 - Collegamento all'originale")
Why Samsung Phones Are Failing Emergency Calls In Australia

We’re taught how to call emergency numbers from a young age; whether it be 911 in the US, 999 in the UK, or 000 in Australia. The concept is simple—if you need aid from police, fire, or ambulance, you pick up a phone and dial and help will be sent in short order.
It’s a service many of us have come to rely on; indeed, it’s function can swing the very balance between life or death. Sadly, in Australia, that has come to pass, with a person dying when their Samsung phone failed to reach the Triple Zero (000) emergency line. It has laid bare an obscure technical issue that potentially leaves thousands of lives at risk.
Peril

Australia’s Triple Zero emergency service becoming a hot-button issue. September 2025 saw widespread failures of emergency calls on the Optus network, an incident that was tied to at least three deaths of those unable to reach help. A series of further isolated cases have drawn more attention to edge case failures that have prevented people from reaching emergency services.
A bigger potential issue with the Triple Zero service has since bubbled up with the increased scrutiny on the system’s operation. Namely, the fact that a huge swathe of older Samsung smartphones cannot be trusted to successfully call 000 in an emergency. The potential issue has been on the radar of telcos and authorities since at least 2024. Since then, on November 13 2025, an individual in Sydney passed away after their phone failed to dial the emergency line. Their phone was using a Lebara SIM card, as managed by TPG and using the Vodafone network, when the incident occurred. Subsequent investigation determined that the problem was due to issues already identified with a wide range of Samsung phones.
The issue surrounds the matter of Australia’s shutdown of 3G phone service, which took place from 2023 to 2024. If you had a 3G phone, it would no longer be able to make any calls after the networks were shut down. Common sense would suggest that phones with 4G and 5G connectivity would be fine going forward. However, there was a caveat. There were a number of phones sold that offered 4G or 5G data connections, but could not actually make phone calls on these networks. This was due to manufacturers failing to implement Voice-over-LTE (VoLTE) functionality required to carry voice calls over 4G LTE networks. Alternatively, in some cases, the 4G or 5G handset could make VoLTE calls, but would fail to make emergency calls in certain situations.
Communication Breakdown
It all comes down to the way voice calls work on 4G and 5G. Unlike earlier 2G and 3G cellular networks, 4G and 5G networks are data only. Phone calls are handled through VoLTE, which uses voice-over-IP technology, or using Voice over NR (VoNR) in a purely 5G environment. Either way, the system is a data-based, packet-switched method of connecting a phone call, unlike the circuit-switched methods used for 2G and 3G calling.
The problem with this is that while 2G and 3G emergency calls worked whenever you had a tower nearby, VoLTE calling is more complex and less robust. VoLTE standards don’t guarantee that a given handset will be interoperable with all LTE networks, particularly when roaming. A given handset might only like IPv4, for example, which may be fine in its home region on its regular carrier. However, when roaming, or when doing an emergency call, that handset might find itself only in range of a different network’s towers, which only like IPv6, and thus VoLTE calling will fail. There are any number of other configuration mismatches that can occur between a handset and a network that can also cause VoLTE calling to fail.
Usually, when you’re in range of your phone’s home network with a modern 4G or 5G handset, you won’t have any problems. Your phone will use its VoLTE settings profile to connect and the emergency call will go through. After all, older models with no VoLTE support have by and large been banned from networks already. However, the situation gets more complex if your home network isn’t available. In those cases, it will look to “camp on” to another provider’s network for connectivity. In this case, if the phone’s VoLTE settings aren’t compatible with the rival network, the call may fail to connect, and you might find yourself unable to reach emergency services.
Specifically, in the Australian case, this appears to affect a range of older Samsung phones. Testing by telecommunications company Telstra found that some of these phones were unable to make Triple Zero emergency calls when only the Vodafone network was available. These phones will happily work when a Telstra or Optus network is available, but fallback to the Vodafone network has been found to fail. Research from other sources has also identified that certain phones can reach Triple Zero when using Telstra or Optus SIM cards, but may fail when equipped with a Vodafone SIM.
For its part, Samsung has provided a list of models affected by the issue. Some older phones, mostly from 2016 and 2017, will need to be replaced, as they will not be updated to reliably make emergency calls over 4G networks. Meanwhile, newer phones, like the Galaxy S20+ and Galaxy S21 Ultra 5G, will be given software updates to enable reliable emergency calling. Telecom operators have been contacting users of affected phones, indicating they will need to replace or upgrade as necessary. Devices that are deemed to be unable to safely make emergency calls will be banned from Australian mobile networks 28 days after initial notification to customers.
Broader Problem

This issue is not limited to just Australia. Indeed, European authorities have been aware of issues with VoLTE emergency calling since at least 2022. Many phones sold in European markets are only capable of making emergency calls on 2G and 3G networks, and could fail to reach emergency services if only 4G connections are available. This issue was particularly noted to be a risk when roaming internationally, where a handset sold in one country may prove inoperable with VoLTE calling on a foreign network.
Some blame has been laid on the loose standardization of the VoLTE standard. Unlike 2G and 3G standards, global interoperability is pretty much non-existent when it comes to phone calls. This wasn’t seen as a big issue early on, as when 4G devices first hit the market, 2G and 3G phone networks were readily available to carry any voice calls that couldn’t be handled by VoLTE. However, with 2G and 3G networks shutting down, the lack of VoLTE standardization and interoperability between carriers has been laid bare.
While Australia is currently tangling with this issue, expect it to crop up in other parts of the world before long. Europe is currently working towards 2G and 3G shutdowns, as our other jurisdictions, and issues around roaming functionality still loom large for those taking handsets overseas. Ultimately, end users will be asking a very simple question. If 2G and 3G technologies could handle emergency calls on virtually any compatible network around the world, how did it go so wrong when 4G and 5G rolled around? Old networks existed as a crutch that avoided the issue for a time, but they were never going to last forever. It surely didn’t have to be this way.

Smart Bandage Leverages AI Model For Healing Purposes

If you get a small cut, you might throw a plastic bandage on it to help it heal faster. However, there are fancier options on the horizon, like this advanced AI-powered smart bandage.
Researchers at UC Santa Cruz have developed a proof-of-concept device called a-Heal, intended for use inside existing commercial bandages for colostomy use. The device is fitted with a small camera, which images the wound site every two hours. The images are then uploaded via a wireless connection, and processed with a machine learning model that has been trained to make suggestions on how to better stimulate the healing process based on the image input. The device can then follow these recommendations, either using electrical stimulation to reduce inflammation in the wound, or supplying fluoxetine to stimulate the growth of healthy tissue. In testing, the device was able to improve the rate of skin coverage over an existing wound compared to a control.
The long-term goal is to apply the technology in a broader sense to help better treat things like chronic or infected wounds that may have difficulty healing. It’s still at an early stage for now, but it could one day be routine for medical treatment to involve the use of small smart devices to gain a better rolling insight on the treatment of wounds. It’s not the first time we’ve explored innovative methods of wound care; we’ve previously looked at how treatments from the past could better inform how we treat in future.
WhatsApp, maxi–fuga di dati: 3,5 miliardi di numeri “rubati” dai ricercatori dell’Università di Vienna
La portata della fuga di notizie, descritta da un team dell’Università di Vienna, dimostra quanto possa essere pericolosa la familiare funzione di ricerca contatti delle app di messaggistica più diffuse.
WhatsApp ha sempre enfatizzato la facilità di aggiunta di nuove persone: basta inserire un numero di telefono nella propria rubrica e il servizio rivela immediatamente se la persona è registrata sull’app, rivelandone nome, foto e profilo parziale. Tuttavia, questa semplicità è diventata la base per una delle più grandi raccolte di dati utente della storia, e tutto ciò è avvenuto senza hackeraggi o aggirando barriere tecniche.
Ricercatori austriaci hanno deciso di testare se la ricerca automatizzata di numeri di telefono potesse rivelare esattamente chi stava usando WhatsApp. Hanno avviato il processo e, nel giro di poche ore, è diventato chiaro che non c’erano praticamente limiti. Il servizio consentiva un numero illimitato di richieste tramite la versione web e, di conseguenza, il team è stato in grado di creare un database di 3,5 miliardi di numeri, raccogliendo essenzialmente informazioni su ogni utente WhatsApp del pianeta. Per quasi il 57% dei record, sono stati in grado di ottenere foto del profilo e per quasi un terzo, stati testuali, che molte persone usano come breve presentazione di sé.

Secondo gli stessi ricercatori, questa sarebbe stata la più grande fuga di dati di numeri di telefono ed elementi di profili pubblici mai registrata se i dati non fossero stati raccolti esclusivamente per scopi accademici. Hanno segnalato la scoperta in primavera e cancellato l’intero set di dati, ma il sistema è rimasto completamente vulnerabile fino a ottobre, il che significa che un’operazione simile avrebbe potuto essere eseguita da chiunque, dagli spammer alle agenzie governative che monitorano le attività indesiderate sui propri cittadini.
Nonostante le rassicurazioni di Meta sull’implementazione di misure di sicurezza sempre più efficaci contro la raccolta massiva di dati, il team di Vienna afferma di non aver effettivamente riscontrato alcuna limitazione. Hanno sottolineato che WhatsApp aveva segnalato un problema simile già nel 2017: il ricercatore olandese Laurent Kloese aveva descritto un sistema per la verifica massiva dei numeri e aveva dimostrato che poteva raccogliere non solo le informazioni del profilo, ma anche il tempo trascorso online. Anche allora, l’azienda aveva affermato che tutto funzionava nel rispetto delle impostazioni di privacy standard .

Confrontando i risultati attuali con quelli di otto anni fa, si nota quanto sia aumentato il rischio. Mentre in precedenza c’erano decine di milioni di record potenzialmente accessibili, ora più di un terzo della popolazione mondiale utilizza il servizio e il numero stesso ha da tempo cessato di essere casuale. I ricercatori sottolineano che un numero di telefono non può fungere da identificatore segreto: gli intervalli di numeri sono limitati, il che significa che gli attacchi brute-force sono sempre possibili, a meno che non vi siano limiti rigorosi al numero di richieste.
Il team ha anche studiato le caratteristiche dei profili per Paese. Negli Stati Uniti, dei 137 milioni di numeri raccolti, il 44% degli utenti aveva foto pubbliche, mentre circa un terzo aveva stati testuali. In India, dove WhatsApp è significativamente più utilizzato, il 62% dei profili su 750 milioni era pubblico. In Brasile, la cifra era quasi la stessa: il 61% su 206 milioni. Più il servizio è popolare, meno persone modificano le proprie impostazioni sulla privacy e più ampia è la cerchia di coloro che rendono pubbliche le proprie immagini e descrizioni.
Di particolare preoccupazione è stata la scoperta di milioni di numeri di telefono in Paesi in cui WhatsApp è ufficialmente bloccato. I ricercatori hanno trovato 2,3 milioni di tali record in Cina e 1,6 milioni in Myanmar. Queste informazioni consentono alle autorità locali di rintracciare le persone che aggirano i divieti e, in alcuni casi, di utilizzarle come base per un’azione penale. Ci sono segnalazioni di persone detenute in Cina semplicemente per aver utilizzato l’app.
Durante l’analisi delle chiavi utilizzate nel protocollo di crittografia end-to-end per recuperare i messaggi, il team ha notato un’altra anomalia: un numero significativo di valori duplicati. Alcune chiavi sono state utilizzate centinaia di volte e circa due dozzine di numeri di telefono americani erano associati a una chiave nulla. I ricercatori sospettano che si tratti di client WhatsApp di terze parti non ufficiali, utilizzati attivamente da gruppi di truffatori. Ciò è indicato anche dal comportamento di alcuni account con chiavi duplicate: sembravano chiaramente strumenti per frodi o messaggi di massa.
L'articolo WhatsApp, maxi–fuga di dati: 3,5 miliardi di numeri “rubati” dai ricercatori dell’Università di Vienna proviene da Red Hot Cyber.

IT threat evolution in Q3 2025. Mobile statistics
IT threat evolution in Q3 2025. Non-mobile statistics
The quarter at a glance
In the third quarter of 2025, we updated the methodology for calculating statistical indicators based on the Kaspersky Security Network. These changes affected all sections of the report except for the statistics on installation packages, which remained unchanged.
To illustrate the differences between the reporting periods, we have also recalculated data for the previous quarters. Consequently, these figures may significantly differ from the previously published ones. However, subsequent reports will employ this new methodology, enabling precise comparisons with the data presented in this post.
The Kaspersky Security Network (KSN) is a global network for analyzing anonymized threat information, voluntarily shared by users of Kaspersky solutions. The statistics in this report are based on KSN data unless explicitly stated otherwise.
The quarter in numbers
According to Kaspersky Security Network, in Q3 2025:
- 47 million attacks utilizing malware, adware, or unwanted mobile software were prevented.
- Trojans were the most widespread threat among mobile malware, encountered by 15.78% of all attacked users of Kaspersky solutions.
- More than 197,000 malicious installation packages were discovered, including:
- 52,723 associated with mobile banking Trojans.
- 1564 packages identified as mobile ransomware Trojans.
Quarterly highlights
The number of malware, adware, or unwanted software attacks on mobile devices, calculated according to the updated rules, totaled 3.47 million in the third quarter. This is slightly less than the 3.51 million attacks recorded in the previous reporting period.
Attacks on users of Kaspersky mobile solutions, Q2 2024 — Q3 2025 (download)
At the start of the quarter, a user complained to us about ads appearing in every browser on their smartphone. We conducted an investigation, discovering a new version of the BADBOX backdoor, preloaded on the device. This backdoor is a multi-level loader embedded in a malicious native library, librescache.so, which was loaded by the system framework. As a result, a copy of the Trojan infiltrated every process running on the device.
Another interesting finding was Trojan-Downloader.AndroidOS.Agent.no, which was embedded in mods for messaging and other apps. It downloaded Trojan-Clicker.AndroidOS.Agent.bl onto the device. The clicker received a URL from its server where an ad was being displayed, opened it in an invisible WebView window, and used machine learning algorithms to find and click the close button. In this way, fraudsters exploited the user’s device to artificially inflate ad views.
Mobile threat statistics
In the third quarter, Kaspersky security solutions detected 197,738 samples of malicious and unwanted software for Android, which is 55,000 more than in the previous reporting period.
Detected malicious and potentially unwanted installation packages, Q3 2024 — Q3 2025 (download)
The detected installation packages were distributed by type as follows:
Detected mobile apps by type, Q2* — Q3 2025 (download)
* Changes in the statistical calculation methodology do not affect this metric. However, data for the previous quarter may differ slightly from previously published figures due to a retrospective review of certain verdicts.
The share of banking Trojans decreased somewhat, but this was due less to a reduction in their numbers and more to an increase in other malicious and unwanted packages. Nevertheless, banking Trojans, still dominated by Mamont packages, continue to hold the top spot. The rise in Trojan droppers is also linked to them: these droppers are primarily designed to deliver banking Trojans.
Share* of users attacked by the given type of malicious or potentially unwanted app out of all targeted users of Kaspersky mobile products, Q2 — Q3 2025 (download)
* The total may exceed 100% if the same users experienced multiple attack types.
Adware leads the pack in terms of the number of users attacked, with a significant margin. The most widespread types of adware are HiddenAd (56.3%) and MobiDash (27.4%). RiskTool-type unwanted apps occupy the second spot. Their growth is primarily due to the proliferation of the Revpn module, which monetizes user internet access by turning their device into a VPN exit point. The most popular Trojans predictably remain Triada (55.8%) and Fakemoney (24.6%). The percentage of users who encountered these did not undergo significant changes.
TOP 20 most frequently detected types of mobile malware
Note that the malware rankings below exclude riskware and potentially unwanted software, such as RiskTool or adware.
| Verdict | %* Q2 2025 | %* Q3 2025 | Difference in p.p. | Change in ranking |
| Trojan.AndroidOS.Triada.ii | 0.00 | 13.78 | +13.78 | |
| Trojan.AndroidOS.Triada.fe | 12.54 | 10.32 | –2.22 | –1 |
| Trojan.AndroidOS.Triada.gn | 9.49 | 8.56 | –0.93 | –1 |
| Trojan.AndroidOS.Fakemoney.v | 8.88 | 6.30 | –2.59 | –1 |
| Backdoor.AndroidOS.Triada.z | 3.75 | 4.53 | +0.77 | +1 |
| DangerousObject.Multi.Generic. | 4.39 | 4.52 | +0.13 | –1 |
| Trojan-Banker.AndroidOS.Coper.c | 3.20 | 2.86 | –0.35 | +1 |
| Trojan.AndroidOS.Triada.if | 0.00 | 2.82 | +2.82 | |
| Trojan-Dropper.Linux.Agent.gen | 3.07 | 2.64 | –0.43 | +1 |
| Trojan-Dropper.AndroidOS.Hqwar.cq | 0.37 | 2.52 | +2.15 | +60 |
| Trojan.AndroidOS.Triada.hf | 2.26 | 2.41 | +0.14 | +2 |
| Trojan.AndroidOS.Triada.ig | 0.00 | 2.19 | +2.19 | |
| Backdoor.AndroidOS.Triada.ab | 0.00 | 2.00 | +2.00 | |
| Trojan-Banker.AndroidOS.Mamont.da | 5.22 | 1.82 | –3.40 | –10 |
| Trojan-Banker.AndroidOS.Mamont.hi | 0.00 | 1.80 | +1.80 | |
| Trojan.AndroidOS.Triada.ga | 3.01 | 1.71 | –1.29 | –5 |
| Trojan.AndroidOS.Boogr.gsh | 1.60 | 1.68 | +0.08 | 0 |
| Trojan-Downloader.AndroidOS.Agent.nq | 0.00 | 1.63 | +1.63 | |
| Trojan.AndroidOS.Triada.hy | 3.29 | 1.62 | –1.67 | –12 |
| Trojan-Clicker.AndroidOS.Agent.bh | 1.32 | 1.56 | +0.24 | 0 |
* Unique users who encountered this malware as a percentage of all attacked users of Kaspersky mobile solutions.
The top positions in the list of the most widespread malware are once again occupied by modified messaging apps Triada.ii, Triada.fe, Triada.gn, and others. The pre-installed backdoor Triada.z ranked fifth, immediately following Fakemoney – fake apps that collect users’ personal data under the guise of providing payments or financial services. The dropper that landed in ninth place, Agent.gen, is an obfuscated ELF file linked to the banking Trojan Coper.c, which sits immediately after DangerousObject.Multi.Generic.
Region-specific malware
In this section, we describe malware that primarily targets users in specific countries.
| Verdict | Country* | %** |
| Trojan-Dropper.AndroidOS.Hqwar.bj | Turkey | 97.22 |
| Trojan-Banker.AndroidOS.Coper.c | Turkey | 96.35 |
| Trojan-Dropper.AndroidOS.Agent.sm | Turkey | 95.10 |
| Trojan-Banker.AndroidOS.Coper.a | Turkey | 95.06 |
| Trojan-Dropper.AndroidOS.Agent.uq | India | 92.20 |
| Trojan-Banker.AndroidOS.Rewardsteal.qh | India | 91.56 |
| Trojan-Banker.AndroidOS.Agent.wb | India | 85.89 |
| Trojan-Dropper.AndroidOS.Rewardsteal.ab | India | 84.14 |
| Trojan-Dropper.AndroidOS.Banker.bd | India | 82.84 |
| Backdoor.AndroidOS.Teledoor.a | Iran | 81.40 |
| Trojan-Dropper.AndroidOS.Hqwar.gy | Turkey | 80.37 |
| Trojan-Dropper.AndroidOS.Banker.ac | India | 78.55 |
| Trojan-Ransom.AndroidOS.Rkor.ii | Germany | 76.90 |
| Trojan-Dropper.AndroidOS.Banker.bg | India | 75.12 |
| Trojan-Banker.AndroidOS.UdangaSteal.b | Indonesia | 75.00 |
| Trojan-Dropper.AndroidOS.Banker.bc | India | 74.73 |
| Backdoor.AndroidOS.Teledoor.c | Iran | 70.33 |
* The country where the malware was most active.
** Unique users who encountered this Trojan modification in the indicated country as a percentage of all Kaspersky mobile security solution users attacked by the same modification.
Banking Trojans, primarily Coper, continue to operate actively in Turkey. Indian users also attract threat actors distributing this type of software. Specifically, the banker Rewardsteal is active in the country. Teledoor backdoors, embedded in a fake Telegram client, have been deployed in Iran.
Notable is the surge in Rkor ransomware Trojan attacks in Germany. The activity was significantly lower in previous quarters. It appears the fraudsters have found a new channel for delivering malicious apps to users.
Mobile banking Trojans
In the third quarter of 2025, 52,723 installation packages for mobile banking Trojans were detected, 10,000 more than in the second quarter.
Installation packages for mobile banking Trojans detected by Kaspersky, Q3 2024 — Q3 2025 (download)
The share of the Mamont Trojan among all bankers slightly increased again, reaching 61.85%. However, in terms of the share of attacked users, Coper moved into first place, with the same modification being used in most of its attacks. Variants of Mamont ranked second and lower, as different samples were used in different attacks. Nevertheless, the total number of users attacked by the Mamont family is greater than that of users attacked by Coper.
TOP 10 mobile bankers
| Verdict | %* Q2 2025 | %* Q3 2025 | Difference in p.p. | Change in ranking |
| Trojan-Banker.AndroidOS.Coper.c | 13.42 | 13.48 | +0.07 | +1 |
| Trojan-Banker.AndroidOS.Mamont.da | 21.86 | 8.57 | –13.28 | –1 |
| Trojan-Banker.AndroidOS.Mamont.hi | 0.00 | 8.48 | +8.48 | |
| Trojan-Banker.AndroidOS.Mamont.gy | 0.00 | 6.90 | +6.90 | |
| Trojan-Banker.AndroidOS.Mamont.hl | 0.00 | 4.97 | +4.97 | |
| Trojan-Banker.AndroidOS.Agent.ws | 0.00 | 4.02 | +4.02 | |
| Trojan-Banker.AndroidOS.Mamont.gg | 0.40 | 3.41 | +3.01 | +35 |
| Trojan-Banker.AndroidOS.Mamont.cb | 3.03 | 3.31 | +0.29 | +5 |
| Trojan-Banker.AndroidOS.Creduz.z | 0.17 | 3.30 | +3.13 | +58 |
| Trojan-Banker.AndroidOS.Mamont.fz | 0.07 | 3.02 | +2.95 | +86 |
* Unique users who encountered this malware as a percentage of all Kaspersky mobile security solution users who encountered banking threats.
Mobile ransomware Trojans
Due to the increased activity of mobile ransomware Trojans in Germany, which we mentioned in the Region-specific malware section, we have decided to also present statistics on this type of threat. In the third quarter, the number of ransomware Trojan installation packages more than doubled, reaching 1564.
| Verdict | %* Q2 2025 | %* Q3 2025 | Difference in p.p. | Change in ranking |
| Trojan-Ransom.AndroidOS.Rkor.ii | 7.23 | 24.42 | +17.19 | +10 |
| Trojan-Ransom.AndroidOS.Rkor.pac | 0.27 | 16.72 | +16.45 | +68 |
| Trojan-Ransom.AndroidOS.Congur.aa | 30.89 | 16.46 | –14.44 | –1 |
| Trojan-Ransom.AndroidOS.Svpeng.ac | 30.98 | 16.39 | –14.59 | –3 |
| Trojan-Ransom.AndroidOS.Rkor.it | 0.00 | 10.09 | +10.09 | |
| Trojan-Ransom.AndroidOS.Congur.cw | 15.71 | 9.69 | –6.03 | –3 |
| Trojan-Ransom.AndroidOS.Congur.ap | 15.36 | 9.16 | –6.20 | –3 |
| Trojan-Ransom.AndroidOS.Small.cj | 14.91 | 8.49 | –6.42 | –3 |
| Trojan-Ransom.AndroidOS.Svpeng.snt | 13.04 | 8.10 | –4.94 | –2 |
| Trojan-Ransom.AndroidOS.Svpeng.ah | 13.13 | 7.63 | –5.49 | –4 |
* Unique users who encountered the malware as a percentage of all Kaspersky mobile security solution users attacked by ransomware Trojans.
securelist.com/malware-report-…





IT threat evolution in Q3 2025. Non-mobile statistics

IT threat evolution in Q3 2025. Mobile statistics
IT threat evolution in Q3 2025. Non-mobile statistics
Quarterly figures
In Q3 2025:
- Kaspersky solutions blocked more than 389 million attacks that originated with various online resources.
- Web Anti-Virus responded to 52 million unique links.
- File Anti-Virus blocked more than 21 million malicious and potentially unwanted objects.
- 2,200 new ransomware variants were detected.
- Nearly 85,000 users experienced ransomware attacks.
- 15% of all ransomware victims whose data was published on threat actors’ data leak sites (DLSs) were victims of Qilin.
- More than 254,000 users were targeted by miners.
Ransomware
Quarterly trends and highlights
Law enforcement success
The UK’s National Crime Agency (NCA) arrested the first suspect in connection with a ransomware attack that caused disruptions at numerous European airports in September 2025. Details of the arrest have not been published as the investigation remains ongoing. According to security researcher Kevin Beaumont, the attack employed the HardBit ransomware, which he described as primitive and lacking its own data leak site.
The U.S. Department of Justice filed charges against the administrator of the LockerGoga, MegaCortex and Nefilim ransomware gangs. His attacks caused millions of dollars in damage, putting him on wanted lists for both the FBI and the European Union.
U.S. authorities seized over $2.8 million in cryptocurrency, $70,000 in cash, and a luxury vehicle from a suspect allegedly involved in distributing the Zeppelin ransomware. The criminal scheme involved data theft, file encryption, and extortion, with numerous organizations worldwide falling victim.
A coordinated international operation conducted by the FBI, Homeland Security Investigations (HSI), the U.S. Internal Revenue Service (IRS), and law enforcement agencies from several other countries successfully dismantled the infrastructure of the BlackSuit ransomware. The operation resulted in the seizure of four servers, nine domains, and $1.09 million in cryptocurrency. The objective of the operation was to destabilize the malware ecosystem and protect critical U.S. infrastructure.
Vulnerabilities and attacks
SSL VPN attacks on SonicWall
Since late July, researchers have recorded a rise in attacks by the Akira threat actor targeting SonicWall firewalls supporting SSL VPN. SonicWall has linked these incidents to the already-patched vulnerability CVE-2024-40766, which allows unauthorized users to gain access to system resources. Attackers exploited the vulnerability to steal credentials, subsequently using them to access devices, even those that had been patched. Furthermore, the attackers were able to bypass multi-factor authentication enabled on the devices. SonicWall urges customers to reset all passwords and update their SonicOS firmware.
Scattered Spider uses social engineering to breach VMware ESXi
The Scattered Spider (UNC3944) group is attacking VMware virtual environments. The attackers contact IT support posing as company employees and request to reset their Active Directory password. Once access to vCenter is obtained, the threat actors enable SSH on the ESXi servers, extract the NTDS.dit database, and, in the final phase of the attack, deploy ransomware to encrypt all virtual machines.
Exploitation of a Microsoft SharePoint vulnerability
In late July, researchers uncovered attacks on SharePoint servers that exploited the ToolShell vulnerability chain. In the course of investigating this campaign, which affected over 140 organizations globally, researchers discovered the 4L4MD4R ransomware based on Mauri870 code. The malware is written in Go and packed using the UPX compressor. It demands a ransom of 0.005 BTC.
The application of AI in ransomware development
A UK-based threat actor used Claude to create and launch a ransomware-as-a-service (RaaS) platform. The AI was responsible for writing the code, which included advanced features such as anti-EDR techniques, encryption using ChaCha20 and RSA algorithms, shadow copy deletion, and network file encryption.
Anthropic noted that the attacker was almost entirely dependent on Claude, as they lacked the necessary technical knowledge to provide technical support to their own clients. The threat actor sold the completed malware kits on the dark web for $400–$1,200.
Researchers also discovered a new ransomware strain, dubbed PromptLock, that utilizes an LLM directly during attacks. The malware is written in Go. It uses hardcoded prompts to dynamically generate Lua scripts for data theft and encryption across Windows, macOS and Linux systems. For encryption, it employs the SPECK-128 algorithm, which is rarely used by ransomware groups.
Subsequently, scientists from the NYU Tandon School of Engineering traced back the likely origins of PromptLock to their own educational project, Ransomware 3.0, which they detailed in a prior publication.
The most prolific groups
This section highlights the most prolific ransomware gangs by number of victims added to each group’s DLS. As in the previous quarter, Qilin leads by this metric. Its share grew by 1.89 percentage points (p.p.) to reach 14.96%. The Clop ransomware showed reduced activity, while the share of Akira (10.02%) slightly increased. The INC Ransom group, active since 2023, rose to third place with 8.15%.
Number of each group’s victims according to its DLS as a percentage of all groups’ victims published on all the DLSs under review during the reporting period (download)
Number of new variants
In the third quarter, Kaspersky solutions detected four new families and 2,259 new ransomware modifications, nearly one-third more than in Q2 2025 and slightly more than in Q3 2024.
Number of new ransomware modifications, Q3 2024 — Q3 2025 (download)
Number of users attacked by ransomware Trojans
During the reporting period, our solutions protected 84,903 unique users from ransomware. Ransomware activity was highest in July, while August proved to be the quietest month.
Number of unique users attacked by ransomware Trojans, Q3 2025 (download)
Attack geography
TOP 10 countries attacked by ransomware Trojans
In the third quarter, Israel had the highest share (1.42%) of attacked users. Most of the ransomware in that country was detected in August via behavioral analysis.
| Country/territory* | %** | |
| 1 | Israel | 1.42 |
| 2 | Libya | 0.64 |
| 3 | Rwanda | 0.59 |
| 4 | South Korea | 0.58 |
| 5 | China | 0.51 |
| 6 | Pakistan | 0.47 |
| 7 | Bangladesh | 0.45 |
| 8 | Iraq | 0.44 |
| 9 | Tajikistan | 0.39 |
| 10 | Ethiopia | 0.36 |
* Excluded are countries and territories with relatively few (under 50,000) Kaspersky users.
** Unique users whose computers were attacked by ransomware Trojans as a percentage of all unique users of Kaspersky products in the country/territory.
TOP 10 most common families of ransomware Trojans
| Name | Verdict | %* | ||
| 1 | (generic verdict) | Trojan-Ransom.Win32.Gen | 26.82 | |
| 2 | (generic verdict) | Trojan-Ransom.Win32.Crypren | 8.79 | |
| 3 | (generic verdict) | Trojan-Ransom.Win32.Encoder | 8.08 | |
| 4 | WannaCry | Trojan-Ransom.Win32.Wanna | 7.08 | |
| 5 | (generic verdict) | Trojan-Ransom.Win32.Agent | 4.40 | |
| 6 | LockBit | Trojan-Ransom.Win32.Lockbit | 3.06 | |
| 7 | (generic verdict) | Trojan-Ransom.Win32.Crypmod | 2.84 | |
| 8 | (generic verdict) | Trojan-Ransom.Win32.Phny | 2.58 | |
| 9 | PolyRansom/VirLock | Trojan-Ransom.Win32.PolyRansom / Virus.Win32.PolyRansom | 2.54 | |
| 10 | (generic verdict) | Trojan-Ransom.MSIL.Agent | 2.05 |
* Unique Kaspersky users attacked by the specific ransomware Trojan family as a percentage of all unique users attacked by this type of threat.
Miners
Number of new variants
In Q3 2025, Kaspersky solutions detected 2,863 new modifications of miners.
Number of new miner modifications, Q3 2025 (download)
Number of users attacked by miners
During the third quarter, we detected attacks using miner programs on the computers of 254,414 unique Kaspersky users worldwide.
Number of unique users attacked by miners, Q3 2025 (download)
Attack geography
TOP 10 countries and territories attacked by miners
| Country/territory* | %** | ||
| 1 | Senegal | 3.52 | |
| 2 | Mali | 1.50 | |
| 3 | Afghanistan | 1.17 | |
| 4 | Algeria | 0.95 | |
| 5 | Kazakhstan | 0.93 | |
| 6 | Tanzania | 0.92 | |
| 7 | Dominican Republic | 0.86 | |
| 8 | Ethiopia | 0.77 | |
| 9 | Portugal | 0.75 | |
| 10 | Belarus | 0.75 |
* Excluded are countries and territories with relatively few (under 50,000) Kaspersky users.
** Unique users whose computers were attacked by miners as a percentage of all unique users of Kaspersky products in the country/territory.
Attacks on macOS
In April, researchers at Iru (formerly Kandji) reported the discovery of a new spyware family, PasivRobber. We observed the development of this family throughout the third quarter. Its new modifications introduced additional executable modules that were absent in previous versions. Furthermore, the attackers began employing obfuscation techniques in an attempt to hinder sample detection.
In July, we reported on a cryptostealer distributed through fake extensions for the Cursor AI development environment, which is based on Visual Studio Code. At that time, the malicious JavaScript (JS) script downloaded a payload in the form of the ScreenConnect remote access utility. This utility was then used to download cryptocurrency-stealing VBS scripts onto the victim’s device. Later, researcher Michael Bocanegra reported on new fake VS Code extensions that also executed malicious JS code. This time, the code downloaded a malicious macOS payload: a Rust-based loader. This loader then delivered a backdoor to the victim’s device, presumably also aimed at cryptocurrency theft. The backdoor supported the loading of additional modules to collect data about the victim’s machine. The Rust downloader was analyzed in detail by researchers at Iru.
In September, researchers at Jamf reported the discovery of a previously unknown version of the modular backdoor ChillyHell, first described in 2023. Notably, the Trojan’s executable files were signed with a valid developer certificate at the time of discovery.
The new sample had been available on Dropbox since 2021. In addition to its backdoor functionality, it also contains a module responsible for bruteforcing passwords of existing system users.
By the end of the third quarter, researchers at Microsoft reported new versions of the XCSSET spyware, which targets developers and spreads through infected Xcode projects. These new versions incorporated additional modules for data theft and system persistence.
TOP 20 threats to macOS
Unique users* who encountered this malware as a percentage of all attacked users of Kaspersky security solutions for macOS (download)
* Data for the previous quarter may differ slightly from previously published data due to some verdicts being retrospectively revised.
The PasivRobber spyware continues to increase its activity, with its modifications occupying the top spots in the list of the most widespread macOS malware varieties. Other highly active threats include Amos Trojans, which steal passwords and cryptocurrency wallet data, and various adware. The Backdoor.OSX.Agent.l family, which took thirteenth place, represents a variation on the well-known open-source malware, Mettle.
Geography of threats to macOS
TOP 10 countries and territories by share of attacked users
| Country/territory | %* Q2 2025 | %* Q3 2025 |
| Mainland China | 2.50 | 1.70 |
| Italy | 0.74 | 0.85 |
| France | 1.08 | 0.83 |
| Spain | 0.86 | 0.81 |
| Brazil | 0.70 | 0.68 |
| The Netherlands | 0.41 | 0.68 |
| Mexico | 0.76 | 0.65 |
| Hong Kong | 0.84 | 0.62 |
| United Kingdom | 0.71 | 0.58 |
| India | 0.76 | 0.56 |
IoT threat statistics
This section presents statistics on attacks targeting Kaspersky IoT honeypots. The geographic data on attack sources is based on the IP addresses of attacking devices.
In Q3 2025, there was a slight increase in the share of devices attacking Kaspersky honeypots via the SSH protocol.
Distribution of attacked services by number of unique IP addresses of attacking devices (download)
Conversely, the share of attacks using the SSH protocol slightly decreased.
Distribution of attackers’ sessions in Kaspersky honeypots (download)
TOP 10 threats delivered to IoT devices
Share of each threat delivered to an infected device as a result of a successful attack, out of the total number of threats delivered (download)
In the third quarter, the shares of the NyaDrop and Mirai.b botnets significantly decreased in the overall volume of IoT threats. Conversely, the activity of several other members of the Mirai family, as well as the Gafgyt botnet, increased. As is typical, various Mirai variants occupy the majority of the list of the most widespread malware strains.
Attacks on IoT honeypots
Germany and the United States continue to lead in the distribution of attacks via the SSH protocol. The share of attacks originating from Panama and Iran also saw a slight increase.
| Country/territory | Q2 2025 | Q3 2025 |
| Germany | 24.58% | 13.72% |
| United States | 10.81% | 13.57% |
| Panama | 1.05% | 7.81% |
| Iran | 1.50% | 7.04% |
| Seychelles | 6.54% | 6.69% |
| South Africa | 2.28% | 5.50% |
| The Netherlands | 3.53% | 3.94% |
| Vietnam | 3.00% | 3.52% |
| India | 2.89% | 3.47% |
| Russian Federation | 8.45% | 3.29% |
The largest number of attacks via the Telnet protocol were carried out from China, as is typically the case. Devices located in India reduced their activity, whereas the share of attacks from Indonesia increased.
| Country/territory | Q2 2025 | Q3 2025 |
| China | 47.02% | 57.10% |
| Indonesia | 5.54% | 9.48% |
| India | 28.08% | 8.66% |
| Russian Federation | 4.85% | 7.44% |
| Pakistan | 3.58% | 6.66% |
| Nigeria | 1.66% | 3.25% |
| Vietnam | 0.55% | 1.32% |
| Seychelles | 0.58% | 0.93% |
| Ukraine | 0.51% | 0.73% |
| Sweden | 0.39% | 0.72% |
Attacks via web resources
The statistics in this section are based on detection verdicts by Web Anti-Virus, which protects users when suspicious objects are downloaded from malicious or infected web pages. These malicious pages are purposefully created by cybercriminals. Websites that host user-generated content, such as message boards, as well as compromised legitimate sites, can become infected.
TOP 10 countries that served as sources of web-based attacks
This section gives the geographical distribution of sources of online attacks (such as web pages redirecting to exploits, sites hosting exploits and other malware, and botnet C2 centers) blocked by Kaspersky products. One or more web-based attacks could originate from each unique host.
To determine the geographic source of web attacks, we matched the domain name with the real IP address where the domain is hosted, then identified the geographic location of that IP address (GeoIP).
In the third quarter of 2025, Kaspersky solutions blocked 389,755,481 attacks from internet resources worldwide. Web Anti-Virus was triggered by 51,886,619 unique URLs.
Web-based attacks by country, Q3 2025 (download)
Countries and territories where users faced the greatest risk of online infection
To assess the risk of malware infection via the internet for users’ computers in different countries and territories, we calculated the share of Kaspersky users in each location on whose computers Web Anti-Virus was triggered during the reporting period. The resulting data provides an indication of the aggressiveness of the environment in which computers operate in different countries and territories.
This ranked list includes only attacks by malicious objects classified as Malware. Our calculations leave out Web Anti-Virus detections of potentially dangerous or unwanted programs, such as RiskTool or adware.
| Country/territory* | %** | ||
| 1 | Panama | 11.24 | |
| 2 | Bangladesh | 8.40 | |
| 3 | Tajikistan | 7.96 | |
| 4 | Venezuela | 7.83 | |
| 5 | Serbia | 7.74 | |
| 6 | Sri Lanka | 7.57 | |
| 7 | North Macedonia | 7.39 | |
| 8 | Nepal | 7.23 | |
| 9 | Albania | 7.04 | |
| 10 | Qatar | 6.91 | |
| 11 | Malawi | 6.90 | |
| 12 | Algeria | 6.74 | |
| 13 | Egypt | 6.73 | |
| 14 | Bosnia and Herzegovina | 6.59 | |
| 15 | Tunisia | 6.54 | |
| 16 | Belgium | 6.51 | |
| 17 | Kuwait | 6.49 | |
| 18 | Turkey | 6.41 | |
| 19 | Belarus | 6.40 | |
| 20 | Bulgaria | 6.36 |
* Excluded are countries and territories with relatively few (under 10,000) Kaspersky users.
** Unique users targeted by web-based Malware attacks as a percentage of all unique users of Kaspersky products in the country/territory.
On average, over the course of the quarter, 4.88% of devices globally were subjected to at least one web-based Malware attack.
Local threats
Statistics on local infections of user computers are an important indicator. They include objects that penetrated the target computer by infecting files or removable media, or initially made their way onto the computer in non-open form. Examples of the latter are programs in complex installers and encrypted files.
Data in this section is based on analyzing statistics produced by anti-virus scans of files on the hard drive at the moment they were created or accessed, and the results of scanning removable storage media: flash drives, camera memory cards, phones, and external drives. The statistics are based on detection verdicts from the on-access scan (OAS) and on-demand scan (ODS) modules of File Anti-Virus.
In the third quarter of 2025, our File Anti-Virus recorded 21,356,075 malicious and potentially unwanted objects.
Countries and territories where users faced the highest risk of local infection
For each country and territory, we calculated the percentage of Kaspersky users on whose computers File Anti-Virus was triggered during the reporting period. This statistic reflects the level of personal computer infection in different countries and territories around the world.
Note that this ranked list includes only attacks by malicious objects classified as Malware. Our calculations leave out File Anti-Virus detections of potentially dangerous or unwanted programs, such as RiskTool or adware.
| Country/territory* | %** | ||
| 1 | Turkmenistan | 45.69 | |
| 2 | Yemen | 33.19 | |
| 3 | Afghanistan | 32.56 | |
| 4 | Tajikistan | 31.06 | |
| 5 | Cuba | 30.13 | |
| 6 | Uzbekistan | 29.08 | |
| 7 | Syria | 25.61 | |
| 8 | Bangladesh | 24.69 | |
| 9 | China | 22.77 | |
| 10 | Vietnam | 22.63 | |
| 11 | Cameroon | 22.53 | |
| 12 | Belarus | 21.98 | |
| 13 | Tanzania | 21.80 | |
| 14 | Niger | 21.70 | |
| 15 | Mali | 21.29 | |
| 16 | Iraq | 20.77 | |
| 17 | Nicaragua | 20.75 | |
| 18 | Algeria | 20.51 | |
| 19 | Congo | 20.50 | |
| 20 | Venezuela | 20.48 |
* Excluded are countries and territories with relatively few (under 10,000) Kaspersky users.
** Unique users on whose computers local Malware threats were blocked, as a percentage of all unique users of Kaspersky products in the country/territory.
On average worldwide, local Malware threats were detected at least once on 12.36% of computers during the third quarter.
securelist.com/malware-report-…










Charge NiMH Batteries with Style, Panache and an RP2040

The increasing dominance of lithium cells in the market place leave our trusty NiMH cells in a rough spot. Sure, you can still get a chargers for the AAs in your life, but it’s old tech and not particularly stylish. That’s where [Maximilian Kern] comes in, whose SPINC project was recently featured in IEEE Spectrum— so you know it has to be good.
With the high-resolution LED, the styling of this device reminds us a little bit of the Pi-Mac-Nano— and anything that makes you think of a classic Macintosh gets automatic style points. There’s something reminiscent of an ammunition clip in the way batteries are fed into the top and let out the bottom of the machine.
[Maximilian] thought of the, ah, less-detail-oriented amongst us with this one, as the dedicated charging IC he chose (why reinvent the wheel?) is connected to an H-bridge to allow the charger to be agnostic as to orientation. That’s a nice touch. An internal servo grabs each battery in turn to stick into the charging circuit, and deposits it into the bottom of the device once it is charged. The LCD screen lets you monitor the status of the battery as it charges, while doubling as a handy desk clock (that’s where the RP2040 comes in). It is, of course, powered by USB-C-PD as all things are these days. Fast-charging upto 1A is enabled, but you might want to go slower to keep your cells lasting as long as possible. Firmware, gerbers and STLs are available on GitHub under a GPL-3.0 license– so if you’re still using NiCads or want to bring this design into the glorious lithium future, you can consider yourself welcome to.
We recently featured a AA rundown, and for now, it looks like NiMH is still the best bang for your buck, which means this project will remain relevant for a few years yet. Of course, we didn’t expect the IEEE to steer us wrong.
Thanks to [George Graves] for the tip.
DK 10x11 - Fermate Idiocracy, voglio scendere!
Difficile mantenere la sanità mentale con tutto quello che succede in giro...
spreaker.com/episode/dk-10x11-…
Cloudflare blackout globale: si è trattato di un errore tecnico interno. Scopriamo la causa
Il 18 novembre 2025, alle 11:20 UTC, una parte significativa dell’infrastruttura globale di Cloudflare ha improvvisamente cessato di instradare correttamente il traffico Internet, mostrando a milioni di utenti di tutto il mondo una pagina di errore HTTP che riportava un malfunzionamento interno della rete dell’azienda.
L’interruzione ha colpito una vasta gamma di servizi – dal CDN ai sistemi di autenticazione Access – generando un’ondata anomala di errori 5xx. Secondo quanto riportato da Cloudflare che lo riporta con estrema trasparenza, la causa non è stata un attacco informatico ma un errore tecnico interno, scatenato da una modifica alle autorizzazioni di un cluster database.
Cloudflare ha precisato fin da subito che nessuna attività malevola, diretta o indiretta, è stata responsabile dell’incidente. L’interruzione, come riporta il comunicato di post mortem, è stata innescata da un cambiamento a un sistema di permessi di un database ClickHouse che, per un effetto collaterale non previsto, ha generato un file di configurazione anomalo utilizzato dal sistema di Bot Management.
Tale “feature file”, contenente le caratteristiche su cui si basa il modello di machine learning anti-bot dell’azienda, ha improvvisamente raddoppiato le sue dimensioni a causa della presenza di numerose righe duplicate.
Questo file, aggiornato automaticamente ogni pochi minuti e propagato rapidamente a tutta la rete globale di Cloudflare, ha superato il limite previsto dal software del core proxy, causando un errore critico.

Il sistema che esegue l’instradamento del traffico – noto internamente come FL e nella sua nuova versione FL2 – utilizza infatti limiti rigidi per la preallocazione di memoria, con un massimo fissato a 200 feature. Il file corrotto ne conteneva più del doppio, facendo scattare un “panic” del modulo Bot Management e interrompendo l’elaborazione delle richieste.
Nei primi minuti dell’incidente, l’andamento irregolare degli errori ha portato i team di Cloudflare a sospettare inizialmente un massiccio attacco DDoS: il sistema sembrava infatti riprendersi spontaneamente per poi ricadere nel guasto, un comportamento insolito per un errore interno.
Questa fluttuazione era dovuta alla natura distribuita dei database coinvolti. Il file veniva generato ogni cinque minuti e, poiché solo alcune parti del cluster erano state aggiornate, il sistema produceva alternativamente file “buoni” e file “difettosi”, propagandoli istantaneamente a tutti i server.
Nell blog si legge :
“Ci scusiamo per l’impatto sui nostri clienti e su Internet in generale. Data l’importanza di Cloudflare nell’ecosistema Internet, qualsiasi interruzione di uno qualsiasi dei nostri sistemi è inaccettabile. Il fatto che ci sia stato un periodo di tempo in cui la nostra rete non è stata in grado di instradare il traffico è profondamente doloroso per ogni membro del nostro team. Sappiamo di avervi deluso oggi“.
Con il passare del tempo, l’intero cluster è stato aggiornato e le generazioni di file “buoni” sono cessate, stabilizzando il sistema nello stato di errore totale. A complicare ulteriormente la diagnosi è intervenuta una coincidenza inaspettata: il sito di stato di Cloudflare, ospitato esternamente e quindi indipendente dall’infrastruttura dell’azienda, è risultato irraggiungibile nello stesso momento, alimentando il timore di un attacco coordinato su più fronti.

La situazione ha iniziato a normalizzarsi alle 14:30 UTC, quando gli ingegneri hanno individuato la radice del problema e interrotto la propagazione del file corrotto. È stato quindi distribuito manualmente un file di configurazione corretto e forzato un riavvio del core proxy. La piena stabilità dell’infrastruttura è stata ripristinata alle 17:06 UTC, dopo un lavoro di recupero dei servizi che avevano accumulato code, latenze e stati incoerenti.
Diversi servizi chiave hanno subito impatti significativi: il CDN ha risposto con errori 5xx, il sistema di autenticazione Turnstile non riusciva a caricarsi, Workers KV restituiva errori elevati e l’accesso alla dashboard risultava bloccato per la maggior parte degli utenti. Anche il servizio Email Security ha visto diminuire temporaneamente la propria capacità di rilevare lo spam a causa della perdita di accesso a una fonte IP reputazionale. Il sistema di Access ha registrato un’ondata di fallimenti di autenticazione, impedendo a molti utenti di raggiungere le applicazioni protette.
L’interruzione ha evidenziato vulnerabilità legate alla gestione distribuita della configurazione e alla dipendenza da file generati automaticamente con aggiornamenti rapidi. Cloudflare ha ammesso che una parte delle deduzioni del suo team durante i primi minuti dell’incidente si è basata su segnali fuorvianti – come il down del sito di stato – che hanno ritardato la corretta diagnosi del guasto. L’azienda ha promesso un piano di intervento strutturato per evitare che un singolo file di configurazione possa nuovamente bloccare segmenti così ampi della sua rete globale.
Cloudflare ha riconosciuto con grande trasparenza la gravità dell’incidente, sottolineando come ogni minuto di interruzione abbia un impatto significativo sull’intero ecosistema Internet, dato il ruolo centrale che la sua rete svolge.
L’azienda ha annunciato che questo primo resoconto sarà seguito da ulteriori aggiornamenti e da una revisione completa dei processi interni di generazione delle configurazioni e gestione degli errori di memoria, con l’obiettivo dichiarato di evitare che un evento simile possa ripetersi.
L'articolo Cloudflare blackout globale: si è trattato di un errore tecnico interno. Scopriamo la causa proviene da Red Hot Cyber.
Il Pledge ‘Secure by Design’ di CISA: un anno di progresso nella sicurezza informatica
A cura di Carl Windsor, Chief Information Security Officer di Fortinet
Le pratiche secure-by-design rappresentano un cambiamento fondamentale nello sviluppo software: la sicurezza non viene più considerata un’aggiunta successiva, ma è integrata fin dalle basi, nel DNA stesso del prodotto. Questa filosofia è ampiamente riconosciuta nel settore come best practice, ma non è ancora obbligatoria, né applicata in modo uniforme o pienamente compresa dai clienti. Tuttavia, adottare un approccio secure by design è sempre più cruciale, poiché le infrastrutture digitali si trovano ad fronteggiare una velocità e un volume senza precedenti di minacce sofisticate. Cybercriminali, sia inesperti che altamente qualificati, sfruttano nuove risorse – dall’acquisto di exploit kit nel dark web all’uso di strumenti automatizzati – per colpire vulnerabilità su larga scala.
Alla RSA Conference 2024, la Cybersecurity and Infrastructure Security Agency (CISA) ha presentato il proprio Secure by Design Pledge, un’iniziativa volta a innalzare il livello minimo di sicurezza informatica in tutto il settore tecnologico, integrando pratiche sicure alla base dello sviluppo dei prodotti e riducendo il rischio sistemico nell’ecosistema digitale. Fortinet è orgogliosa di essere stata tra i primi firmatari di questo impegno, e il nostro Jim Richberg ha avuto un ruolo chiave nella sua definizione.

Sebbene Fortinet sia da tempo in prima linea nell’adozione e nella promozione delle migliori pratiche di cybersecurity, il Secure by Design Pledge rappresenta un passo avanti significativo nel definire e promuovere politiche che impongano a tutti i produttori di software standard più rigorosi. Il Pledge individua sette obiettivi principali, focalizzati sull’integrazione della sicurezza lungo l’intero ciclo di vita dello sviluppo dei prodotti, offrendo ai fornitori di software linee guida concrete per progredire verso tali traguardi.
Adozione e avanzamento dei principi Secure-by-Design in Fortinet
Fortinet adotta molti di questi principi da decenni e, in più occasioni, ha illustrato i progressi compiuti nell’implementazione e nel perfezionamento di tali standard. Di seguito una panoramica delle azioni intraprese da Fortinet per rispondere agli obiettivi del Pledge:
Obiettivo n.1: Dimostrare azioni volte ad aumentare in modo misurabile l’uso dell’autenticazione a più fattori (MFA) nei prodotti del produttore.
Risultato Fortinet: Fortinet ha abilitato l’MFA per gli account cloud dei clienti, con il 95% di questi che utilizza effettivamente questa misura di sicurezza.
Obiettivo n.2: Dimostrare progressi misurabili nella riduzione delle password predefinite nei prodotti del produttore.
Risultato Fortinet: Le password predefinite sono state eliminate nella Fortinet Secure Development Lifecycle Policy e rimosse da tutti i prodotti, imponendo agli utenti la creazione di credenziali uniche durante l’installazione.
Obiettivo n.3: Dimostrare azioni volte a ridurre in modo significativo e misurabile la presenza di una o più classi di vulnerabilità nei prodotti del produttore.
Risultato Fortinet: Fortinet ha intrapreso la rimozione delle vulnerabilità di tipo SQL injection e buffer overflow. Si tratta di un processo continuo che proseguirà nelle future versioni.
Obiettivo n.4: Dimostrare azioni intraprese dai clienti per aumentare in modo misurabile l’installazione di patch di sicurezza.
Risultato Fortinet: Fortinet ha compiuto importanti progressi in questo ambito grazie all’introduzione della funzionalità di auto-update, che ha aggiornato oltre un milione di dispositivi dalla sua implementazione, contribuendo in modo sostanziale alla sicurezza dei clienti.
Obiettivo n.5: Pubblicare una Vulnerability Disclosure Policy (VDP).
Risultato Fortinet: Fortinet è membro del Forum of Incident Response and Security Teams (FIRST), che consente ai suoi oltre 600 membri in più di 100 Paesi di condividere obiettivi, idee e informazioni relative alla gestione degli incidenti di sicurezza e allo sviluppo di programmi di risposta. Fortinet applica le conoscenze acquisite attraverso FIRST per garantire una comunicazione costante con i propri clienti. Inoltre, Fortinet pubblica la propria VDP sulla pagina dedicata al Product Security Incident Response Team (PSIRT) e tramite un file Security.txt.
Obiettivo n.6: Dimostrare trasparenza nella segnalazione delle vulnerabilità.
Risultato Fortinet: Fortinet ha implementato da tempo un programma di trasparenza radicale nella pubblicazione e comunicazione delle Common Vulnerabilities and Exposures (CVE), includendo già i campi Common Weakness Enumeration (CWE) e Common Platform Enumeration (CPE) in ogni CVE. Inoltre, Fortinet è impegnata a divulgare in modo proattivo e trasparente le vulnerabilità attraverso il suo solido programma PSIRT.
Obiettivo n.7: Dimostrare un incremento misurabile della capacità dei clienti di raccogliere evidenze di intrusioni informatiche che coinvolgono i prodotti del produttore.
Risultato Fortinet: A partire dalla versione 7.4.4 di FortiOS, sono state introdotte nuove funzionalità di controllo dell’integrità del file system per rilevare e registrare modifiche o aggiunte non autorizzate ai file. Fortinet continuerà ad aggiungere nuove funzioni con il rilascio delle versioni successive di FortiOS.
Oltre il Pledge: le iniziative aggiuntive di Fortinet
Fortinet adotta ulteriori misure che vanno oltre quanto previsto dal CISA Secure by Design Pledge, tra cui:
- Esecuzione regolare di test e audit approfonditi del codice, oltre a test di penetrazione condotti da terze parti.
- Obiettivi di performance (Management by Objectives) legati alla qualità del codice.
- Lancio di un programma pubblico di bug bounty.
- Collaborazione continua con diverse alleanze di cybersecurity, tra cui la Network Resilience Coalition, la Joint Cyber Defense Collaborative (JCDC) e la Cyber Threat Alliance (CTA), per condividere informazioni sulle minacce e sviluppare strategie volte a migliorare la resilienza cibernetica.
Guardando al futuro
Fortinet continua a lavorare su iniziative volte a incoraggiare i clienti a implementare patch e aggiornamenti, monitorando al contempo l’impatto di tali miglioramenti di sicurezza. Riconosciamo l’importanza di un’adozione su larga scala dei principi secure-by-design per costruire un ecosistema digitale più resiliente – un obiettivo che richiede un forte impegno e collaborazione tra settore pubblico e privato.
Fortinet continuerà a sostenere gli sforzi di organizzazioni come CISA e MITRE, introducendo e rispettando standard solidi che rafforzano la resilienza informatica a beneficio di tutti.
Per ulteriori informazioni dettagliate sul nostro impegno nel promuovere i principi secure-by-design, visita:
- Fortinet Reaffirms Its Commitment to Secure Product Development Processes and Responsible Vulnerability Disclosure Policies
- Proactive, Responsible Disclosure Is One Crucial Way Fortinet Strengthens Customer Security
- Fortinet’s Progress on Its Secure-by-Design Commitments
- Secure by Design: A Continued Priority in 2025 and Beyond
L'articolo Il Pledge ‘Secure by Design’ di CISA: un anno di progresso nella sicurezza informatica proviene da Red Hot Cyber.
Hacking a Pill Camera

A gastroscopy is a procedure that, in simple terms, involves sticking a long, flexible tube down a patient’s throat to inspect the oesophagus and adjacent structures with a camera fitted to the tip. However, modern technology has developed an alternative, in the form of a camera fitted inside a pill. [Aaron Christophel] recently came across one of these devices, and decided to investigate its functionality.
[Aaron’s] first video involves a simple teardown of the camera. The small plastic pill is a marvel of miniaturization. Through the hemispherical transparent lens, we can see a tiny camera and LEDs to provide light in the depths of the human body. Slicing the camera open reveals the hardware inside, however, like the miniature battery, the microcontroller, and the radio hardware that transmits signals outside the body. Unsurprisingly, it’s difficult to get into, since it’s heavily sealed to ensure the human body doesn’t accidentally digest the electronics inside.
Unwilling to stop there, [Aaron] pushed onward—with his second video focusing on reverse engineering. With a little glitching, he was able to dump the firmware from the TI CC1310 microcontroller. From there, he was able to get to the point where he could pull a shaky video feed transmitted from the camera itself. Artists are already making music videos on Ring doorbells; perhaps this is just the the next step.
Smart pills were once the realm of science fiction, but they’re an increasingly common tool in modern medicine. Video after the break.
youtube.com/embed/pf_eOLRd6B4?…
youtube.com/embed/qEIW5gOLzIs?…
Kubernetes Cluster Goes Mobile in Pet Carrier

There’s been a bit of a virtualization revolution going on for the last decade or so, where tools like Docker and LXC have made it possible to quickly deploy server applications without worrying much about dependency issues. Of course as these tools got adopted we needed more tools to scale them easily. Enter Kubernetes, a container orchestration platform that normally herds fleets of microservices in sprawling cloud architectures, but it turns out it’s perfectly happy running on a tiny computer stuffed in a cat carrier.
This was a build for the recent Kubecon in Atlanta, and the project’s creator [Justin] wanted it to have an AI angle to it since the core compute in the backpack is an NVIDIA DGX Spark. When someone scans the QR code, the backpack takes a picture and then runs it through a two-node cluster on the Spark running a local AI model that stylizes the picture and sends it back to the user. Only the AI workload runs on the Spark; [Justin] also is using a LattePanda to handle most of everything else rather than host everything on the Spark.
To get power for the mobile cluster [Justin] is using a small power bank, and with that it gets around three hours of use before it needs to be recharged. Originally it was planned to work on the WiFi at the conference as well but this was unreliable and he switched to using a USB tether to his phone. It was a big hit with the conference goers though, with people using it around every ten minutes while he had it on his back. Of course you don’t need a fancy NVIDIA product to run a portable kubernetes cluster. You can always use a few old phones to run one as well.
youtube.com/embed/XudewmfourQ?…
Humane Mousetrap Lets You Know It’s Caught Something

“Build a better mousetrap and the world will beat a path to your door,” so goes the saying, but VHS beat Betamax and the world hasn’t been the same since. In any case, you might not get rich building a better mousetrap, but you can certainly create something more humane than the ol’ spring’n’snap, as [nightcustard] demonstrates.
The concept is the same as many humane mousetraps on the market. The mouse is lured into a confined cavity with the use of bait, and once inside, a door closes to keep the mouse inside without injuring it. [nightcustard] achieved this by building a plastic enclosure with plenty of air holes, which is fitted with a spring-loaded door. When a mouse walks through an infra-red break beam sensor, a Raspberry Pi Pico W triggers a solenoid which releases the door, trapping the mouse inside. This design was chosen over a passive mechanical solution, because [nightcustard] noted that mice in the attic were avoiding other humane traps with obvious mechanical trigger mechanisms.
As a bonus, the wireless connectivity of the Pi Pico W allows the trap to send a notification via email when it has fired. Thus, you can wake up in the morning and check your emails to see if you need to go and release a poor beleaguered mouse back into the wild. This is critical, as otherwise, if you forget to check your humane trap… it stops being humane pretty quickly.
If you’re looking for more inspiration to tackle your mouse problems, we can help. We’ve featured other traps of this type before, too. Meanwhile, if you’ve got your own friendly homebrew solutions to pesky pest problems, don’t hesitate to hit up the tipsline.
Casting Metal Tools With Kitchen Appliances

Perhaps the biggest hurdle to starting a home blacksmithing operating is the forge. There’s really no way around having a forge; somehow the metal has to get hot enough to work. Although we might be imagining huge charcoal- or gas-fired monstrosities, [Shake the Future] has figured out how to use an unmodified, standard microwave oven to get iron hot enough to melt and is using it in his latest video to cast real, working tools with it.
In the past, [Shake the Future] has made a few other things with this setup like an aluminum pencil with a graphite core. This time, though, he’s stepping up the complexity a bit with a working tool. He’s decided to build a miniature bench vice, which uses a screw to move the jaws. He didn’t cast the screw, instead using a standard size screw and nut, but did cast the two other parts of the vice. He first 3D prints the parts in order to make a mold that will withstand the high temperatures of the molten metal. With the mold made he can heat up the iron in the microwave and then pour it, and then with some finish work he has a working tool on his hands.
A microwave isn’t the only kitchen appliance [Shake the Future] has repurposed for his small metalworking shop. He also uses a standard air fryer in order to dry parts quickly. He works almost entirely from the balcony of his apartment so he needs to keep his neighbors in mind while working, and occasionally goes to a nearby parking garage when he has to do something noisy. It’s impressive to see what can be built in such a small space, though. For some of his other work be sure to check out how he makes the crucibles meant for his microwave.
youtube.com/embed/56JHC8Jw8IE?…
Cheap VHF Antenna? Can Do!

The magnetic loop antenna is a familiar sight in radio amateur circles as a means to pack a high performance HF antenna into a small space. It takes the form of a large single-turn coil made into a tuned circuit with a variable capacitor, and it provides the benefits of good directionality and narrow bandwidth at the cost of some scary RF voltages and the need for constant retuning. As [VK3YE] shows us though, magnetic loops are not limited to HF — he’s made a compact VHF magnetic loop using a tin can.
It’s a pretty simple design; a section from the can it cut out and made into a C shape, with a small variable capacitor at the gap. The feed comes in at the bottom, with the feed point about 20 % of the way round the loop for matching. The bandwidth is about 100 MHz starting from the bottom of the FM broadcast band, and he shows us it receiving broadcast, Airband, and 2 meter signals. It can be used for transmitting too and we see it on 2 meter WSPR, but we would have to wonder whether the voltages induced by higher power levels might be a little much for that small capacitor.
He’s at pains to point out that there are many better VHF antennas as this one has no gain to speak of, but we can see a place for it. It’s tiny, if you’re prepared to fiddle with the tuning its high Q gets rid of interference, and its strong side null means it can also reduce unwanted signals on the same frequency. We rather like it, and we hope you will too after watching the video below.
youtube.com/embed/JYIU0Nxn8fg?…
Congratulations to the 2025 Component Abuse Challenge Winners

For the Component Abuse Challenge, we asked you to do the wrong thing with electrical parts, but nonetheless come out with the right result. It’s probably the most Hackaday challenge we have run in a long time, and you all delivered! The judging was tight, but in the end three projects rose up to the top, and will each be taking home a $150 DigiKey gift certificate, but that doesn’t mean you shouldn’t give all of the projects a look.
So without further ado, let’s check out the winners and all the others that tickled the hacky regions of our judges’ brains.
Prize Winners

The component misuse is an old favorite: the diode’s forward voltage drop depends on the temperature, and if you measure the voltage across the current-limiting resistor, you can read this voltage and determine when someone is setting fire to your LED. A bonus of the single-LED configuration is that if you touch the LED’s leads, your finger shunts some of the current, and you can “snuff” the LEDs out. And while we’ve seen similar LED hacks before, the addition of actual fire to this one seems to have warmed our judges’ hearts.
[Luke J. Barker]’s Need an Electrical Slip Ring? is simplicity itself, and appears to have been born of the mother of invention. [Luke] was making a VertiBird helicopter toy, which spins around on the desk and rises and falls with joystick control. And for that, he needed a slip ring. Enter the humble audio jack, which fills the job nicely, transmitting power to the rotating helicopter without twisting up wires in the process. There’s not much magic here, but it’s a fantastic idea when you need something to spin.
On the other end of the spectrum, [Craig D]’s Boosting voltage with a cable looks like it shouldn’t work at first, but it does. In most step-up-voltage setups, you’re storing the energy in either a capacitor or inductor, and switching it in and out of the circuit to hop the voltage up. Here, the energy isn’t ever really “stored” as much as it’s “in flight”.


A circuit sends a pulse down a long length of coaxial cable that is left open at the other end. The pulse reflects off the open end and heads back toward the voltage driver, which then fires off another pulse at just the right time to make the travelling wave a little bit bigger, and this continues. It’s like pushing a swing – adding a little extra oomph at just the right time can build up. There’s a lot of cool physics here, a nice simulation that actually ends up corresponding very well with reality, and in the end the pulse timing isn’t rocket science, but rather figuring out the resonant frequency along the coax. And it works well enough to light up two neon bulbs in series (~140 V) off of a 15 V power supply.
Honorable Mentions
We got way more cool entries than we have prizes, so we try to round them up into categories and give them a little time in the sun.
Out of Spec
Normally, a 555 timer oscillator circuit relies on filling up a capacitor with a current that’s throttled through a resistor. How can you make it go faster? Make the capacitor smaller and the resistor less resistive. What happens when you get rid of them both entirely, relying on stray capacitance and the resistance of whatever wire you’re using? That’s what [MagicWolfi] aimed to find out with his Ludicrous 555 project.
The IC-Abusing Diode Tester is an absolutely horrible circuit. Nothing in it works like it should. The only reason the IC doesn’t burn up is that it’s more robust than the datasheet promises, and the battery used has such a high internal resistance that it can’t source that much current anyway. Parts are powered by leakage current, and below their minimum voltage. [Joseph Eoff] counts seven values that are out of spec in this single historical circuit, so that’s gotta count for something.
Junk Box Substitutions

Or maybe you’re working on self-assembling robots and you need some magic glue to hold different modules together. [Miana]’s Low-melt-solder connected robots is half research project, and half hack. Resistors are used to melt solder, magnets align the parts together, and when it all cools down, it’s as if two modules are brazed together. This one’s a lot more than a hack, but we’re honored to have it entered in the contest anyway!
Bizarro World
We honestly thought we’d get more entries that made use of the duality of most sensors / emitters. Instead, we got two. [Nick]’s Better Than Bluetooth does the LED-as-photosensor trick, and concludes that it’s better than Bluetooth if expense, limited range, and frustration are what you’re looking for in a data link. Meanwhile, [Kauz] proves that electromagnets are also pickups by building a guitar pickup out of six relays.
Side Effects

Most old op-amps oscillate out of control when given feedback, unless you damp it down a bit with a capacitor. [Adrian Freed] found an op-amp lousy enough that would do this at audio frequencies, and used it to reimagine a classic noisemaker.
Finally, while you should probably avoid the metastable middle-zones between digital one and zero, [SHAOS] combines unbuffered NAND and NOR gates to tease out a third logic state. [Bob Widlar] would be proud.
Thanks All!
As always, we had more great entries that we could feature here, so head on over to Hackaday.io and check them out. And thanks again to DigiKey for providing our top three with $150 gift certificates. If you’re looking for your chance to show off a project that you’re working on, hang on for a while because we’ll be starting up a new contest in early 2026.

A Quick Primer On TinkerCAD’s New Features

TinkerCAD had its first release all the way back in 2011 and it has come a long way since then. The latest release has introduced a raft of new, interesting features, and [HL ModTech] has been nice enough to sum them up in a recent video.
He starts out by explaining some of the basics before quickly jumping into the new gear. There are two headline features: intersect groups and smooth curves. Where the old union group tool simply merged two pieces of geometry, intersect group allows you to create a shape only featuring the geometry where two individual blocks intersect. It’s a neat addition that allows the creation of complex geometry more quickly. [HL ModTech] demonstrates it with a sphere and a pyramid and his enthusiasm is contagious.
As for smooth curves, it’s an addition to the existing straight line and Bézier curve sketch tools. If you’ve ever struggled making decent curves with Bézier techniques, you might appreciate the ease of working with the smooth curve tool, which avoids any nasty jagged points as a matter of course.
While it’s been gaining new features at an impressive rate, ultimately TinkerCAD is still a pretty basic tool — it’s not the sort of thing you’d expect to see in the aerospace world or anything. ut it’s a great way to start whipping up custom stuff on your 3D printer.
youtube.com/embed/nMDNAysi5EE?…
In Praise of Plasma TVs

I’m sitting in front of an old Sayno Plasma TV as I write this on my media PC. It’s not a productivity machine, by any means, but the screen has the resolution to do it so I started this document to prove a point. That point? Plasma TVs are awesome.
Always the Bridesmaid, Never the Bride

It’s funny, because I firmly believe that without plasma displays, CRTs would have never gone away. Perhaps for that I should hate them, but it’s for the very reasons that Plasma won out over HD-CRTs in the market place that I love them.
What You Get When You Get a Plasma TV
I didn’t used to love Plasma TVs. Until a few years ago, I thought of them like you probably do: clunky, heavy, power-hungry, first-gen flatscreens that were properly consigned to the dustbin of history. Then I bought a house.
The house came with a free TV– a big plasma display in the basement. It was left there for two reasons: it was worthless on the open market and it weighed a tonne. I could take it off the wall by myself, but I could feel the ghost of OSHA past frowning at me when I did. Hauling it up the stairs? Yeah, I’d need a buddy for that… and it was 2020. By the time I was organizing the basement, we’d just gone into lockdown, and buddies were hard to come by. So I put it back on the wall, plugged in my laptop, and turned it on.
I was gobsmacked. It looked exactly like a CRT– a giant, totally flat CRT in glorious 1080p. When I stepped to the side, it struck me again: like a CRT, the viewing angle is “yes”.
How it Works
None of this should have come as a surprise, because I know how a Plasma TV works. I’d just forgotten how good they are. See, a Plasma TV really was an attempt to get all that CRT goodness in a flat screen, and the engineers at Fujitsu, and later elsewhere, really pulled it off.
Like CRTs, you’ve got phosphors excited to produce points of light to create an image– and only when excited, so the blacks are as black as they get. The phosphors are chemically different from those in CRTs but they come in similar colours, so colours on old games and cartoons look right in a way they don’t even on my MacBook’s retina display.
Unlike a CRT, there’s no electron beam scanning the screen, and no shadow mask. Instead, the screen is subdivided into individual pixels inside the flat vacuum panel. The pixels are individually addressed and zapped on and off by an electric current. Unlike a CRT or SED, the voltage here isn’t high enough to generate an electron beam to excite the phosphors; instead the gas discharge inside the display emits enough UV light to do the same job.
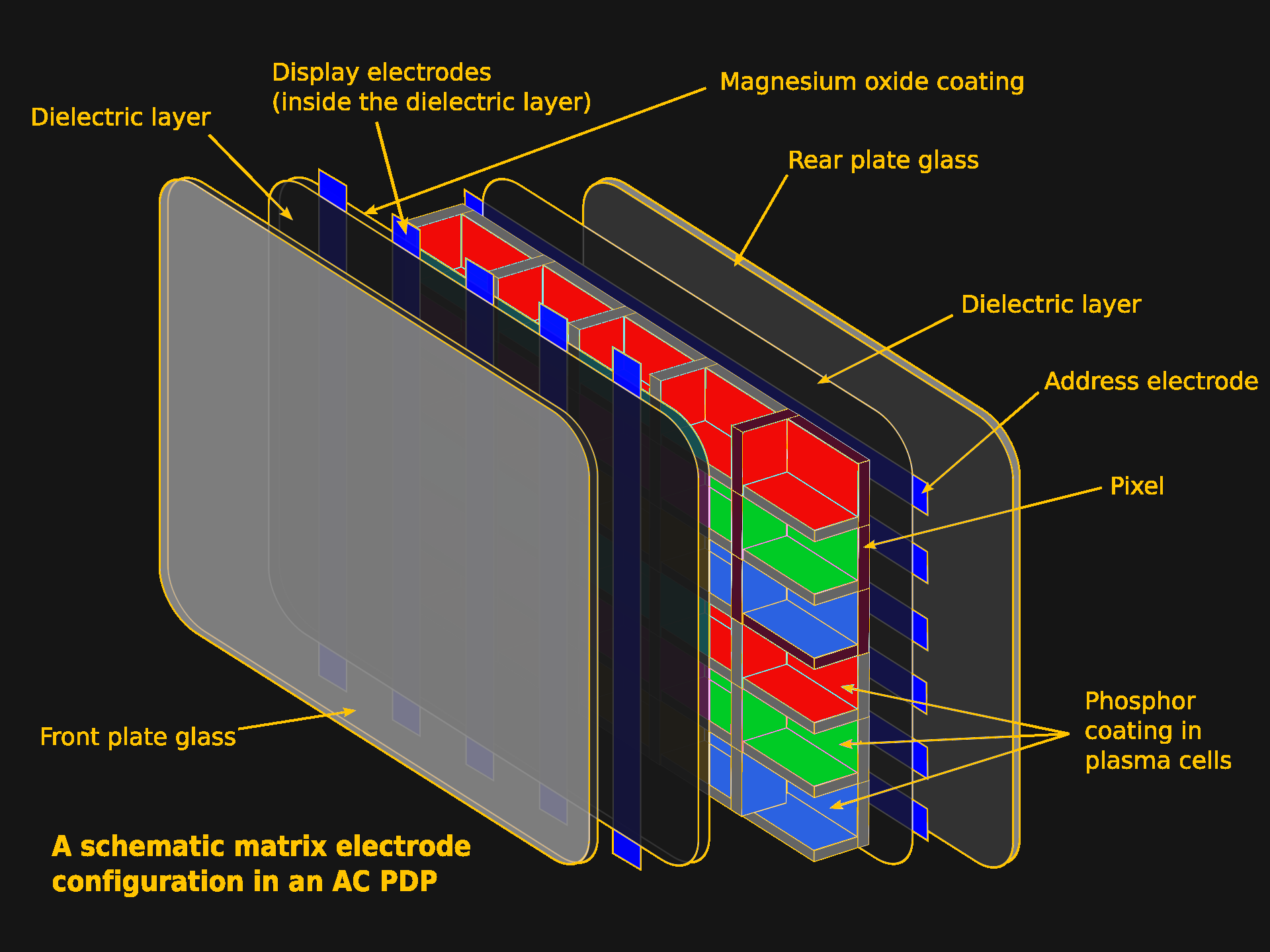
Image based on “Plasma-Display-Composition.svg” by [Jari Laamanen].Still, if it feels like a CRT, and that’s because the subpixels are individual blobs of phosphors, excited from behind, and generating their own glorious light.
It’s Not the Same, Though
It’s not a CRT, of course. The biggest difference is that it’s a fixed-pixel display, with all that comes with that. This particular TV has all the ports on the back to make it great for retrogaming, but the NES, or what have you, signal still has to be digitally upscaled to match the resolution. Pixel art goes unblurred by scanlines unless I add it in via emulation, so despite the colour and contrast, it’s not quite the authentic experience.

Those big CRTs don’t have to worry about burn in, either, something I have been very careful in the five years I’ve owned this second-hand plasma display to avoid. I can’t remember thinking much about burn-in with CRTs since we retired the amber-phosphor monitor plugged into the Hercules Graphics card on our family’s 286 PC.
The dreaded specter of burn-in is plasma’s Achilles heel – more than the weight and thickness, which were getting much better before LG pulled the plug as the last company to exit this space, or the Energy Star ratings, which weren’t going to catch up to LED-backlit LCDs, but had improved as well. The fear of burn-in made you skip the plasma, especially for console gaming.

By the end, the phosphors improved and various tricks like jiggling the image pixel-by-pixel were found to avoid burn-in, and it seems to have worked: there’s absolutely no ghosting on my model, and you can sometimes find late-model Plasma TVs for the low, low cost of “get this thing off my wall and up the stairs” that are equally un-haunted. I may grab another, even if I have to pay for it. It’s a lot easier to hide a spare flatscreen than an extra CRT, another advantage to the plasma TVs, and in no case do phosphors last forever.
But Where’s the Hack?
Is “grab an old flat screen instead of hunting around for an impossible CRT” a hack? Maybe it’s not, but it’s worth considering, though, because Plasma TVs don’t get the love they deserve. (And seriously, you’re not going to find the mythical 43-inch CRT, even if it technically existed. And you’ll never find a tube that could match the 152” monster Panasonic put out to claim the record back in the day.)
In the mean time, I’m going to enjoy the contrast ratio, refresh rate, and the bonus space heater. I’m in Canada, and winter is coming, so it’s hard to get too overworked about waste heat when there’s frost on your windowpanes.
Featured image: “IFA 2010 Internationale Funkausstellung Berlin 124” by [Bin im Garten].
Cloudflare va giù nel magnifico Cloud! incidente globale in fase di risoluzione
18 novembre 2025 – Dopo ore di malfunzionamenti diffusi, l’incidente che ha colpito la rete globale di Cloudflare sembra finalmente vicino alla risoluzione. L’azienda ha comunicato di aver implementato una correzione e di essere ora nella fase di monitoraggio attivo, dopo una giornata caratterizzata da disservizi, errori intermittenti e problemi sui servizi applicativi e di sicurezza.
L’incidente, iniziato alle 11:48 UTC, ha coinvolto varie componenti dell’infrastruttura Cloudflare, generando rallentamenti, timeout e blocchi a livello globale, con impatti anche su CDN, API, autenticazione e dashboard di gestione.
Di seguito la ricostruzione completa della giornata.

Timeline dell’incidente Cloudflare
11:48 UTC – Inizio dell’incidente
Cloudflare segnala un degrado interno del servizio. Diversi servizi risultano instabili a livello globale e viene avviata l’analisi del problema.
12:03 UTC – Indagine in corso
Cloudflare conferma che alcuni servizi continuano a essere colpiti da errori intermittenti.
12:21 UTC – Prime evidenze di ripristino parziale
Cloudflare osserva miglioramenti, ma i clienti sperimentano ancora errori più elevati del normale.
12:37 UTC – Indagine ancora attiva
Persistono anomalie diffuse sulla rete.
12:53 UTC – Indagine ancora in corso
I tecnici continuano a lavorare senza individuare ancora una soluzione definitiva.
13:04 UTC – Disattivato temporaneamente l’accesso WARP a Londra
Durante i tentativi di mitigazione, Cloudflare disattiva WARP nella region di Londra. Gli utenti locali non riescono a connettersi tramite il servizio.
13:09 UTC – Problema identificato
Cloudflare comunica di aver individuato la causa dell’incidente e di aver iniziato a implementare una soluzione.
13:13 UTC – Ripristino parziale di Access e WARP
Cloudflare ripristina Access e WARP, riportando i livelli di errore alla normalità.
WARP Londra torna operativo. Si continua a lavorare sui restanti servizi applicativi.
13:35 UTC – Problemi ancora presenti
I servizi applicativi non sono ancora stati ripristinati completamente.
13:58 UTC – Lavori in corso
Continuano gli interventi per riportare online i servizi rimanenti.

14:22 UTC – Ripristino dashboard
La dashboard Cloudflare torna operativa, anche se i servizi applicativi mostrano ancora instabilità.
14:34 UTC – Continuano i lavori di ripristino
Il team tecnico prosegue con le attività necessarie a ripristinare tutti i servizi.
14:42 UTC – Cloudflare: “Incidente risolto, monitoraggio in corso”
Cloudflare annuncia di aver implementato una correzione definitiva. Tutti i servizi dovrebbero tornare progressivamente alla normalità, ma rimane attivo il monitoraggio post-incident.

Impatti dell’incidente
L’incidente ha avuto un impatto rilevante su scala globale. Molti siti web serviti da Cloudflare (tra cui redhotcyber.com) hanno mostrato rallentamenti, pagine non raggiungibili, errori 502, 522 e 526, oltre a problemi di caching e routing.
I servizi di sicurezza e autenticazione, come Cloudflare Access e WARP, sono stati fortemente colpiti nella prima fase. In alcune regioni gli utenti non hanno potuto autenticarsi o accedere alle risorse protette.
Anche Downdetector ha mostrato malfunzionamenti, rendendo difficile monitorare l’ampiezza dell’incidente e contribuendo alla percezione di un blackout molto esteso.
L’infrastruttura globale Cloudflare ha registrato rallentamenti e instabilità, con ripercussioni a catena su servizi non direttamente ospitati sulla piattaforma.
Che cos’è Cloudflare WARP
Cloudflare WARP è un servizio sviluppato da Cloudflare con l’obiettivo di migliorare la sicurezza e le prestazioni della connessione Internet degli utenti. A differenza delle VPN tradizionali, che puntano principalmente a fornire anonimato instradando tutto il traffico attraverso server remoti, WARP è progettato per rendere la navigazione più veloce, stabile e protetta, senza appesantire la connessione.
Come funziona
WARP utilizza il protocollo WireGuard, noto per essere leggero, rapido e altamente sicuro. Il traffico viene instradato attraverso la rete globale di Cloudflare, che funge da “strato protettivo” tra l’utente e il web. Questo permette di:
- criptare le connessioni su reti non sicure (come Wi-Fi pubblici),
- ridurre la latenza grazie alla rete globale Cloudflare,
- filtrare automaticamente traffico malevolo o sospetto,
- proteggere da intercettazioni e attacchi man-in-the-middle.
Non mira all’anonimato totale come una VPN classica, ma si concentra su sicurezza e stabilità della connessione.
La differenza tra WARP e WARP+
Cloudflare offre due versioni del servizio:
- WARP: gratuito, utilizza la rete standard Cloudflare.
- WARP+: a pagamento, instrada parte del traffico tramite la tecnologia Argo Smart Routing, che sceglie dinamicamente il percorso più veloce tra i server Cloudflare, migliorando ulteriormente la velocità.
Situazione attuale
Secondo l’ultimo aggiornamento, la correzione è stata applicata con successo e i servizi stanno tornando alla normalità. Cloudflare è ora nella fase di monitoraggio attivo e nelle prossime ore potrebbero verificarsi residui di instabilità durante l’assestamento della rete
L'articolo Cloudflare va giù nel magnifico Cloud! incidente globale in fase di risoluzione proviene da Red Hot Cyber.
Cloudflare down: siti web e servizi offline il 18 novembre 2025
La mattinata del 18 novembre 2025 sarà ricordata come uno dei blackout più anomali e diffusi della rete Cloudflare degli ultimi mesi. La CDN – cuore pulsante di milioni di siti web, applicazioni e servizi API – ha iniziato a mostrare malfunzionamenti a catena in diverse aree geografiche, con impatti significativi anche sul nostro sito, Red Hot Cyber, che utilizza l’infrastruttura Cloudflare per CDN, caching e protezione DDoS.
Sul portale Cloudflare System Status è stato pubblicato il seguente avviso:
11:48 UTC: “Cloudflare is aware of, and investigating an issue which potentially impacts multiple customers.”
12:03 UTC: “We are continuing to investigate this issue.”
Anche Downdetector in tilt
Uno degli elementi più insoliti è il fatto che Downdetector, piattaforma utilizzata per verificare interruzioni e anomalie sui grandi servizi, risulta anch’esso irraggiungibile o con caricamenti estremamente lenti.
Questo ha reso più difficile monitorare il picco di segnalazioni da parte degli utenti, creando un effetto domino informativo: molti utenti non riescono neppure a verificare quali servizi siano effettivamente offline, aumentando la percezione di un blackout generalizzato.
Una falla globale senza spiegazione
Al momento la causa dell’incidente rimane completamente sconosciuta. Cloudflare non ha ancora diffuso dettagli tecnici, e l’assenza di indicazioni precise apre a diverse ipotesi operative:
- Possibile instabilità del backbone globale, ma senza conferme.
- Anomalia nei sistemi di routing interni (es. BGP), che in passato ha causato effetti simili.
- Errore di configurazione su un cluster core, un’ipotesi frequente nei grandi provider.
- Attacco mirato, sebbene non ci siano segnali evidenti, e Cloudflare non lo ha indicato come causa probabile.
- Malfunzionamento su larga scala delle edge locations, che avrebbe un impatto immediato sui siti statici e sulle API protette.
La simultaneità con il tilt di Downdetector, inoltre, suggerisce che il problema potrebbe aver colpito non solo i contenuti serviti via Cloudflare, ma anche altri nodi critici dell’ecosistema di monitoraggio pubblico.
L'articolo Cloudflare down: siti web e servizi offline il 18 novembre 2025 proviene da Red Hot Cyber.
Di Corinto a Radio Rai 1
Podcast/ Algoritmi truffatori: come l’AI traveste i criminali da persone fidate
Una voce ordina al direttore finanziario un bonifico urgente: sembra l’amministratore delegato, ma è la sua perfetta imitazione digitale.
Un messaggio disperato convince una madre a inviare soldi al figlio in difficoltà: ma non era lui, era la sua voce clonata in pochi secondi.
Un software manomesso addestra l’algoritmo antifrode della banca a considerare leciti bonifici che sono invece fraudolenti, una goccia di veleno finita nel pozzo dei dati.
Sono solo tre volti dei nuovi rischi informatici realizzati con l’intelligenza artificiale generativa: truffe credibili, identità sintetiche e manipolazioni invisibili che scavalcano le nostre difese più umane.
Di questo abbiamo parlato nel nuovo episodio di Pillole di Eta Beta, condotto da Massimo Cerofolini con la regia di Mimmi Micocci, e con la partecipazione di Beta, l’intelligenza artificiale parlante.
Grazie Massimo Cerofolini e Radio1 di avermi invitato a parlarne.
Per ascoltare il podcast:
raiplaysound.it/programmi/pill…

Internet Archive Hits One Trillion Web Pages

In case you didn’t hear — on October 22, 2025, the Internet Archive, who host the Wayback Machine at archive.org, celebrated a milestone: one trillion web pages archived, for posterity.
Founded in 1996 by Brewster Kahle the organization and its facilities grew through the late nineties; in 2001 access to their archive was greatly improved by the introduction of the Wayback Machine. From their own website on Oct 21 2009 they explained their mission and purpose:
Most societies place importance on preserving artifacts of their culture and heritage. Without such artifacts, civilization has no memory and no mechanism to learn from its successes and failures. Our culture now produces more and more artifacts in digital form. The Archive’s mission is to help preserve those artifacts and create an Internet library for researchers, historians, and scholars.
We were curious about the Internet Archive technology. Storing a copy (in fact two copies!) of the internet is no mean feat, so we did some digging to find out how it’s done. The best information available is in this article from 2016: 20,000 Hard Drives on a Mission. They keep two copies of every “item”, which are stored in Linux directories. In 2016 they had over 30 petabytes of content and were ingesting at a rate of 13 to 15 terabytes per day, web, and television being the most voluminous.
In 2016 they had around 20,000 individual disk drives, each housed in specialized computers called “datanodes”. The datanodes have 36 data drives plus two operating system drives per machine. Datanodes are organized into racks of 10 machines, having 360 data drives per rack. These racks are interconnected via high-speed Ethernet to form a storage cluster.
Even though content storage tripled over 2012 to 2016, the count of disk drives stayed about the same; this is because of disk drive technology improvements. Datanodes that were once populated with 36 individual 2 terabyte drives are today filled with 8 terabyte drives, moving single node capacity from 72 terabytes (64.8 T formatted) to 288 terabytes (259.2 T formatted) in the same physical space. The evolution of disk density did not happen in a single step, so there are populations of 2, 3, 4, and 8 T drives in the storage clusters.
We will leave you with the visual styling of Hackaday Beta in 2004, and what an early google.com or amazon.com looked like back in the day. Super big shout out to the Internet Archive, thanks for providing such an invaluable service to our community, and congratulations on this excellent achievement.
Micro:Bit Gets Pseudo-Polyphonic Sound With Neat Hack

The Micro:bit is a fun microcontroller development platform, designed specifically for educational use. Out of the box, it’s got a pretty basic sound output feature that can play a single note at a time. However, if you’re willing to get a bit tricky, you can do some pseudo-polyphonic stuff as [microbit-noob] explains.
The trick to polyphony in a monophonic world? Rapidly alternating between the different notes you want to be playing at the same time. Do this fast enough and it feels like they’re playing together rather than seperately. [microbit-noob] demonstrates how to implement this with a simple function coded for the Micro:bit. Otherwise, it uses the completely stock sound hardware. However, the IR receiver is added to the device in order to allow a simple remote control to be used to command the notes desired, along with some extra tactile buttons to add further control.
Is it chiptune? Well, it’s a chip, playing a tune, so yes. Even if it is through a tiny speaker stuck to the PCB. In any case, if you’re trying to get some better bleeps and bloops out of the Micro:bit, this is a great place to start. If you’ve got other hacks for Britain’s educational little board, let us know on the tipsline!
Shakerati Anonimi: l’esperienza di Nicoletta e il thriller della carta di credito
La stanza è la solita: luci tenui, sedie in cerchio, termos di tisane ormai diventate fredde da quanto tutti parlano e si sfogano. Siamo gli Shakerati Anonimi, un gruppo di persone che non avrebbe mai immaginato di finire qui, unite da un’unica cosa: essere state scosse, raggirate, derubate da chi, dietro la tastiera, non ha nulla da perdere.
Dopo Pasquale, Simone e Gianni, una donna prende fiato, sistema la sciarpa e si alza.
È il suo turno.

“Ciao… io sono Nicoletta”
«Ciao a tutti, mi chiamo Nicoletta» dice con un mezzo sorriso tirato. «Ho 42 anni, lavoro come impiegata amministrativa in uno studio notarile… e sì, sono stata truffata.»
Il cerchio annuisce, qualcuno sussurra “ciao Nicoletta”. Lei inspira profondamente, come se dovesse immergersi in acqua gelida.
«Doveva essere una giornata qualunque. Non dormivo bene da qualche giorno e la testa non era proprio al massimo. Verso le 11 mi arriva una chiamata dalla mia banca. Lo diceva anche il display.»
Fa un gesto con la mano, come per scacciare un pensiero fastidioso.
«Mi dicono che la mia nuova carta evolution, quella sostitutiva, era finalmente stata presa in carico e serviva completare l’attivazione. La stavo aspettando da tempo quella carta, perché la mia era in scadenza. Tutto sembrava normale. Niente richieste strane. Niente codici da dare. Mi dicevano solo di confermare sull’app alcune notifiche… Confermare, capite?»
Un silenzio pesante si posa sul gruppo. Nicoletta continua:
«Nemmeno avevo in mano la carta nuova, non sapevo nemmeno il numero! E questo mi ha fregata! Perché quando vedi che loro sanno tutto, pensi che sia tutto regolare. Così eseguo quello che mi chiedono.»
Abbassa lo sguardo.
«Due minuti dopo… mi accorgo che il conto era stato svuotato. Non alleggerito. Svuotato. Zero.»
La corsa nel vuoto
«Sono partita come una furia verso i Carabinieri. Mi hanno spiegato che potevo denunciare e sperare nel rimborso, oppure tentare di avviare un’indagine più approfondita… ma che “tanto è difficile che li prendiamo”.»
Le virgolette le pronuncia con amarezza.
«Poi in banca ho scoperto un dettaglio che mi ha gelata: la mia carta non era “in consegna”.
Era sparita. Persa durante la consegna. La mia carta nuova era finita nelle mani di qualcuno prima ancora che arrivasse nella mia cassetta.»
Qualcuno nel cerchio mormora incredulo.
«E qui arriva la parte che mi tiene sveglia la notte. Mi hanno detto che il truffatore ha prelevato contanti in un ATM, e che un complice ha attivato la carta dal sito. Come se avessero tutto pianificato: la carta sottratta, i miei dati già pronti, la telefonata sincronizzata.»
Nicoletta si siede. La sua voce trema un istante.
Il colpo di scena
«Il giorno dopo, non so perché ma ho deciso di controllare l’app delle consegne.
E ho trovato qualcosa.»
Il gruppo si raddrizza sulle sedie.
«La mia carta risultava consegnata due giorni prima della telefonata. Ma io non avevo ricevuto niente. Nessun avviso, nessun postino. Zero.»
Un paio di persone sussultano.
«Ho chiesto alle banca di vedere la foto della consegna. Sapete quella che scattano ormai per dimostrare l’avvenuta consegna?»
Annuisce lentamente.
«Mi aspettavo una firma falsa. Una foto del portone. Un buco. E invece… nella foto c’era una mano.
Una mano che mi diceva qualcosa. Non la mia. Ma…» sospira, quasi incredula, «…ma quella mano l’avevo già vista.»
Il gruppo trattiene il fiato.
«Era la mano del postino che serve il mio palazzo da anni. Il mio postino. Lui ha consegnato la carta… a qualcuno che non ero io.»
La stanza esplode in un brusio incredulo.
«Ho capito che non era una truffa qualunque. Era qualcosa costruito in silenzio, con qualcuno che conosceva le mie abitudini, sapeva che aspettavo la carta, sapeva quando sarebbe arrivata… e ha agito.»
Nicoletta stringe la sciarpa.
«Forse non saprò mai se il postino è complice o se è stato raggirato. Ma ora almeno so una cosa: non era un furto casuale. Era un colpo su misura.»
Lesson Learned
Da questa storia abbiamo imparato tre lezioni fondamentali:
1 .Denuncia il fatto alla Polizia Postale
Quando ci si trova di fronte a una truffa, la prima cosa da fare è denunciarla immediatamente alle autorità competenti: Polizia Postale o Carabinieri. Questo passaggio è fondamentale per due motivi: permette alle forze dell’ordine di avviare gli accertamenti necessari e, allo stesso tempo, consente alla vittima di avviare le procedure ufficiali per un eventuale rimborso o recupero dei fondi. Agire tempestivamente aumenta le possibilità che la truffa venga tracciata, documentata e, quando possibile, fermata prima che possa colpire altre persone.
2. La truffa non avviene solo al telefono o online. Può iniziare molto prima.
La frode di Nicoletta è partita fisicamente, con la sottrazione della carta prima della consegna.
Questo dimostra che i criminali non agiscono solo digitalmente: spesso combinano mondo reale e digitale per rendere l’attacco più credibile.
3. Le chiamate verosimili sono le più pericolose.
Il truffatore non ha chiesto codici insoliti, non ha parlato in modo sospetto.
Ha solo guidato Nicoletta a confermare notifiche sull’app. E questo è esattamente ciò che molte vittime non si aspettano: una truffa che non richiede dati sensibili, ma sfrutta ciò che già possiedono.
4. Prevenire è possibile: basta conoscere gli indicatori chiave.
- Nessuna banca o servizio postale attiva una carta tramite telefonata.
- Le notifiche push che prevedono conferme dovrebbero essere trattate come “operazioni bancarie”: se non sei tu ad avviarle, non le confermi.
- Ogni consegna di carte o documenti sensibili deve essere monitorata, chiedendo sempre la prova di consegna.
- Se la carta non arriva nei tempi previsti, bisogna allertare subito l’ente emittente.
Genesi dell’articolo
L’articolo è stato ispirato da una truffa reale, condivisa da un utente su Reddit.
A questa persona va tutto il nostro conforto: il suo coraggio nel raccontare ciò che ha vissuto permette ad altri di riconoscere i segnali, proteggersi e imparare dall’esperienza che ha affrontato.
L'articolo Shakerati Anonimi: l’esperienza di Nicoletta e il thriller della carta di credito proviene da Red Hot Cyber.

Writing Type-Safe Generics in C

The fun part about a programming language like C is that although the language doesn’t directly support many features including object-oriented programming and generics, there’s nothing that’s keeping you from implementing said features in C. This extends to something like type-safe generics in C, as [Raph] demonstrates in a blog post.
After running through the various ways that generics are also being implemented using methods including basic preprocessor macros and void pointers, the demonstrated method is introduced. While not necessarily a new one, the advantage with this method is that is type-safe. Much like C++ templates, these generics are evaluated at compile time, with the preprocessor handling both the type checking and filling in of the right template snippets.
While somewhat verbose, it can be condensed into a single header file, doesn’t rely on the void type or pointers and can be deduplicated by the linker, preventing bloat. If generics is what you are looking for in your C project, this might be a conceivable solution.
Binary Clock Also Monitors Weather

There are two things most of us want to know on a daily basis—the weather, and what time it is. [Guitarman9119] built a single device that can provide both pieces of information with a pleasingly nerdy aesthetic.
The heart of the build is a Raspberry Pi Pico W, which is proudly displayed on the front panel of the device. It’s responsible for driving the array of LEDs that display the time in hours, minutes, and seconds in binary format. The Pi Pico W uses its wireless connection to query the WorldTime API and an IP geolocation server. This provides the local date and time, and the location is then used to query the OpenWeather service for current weather information. The weather information is thankfully not displayed in binary format, because that would be straining to read. Instead, it’s displayed in human-readable format on a small OLED display.
There’s something about the way this is built—the discrete LEDs, that weird blue color that seemed to disappear by 1984—that gives this a wonderfully old school charm. You could imagine it turning up in a college lab full of old blinkenlights gear. Video after the break.
youtube.com/embed/hAAY1Tiw1yg?…
Building A Smart Speaker Outside The Corporate Cloud

If you’re not worried about corporate surveillance bots scraping your shopping list and manipulating you through marketing, you can buy any number of off-the-shelf smart speakers for your home. Alternatively, you can roll your own like [arpy8] did, and keep your life a little more private.
The build is based around an ESP32 microcontroller. It connects to the ‘net via its inbuilt Wi-Fi connection, and listens out for your voice with an INMP441 omnidirectional microphone module. The audio data is trucked off to a backend server running a Whisper speech-to-text model. The text is then passed to Google’s Gemini 2.5 Flash large language model. The response generated is passed to the Piper Neural Voice text-to-speech engine, sent back to the ESP32, and spat out via the device’s DAC output and a speaker attached to an LM386 amplifier. Basically, anything you could ask Gemini, you can do with this device.
By virtue of using a commercial large language model, it’s not perfectly private by any means. Still, it’s at least a little farther removed than using a smart speaker that’s directly logged in to your Amazon/Google/Hulu/Beanstikk account. Files are on Github for those eager to dive into the code. We’ve seen some other fun builds along these lines before, too. Video after the break.
youtube.com/embed/_BZOLwxb_aU?…
Meet The Shape That Cannot Pass Through Itself

Can a shape pass through itself? That is to say, if one had two identical solids, would it be possible to orient one such that a hole could be cut through it, allowing the other to pass through without breaking the first into separate pieces? It turns out that the answer is yes, at least for certain shapes. Recently, two friends, [Sergey Yurkevich] and [Jakob Steininger], found the first shape proven not to have this property.

Later, researchers showed this was also true of more complex shapes. This ability to pass unbroken through a copy of oneself became known as Rupert’s Property. Sometimes it’s an amazingly tight fit, but it seems to always work.
In fact, it was so difficult to find candidates for exceptions to this that it was generally understood and accepted by mathematicians that every convex polyhedron (that is, every shape with flat sides and no holes, protrusions, or indentations) would have Rupert’s property. Until one was found that did not.
The first shape proven not to be able to pass through itself — known as the Noperthedron — is a vaguely ball-like shape, with a flat top and bottom. A fan has already added a cavity to create a 3D-printable pencil holder version of the noperthedron (shown here) if you want your own.
There are other promising candidate objects (they are rare) that may also lack Rupert’s property, but so far, this is the only proven one.
Shapes with unusual properties are interesting, and we love how tactile and visual they are. Consider Penrose tiles, a tile set that can cover any size of area without repeating. For decades, the minimum number of tile shapes needed to accomplish this was two. Recently, though, the number has dropped to one thanks to a shape known as “the hat.”
Keebin’ with Kristina: the One with the Cipher-Capable Typewriter

I must confess that my mouth froze in an O when I saw [Jeff]’s Typeframe PX-88 Portable Computing System, and I continue to stare in slack-jawed wonder as I find the words to share it with you. Let me give it a shot.
[Jeff] tells us that he designed Typeframe for his spouse to use as a writer deck. That’s good spousing, if you ask me. Amazingly, this is [Jeff]’s first project of this type and scope, and somehow it’s an elegant, yet easy build that’s quite well documented to boot. Whatever Typeframe’s design may borrow, it seems to give back in spades.

This Raspberry Pi 4B-based productivity machine has all sorts of neat features. The touch screen flips upward at an angle, so you don’t have to hunch over it or carry a mouse around. Want to sit back a bit while you work? The aesthetically spot-on keyboard is detachable. Yeah.
If that’s not enough to get you interested, Typeframe is designed for simple construction with minimal soldering, and the sliding panels make maintenance a breeze.
A little more about that keyboard — this is Keebin’, after all. It’s an MK Point 65, which boasts hot-swap sockets under those DSA Dolch keycaps. See? Minimal soldering. In fact, the only things you have to solder to make the Typeframe your own are the power switch and the status light. Incredible.
Decktility Goes Where You Go
Need something even more portable than the Typeframe? Something that might even fit in your cargo pocket? Decktility could be your answer. You’re gonna have to use your thumbs to type on this one, but that’s the price you pay for ultra portability.

The tricky part about using your thumbs is that the experience can be somewhat lacking. But the Bluetooth keyboard [Ken] used actually looks pretty good, and I say this based on this close-up from GitHub. The keys look responsive and the caps aren’t too shallow.
One of the design challenges centered around the batteries — 18650s, because as [Ken] says, flat Li-Pos get spicy when they short-circuit. Both the 18650s and the screen are somewhat heavy, so everything is balanced with the batteries acting somewhat as handles.
This is a great project, and it seems as though [Ken] learned a lot in the process. Be sure to check out the build log for all the gory details.
The Centerfold: Party Like It’s Nineteen Nine-T9

Rather than using predictive typing, the ScottoT9 uses QMK tap dance, wherein a single key can do ‘3, 5, or 100 different things’ depending on how many times you hit it in quick succession. [Joe] reports that it’s surprisingly easy get up to speed on the thing.
This RP2040 Pro Micro-based build is completely open source, including those lovely keycaps. But if you want them to look this good, you may want to just buy some.
Do you rock a sweet set of peripherals on a screamin’ desk pad? Send me a picture along with your handle and all the gory details, and you could be featured here!
Historical Clackers: the Diskret Code Typewriter
The Diskret (discreet) code typewriter from 1899 is a stunning German beauty of an index typewriter, far removed from the neon-accented see-through plastic label-maker from the late 80s that I often use.
Yet they are of the same spirit: choose a letter with some pointing device, imprint it with some lever action, and repeat.
Stark aesthetic differences aside, the Diskret does far more than my newfangled index typewriter. Designed with two concentric rings, the inner ring can be spun to allow the user to type in code.
For normal typewritering, the typist chose a letter from the outer ring of characters with a lever, which turned the typewheel mounted behind it. Then they would press down to print, and the carriage would advance by one character width to get ready for the next impression.
To use the Diskret as a cipher machine, the typist would spin the inner ring to create a false index, generating a coded letter. The recipient would have to have a Diskret in the same position in order to read the message. Yes, it’s basic, but it was one of the first code typewriters.
Most of this beautiful machine’s metal components were engraved with Jugendstil, or German Art Nouveau embellishments. It came mounted to a thick wood base, and featured a top with handle. A Diskret cost 75 marks, and, at the time, one mark equaled about $4. So, not exactly cheap, but it’s two typewriters in one.
Finally, Will Gen Alpha Cancel Keyboards Altogether?
No, of course not. But a study by the London School of Economics seems to think that the office drones of 2030 or so will skirt future first-draft keyboard use with AI voice typing tools, like everyday, all the time. And yeah, but they’ll have to use a keyboard to edit. Or, get this — they’ll just send voice notes to their bosses all the time. You know, good old unsearchable audio files that will be a pain to sift through later. Sure.
Did I mention that the study was done in collusion with Jabra, an audio-video technology company? They make highfalutin’ headsets and such. Ahem.
Now, I have a little secret — Y.T. has used powerful (and not-so-powerful) dictation tools here and there, especially after the surgery, and I could swear I’ve heard others talk-typing around the Hackaday Dungeon, although I can’t be sure. But I really like the act of typing, especially now that it doesn’t cause me intense, weird pain.
If I may cherry-pick a quote from the Fortune article, I choose this one: “speaking replaces typing because it matches how we think: fast, iterative, conversational.” I say all of that depends on your level of written wit, something that gets refined throughout the course of one’s life by, you know, writing or typing, and then reading, editing, removing, replacing, and so forth until it appears flowy and conversational.
And no, I didn’t speak-type a bit of this column. I missed typing on my Kinesis Advantage too much. See you next week-ish.
Got a hot tip that has like, anything to do with keyboards? Help me out by sending in a link or two. Don’t want all the Hackaday scribes to see it? Feel free to email me directly.
Watching Radioactive Decay with a Homemade Spinthariscope

Among the many science toys that have fallen out of fashion since we started getting nervous around things like mercury, chlorinated hydrocarbons, and radiation is the spinthariscope, which let people watch the flashes of light on a phosphor screen as a radioactive material decayed behind it. In fact, they hardly expose their viewers to any radiation, which makes [stoppi]’s homemade spinthariscope much safer than it might first seem.
[Stoppi] built the spinthariscope out of the eyepiece of a telescope, a silver-doped zinc sulfide phosphor screen, and the americium-241 capsule from a smoke detector. A bit of epoxy holds the phosphor screen in the lens’s focal plane, and the americium capsule is mounted on a light filter and screwed onto the eyepiece. Since americium is mainly an alpha emitter, almost all of the radiation is contained within the device.
After sitting in a dark room for a few minutes to let one’s eyes adjust, it’s possible to see small flashes of light as alpha particles hit the phosphor screen. The flashes were too faint for a smartphone camera to pick up, so [stoppi] mounted it in a light-tight metal box with a photomultiplier and viewed the signal on an oscilloscope, which revealed many small pulses.
While a spinthariscope is a bit easier to set up, they’re considerably less common among amateurs than are cloud chambers, another way to view radioactive decay. For scientific instruments, though, this project’s scintillator-and-photomultiplier approach is the standard, from tiny gamma ray spectrometers to giant neutrino detectors.
youtube.com/embed/ifEmv3BeM1I?…
Tech in Plain Sight: Pneumatic Tubes

Today, if you can find a pneumatic tube system at all, it is likely at a bank drive-through. A conversation in the Hackaday bunker revealed something a bit surprising. Apparently, in some parts of the United States, these have totally disappeared. In other areas, they are not as prevalent as they once were, but are still hanging in there. If you haven’t seen one, the idea is simple: you put things like money or documents into a capsule, put the capsule in a tube, and push a button. Compressed air shoots the capsule to the other end of the tube, where someone can reverse the process to send you something back.
These used to be a common sight in large offices and department stores that needed to send original documents around, and you still see them in some other odd places, like hospitals or pharmacy drive-throughs, where they may move drugs or lab samples, as well as documents. In Munich, for example, a hospital has a system with 200 stations and 1,300 capsules, also known as carriers. Another medical center in Rotterdam moves 400 carriers an hour through a 16-kilometer network of tubes. However, most systems are much smaller, but they still work on the same principle.
That Blows — Or Sucks?
Air pressure can push a carrier through a tube or suck it through the tube. Depending on the pressure, the carrier can accelerate or decelerate. Large systems like the 12-mile and 23-mile systems at Mayo Clinic, shown in the video below, have inbound pipes, an “exchanger” which is basically a switchboard, and outbound pipes. Computers control the system to move the carriers at about 19 miles per hour. You’ll see in the video that some systems use oval tubes to prevent the tubes from spinning inside the pipes, which is apparently a bad thing to do to blood samples.
In general, carriers going up will move via compressed air. Downward motion is usually via suction. If the carrier has to go in a horizontal direction, it could be either. An air diverter works with the blower to provide the correct pressures.
youtube.com/embed/-izeXQpRd_k?…
History
This seems a bit retro, but maybe like something from the 1950s. Turns out, it is much older than that. The basic system was the idea of William Murdoch in 1799. Crude pipelines carried telegram messages to nearby buildings. It is interesting, too, that Hero understood that air could move things as early as the first century.
In 1810, George Medhurst had plans for a pneumatic tube system. He posited that at 40 PSI — just a bit more than double normal sea-level air pressure — air would move at about 1,600 km/h. He felt that even propelling a load, it could attain a speed of 160 km/h. He died in 1827, though, with no actual model built.
In 1853, Josiah Latimer Clark installed a 200-meter system between the London Stock Exchange and the telegraph office. The telegraph operator would sell stock price data to subscribers — another thing that you’d think was more modern but isn’t.
Within a few years, the arrangement was common around other stock exchanges. By 1870, improvements enabled faster operation and the simultaneous transit of multiple carriers. London alone had 34 kilometers of tube by 1880. In Aberdeen, a tube system even carried fish from the market to the post office.
There were improvements, of course. Some systems used rings that could dial in a destination address, mechanically selecting a path through the exchange, which you can see one in the Mayo Clinic video. But even today, the systems work essentially the way they did in the 1800s.
Famous Systems
Several cities had pneumatic mail service. Paris ran a 467 km system until 1984. Prague’s 60 km network was in operation until 2002. Berlin’s system covered 400 km in 1940. The US had its share, too. NASA’s mission control center used tubes to send printouts from the lower floors up to the mission control room floor. The CIA Headquarters had a system running until 1989.
In 1920 Berlin, you could use the system as the equivalent of text messaging if you saw someone who caught your eye at one local bar. You could even send them a token of your affection, all via tube.
In 1812, there was some consideration of moving people using this kind of system, and there were short-lived attempts in Ireland, London, and Paris, among other places, in the mid-1800s. In general, this is known as an “atmospheric railroad.”
As a stunt, in 1865, the London Pneumatic Despatch Company sent the Duke of Buckingham and some others on a five-minute trip through a pneumatic tube. The system was made to carry parcels at 60 km/h using a 6.4-meter fan run by a steam engine. The capsules, in this case, looked somewhat like an automobile. There are no reports of how the Duke and his companions enjoyed the trip.
A 550-meter demonstration pneumatic train showed up at the Crystal Palace in 1864. Designed by Thomas Webster Rammell. It only operated for two months. A 6.7-meter fan blew air one way for the outbound trip and sucked it back for the return.
Don’t think the United States wasn’t in on all this, too. New York may be famous for its subway system, but its early predecessor was, in fact, pneumatic, as you can see in the video below.
youtube.com/embed/9g9dikUrbmk?…
Many of these atmospheric trains didn’t put the passengers in the capsule, but used the capsule to move a railcar. The Paris St. Germain system, which opened in 1837, used this idea.
Modern Times
Of course, where you once would send documents via tube, you’d now send a PDF file. Today, you mainly see tubes where it is important for an actual item to arrive quickly somewhere: an original document, cash, or medical samples. ThyssenKrupp uses a tube system to send toasty 900 °C steel samples from a furnace to a laboratory. Can’t do that over Ethernet.
There have been attempts to send food over tubes and even take away garbage. Some factories use them to move materials, too. So pneumatic tubes aren’t going away, even if they aren’t as common as they once were. In fact, we hear they are even more popular than ever in hospitals, so these aren’t just old systems still in use.
We haven’t seen many DIY pneumatic tube systems that were serious (we won’t count sucking Skittles through a tube with a shop vac). But we do see it in some robot projects. What would you do with a system like this? Even more importantly, are these still common in your area or a rarity? Let us know in the comments.
La Presidenza Del Consiglio e Giorgia Meloni Advisor di Senvix? Attenzione alle truffe online!
Un nuovo allarme sulla sicurezza nel mondo degli investimenti online viene portato all’attenzione da Paragon sec, azienda attiva nel settore della cybersecurity, che ha pubblicato su LinkedIn un post, riferendosi a una sito che prometterebbe guadagni facili ma potrebbe nascondere rischi fraudolenti.
Tale sito pubblicizza Senvix è una piattaforma di trading di criptovalute basata su intelligenza artificiale: analizza costantemente i dati di mercato (prezzi, volumi, sentiment) con algoritmi avanzati per identificare opportunità di trading e, a seconda della versione, può generare segnali o anche eseguire operazioni automaticamente tramite broker partner.
Cosa viene denunciato
Secondo il post dei ricercatori di sicurezza, diversi segnali relativi al dominio https://presidenzagoverno[.]com/ indicano che il sito in questione non sia una piattaforma di investimento legittima, ma un potenziale schema fraudolento.
Intanto il sito è un dominio .com e non ha la consueta estensione .gov.it. Sebbene non vengano specificati tutti i dettagli relativi al nome del dominio o ai numeri coinvolti, l’avvertimento invita gli utenti alla cautela e a non fidarsi di promesse di rendimenti elevati senza adeguata verifica.
L’intervento di Paragonsec rientra in un quadro più ampio di pericoli legati al trading online non regolamentato, un fenomeno sempre più sotto i riflettori e sul Quale spesso forniamo informative su Red Hot Cyber.
Inoltre all’interno del sito presidenzagoverno[.]com sono presenti diversi video deepfake, come ad esempio quello della presidente del consiglio dei ministri Giorgia Meloni, che riporta la qualità della piattaforma Senvix.

Il contesto delle truffe di trading online
Il trading online, soprattutto su criptovalute o mercati ad alta volatilità, è diventato terreno fertile per le frodi. Questo tipo di truffe è sempre più diffuso e comporta ingenti danni economici per gli investitori.
Molti truffatori fanno leva su messaggi accattivanti: “rendimento garantito“, “guadagni rapidi“, “nessun rischio“. L’utente medio, attratto da queste promesse, può cadere in siti non regolamentati, contattati via email, social network o perfino telefonate dirette.

Come riconoscere un sito di trading sospetto
Paragonsec, attraverso il suo post, sembra voler attivare un campanello d’allarme tra potenziali vittime. Ecco alcuni segnali di pericolo, confermati anche da fonti istituzionali:
- Mancanza di autorizzazioni – Un broker o una piattaforma di trading riconosciuta deve essere autorizzato da un ente di regolamentazione finanziaria nazionale (in Italia, la CONSOB) o da un organismo equivalente europeo.
- Promesse irrealistiche – Rendimenti elevatissimi, soprattutto se “garantiti” o costanti, sono un forte indicatore di potenziale schema Ponzi.
- Struttura web poco professionale – Siti mal progettati, con email da domini generici (es. Gmail), mancanza di documentazione regolamentare o informazioni societarie chiare sono segnali di scarsa affidabilità.
- Segnalazioni dall’autorità – La CONSOB, per esempio, ha una pagina “Occhio alle truffe” dove mette in guardia proprio su soggetti che non hanno l’autorizzazione.
- Difficoltà nei prelievi – Nei casi di broker truffaldini, gli utenti possono incontrare ostacoli al ritiro dei fondi, scuse tecniche o blocchi repentini.

Un precedente recente: il caso 2139 Exchange
Il post arriva in un momento in cui il tema delle truffe nel trading è particolarmente caldo. Un esempio significativo è il 2139 Exchange, una piattaforma che prometteva rendimenti altissimi (fino all’1% al giorno) ma su cui sono emerse forti sospetti di schema Ponzi.
La CONSOB ha preso provvedimenti: ha ordinato la chiusura e l’oscuramento di siti collegati all’exchange per abusivismo finanziario, dopo aver rilevato che la società non aveva le autorizzazioni previste.
Testimonianze di utenti riportano come, inizialmente, fosse possibile prelevare piccole somme: una tattica classica per alimentare la fiducia e attirare più “investitori”.

Cosa fare se si è di fronte a un possibile scam
Alla luce dell’allerta posta dai ricercatori di sicurezza, è fondamentale adottare comportamenti prudenti:
- Prima di investire, verificare il broker su siti ufficiali (ad esempio, cercando la sua registrazione CONSOB).
- Non farsi sedurre da guadagni straordinari senza garanzia.
- Conservare tutte le comunicazioni (email, screenshot, contratti) nel caso ci fosse la necessità di denunciare o richiedere assistenza legale.
- Diiffidare di sedicenti “aiutanti del recupero fondi”: spesso, i truffatori usano anche questa tattica secondaria. Il vademecum “Un calcio alle frodi” raccomanda di non versare denaro per presunti recuperi.
- Segnalare eventuali sospetti alle autorità competenti (polizia postale, CONSOB) e valutare l’assistenza di professionisti per capire come agire.
Conclusione
L’allarme è un richiamo importante per tutti coloro che operano (o vorrebbero operare) nel trading online: non tutto ciò che sembra un’opportunità lo è davvero.
Il mondo degli investimenti digitali è affascinante, ma anche insidioso. Solo con informazione, prudenza e verifiche puntuali è possibile tutelarsi da rischi seri, e potenzialmente rilevanti perdite economiche.
L'articolo La Presidenza Del Consiglio e Giorgia Meloni Advisor di Senvix? Attenzione alle truffe online! proviene da Red Hot Cyber.
Brussels' digital power grab
IT'S MONDAY, AND THIS IS DIGITAL POLITICS. I'm Mark Scott, and am getting a serious case of SAD now that the weather has turned. Luckily, someone created this playlist to make everything just a little bit better.

— The European Commission has big plans for digital. A lot of it means giving more power and control to Brussels.
— Are we reaching the end of an American internet?
— Almost 40 percent of children under 2-years old have access to a smartphone. Here are the figures to prove it.
Let's get started
ASGARD: Conti Bancari “Made in Italy” in VENDITA a partire da 80$! Sei tra le vittime?
Un’indagine su forum e piattaforme online specializzate ha rivelato l’esistenza di un fiorente mercato nero di account finanziari europei. Un’entità denominata “ASGARD”, sta pubblicizzando attivamente come il “Negozio di Account N.1“, offrendo la vendita di conti bancari, aziendali e servizi di scambio di criptovalute in numerosi Paesi UE, inclusa l’Italia.
Le offerte, promosse tramite materiale grafico professionale in lingua russa, specificano chiaramente la disponibilità di conti per diverse giurisdizioni, tra cui Spagna e Italia (EU SPAIN/ITALY), con prezzi che oscillano tra i $100 e i $650. Altri pacchetti riguardano conti in Francia (fino a $700) e Polonia/UK.

La Vendita di “Accessi” e i Rischi
Il venditore, che opera apertamente sotto il nome di “ASGARD”, sottolinea di non essere un “agente” ufficiale, un dettaglio che solleva immediatamente gravi preoccupazioni legali e di sicurezza. La merce offerta non è il servizio di intermediazione, ma l’accesso a conti già attivi.
Gli esperti di sicurezza informatica e riciclaggio di denaro ritengono che gli account venduti in contesti simili possano provenire da diverse fonti illecite:
- Identità Rubate (Identity Theft): Conti aperti da truffatori utilizzando documenti e dati personali sottratti a vittime ignare.
- Mule Finanziarie: Conti aperti da persone reclutate e pagate per fungere da intermediari (i “money mules”) per il riciclaggio di proventi criminali.
- Account Aziendali Fittizi: Conti creati per società di comodo, spesso utilizzati per frodi fiscali o schemi di riciclaggio su vasta scala.

Conti Italiani Sotto la Lente
Il fatto che i conti italiani siano esplicitamente inclusi nell’offerta (accanto a Spagna, Francia e Polonia) accende un faro sulla vulnerabilità dei sistemi di verifica KYC (Know Your Customer) di alcuni istituti finanziari operanti nel nostro Paese.
Il riferimento a banche specifiche, come ad esempio Santander e Revolut, suggerisce che l’operatore stia targettizzando istituti noti per la rapidità di apertura dei conti o per la loro natura digitale, sfruttandone eventuali debolezze nella fase di onboarding.

Per i cittadini italiani, i rischi sono duplici:
- Vittime del Furto d’Identità: I dati personali e i documenti potrebbero essere stati utilizzati per aprire il conto, rendendo il titolare originale corresponsabile involontario di qualsiasi attività illecita svolta con quell’account.
- Rischio di Frode: Chi acquista questi conti sul mercato nero lo fa quasi esclusivamente per riciclare denaro sporco, evadere il fisco o commettere frodi internazionali.
Il messaggio promozionale di ASGARD promette “Qualità e velocità”, caratteristiche che nel contesto del cyber-crimine si traducono in un servizio rapido per occultare la provenienza illecita del denaro.
Le autorità di polizia postale e la Guardia di Finanza sono costantemente impegnate nel monitoraggio di queste piattaforme. La vendita di questi “pacchetti finanziari” non regolamentati rappresenta una seria minaccia all’integrità del sistema finanziario europeo, facilitando la criminalità organizzata transnazionale e esponendo i cittadini al rischio di gravi sanzioni legali.
L'articolo ASGARD: Conti Bancari “Made in Italy” in VENDITA a partire da 80$! Sei tra le vittime? proviene da Red Hot Cyber.
Reverse Engineering the Miele Diagnostic Interface
")
Since modern household appliances now have an MCU inside, they often have a diagnostic interface and — sometimes — more. Case in point: Miele washing machines, like the one that [Severin] recently fixed, leading to the firmware becoming unhappy and refusing to work. This fortunately turned out to be recoverable by clearing the MCU’s fault memory, but if you’re unlucky, you will have to recalibrate the machine, which requires very special and proprietary software.

Naturally, this led [Severin] down the path of investigating how exactly the Miele Diagnostic Utility (MDU) and the Program Correction (PC) interface communicate. Interestingly, the PC interface uses an infrared LED/receiver combination that’s often combined with a status LED, as indicated by a ‘PC’ symbol. This interface uses the well-known IrDA standard, but [Severin] still had to track down the serial protocol.
Research started with digging into a spare 2010-era Miele EDPW 206 controller board with the 65C02-like Mitsubishi 740 series of 8-bit MCUs. These feature a mask ROM for the firmware, so no easy firmware dumping. Fortunately, the Miele@Home ‘smart appliance’ feature uses a module that communicates via UART with the MCU, using a very similar protocol, including switching from 2400 to 9600 baud after a handshake. An enterprising German user had a go at reverse-engineering this Miele@Home serial protocol, which proved to be incredibly useful here.
What is annoying is that the PC interface requires a special unlock sequence, which was a pain to figure out. Fortunately, the SYNC pin on the MCU’s pins for (here unused) external memory was active. It provided insight in which code path was being followed, making it much easier to determine the unlock sequence. As it turned out, 11 00 00 02 13 were the magic numbers to send as the first sequence.
After this, [Severin] was able to try out new commands, including 30 which, as it turns out, can be used to dump the mask ROM. This enabled the creation of a DIY transceiver you can tape to a fully assembled washing machine, for testing. As of now, the next target is a Miele G651 I Plus-3 dishwasher, which annoyingly seems to use a different unlock key.
Of course, you can just trash the electronics and roll your own. That happens more often than you might think.
Thanks to [Daniel] for the tip.
Pornografia algoritmica. Come i motori di ricerca amplificano lo sporco del web, sotto gli occhi di tutti
C’è un fenomeno noto ma di cui si parla poco, e che ogni giorno colpisce senza distinzione: la pornografia algoritmica.
È una forma di inquinamento semantico che trasforma l’identità digitale in un terreno di caccia.
Un solo algoritmo può trascinare milioni di nomi in una catena invisibile, spingendoli dove non dovrebbero apparire.
È il punto estremo dell’automatismo digitale: quando i motori di ricerca, invece di filtrare lo sporco del web, finiscono per amplificarlo.
Dal punto di vista tecnico, ciò che emerge è che questo fenomeno non nasce da un errore dell’algoritmo, ma da pratiche di Black Hat SEO applicate su scala industriale. I grandi portali per adulti generano automaticamente pagine costruite su combinazioni casuali di nomi reali e termini erotici con un unico obiettivo: intercettare ricerche, produrre traffico e alimentare circuiti pubblicitari.
Sono pagine create per sfruttare ogni possibile variazione semantica e trasformarla in impression monetizzabili. Ed è questa la ricerca condotta dal team di Red Hot Cyber, per spiegare il funzionamento di questo scempio digitale.
Nota dell’autore
In questo articolo non leggerete alcun nome reale all’interno del testo. È una scelta precisa.
La pornografia algoritmica vive di accoppiamenti linguistici ripetuti: basta che un nome compaia nel posto sbagliato perché gli algoritmi lo registrino, lo combinino, lo trascinino altrove. Ripeterlo qui significherebbe contribuire, anche solo per un istante, allo stesso meccanismo che l’indagine intende segnalare.
Per questo i nomi restano confinati negli screenshot tecnici, dove non generano nuove pagine indicizzabili né nuove associazioni. Sebbene Google disponga di tecnologie OCR molto avanzate e possa, in alcuni casi, leggere il testo contenuto nelle immagini, non esistono evidenze né documentazione ufficiale che mostrino un uso sistematico di queste informazioni per creare accostamenti sensibili nelle SERP. Nei contesti di analisi come questo, il testo presente negli screenshot ha esclusivamente valore documentale.
Segnalare un fenomeno richiede anche di non diventare parte della sua eco linguistica: quindi, i nomi restano fuori e parlano solo gli algoritmi.
L’esperimento: quando la politica incontra il porno
Basta una ricerca su Google per comprenderne la logica.
Non servono nomi reali: basta immaginare la struttura tipica delle query che generano le cosiddette pagine fantasma, cioè l’accoppiata “Nome Cognome + parola erotica”.
Il meccanismo segue sempre lo stesso schema: un nome reale, accostato a un termine sessuale, diventa il seme con cui gli algoritmi dei portali pornografici producono automaticamente nuove pagine e URL indicizzabili.



Sembra uno scherzo sporco
In realtà è una rete di pagine automatiche generate dai grandi portali pornografici, che producono migliaia di combinazioni tra nomi noti e parole erotiche.
Quando un nome viene cercato nei motori interni di questi siti o compare come query già intercettata da Google, il sistema lo usa come tag semantico per creare una nuova pagina pubblica. Anche se non esiste alcun contenuto effettivo, la piattaforma produce una struttura HTML coerente e indicizzabile.
Tecnicamente, queste pagine sono soft 404 o empty pages: rispondono con un codice 200 OK, ma non offrono alcun contenuto utile.
I motori di ricerca tendono comunque a includerle nell’indice perché il dominio è autorevole, la struttura SEO coerente e il pattern in linea con migliaia di altre pagine simili.
Così anche un titolo vuoto ma semanticamente tossico, in cui un nome reale viene accostato a termini che suggeriscono contenuti impropri, è sufficiente a innescare un’associazione nei modelli linguistici di ranking e suggerimento.
È il paradosso delle pagine fantasma: non mostrano nulla, ma inquinano tutto.

Quando l’algoritmo divora tutto
I dati ufficiali di Pornhub Insights – Year in Review 2024 confermano che le Olimpiadi di Parigi hanno avuto un impatto immediato sulle ricerche legate al mondo dello sport. Il report non indica una tempistica precisa, ma la tendenza è evidente: quando un evento domina il discorso pubblico, diventa materiale pornografico.
Nel terzo trimestre del 2024, le ricerche per termini come “swimmer” (+101%), “gymnastics” (+79%), “athlete” (+88%) e “volleyball” (+165%) sono esplose, insieme a query direttamente legate ai giochi, come “sex olympics” e “nude olympics”.
Il documento lo riassume così: tutto ciò che è “front and center” nella cultura viene inevitabilmente sessualizzato dagli utenti. Non è l’algoritmo a generare il fenomeno, ma il volume stesso delle ricerche: un’onda di attenzione collettiva che modella ciò che i sistemi automatici troveranno e organizzeranno.
È all’interno di questa dinamica – dove ciò che attira attenzione viene amplificato e replicato – che attecchiscono i meccanismi di inquinamento semantico descritti in questo articolo.


Doorway pages: il nome tecnico dell’inganno
Nel linguaggio di Google, le doorway pages sono pagine create per intercettare query specifiche e indirizzare l’utente altrove.
Servono a manipolare il ranking, non a informare.
Wikipedia le definisce pagine ponte o gateway pages: strutture progettate per influenzare gli indici dei motori di ricerca.
Le dinamiche osservate nei portali per adulti seguono lo stesso principio, non tanto nell’intento quanto nell’effetto.
Si tratta di pagine generate in serie, con titoli costruiti su combinazioni di parole e reindirizzamenti interni che generano traffico anche senza alcun contenuto.
SEO Porn Automation: il motore dell’inganno
Dietro questo meccanismo non c’è un attacco diretto, ma una strategia puramente economica.
I siti per adulti vivono di traffico: più keyword intercettano, più click generano.
E ogni click significa pubblicità, tracciamento, cookie e profili vendibili.
Per moltiplicare le visite, i motori porno usano generatori automatici di pagine (SEO farming) che combinano parole comuni e nomi reali in modo massivo:
{persona, istituzione, testata giornalistica, evento} + {parola chiave}
È una formula semplice, ma devastante: migliaia di nuove URL ogni giorno, tutte con lo stesso layout, stesso stack server, stessi cookie “settings”, stessa CDN.
Associazione semantica: il lato oscuro del SEO
Il danno non è solo morale. È strutturale.
Quando il nome di una persona finisce accanto a parole sessuali, gli algoritmi di ricerca apprendono quell’associazione. Anche se la pagina è vuota, anche se nessuno la cerca davvero.
È l’equivalente digitale di una macchia indelebile: invisibile ai più, ma incisa nel grafo semantico che definisce la nostra identità online.
È quello che potremmo definire “porn reputation poisoning” – un avvelenamento reputazionale algoritmico, dove la contaminazione non riguarda i contenuti, ma il linguaggio che li collega.
Le vittime non lo sanno
La parte più preoccupante è la sua invisibilità.
Le vittime raramente se ne accorgono.
Spesso non cercano il proprio nome con parole simili, né ricevono notifiche dai motori di ricerca.
Quasi mai vedono immagini o contenuti espliciti: solo titoli.
Eppure il danno d’immagine si propaga, silenzioso, nei suggerimenti e nelle ricerche correlate.
Solo tramite analisi OSINT o monitoraggi reputazionali mirati si scopre la reale estensione del fenomeno: migliaia di risultati “fantasma”, in cui figure pubbliche o istituzioni italiane vengono accostate a contesti pornografici senza che vi sia alcun contenuto vero.

L’ambiguità come scudo: l’arma dell’omonimia
Dal punto di vista delle regole e delle responsabilità online, non c’è un reato immediato
non ci sono immagini, non ci sono video falsi, e nessuno “pubblica” qualcosa di diffamatorio in senso classico.
A generare tutto è un processo automatico: l’esecuzione impersonale di un algoritmo che applica le proprie regole senza distinguere contesto o identità.
In più, il meccanismo sfrutta quasi sempre una zona grigia precisa: l’omonimia.
Le pagine generate automaticamente non mostrano volti, né immagini, né video reali.
Si limitano a ripetere un nome, che può appartenere a chiunque, accostandolo a parole erotiche.
Dal punto di vista tecnico, questo rende difficile stabilire se la combinazione si riferisca a una persona specifica o a un nome generico.
Ed è proprio questa ambiguità a diventare la chiave: nessun volto, nessuna prova, nessuna responsabilità.
I portali per adulti giocano su questa soglia.
Il risultato è che persone diverse, accomunate solo da un nome, finiscono legate allo stesso contesto semantico.
Una trappola perfetta: legalmente difendibile, ma reputazionalmente pericolosa.
Una forma di danno digitale?
Questa è la parte più importante:
il fenomeno non è solo SEO spinto. È una forma di rischio per la reputazione digitale.
Colpisce soprattutto:
- figure pubbliche o in posizioni di potere usate come “esca semantica” per traffico pornografico;
- donne e uomini della politica, giornaliste/i, avvocate/i
- chiunque abbia un’identità digitale significativa
Non serve un deepfake: basta un titolo sbagliato, replicato un milione di volte.

È in questo contesto che la fase sperimentale diventa decisiva.
La prova dai terminali
Dopo aver ricostruito il meccanismo teorico della pornografia algoritmica, la fase successiva è stata verificarne l’esistenza empirica.
Quattro esperimenti distinti, condotti in ambiente PowerShell e successivamente validati con analisi forense e modelli di intelligenza artificiale, hanno permesso di osservare il fenomeno in azione, confermandone la natura sistematica, automatica e riproducibile.
Ogni test esplora un diverso anello della catena algoritmica:
- Generazione – come i portali per adulti creano automaticamente pagine associate a nomi reali, anche in assenza di contenuto.
- Indicizzazione – come i motori di ricerca registrano temporaneamente quelle pagine, associando nomi e parole chiave tossiche.
- Amplificazione – come i sistemi di tracciamento esterni (es. Bing) contribuiscono a diffonderle e mantenerle in visibilità.
- Convalida semantica – come l’analisi forense e l’intelligenza artificiale dimostrano che tali associazioni non hanno alcun legame linguistico reale, ma sono il risultato di correlazioni statistiche indotte dagli algoritmi di ranking.
La macchina che sporca i nomi: il comportamento dei portali Aylo
Il primo test ha coinvolto i principali portali del gruppo Aylo (ex MindGeek) – Pornhub, YouPorn, RedTube, Tube8, Spankwire, KeezMovies e Brazzers – utilizzando un insieme di termini neutri e istituzionali. Su tutti i domini, il comportamento si è ripetuto senza eccezioni: l’inserimento di un nome, anche non collegato al mondo adulto, provoca la generazione immediata di una pagina pubblica, formalmente valida e accessibile, anche quando non esistono risultati pertinenti. In ogni caso, la pagina carica comunque le risorse della piattaforma pubblicitaria proprietaria di Aylo (trafficjunky), insieme alla CDN cdn77.net, come se la query avesse restituito contenuti reali.
I log raccolti con PowerShell lo mostrano chiaramente. Le stringhe individuate – trafficjunky, ads.trafficjunky.net, static.trafficjunky.com, pix-ht.trafficjunky.net e pix-cdn77 – indicano che il codice HTML della pagina, anche quando riporta “0 risultati”, attiva risorse pubblicitarie complete: script JavaScript, pixel di tracciamento, endpoint dell’asta, immagini dei banner e moduli di misurazione. Non si tratta di elementi ornamentali: sono gli stessi asset che gestiscono impression, profilazione e ricavi.
Questa dinamica offre un primo indizio chiave: anche quando la pagina non contiene alcun video, la monetizzazione viene attivata. Basta che la pagina esista – anche senza contenuti – perché il circuito economico parta.


Validazione tecnica aggiuntiva: il browser headless
Per escludere ogni dubbio riguardo alla reale esecuzione di questi script, il test è stato replicato con un browser headless basato sul DevTools Protocol. A differenza dell’analisi del sorgente HTML, questa tecnica intercetta in diretta tutte le chiamate di rete, replicando esattamente il comportamento di un browser reale.
La sessione eseguita su Pornhub ha evidenziato richieste dirette agli script pubblicitari di TrafficJunky, agli endpoint dell’asta ads_batch, alle immagini dei banner caricate attraverso cdn77 e persino ai pixel analitici di Google Analytics. Questi elementi non provengono da una lettura statica del codice: sono risorse scaricate, inizializzate e attive durante la navigazione. Ciò conferma che la pagina, anche quando non restituisce risultati, avvia l’intera pipeline tecnica predisposta per visibilità, tracciamento e monetizzazione.
Il comportamento osservato è identico a quello di una pagina che contiene veri contenuti: gli script vengono caricati, le misurazioni avviate, gli endpoint pubblicitari contattati, le risorse CDN richieste e i sistemi di analisi attivati. La sola generazione della pagina basta a mettere in moto l’intero sistema: anche senza risultati video, la pagina attiva comunque l’intero circuito di delivery pubblicitaria.


I numeri dell’esperimento
Nel complesso sono stati testati otto termini su otto domini, per un totale di sessantaquattro richieste, analizzate prima in PowerShell e poi con il browser headless. Solo Pornhub ha restituito risultati reali: 560 link nella sola prima pagina. Tutti gli altri siti hanno generato cinquantasei pagine “fantasma”, strutturalmente identiche ma prive di contenuto.
Tutte però – senza eccezioni – hanno risposto con codice 200 OK, presentavano un titolo SEO valido, uno scheletro HTML completo e l’esecuzione degli stessi script pubblicitari già osservati su Pornhub.
Il risultato è inequivocabile: ogni query, anche priva di significato, produce una pagina pronta per essere indicizzata, monetizzata e tracciata. L’associazione tra nomi reali e contesto erotico non nasce da contenuti effettivi, ma da un processo automatico di generazione e monetizzazione integrato nell’infrastruttura stessa di questi portali.

I comportamenti fuori dal circuito Aylo
Per verificare se il comportamento osservato nei siti del gruppo Aylo fosse un’eccezione o un pattern più ampio, è stata condotta una seconda analisi su una serie di piattaforme indipendenti: XVideos, xHamster, FapHouse e SoloPornoItaliani.
La metodologia è rimasta identica: scansione headless da terminale, query standardizzate, logging completo di ogni risorsa caricata.
A differenza del circuito Aylo – che genera pagine senza contenuto – i portali non appartenenti allo stesso gruppo mostrano tre comportamenti distinti, tutti riconducibili a forme diverse di “pornografia algoritmica”.

Pagine popolate realmente (XVideos, xHamster)
XVideos e xHamster sono gli unici portali a restituire risultati coerenti con la dinamica del nome: decine di thumbnail, contenuti visivi e un caricamento massiccio di risorse attraverso CDN come cdn77 e gcore, insieme a circuiti pubblicitari esterni come ExoClick.
In questo caso il nome digitato non genera pagine fantasma:
il portale costruisce accoppiamenti semantici reali, producendo centinaia di immagini e anteprime anche quando non esiste alcuna correlazione reale con la persona cercata.

Questo approccio offre due vantaggi decisivi:

1- La pagina appare “piena” agli occhi dell’algoritmo.
Google non la classifica come Soft 404 perché trova contenuti reali: immagini, titoli, tag, markup strutturale.
Il risultato è che l’associazione “nome + porno” diventa molto più stabile e difficile da rimuovere.
2- La pagina genera più rendita economica.
Ogni thumbnail carica risorse aggiuntive, banner, cookie e script pubblicitari.
Anche se il contenuto non ha alcun legame con il nome cercato, la pagina resta monetizzabile e mantiene un valore elevato nel circuito della pubblicità programmatica.
In altre parole:
le piattaforme non si limitano a creare l’associazione: la rafforzano e ci guadagnano sopra.
Pagine “ibride”: contenuti veri ma non legati alla query (FapHouse, SoloPornoItaliani)
Le scansioni su FapHouse e SoloPornoItaliani mostrano un comportamento intermedio: le pagine esistono, rispondono con codice 200 OK e caricano decine di video reali da CDN esterne, ma non hanno alcun rapporto con il nome inserito. Non si tratta di pagine fantasma come nei portali Aylo, bensì di sostituzioni algoritmiche: la query viene ignorata e lo spazio viene riempito con contenuti generici, mentre l’intero circuito pubblicitario continua a funzionare come se esistesse un risultato pertinente.
La raccolta del termine digitato (SoloPornoItaliani)
L’analisi headless rivela un comportamento più delicato. Su SoloPornoItaliani, il nome inserito nella ricerca viene inviato in chiaro a Google Analytics attraverso il parametro:
ep.search_term=<nome>
La piattaforma trasmette quel valore all’endpoint ufficiale GA4:
google-analytics.com/g/collect
Il termine digitato diventa così un dato comportamentale, non un contenuto visualizzato. Entra nei log analitici della piattaforma come evento di ricerca. Questo passaggio produce tre conseguenze dirette:

- il nome entra nel dataset interno, indipendentemente dalla pertinenza dei contenuti mostrati;
- la query alimenta le logiche di profilazione e può contribuire alle strategie di monetizzazione;
- il valore può essere riutilizzato nei sistemi di raccomandazione o nei modelli di analisi del comportamento.
Le controprove ottenute con parole inventate, stringhe casuali e nomi reali confermano la natura sistemica del meccanismo: qualsiasi valore inserito viene trasmesso a Google senza mascheramento.

Il caso opposto: FapHouse non traccia il termine
FapHouse si comporta in modo diverso. Il sito carica molte risorse, usa CDN esterne e attiva gli script pubblicitari, ma non registra il testo inserito. Nei log non compare alcun parametro riconducibile alla query.
La piattaforma monitora l’interazione con la pagina, ma esclude il nome digitato dai suoi flussi di tracciamento.
Monetizzazione invariata: la query non serve
Nonostante la differenza nel trattamento del termine di ricerca, entrambe le piattaforme producono valore economico in modo identico. Gli script si attivano, le CDN distribuiscono i contenuti e i circuiti pubblicitari registrano impression e richieste come se la pagina contenesse un risultato reale.
Il sistema monetizza anche quando la ricerca non genera alcuna corrispondenza.
Interpretazione complessiva
La contaminazione semantica non dipende dal contenuto della pagina, ma dal percorso che la query compie all’interno dell’infrastruttura.
Quando il nome viene registrato – come accade su SoloPornoItaliani – entra nella catena che alimenta la monetizzazione, la profilazione e la costruzione di pattern comportamentali. La piattaforma tratta il nome come un segnale utile, anche se non lo mostra a schermo e non lo collega a contenuti pertinenti.
Questo implica che:
- il nome non appare nella pagina, ma viene memorizzato;
- non determina i contenuti, ma entra nei dataset interni;
- non personalizza la ricerca, ma alimenta i sistemi di misurazione e remarketing.
La pornografia algoritmica, in questa forma, non costruisce solo associazioni visive: costruisce associazioni statistiche.
Ed è proprio questa la sua caratteristica più insidiosa: una forma di inquinamento semantico silenziosa e difficile da intercettare.
Intermezzo tecnico – La vulnerabilità temporale del ranking
Come emerso nei test precedenti, molti portali adulti restituiscono pagine formalmente valide – codice 200 OK e titolo SEO completo – anche quando il contenuto è inesistente. Questa caratteristica strutturale, già osservata tanto nei domini Aylo quanto in quelli indipendenti, è il punto di partenza per comprendere un fenomeno più sottile: la finestra temporale in cui i motori di ricerca trattano queste pagine come se fossero autentiche.
I test PowerShell condotti su vari portali adulti hanno mostrato risposte del tipo:
adult-network] /search/ 200 375900“[termine] Video Porno | [adult-network]” False 
La finestra di favore: l’honeymoon SEO
Questo comportamento rispecchia quello che, in ambito tecnico, viene definito honeymoon SEO o honeymoon period: una fase iniziale in cui Google testa e indicizza rapidamente nuove pagine o nuovi domini, garantendo loro una visibilità temporanea utile a valutarne la qualità.
In questo intervallo, qualunque URL, anche se generata automaticamente e priva di contenuti, può comunque ottenere un posizionamento provvisorio. Le URL osservate durante i test mostrano infatti un pattern coerente con la creazione o rigenerazione automatica di contenuti effimeri, progettati per durare il tempo necessario a essere esaminati prima del naturale declassamento.
L’analisi PowerShell degli header HTTP ha confermato questa dinamica: la presenza delle direttive transfer-encoding: chunked e cache-control: no-cache, no-store, must-revalidate indica che le pagine vengono generate in tempo reale e non servite da cache.
Durante questo breve ciclo di valutazione, l’algoritmo analizza gli accessi e i segnali esterni, assegnando temporaneamente una posizione più alta nei risultati. È proprio qui che i gestori più esperti, anche nei settori borderline come l’adult, sfruttano l’occasione per massimizzare i ricavi prima che la pagina venga rimossa o scivoli naturalmente nel ranking.

Sintesi dell’intermezzo
Quanto emerso mostra dunque che la pornografia algoritmica non si limita a creare pagine inesistenti: sfrutta il modo in cui i motori di ricerca testano e valutano pagine nuove.
È in questa finestra temporale, rapida e silenziosa, che l’associazione semantica prende forma.
E anche se la pagina viene presto declassata, l’impronta nei sistemi di suggerimento può rimanere più a lungo del contenuto stesso.
Analisi forense del reindirizzamento
Durante l’analisi delle SERP di Bing, i collegamenti che portavano a risultati pornografici anomali – apparentemente associati a nomi reali o sigle politiche – mostravano una struttura comune: un dominio di Bing seguito da una lunga catena di parametri, tra cui il campo u=.
Questa architettura non è casuale.
Bing, come altri motori di ricerca, utilizza un sistema di reindirizzamento interno che non invia l’utente direttamente al sito di destinazione, ma passa prima per un URL intermedio di tracciamento.
Lo scopo dichiarato è misurare i click e migliorare la qualità dei risultati, ma tecnicamente questa struttura consente di offuscare l’indirizzo reale finché non viene decodificato o aperto dal browser.
Un esempio concreto del collegamento analizzato è il seguente:
Il parametro u= contiene, in forma codificata Base64 e preceduta dal prefisso a1, l’URL effettivo verso cui Bing reindirizza l’utente dopo il click.
Decodifica del parametro di reindirizzamento
L’analisi, condotta in ambiente PowerShell, ha decodificato la sequenza normalizzando il prefisso e ricomponendo il padding necessario alla conversione.
Il risultato ha rivelato in chiaro l’indirizzo originale della query, riconducibile al portale Pornhub.
A conferma dei risultati, una successiva interrogazione HTTP di tipo HEAD ha restituito come host di risposta lo stesso dominio, senza passaggi intermedi né redirect di terze parti.
La ricostruzione evidenzia che il link non proviene da un sito esterno, ma da un meccanismo interno di generazione dinamica del portale Pornhub, che crea automaticamente pagine di ricerca per qualunque termine indicizzato, inclusi nomi di persone, marchi o sigle politiche.

Target dell’esperimento: il caso di una testata giornalistica
L’indagine è stata focalizzata su un insieme di query in cui compariva impropriamente il nome di una testata giornalistica italiana accostato a keyword di natura pornografica.
Tali risultati, presenti su diversi motori di ricerca, indicano un comportamento assimilabile al SEO poisoning e al keyword hijacking: un’alterazione automatica del ranking che associa entità riconoscibili, come marchi o media, a categorie erotiche, sfruttandone la reputazione per generare traffico spurio.
L’obiettivo tecnico era determinare se tale associazione derivasse da una reale affinità linguistica o da un meccanismo algoritmico privo di coerenza semantica.
L’indagine si è svolta in ambiente isolato e privo di cache, mediante un motore di raccolta automatica capace di interrogare più piattaforme di ricerca, acquisire HTML, titoli, screenshot e metadati HTTP, e salvarli in formato forense con marcatura temporale.

Metodologia tecnica
Crawling forense
Lo script ha interrogato in parallelo i principali motori di ricerca, simulando la navigazione di un utente reale, e ha acquisito le relative risposte HTTP con i parametri di header, stato e tempo di risposta.
Ogni sessione di test è stata replicata e confrontata per escludere variazioni temporanee o di geolocalizzazione.
Hashing e integrità dei dati
Tutti gli elementi raccolti (HTML, immagini, log e metadati) sono stati sottoposti a hashing tramite algoritmo SHA-256, producendo firme digitali univoche per ogni evidenza.
Gli hash garantiscono che nessun dato sia stato alterato dopo l’acquisizione: ogni evidenza è tracciabile, verificabile e conforme agli standard di digital forensics.
Analisi semantica AI
Nella fase cognitiva è stato impiegato un modello neurale SentenceTransformer (paraphrase-multilingual-MiniLM-L12-v2), costruito su architettura Transformer multilingue con 12 strati e 384 dimensioni vettoriali.
Il modello genera embedding semantici dei termini analizzati e calcola la cosine similarity tra il vettore di riferimento e quello associato alle categorie in cui i termini compaiono impropriamente.
Sono state confrontate coppie come “nome della testata” 
Il modello opera in modalità descrittiva: misura la distanza vettoriale tra i termini senza applicare livelli inferenziali o interpretativi di tipo semantico.
Il valore medio di similarità (0.22) mostra l’assenza di un legame linguistico significativo. Su una scala da 0 a 1, questo valore corrisponde a una relazione semantica trascurabile.
In questo contesto, i motori di ricerca tendono ad amplificare associazioni che non esistono nel linguaggio naturale, ma soltanto nella logica di ranking automatizzato.
Risultato
L’analisi ha confermato che le pagine individuate non contenevano contenuti reali.
Si trattava di strutture SEO automatizzate, progettate per attrarre traffico attraverso accoppiamenti linguistici casuali e privi di coerenza semantica.
Le correlazioni osservate tra i termini risultano artificiali, deboli e indotte: una prova tecnica che il fenomeno è un’anomalia di indicizzazione algoritmica, e non un comportamento umano o editoriale.



Un disegno, non un errore
Le evidenze raccolte non dimostrano che le pagine osservate rimarranno stabilmente nelle SERP, ma mostrano un fatto più rilevante: la generazione automatica di pagine idonee all’indicizzazione è sistematica, riproducibile e coerente su tutti i portali analizzati.
Gli esperimenti confermano, con un elevato grado di confidenza, che il fenomeno non nasce da anomalie sporadiche, ma da un’architettura progettata per trasformare ogni query in traffico monetizzabile. È un sistema che pubblica, traccia ed esegue script pubblicitari anche quando il contenuto reale non esiste.
Non è un attacco verso persone, istituzioni o testate: è un processo automatico che ingloba qualunque termine digitato, trascinandolo dentro un ecosistema dove la visibilità conta più della coerenza semantica. Ogni nome associato a una keyword erotica viene trattato come un’informazione utile, non come un’identità da tutelare.
In questo scambio dove il significato pesa meno della possibilità di generare impression, il confine tra algoritmo e responsabilità si assottiglia. Il traffico diventa il vero prodotto: ogni pagina generata, ogni richiesta di rete, ogni cookie e ogni evento registrato alimentano un’economia che non vende contenuti, ma attenzione.
Perché conviene davvero (e quanto vale una pagina in più)
Una pagina generata automaticamente – anche quando non mostra alcun video – ha comunque un valore economico. Non perché offra contenuti utili, ma perché entra nel flusso di impression che sostiene l’intera industria pubblicitaria dei portali per adulti. In questo modello, ciò che conta non è la pertinenza della pagina, ma il suo contributo numerico alla massa complessiva di richieste servite ogni giorno.
I dati ufficiali mostrano la scala:
TrafficJunky supera i 6,5 miliardi di impression al giorno, ExoClick oltre 12 miliardi, Adsterra arriva a circa 35 miliardi. Dentro queste dimensioni, anche millesimi di centesimo generati da una singola pagina hanno un peso, perché ampliano l’inventory vendibile e rafforzano la capacità della piattaforma di attrarre inserzionisti.
È così che funziona l’economia dei portali per adulti: un pixel che scatta, uno script che si carica, una sessione che viene registrata. Ogni elemento diventa valore. Una pagina in più non cambia il panorama, ma contribuisce a far girare una macchina costruita per monetizzare ogni richiesta utile, indipendentemente dal contenuto.

L’altra faccia della medaglia
Dopo l’aggiornamento antispam di Google dell’agosto 2025, le metriche di visibilità organica hanno mostrato un comportamento anomalo.
Si è registrato un picco improvviso di volatilità, seguito da un rallentamento costante.
Il dato indica che il motore ha tentato di ricalibrare i segnali di fiducia associati alle pagine generate automaticamente.
Ha ridotto la loro visibilità, ma non è riuscito a rimuoverle completamente dal grafo semantico.
Le evidenze osservate nei grafici di ranking e nelle SERP non dimostrano un legame causale diretto tra lo Spam Update e la pornografia algoritmica, ma rivelano una correlazione coerente.
I picchi di volatilità e le associazioni spurie ancora visibili nelle ricerche mostrano che il fenomeno non è stato eliminato.
È solo attenuato, una distorsione residua che sopravvive nei modelli di ranking e nei sistemi di completamento automatico.

Persistenza algoritmica
Anche dopo la deindicizzazione o il declassamento, le relazioni semantiche tra nomi reali e keyword pornografiche continuano a esistere nei modelli di ranking e nei sistemi di query suggestion.
L’algoritmo conserva la memoria statistica dell’associazione, influenzando le predizioni e la percezione di pertinenza.
Questo effetto collaterale deriva direttamente dalla logica distribuita dei modelli linguistici che alimentano i motori di ricerca.
Contaminazione del grafo semantico
Sul piano tecnico, il fenomeno produce una contaminazione del grafo semantico, la rete interna che Google utilizza per collegare un nome ai suoi significati, ai contesti in cui compare e alle entità con cui interagisce. Le co-occorrenze tossiche riducono la fiducia dei segnali associati al nome (entity trust) e generano keyword dilution. Ne derivano micro-penalizzazioni nei cluster tematici. Nei casi prolungati, la riduzione del punteggio di pertinenza può provocare un vero e proprio SERP decay: un abbassamento progressivo del posizionamento dei contenuti legittimi legati alla stessa entità.
Un danno strutturale
La pornografia algoritmica, in questo senso, non colpisce solo la reputazione individuale.
Agisce sul tessuto stesso del web.
Non si limita a sporcare i risultati: altera la memoria dei motori di ricerca, riscrivendo in modo silenzioso le connessioni statistiche da cui dipende la nostra identità digitale.
L’algoritmo del desiderio. Come l’industria del porno parla con Google
Dietro le luci dei portali per adulti si muove un’industria metodica che non produce soltanto video, ma codice, parole chiave e strategie di posizionamento.
Nel suo linguaggio, il desiderio non è più un impulso umano: è una metrica.
Ogni emozione, ogni clic, ogni microsecondo di attenzione viene convertito in un segnale economico, destinato ai motori di ricerca.
A confermarlo non sono ipotesi, ma documenti interni dello stesso settore.
Uno in particolare, pubblicato nel 2023 da Traffic Cardinal e circolato tra alcune agenzie di marketing per adulti, descrive con minuzia le tecniche di affiliazione e monetizzazione del traffico erotico.
Non è un manuale promozionale: è una grammatica industriale del desiderio online.
Il desiderio come dato
Nel capitolo introduttivo, la guida spiega che l’adult affiliate marketing è un gioco a tre: inserzionista, affiliato e utente.
L’obiettivo è semplice: acquistare traffico al prezzo più basso possibile e rivenderlo come azione monetizzabile.
Ogni clic, ogni registrazione, ogni caricamento di pagina ha un prezzo.
Il documento lo dice esplicitamente:
“L’idea generale è acquistare traffico, selezionare un pubblico caldo e ottenere l’azione target pagata dall’inserzionista.”
In questa logica, l’attenzione diventa materia prima.
Il testo parla di “pubblico affidabile”, “lead motivati” e “conversioni istantanee”: un lessico che traduce l’intimità in comportamento prevedibile.
È la nascita di una psicologia algoritmica del desiderio.
La doppia realtà del web
Per superare i filtri e le regole pubblicitarie, l’industria ricorre agli stessi meccanismi individuati nelle analisi tecniche del fenomeno: duplicazione di pagine, cloaking e mascheramento dei contenuti.
La prima si chiama cloaking: mostrare due versioni dello stesso sito, una “whitehat” per i moderatori e i crawler di Google, e una reale per l’utente.
“Mostra ai moderatori una landing page conforme alle regole, mentre il pubblico osserva la versione completa. Il bot sarà ingannato due volte, ma l’utente capirà il suggerimento.”
È la riproduzione tecnica della pornografia algoritmica: una rete che parla due lingue, una per l’algoritmo e una per l’uomo.
Pre-lander: le pagine fantasma
Un’altra sezione della guida illustra il concetto di pre-lander su Fleek:
pagine “intermedie”, neutre nell’aspetto, progettate per farsi indicizzare da Google e reindirizzare poi verso portali pornografici o piattaforme di webcam.
“Sembrano siti reali”, scrive la guida, “così i moderatori concedono il via libera.”
Sono le stesse pagine fantasma individuate nelle SERP: strutture apparentemente regolari, ma semanticamente vuote e perfettamente leggibili per l’algoritmo.
Un web specchio costruito per riflettere attenzione, non informazione.
Smartlink: il desiderio automatico
Il passo successivo è l’automazione.
Gli smartlink sono collegamenti dinamici che analizzano in tempo reale geolocalizzazione, dispositivo, lingua e ora del clic per decidere quale offerta mostrare.
“Gli algoritmi incorporati ricevono i dati relativi ai clic, analizzano gli utenti e li inviano al sito più redditizio.”
È la stessa logica dei sistemi di raccomandazione, applicata al sesso.
Un apprendimento continuo che adatta il contenuto all’utente senza che l’utente se ne accorga.
In questo modo, il marketing adulto parla la lingua dei motori: parole chiave, pattern, coerenza semantica, conversione.
Creatività invisibili e semiotica dell’allusione
Poiché i social e i circuiti pubblicitari vietano l’esplicito, i marketer imparano a usare metafore visive e linguaggio codificato: banane, melanzane, frutti tropicali, doppi sensi.
Il manuale spiega perfino come sovrapporre immagini neutre a quelle erotiche per “ingannare i bot di moderazione”.
La semiotica dell’allusione funziona così: segni che l’algoritmo non riconosce ma che il pubblico umano decifra all’istante.
È un linguaggio sotterraneo, fluido, capace di passare inosservato nei sistemi di controllo automatico.
Economia della curiosità
In questo ecosistema, il valore non dipende da ciò che una pagina offre, ma dal comportamento che riesce a generare.
Ogni pagina diventa un ponte di conversione che trasforma la curiosità in ROI.
Il documento cita casi di studio con rendimenti fino all’86% in venti giorni, ottenuti tramite notifiche push, teaser e campagne di cloaking su larga scala.
L’industrializzazione del desiderio è un meccanismo che trasforma l’interesse umano in merce misurabile, rivenduto sotto forma di spazio pubblicitario.
Il linguaggio dell’algoritmo
La sintassi di questo sistema è elementare:
- Generare traffico
- Adattarlo
- Mascherarlo
- Monetizzarlo
Il contenuto in questo contesto è irrilevante.
Conta solo la sua leggibilità algoritmica: keyword, permanenza, click-through rate.
In questa logica, Google non è più osservatore, ma interlocutore: il vero destinatario del messaggio pubblicitario.
I portali per adulti non parlano agli utenti, ma ai motori di ricerca.
È con loro che stringono il patto linguistico: visibilità in cambio di conformità semantica.
La macchina del desiderio
La guida di Traffic Cardinal non parla di pornografia: parla di ottimizzazione.
Eppure, tra le righe, rivela che la pornografia è solo il pretesto funzionale di un’economia che ha imparato a tradurre il desiderio in dato, e il dato in valore.
Il piacere non è più l’obiettivo, ma un effetto collaterale.
Ciò che conta è la sua tracciabilità: il segnale che genera traffico, il traffico che genera profitto.
E nel silenzio dei crawler, i motori di ricerca ne diventano inconsapevolmente la lingua madre.
Epilogo: quando neppure i grandi sono al sicuro
Nell’ottobre 2025 persino The Walt Disney Company si è trovata vittima di un meccanismo simile, ma in un contesto del tutto diverso dal mondo adult. Per alcuni giorni, tra i risultati ufficiali di My Disney Account, Google mostrava un titolo anomalo:
“Buy Black Hat SEO Packages – My Disney”.
Non si trattava di un attacco informatico, ma dell’effetto di un inquinamento semantico indotto.
Decine di domini esterni avevano collegato l’URL legittimo a quell’ancora testuale, generando un segnale artificiale di pertinenza.
L’algoritmo ha interpretato la combinazione come rilevante e ha riscritto automaticamente il titolo della pagina ufficiale.
Google ha corretto l’errore in quarantotto ore.
Ma milioni di nomi meno noti restano imprigionati in quelle stesse dinamiche per settimane, talvolta per mesi.
Invisibili agli occhi del pubblico, ma non alla memoria dei motori di ricerca.

La pornografia algoritmica, dopotutto, non riguarda solo il sesso.
Riguarda il potere di decidere chi resta sporco e chi viene lavato via.
La prossima volta che cerchiamo un nome su Google, chiediamoci:
chi lo ha scritto davvero, e chi ci guadagna se ci clicchiamo sopra?
L'articolo Pornografia algoritmica. Come i motori di ricerca amplificano lo sporco del web, sotto gli occhi di tutti proviene da Red Hot Cyber.
16 anni di Go: un linguaggio di programmazione innovativo e scalabile
Nel novembre 2025, il linguaggio di programmazione Go ha compiuto 16 anni. È stato rilasciato pubblicamente il 10 novembre 2009, come esperimento di Google per creare un linguaggio semplice e veloce per grandi sistemi distribuiti. Oggi è uno strumento chiave per lo sviluppo lato server moderno. L’attuale versione stabile ha raggiunto la versione 1.25.4 di Go, con patch di sicurezza regolari e miglioramenti al runtime e alla libreria standard.
L’idea di Go è nata all’interno di Google con Robert Griesemer, Rob Pike e Ken Thompson. Volevano un linguaggio che si compilasse quasi alla stessa velocità del C, ma che fosse anche simile in usabilità a Python e scalabile a basi di codice di grandi dimensioni e server multithread. Go 1.0 è stato rilasciato nel 2012 con una promessa pubblica: il codice scritto per la prima versione avrebbe continuato a essere sviluppato nelle versioni successive.
La compatibilità è stata effettivamente mantenuta nel corso degli anni, il che distingue significativamente Go da molti concorrenti e riduce i costi di supporto per progetti di lunga durata.
Negli ultimi 16 anni, Go è diventato più di un semplice linguaggio, ma uno standard de facto per le infrastrutture cloud. È alla base di Docker, Kubernetes, Terraform e Prometheus, gli strumenti che alimentano la stragrande maggioranza delle moderne piattaforme cloud e container. Tra il 2015 e il 2018 circa, Go si è affermato come la scelta principale per i microservizi e gli strumenti per container e, entro il 2024, è diventato uno dei linguaggi più utilizzati al mondo, in particolare nei servizi di intelligenza artificiale e nei dispositivi edge. Secondo una ricerca di JetBrains e SlashData, ci sono milioni di sviluppatori Go in tutto il mondo e, in classifiche come TIOBE e GitHub Octoverse, il linguaggio si posiziona costantemente tra i primi 10 ed è uno dei linguaggi open source in più rapida crescita e tra i client API.
Sebbene l’evoluzione del linguaggio sia proceduta senza intoppi, ci sono stati diversi punti di svolta. L’evento più significativo degli ultimi anni è stata l’introduzione dei generici in Go 1.18 nel 2022. Si è trattato del più grande aggiornamento sintattico nella storia del linguaggio, atteso con ansia dagli sviluppatori da molti anni.

Ora è possibile scrivere collection generiche e codice di utilità senza infiniti copia-incolla, mantenendo la semplicità che contraddistingue Go. Le versioni successive si sono concentrate meno sull’aspetto sorprendente e più sul perfezionamento di quanto già esistente. Go 1.22 e Go 1.23 hanno introdotto miglioramenti al compilatore e al linker, ottimizzazioni guidate dal profilo più efficaci, nuovi pacchetti iter e struct, timer e ticker rielaborati e aggiornamenti alle librerie di crittografia e networking, incluso il supporto per Encrypted Client Hello e schemi post-quantistici sperimentali in TLS.
Nel 2025, è stata rilasciata Go 1.25, che ha ulteriormente migliorato l’osservabilità e la containerizzazione: il runtime ora adatta automaticamente il numero di thread ai limiti della CPU, sono state introdotte una garbage collection sperimentale con pause più brevi e una modalità Flight Recorder per il tracciamento continuo con basso overhead, e la libreria standard ha acquisito strumenti per un test del codice simultaneo più pratico e una nuova versione di encoding/json.
Le statistiche della community mostrano che il linguaggio è entrato in una fase matura, ma rimane attraente. JetBrains classifica Go tra i linguaggi più promettenti secondo il Language Promise Index,e Stack Overflow lo classifica tra le tecnologie più “desiderate” e “rispettate”, con gli sviluppatori Go che guadagnano, in media, al di sopra della media del settore. Nel 2024, il team del linguaggio ha assistito a un cambio nella leadership tecnica: dopo l’uscita di Russ Cox, Austin Clements ha assunto il ruolo di responsabile tecnico generale e Cherry Mooy è ora responsabile del core di Go, sebbene la direzione dello sviluppo non sia cambiata. Il team continua a dare priorità alla stabilità, a modifiche accurate e a miglioramenti basati sulla telemetria e sui sondaggi degli utenti.
Nel suo sedicesimo anniversario, Go si presenta come un raro esempio di linguaggio “calmo” che non insegue l’hype, ma rafforza costantemente la sua posizione in aree in cui affidabilità, prevedibilità e facilità di manutenzione sono fondamentali. Per le aziende, questo significa la possibilità di sviluppare sistemi per anni a venire senza continue riscritture, e per gli sviluppatori, significa uno strumento chiaro e comprensibile che non enfatizza funzionalità di tendenza, ma piuttosto garantisce che la programmazione distribuita complessa rimanga un compito gestibile per i team tradizionali.
L'articolo 16 anni di Go: un linguaggio di programmazione innovativo e scalabile proviene da Red Hot Cyber.
An Introduction to DC Motor Technology

[Thinking Techie] takes us back to basics in a recent video explaining how magnets, coils, brushed DC motors, and brushless DC motors work. If this is on your “to learn” list, or you just want a refresher, you can watch the video below. It’ll be ten minutes well-spent.
The video covers the whole technology stack behind the humble DC motor in its various incarnations. Starting with basic magnetic effects, it then proceeds through 2-wire brushed DC motors and finally into 3-wire brushless DC motors (BLDC motors).
It’s worth knowing that the 3-wires in a BLDC motor are for three power phases; they are not, as in an RC servo, positive, negative, and signal leads. But, confusingly, the BLDC motors in your PC fans do have positive, negative, and signal pins. But that’s because, like an RC servo, the fans have controllers built into the case.
Thanks to [Keith Olson] for writing in about this one. If you’d like to go deeper into BLDC controller tech, check out Take A Ride Through The Development Of A Custom BLDC Motor Controller and Moteus Open Source BLDC Controller Gets Major Upgrade.
youtube.com/embed/me6034BrwN8?…
Supersized Calculator Brings the Whole Intel 4000 Gang Together

Though mobile devices and Apple Silicon have seen ARM-64 explode across the world, there’s still decent odds you’re reading this on a device with an x86 processor — the direct descendant of the world’s first civilian microprocessor, the Intel 4004. The 4004 wasn’t much good on its own, however, which is why [Klaus Scheffler] and [Lajos Kintli] have produced super-sized discrete chips of the 4001 ROM, 4002 RAM, and 4003 shift register to replicate a 1970s calculator at 10x the size and double the speed, all in time for the 4004’s 50th anniversary.
We featured this project a couple of years back, when it was just a lonely microprocessor. Adding the other MSC-4 series chips enabled the pair to faithfully reproduce the logic of a Busicom 141-PF calculator, the very first to market with Intel’s now-legendary microprocessor. Indeed, this calculator is the raison d’etre for the 4004: Busicom commissioned the whole Micro-Computer System 4-bit (MCS-4) set of chips specifically for this calculator. Only later, once they realized what they had made, did Intel buy the rights back from the Japanese calculator company, and the rest, as they say, is history.
Since its history, it belongs in a museum– and that’s where this giant, FET-based calculator is going. If you happen to be in Solothurn, Switzerland, you’ll be able to see it at a new history of technology exhibit opening at the Enter Museum in 2026. Do check out the write-up and links at 4004.com if you want to learn about this important piece of human history.

Hackaday Links: November 16, 2025

We make no claims to be an expert on anything, but we do know that rule number one of working with big, expensive, mission-critical equipment is: Don’t break the big, expensive, mission-critical equipment. Unfortunately, though, that’s just what happened to the Deep Space Network’s 70-meter dish antenna at Goldstone, California. NASA announced the outage this week, but the accident that damaged the dish occurred much earlier, in mid-September. DSS-14, as the antenna is known, is a vital part of the Deep Space Network, which uses huge antennas at three sites (Goldstone, Madrid, and Canberra) to stay in touch with satellites and probes from the Moon to the edge of the solar system. The three sites are located roughly 120 degrees apart on the globe, which gives the network full coverage of the sky regardless of the local time.
Losing the “Mars Antenna,” as DSS-14 is informally known, is a blow to the DSN, a network that was already stretched to the limit of its capabilities, and is likely to be further challenged as the race back to the Moon heats up. As for the cause of the accident, NASA explains that the antenna was “over-rotated, causing stress on the cabling and piping in the center of the structure.” It’s not clear which axis was over-rotated, but based on some specs we found that say the azimuth travel range is ±265 degrees “from wrap center,” we suspect it was the vertical axis in the base. It sounds like the azimuth went past that limit, which wrapped the swags of cables and hoses that run the antenna tightly, causing the damage. We’d have thought there would be a physical stop of some sort to prevent over-rotation, but then again, running a structure that big up against a stop would be very much an “irresistible force, immovable object” scenario. Here’s hoping they can get DSS-14 patched up quickly and back in service.
Speaking of having a bad day on the job, we have to take pity on these Russian engineers for the “demo hell” they went through while revealing the country’s first AI-powered humanoid robot. AIdol, as the bot is known, seemed to struggle from the start, doddering from behind some curtains like a nursing home patient with a couple of nervous-looking fellows flanking it. The bot paused briefly before continuing its drunk-walk, pausing again to deliver a somewhat feeble wave to the crowd before entering the terminal stumble and face-plant part of the demo. The bot’s attendants quickly dragged it away, leaving a pile of parts on the stage while more helpers tried — and failed — to deploy a curtain to hide the scene. It was a pretty sad scene to behold, made worse by the choice of walk-out music (Bill Conti’s iconic “Gonna Fly Now,” better known as the theme from Rocky).
youtube.com/embed/LyfCLRkXKYs?…
We just noticed that pretty much everything we have to write about this week has a “bad day at work” vibe to it, so to continue on with that theme, witness this absolutely disgusting restoration of a GPU that spent way too many years in a smoker’s house. The card, an Asus 9800GT Matrix, is from 2008, so it may have spent the last 17 years getting caked with tar and nicotine, along with a fair amount of dust and perhaps cat hair, from the look of it. Having spent way too much time cleaning TVs similarly caked with grossness most foul, we couldn’t stomach watching the video of the restoration process, but it’s available in the article if you dare.
And the final entry in our “So you think your job sucks?” roundup, behold the poor saps who have to generate training data for AI-powered domestic robots. The story details the travails of Naveen Kumar, who spends his workday on simple chores such as folding towels, with the twist of doing it with a GoPro strapped to his forehead to capture all the action. The videos are then sent to a U.S. client, who uses them to develop a training model so that humanoid robots can eventually copy the surprisingly complex physical movements needed to perform such a mundane task. Training a robot is all well and good, but how about training them how to move around inside a house made for humans? That’s where it gets really creepy, as an AI startup has partnered with a big real estate company to share video footage captured from those “walk-through” videos real estate agents are so fond of. So if your house has recently been on the market, there’s a non-zero chance that it’s being used to train an army of domestic robots.
And finally, we guess this one fits the rough-day-at-work theme, but only if your job is being a European astronaut, who may someday be chowing down on protein powder made from their own urine. The product is known as Solein — sorry, but have they never seen the movie Soylent Green? — and is made via a gas fermentation process using microbes, electricity, and air. The Earth-based process uses ammonia as a nitrogen source, but in orbit or on long-duration deep-space missions, urea harvested from astronaut pee would be used instead. There’s no word on what Solein tastes like, but from the look of it, and considering the source, we’d be a bit reluctant to dig in.
The Simplest Ultrasound Sensor Module, Minus the Module

Just about every “getting started with microcontrollers” kit, Arduino or otherwise, includes an ultrasonic distance sensor module. Given the power of microcontrollers these days, it was only a matter of time before someone asked: “Could I do better without the module?” Well, [Martin Pittermann] asked, and his answer, at least with the Pi Pico, is a resounding “Yes”. A micro and a couple of transducers can offer a better view of the world.
The project isn’t really about removing the extra circuitry on the SR-HC0, since there really isn’t that much to start. [Martin] wanted to know just how far he could push ultrasound scanning technology using RADAR signal processing techniques. Instead of bat-like chirps, [Martin] is using something called Frequency-Modulated Continuous Wave, which comes from RADAR and is exactly what it sounds like. The transmitter emits a continuous carrier wave with a varying frequency modulation, and the received wave is compared to see when it must have been sent. That gives you the time of flight, and the usual math gives you a distance.
Since he’s inspired by RADAR, it’s no surprise perhaps that [Martin]’s project reminds us of SDR, and the write-up gets right into the signal-processing code. Does it work better than a chirping module? Well, aside from using fewer parts, [Martin] can generate a full range plot for all objects in the arc of the sensor’s emissions out to 4 meters using just the Pico. [Martin] points out that it wouldn’t take much amplification to get a greater range. He’s not finished yet, though — the real goal here is to measure wind speed, which means he’s going to have to go full Doppler. We look forward to it.
This isn’t the first time we’ve seen the Pico doing fun stuff at these frequencies, and Doppler RADAR is a thing hackers do, so why not ultrasound?