The media in this post is not displayed to visitors. To view it, please log in.

Introduction
We have been tracking two new backdoors, OctLurk and SilkLurk, observed in attacks against government organizations primarily in Central Asia since January 2025. Identified victims are located in Afghanistan, Kyrgyzstan, Tajikistan, Uzbekistan, Kazakhstan, and the Syrian Arab Republic. These organizations operate across several sectors, including healthcare, research, government offices, ministries of foreign affairs, logistics, law‑enforcement agencies, urban planning and facilities management, and public educational establishments.
The backdoor loaders are customized for each victim and use information from the victim’s machine to decrypt the payload. Both the loaders and the backdoors are heavily obfuscated, making analysis more complicated. OctLurk and SilkLurk can download and inject additional plugins to perform further malicious actions, including launching command shells, performing file system activity, synthesizing keyboard and mouse events, network scanning, credential dumping, keylogging, password theft from browsers, email collection, and remote access. Furthermore, the attackers deployed a specialized utility we named LurkProxy, which we also cover in this report. While it has a highly similar architecture to the OctLurk backdoor, it is not a backdoor itself.
Our investigation shows that the same threat actor operates both SilkLurk and OctLurk , and some victims infected with SilkLurk also contain OctLurk. We assess with medium confidence that the same actor is behind both backdoors, and that they are Chinese‑speaking. However, at the time of publication, we couldn’t attribute this activity to any known group.
OctLurk
OctLurk Deployment
The attacker created a scheduled task named GoogleUpDate on remote machines using admin credentials. The task runs once with System account privileges right after it was created, executing the batch script located at C:\Users\<username>\Videos\1.bat (MD5 6ecf84fb18f6747ed08d7598364d853a). Prior to executing the task, the actor queries its status. It is then run, as shown below.

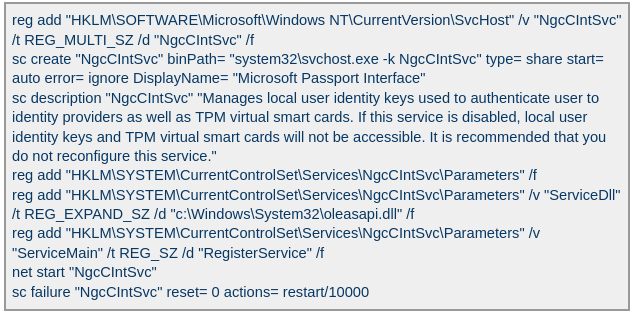
The 1.bat script creates a service named NgcCIntSvc, which loads the loader DLL named oleasapi.dll (MD5 082d49ef9f14e6811d68c7e0e82e5069). The ServiceMain parameter in the service’s registry entry is set to invoke the RegisterService function of oleasapi.dll as shown below.

LurkPoxy Deployment
In another case, the attacker at first checked connectivity to the domain dns[.]ssentialserv[.]xyz as shown below. At the time of our research, the domain was resolving to the address 154[.]196[.]162[.]76 which is used as a LurkProxy C2 server.

After confirming that the C2 server was reachable, the attacker executed the batch script C:\Users\[username]\Desktop\auto.bat (MD5 b874123a80fc4f40e06872b9cb54ebc6). The script created a service named Cusrxsrv, which loads a DLL named msbasesysdc.dll. In the service registry, the ServiceMain parameter was set to call the RegisterService function of msbasesysdc.dll as shown below.

We identified several service names — specitsrc, cmtastsvc, PNRPHostSvc, vmictimerosync, and vmicagent — that the attackers used to load a malicious DLL onto compromised machines.
OctLurk loader
The loader DLL exports two methods, Refresh and RegisterService. The previously created service first calls RegisterService, which in turn invokes Refresh, the method that contains the malicious code. To locate the payload, the loader double-XOR-decrypts and then zlib-decompresses a set of hard‑coded bytes, yielding the payload file path. The payload bytes itself undergoes the same double‑XOR decryption and zlib decompression to produce the backdoor DLL bytes.
The double‑XOR decryption uses two distinct multibyte keys:
- Key 1: hard‑coded in the loader
- Key 2: derived from the serial number of the C: drive
The backdoor DLL is reflectively injected into memory and its entry point is executed. The loader can then call the DLL’s exported methods either by name or by ordinal; both the method name and the ordinal number are hard‑coded in the loader and are decrypted using the same double‑XOR and zlib‑decompression process applied to the payload path and bytes.
OctLurk backdoor
The loader invokes the backdoor’s curl_easy_escape function (ordinal 2). The backdoor then creates a stream socket using a hard‑coded C2 address (dns[.]multitoconference[.]com) and port 443. It gathers the following information from the victim machine:
- OS information as RTL_OSVERSIONINFOW structure
- Computer name
- User name
- Local host name
- Local IP address in format %u.%u.%u.%u, with local hostname-to-IP-address translation
- Current local date and time as SYSTEMTIME struct
To encrypt the collected data, the backdoor employs a hard‑coded XOR key, which in most cases we observed was the string FDrertgr##@QEWASGkio865ehyf98foidsjzhug874392dfsREFDfdsAGH43wea98h. In addition, it generates 0x53 (83) random bytes — this length is also hard‑coded in the sample — and uses them as a second XOR key. The collected victim information is first compressed with zlib (deflate), and then XOR‑encrypted twice, first with the hard‑coded string key and then with the randomly generated byte sequence. The final data is arranged as follows:
- 0x00: randomly generated XOR key bytes (size 83 bytes)
- 0x53: compressed data size
- 0x57: compressed data in the following format: <uncompressed_size> <deflate(data)>
- 0x57 + compressed_data_size: randomly generated bytes (from 14 to 41 bytes)
The backdoor initially transmits a 16‑byte header that specifies the size of the incoming data packet, as shown below. It then sends the actual data packet.
- 0x00: randomly picked 10 chars from the string “zyxwvutsrqponmlkjihgfedcbaABCDEFGHIJKLMNOPQRSTUVWXYZ9876543210-_”
- 0x0A: \x00\x00
- 0x0C: next_packet_size
The first packet received is 16 bytes long, and its last four bytes specify the size of the subsequent data packet. The format of the subsequent data packet is shown below.
- 0x00: XOR key; size 83 bytes
- 0x53: compressed data size
- 0x57: compressed data in the format: <uncompressed_size> <deflate(data)>
The received data is decrypted using a double‑XOR method: first with the XOR key contained in the packet, then with a hard‑coded XOR key. After the XOR decryption, the data is zlib decompressed. The data may be a command or a plugin code.
OctLurk loads plugins from the C2 server directly into memory to perform various tasks. Each plugin exports two methods — ins_ctl_db and oct_lk_col — with the actual functionality implemented in oct_lk_col. Our analysis shows that the plugins listed below are commonly deployed on victim machines.
- Command Shell: provides a command shell
- File Manager: performs filesystem interaction
- Interaction Manager: synthesizes keyboard and mouse events
The table below provides a detailed description of operations performed by these plugins, where each switch case value denotes command ID.
| Plugin type | Description |
| File Manager | ● case 0x10020: for each drive, retrieve the following information: volume GUID path, drive letter, volume name, file system name, drive type, volume serial number, total size in bytes, and free space in bytes.
● case 0x10030: search for a file that matches a specified name and retrieve the following information: file attributes, creation time, last access time, last write time, file size, the file’s name, and its short (8.3) name.
● case 0x10040: recursively list all files in a specified location, including only those whose size, creation time, last write time, and last access time fall within the threshold values defined by C2. For each listed file, retrieve the following details: file attributes, creation time, last access time, last write time, file size, file name and alternative name for the file
● case 0x10050: use the ShellExecuteExW API to open the specified file path, which may be an executable, a document, or a folder.
● case 0x10051: execute the specified command line using the CreateProcessAsUserW API.
● case 0x10060: perform the following file‑system operations: copy, delete, move, and rename — using the SHFileOperationW API.
● case 0x10070: create a directory.
● case 0x10080: set the attributes for a file or directory.
● case 0x10090: for the filename provided by C2, set the file created, last accessed, and last modified timestamps to the values received from C2.
● case 0x20010: get the size of a file.
● case 0x20020: read a file from the system in chunks, starting at a specified offset.
● case 0x20030: calculate the CRC32 of each file data chunk, and retrieve the file created, last accessed, and last written times.
● case 0x20040: close the file handle and free the associated metadata (file path, handle, and size).
● case 0x20110: create a file at the specified path and write the bytes received from C2 into it. Then set the file created, last accessed, and last modified times using the timestamps supplied by C2. |
| Command Shell | ● case 0x3E9: launch cmd.exe as shell.
● case 0x3EA: send the exit command to close the command shell.
● case Default: if a command string is received from the C2 and the shell is running, write the command to the shell. Then read the shell’s output and send it back to the C2.
If a command string is received from the C2 server and the shell is not already running, execute the command using C:\Windows\System32\cmd.exe /S /C "<command_string>" > %TEMP%\tmp%d%x.tmp where %d and %x are random values. Afterwards, read the output from the temporary file tmp%d%x.tmp and then delete the file. |
| Interaction Manager | ● case 0x3E9: capture the entire screen as a BMP image.
● case 0x3EA: capture the entire screen at specified intervals.
● case 0x3EC: retrieve clipboard data.
● case 0x3ED: copy the data to the clipboard.
● case 0x3F3: MOUSEEVENTF_LEFTDOWN: set the cursor to the specified position and press the left mouse button.
● case 0x3F5: MOUSEEVENTF_LEFTDOWN | MOUSEEVENTF_LEFTUP: move the cursor to the specified position, then press and release the left mouse button.
● case 0x3F6: MOUSEEVENTF_RIGHTDOWN: set the cursor to the specified position and press the right mouse button.
● case 0x3F7: MOUSEEVENTF_RIGHTUP: set the specified cursor position and release the right mouse button.
● case 0x3F8: MOUSEEVENTF_MOVE: move the mouse cursor to specific coordinates, simulating a mouse movement event.
● case 0x3F9: MOUSEEVENTF_WHEEL: move the mouse wheel by a specified amount.
● case 0x3FD: press the key indicated by the virtual‑key code.
● case 0x3FE: KEYEVENTF_KEYUP: release the key identified by the virtual-key code.
● case DEFAULT: MOUSEEVENTF_LEFTUP: move the cursor to the specified position and release the left mouse button. |
Post-compromise activity
The attacker used the command‑shell plugin installed via the OctLurk backdoor to perform the following actions:
Victim fingerprinting
The attacker used admin credentials to create a scheduled task named GoogleUpDate on remote machines. This task runs once with System account privileges, executing the script located at C:\windows\temp\in.bat (MD5 45cf5916fab4272a1313c26e67aa9220, 4e6d5c4770d5a822d7fcce6a74f7ad73). After querying the task’s status, the attacker triggers its execution, as shown below.

The batch script runs a series of commands that collect comprehensive information about the machine’s hardware, software, and network configuration as shown in the table below. The results are saved in three files — info.txt, <hostname>.datb, and <hostname>_logs.datb — all stored in the %TEMP% directory.
| Command | Description |
| chcp 1256 | Changes the system’s code page to 1256, which supports Arabic characters. |
| powershell $PSVersionTable | Retrieves the version information of PowerShell. |
| qwinsta | Views all active sessions on the local machine. |
| klist sessions | Displays a list of logon sessions on this computer (Including Kerberos). |
| TASKLIST /V | Lists all running tasks with detailed information. |
| findstr /i /c:”explorer.exe” | Searches for explorer.exe in a case-insensitive manner. Used together with TASKLIST /V. |
| wevtutil qe Security /f:text /c:5 /rd:true /q:”*[System[(EventID=4624)]] and *[EventData[Data[@Name=’LogonType’]=10]]” | Retrieves the last 5 events from the Security event log where the event ID is 4624 (successful logon event) and the logon type is 10 (remote interactive logon e.g., Remote Desktop Protocol). |
| powershell “ipconfig|select-string v4 -context 1,3” | Uses PowerShell to filter ipconfig output for IPv4 addresses. |
| ipconfig /all | Displays detailed network configuration information. |
| WHOAMI /all | Displays detailed information about the current user, including their security identifiers (SIDs), privileges, group memberships, and authentication details. |
| WMIC /Node:localhost /Namespace:\root\SecurityCenter2 Path AntiVirusProduct Get displayName /Format:List | findstr “=” | Retrieves information about installed antivirus software. |
| powershell Get-NetTCPConnection | Retrieves information about TCP connections. |
| netstat -ano | findstr LISTENING | Shows listening ports. |
| netstat -ano | findstr ESTABLISHED | Displays established connections. |
| cmd.exe /c netstat -ano | findstr “EST” | findstr -v 127.0.0.1 | Filters established connections excluding the loopback address. |
| powershell.exe “get-wmiobject -query ‘select * from win32_process’ | Select-Object ProcessId,ProcessName,CommandLine,ExecutablePath,CreationDate | Where-object {$_.ProcessId -eq 500} | Format-List” | Retrieves detailed information about a specific process. |
| reg query HKLM /s /f “ProfileImagePath” /t REG_EXPAND_SZ | Searches the Windows Registry under HKEY_LOCAL_MACHINE (HKLM) for entries where the value name is “ProfileImagePath” and the type is REG_EXPAND_SZ. It points to the location of a user’s profile folder. |
| cmd.exe /c dir /b c:\users | Lists the contents of the C:\Users directory. |
| wmic startup get caption,command | findstr exe | Filters startup items for executable files. |
| powershell “get-MpComputerStatus” | Retrieves the status and configuration details of Microsoft Defender Antivirus (formerly Windows Defender) on a Windows system. |
| reg query “HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows Defender\Features” /v “TamperProtection” | Queries whether Microsoft Defender antivirus’s tamper protection is enabled. |
| reg query “HKLM\SOFTWARE\Microsoft\Windows Defender\Exclusions” /s | Queries exclusion settings for Microsoft Defender Antivirus. This is where you can configure files, folders, processes, and extensions that should be excluded from being scanned by Defender. |
| wevtutil gli Security | Configures the Security event log. |
| wevtutil gl Security /f:xml | Retrieves events from the Security log in XML format. |
| wevtutil gli “Windows PowerShell” | Configures the Windows PowerShell event log. |
| wevtutil gl “Windows PowerShell” /f:xml | Retrieves events from the Windows PowerShell log in XML format. |
| wevtutil gli System | Configures the System event log. |
| wevtutil gl System /f:xml | Retrieves events from the System log in XML format. |
| schtasks /query /fo LIST /v | findstr “TaskName> Status> ‘Task To Run’> ‘Run As User’>” | Lists all scheduled tasks in verbose mode and extracts the following fields: Status, Task To Run, Run As User, and TaskName. |
| systeminfo | Displays detailed system information. |
| powershell “Get-WmiObject -Class Win32_BIOS | Format-list” | Retrieves BIOS information. |
| powershell “Get-WMIObject -Class Win32_PhysicalMemory | Format-list” | Retrieves physical memory information. |
| powershell “Get-WMIObject -Class Win32_Processor | Format-list” | Retrieves processor information. |
| powershell “Get-WMIObject -Class Win32_DiskDrive | Format-list” | Retrieves disk drive information. |
| netsh interface ipv4 show interfaces | Displays information about IPv4 interfaces. |
| powershell “gwmi Win32_NetworkAdapter | Format-list” | Provides hardware-level and driver-level information about adapters. |
| powershell “gwmi Win32_NetworkAdapterConfiguration | Format-list” | Provides network configuration details, such as IP address, DNS, DHCP status, etc. |
| ipconfig /all | Displays detailed network configuration. |
| netstat -e -s | Displays detailed network protocol statistics. |
| certutil -urlcache | Displays URL cache entries. |
| ipconfig /displaydns | Displays the contents of the DNS client resolver cache. |
Event log collection
The attackers ran commands to export successful logon events for remote interactive logons (e.g., Remote Desktop Protocol) and to query those events for specific users.

Credential harvesting
Impacket — secretsdump
Attackers ran a malicious file named Adobe.exe (MD5 32a5985543433a4f60da2fafd873b927), which is a portable‑executable version of Impacket’s secretsdump.py tool. Using this tool, they extracted password hashes from domain controllers, the critical servers in an Active Directory environment. Immediately after harvesting the hashes, they issued commands to list all members of the “Domain Controllers” group, likely to identify and target additional domain controllers for further compromise.

Keylogger
Attackers dropped and executed a keylogger located at C:\Users\Public\Pictures\AnyDesk.exe (MD5: 2a571f6cee42a17d873f4c942649813f). They then created a scheduled task named AnyDesk to run the keylogger whenever any user logged on as shown below.

The keylogger creates two files: C:\Users\Public\Libraries\msect\dev0, which stores captured keystrokes, and C:\Users\Public\Libraries\msect\dev1, which holds clipboard data. Before writing to these files, the captured data is encoded by subtracting 2 from each byte.
Browser Password Decryptor
The Browser Password Decryptor tool C:\users\[username]\libraries\64.exe (MD5 37dc84e4bcad92fa28f1e7778d088283) is used to extract passwords from browsers. The tool offers two options: -help to extract passwords from Chrome and -exit to extract passwords from Firefox. For Chrome, the tool targets the Login Data and Local State databases located at %LOCALAPPDATA%\Google\Chrome\User Data\Default\Login Data and %LOCALAPPDATA%\Google\Chrome\User Data\Local State, respectively. The Local State contains the master key, which is essential for decrypting encrypted login information stored in the Login Data database file. For Firefox, the tool targets the logins.json file located at %APPDATA%\Mozilla\Firefox\Profiles\{profile folder}. The logins.json file in Firefox stores encrypted usernames and passwords for websites.
Remote access : Pandora FMS agents (Pandora RC agent)
Pandora RC agent provides remote control of a victim’s computer, allowing attackers to monitor and manipulate the system. Using administrative credentials, the attacker creates a scheduled task named GoogleUpDate on the compromised machines. This task runs once with System account privileges and executes the script 1.bat, which can be found at either C:\Users\[username]\1.bat or C:\ProgramData\1.bat (MD5 5e26df131ff0a679a0a2699b723b46e3). The task’s status is first queried, then it is executed, as shown below.

The batch script 1.bat executes a command that downloads and installs the Pandora RC agent using the arguments shown below.

- EHUSER: a Pandora RC user
- STARTEHORUSSERVICE: start the agent after the installation finishes (default = 1)
- EHORUSINSTALLFOLDER: specify the folder where you want to install the agent (default:
%ProgramFiles%\_agent) - DESKTOPSHORTCUT: 0: do not create a desktop shortcut
Network scan: FSCAN
Fscan is a comprehensive internal‑network scanning tool that offers a range of functions, including network discovery, vulnerability assessment, reverse‑shell creation, and brute forcing of common services. The executable is dropped to %TEMP%\fc.exe (MD5: cf903e4a1629aa0582fd0363b5786676) and writes its output to %TEMP%\result.txt. Using Fscan, both internal and public networks were scanned to identify services running on specific ports, such as Secure Shell (SSH) on port 22 and MySQL on port 3306. The tool also attempted to access these services using credentials from the password file pp.txt.

Email harvesting
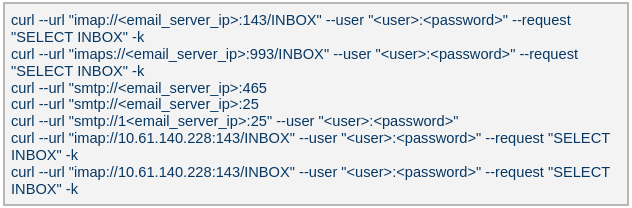
The attackers used the curl command to connect to an email server, authenticate with a username and password, and issue a command to select the Inbox folder. Typically, the goal is to:
- Verify that a connection to the email server is working
- Authenticate the user
- Prepare the Inbox folder for reading or manipulating messages (e.g., listing, fetching, or deleting emails)

LurkProxy
In a similar manner to the OctLurk backdoor, the attacker also deployed another implant we named LurkProxy, which uses a heavily obfuscated version of the OctLurk loader. While LurkProxy has a nearly identical architecture to the OctLurk backdoor, its primary role is to proxy network traffic. Like the OctLurk, it exports a function named curl_escape_easy, which the loader invokes. Once executed, LurkProxy listens on all interfaces on hard‑coded port 64980 and establishes a TLS‑encrypted connection to the C2 server (154[.]196[.]162[.]76). The C2 communication uses a proprietary binary protocol, where each packet is compressed with zlib, encrypted with a double‑XOR scheme, and follows the structure outlined below.
| Offset | Data | Type |
| 0x00 (00) | Unused | – |
| 0x08 (08) | Packet control flags. Bit 0 indicates high priority packet, bit 1 indicates single packet | bit array |
| 0x0C (12) | Command number | int |
| 0x10 (16) | Handler number (unique identifier for each proxy client in the first mode) | int |
| 0x14 (20) | Command integer argument | int |
| 0x18 (24) | Unused | – |
| 0x1C (28) | Data 1 payload size | int |
| 0x20 (32) | Data 2 payload size | int |
| 0x24 (36) | Data 1 byte stream | bytes |
| 0x24 (36) + N | Data 2 byte stream | bytes |
LurkProxy can function as a reverse proxy in two distinct modes as described below. The mode is selected by a static flag, meaning the proxy can operate in only one mode at a time. In the implant we examined, the first (SOCKS5) mode was used.
Mode 1: SOCKS5 proxy
When a client connects, LurkProxy sends to the C2 the command 0x1000010, indicating that the connection has been established and includes the target address in the packet data. The C2 server then opens a connection to that address, enabling bidirectional communication through the appropriate commands.
Mode 2: transparent proxy
In this mode, the target address and port are hard‑coded. Upon startup, LurkProxy immediately connects to the predefined target via the C2 channel using the same command. All subsequent client connections are routed through this single, fixed target. This mode handles raw network traffic directly, bypassing the SOCKS5 layer.
| Command ID | Direction | Description | Arguments |
| 0x1000010 | Implant -> C2 | When a new proxy client connects, it creates a proxy session and notifies C2 of the successful configuration | Target port in command integer argument
UTF-16 encoded connection hostname in data 1 |
| 0x1000010 | C2 -> Implant | Used to control the session, allowing it to pause or stop proxying | Action in command integer argument (1 to pause, or any other value to terminate) |
| 0x1000030 | Implant -> C2 | Sent when the LurkProxy is shut down | – |
| 0x1000050 | Implant -> C2 | Forwards the received bytes from the client to C2 | Raw TCP bytes in data 1 |
| 0x1000050 | C2 -> Implant | Forwards the received bytes from the proxy target to the client | Raw TCP bytes in data 1 |
SilkLurk
Deployment
The attacker created a service that executes legitimate binaries, such as NetSetSvc.exe (NVIDIA debug dump), nvgwls.exe (NVIDIA background tool responsible for autotuning), RtkSmbus.exe (Realtek Semiconductor’s noise‑cancelling program), and RtkNGUI64.exe (Realtek High‑Definition Audio Manager), to side‑load malicious loader DLLs: nvml.dll, vulkan-1.dll, RtkSmbusLoc.dll, and RtkNGUI64Loc.dll, respectively. These DLLs act as a loader that will inject SilkLurk backdoor into the process memory.
SilkLurk loader

SilkLurk loader working logic
The loader first verifies that it is running within the legitimate executable that loads it. Next, it moves the payload file (in the analyzed sample, it was named OneDrive.dat) from its module location (C:\ProgramData\Microsoft\Network\Connections in the analyzed sample) to the hard‑coded payload path (C:\ProgramData\Microsoft OneDrive\setup in the analyzed sample). Note that the hard-coded payload path may vary depending on the loader.
Next, the loader creates a service named RmSs to maintain persistence. The service will run the legitimate module binary (C:\ProgramData\Microsoft\Network\Connections\nvgwls.exe) that loads the malicious loader (vulkan-1.dll). The service is configured with the parameters mentioned below. Additionally, the service configuration is modified to restart the service in the event of a failure. Finally, the loader starts the service.
- Service Type:
SERVICE_WIN32_OWN_PROCESS - Start Type:
SERVICE_AUTO_START - Error Control:
SERVICE_ERROR_NORMAL
On service start, loader calls StartServiceCtrlDispatcher, which will invoke ServiceProc. The ServiceProc then calls the routine s_1800078F0_decrypt_and_run_payload. This routine computes a 32-bit hash (dword) of the victim’s computer name. The dword hash is used by a custom algorithm made up of arithmetic and logical operations to decrypt the hardcoded payload file path. The payload bytes themselves are decrypted with the same algorithm that decoded the file path. By using the victim’s computer name in the decryption of both the file path and the payload bytes, the loader becomes specific to each victim. The decrypted bytes contain shellcode with the following structure:
| Shellcode offset | Description |
| 0x000 (0) | Stub code, which performs reflective code injection |
| 0x770 (1904) | Hardcoded value 0x11113F68, XORed with the computer name hash |
| 0x774 (1908) | Hardcoded byte 0xD9, used as XOR key to decrypt import DLL names and APIs |
| 0x775 (1909) | Size of the encrypted backdoor |
| 0x779 (1913) | Encrypted backdoor data blob |
The stub code decrypts and injects the backdoor blob into memory. To decrypt the blob, it first computes a dword hash of the computer’s name. This hash is then fed into a custom algorithm — a series of arithmetic and logical operations — that performs the decryption. This algorithm differs from the one used to decrypt the payload file.
The IMAGE_DOS_HEADER of the backdoor binary is zeroed out. Information in the IMAGE_NT_HEADERS, such as ImageSize and NumberOfSections, is XOR-decrypted using the hash of the computer name. The first three sections are decrypted again using a custom algorithm (a series of arithmetic and logical operations) before being injected into memory.
During import resolution, DLL names and API names are XOR‑decrypted using a hard‑coded single‑byte key. After the import DLL is loaded and the API addresses are resolved, the DLL and API name strings are zeroed out.
During relocation, the size of each relocation block, the value of each relocation entry, and the bytes to be relocated are XOR‑decrypted using the dword hash of the computer name. Afterward, the entry point is also XOR‑decrypted with the same hash and then invoked.
SilkLurk backdoor
The backdoor contains a hardcoded configuration of 0x4AC (1196) bytes, with the first 0x10 (16) bytes holding a mutex string and the remaining 0x49C (1180) bytes comprising encrypted configuration data; this configuration is written to a hardcoded filename (e.g., 2470b666bece868f, 27879a4df1a740ff) that differs across samples and is placed in the %APPDATA% directory. The configuration is decrypted using a custom algorithm involving a series of arithmetic and logical operations that is distinct from the algorithm used to decrypt the encrypted backdoor blob and payload file. The configuration has the following structure:
| Offset | Description |
| 0x00 (000) | C2 Host 1 |
| 0x64 (100) | C2 Host 2 |
| 0xC8 (200) | C2 Host 3 |
| 0x12C (300) | C2 Host 4 |
| 0x190 (400) | Port for C2 Host 1 |
| 0x192 (402) | Port for C2 Host 2 |
| 0x194 (404) | Port for C2 Host 3 |
| 0x196 (406) | Port for C2 Host 4 |
| 0x198 (408) | Unknown 21 bytes |
| 0x1AD (429) | Proxy address 1 |
| 0x22A (554) | Proxy username 1 |
| 0x2A7 (679) | Proxy password 1 |
| 0x324 (804) | Proxy address 2 |
| 0x3A1 (929) | Proxy username 2 |
| 0x41E (1054) | Proxy password 2 |
The backdoor creates a TCP socket and connects to the C2 server defined in the configuration. If proxy details are provided, it attempts to establish the C2 connection through the proxy. The proxy request uses the following format:
CONNECT %s:%d HTTP/1.1
Proxy-Connection: Keep-Alive
Host: %s:%d
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/86.0.4240.75 Safari/537.36
After successfully connecting to the C2 server, it generates a random 32‑byte (0x20) network key that will be used to encrypt and decrypt network packets. This key is appended to the magic dword, as shown in the table below, creating a 40‑byte block that is then encrypted with a custom algorithm: a series of arithmetic and logical operations that differs from the one used to decrypt the configuration.
| Field offset | Field size (in bytes) | Field value |
| 0x00 (00) | 0x04 (04) | 0x0C7FFBE86h (magic dword) |
| 0x04 (04) | 0x04 (04) | 0 |
| 0x08 (08) | 0x20 (32) | Network key (will be used to encrypt and decrypt network traffic) |
It then prepares a packet to send the key to the command‑and-control server, as shown in the table below. The packet contains a 0xC (12‑byte) header, a 0x28 (40‑byte) block of encrypted network‑key data (see the table above), and a randomly generated payload whose size ranges from 0x14 (20) to 0xB4 (180) bytes.
| Field offset | Field size (in bytes) | Field value |
| 0x00 (00) | 0x08 (08) | data_size (encrypted_key_data + random_bytes_size) |
| 0x08 (08) | 0x04 (04) | data_size XORed with 0x39 |
| 0x0C (12) | 0x28 (40) | Encrypted network key data (as mentioned in above table) |
| 0x34 (52) | size between 0x14 (20) and 0xB4 (180) | Random data bytes |
After sending the key, the backdoor collects the following victim information: local computer name, DNS domain assigned to the local computer, user’s logon name, processor architecture, OS major version and build number, host IP address, current process ID, tick count value, and backdoor module name. The collected victim information is first compressed and then encrypted using the network key. The custom algorithm (a series of arithmetic and logical operations) used to encrypt collected victim information is different from the algorithms used to decrypt the configuration and encrypt the network key. Before sending the victim information, a 0x0F (15) byte header is generated and encrypted using the same custom algorithm used to encrypt the collected victim data. The header follows the format as shown in the table below.
| Field offset | Field size (in bytes) | Field value |
| 0x00 (00) | 0x04 (04) | 0xC7FFBE86 (magic dword) |
| 0x04(04) | 0x04 (04) | Message type (1 means victim information) |
| 0x08 (08) | 0x04 (04) | Data size (size of encrypted victim information) |
| 0x0C (12) | 0x01 (01) | Compression flag (1 means compressed) |
| 0x0D (13) | 0x02 (02) | Size of random bytes, between 0x14 and 0x96 bytes |
Finally, the encrypted header and victim information are formatted as shown below and transmitted to the C2 server.
<random_dword><encrypted header><encrypted victim information><random bytes>
Once the backdoor has transmitted the victim information, it waits for a 0x13‑byte (19‑byte) response from the C2 server. This response follows the structure presented in the table below.
| Field offset | Field size (in bytes) | Field value |
| 0x00 (00) | 0x04 (04) | Random dword |
| 0x04 (04) | 0x0F (15) | Encrypted header data |
The encrypted header contained in the response is decrypted with the network key that was generated and shared with the C2 server. After decryption, the header retains the same size and structure as the one used in the victim information message.
The message type field in the header (offset 0x04) determines which operation (command) to perform. Next, the backdoor figures out the size of the command data to receive by adding up the size of the encrypted data (found at position 0x08 in the received header) and the size of the random bytes (found at position 0x0D in the received header). The received command data is first decompressed, based on the compression flag located at position 0x0D in the received header, and then decrypted using the custom algorithm that was used to encrypt the sent data. The backdoor supports the following commands:
| Command (message type) | Description |
| 03 | Based on subcommand, perform the following operations:
00: Get target system’s local time
01: Set sleep time in milliseconds, after which to reconnect to the C2 server |
| 04 | Send current backdoor configuration |
| 05 | Update backdoor configuration |
| 06 | Receive and inject additional payloads (plugins) into memory. Based the on subcommand, perform the following operations:
01: Inject payload (plugin) bytes into memory and execute payload’s entry point
03: Call export method of injected plugin |
Post-compromise activity
The threat actor operating the SilkLurk backdoor first used it to invoke cmd.exe to launch PowerShell. Within PowerShell, they ran commands such as net use to connect to shared network resources with administrative credentials. After establishing the connection, they searched the shared drives for confidential documents to exfiltrate. Once the search was complete, they disconnected from the network share to erase evidence of which internal servers had been accessed. To archive the stolen data, they employed legitimate archiving tools: WinRAR and 7‑Zip.

Below are the paths and names of the WinRAR and 7Zip binaries used by the attackers.
| WinRAR | 18dc8bff47cc282508354771d0c8cf8c | C:\Users\[username]\Libraries\RecordedTV.exe
C:\Users\[username]\Libraries\recordutil.exe |
| 7Zip | 9a1dd1d96481d61934dcc2d568971d06 | C:\windows\vss\7z.exe |
Second-stage payload
PlugX
The SilkLurk backdoor opened a command shell (cmd.exe). Using this shell, the attacker executed the file C:\ProgramData\microsoft\html help\kmsonline.exe (MD5: 3c9a1ba8e0c7475706adc6376e9d7b7c). The kmsonline.exe binary acted as a dropper for the PlugX malware, deploying the malicious files listed below.
C:\ProgramData\Symantec\RasTls.exe - Legitimate Binary (MD5 62944e26b36b1dcace429ae26ba66164)
C:\ProgramData\Symantec\RasTls.dll - PlugX Loader Dll (MD5 ef59aad625eebda8650aec5820d6ce69)
C:\ProgramData\Symantec\RasTls.dll.res - PlugX Payload file
Our Kaspersky Threat Attribution Engine (KTAE) also identified a strong degree of similarity between kmsonline.exe (MD5: 3c9a1ba8e0c7475706adc6376e9d7b7c) and PlugX.

PlugX was configured to communicate with the C2 domain gycudore[.]kozow[.]com and the IP address 64[.]7[.]198[.]130. Below are the extracted configuration fields from PlugX.
| Config field name | Value |
| Injection Target Process | %SystemRoot%\system32\svchost.exe |
| Home Directory | %ALLUSERSPROFILE%\Symantec |
| Persistence Name | SymantecRAS |
| Service Display Name | SymantecRAS |
| Service Description | Symantec RAS Services |
| Campaign ID | KG_MFA |
Infrastructure
The threat infrastructure relies on VPS servers. Some OctLurk and LurkProxy C2 addresses are referenced in a public report by Kazakhstan’s State Technical Service (STS) company. According to available data, a campaign targeting critical infrastructure in Kazakhstan was discovered in March 2025. During this campaign, attackers employed the TrustFall (STS internal designation) remote access malware, also known as MystRodX (Qianxin) and SilentRaid (Cisco) and designed for Linux-based operating systems. Subsequently, in October 2025, STS researchers found additional TrustFall samples, while also discovering its new C2 servers via active probing. Notably, three observed TrustFall C2 addresses were also leveraged by OctLurk and LurkProxy. This overlap points to shared infrastructure across multiple OS-targeting campaigns, though it remains unclear whether these activities ran concurrently or at different times.
Attribution
We identified multiple artifacts confirming that OctLurk and SilkLurk are operated by the same threat actor. Several users infected with OctLurk were also found to be infected with SilkLurk, and in some cases both malware families used the same staging directory. Below are examples of these artifacts.
- In one incident, the attackers created the service
C:\Windows\system32\svchost.exe -k ExAstSrc -s ExAstSrc to deploy OctLurk. They used OctLurk to obtain a command shell and were observed dropping the SilkLurk loader vulkan-1.dll (MD5 be4731c09734da2e8eb6814a9c82f266) via this shell, as shown below.

- In another incident, we observed attackers using the same directory
C:\ProgramData\intel\ to drop both the OctLurk and SilkLurk loader DLLs.
| OctLurk | C:\ProgramData\intel\mscastrac.dll (MD5 7c2f64461bb519c6cbf1fc687675514c)
C:\ProgramData\intel\msbasesysdc.dll (MD5 f4578e869a735cfad691f927bae3e638) |
| SilkLurk | C:\ProgramData\intel\vulkan-1.dll (MD5 2f18472866f38c1e1c2c5c14b9a6ab56) |
In one incident, the attacker used SilkLurk to obtain a command shell (cmd.exe) and then deployed and executed the PlugX malware. The PlugX sample was configured to contact gycudore[.]kozow[.]com as its command‑and‑control (C2) server, while the SilkLurk backdoor used ctyuhjerf[.]kozow[.]com for C2. PlugX is a well‑known modular remote‑access Trojan (RAT) that has been active since at least 2008 and historically linked to Chinese-speaking threat actors. This suggests that both OctLurk and SilkLurk were also developed and operated by a Chinese‑speaking actor, although at this time, we cannot attribute this activity to a known threat group.
Conclusions
The emergence of the OctLurk and SilkLurk multi‑plugin malware framework highlights how threat actors continuously refine their tactics to evade detection and maintain control over compromised networks. Both families operate primarily in memory, leaving only a minimalistic loader on disk that relies on machine‑specific data (OctLurk uses the drive serial number, and SilkLurk uses the computer name) to decode payload locations and contents. This victim‑specific encoding makes reverse engineering and automated detection considerably harder.
In addition to sophisticated obfuscation, the attackers establish redundant access channels, harvest credentials, and deploy well‑known remote access and monitoring tools. These secondary pathways ensure persistence even if the original infection vector is discovered or neutralized.
Indicators of Compromise
Additional IoCs are available to customers of our Threat Intelligence Reporting service. For more details, contact us at intelreports@kaspersky.com.
Backdoor domains and IPs
OctLurk C2
dns[.]multitoconference[.]com
tj[.]tajikistandip[.]com
fm01[.]clouddevicemetrics[.]com
confbase[.]mdpsupport[.]net
digital[.]leroymerling[.]com
api2[.]annoyingremote[.]com
about[.]blsouqs[.]com
ssl[.]blsouqs[.]com
45[.]138[.]157[.]165
LurkProxy C2
dns[.]ssentialserv[.]xyz
154[.]196[.]162[.]76
SilkLurk C2
tyhbgtyuj[.]gleeze[.]com
95[.]179[.]210[.]138
wedfcvbn[.]gleeze[.]com
45[.]77[.]136[.]228
rgnojb[.]casacam[.]net
95[.]179[.]141[.]26
ctyuhjerf[.]kozow[.]com
45[.]32[.]152[.]50
212[.]11[.]39[.]138
195[.]86[.]120[.]2
uyhvfredc[.]accesscam[.]org
154[.]196[.]187[.]73
45[.]61[.]149[.]112
wedfcvbn[.]gleeze[.]com
45[.]77[.]136[.]228
gycudore[.]kozow[.]com
64[.]7[.]198[.]130
Loaders
OctLurk loader
082d49ef9f14e6811d68c7e0e82e5069 oleasapi.dll
f4578e869a735cfad691f927bae3e638 msbasesysdc.dll
7c2f64461bb519c6cbf1fc687675514c mscastrac.dll
SilkLurk loader
8269d6ba1b6842f9152c90cf7add9b93 vulkan-1.dll
PlugX dropper
3c9a1ba8e0c7475706adc6376e9d7b7c kmsonline.exe
PlugX loader
ef59aad625eebda8650aec5820d6ce69 RasTls.dll
OctLurk backdoor
a0cc7accc79abb0287aaba825d0351f0
OctLurk File Manager plugin
a56cce62930a6bee80d679b4c495a340
OctLurk Command Shell plugin
1415a78b75de7db4ba3d1e61d7db4501
OctLurk Interaction Manager plugin
a4d550a3ba0cd073fe3839b99d98a7a8
Impacket’s secretsdump (not available)
32a5985543433a4f60da2fafd873b927 Adobe.exe
Keylogger
2a571f6cee42a17d873f4c942649813f AnyDesk.exe
Browser password stealer
37dc84e4bcad92fa28f1e7778d088283 x64.exe
FSCAN
cf903e4a1629aa0582fd0363b5786676 fc.exe
Batch scripts (not available)
6ecf84fb18f6747ed08d7598364d853a 1.bat
b874123a80fc4f40e06872b9cb54ebc6 auto.bat
45cf5916fab4272a1313c26e67aa9220 in.bat
4e6d5c4770d5a822d7fcce6a74f7ad73 in.bat
5e26df131ff0a679a0a2699b723b46e3 1.bat
Archive utilities
WinRAR
18dc8bff47cc282508354771d0c8cf8c RecordedTV.exe, recordutil.exe
7zip
9a1dd1d96481d61934dcc2d568971d06 7z.exe
File paths
OctLurk file paths
C:\Users\[username]\Videos\1.bat
C:\Windows\System32\oleasapi.dll
C:\Windows\Media\Welcome01.wav
C:\windows\temp\in.bat
C:\Users\[username]\1.bat
C:\ProgramData\1.bat
C:\Windows\System32\msbasesysdc.dll
C:\Windows\System32\Waavsstrace.dll
C:\Windows\System32\SystemSettings.Publishing.dll
C:\Windows\System32\msdctries.dll
C:\Users\Public\Pictures\AnyDesk.exe
C:\Users\Public\Libraries\msect\dev0
C:\Users\Public\Libraries\msect\dev1
C:\users\[username]\libraries\64.exe
C:\ProgramData\Ehorus\
%TEMP%\fc.exe
SilkLurk file paths
C:\programdata\microsoft\network\connections\nvgwls.exe
C:\ProgramData\Veeam\EndpointData\nvgwls.exe
c:\ProgramData\microsoft\network\connections\vulkan-1.dll
C:\ProgramData\microsoft\network\downloader\vulkan-1.dll
C:\ProgramData\intel\vulkan-1.dll
C:\Users\Public\Music\vulkan-1.dll
C:\ProgramData\HP\NCCOM\vulkan-1.dll
C:\ProgramData\intel\gcc\vulkan-1.dll
C:\Windows\System32\0409\vulkan-1.dll
C:\ProgramData\veeam\endpointdata\vulkan-1.dll
C:\ProgramData\plug\vulkan-1.dll
C:\Program Files\nvidia corporation\display.nvcontainer\plugins\vulkan-1.dll
C:\ProgramData\microsoft onedrive\setup\vulkan-1.dll
C:\vmware\vmware tools\vmware vgauth\schemas\vulkan-1.dll
C:\ProgramData\nvidia\ngx\vulkan-1.dll
C:\ProgramData\microsoft\microsoft\vulkan-1.dll
C:\ProgramData\usoprivate\updatestore\vulkan-1.dll
C:\ProgramData\Microsoft OneDrive\setup\OneDrive.dat
C:\ProgramData\NVIDIA\DisplayDriverContainer1.log
C:\ProgramData\Microsoft\Diagnosis\ETLLogs\ETL.log
C:\ProgramData\NVIDI\NGX\ngx.dat
C:\ProgramData\Intel\GCC\2024.log
C:\ProgramData\veem\pyshellext.amd64.log
C:\ProgramData\Microsoft\RtkNGUI\RtkNGUI64.exe
C:\ProgramData\microsoft\rtkngui\RtkNGUI64Loc.dll
C:\ProgramData\realtek\audio\RtkNGUI64Loc.dll
C:\realtek\audio\RtkNGUI64Loc.dll
C:\ProgramData\USOPrivate\UpdateStore\Store.dat
C:\ProgramData\Microsoft\Crypto\Keys\Store.key
C:\DrvPath\Network\Lan\Realtek\NetSetSvc.exe
C:\drvpath\network\lan\realtek\nvml.dll
C:\microsoft\network\connections\nvml.dll
C:\ProgramData\microsoft\network\connections\nvml.dll
C:\Windows\System32\0419\nvml.dll
C:\veeam\nvml.dll
C:\microsoft\network\nvml.dll
C:\ProgramData\hp\nvml.dll
C:\usoprivate\updatestore\nvml.dll
c:\nvidia corporation\display.nvcontainer\plugins\nvml.dll
C:\Users\Public\Pictures\image.png
C:\Users\Public\Documents\My Pictures\image.png
C:\ProgramData\Realtek\Audio\RtkSmbus.exe
C:\ProgramData\realtek\audio\RtkSmbusLoc.dll
C:\rtksmbusact\RtkSmbusLoc.dll
C:\ProgramData\rtksmbusact\RtkSmbusLoc.dll
C:\realtek\audio\RtkSmbusLoc.dll
PlugX file paths
C:\ProgramData\microsoft\html help\kmsonline.exe
C:\ProgramData\Symantec\RasTls.exe
C:\ProgramData\Symantec\RasTls.dll
C:\ProgramData\Symantec\RasTls.dll.res
WinRAR and 7z file paths
C:\Users\[username]\Libraries\RecordedTV.exe
C:\Users\[username]\Libraries\recordutil.exe
C:\windows\vss\7z.exe
securelist.com/octlurk-silklur…

 - Collegamento all'originale")



































")





josh g.
in reply to Lorenzo Franceschi-Bicchierai • • •