel nuovo kernel impediscono di ottenerlo direttamente.
Timeline
- 31-01-2025: Vulnerabilità segnalata al PSIRT di Fortinet.
- 19-02-2025: Vulnerabilità confermata dal PSIRT di Fortinet.
- 09-05-2025: Fortinet dichiara di aver risolto il problema assegnando CVE-2025-47761.
- 18-11-2025: Fortinet pubblica sul PSIRT il bollettino riguardante la CVE.
L'articolo HackerHood di RHC scopre una privilege escalation in FortiClient VPN proviene da Red Hot Cyber.
Using an e-Book Reader as a Secondary Display

[Alireza Alavi] wanted to use an e-ink tablet as a Linux monitor. Why? We don’t need to ask. You can see the result of connecting an Onyx BOOX Air 2 to an Arch Linux box in the video below.
Like all good projects, this one had a false start. Deskreen sounds good, as it is an easy way to stream your desktop to a browser. The problem is, it isn’t very crisp, and it can be laggy, according to the post. Of course, VNC is a tried-and-true solution. The Onyx uses Android, so there were plenty of VNC clients, and Linux, of course, has many VNC servers.
Putting everything together as a script lets [Alireza] use the ebook as a second monitor. Using it as a main monitor would be difficult, and [Alireza] reports using the two monitors to mirror each other, so you can glance over at the regular screen for a color image, for example.
Another benefit of the mirrored screens is that VNC lets you use the tablet’s screen as an input device, which is handy if you are drawing in GIMP or performing similar tasks.
We sometimes use VNC on Android just to get to a fake Linux install running on the device.
youtube.com/embed/TeOg7Of8ZU4?…
From cheats to exploits: Webrat spreading via GitHub

In early 2025, security researchers uncovered a new malware family named Webrat. Initially, the Trojan targeted regular users by disguising itself as cheats for popular games like Rust, Counter-Strike, and Roblox, or as cracked software. In September, the attackers decided to widen their net: alongside gamers and users of pirated software, they are now targeting inexperienced professionals and students in the information security field.
Distribution and the malicious sample
In October, we uncovered a campaign that had been distributing Webrat via GitHub repositories since at least September. To lure in victims, the attackers leveraged vulnerabilities frequently mentioned in security advisories and industry news. Specifically, they disguised their malware as exploits for the following vulnerabilities with high CVSSv3 scores:
| CVE | CVSSv3 |
| CVE-2025-59295 | 8.8 |
| CVE-2025-10294 | 9.8 |
| CVE-2025-59230 | 7.8 |
This is not the first time threat actors have tried to lure security researchers with exploits. Last year, they similarly took advantage of the high-profile RegreSSHion vulnerability, which lacked a working PoC at the time.
In the Webrat campaign, the attackers bait their traps with both vulnerabilities lacking a working exploit and those which already have one. To build trust, they carefully prepared the repositories, incorporating detailed vulnerability information into the descriptions. The information is presented in the form of structured sections, which include:
- Overview with general information about the vulnerability and its potential consequences
- Specifications of systems susceptible to the exploit
- Guide for downloading and installing the exploit
- Guide for using the exploit
- Steps to mitigate the risks associated with the vulnerability
Contents of the repository

In all the repositories we investigated, the descriptions share a similar structure, characteristic of AI-generated vulnerability reports, and offer nearly identical risk mitigation advice, with only minor variations in wording. This strongly suggests that the text was machine-generated.
The Download Exploit ZIP link in the Download & Install section leads to a password-protected archive hosted in the same repository. The password is hidden within the name of a file inside the archive.
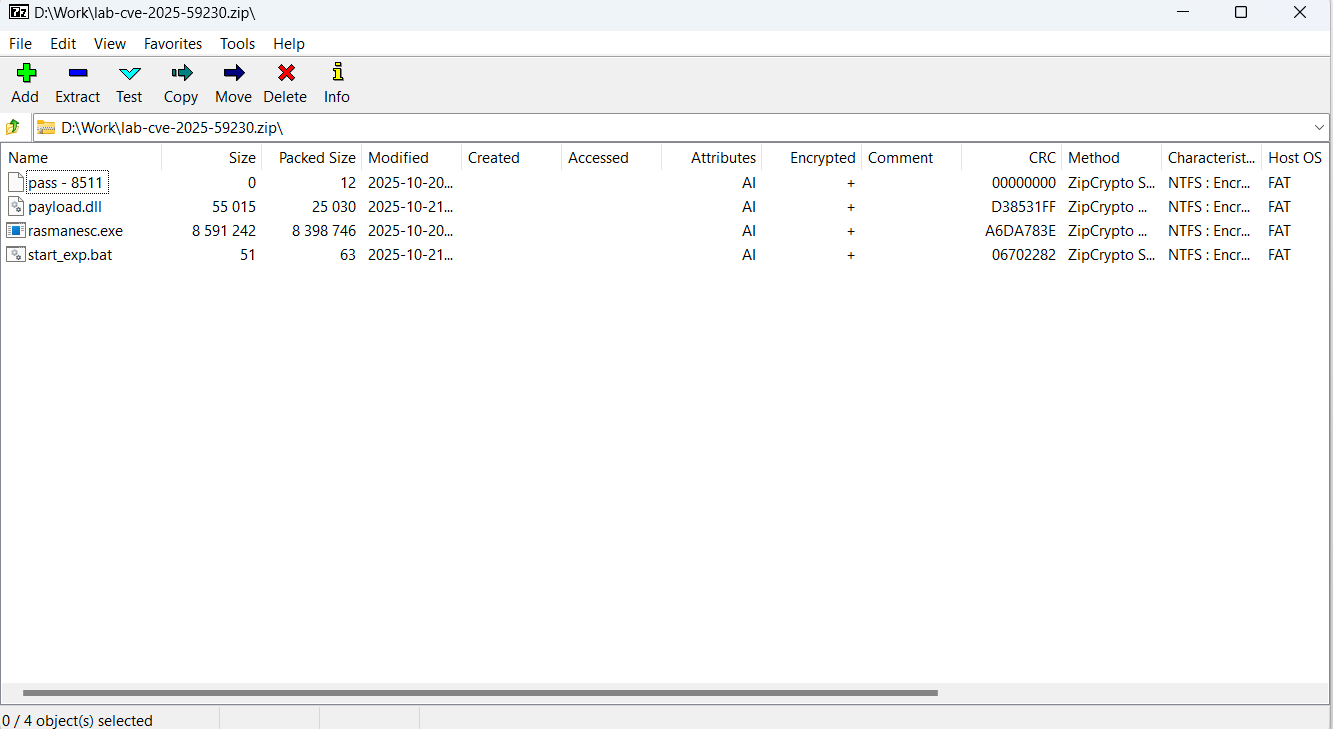
The archive downloaded from the repository includes four files:
- pass – 8511: an empty file, whose name contains the password for the archive.
- payload.dll: a decoy, which is a corrupted PE file. It contains no useful information and performs no actions, serving only to divert attention from the primary malicious file.
- rasmanesc.exe (note: file names may vary): the primary malicious file (MD5 61b1fc6ab327e6d3ff5fd3e82b430315), which performs the following actions:
- Escalate its privileges to the administrator level (T1134.002).
- Disable Windows Defender (T1562.001) to avoid detection.
- Fetch from a hardcoded URL (ezc5510min.temp[.]swtest[.]ru in our example) a sample of the Webrat family and execute it (T1608.001).
- start_exp.bat: a file containing a single command: start rasmanesc.exe, which further increases the likelihood of the user executing the primary malicious file.
The execution flow and capabilities of rasmanesc.exe

Webrat is a backdoor that allows the attackers to control the infected system. Furthermore, it can steal data from cryptocurrency wallets, Telegram, Discord and Steam accounts, while also performing spyware functions such as screen recording, surveillance via a webcam and microphone, and keylogging. The version of Webrat discovered in this campaign is no different from those documented previously.
Campaign objectives
Previously, Webrat spread alongside game cheats, software cracks, and patches for legitimate applications. In this campaign, however, the Trojan disguises itself as exploits and PoCs. This suggests that the threat actor is attempting to infect information security specialists and other users interested in this topic. It bears mentioning that any competent security professional analyzes exploits and other malware within a controlled, isolated environment, which has no access to sensitive data, physical webcams, or microphones. Furthermore, an experienced researcher would easily recognize Webrat, as it’s well-documented and the current version is no different from previous ones. Therefore, we believe the bait is aimed at students and inexperienced security professionals.
Conclusion
The threat actor behind Webrat is now disguising the backdoor not only as game cheats and cracked software, but also as exploits and PoCs. This indicates they are targeting researchers who frequently rely on open sources to find and analyze code related to new vulnerabilities.
However, Webrat itself has not changed significantly from past campaigns. These attacks clearly target users who would run the “exploit” directly on their machines — bypassing basic safety protocols. This serves as a reminder that cybersecurity professionals, especially inexperienced researchers and students, must remain vigilant when handling exploits and any potentially malicious files. To prevent potential damage to work and personal devices containing sensitive information, we recommend analyzing these exploits and files within isolated environments like virtual machines or sandboxes.
We also recommend exercising general caution when working with code from open sources, always using reliable security solutions, and never adding software to exclusions without a justified reason.
Kaspersky solutions effectively detect this threat with the following verdicts:
- HEUR:Trojan.Python.Agent.gen
- HEUR:Trojan-PSW.Win64.Agent.gen
- HEUR:Trojan-Banker.Win32.Agent.gen
- HEUR:Trojan-PSW.Win32.Coins.gen
- HEUR:Trojan-Downloader.Win32.Agent.gen
- PDM:Trojan.Win32.Generic
Indicators of compromise
Malicious GitHub repositories
https://github[.]com/RedFoxNxploits/CVE-2025-10294-Poc
https://github[.]com/FixingPhantom/CVE-2025-10294
https://github[.]com/h4xnz/CVE-2025-10294-POC
https://github[.]com/usjnx72726w/CVE-2025-59295/tree/main
https://github[.]com/stalker110119/CVE-2025-59230/tree/main
https://github[.]com/moegameka/CVE-2025-59230
https://github[.]com/DebugFrag/CVE-2025-12596-Exploit
https://github[.]com/themaxlpalfaboy/CVE-2025-54897-LAB
https://github[.]com/DExplo1ted/CVE-2025-54106-POC
https://github[.]com/h4xnz/CVE-2025-55234-POC
https://github[.]com/Hazelooks/CVE-2025-11499-Exploit
https://github[.]com/usjnx72726w/CVE-2025-11499-LAB
https://github[.]com/modhopmarrow1973/CVE-2025-11833-LAB
https://github[.]com/rootreapers/CVE-2025-11499
https://github[.]com/lagerhaker539/CVE-2025-12595-POC
Webrat C2
http://ezc5510min[.]temp[.]swtest[.]ru
http://shopsleta[.]ru
MD5
28a741e9fcd57bd607255d3a4690c82f
a13c3d863e8e2bd7596bac5d41581f6a
61b1fc6ab327e6d3ff5fd3e82b430315
SharePoint e DocuSign come esca: il phishing che ha provato ad ingannare 6000 aziende
I ricercatori di Check Point, pioniere e leader globale nelle soluzioni di sicurezza informatica, hanno scoperto una campagna di phishing in cui gli attaccanti si fingono servizi di condivisione file e firma elettronica per inviare esche a tema finanziario camuffate da notifiche legittime.
Il mondo iperconnesso ha reso più facile che mai per aziende e consumatori scambiarsi documenti, approvare transazioni e completare flussi di lavoro finanziari critici con un semplice clic. Le piattaforme di condivisione di file digitali e di firma elettronica, ampiamente utilizzate nel settore bancario, immobiliare, assicurativo e nelle operazioni commerciali quotidiane, sono diventate essenziali per il funzionamento veloce delle organizzazioni moderne. Questa comodità crea anche un’opportunità per i criminali informatici.
In questa campagna, i dati della telemetria Harmony Email di Check Point mostrano che nelle ultime settimane sono state inviate oltre 40.000 e-mail di phishing che hanno preso di mira circa 6.100 aziende.
Tutti i link malevoli sono stati convogliati attraverso l’indirizzo https://url.za.m.mimecastprotect.com/feed, aumentando la fiducia degli utenti grazie alla riproduzione di flussi di reindirizzamento a loro familiari.
Abuso della funzione di riscrittura dei link sicuri di Mimecast,
Poiché Mimecast Protect è un dominio affidabile, questa tecnica aiuta gli URL malevoli a eludere sia i filtri automatici che i sospetti degli utenti. Per aumentare la credibilità, le e-mail copiavano le immagini ufficiali del servizio (loghi dei prodotti Microsoft e Office), utilizzavano intestazioni, scritte a piè di pagina e pulsanti “Rivedi documento” in stile servizio e nomi visualizzati contraffatti come “X tramite SharePoint (Online)”, “eSignDoc tramite Y” e “SharePoint“, che ricalcavano in modo fedele i modelli di notifica autentici.

Oltre alla grande campagna SharePoint/e-signing, i ricercatori hanno identificato anche un’operazione più piccola ma correlata, che imita le notifiche DocuSign. Come l’attacco principale, questa impersona una piattaforma SaaS affidabile e sfrutta un’infrastruttura di reindirizzamento legittima, ma la tecnica utilizzata per mascherare la destinazione malevola è significativamente diversa.
Nella campagna principale, il reindirizzamento secondario agisce come un reindirizzamento aperto, lasciando visibile l’URL di phishing finale nella stringa di query nonostante sia racchiuso in servizi affidabili. Nella variante a tema DocuSign, il link passa attraverso un URL Bitdefender GravityZone e poi attraverso il servizio di tracciamento dei clic di Intercom, con la vera pagina didestinazione completamente nascosta dietro un reindirizzamento tokenizzato. Questo approccio nasconde completamente l’URL finale, rendendo la variante DocuSign ancora più elusiva e difficile da rilevare.

La campagna ha preso di mira principalmente organizzazioni negli Stati Uniti (34.057), in Europa (4.525), in Canada (767), in Asia (346), in Australia (267) e in Medio Oriente (256), concentrandosi in particolare sui settori della consulenza, della tecnologia e dell’edilizia/immobiliare, con ulteriori vittime nei settori sanitario, finanziario, manifatturiero, dei media e del marketing, dei trasporti e della logistica, dell’energia, dell’istruzione, della vendita al dettaglio, dell’ospitalità e dei viaggi e della pubblica amministrazione. Questi settori sono obiettivi appetibili perché scambiano regolarmente contratti, fatture e altri documenti transazionali, rendendo la condivisione di file e l’usurpazione di identità tramite firme elettroniche molto convincenti e con maggiori probabilità di successo.
Perché è importante
Si è già scritto di campagne di phishing simili negli anni passati, ma ciò che rende unico questo attacco è che mostra quanto sia facile per gli aggressori imitare servizi di condivisione di file affidabili per ingannare gli utenti, e sottolinea la necessità di una consapevolezza continua, soprattutto quando le e-mail contengono link cliccabili, dettagli sospetti sul mittente o contenuti insoliti nel corpo del messaggio.
Cosa dovrebbero fare le organizzazioni
Anche le organizzazioni e gli individui devono adottare misure proattive per ridurre il rischio. Alcuni modi per proteggersi includono:
- Approcciare sempre con cautela i link incorporati nelle e-mail, soprattutto quando sembrano inaspettati o urgenti.
- Prestare molta attenzione ai dettagli delle e-mail, come discrepanze tra il nome visualizzato e l’indirizzo effettivo del mittente, incongruenze nella formattazione, dimensioni dei caratteri insolite, loghi o immagini di bassa qualità e qualsiasi cosa che sembri fuori posto.
- Passare il mouse sui link prima di cliccarci sopra per verificare la destinazione reale e assicurarsi che corrisponda al servizio che presumibilmente ha inviato il messaggio.
- Aprire il servizio direttamente nel browser e cercare il documento direttamente, piuttosto che utilizzare i link forniti nelle e-mail.
- Istruire regolarmente i dipendenti e i team sulle tecniche di phishing emergenti, in modo che comprendano quali sono i modelli sospetti.
- Utilizzare soluzioni di sicurezza come il rilevamento delle minacce e-mail, i motori anti-phishing, il filtraggio degli URL e gli strumenti di segnalazione degli utenti per rafforzare la protezione complessiva.
La campagna di attacco descritta da Check Point ha sfruttato servizi di reindirizzamento URL legittimi per nascondere link dannosi, non una vulnerabilità di Mimecast. Gli aggressori hanno abusato di infrastrutture affidabili, tra cui il servizio di riscrittura URL di Mimecast, per mascherare la vera destinazione degli URL di phishing. Si tratta di una tattica comune in cui i criminali sfruttano qualsiasi dominio riconosciuto per eludere il rilevamento.
“I clienti Mimecast non sono suscettibili a questo tipo di attacco“, afferma un responsabile di Mimecast. “I motori di rilevamento di Mimecast identificano e bloccano questi attacchi. Le nostre funzionalità di scansione degli URL rilevano e bloccano automaticamente gli URL malevoli prima della consegna, dopodiché, il nostro servizio di riscrittura degli URL ispeziona i link al clic, fornendo un ulteriore livello di protezione che intercetta le minacce anche quando sono nascoste dietro catene di reindirizzamento legittime. Continuiamo a migliorare le nostre protezioni contro le tecniche di phishing in continua evoluzione. I clienti possono consultare la nostra analisi del 2024 su campagne simili al link https://www.mimecast.com/threat-intelligence-hub/phishing-campaigns-using-re-written-links/. Apprezziamo che Check Point abbia condiviso i propri risultati attraverso una divulgazione responsabile“.
L'articolo SharePoint e DocuSign come esca: il phishing che ha provato ad ingannare 6000 aziende proviene da Red Hot Cyber.
SigCore UC: An Open-Source Universal I/O Controller for the Raspberry Pi

Recently, [Edward Schmitz] wrote in to let us know about his Hackaday.io project: SigCore UC: An Open-Source Universal I/O Controller With Relays, Analog I/O, and Modbus for the Raspberry Pi.
In the video embedded below, [Edward] runs us through some of the features which he explains are a complete industrial control and data collection system. Features include Ethernet, WiFi, and Modbus TCP connectivity, regulated 5 V bus, eight relays, eight digital inputs, four analog inputs, and four analog outputs. All packaged in rugged housing and ready for installation/deployment.
[Edward] says he wanted something which went beyond development boards and expansion modules that provided a complete and ready-to-deploy solution. If you’re interested in the hardware, firmware, or software, everything is available on the project’s GitHub page. Beyond the Hackaday.io article, the GitHub repo, the YouTube explainer video, there is even an entire website devoted to the project: sigcoreuc.com. Our hats off to [Edward], he really put a lot of polish on this project.
If you’re interested in using the Raspberry Pi for input/output you might also like to read about Raspberry Pi Pico Makes For Expeditious Input Device and Smart Power Strip Revived With Raspberry Pi.
youtube.com/embed/jJMRukokuP8?…
An HO Model Power Bogie For Not A Lot

For people who build their own model trains there are a range of manufacturers from whom a power bogie containing the motor and drive can be sourced. But as [Le petit train du Berry] shows us in a video, it’s possible to make one yourself and it’s easier than you might think (French language video with truly awful YouTube auto-translation).
At the heart of the design is a coreless motor driving a worm gear at each end that engages with a gear on each axle. The wheelsets and power pickups are off-the-shelf items. The chassis meanwhile is 3D printed, and since this is an ongoing project we see two versions in the video. The V5 model adds a bearing, which its predecessor lacked.
The result is a pretty good power bogie, but it’s not without its faults. The gear ratio used is on the high side in order to save height under a model train body, and in the version without a bearing a hard-wearing filament is required because PLA will wear easily. We’re guessing this isn’t the last we’ll see of this project, so we hope those are addressed in future versions.
We like this project and we think you will too after you’ve watched the video below the break. For more home-made model railway power, how about a linear motor?
youtube.com/embed/X7C90o_rN9Q?…
High-Speed Pocket Hot Dog Cooker

Few of us complain that hot dogs take too long to cook, because we buy them from a stand. Still, if you do have to make your own dog, it can be a frustrating problem. To solve this issue, [Joel Creates] whipped up a solution to cook hot dogs nearly instantaneously. What’s more, it even fits in your pocket!
The idea behind this build is the same as the classic Presto hot dog cooker—pass electricity through a hot dog frank, and it’ll heat up just like any other resistive heating element. To achieve this, [Joel] hooked up a lithium-polymer pack to a 12-volt to 120-volt inverter. The 120-volt output was hooked up to a frank, but it didn’t really cook much. [Joel] then realized the problem—he needed bigger electrodes conducting electricity into the sausage. With 120 volts pumping through a couple of bolts jammed into either end of the frank, he had it cooked in two minutes flat.
All that was left to do was to get this concept working in a compact, portable package. What ensued was testing with a variety of boost converter circuits to take power from the batteries and stepping it up to a high enough voltage to cook with. That, and solving the issue of nasty chemical byproducts produced from passing electricity through the sausages themselves. Eventually, [Joel] comes up with a working prototype which can electrically cook a hot dog to the point of shooting out violent bursts of steam in under two minutes. You’d still have to be pretty brave to eat something that came out of this thing.
The biggest problem with hot dogs remains that the franks are sold in packs of four while buns are sold in packs of six. Nobody’s solved that problem yet, except for those hateful people who inexplicably have eleven friends. If you solve that one, don’t hesitate to notify the tipsline. Don’t forget, either, that the common hot dog can make for an excellent LED tester. Video after the break.
youtube.com/embed/0-OKW5CsKkU?…
Christmas Ornament Has Hidden Compartment, Clever Design

If you need something clever for a gift, consider this two-part 3D-printed Christmas ornament that has a small secret compartment. But there’s a catch: the print is a challenging one. So make sure your printer is up to the task before you begin (or just mash PRINT and find out).
This design is from [Angus] of [Maker’s Muse] and it’s not just eye-catching, but meticulously designed specifically for 3D printing. In fact, [Angus]’s video (embedded under the page break) is a great round-up of thoughtful design for manufacture (DFM) issues when it comes to filament-based 3D printing.
The ornament prints without supports, which is interesting right off the bat because rounded surfaces (like fillets, or a spherical surface) facing the build plate — even when slightly truncated to provide a flat bottom — are basically very sharp overhangs. That’s a feature that doesn’t generally end up with a good surface finish. [Angus] has a clever solution, and replaces a small section with a flat incline. One can’t tell anything is off by looking at the end result, but it makes all the difference when printing.
There are all kinds of little insights into the specific challenges 3D printing brings, and [Angus] does a fantastic job of highlighting them as he explains his design and addresses the challenges he faced. One spot in particular is the flat area underneath the hang hole. This triangular area is an unsupported bridge, and because of its particular shape, it is trickier to print than normal bridges. The workable solution consists of countersinking a smaller triangle within, but [Angus] is interested in improving this area further and is eager to hear ideas on how to do so. We wonder if he’s tried an approach we covered to get better bridges.
Want to print your own? 3D files are available direct from [Angus]’s site in a pay-what-you-like format. If your 3D printer is up to it, you should be able to make a few before Christmas. But if you’d prefer to set your sights on next year with something that uses power and hardware, this tiny marble machine ornament should raise some eyebrows.
youtube.com/embed/Oyy16lbpe_c?…
Calibrating a Printer with Computer Vision and Precise Timing

[Dennis] of [Made by Dennis] has been building a Voron 0 for fun and education, and since this apparently wasn’t enough of a challenge, decided to add a number of scratch-built improvements and modifications along the way. In his latest video on the journey, he rigorously calibrated the printer’s motion system, including translation distances, the perpendicularity of the axes, and the bed’s position. The goal was to get better than 100-micrometer precision over a 100 mm range, and reaching this required detours into computer vision, clock synchronization, and linear algebra.
To correct for non-perpendicular or distorted axes, [Dennis] calculated a position correction matrix using a camera mounted to the toolhead and a ChArUco board on the print bed. Image recognition software can easily detect the corners of the ChArUco board tiles and identify their positions, and if the camera’s focal length is known, some simple trigonometry gives the camera’s position. By taking pictures at many different points, [Dennis] could calculate a correction matrix which maps the printhead’s reported position to its actual position.
Leveling the bed also took surprisingly deep technical knowledge; [Dennis] was using a PZ probe to detect when the hotend contacted the bed in various places, and had made a wiper to remove interfering plastic from the nozzle, but wasn’t satisfied by the bed’s slight continued motion after making contact (this might have introduced as much as five micrometers of error). To correct for this, he had the microcontroller in the hotend record the time of contact and send this along with the hit signal to the Raspberry Pi controller, which keeps a record of times and positions, letting the true contact position be looked up. This required the hotend’s and the printer’s microcontrollers to have their clocks synchronized to within one microsecond, which the Pi managed using USB start-of-frame packets.
The final result was already looking quite professional, and should only get better once [Dennis] calibrates the extrusion settings. If you’re looking for more about ChArUco boards, we’ve covered them before, as well as calibration models. If you’re looking for high-precision bed leveling, you could also check out this Z sensor.
youtube.com/embed/8DvygwWloCc?…
Thanks to [marble] for the tip!
RansomHouse rilascia Mario! Il ransomware si evolve e diventa più pericoloso
Il gruppo dietro RansomHouse, uno dei più noti servizi di distribuzione di ransomware, ha rafforzato le capacità tecniche dei suoi attacchi. Secondo gli esperti, i criminali informatici hanno aggiunto al loro arsenale uno strumento di crittografia aggiornato, caratterizzato da un’architettura più complessa e funzionalità ampliate.
Le modifiche hanno interessato sia l’algoritmo di elaborazione dei file sia i metodi che ne complicano l’analisi successiva. RansomHouse è attivo dalla fine del 2021, inizialmente con fughe di dati e poi con l’uso attivo di ransomware negli attacchi.
Il servizio si è sviluppato rapidamente, incluso il rilascio dell’utility MrAgent per il blocco di massa degli hypervisor VMware ESXi. Uno degli incidenti più recenti noti ha riguardato l’uso di diverse varianti di ransomware contro la società di e-commerce giapponese Askul
Un recente rapporto dell’Unità 42 di Palo Alto Networks descrive una nuova variante del ransomware chiamata “Mario“. A differenza della versione precedente, che utilizzava un’elaborazione monofase, la modifica aggiornata utilizza un approccio a due fasi con due chiavi: una chiave primaria da 32 byte e una chiave secondaria da 8 byte.

Ciò aumenta significativamente la potenza della crittografia e complica i tentativi di recupero dei dati.
Un’ulteriore protezione è fornita da un meccanismo di elaborazione dei file riprogettato. Invece di uno schema lineare, viene utilizzata la suddivisione dinamica dei blocchi, con una soglia di 8 GB e crittografia parziale.

Le dimensioni e il metodo di elaborazione di ciascun file dipendono dalle sue dimensioni e vengono calcolati utilizzando complesse operazioni matematiche. Questo approccio complica l’analisi statica e rende il comportamento del crittografo meno prevedibile.
Anche la struttura di gestione della RAM è stata modificata: ora vengono utilizzati buffer separati per ogni fase di crittografia. Ciò aumenta la complessità del codice e riduce la probabilità di rilevamento durante l’analisi. Inoltre, la nuova versione fornisce informazioni più dettagliate durante l’elaborazione dei file, mentre in precedenza si limitava a un messaggio sul completamento dell’attività.
I file delle macchine virtuali, che ricevono l’estensione “.emario” dopo la crittografia, rimangono il bersaglio degli attacchi. In ogni directory interessata viene lasciato un messaggio con le istruzioni su come ripristinare l’accesso ai dati (ransom note).
Gli specialisti dell’Unità 42 sottolineano che questa evoluzione del ransomware RansomHouse è un segnale d’allarme. La maggiore complessità ostacola la decrittazione e complica notevolmente l’analisi dei campioni, suggerendo una strategia ben ponderata, focalizzata non sulla scala, ma sull’efficienza e sulla segretezza.
L'articolo RansomHouse rilascia Mario! Il ransomware si evolve e diventa più pericoloso proviene da Red Hot Cyber.
Ask Hackaday: What Goes Into A Legible Font, And Why Does It Matter?


There’s an interesting cultural observation to be made as a writer based in Europe, that we like our sans-serif fonts, while our American friends seem to prefer a font with a serif. It’s something that was particularly noticeable in the days of print advertising, and it becomes very obvious when looking at government documents.
We’ve brought together two 1980s patents from the respective sources to illustrate this, the American RSA encryption patent, and the British drive circuitry patent for the Sinclair flat screen CRT. The American one uses Times New Roman, while the British one uses a sans-serif font which we’re guessing may be Arial. The odd thing is in both cases they exude formality and authority to their respective audiences, but Americans see the sans-serif font as less formal and Europeans see the serif version as old-fashioned. If you thought Brits and Americans were divided by a common language, evidently it runs much deeper than that.
But What Makes Text Easier To Read?

We’re told that the use of fonts such as Arial or Calibri goes a little deeper than culture or style, in that these sans-serif fonts have greater readability for users with impaired vision or other conditions that impede visual comprehension. If you were wondering where the hack was in this article it’s here, because many of us will have made device interfaces that could have been more legible.
So it’s worth asking the question: just what makes a font legible? Is there more to it than the presence or absence of a serif? In answering that question we’re indebted to the Braille Institute of America for their Atkinson Hyperlegible font, and to Mencap in the Uk for their FS Me accessible font. It becomes clear that these fonts work by subtle design features intended to clearly differentiate letters. For example the uppercase “I”, lowercase letter “l”, and numeral “1” can be almost indistinguishable in some fonts: “Il1”, as can the zero and uppercase “O”, the lowercase letters “g”, and “q”, and even the uppercase “B” and the numeral “8”. The design features to differentiate these letters for accessibility don’t dominate the text and make a font many readers would consider “weird”.
Bitmap Fonts For The Unexpected Win

It’s all very well to look at scaleable fonts for high resolution work, but perhaps of more interest here are bitmap fonts. After all it’s these we’ll be sending to our little screens from our microcontrollers. It’s fair to say that attempts to produce smooth typefaces as bitmaps on machines such as the Amiga produced mixed results, but it’s interesting to look at the “classic” ROM bitmap fonts as found in microcomputers back in the day. After years of their just flowing past he eye it’s particularly so to examine them from an accessibility standpoint.
Machines such as the Sinclair Spectrum or Commodore 64 have evidently had some thought put into differentiating their characters. Their upper-case “Ii” has finials for example, and we’re likely to all be used to the zero with a line through it to differentiate it from the uppercase “O”. Perhaps of them all it’s the IBM PC’s code page 437 that does the job most elegantly, maybe we didn’t realise what we had back in the day.
So we understand that there are cultural preferences for particular design choices such as fonts, and for whatever reason these sometimes come ahead of technical considerations. But it’s been worth a quick look at accessible typography, and who knows, perhaps we can make our projects easier to use as a result. What fonts do you use when legibility matters?
Header: Linotype machines: AE Foster, Public domain.
The Music of the Sea

For how crucial whales have been for humanity, from their harvest for meat and oil to their future use of saving the world from a space probe, humans knew very little about them until surprisingly recently. Most people, even in Herman Melville’s time, considered whales to be fish, and it wasn’t until humans went looking for submarines in the mid-1900s that we started to understand the complexities of their songs. And you don’t have to be a submarine pilot to listen now, either; all you need is something like these homemade hydraphones.
This project was done as part of a workshop in Indonesia, and it only takes a few hours to build. It’s based on a piezo microphone enclosed in a small case. A standard 3.5 mm audio cable runs into the enclosure and powers a preamp using a transistor and two resistors. With the piezo microphone and amplifier installed in this case, the case itself is waterproofed with a spray and allowed to dry. When doing this build in places where Plasti-Dip is available, it was found to be a more reliable and faster waterproofing method. Either way, with the waterproofing layer finished, it’s ready to toss into a body of water to listen for various sounds.
Some further instructions beyond construction demonstrate how to use these to capture stereo sounds, using two microphones connected to a stereo jack. The creators also took a setup connected to a Raspberry Pi offshore to a floating dock and installed a set permanently, streaming live audio wirelessly back to the mainland for easy listening, review, and analysis. There are other ways of interacting with the ocean using sound as well, like this project, which looks to open-source a sonar system.
Thanks to [deathbots] for the tip!
Internet-Connected Consoles Are Retro Now, And That Means Problems

A long time ago, there was a big difference between PC and console gaming. The former often came with headaches. You’d fight with drivers, struggle with crashes, and grow ever more frustrated dealing with CD piracy checks and endless patches and updates. Meanwhile, consoles offered the exact opposite experience—just slam in a cartridge, and go!
That beautiful feature fell away when consoles joined the Internet. Suddenly there were servers to sign in to and updates to download and a whole bunch of hoops to jump through before you even got to play a game. Now, those early generations of Internet-connected consoles are becoming retro, and that’s introduced a whole new set of problems now the infrastructure is dying or dead. Boot up and play? You must be joking!
Turn 360 Degrees And Log Out

Microsoft first launched the Xbox 360 in 2005. It was the American company’s second major console, following on from the success of the Xbox that fought so valiantly against the Sony PlayStation 2 and the Nintendo GameCube. Where those sixth generation consoles had been the first to really lean in to online gaming, it was the seventh generation that would make it a core part of the console experience.
The Xbox 360 liked to sign you straight into Xbox Live the moment you switched on the console. All your friends would get hear a little bling as they were notified that you’d come online, and you’d get the same in turn. You could then boot into the game of your choice, where you’d likely sign into a specific third-party server to check for updates and handle any online matchmaking.
The Xbox 360 didn’t need to be always online, it just really wanted you to be. This was simply how gaming was to be now. Networked and now highly visible, in a semi-public way. Where Microsoft blazed a trail in the online user experience for the console market, Sony soon followed with its own feature-equivalent offering, albeit one that was never quite as elegant as that which it aimed to duplicate.
Fire up an Xbox 360 today, and you’ll see that console acting like it’s still 2008 or something. It will pleasantly reach out to Microsoft servers, and it will even get a reply—and it will then prompt you to log in with your Xbox Live or Microsoft account. You’ve probably got one—many of us do—but here lies a weird problem. When you try to log in to an Xbox 360 with your current Microsoft account, you will almost certainly fail! You might get an error like 8015D086 or 8015D000, or have it fail more quietly with a simple timeout.
It all comes down to authentication. See, the Internet was a much happier, friendly place when the Xbox 360 first hit the shelves. Back then, a simple password of 8 characters or more with maybe a numeral or two was considered pretty darn good for login purposes. Not like today, where you need to up the complexity significantly and throw in two-factor authentication to boot. And therein lies the problem, because the Xbox 360 was never expecting two-factor authentication to be a thing.
Today, your Microsoft account won’t be authorized for login without it, and thus your Xbox 360 won’t be able to log in to Xbox Live. In fairness, you wouldn’t miss much. All the online stores and marketplaces and games servers were killed ages ago, after all. However, the 360 really doesn’t like not being online. It will ask you all the time if you want to sign in! Plus, if you wanted to get your machine the very last dashboard updates or anything like that… you need to be able to sign into Xbox Live.
Thankfully, there is a workaround. Community members have found various solutions, most easily found in posts shared on Reddit. Sometimes you can get by simply by disabling two-factor authentication and changing to a low-complexity password due to the 360’s character limit in the entry field. If that doesn’t work, though, you have to go to the effort to set up a special “App Password” in your Microsoft account that will let the Xbox 360 authenticate in a simpler, more direct fashion.
Pull all this off, and you’ll hear that famous chime as your home console reaches the promised land of Xbox Live. None of your friends will be online, and nobody’s really checking your Gamerscore anymore, but now you can finally play some games!
Only, for a great many titles on the Xbox 360, there were dedicated online servers, too. Pop in FIFA 16, and the game will stall for a moment before it reports that it’s failed to connect to EA’s servers. Back in the day, those servers provided a continual stream of minor updates to the game, player rosters, and stats, making it feel like almost a living thing. Today, there’s nothing out there but a request that always times out.
This would be no issue if it happened just once, but alas… you’ll have to tangle with the game doing this time and again, every time you boot it up. It wants that server, it’s so sure it’s out there… but it never phones back from the aether.
Many games still retain most of their playability without an Internet connection, and most consoles will still boot up without one. Nevertheless, the more these machines are built to rely on an ever-present link to the cloud, the less of them will be accessible many years into the future.
Not Unique

This problem is not unique to the Xbox 360. It’s common to run into similar problems with the PlayStation 3, with Sony providing a workaround to get the old consoles online. For both consoles, you’re still relying on the servers remaining online. It’s fair to assume the little remaining support for these machines will be switched off too, in time. Meanwhile, if you’re playing Pokemon Diamond on the Nintendo DS, you’ve probably noticed the servers are completely gone. In that case, you’re left to rely on community efforts to emulate the original Nintendo WFC servers, which run with varying levels of success. For less popular games, though there’s simply nothing left—whatever online service there was is gone, and it’s not coming back.
These problems will come for each following console generation in turn. Any game and any console that relies on manufacturer-run infrastructure will eventually shut down when it becomes no longer profitable or worthwhile to run. It’s a great pity, to be sure. The best we can do is to pressure manufacturers to make sure that their hardware and games retain as much capability as possible when a connection isn’t available. That will at least leave us with something to play when the servers do finally go dark.
Phishing NoiPA: analisi tecnica di una truffa che sfrutta aumenti e arretrati
“Salve.”
Non “Gentile”, non “Spettabile”, non nome e cognome.
Solo “Salve.”
A leggerla così, fa quasi tenerezza.
Sembra l’inizio di una mail scritta di corsa, magari riciclata da un modello vecchio, senza nemmeno lo sforzo di una personalizzazione. C’è il logo giusto, c’è un titolo burocratico abbastanza vago, c’è quel tono da comunicazione di sistema che abbiamo imparato a riconoscere – e a ignorare.
E infatti il primo istinto, per chi è un minimo smaliziato, è questo: “Ma dai.”
Ed è proprio qui che conviene fermarsi.

Perché se viene da ridere, se si giudica per quanto è scritta male, si sta facendo esattamente quello che questa email si aspetta.
Una mail di phishing non deve essere elegante né credibile al cento per cento.
Spesso deve essere solo sufficientemente compatibile con ciò che ci si aspetta di ricevere in quel momento.
Da qui in poi, non ha più senso parlare di stile.
Ha senso parlare di funzione.

Una truffa vecchia che sfrutta un contesto nuovo
Questa non è una truffa nuova. È uno schema già visto, che continua a funzionare perché viene riattivato nel momento giusto.
Negli ultimi mesi, complice il tema degli aumenti e degli arretrati NoiPA, è tornata a circolare questa campagna di phishing che ripropone modelli noti, con variazioni minime nel lessico e nei riferimenti temporali. Non introduce tecniche innovative né soluzioni sofisticate: sfrutta un’aspettativa reale, quella di ricevere una comunicazione ufficiale legata a eventi economici concreti e ampiamente discussi.
Il punto di forza dell’attacco è tutto qui.
L’aggancio a elementi reali e verificabili – aumenti, arretrati, emissioni straordinarie – elimina la necessità di costruire una narrazione articolata. Il destinatario non deve chiedersi se quella comunicazione possa esistere, ma solo se sia arrivata nel modo corretto.
Per questo l’interesse del caso non sta nella truffa in sé, che è nota e ciclica, ma nella sua sincronizzazione con il contesto. È una dinamica ricorrente: ogni volta che un evento reale rende plausibile l’azione richiesta, lo schema torna a funzionare.
Ed è su questa dinamica, più che sulla singola campagna, che vale la pena soffermarsi.

Il metodo: analisi di un testo di phishing
Un’email di phishing va letta come una sequenza di obiettivi operativi, non come un messaggio informativo.
Gli obiettivi sono sempre gli stessi:
- farsi aprire
- non generare sospetto immediato
- spingere l’utente verso un’azione esterna
Se questa sequenza è coerente, il phishing molto spesso funziona anche quando il testo è mediocre.
Con questo schema in mente, il messaggio diventa leggibile per quello che è.
Dissezione tecnica del messaggio: cosa fa ogni elemento e perché funziona
Un’email di phishing non racconta una storia.
Implementa una sequenza di azioni progettate per guidare il comportamento dell’utente con il minimo attrito possibile.
Apertura e saluto: scalabilità prima di tutto
Il messaggio si apre con un semplice “Salve”.
Nessun nome, nessun cognome, nessuna personalizzazione.
Non è una svista. È una scelta funzionale alla scalabilità dell’attacco. Inserire dati anagrafici richiede liste affidabili, aggiornate e coerenti. Ometterli consente l’invio massivo senza ridurre in modo significativo il tasso di apertura. L’obiettivo non è colpire tutti, ma colpire abbastanza.
Allo stesso tempo, l’assenza di riferimenti personali colloca l’email nel perimetro delle comunicazioni automatiche: non sembra una mail individuale, ma una mail “di sistema”. Questo normalizza l’anomalia.
Oggetto e apertura: abbassare la soglia di attenzione
Oggetto e prime righe utilizzano formule vaghe e amministrative, come “integrazione dati personali”.
Non forniscono informazioni concrete, non promettono nulla, ma sono compatibili con messaggi di servizio reali.
La loro funzione è semplice: farsi aprire senza attivare allarmi immediati.
Registro linguistico: personalizzazione apparente a costo zero
Nel corpo del messaggio compare l’uso ripetuto del pronome “tua”:
“la tua area riservata”, “la tua posizione”.
Non è informazione. È simulazione di personalizzazione.
Questo registro non appartiene alle comunicazioni ufficiali di NoiPA, normalmente impersonali e normative. Serve a creare l’illusione di un riferimento diretto senza introdurre elementi verificabili che potrebbero essere controllati o smentiti.
È una scorciatoia tipica del phishing bancario e previdenziale.
Link e azione richiesta: spostare il contesto
Il cuore dell’attacco è l’invito ad accedere all’area riservata tramite un link presente nell’email.
Questo passaggio risolve il problema centrale dell’attaccante: portare l’utente fuori dal canale email. Finché l’utente resta nel client di posta ha tempo, contesto e strumenti per verificare. Il link serve a trasferirlo rapidamente su un dominio controllato dall’attaccante, dove interfaccia, linguaggio e richieste sono completamente manipolabili.
Dal punto di vista procedurale, questo è il punto di rottura oggettivo: NoiPA non richiede accessi ai propri servizi tramite link email né aggiornamenti di dati personali con questa modalità.
Call to action: riutilizzabilità e attrito minimo
Il pulsante “Modifica i tuoi dati” è volutamente generico.
Non contiene riferimenti amministrativi, numeri di pratica o identificativi utente.
La sua genericità lo rende riutilizzabile su più campagne, più brand, più contesti. Specificare quali dati o quale procedura introdurrebbe attrito e aumenterebbe le possibilità di incoerenza. L’obiettivo non è spiegare, ma ottenere un click.
Urgenza: comprimere il tempo di verifica
L’urgenza viene introdotta solo nella parte finale del messaggio.
Il link ha una validità limitata e il mancato intervento potrebbe compromettere l’aggiornamento della busta paga con gli aumenti previsti.
Non serve a spaventare subito, ma a ridurre il tempo di verifica quando il messaggio è già apparso coerente. Inserirla all’inizio attiverebbe sospetti; inserirla alla fine forza una decisione rapida quando l’utente è già coinvolto.
Contesto reale: plausibilità senza spiegazioni
Il riferimento agli aumenti e agli arretrati risolve il problema della plausibilità contestuale.
Usare un evento reale elimina la necessità di costruire una narrativa artificiale. Il motivo della comunicazione è già noto.
Questo abbassa drasticamente la soglia critica.
Firma: autorità senza verificabilità
La firma “Il Team NoiPA” chiude il messaggio senza fornire alcun elemento verificabile.
Nessun nome, nessun ufficio, nessun riferimento normativo o contatto ufficiale.
È un’autorità astratta, sufficiente nel breve intervallo che precede il click. Inserire dettagli renderebbe possibile una verifica immediata, cosa che l’attaccante deve evitare.
Conclusione
Questa campagna non si regge su tecniche avanzate né su un’elaborazione particolarmente sofisticata del messaggio. Si regge su qualcosa di molto più semplice: l’allineamento temporale. Uno schema noto viene riattivato quando l’argomento è reale, atteso e già presente nel flusso informativo quotidiano.
In questo scenario, la qualità del testo diventa quasi irrilevante. La familiarità del tema abbassa le difese, riduce il tempo di verifica e sposta l’attenzione dal come al perché. È sufficiente che il messaggio sembri plausibile nel momento giusto.
Ed è proprio per questo che un’email che all’inizio “fa sorridere” continua ancora oggi a colpire.
L'articolo Phishing NoiPA: analisi tecnica di una truffa che sfrutta aumenti e arretrati proviene da Red Hot Cyber.
DK 10x16 - Buon Natale
Una buona notizia per chiudere l'anno. Festeggiate, riposate, che nel 2026 avremo bisogno di rabbia nuova.
spreaker.com/episode/dk-10x16-…
How To Build Good Contact Mics

We’re most familiar with sound as vibrations that travel through the atmosphere around us. However, sound can also travel through objects, too! If you want to pick it up, you’d do well to start with a contact mic. Thankfully, [The Sound of Machines] has a great primer on how to build one yourself. Check out the video below.
The key to the contact mic is the piezo disc. It’s an element that leverages the piezoelectric effect, converting physical vibration directly into an electrical signal. You can get them in various sizes; smaller ones fit into tight spaces, while larger ones perform better across a wider frequency range.
[The Sound of Machines] explains how to take these simple piezo discs and solder them up with connectors and shielded wire to make them into practical microphones you can use in the field. The video goes down to the bare basics, so even if you’re totally new to electronics, you should be able to follow along. It also covers how to switch up the design to use two piezo discs to deliver a balanced signal over an XLR connector, which can significantly reduce noise.
There’s even a quick exploration of creative techniques, such as building contact mics with things like bendable arms or suction cups to make them easier to mount wherever you need them. A follow-up explores the benefits of active amplification. The demos in the video are great, too. We hear the sound of contact mics immersed in boiling water, pressed up against cracking spaghetti, and even dunked in a pool. It’s all top stuff.
These contact mics are great for all kinds of stuff, from recording foley sounds to building reverb machines out of trash cans and lamps.
youtube.com/embed/JrN4HSJadNM?…
youtube.com/embed/Di3zThxTnnw?…
What I learned about tech policy in 2025
IT'S MONDAY, AND THIS IS DIGITAL POLITICS. I'm Mark Scott, and I hope you, like me, are getting ready for Festivus on Dec 23. (Remember: it's for the rest of us.) My household already has its Festivus pole up, and is preparing for both feats of strength and the annual airing of grievances.

In all seriousness, thank you for all the support this year. I hope you and yours can find time to rest and recover over the final weeks of the year.
One programming note: the first Digital Politics newsletter of 2026 will be on Jan 5, so no edition next week. Happy Holidays.
Let's get started:
MS13-089: il nuovo gruppo ransomware che ruba il nome a un vecchio bollettino Microsoft
MS13-089 apre un leak site sul dark web, espone i primi dati e adotta una strategia di doppia estorsione senza cifratura.
Un brand costruito su un vecchio ID Microsoft
Per anni “MS13-089” ha identificato un bollettino di sicurezza Microsoft del 2013 relativo a una vulnerabilità critica nel componente grafico GDI di Windows, sfruttabile per esecuzione di codice remoto. Oggi la stessa sigla viene riciclata come nome di un nuovo gruppo ransomware MS13-089.
Questa scelta non è solo un vezzo: riutilizzare un identificatore storico del mondo Microsoft introduce rumore nelle ricerche OSINT e sposta l’attenzione dall’immaginario “gang di strada” a quello “vulnerabilità software”. In pratica il gruppo si colloca subito nel perimetro cyber, sfruttando una sigla che gli analisti associano da anni a un problema di sicurezza ben documentato.

Il leak site: un messaggio chiaro
Lo screenshot, rilanciato da diversi siti e canali social del clearnet del leak site, mostra un’impostazione essenziale: in alto il nome MS13-089, al centro la sezione “LEAKED DATA” e subito sotto due card affiancate dedicate alle prime vittime. Ogni riquadro riporta logo, dominio, breve descrizione ufficiale estratta dal sito della vittima e una barra con la dicitura “PUBLISHED 1%”, insieme al pulsante “MORE”.
Questa struttura ricalca il modello ormai standard dei leak site di doppia estorsione: brand della gang in evidenza, elenco delle organizzazioni colpite con una scheda sintetica e un chiaro invito – il tasto “MORE” – a esplorare i campioni di dati pubblicati come prova dell’intrusione.
La barra “PUBLISHED 1%” che compare sotto ciascuna vittima non è una trovata grafica, ma un indicatore del livello di esposizione pubblica dei dati. Nel gergo dei leak site ransomware, questa etichetta segnala che solo circa l’1% dei dati sottratti è stato reso pubblico, mentre il restante 99% è ancora trattenuto dal gruppo come leva nella negoziazione con la vittima.
Doppia estorsione senza cifratura: la narrativa “non danneggiamo i pazienti”
Uno degli aspetti più peculiari di MS13-089 è la scelta dichiarata di non cifrare i sistemi delle vittime, concentrandosi esclusivamente su furto e minaccia di leak dei dati. In comunicazioni riportate da siti di monitoraggio delle violazioni, il gruppo sostiene di non aver cifrato gli asset di Virginia Urology “per non danneggiare i pazienti”, rivendicando una strategia basata unicamente sulla doppia estorsione.
Questa narrativa – già vista in altri contesti in cui gli attori cercano di presentarsi come “professionisti” più che come vandali – non cambia però la sostanza: l’esfiltrazione di cartelle cliniche, dati assicurativi e documentazione fiscale rimane un danno grave, con potenziali ricadute per milioni di persone e importanti conseguenze regolatorie (HIPAA nel contesto USA, GDPR in Europa). La leva non è più la paralisi operativa tramite cifratura, ma la minaccia di una esposizione pubblica irreversibile.
Impatti
Il debutto di MS13-089 conferma tendenze chiave del panorama ransomware:
- La doppia estorsione evolve oltre la cifratura: gruppi come MS13-089 mostrano che, in molti scenari, la sola minaccia di leak può bastare a innescare crisi reputazionali, legali e regolatorie di ampia portata, anche senza bloccare direttamente i sistemi.
- I leak site diventano asset di comunicazione centrale: elementi come la barra “PUBLISHED 1%” sono pensati non solo per informare gli analisti, ma per costruire una narrativa pubblica e temporizzata della pressione sul bersaglio.
Per i defender questo significa integrare nei playbook di risposta non solo scenari di cifratura massiva, ma anche casi in cui l’intero impatto è giocato sulla fuga di dati: monitoraggio costante dei leak site, capacità di reagire rapidamente alle pubblicazioni parziali e piani di comunicazione e notifica pensati per gestire la progressione da “1% pubblicato” alla minaccia di esposizione totale.
L'articolo MS13-089: il nuovo gruppo ransomware che ruba il nome a un vecchio bollettino Microsoft proviene da Red Hot Cyber.
Lichtenberg Lightning in a Bottle, Thanks To The Magic of Particle Accelerators

You’ve probably seen Lichtenberg figures before, those lightning-like traces left by high-voltage discharge. The safe way to create them is using an electron beam to embed charge inside an acrylic block, and then shake them loose with a short, sharp tap. The usual technique makes for a great, flat splay of “lightning” that looks great in a rectangular prism or cube on your desk. [Electron Impressions] was getting bored with that, though, and wanted to do something unique — they wanted to capture lightning in a bottle, with a cylindrical-shaped Lichtenberg figure. The result is in the video below.
They’re still using the kill-you-in-milliseconds linear accelerator that makes for such lovely flat figures, but they need to rotate the cylinder to uniformly deposit charge around its axis. That sounds easy, but remember this is a high-energy electron beam that’s not going to play nice with any electrical components that are put through to drive the spinning.
Ultimately, he goes old-school: a lead-acid battery and a brushed DC motor. Apparently, more power-dense batteries have trouble with the radiation. Though the 3D-printed roller assembly is perhaps not that old-school, it’s neat to know that PETG is resilient to beta ray exposure. Getting footage from inside the linear accelerator with a shielded GoPro is just a bonus. (Jump to five minutes in to see it go into the beam chamber.)
The whole process is very similar to one we featured long ago to put Lichtenberg figures into acrylic spheres (the linked post is dead, but the video survives). If you don’t have access to a powerful electron beam, you can still make Lichtenberg figures the old-fashioned way with a microwave sign transformer, but that’s very much an “at your own risk” project, considering it’s the deadliest hack on the internet.
youtube.com/embed/8a3GfozsU0s?…
Account Microsoft 365 violati senza password: ecco il nuovo incubo OAuth
I criminali informatici stanno diventando sempre più furbi e hanno trovato un nuovo modo per sfruttare i protocolli di sicurezza aziendali. Sembra incredibile, ma è vero: stanno usando una funzionalità di autenticazione Microsoft legittima per rubare gli account utente.
Il team di ricerca di Proofpoint ha rilevato un aumento del “Device Code Phishing”, una tecnica di phishing che convince le vittime a concedere il controllo completo dei propri account semplicemente inserendo un codice su un sito web attendibile. È come se i malintenzionati avessero trovato un modo per trasformare i protocolli di sicurezza in una debolezza. Ma come funziona esattamente questa tecnica? E cosa possono fare le aziende per proteggersi? Scopriamolo!
Quando OAuth diventa il bersaglio: il dirottamento del flusso di autorizzazione
“La tradizionale consapevolezza del phishing spesso enfatizza la verifica della legittimità degli URL. Questo approccio non affronta efficacemente il phishing tramite codice dispositivo, in cui agli utenti viene chiesto di inserire un codice dispositivo sul portale Microsoft attendibile”, hanno riportato gli esperti nel loro rapporto.
La campagna evidenzia un cambiamento di tattica: invece di rubare direttamente le password, gli hacker rubano le “chiavi” dell’account stesso tramite il protocollo OAuth 2.0. L’attacco sfrutta il flusso di autorizzazione del dispositivo, una funzionalità progettata per aiutare gli utenti ad accedere a dispositivi con capacità di input limitate, come smart TV o stampanti. Quando il dispositivo è legittimo, visualizza un codice e l’utente lo inserisce su un computer o telefono separato per autorizzare l’accesso.

Gli aggressori hanno dirottato questo processo. Inviano email di phishing contenenti un codice e un link al portale di accesso ufficiale di Microsoft (microsoft.com/devicelogin). Poiché l’URL è legittimo, la formazione standard sul phishing spesso fallisce. Questa non è una tecnica isolata utilizzata da un singolo gruppo. I ricercatori di Proofpoint hanno osservato “molteplici cluster di minacce, sia di matrice statale che motivate da interessi finanziari”, che adottano questo metodo.
Una volta che l’utente inserisce il codice, all’applicazione dannosa dell’aggressore viene concesso un token che consente l’accesso persistente all’account Microsoft 365 della vittima. Questo accesso può essere utilizzato per “esfiltrare dati e altro ancora”, spesso aggirando la necessità di conoscere la password dell’utente nelle sessioni future.
L’attacco Account Takeover (ATO).
L’Account Takeover (ATO) è una tecnica di attacco informatico in cui un criminale ottiene il controllo completo di un account legittimo, impersonando l’utente reale senza destare sospetti immediati. A differenza delle violazioni tradizionali, l’ATO non richiede necessariamente il furto della password: gli attaccanti possono sfruttare token di autenticazione, flussi OAuth o meccanismi di accesso legittimi per entrare nell’account in modo del tutto valido dal punto di vista tecnico. Questo rende l’attacco particolarmente insidioso, perché i sistemi di sicurezza registrano l’accesso come regolare.
Una volta compromesso l’account, l’attaccante può leggere email, accedere a documenti riservati, creare regole di inoltro invisibili, avviare frodi interne o mantenere un accesso persistente nel tempo, anche dopo il cambio della password. L’Account Takeover è oggi una delle minacce più pericolose per le organizzazioni, perché sfrutta la fiducia riposta nei meccanismi di autenticazione moderni e nella stessa identità digitale dell’utente, trasformando un accesso legittimo in un vettore di compromissione.
La componente psicologica negli attacchi OAuth-based è sempre la base
La chiave del successo di questi attacchi risiede nella manipolazione della psicologia degli utenti. Un senso di urgenza viene creato dalle esche, che spesso mimano avvisi di sicurezza o richieste amministrative. Gli aggressori, rappresentando l’attacco come un controllo obbligatorio o un aggiornamento di sicurezza, inducono gli utenti a compiere l’azione che li rende vulnerabili.
Mentre le organizzazioni rafforzano le loro difese con l’autenticazione a più fattori (MFA) e le chiavi FIDO, gli aggressori sono costretti a trovare soluzioni alternative. L’abuso di flussi di autorizzazione validi sembra essere la prossima frontiera. “Proofpoint stima che l’abuso dei flussi di autenticazione OAuth continuerà a crescere con l’adozione di controlli MFA conformi a FIDO”, hanno concluso i ricercatori.
Come difendersi dal Device Code Phishing
La difesa da questo tipo di attacco richiede un cambio di paradigma: non basta più insegnare agli utenti a controllare l’URL. Il Device Code Phishing sfrutta portali legittimi e flussi di autenticazione validi, rendendo inefficace la formazione basata esclusivamente sul riconoscimento di siti falsi. È quindi fondamentale affiancare alla consapevolezza dell’utente controlli tecnici mirati sui flussi OAuth.
Dal punto di vista operativo, le organizzazioni dovrebbero limitare o disabilitare il Device Code Flow ove non strettamente necessario e applicare policy di Conditional Access più restrittive, includendo MFA anche per i flussi OAuth e non solo per il login interattivo. Il controllo del contesto di accesso (posizione, dispositivo, rischio della sessione) diventa cruciale per intercettare utilizzi anomali di token apparentemente legittimi.
Infine, è essenziale monitorare e governare le applicazioni OAuth autorizzate nel tenant. L’uso di app non verificate o con privilegi eccessivi rappresenta un vettore di compromissione spesso sottovalutato. La revisione periodica dei consensi, il principio del minimo privilegio e il monitoraggio dei log di autenticazione legati al Device Code Flow possono fare la differenza nel rilevare e contenere un Account Takeover prima che l’accesso diventi persistente.
L'articolo Account Microsoft 365 violati senza password: ecco il nuovo incubo OAuth proviene da Red Hot Cyber.
Origami on another Level with 3D Printing

Origami has become known as a miracle technique for designers. Elegant compliant mechanisms can leverage the material properties of a single geometry in ways that are sometimes stronger than those of more complicated designs. However, we don’t generally see origami used directly in 3D printed parts. [matthew lim] decided to explore this uncharted realm with various clever designs. You can check out the video below.

First, [matthew] converts some basic folds into thin 3D printed sheets with thinner portions on crease lines. This allows the plastic to be stiff along flat portions and flexible in bends. Unfortunately, this becomes more difficult with more complicated designs. Crease lines become weak and overstrained to the point of failure, requiring an adjusted method.
With a bit of digging, [matthew] finds some prior work mentioning folds on alternative sides of the panels. Using offset panels allows for complex folds with improved traits, allowing for even thicker panels. [matthew] also experimented with more compliant mechanism-focused prints, twisting cylinders that contract.
This type of 3D printing is always fascinating, as it pushes the limits of what you think is possible with 3D printing alone. If you want more mind-bending 3D printing goodness, check out this mechanism that contracts when you try pulling it apart!
youtube.com/embed/FNVBK7-h9Fs?…
The Unusual Pi Boot Process Explained

If you’ve ever experimented with a microprocessor at the bare metal level, you’ll know that when it starts up, it will look at its program memory for something to do. On an old 8-bit machine, that program memory was usually an EPROM at the start of its address space, while on a PC, it would be the BIOS or UEFI firmware. This takes care of initialising the environment in both hardware and software, and then loading the program, OS, or whatever the processor does. The Raspberry Pi, though, isn’t like that, and [Patrick McCanna] is here to tell us why.
The Pi eschews bringing up its ARM core first. Instead, it has a GPU firmware that brings up the GPU. It’s this part of the chip that then initialises all peripherals and memory. Only then does it activate the ARM part of the chip. As he explains, this is because the original Pi chip, the BCM2835, is a set-top-box chip. It’s not an application processor at all, but a late-2000s GPU that happened to have an ARM core on a small part of its die, so the GPU wakes first, not the CPU. Even though the latest versions of the Pi have much more powerful Broadcom chips, this legacy of their ancestor remains. For most of us using the board it doesn’t matter much, but it’s interesting to know.
Fancy trying bare metal Pi programming? Give it a go. We’ve seen some practical projects that start at that level.
Hackaday Links: December 21, 2025

It’s amazing how fragile our digital lives can be, and how quickly they can fall to pieces. Case in point: the digital dilemma that Paris Buttfield-Addison found himself in last week, which denied him access to 20 years of photographs, messages, documents, and general access to the Apple ecosystem. According to Paris, the whole thing started when he tried to redeem a $500 Apple gift card in exchange for 6 TB of iCloud storage. The gift card purchase didn’t go through, and shortly thereafter, the account was locked, effectively bricking his $30,000 collection of iGadgets and rendering his massive trove of iCloud data inaccessible. Decades of loyalty to the Apple ecosystem, gone in a heartbeat.
As for why the account was locked, it appears that the gift card Paris used had been redeemed previously — some kind of gift card fraud, perhaps. But Paris only learned that after the issue was resolved. Before that, he relates five days of digital limbo and customer support hell, which included unhelpful advice such as creating a new account and starting over from scratch, which probably would have led to exactly the same place, thanks to hardware linking of all his devices to the nuked account. The story ends well, perhaps partly due to the victim’s high profile in the Apple community, but it’s a stark lesson in owning your digital data. If they’re not your computer, they’re not your files, and if someone like Paris can get caught up in a digital disaster like this, it can happen to anyone.
Hackaday isn’t the place readers normally turn to for fiction, but we wanted to call attention to a piece of short fiction with a Hackaday angle. Back in June, Canadian writer Kassandra Haakman contacted us about a short story she wrote focused on the 1989 geomagnetic storm that temporarily wiped out the electric grid in Québec. She wanted permission to quote our first-hand description of that night’s aurorae, which we wrote a bit about on these pages. We happily granted permission for the quote, on condition that she share a link to the article once it’s published. The story is out now; it’s a series of vignettes from that night, mostly looking at the disorientation of waking up to no electricity but a sky alive with light and energy. Check it out — we really enjoyed it.
Speaking of solar outbursts, did 6,000 Airbus airliners really get grounded because of solar storms? We remember feeling a bit skeptical when this story first hit the media, but without diving into it at the time, cosmic rays interfering with avionics seemed as good an explanation as anything. But now an article in Astronomy.com goes into much more detail about this Emergency Airworthiness Directive and exactly what happened to force aviation authorities to ground an entire fleet of planes. The article speaks for itself, but to summarize, it appears that the EAD was precipitated by an “uncommanded and limited pitch down” event on a JetBlue flight on October 10 that injured several passengers. The post-incident analysis revealed that the computer controlling the jet’s elevators and ailerons may have suffered a cosmic-ray-induced “bit flip,” temporarily scrambling the system and resulting in uncommanded movement of the control surfaces. The article goes into quite some detail about the event and the implications of increased solar activity for critical infrastructure.
And finally, if you’ve been paying attention to automotive news lately, it’s been kind of hard to miss the brewing public relations nightmare Toyota is facing over the rash of engine failures affecting late-model Tundra pickups. The 3.4-liter V6 twin-turbo engine that Toyota chose to replace the venerable but thirsty 5.7-liter V8 that used to power the truck is prone to sudden death, even with very few miles on the odometer. Toyota has been very cagey about what exactly is going wrong with these engines, but Eric over at “I Do Cars” on YouTube managed to get his hands on an engine that gave up the ghost after a mere 38,000 miles, and the resulting teardown is very interesting. Getting to the bottom of the problem required a complete teardown of the engine, top to bottom, so all the engineering behind this power plant is on display. Everything looked good until the very end; we won’t ruin the surprise, but suffice it to say, it’s pretty gnarly. Enjoy!
youtube.com/embed/vL4tIHf_9i8?…
Pause Print, Add Hardware, and Enjoy Strength

3D Printing is great, but it is pretty much the worst way to make any given part– except that every other technique you could use to make that part is too slow and/or expensive, making the 3D print the best option. If only the prints were stiffer, stronger, more durable! [JanTech Engineering] feels your plight and has been hacking away with the M601 command to try embedding different sorts of hardware into his prints for up to 10x greater strength, as seen in the video embedded below.
It’s kind of a no-brainer, isn’t it? If the plastic is the weak point, maybe we could reinforce the plastic. Most concrete you see these days has rebar in it, and fiber-reinforced plastic is the only way most people will use resin for structural applications. So, how about FDM? Our printers have that handy M601 “pause print” command built in. By creatively building voids into your parts that you can add stronger materials, you get the best of all possible worlds: the exact 3D printed shape you wanted, plus the stiffness of, say, a pulltruded carbon-fiber rod.
[JanTech] examines several possible inserts, including the aforementioned carbon rods. He takes a second look at urethane foam, which we recently examined, and compares it with less-crushable sand, which might be a good choice when strength-to-weight isn’t an issue. He doesn’t try concrete mix, but we’ve seen that before, too. Various metal shapes are suggested — there are all sorts of brackets and bolts and baubles that can fit into your prints depending on their size — but the carbon rods do come out ahead on strength-to-weight, to nobody’s surprise.
You could do a forged carbon part with a printed mold to get that carbon stiffness, sure, but that’s more work, and you’ve got to handle epoxy resins that some of us have become sensitized to. Carbon rods and tubes are cheap and safer to work with, though be careful cutting them.
Finally, he tries machining custom metal insets with his CNC machine. It’s an interesting technique that’s hugely customizable, but it does require you to have a decent CNC available, and, at that point, you might want to just machine the part. Still, it’s an interesting hybrid technique we haven’t seen before.
Shoving stuff into 3D-printed plastic to make it a better composite object is a great idea and a time-honored tradition. What do you put into your prints? We’d love to know, and so would [Jan]. Leave a comment and let us know.
youtube.com/embed/b1JfzW8GPZo?…
Sbarca sul Dark Web DIG AI! Senza Account, Senza costi e … senza nessuna censura
Un nuovo strumento AI è apparso sul dark web e ha rapidamente attirato l’attenzione degli esperti di sicurezza, e non per le migliori ragioni.
Si tratta di un servizio di intelligenza artificiale chiamato DIG AI, privo di limitazioni integrate. Questo bot è già attivamente utilizzato in schemi fraudolenti , sviluppo di malware, diffusione di materiale estremista e creazione di contenuti relativi allo sfruttamento sessuale dei minori.
I ricercatori di Re Security avevano rilevato per la prima volta tracce di DIG AI il 29 settembre 2025. Quasi subito dopo il suo lancio, l’amministratore del servizio ha iniziato a promuoverlo attivamente su un forum della darknet, vantandosi del suo carico di lavoro: nelle prime 24 ore, il sistema avrebbe elaborato circa diecimila richieste.
A differenza dei precedenti strumenti di intelligenza artificiale per la criminalità organizzata come FraudGPT o WormGPT, venduti in abbonamento, DIG AI è progettato in modo diverso. Non richiede registrazione, pagamento o addirittura un account: richiede semplicemente l’accesso tramite la rete Tor. Inoltre, il creatore afferma che il servizio è distribuito sulla propria infrastruttura e non si basa su cloud di terze parti, migliorando ulteriormente la sua resilienza ai blocchi.

Resecurity ha condotto una serie di test e ha concluso che il bot risponde senza esitazione a domande relative alla produzione di esplosivi, droghe, altre sostanze proibite, frodi finanziarie e altri argomenti vietati dal diritto internazionale. Durante gli esperimenti, il sistema ha generato script dannosi funzionanti , tra cui codice per l’installazione di backdoor e altri tipi di malware. Gli analisti ritengono che i risultati siano piuttosto adatti all’uso pratico.
C’è particolare attenzione alla capacità di DIG AI nella community di cybersecurity, anche in relazione alle sue capacità di elaborare contenuti pornografici. Lo strumento era in grado sia di creare materiali interamente sintetici sia di modificare immagini di minori reali, trasformando fotografie innocue in materiale illegale. Gli esperti definiscono questo aspetto uno dei più allarmanti.

Nonostante tutte le sue potenzialità, il servizio presenta ancora dei limiti. Alcune operazioni richiedono diversi minuti per essere completate, il che indica risorse di elaborazione limitate. Ma questo problema può essere facilmente risolto, ad esempio introducendo un accesso a pagamento e scalando l’hardware in base alla domanda.
Intanto su varie piattaforme TOR ci sono banner pubblicitari di DIG AI associati al traffico di droga e alla rivendita di dati di pagamento compromessi. Questa selezione di piattaforme descrive accuratamente il pubblico a cui si rivolge lo sviluppatore del servizio. L’amministratore, che usa lo pseudonimo di Pitch, afferma che uno dei tre modelli disponibili è basato su ChatGPT Turbo.
Tra il 2024 e il 2025, le menzioni e l’uso effettivo di strumenti di intelligenza artificiale dannosi sui forum underground sono triplicati. I criminali informatici stanno padroneggiando sempre più modelli linguistici di grandi dimensioni e l’emergere di nuovi sistemi non fa che accelerare questo processo.

Ovviamente queste tecnologie possono portare un aumento significativo delle minacce già a partire dal 2026. Questa preoccupazione è accentuata dai grandi eventi internazionali previsti per quel periodo, tra cui le Olimpiadi invernali di Milano e la Coppa del Mondo FIFA.
Gli analisti ritengono che i sistemi di intelligenza artificiale criminale stiano abbassando le barriere d’ingresso per la criminalità informatica automatizzando e amplificando gli attacchi, ampliando così il bacino di potenziali aggressori.

L'articolo Sbarca sul Dark Web DIG AI! Senza Account, Senza costi e … senza nessuna censura proviene da Red Hot Cyber.
Why Chopped Carbon Fiber in FDM Prints is a Contaminant

A lot of claims have been made about the purported benefits of adding chopped carbon fiber to FDM filaments, but how many of these claims are actually true? In the case of PLA at least, the [I built a thing] channel on YouTube makes a convincing case that for PLA filament, the presence of chopped CF can be considered a contaminant that weakens the part.
Using the facilities of the University of Basel for its advanced imaging gear, the PLA-CF parts were subjected to both scanning electron microscope (SEM) and Micro CT imaging. The SEM images were performed on parts that were broken apart to see what this revealed about the internal structure. From this, it becomes apparent that the chopped fibers distribute themselves both inside and between the layers, with no significant adherence between the PLA polymer and the CF. There is also evidence for voids created by the presence of the CF.
To confirm this, an intact PLA-CF print was scanned using a Micro CT scanner over 13 hours. This confirmed the SEM findings, in that the voids were clearly visible, as was the lack of integration of the CF into the polymer. This latter point shouldn’t be surprising, as the thermal coefficient of PLA is much higher than that of the roughly zero-to-negative of CF. This translates into a cooling PLA part shrinking around the CF, thus creating the voids.
What this means is that for PLA-CF, the presence of CF is by all measures an undesirable contaminant that effectively compromises it as much as having significant moisture in the filament before printing. Although for other thermoplastics used with FDM printing, chopped CF may make more sense, with PLA-CF, you’re effectively throwing away money for worse results.
As also noted in the video, in medical settings, these CF-reinforced FDM filaments aren’t permitted due to the chopped CF fragments. This topic has featured more widely in both the scientific literature and YouTube videos in recent years, with some significant indications that fragments of these chopped fibers can have asbestos-like implications when inhaled. Looking for the thrill of a weird filament? Maybe try one of these.
youtube.com/embed/w7JperqVfXI?…
A Compact, Browser-Based ESP32 Oscilloscope

An oscilloscope is usually the most sensitive, and arguably most versatile, tool on a hacker’s workbench, often taking billions of samples per second to produce an accurate and informative representation of a signal. This vast processing power, however, often goes well beyond the needs of the signals in question, at which point it makes sense to use a less powerful and expensive device, such as [MatAtBread]’s ESP32 oscilloscope.

The oscilloscope doesn’t have a display; instead, it hosts a webpage that displays the signal trace and provides the interface. Since the software uses direct memory access to continually read a signal from the ADC, it’s easy to adjust the sampling rate up to the hardware’s limit of 83,333 Hz. In addition to sampling-rate adjustment options, the browser interface includes a crosshair pointer for easy voltage reading, an adjustable trigger level, attenuation controls, and the ability to set the test signal frequency. The oscilloscope’s hardware is simply a Seeed Studio Xiao development board mounted inside a 3D-printed case with an AA battery holder and three pin breakouts for ground, signal input, and the test signal output.
This isn’t the first ESP32-based oscilloscope we’ve seen, though it is the fastest. If you’re looking for a screen with your simple oscilloscope, we’ve seen them built with an STM32 and Arduino. To improve performance, you might add an anti-aliasing filter.
Shoot Instax Film In A Polaroid Camera With The Aid Of Tape

Polaroid cameras have been very popular for a very long time and are especially hot gifts this year. Fresh film is easy to find but relatively expensive. In contrast, Fuji’s Instax line of instant film and cameras aren’t as well established, but the film is easy to find and cheap. You might like to shoot cheap Instax film in your Polaroid camera. Thankfully, [Nick LoPresti] figured out how to do just that.
You can’t just slam an Instax cassette in an old Polaroid camera and expect it to work. The films are completely different sizes, and there’s no way they will feed properly through the camera’s mechanisms at all. Instead, you have to get manual about things. [Nick] starts by explaining the process of removing Instax film sheets from a cassette, which must be done without exposure to light if you want the film to remain useful. Then, if you know what you’re doing, you can tape it in place behind the lens of an old-school Polaroid camera, and expose it as you would any other shot. The chemistry is close enough that you’ll have a fair chance of getting something with passable exposure.
Once exposed, you have to develop the film. Normally, a Polaroid camera achieves this by squeezing the film sheet out through rollers to release the developer and start the process. Without being able to rely on the camera’s autofeed system, you need to find an alternative way to squeeze out the chemicals and get the image to develop. [Nick] recommends a simple kitchen rolling pin, while noting that you might struggle with some uneven chemical spread across the sheet. Ultimately, it’s a fussy hack, but it does work. It might only be worthwhile if you’ve got lots of Instax film kicking around and no other way to shoot it.
Instant cameras can seem a little arcane, but they’re actually quite simple to understand once you know how they’re built. You can even 3D print one from scratch if you’re so inclined. Video after the break.
youtube.com/embed/rgaRJbFf4LE?…
A Heavily Modified Rivian Attempts the Cannonball Run

There are few things more American than driving a car really fast in a straight line. Occasionally, the cars will make a few left turns, but otherwise, this is the pinnacle of American motorsport. And there’s no longer, straighter line than that from New York to Los Angeles, a time trial of sorts called the Cannonball Run, where drivers compete (in an extra-legal fashion) to see who can drive the fastest between these two cities. Generally, the cars are heavily modified with huge fuel tanks and a large amount of electronics to alert the drivers to the presence of law enforcement, but until now, no one has tried this race with an EV specifically modified for this task.
The vehicle used for this trial was a Rivian electric truck, chosen for a number of reasons. Primarily, [Ryan], the project’s mastermind, needed something that could hold a significant amount of extra batteries. The truck also runs software that makes it much more accepting of and capable of using an extra battery pack than other models. The extra batteries are also from Rivians that were scrapped after crash tests. The team disassembled two of these packs to cobble together a custom pack that fits in the bed of the truck (with the tonneau closed), which more than doubles the energy-carrying capacity of the truck.
Of course, for a time trial like this, an EV’s main weakness is going to come from charging times. [Ryan] and his team figured out a way to charge the truck’s main battery at one charging stall while charging the battery in the bed at a second stall, which combines for about a half megawatt of power consumption when it’s all working properly and minimizes charging time while maximizing energy intake. The other major factor for fast charging the battery in the bed was cooling, and rather than try to tie this system in with the truck’s, the team realized that using an ice water bath during the charge cycle would work well enough as long as there was a lead support vehicle ready to go at each charging stop with bags of ice on hand.
Although the weather and a few issues with the double-charging system stopped the team from completing this run, they hope to make a second attempt and finish it very soon. They should be able to smash the EV record, currently held by an unmodified Porsche, thanks to these modifications. In the meantime, though, there are plenty of other uses for EV batteries from wrecked vehicles that go beyond simple transportation.
youtube.com/embed/yfgkh4Fgw98?…
CVE-2025-20393: zero-day critico nei Cisco Secure Email Gateway
Una falla zero-day critica nei dispositivi Cisco Secure Email Gateway e Cisco Secure Email and Web Manager sta facendo tremare i ricercatori di sicurezza. Con oltre 120 dispositivi vulnerabili già identificati e sfruttati attivamente dagli aggressori, la situazione è a dir poco allarmante.
La vulnerabilità, identificata come CVE-2025-20393,non ha ancora una patch disponibile. Ciò significa che le organizzazioni che si affidano a questi sistemi per proteggere le proprie reti da attacchi di phishing e malware sono esposte a un rischio compromissione.
Secondo le informazioni sulle minacce fornite dalla Shadowserver Foundation, i dispositivi vulnerabili rappresentano un sottoinsieme di oltre 650 dispositivi di sicurezza della posta elettronica Cisco esposti e accessibili tramite Internet.
Il CVE-2025-20393 prende di mira l’infrastruttura di sicurezza della posta elettronica di Cisco, utilizzata dalle aziende per ispezionare il traffico di posta elettronica in entrata e in uscita alla ricerca di minacce.

Sebbene i dettagli tecnici specifici sul metodo di sfruttamento rimangano limitati per prevenire abusi diffusi, la conferma dello sfruttamento attivo indica che gli autori della minaccia stanno già sfruttando questa debolezza per compromettere i sistemi vulnerabili.
Cisco ha riconosciuto la vulnerabilità e ha pubblicato un avviso di sicurezza in cui esorta le organizzazioni a implementare misure difensive immediate. Il colosso del networking consiglia ai clienti interessati di rivedere le proprie configurazioni di sicurezza e di applicare misure di mitigazione temporanee fino a quando non sarà disponibile una soluzione definitiva. Le aziende possono accedere a una guida dettagliata tramite il portale Security Advisory di Cisco .
La situazione evidenzia le continue sfide che le organizzazioni devono affrontare a causa delle vulnerabilità zero-day, in particolare nei componenti critici delle infrastrutture come i gateway di posta elettronica. Questi dispositivi si trovano in un punto cruciale delle reti aziendali, gestendo comunicazioni sensibili e fungendo da principale difesa contro le minacce trasmesse tramite e-mail. Una compromissione riuscita potrebbe consentire agli aggressori di intercettare comunicazioni riservate, distribuire ransomware o stabilire un accesso persistente alla rete.
Cisco sta lavorando attivamente per sistemare la falla che come riportato dal loro bollettino risulterebbe avere un base score pari a 10.
L'articolo CVE-2025-20393: zero-day critico nei Cisco Secure Email Gateway proviene da Red Hot Cyber.
A Tiny Reflecting Telescope For Portable Astronomy

For most of us who are not astronomers, the image that comes to mind when describing a reflecting telescope is of a huge instrument in its own domed-roof building on a mountain top. But a reflecting telescope doesn’t have to be large at all, as shown by the small-but-uncompromising design from [Lucas Sifoni].
Using an off-the-shelf mirror kit with a 76mm diameter and a 300mm focal length, he’s made a pair of 3D-printed frames that are joined by carbon fibre rods. The eyepiece and mirror assembly sit in the front 3D-printed frame, and the eyepiece is threaded so the telescope can be focused. There’s a 3D-printed azimuth-elevation mount, and once assembled, the whole thing is extremely compact.
While a common refracting telescope uses a lens and an eyepiece to magnify your view, a reflector uses a parabolic mirror to focus an image on a smaller diagonal mirror, and that mirror sends the image through the eyepiece. Most larger telescopes use this technique or a variation on it because large first-surface mirrors are easier to make than large lenses. There are also compound telescope types that use different combinations of mirrors and lenses. Which one is “best” depends on what you want to optimize, but reflectors are well known for being fairly simple to build and for having good light-gathering properties.
If you’d like to build your own version of this telescope then the files can all be found on Printables, meanwhile this isn’t the first 3D-printed telescope you might have seen on these pages. If you want to make your own mirror, that’s a classic hacker project, too.
Building a Multi-Channel Pipette for Parallel Experimentation

One major reason for the high cost of developing new drugs and other chemicals is the sheer number of experiments involved; designing a single new drug can require synthesizing and testing hundreds or thousands of chemicals, and a promising compound will go through many stages of testing. At this scale, simply performing sequential experiments is wasteful, and it’s better to run tens or hundreds of experiments in parallel. A multi-channel pipette makes this significantly simpler by collecting and dispensing liquid into many vessels at once, but they’re, unfortunately, expensive. [Triggy], however, wanted to run his own experiments, so he built his own 96-channel multi-pipette for a fiftieth of the professional price.
The dispensing mechanism is built around an eight-by-twelve grid of syringes, which are held in place by one plate and have their plungers mounted to another plate, which is actuated by four stepper motors. The whole syringe mechanism needed to move vertically to let a multi-well plate be placed under the tips, so the lower plate is mounted to a set of parallel levers and gears. When [Triggy] manually lifts the lever, it raises the syringes and lets him insert or remove the multi-well. An aluminium extrusion frame encloses the entire mechanism, and some heat-shrink tubing lets pipette tips fit on the syringes.
[Triggy] had no particularly good way to test the multi-pipette’s accuracy, but the tests he could run indicated no problems. As a demonstration, he 3D-printed two plates with parallel channels, then filled the channels with different concentrations of watercolors. When the multi-pipette picked up water from each channel plate and combined them in the multi-well, it produced a smooth color gradient between the different wells. Similarly, the multi-pipette could let someone test 96 small variations on a single experiment at once. [Triggy]’s final cost was about $300, compared to $18,000 for a professional machine, though it’s worth considering the other reason medical development is expensive: precision and certifications. This machine was designed for home experiments and would require extensive testing before relying on it for anything critical.
We’ve previously looked at the kind of miniaturization that made large-scale biology possible and some of the robots that automate that kind of lab work. Some are even homemade.
youtube.com/embed/2TTu-Lkz2Eo?…
Thanks to [Mark McClure] for the tip!
Hardware Store Marauder’s Map is Clarkian Magic

The “Marauder’s Map” is a magical artifact from the Harry Potter franchise. That sort of magic isn’t real, but as Arthur C. Clarke famously pointed out, it doesn’t need to be — we have technology, and we can make our own magic now. Or, rather, [Dave] on the YouTube Channel Dave’s Armoury can make it.
[Dave]’s hardware store might be in a rough neighborhood, since it has 50 cameras’ worth of CCTV coverage. In this case, the stockman’s loss is the hacker’s gain, as [Dave] has talked his way into accessing all of those various camera feeds and is using machine vision to track every single human in the store.
Of course, locating individuals in a video feed is easy — to locate them in space from that feed, one first needs an accurate map. To do that, [Dave] first 3D scans the entire store with a rover. The scan is in full 3D, and it’s no small amount of data. On the rover, a Jetson AGX is required to handle it; on the bench, a beefy HP Z8 Fury workstation crunches the point cloud into a map. Luckily it came with 500 GB of RAM, since just opening the mesh file generated from that point cloud needs 126 GB. That is processed into a simple 2D floor plan. While the workflow is impressive, we can’t help but wonder if there was an easier way. (Maybe a tape measure?)
Once an accurate map has been generated, it turns out NVIDIA already has a turnkey solution for mapping video feeds to a 2D spatial map. When processing so much data — remember, there are 50 camera feeds in the store — it’s not ideal to be passing the image data from RAM to GPU and back again, but luckily NVIDIA’s “Deep Stream” pipeline will do object detection and tracking (including between different video streams) all on the GPU. There’s also pose estimation right in there for more accurate tracking of where a person is standing than just “inside this red box”. With 50 cameras, it’s all a bit much for one card, but luckily [Dave]’s workstation has two GPUs.
Once the coordinates are spat out of the neural networks, it’s relatively simple to put footprints on the map in true Harry Potter fashion. It really is magic, in the Clarkian sense, what you can do if you throw enough computing power at it.
Unfortunately for show-accuracy (or fortunately, if you prefer to avoid gross privacy violations), it doesn’t track every individual by name, but it does demonstrate the possibility with [Dave] and his robot. If you want a map of something… else… maybe check out this backyard project.
youtube.com/embed/dO32ImnsX-4?…
The ‘Hidden’ Microphone inside the Sipeed NanoKVM

Recently, [Jeff Geerling] dropped into the bad press feeding frenzy around Sipeed’s NanoKVM, most notably because of a ‘hidden’ microphone that should have no business on a remote KVM solution. The problem with that reporting is, as [Jeff] points out in the video below, that the NanoKVM – technically the NanoKVM-Cube – is merely a software solution that got put on an existing development board, the LicheeRV Nano, along with an HDMI-in board. The microphone exists on that board and didn’t get removed for the new project, and it is likely that much of the Linux image is also reused.
Of course, the security report that caused so much fuss was published back in February of 2025, and some of the issues pertaining to poor remote security have been addressed since then on the public GitHub repository. While these were valid concerns that should be addressed, the microphone should not be a concern, as it’d require someone to be logged into the device to even use it, at which point you probably have bigger problems.
Security considerations aside, having a microphone in place on a remote KVM solution could also be very useful, as dutifully pointed out in the comments by [bjoern.photography], who notes that being able to listen to beeps on boot could be very useful while troubleshooting a stricken system. We imagine the same is true for other system sounds, such as fan or cooling pump noises. Maybe all remote KVM solutions should have microphone arrays?
Of course, if you don’t like the NanoKVM, you could always roll your own.
Top image: the NanoKVM bundle from [Jeff]’s original review. (Credit: [Jeff Geerling])
youtube.com/embed/RSUqyyAs5TE?…
Two-Wheeled Arduino Robot Project for Beginners

Here’s a fun build from [RootSaid] that is suitable for people just getting started with microcontrollers and robotics — an Arduino-controlled two-wheeled robot.
The video assumes you already have one of the common robotics kits that includes the chassis, wheels, and motors, something like this. You’ll also need a microcontroller (in this case, an Arduino Nano), a L293D motor driver IC, a 9 V battery, and some jumper wires.
The L293D motor driver IC powers and controls the motors connected to the wheels. The L293D takes its commands from the Arduino. The rest of the video is spent going over the software for controlling the wheels.
When you’re ready to go to the next level, you might enjoy this robot dog.
youtube.com/embed/sn_NWZkKO5g?…
Retrocomputing: Simulacrum or the Real Deal?

The holidays are rapidly approaching, and you probably already have a topic or two to argue with your family about. But what about with your hacker friends? We came upon an old favorite the other day: whether it “counts” as retrocomputing if you’re running a simulated version of the system or if it “needs” to run on old iron.

We’ll admit to being entirely torn. There’s something about the old computers that’s very nice to lay hands on, and we just don’t get the same feels from an emulator running on our desktop. But a physical reproduction like with many of the modern C64 recreations, or [Oscar Vermeulen]’s PiDP-8/I really floats our boat in a way that an in-the-browser emulation experience simply doesn’t.
Another example was the Voja 4, the Supercon 2022 badge based on a CPU that never existed. It’s not literally retro, because [Voja Antonics] designed it during the COVID quarantines, so there’s no “old iron” at all. Worse, it’s emulated; the whole thing exists as a virtual machine inside the onboard PIC.

So we’ll fittingly close this newsletter with a holiday message of peace to the two retrocomputing camps: Maybe you’re both right. Maybe the physical device and its human interfaces do matter – emulation sucks – but maybe it’s not entirely relevant what’s on the inside of the box if the outside is convincing enough. After all, if we hadn’t done [Kevin Noki] dirty by showing the insides of his C64 laptop, maybe nobody would ever have known.
This article is part of the Hackaday.com newsletter, delivered every seven days for each of the last 200+ weeks. It also includes our favorite articles from the last seven days that you can see on the web version of the newsletter. Want this type of article to hit your inbox every Friday morning? You should sign up!
Testing 8 Solder Flux Pastes After Flux Killed a GeForce2 GTS
")
Flux is one of those things that you cannot really use too much of during soldering, as it is essential for cleaning the surface and keeping oxygen out, but as [Bits und Bolts] recently found, not all flux is made the same. After ordering the same fake Amtech flux from the same AliExpress store, he found that the latest batch didn’t work quite the same, resulting in a Geforce 2 GTS chip getting cooked while trying to reball the chip with uncooperative flux.

Although it’s easy to put this down to a ‘skill issue’, the subsequent test of eight different flux pastes ordered from both AliExpress and Amazon, including — presumably genuine — Mechanic flux pastes with reballing a section of a BGA chip, showed quite different flux characteristics, as you can see in the video below. Although all of these are fairly tacky flux pastes, with some, the solder balls snapped easily into place and gained a nice sheen afterwards, while others formed bridges and left a pockmarked surface that’s indicative of oxygen getting past the flux barrier.
Not all flux pastes are made the same, which also translates into how easy the flux remnants are to clean up. So-called ‘no clean’ flux pastes are popular, which take little more than some IPA to do the cleaning, rather than specialized PCB cleaners as with the used Mechanic flux. Although the results of these findings are up for debate, it can probably be said that ordering clearly faked brand flux paste is a terrible idea. While the top runner brand Riesba probably doesn’t ring any bells, it might be just a Chinese brand name that doesn’t have a Western presence.
As always, caveat emptor, and be sure to read those product datasheets. If your flux product doesn’t come with a datasheet, that would be your first major red flag. Why do we need flux? Find out.
youtube.com/embed/uAqofdpe744?…
Kimwolf, la botnet che ha trasformato smart TV e decoder in un’arma globale
Un nuovo e formidabile nemico è emerso nel panorama delle minacce informatiche: Kimwolf, una temibile botnet DDoS, sta avendo un impatto devastante sui dispositivi a livello mondiale. Le conseguenze di questa minaccia possono essere estremamente gravi e la sua portata è in costante aumento.
Per capire la reale entità di questo problema, è essenziale considerare che Kimwolf è una rete di dispositivi contaminati da malware, i quali possono essere controllati a distanza dagli aggressori. L’obiettivo principale di Kimwolf è quello di condurre attacchi DDoS, mirati a sovraccaricare e rendere inaccessibili sistemi o reti.
Secondo l’azienda cinese QiAnXin, Kimwolf è riuscita a compromettere almeno 1,8 milioni di dispositivi eterogenei, tra cui smart TV, decoder e tablet basati su Android. Questo numero è davvero impressionante e la varietà dei dispositivi colpiti rende la situazione ancora più preoccupante.
In definitiva, Kimwolf incarna un problema che non può essere ignorato. La sua capacità di propagarsi velocemente su dispositivi diversi e di effettuare attacchi DDoS. Considerando il numero elevato di dispositivi già coinvolti, Kimwolf rappresenta una minaccia significativa che richiede attenzione e azione.
Kimwolf è compilato utilizzando il Native Development Kit (NDK) e va oltre le funzionalità DDoS convenzionali. Oltre a lanciare attacchi denial-of-service su larga scala, integra funzionalità di proxy forwarding, reverse shell access e gestione dei file. Di conseguenza, gli aggressori possono non solo arruolare dispositivi come bot, ma anche sfruttarli per operazioni offensive più ampie.
Secondo le stime di QiAnXin, la botnet ha generato un totale di 1,7 miliardi di attacchi DDoS tra il 19 e il 22 novembre 2025. A causa dell’elevato volume di attività, il suo dominio di comando e controllo, 14emeliaterracewestroxburyma02132[.]su, si è posizionato al vertice della classifica DNS di Cloudflare.
I bersagli principali di questa botnet sono modelli come TV BOX, SuperBOX, HiDPTAndroid, P200, X96Q, XBOX, SmartTB, MX10 e vari altri. Sono state osservate infezioni in tutto il mondo, con concentrazioni particolarmente elevate in Brasile, India, Stati Uniti, Argentina, Sudafrica e Filippine. QiAnXin non ha ancora determinato come il malware iniziale sia stato distribuito a questi dispositivi.

In particolare, i domini di comando e controllo di Kimwolf sono stati disattivati con successo almeno tre volte a dicembre da soggetti non identificati, probabilmente attori rivali o ricercatori di sicurezza indipendenti . Questa interruzione ha costretto gli operatori della botnet a cambiare strategia e ad adottare l’Ethereum Name Service (ENS) per rafforzare la propria infrastruttura contro ulteriori rimozioni.
La botnet Kimwolf è anche collegata alla famigerata botnet AISURU. Gli investigatori hanno scoperto che gli aggressori hanno riutilizzato il codice di AISURU durante le prime fasi di sviluppo, prima di creare Kimwolf come successore più evasivo. QiAnXin sospetta che alcune campagne DDoS precedentemente attribuite ad AISURU possano aver coinvolto Kimwolf, o addirittura essere state orchestrate principalmente da quest’ultimo.
Si consiglia agli utenti di smart TV e decoder Android di verificare se i propri dispositivi utilizzano ancora le password predefinite e, in tal caso, di modificarle immediatamente. Se viene rilevato un comportamento anomalo, potrebbe essere necessario un ripristino completo del dispositivo.
Gli aggiornamenti del firmware o del sistema dovrebbero essere applicati tempestivamente non appena disponibili. Tuttavia, molti di questi dispositivi ricevono scarso o nessun supporto per gli aggiornamenti dopo il rilascio, rendendo difficile la correzione a lungo termine anche quando vengono identificate vulnerabilità .
L'articolo Kimwolf, la botnet che ha trasformato smart TV e decoder in un’arma globale proviene da Red Hot Cyber.