 - Collegamento all'originale")
Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio
Negli ultimi anni i modelli di linguaggio di grandi dimensioni (LLM, Large Language Models) come GPT, Claude o LLaMA hanno dimostrato capacità straordinarie nella comprensione e generazione del linguaggio naturale. Tuttavia, dietro le quinte, far funzionare un LLM non è un gioco da ragazzi: richiede una notevole infrastruttura computazionale, un investimento economico consistente e scelte architetturali precise. Cerchiamo di capire perché.
70 miliardi di parametri: cosa significa davvero
Un LLM da 70 miliardi di parametri, come LLaMA 3.3 70B di Meta, contiene al suo interno 70 miliardi di “pesi”, ovvero numeri in virgola mobile (di solito in FP16 o BF16, cioè 2 byte per parametro) che rappresentano le abilità apprese durante l’addestramento. Solo per caricare in memoria questo modello, servono circa:
- 140 GB di RAM GPU (70 miliardi × 2 byte).
A questa cifra vanno aggiunti altri 20-30 GB di VRAM per gestire le operazioni dinamiche durante l’inferenza: cache dei token (KV cache), embedding dei prompt, attivazioni temporanee e overhead di sistema. In totale, un LLM da 70 miliardi di parametri richiede circa 160-180 GB di memoria GPU per funzionare in modo efficiente.
Perché serve la GPU: la CPU non basta
Molti si chiedono: “Perché non far girare il modello su CPU?”. La risposta è semplice: latenza e parallelismo.
Le GPU (Graphics Processing Unit) sono progettate per eseguire milioni di operazioni in parallelo, rendendole ideali per il calcolo tensoriale richiesto dagli LLM. Le CPU, invece, sono ottimizzate per un numero limitato di operazioni sequenziali ad alta complessità. Un modello come LLaMA 3.3 70B può generare una parola ogni 5-10 secondi su CPU, mentre su GPU dedicate può rispondere in meno di un secondo. In un contesto produttivo, questa differenza è inaccettabile.
Inoltre, la VRAM delle GPU di fascia alta (es. NVIDIA A100, H100) consente di mantenere il modello residente in memoria e di sfruttare l’accelerazione hardware per la moltiplicazione di matrici, cuore dell’inferenza LLM.
Un esempio: 100 utenti attivi su un LLM da 70B
Immaginiamo di voler offrire un servizio simile a ChatGPT per la sola generazione di testo, basato su un modello LLM da 70 miliardi di parametri, con 100 utenti attivi contemporaneamente. Supponiamo che ogni utente invii prompt da 300–500 token e si aspetti risposte rapide, con una latenza inferiore a un secondo.
Un modello di queste dimensioni richiede circa 140 GB di memoria GPU per i soli pesi in FP16, a cui vanno aggiunti altri 20–40 GB per la cache dei token (KV cache), attivazioni temporanee e overhead di sistema. Una singola GPU, anche top di gamma, non dispone di sufficiente memoria per eseguire il modello completo, quindi è necessario distribuirlo su più GPU tramite tecniche di tensor parallelism.
Una configurazione tipica prevede la distribuzione del modello su un cluster di 8 GPU A100 da 80 GB, sufficiente sia per caricare il modello in FP16 sia per gestire la memoria necessaria all’inferenza in tempo reale. Tuttavia, per servire contemporaneamente 100 utenti mantenendo una latenza inferiore al secondo per un LLM di queste dimensioni, una singola istanza su 8 GPU A100 (80GB) è generalmente insufficiente.
Per raggiungere l’obiettivo di 100 utenti simultanei con latenza sub-secondo, sarebbe necessaria una combinazione di:
- Un numero significativamente maggiore di GPU A100 (ad esempio, un cluster con 16-32 o più A100 da 80GB), distribuite su più POD o in un’unica configurazione più grande.
- L’adozione di GPU di nuova generazione come le NVIDIA H100, che offrono un netto miglioramento in termini di throughput e latenza per l’inferenza di LLM, però ad un costo maggiore.
- Massimizzare le ottimizzazioni software, come l’uso di framework di inferenza avanzati (es. vLLM, NVIDIA TensorRT-LLM) con tecniche come paged attention e dynamic batching.
- L’implementazione della quantizzazione (passando da FP16 a FP8 o INT8/INT4), che ridurrebbe drasticamente i requisiti di memoria e aumenterebbe la velocità di calcolo, ma con una possibile conseguente perdita di qualità dell’output generato (soprattutto per la quantizzazione INT4).
Per scalare ulteriormente, è possibile replicare queste istanze su più GPU POD, abilitando la gestione di migliaia di utenti totali in modo asincrono e bilanciato, in base al traffico in ingresso. Naturalmente, oltre alla pura inferenza, è fondamentale prevedere risorse aggiuntive per:
- Scalabilità dinamica in funzione della domanda.
- Bilanciamento del carico tra istanze.
- Logging, monitoraggio, orchestrazione e sicurezza dei dati.
Ma quanto costa un’infrastruttura di questo tipo?
L’implementazione on-premise richiede centinaia di migliaia di euro di investimento iniziale, cui si aggiungono i costi annuali di gestione, alimentazione e personale. In alternativa, i principali provider cloud offrono risorse equivalenti ad un costo mensile molto più accessibile e flessibile. Tuttavia, è importante sottolineare che anche in cloud, una configurazione hardware capace di gestire un tale carico in tempo reale può comportare costi mensili che facilmente superano le decine di migliaia di euro, se non di più, a seconda dell’utilizzo.
In entrambi i casi, emerge con chiarezza come l’impiego di LLM di grandi dimensioni rappresenti non solo una sfida algoritmica, ma anche infrastrutturale ed economica, rendendo sempre più rilevante la ricerca di modelli più efficienti e leggeri.
On-premise o API? La riservatezza cambia le carte in tavola
Un’alternativa semplice per molte aziende è usare le API di provider esterni come OpenAI, Anthropic o Google. Tuttavia, quando entrano in gioco la riservatezza e la criticità dei dati, l’approccio cambia radicalmente. Se i dati da elaborare includono informazioni sensibili o personali (ad esempio cartelle cliniche, piani industriali o atti giudiziari), inviarli a servizi cloud esterni può entrare in conflitto con i requisiti del GDPR, in particolare rispetto al trasferimento transfrontaliero dei dati e al principio di minimizzazione.
Anche molte policy aziendali basate su standard di sicurezza come ISO/IEC 27001 prevedono il trattamento di dati critici in ambienti controllati, auditabili e localizzati.
Inoltre, con l’entrata in vigore del Regolamento Europeo sull’Intelligenza Artificiale (AI Act), i fornitori e gli utilizzatori di sistemi di AI devono garantire tracciabilità, trasparenza, sicurezza e supervisione umana, soprattutto se il modello è impiegato in contesti ad alto rischio (finanza, sanità, istruzione, giustizia). L’uso di LLM attraverso API cloud può rendere impossibile rispettare tali obblighi, in quanto l’inferenza e la gestione dei dati avvengono fuori dal controllo diretto dell’organizzazione.
In questi casi, l’unica opzione realmente compatibile con gli standard normativi e di sicurezza è adottare un’infrastruttura on-premise o un cloud privato dedicato, dove:
- Il controllo sui dati è totale;
- L’inferenza avviene in un ambiente chiuso e conforme;
- Le metriche di auditing, logging e accountability sono gestite internamente.
Questo approccio consente di preservare la sovranità digitale e la conformità a GDPR, ISO 27001 e AI Act, pur richiedendo un effort tecnico ed economico significativo.
Conclusioni: tra potenza e controllo
Mettere in servizio un LLM non è solo una sfida algoritmica, ma soprattutto un’impresa infrastrutturale, fatta di hardware specializzato, ottimizzazioni complesse, costi energetici elevati e vincoli di latenza. I modelli di punta richiedono cluster da decine di GPU, con investimenti che vanno da centinaia di migliaia fino a milioni di euro l’anno per garantire un servizio scalabile, veloce e affidabile.
Un’ultima, ma fondamentale considerazione riguarda l’impatto ambientale di questi sistemi. I grandi modelli consumano enormi quantità di energia elettrica, sia in fase di addestramento che di inferenza. Con l’aumentare dell’adozione di LLM, diventa urgente sviluppare modelli più piccoli, più leggeri e più efficienti, che riescano a offrire prestazioni comparabili a fronte di un footprint computazionale (ed energetico) significativamente ridotto.
Come è accaduto in ogni evoluzione tecnologica — dal personal computer ai telefoni cellulari — l’efficienza è la chiave della maturità: non servono sempre modelli più grandi, ma modelli più intelligenti, più adattivi e sostenibili.
L'articolo Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio proviene da il blog della sicurezza informatica.
GR Valle d'Aosta del 18/07/2025 ore 07:20
GR Regionale Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 18/07/2025 - 07:20

Coltivare la mente come difesa nella Cybersecurity: Il cervello sarà la prossima fortezza digitale?
Immagina per un attimo di trovarti di fronte al pannello di controllo più critico di una infrastruttura IT.
Non un server, non un firewall di ultima generazione, non un sistema AI avanzatissimo.
Immaginiamo che quel pannello sia la tua mente. È da lì che provengono le decisioni più importanti, le reazioni più rapide, le analisi più profonde.
Ed è lì che, troppo spesso, risiedono la vulnerabilità più inaspettate.
Sono qui, tra voi, da più di venti anni.
Ho visto incidenti, ho celebrato successi e ho sentito la pressione che ogni professionista della cybersecurity conosce bene. Ma la mia prospettiva è sempre stata unica, ho sempre portato con me gli strumenti di uno psicologo, di un counselor e di un coach. E ciò che ho imparato, osservando le violazioni informatiche e le persone, è che la vera frontiera della sicurezza non è solo tecnologica.
È profondamente, intrinsecamente, umana.
Il firewall più potente quale sarà?
Pensiamoci bene. Investiamo somme enormi in sistemi avanzatissimi, in intelligenza artificiale, in difese perimetrali quasi inespugnabili. Eppure, una semplice email di phishing, un messaggio subdolo, un invito a cliccare su un link… e tutto può crollare.
Perché accade questo? Perché gli attaccanti, i veri maestri, non puntano ai nostri server; puntano al nostro circuito neurale.
L’ingegneria sociale non è più un semplice trucco; è diventata neuro-ingegneria sociale. I cybercriminali sono diventati esperti nel capire come funziona il nostro cervello: sanno attivare le nostre risposte emotive più primitive, bypassare il nostro ragionamento logico, sfruttare i nostri bias cognitivi. La nostra curiosità, la fretta, la tendenza a fidarci, la paura di perdere un’opportunità sono tutte “vulnerabilità” nel nostro hardware biologico. Il nostro cervello, pur essendo la macchina più potente che conosciamo, è anche quella più facilmente “hackerabile” se non lo comprendiamo e non lo alleniamo adeguatamente.
La chimica dello stress cosa genera?
E non è solo l’utente finale ad essere vulnerabile. Lo siamo anche noi, i professionisti della sicurezza! Noi che lavoriamo sotto la costante minaccia di un attacco, con la responsabilità enorme di proteggere dati e infrastrutture critiche. Quante volte abbiamo sentito quella scarica di adrenalina, quella mente che si annebbia quando un alert suona nel cuore della notte o nel fine settimana..
Cortisolo e adrenalina inondano il nostro sistema.
Sono un’ottima risposta se stiamo scappando da una tigre, ma devastante per la lucidità e la capacità decisionale necessarie per gestire un incidente cyber complesso. La stanchezza decisionale, il burnout cognitivo non sono solo etichette.
Sono la manifestazione di processi neurologici che minano direttamente la nostra performance.
Un analista sotto stress cronico non è semplicemente “stanco”; il suo cervello opera in una modalità di sopravvivenza che limita l’accesso alle funzioni esecutive superiori, quelle cruciali per il problem solving e la strategia.
È come se il nostro sistema difensivo più critico fosse costantemente sotto attacco interno.
Quale potrebbe essere un piano di azione futuro?
Allora, la domanda da un milione di dollari, quella che mi pongo ogni giorno è: se il cervello è la nostra risorsa più potente e la nostra vulnerabilità più grande, come possiamo trasformarlo nella nostra prossima e più potente risorsa cyber?
Non si tratta di fantascienza, ma di un piano d’azione concreto basato sulle neuroscienze e sulla psicologia umana:
- Oltre la semplice consapevolezza
- Azione: dobbiamo implementare programmi di formazione che vadano oltre il “cosa fare”. Iniziamo a insegnare il “perché” le persone cadono nelle truffe, analizzando i meccanismi psicologici e neurologici dietro l’ingegneria sociale.
- Focus: utilizziamo simulazioni avanzate, non solo tecniche, ma comportamentali. Pensiamo a esercizi che creino “memoria muscolare” nel cervello per le risposte di sicurezza, usando tecniche di ripetizione e rinforzo cognitivo. Come un atleta allena il suo corpo, noi dobbiamo allenare la nostra mente.
- Ottimizzare l’ambiente mentale
- Azione: dobbiamo ripensare gli ambienti di lavoro e i flussi operativi per ridurre il carico cognitivo e promuovere la lucidità mentale. Ciò include la gestione intelligente dei turni, pause strategiche per il recupero mentale e la progettazione di interfacce utente che minimizzino la fatica decisionale.
- Focus: integriamo pratiche di mindfulness o brevi esercizi di “respirazione consapevole” per aiutare i team a gestire lo stress in tempo reale e a resettare i livelli di cortisolo. Un cervello calmo è un cervello che prende decisioni migliori.
- Comprendere la mente dell’avversario
- Azione: utilizziamo le conoscenze delle neuroscienze e della psicologia criminale per comprendere non solo cosa fanno gli attaccanti, ma come pensano, quali motivazioni profonde li guidano e quali bias psicologici cercano di sfruttare nelle loro vittime.
- Focus: sviluppiamo modelli predittivi che incorporino profili psicologici e comportamentali degli attaccanti, anticipando le loro mosse non solo a livello tecnico, ma anche a livello umano e mentale.
In conclusione?
La cybersecurity è sempre stata una battaglia di intelligenze: macchina contro macchina, algoritmo contro algoritmo. Ma la vera sfida, la prossima grande evoluzione, è integrare profondamente la comprensione della nostra stessa biologia cognitiva nella nostra strategia difensiva.
Non proteggiamo solo dati, proteggiamo le menti che quei dati li gestiscono e li difendono.
Per proteggerci veramente, per costruire difese resilienti e a prova di futuro, non bastano le tecnologie più avanzate o i protocolli più stringenti.
È fondamentale che i nostri team di cybersecurity siano multidisciplinari. Dobbiamo superare la convinzione che basti essere esperti di codice o di rete. Abbiamo bisogno di umanisti, sociologi, psicologi, esperti di comunicazione che lavorino fianco a fianco con gli ingegneri e gli analisti. Sono loro che possono aiutarci a capire il “fattore umano” nelle sue sfumature più profonde, a progettare difese che tengano conto dei comportamenti e delle emozioni, a formare le persone non solo sulle regole, ma sulle ragioni intrinseche della sicurezza.
La cyber-resilienza non è un muro inespugnabile, ma una danza costante tra la logica del codice e l’imprevedibilità dell’anima umana. È un’arte sottile, un caos ordinato dove l’innovazione tecnologica incontra la profonda conoscenza di sé. Non possiamo più permetterci di essere i ciechi veggenti della sicurezza, che vedono ogni bit e byte ma non il battito cardiaco che li muove.
Se la nostra difesa più critica risiede nella mente, siamo davvero pronti a investire in essa come nell’ultima soluzione tecnologica?
Siamo pronti a ridefinire il concetto stesso di “sicurezza informatica” per includere l’elemento più cruciale: l’essere umano?
E, soprattutto, cosa siamo disposti a cambiare nel nostro approccio da domani per iniziare a costruire questa fortezza ?
L'articolo Coltivare la mente come difesa nella Cybersecurity: Il cervello sarà la prossima fortezza digitale? proviene da il blog della sicurezza informatica.

3 bug da score 10 sono stati rilevati in Cisco ISE e ISE-PIC: aggiornamenti urgenti
Sono state identificate diverse vulnerabilità nei prodotti Cisco Identity Services Engine (ISE) e Cisco ISE Passive Identity Connector (ISE-PIC) che potrebbero consentire a un utente malintenzionato remoto di eseguire comandi arbitrari sul sistema operativo sottostante con privilegi di amministratore.
Cisco ha già rilasciato aggiornamenti software per correggere queste vulnerabilità e, al momento, non risultano disponibili soluzioni alternative per mitigarle. Un attaccante remoto potrebbe sfruttare tali vulnerabilità per ottenere accesso con privilegi di root ed eseguire comandi sul sistema.
Le vulnerabilità sono indipendenti tra loro: ciò significa che lo sfruttamento di una non è condizione necessaria per sfruttare le altre. Inoltre, una determinata versione software vulnerabile a una di queste problematiche potrebbe non essere interessata dalle restanti.
CVE-2025-20281 e CVE-2025-20337: vulnerabilità di esecuzione di codice remoto non autenticato dell’API Cisco ISE
Diverse vulnerabilità in una specifica API di Cisco ISE e Cisco ISE-PIC potrebbero consentire a un aggressore remoto non autenticato di eseguire codice arbitrario sul sistema operativo sottostante come utente root . L’aggressore non necessita di credenziali valide per sfruttare queste vulnerabilità.
Queste vulnerabilità sono dovute a una convalida insufficiente dell’input fornito dall’utente. Un aggressore potrebbe sfruttarle inviando una richiesta API contraffatta. Un exploit riuscito potrebbe consentire all’aggressore di ottenere privilegi di root su un dispositivo interessato.
CVE-2025-20282: Vulnerabilità di esecuzione di codice remoto non autenticato nell’API Cisco ISE
Una vulnerabilità in un’API interna di Cisco ISE e Cisco ISE-PIC potrebbe consentire a un aggressore remoto non autenticato di caricare file arbitrari su un dispositivo interessato e quindi eseguire tali file sul sistema operativo sottostante come root .
Questa vulnerabilità è dovuta alla mancanza di controlli di convalida dei file che impedirebbero il posizionamento dei file caricati in directory privilegiate su un sistema interessato. Un aggressore potrebbe sfruttare questa vulnerabilità caricando un file contraffatto sul dispositivo interessato. Un exploit riuscito potrebbe consentire all’aggressore di memorizzare file dannosi sul sistema interessato e quindi eseguire codice arbitrario o ottenere privilegi di root sul sistema.
L'articolo 3 bug da score 10 sono stati rilevati in Cisco ISE e ISE-PIC: aggiornamenti urgenti proviene da il blog della sicurezza informatica.

Sophos risolve vulnerabilità in Intercept X per Windows
Sophos ha annunciato di aver risolto tre distinte vulnerabilità di sicurezza in Sophos Intercept X per Windows e nel relativo programma di installazione. Queste problematiche, identificate con i codici CVE-2024-13972, CVE-2025-7433 e CVE-2025-7472, sono state classificate con un livello di gravità “Alto”. Il bollettino di sicurezza, con ID pubblicazione sophos-sa-20250717-cix-lpe, è stato aggiornato e pubblicato il 17 luglio 2025 e non prevede soluzioni alternative temporanee. I prodotti interessati sono Sophos Intercept X Endpoint e Intercept X per il server.
La prima vulnerabilità, CVE-2024-13972, riguarda un problema di permessi nel registro durante l’aggiornamento di Intercept X per Windows. Questa falla avrebbe potuto consentire a un utente locale di ottenere privilegi a livello di sistema durante il processo di aggiornamento del prodotto. Sophos ha ringraziato Filip Dragovic di MDSec per aver segnalato responsabilmente questa vulnerabilità.
La seconda criticità, CVE-2025-7433, è una vulnerabilità di escalation dei privilegi locali nel componente Device Encryption di Sophos Intercept X per Windows. Questa falla avrebbe potuto permettere l’esecuzione di codice arbitrario. Sophos ha espresso gratitudine a Sina Kheirkhah (@SinSinology) di watchTowr per la sua segnalazione responsabile.
Infine, la CVE-2025-7472 è una vulnerabilità di escalation dei privilegi locali scoperta nel programma di installazione di Intercept X per Windows. Se il programma di installazione fosse stato eseguito con privilegi di sistema (SYSTEM), un utente locale avrebbe potuto ottenere privilegi a livello di sistema.
Questa vulnerabilità è stata scoperta e segnalata a Sophos tramite il suo programma bug bounty, con un ringraziamento particolare a Sandro Poppi per la sua segnalazione responsabile. Per i clienti che utilizzano versioni precedenti del programma di installazione per distribuire attivamente endpoint e server, è fondamentale scaricare la versione più recente del programma di installazione da Sophos Central.
Per la maggior parte dei clienti, non è richiesta alcuna azione manuale. Ciò è dovuto al fatto che, per impostazione predefinita, i clienti che utilizzano la politica di aggiornamento predefinita ricevono automaticamente gli aggiornamenti per i pacchetti raccomandati. Questo assicura che le correzioni per queste vulnerabilità vengano installate senza intervento dell’utente.
Tuttavia, i clienti che utilizzano pacchetti di Supporto a Termine Fisso (FTS) o Supporto a Lungo Termine (LTS) devono intraprendere un’azione per ricevere queste correzioni. È necessario che questi utenti eseguano un aggiornamento per assicurarsi che le patch di sicurezza siano applicate ai loro sistemi.
L'articolo Sophos risolve vulnerabilità in Intercept X per Windows proviene da il blog della sicurezza informatica.
Improve Your KiCad Productivity With These Considered Shortcut Keys

Over on his YouTube channel [Pat Deegan] from Psychogenic Technologies shows us two KiCad tips to save a million clicks.
In the same way that it makes sense for you to learn to touch type if you’re going to be using a computer a lot, it makes sense for you to put some thought and effort into your KiCad keyboard shortcuts keys, too.
In this video [Pat] introduces the keymap that he has come up with for the KiCad programs (schematic capture and PCB layout) and explains the rules of thumb that he used to generate his recommended shortcut keys, being:
- one handed operation; you should try to make sure that you can operate the keyboard with one hand so your other hand can stay on your mouse
- proximity follows frequency; if you use it a lot it should be close to hand
- same purpose, same place; across programs similar functions should share the same key
- birds of a feather flock together; similar and related functionality kept in proximate clusters
- typing trounces topography; if you have to use both hands for typing you have to take your hand off the mouse anyway so then it doesn’t really matter where on the keyboard the shortcut key is
You can find importable KiCad keymaps and customizable SVG cheatsheets in the downloads section of his notes.
[Pat]’s video includes some other tips and commentary (he gives you free access to a KiCad course he has put together) but for us the big takeaway was the keymaps. Also, if you haven’t been keeping abreast of developments, KiCad is now at version 9, as of February this year.
youtube.com/embed/T-voZId8eyw?…
8-Core ARM Pocket Computer Runs NixOS

What has 8 ARM cores, 8 GB of RAM, fits in a pocket, and runs NixOS? It’s no pi-clone SBC, but [MWLabs]’s smartphone– a OnePlus 6, to be precise.
The video embedded below, and the git link above, are [MWLabs]’s walk-through for loading the mobile version of Nix onto the cell phone, turning it into a tiny-screened Linux computer. He’s using the same flake on the phone as on his desktop, which means he gets all the same applications set up in the same way– talk about convergence. That’s an advantage to Nix in this application, compared to the usual Alpine-based PostMarketOS.
Of course some of the phone-like features of this pocket-computer are lacking: the SIM is detected, and he can text, but 4G is nonfunctional. The rear camera is also not there yet, but given that Mobile-NixOS builds on the work done by well-established PostMarketOS, and PostMarketOS’ testing version can run the camera, it’s only a matter of time before support comes downstream. Depending what you need a tiny Linux device for, the camera functionality may or may not be of particular interest. If you’re like us, the idea of a mobile device running Nix might just intrigue you,
Smartphones can be powerful SBC alternatives, after all. You can even turn them into SBCs. As long as you don’t need a lot of GPIO, like for a server,a phone in hand might be worth two birds in the raspberry bush.
youtube.com/embed/yxfDNqZ9WTM?…
ESP32 Plugs In to Real-Time Crypto Prices

In today’s high-speed information overload environment, we often find ourselves with too much data to take in at once, causing us to occasionally miss out on opportunities otherwise drowned out in noise. None of this is more evident in the realm of high-speed trading, whether it’s for stocks, commodities, or even crypto. Most of us won’t be able to build dedicated high speed connections directly to stock exchanges for that extra bit of edge over the other traders, but what we can do is build a system that keys us in to our cryptocurrency price of choice so we know exactly when to pull the trigger on a purchase or sale.
[rishab]’s project for doing this is based on an ESP32 paired with a 10″ touchscreen display. It gathers live data from Binance, a large cryptocurrency exchange that maintains various pieces of information about many digital currencies. [rishab]’s tool offers a quick, in-depth look at a custom array of coins, with data such as percentage change over a certain time and high and low values for that coin as well. The chart updates in real time, and [rishab] also built a feature in which scales coins up if they have been seeing large movements in price over short timeframes.
Although it’s not a direct fiber link into an exchange, it certainly has its advantages over keeping this information in a browser window on a computer where it could get missed, and since it’s dedicated hardware running custom firmware it can show you exactly what you need to see if you’re day trading crypto. Certainly projects like this are in the DIY spirit that crypto enthusiasts tout as ideals of the currency, and as people move away from mining and more into speculative trading we’d expect to see more projects like this.
youtube.com/embed/U1MZoj3MJso?…

Building a Stirling Engine Bike

Over on his YouTube channel [Tom Stanton] shows us how to build a Stirling Engine for a bike.
A Stirling Engine is a heat engine, powered by the expansion and contraction of a working fluid (such as air) which is heated and cooled in a cycle. In the video [Tom] begins by demonstrating the Stirling Engine with some model engines and explains the role of the displacer piston. His target power output for his bike engine is 150 watts (about 0.2 horsepower) which is enough power to cycle at about 15 mph (about 24 km/h). After considering a CPU heatsink as the cooling system he decided on water cooling instead.
[Tom] goes on to 3D print and machine various parts for his bike engine. He uses myriad materials including aluminum and Teflon. He isn’t yet comfortable machining steel, so he had the steel part he needed for handling the hot end of the engine manufactured by a third party.
[Tom] explains that when he started the project he had intended to make a steam engine. But after some preliminary research he discovered that a Stirling Engine was a better choice, particularly they are quieter, more efficient, and safer. After a number of false starts and various adjustments he manages to get his engine to run, which is pretty awesome. Standby for part two to see the bike in action!
We have covered the Stirling Engine here on Hackaday many times before. You might like to read about how to create one with minimal parts or how to make one from expedient materials.
youtube.com/embed/zB3lrLjqIh4?…
FPF, Demand Progress file ethics complaint against Judge Edward Artau
On Thursday, Demand Progress and Freedom of the Press Foundation (FPF) filed an ethics complaint against Edward L. Artau, a Florida judge who was nominated by President Donald Trump to a federal district court after delivering a favorable ruling for Trump in his defamation lawsuit against the Pulitzer Board. The ethics complaint asks the D.C. Court of Appeals and the Florida Judicial Qualifications Commission to investigate Artau for potentially breaking rules requiring judges to recuse themselves to avoid conflicts of interest, remain impartial, avoid impropriety, and avoid giving false statements.
Politico reported that Artau, who sought for Trump to nominate him shortly after the president won the 2024 presidential election, later ruled in Trump’s favor as part of a panel of state appellate judges deciding whether to allow the president’s lawsuit against the Pulitzer Prize Board to move forward. After joining a favorable panel ruling for Trump, and after going out of his way to write a gratuitous solo concurrence praising the lawsuit’s claims on the merits, Artau was nominated to be a judge on South Florida’s U.S. trial court. Artau later gave an incomplete and misleading testimony about these events to the Senate Judiciary Committee while under oath.
“A federal judge’s goal should be upholding the law and the American people’s confidence in the judiciary, not delivering whatever the president wants so that they can get a job,” said Emily Peterson-Cassin, director of corporate power at Demand Progress. “Judge Ed Artau’s behind-closed-doors jockeying for his nomination, his failure to recuse himself from the Pulitzer lawsuit and his misleading testimony to the Senate all raise bright red flags that need to be investigated.”
Seth Stern, director of advocacy at Freedom of the Press Foundation, said: “Judges should be safeguarding us against President Trump’s frivolous attacks on the free press, the First Amendment and the rule of law. Instead, Judge Artau seems eager to facilitate Trump’s unconstitutional antics in exchange for a job. That’s far from the level of integrity that the Rules of Professional Conduct demand. Attorney disciplinary commissions need to rise to this moment and not tolerate ethical violations that impact not only individuals before the court but our entire democracy.”
Read the Complaint here or below.
freedom.press/static/pdf.js/we…
Next board meeting will take place on 05.08.2025 at 14:00 UTC
Our next PPI board meeting will take place on 05.08.2025 at 14:00 UTC / 16:00 CEST.
All official PPI proceedings, Board meetings included, are open to the public. Feel free to stop by. We’ll be happy to have you.
Where:jitsi.pirati.cz/PPI-Board
The prior meeting was unfortunately delayed.
Prior to that meeting a SCENE meeting is scheduled on July 22 at 7 pm/ UTC 9 pm CEST.
All of our meetings are posted to our calendar: pp-international.net/calendar/
We look forward to seeing visitors.
Thank you for your support,
The Board of PPI



TGR Valle d'Aosta del 17/07/2025 ore 19:30
TGR Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 17/07/2025 - 19:30

Meteo Valle d'Aosta del 17/07/2025 ore 19:30
Meteo Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 17/07/2025 - 19:30


2025 One Hertz Challenge: Building a Better Jumping Bean

Do you feel nostalgia for a childhood novelty toy that had potential but ultimately fell short of its promise? Do you now have the skills to go make a better version of that toy to satisfy your long-held craving? [ExpensivePlasticCrap] does and has set off on a mission to make a better jumping bean.
Jumping beans, the phenomenon on which the novelty of [ExpensivePlasticCrap]’s childhood is based, are technically not beans, and their movement is arguably not a jump — a small hop at best. The trick is that the each not-a-bean has become the home to moth larvae that twitches and rolls on the ground as the larvae thrash about, trying to move their protective shells out of the hot sun.
The novelty bean was a small plastic pill-like capsule with a ball bearing inside what would cause the “bean” to move in unexpected ways as it rolled around. [ExpensivePlasticCrap]’s goal is to make a jumping bean that lives up to its name.
Various solenoids and motors were considered for the motion component of this new and improved bean. Ultimately, it was a small sealed vibrating motor that would be selected to move the bean without getting tangled in what was to become a compact bundle of components.
An ATtiny microcontroller won out over discrete components for the job of switching the motor on and off (once per second), for ease of implementation. Add this along with a MOSFET, battery and charging board for power into a plastic capsule, and the 1 Hz jumping bean was complete.
[ExpensivePlasticCrap] offers some thoughts on how to get more jump out of the design by reducing the weight of the build and giving it a more powerful source of motion.
If insect-inspired motion gets you jumping, check out this jumping robot roach and these tiny RoboBees.

The Apollo–Soyuz Legacy Lives On, Fifty Years Later

On this date in 1975, a Soviet and an American shook hands. Even for the time period, this wouldn’t have been a big deal if it wasn’t for the fact that it happened approximately 220 kilometers (136 miles) over the surface of the Earth.
Although their spacecraft actually launched a few days earlier on the 15th, today marks 50 years since American astronauts Thomas Stafford, Vance Brand, and Donald “Deke” Slayton docked their Apollo spacecraft to a specifically modified Soyuz crewed by Cosmonauts Alexei Leonov and Valery Kubasov. The two craft were connected for nearly two days, during which time the combined crew was able to freely move between them. The conducted scientific experiments, exchanged flags, and ate shared meals together.
Politically, this very public display of goodwill between the Soviet Union and the United States helped ease geopolitical tensions. On a technical level, it not only demonstrated a number of firsts, but marked a new era of international cooperation in space. While the Space Race saw the two counties approach spaceflight as a competition, from this point on, it would largely be treated as a collaborative endeavour.
The Apollo–Soyuz Test Project lead directly to the Shuttle–Mir missions of the 1990s, which in turn was a stepping stone towards the International Space Station. Not just because that handshake back in 1975 helped establish a spirit of cooperation between the two space-fairing nations, but because it introduced a piece of equipment that’s still being used five decades later — the Androgynous Peripheral Attach System (APAS) docking system.
Meeting in the Middle
While the Apollo–Soyuz Test Project was the first time spacecraft from two different countries linked up, it was far from the first docking in space. The Apollo program relied heavily on the concept, as the Command Module and Lunar Module would dock and undock multiple times on each lunar mission. For their part, the Soviets had also docked a pair of Soyuz capsules together as early as 1967. By the early 1970s, both nations had also docked spacecraft to their respective space stations.
The problem was, the docking systems used by both countries weren’t compatible with each other. In fact, things were changing so fast that even vehicles from the same country couldn’t necessarily dock with each other. For example, an American Gemini capsule wouldn’t be able to dock with Skylab. Of course, this isn’t terribly surprising. At this point, most of the hardware was mission-specific, and only flew once.
What was the Apollo–Soyuz Test Project needed was a standardized docking interface that took into account the lessons learned by both countries so far. By 1970, Soviet and US engineers had started meeting and exchanging information to decide what such a docking standard would look like. It was decided early on that this new docking standard should be androgynous — rather than having distinct “male” and “female” variants as was the norm with earlier docking ports. In this way, the same docking port could be used to support two spacecraft docking together as was planned for the Apollo–Soyuz Test Project, while at the same time allowing a vehicle to dock to a space station.
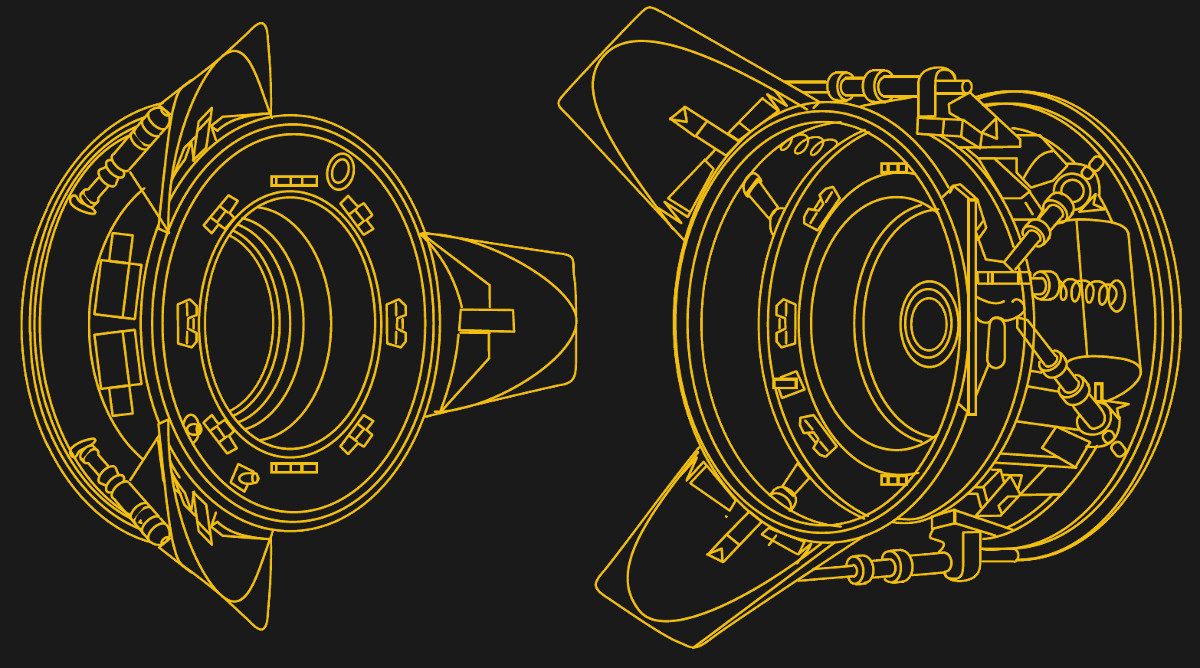
This capability was so key to the design that the docking standard ultimately came to be known as the Androgynous Peripheral Attach System. While the US and Soviet versions did differ slightly, they were mechanically compatible with each other. Some elements of the design were the result of a compromise, such as the overall diameter of the port being limited to the size of the existing Apollo and Soyuz capsules, but otherwise it was hoped the concept would prove useful for future missions and spacecraft from both nations.
Built to Last
The Apollo–Soyuz Test Project was the only time an Apollo and Soyuz spacecraft docked in space. In fact, it was the last time an Apollo spacecraft flew — after the conclusion of this mission, there wouldn’t be anther crewed American mission until the Space Shuttle came online nearly six years later.
But once the Americans started flying the Shuttle, and the Soviets had established their Mir space station, it wasn’t long before the two would meet. The Soviets had already designed a modified version of APAS that they called APAS-89, which was intended to allow the Buran spacecraft to dock with Mir. Buran never made it past the testing phase, but the work on the docking port ended up being adapted once more for the Shuttle. This final version of the standard became known as APAS-95, and was used until the final Shuttle-Mir mission in June of 1998.
APAS-95 performed so well during the Mir missions that it was decided the Shuttle would continue to use it for the International Space Station. In addition, APAS-95 (as well as a modified “hybrid” version) would also be used to hold together the core US and Russian modules of the Station.
It was the defacto docking standard used until the introduction of the International Docking Adapter in 2015, which converted the exposed APAS-95 ports used for visiting American spacecraft to a newer design to be used by modern vehicles such as the SpaceX Dragon and Boeing Starliner.
While it has now been retired for the International Docking System Standard (IDSS), the ISS is still being held together by APAS-95, and will remain that way until the space laboratory is eventually de-orbited. Not a bad legacy for a technology initially developed for a simple handshake.
ProtoWeb: Browsing the Information Superhighway Like It’s 1995

Feeling nostalgic? Weren’t around in the 90s but wonder what it was like? ProtoWeb has you covered! Over on his YouTube channel [RetroTech Chris] shows you how to browse the web like it’s 1995.
The service that [RetroTech Chris] introduces is on the web over here: protoweb.org. The way it works is that you configure your browser to use the service’s proxy server, then the service will be able to intercept your browsing activity and serve you old content from its cache. Also, for some supported sites, you will see present-day content but presented in the format you would have seen in the 90s. Once you have configured your browser to use the ProtoWeb proxy you can navigate to inode.com/ where you will find a directory listing of sites which have been archived or emulated within the service.
In his video [RetroTech Chris] actually demos some of the old web browsers running on old hardware, which is a very good recreation of what things were like. If you want the most realistic experience you can even configure ProtoWeb to slow down your network connection to the speed of a 56k dial-up modem. There are some things from the 90s that we miss, but waiting for websites to load isn’t one of them!
We had a look in our own archive to see how far back we here at Hackaday could go, and we found our first post, from September 2004: Radioshack Phone Dialer – Red Box. A red box! Spicy.
youtube.com/embed/-Qs3LVPmLgk?…
Thanks to [Teejay] for writing in about this one.
Joe Vinegar reshared this.
Mangelnde Fehlerkultur, Racial Profiling: Polizeibeauftragter legt ersten Jahresbericht vor
netzpolitik.org/2025/mangelnde…

Пираты любят мемы
Пиратская партия Германии на сайте Пиратского Интернационала обратила внимание на важную проблему: корпорации преследуют людей за создание мемов, не имеющих коммерческой цели.
Мемы, пародии и интернет-фольклор — важная часть современной культуры. Они рождаются в сетевых сообществах, переосмысливают медиа и становятся новым языком общения. Но так называемые правообладатели пытаются приватизировать даже те образы, которые давно стали частью общественного достояния.
В России, как и во всём мире, люди сталкиваются с аналогичными проблемами. Правообладатели активно подают в суд за использование мемов, даже если они созданы для развлечения. Например, «Си Ди Лэнд Контакт», приватизировавший Ждуна, несколько раз судился за его использование, Москвариум заявил о намерении зарегистрировать товарный знак «Рыбов показываем», петербургский предприниматель пытался, впрочем, безуспешно, зарегистрировать товарный знак «Как тебе такое, Илон».
Эта мировая практика показывает, как устаревшие законы о так называемом авторском праве, которое в первую очередь защищает не автора, а правообладателя, то есть, того, кто первым подберёт плохо лежащее, подавляют творчество и свободное выражение.
Пиратская партия России всецело поддерживает позицию ПП Германии.
Публикуем перевод их заявления:
Культура мемов — это здорово! Пираты обожают мемы. Мемы помогают людям делиться идеями и шутками. Но некоторые жадные создатели корпоративного контента нападают на тех, кто их создаёт. Они подают в суд на тех, кто создаёт мемы без какой-либо коммерческой цели. Мы должны дать этому отпор!Один явный случай произошел в Германии. Фанаты создали мемы о героине детской книги Конни. Издатель разослал письма с требованием прекратить противоправные действия. Они угрожали аккаунту в <запрещённой в РФ соцсети с фотографиями>. И им это удалось. Они закрыли аккаунт. Они ограничили свободу слова. Они уничтожили собственное творение. Мемы позволили бы Конни выжить. Конни умрёт. Спасите Конни!
Хотя в Германии особенно строго относятся к «нарушению авторских прав», эта проблема носит глобальный характер и не ограничивается только мемами.
Такие случаи случаются в мире искусства. Disney разослал официальные уведомления о фан-арте.
Такие случаи происходят в игровой индустрии. Nintendo закрывает игры, созданные на основе их контента.
В музыкальной индустрии такое случается. Музыканты подают в суд на других музыкантов за ремиксы своих треков.
Они происходят в социальных сетях. Поклонников событий в Южной Корее предостерегли по поводу мемов о военном положении.
Мемы — это здорово! Переделки игр — это здорово! Ремиксы — это здорово! Протесты в социальных сетях — это здорово! Так общество развивается и создаёт новые формы самовыражения. Знания — производны. Мы учимся на истории и создаём новые версии, которые немного отличаются, но лучше.
Давайте потребуем защиты мемов! Ни один материал не должен быть заморожен авторским правом!
Вся история искусства — это цепочка заимствований, переосмыслений и новых интерпретаций. Шекспир перерабатывал старые сюжеты, музыканты делали каверы, а кинорежиссёры снимали ремейки. Сегодня цифровые технологии позволяют людям создавать новые формы искусства на основе существующих произведений, но корпорации хотят запретить это, превратив культуру в «закрытый клуб».
Наша цель — культура, которая принадлежит людям и авторам, а не так называемым правообладателям!
Вступайте в Пиратскую партию России и присоединяйтесь к борьбе за свободные мемы, открытые лицензии и право на ремиксы. Вместе мы сможем остановить цензуру и сохранить интернет как пространство творчества.
Сообщение Пираты любят мемы появились сначала на Пиратская партия России | PPRU.
Copyright - «Рыбов показываем»: Москвариум планирует запатентовать популярный интернет-мем
Новости в сфере интеллектуальной собственности, информация о патентах.Консультации квалифицированных специалистов.Подборка нормативно - правовых актов по авторскому праву и смежным правамCopyright
Raid israeliano sulla chiesa della Sacra Famiglia a Gaza: ferito padre Romanelli
@Giornalismo e disordine informativo
articolo21.org/2025/07/raid-is…
Raid dell’esercito israeliano sulla chiesa della Sacra Famiglia a Gaza City, unico luogo di culto cattolico della Striscia: due le
Giornalismo e disordine informativo reshared this.
Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Hanno cominciato ad ammazzare cattolici, stai a vedere che adesso comincia a importarcene qualcosa...
La presidente del Consiglio Giorgia Meloni ha condannato l’attacco contro la chiesa e in generale contro la popolazione civile con toni particolarmente duri: in un comunicato ha detto che «sono inaccettabili gli attacchi contro la popolazione civile che Israele sta dimostrando da mesi. Nessuna azione militare può giustificarla.
ilpost.it/2025/07/17/chiesa-sa…

Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Quella della Sacra Famiglia: tre persone sono state uccise e nove ferite, fra cui il parrocoIl Post
Poliversity - Università ricerca e giornalismo reshared this.


TGR Valle d'Aosta del 17/07/2025 ore 14:00
TGR Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 17/07/2025 - 14:00

Meteo Valle d'Aosta del 17/07/2025 ore 14:00
Meteo Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 17/07/2025 - 14:00



A Field Guide to the North American Cold Chain

So far in the “Field Guide” series, we’ve mainly looked at critical infrastructure systems that, while often blending into the scenery, are easily observable once you know where to look. From the substations, transmission lines, and local distribution systems that make up the electrical grid to cell towers and even weigh stations, most of what we’ve covered so far are mega-scale engineering projects that are critical to modern life, each of which you can get a good look at while you’re tooling down the road in a car.
This time around, though, we’re going to switch things up a bit and discuss a less-obvious but vitally important infrastructure system: the cold chain. While you might never have heard the term, you’ve certainly seen most of the major components at one time or another, and if you’ve ever enjoyed fresh fruit in the dead of winter or microwaved a frozen burrito for dinner, you’ve taken advantage of a globe-spanning system that makes sure environmentally sensitive products can be safely stored and transported.
What’s A Cold Chain?
Simply put, the cold chain is a supply chain that’s capable of handling items that are likely to be damaged or destroyed unless they’re kept within a specific temperature range. The bulk of the cold chain is devoted to products intended for human consumption, mainly food but also pharmaceuticals and vaccines. Certain non-consumables also fall under the cold chain umbrella, including cosmetics, personal care products, and even things like cut flowers and vegetable seedlings. We’ll be mainly looking at the food cold chain for this article, though, since it uses most of the major components of a cold chain.
As the name implies, the cold chain is designed to maintain a fixed temperature over the entire life of a product. “Farm to fork” is a term often used to describe the cold chain, since the moment produce is harvested or prepared foods are manufactured, the clock starts ticking. The exact temperature required varies by food type. Many fruits and vegetables that ripen in the summer or early autumn can stand pretty high temperatures, at least for a while after harvesting, but some produce, like lettuces and fresh greens, will start wilting very quickly after harvest.
For extremely sensitive crops, the cold chain might start almost the second the crop is harvested. Highly perishable crops such as sweet corn, greens, asparagus, and peas require rapid cooling to remove field heat and to slow the biological processes that were still occurring within the plant tissues at the time of harvest. This is often accomplished right in the field with a hydrocooler, which uses showers or flumes of chilled water. Extremely perishable crops such as broccoli might even be placed directly into flaked ice in the field. Other, less-sensitive crops that can wait an hour or two will enter the cold chain only when they’re trucked a short distance to an initial processing plant.
Many foods, including different kinds of produce, fresh meat and fish, and lots of prepared meals, benefit from flash freezing. Flash freezing aims to reduce damage to the food by controlling the size and number of ice crystals that form within the cells of the plant or animal tissue. Simply putting a food item in a freezer and waiting for the heat to passively transfer out of it tends to form few but large ice crystals, which are far more damaging than the many tiny ice crystals that form when the heat is rapidly removed. Flash freezing methods include cryogenic baths using liquid nitrogen or liquid carbon dioxide, blast cooling with high-velocity jets of chilled air, fluidized bed cooling, where pressurized chilled air is directed upward through a bed of produce while it’s being agitated, and plate cooling, where chilled metal plates lightly contact flat, thin foods such as pizza or sliced fish.
youtube.com/embed/i0f-ychdTdE?…
Big and Cold

Once food is chilled to the proper temperature, it needs to be kept at that temperature until it can be sold. This is where cold warehousing comes in, an important part of the cold chain that provides controlled-temperature storage space that individual producers simply can’t afford to maintain. The problem for farmers is that many crops are determinate, meaning that all the fruits or vegetables are ready for harvest more or less at the same time. Outsourcing their cold warehousing to companies that specialize in that part of the cold chain allows them to concentrate on growing and harvesting their crop instead of having to maintain a huge amount of storage space, which would sit unused for the entire growing season.
Cold warehouses, or public refrigerated warehouses (PRWs) as they’re known in the trade, benefit greatly from economies of scale, and since they accept produce from hundreds or even thousands of producers, their physical footprints can be staggering. The average PRW in the United States has grown in size dramatically since the post-pandemic e-commerce boom and now covers almost 185,000 square feet, or more than 4 acres. Most PRWs have four temperature zones: deep freeze (-20°F to -10°F) for items such as ice cream and frozen vegetables; freezer (0°F to 10°F) for meats and prepared foods; refrigerated (35°F to 45°F), for fresh fruits and vegetables; and cool storage, which is basically just consistent room-temperature storage for shelf-stable food items. What’s more, each zone can have sub-zones tailored specifically for foods that prefer a specific temperature; bananas, for example, do best around 46°F, making the fridge section too cold and the cool section too warm. Sub-zones allow goods to be stored just right.
Due to the nature of their business, location is critical to PRWs. They have to be close to where the food is produced as well as handy to transportation hubs, which means you’ve probably seen one of these behemoth buildings from a highway and not even known it. The map above highlights the main agricultural regions of the United States, such as the fruit and vegetable producers in the Central Valley of California and the Willamette Valley in Oregon, meat packing plants in the Upper Midwest, the hog and chicken producers in the South, and seafood producers along both coasts. It also shows a couple of areas with no PRWs, which are areas where agriculture is limited to cereal grains, which don’t require refrigeration after harvest, and livestock, which are usually shipped for slaughter somewhere other than where they were raised.
Thanks to the complicated logistics of managing multiple shippers and receivers, most cold warehouses have a level of automation that rivals that of an Amazon distribution center. A lot of the automation is found in the high-bay freezer, a space often three or four stories tall that has rack after rack of space for storing palletized products. Automated storage and retrieval systems (AS/RS) store and fetch pallets using large X-Y gantry systems running between the racks. Algorithms determine the best storage location for pallets based on their contents, the temperature regime they require, and the predicted length of stay within the warehouse.
While AS/RS reduces the number of workers needed to run a cold warehouse, and there are some fully automated PRWs, most cold warehouses maintain a large workforce to run forklifts, pick pallets, and assemble orders for shipping. These workers face significant health and safety challenges, risking everything from slips and falls on icy patches to trench foot and chill-induced arthritis and dermatitis. Cold-stress injuries, such as hypothermia and frostbite, are possible too. Warehouses often have to limit the number of hours their employees work in the cold zones, and they have to provide thermal wear along with the standard complement of PPE.
youtube.com/embed/mW11jmZUHoE?…
Reefer Madness
Once an order is assembled and ready to ship from the cold warehouse, food enters perhaps the most visible — and riskiest — link in the cold chain: refrigerated trucks and shipping containers. Known as reefers, these are specialized vehicles that have the difficult task of keeping their contents at a constant temperature no matter what the outside conditions might be. A reefer might have to deliver a load of table grapes from a PRW in California to a supermarket distribution center in Massachusetts, continue to Maine to pick up a load of live lobsters, and drop that off at a PRW in Florida before running a load of oranges to Washington.
Meeting the challenge of all these conditions is the job of the refrigeration unit. Typically mounted in an aerodynamic fairing on the front of a semi-trailer unit, the refrigeration unit is essentially a heat pump on steroids. For over-the-road (OTR) reefers, as opposed to railcar reefers or shipping container reefers, the refrigeration unit is powered by a small but powerful diesel engine. Typically either three- or four-cylinder engines making 20 to 30 horsepower, these engines run the compressor that pumps the refrigerant through the condenser and evaporator, as well as the powerful fan that circulates air inside the trailer. Fuel for the engine is stored in a tank mounted under the trailer, allowing the reefer to run even when the trailer is parked with no tractor attached. The refrigeration unit is completely automatic, with a computer taking input from temperature sensors inside the trailer to make sure the interior remains at the setpoint. The computer also logs everything going on in the reefer, making the data available via a USB drive or to a central dispatcher via a telematics link.
The trailer body itself is carefully engineered, with thick insulation to minimize heat transfer to and from the outside environment while maximizing heat transfer between the produce and the air inside the trailer. For maximum cooling — or heating; if a load of bananas has to be kept at their happy place of 46°F while being trucked across eastern Wyoming in January, the refrigeration unit will probably have to run its cycle in reverse to add heat to the trailer — the air must reach the back of the unit. Reefer units use flexible ducts in the ceiling to direct the air 48 to 53 feet to the very back of the trailer, where it bounces off the rear doors and returns to the front of the trailer with the help of channels built into the floor. Shippers need to be careful when loading a reefer to obey load height limits and to correctly orient pallets so as not to block air circulation inside the trailer.
In addition to the data logging provided by the refrigeration unit, shippers will often include temperature loggers inside their shipments. Known generically to produce truckers as a “Ryan” for a popular brand, these analog strip chart recorders use a battery-powered motor to move a strip of paper past a bimetallic arm. Placed in a tamper-evident container, the recorder is placed within a pallet and records the temperature over a 10- to 40-day period. The receiver can break the seal open and see a complete temperature history of the shipment, detecting any accidental (or intentional; drivers sometimes find it hard to sleep with the reefer motor roaring right behind the sleeper cab) interruptions in the operation of the reefer.
Featured image: “Close Up of Frozen Vegetables” by Tohid Hashemkhani
This Service Life Study Really Grinds Our Gears

3D printing is arguably over-used in the maker community. It’s just so easy to run off a quick prototype and then… well, it’s good enough, right? Choosing the right plastic can go a long way to making sure your “good enough” prototype really is good enough for long term use. If you’re producing anything with gearing, you might want to cast your eyes to a study by [Mert Safak Tunalioglu] and [Bekir Volkan Agca] titled: Wear and Service Life of 3-D Printed Polymeric Gears.
The authors printed simple test gears in ABS, PLA, and PETG, and built a test rig to run them at 900 rpm with a load of 1.5 Nm against a steel drive gear. The gears were pulled off and weighed every 10,000 rotations, and allowed to run to destruction, which occurred in the hundreds-of-thousands of rotations in each case. The verdict? Well, as you can tell from the image, it’s to use PETG.
The authors think that this is down to PETG’s ductility, so we would have liked to see a hard TPU added to the mix, to say nothing of the engineering filaments. On the other hand, this study was aimed at the most common plastics in the 3D printing world and also verified a theoretical model that can be applied to other polymers.
This tip was sent in by [Benjamin], who came across it as part of the research to build his first telescope, which we look forward to seeing. As he points out, it’s quite lucky for the rest of us that the U.S. government provides funding to make such basic research available, in a way his nation of France does not. All politics aside, we’re grateful both to receive your tips and for the generosity of the US taxpayer.
We’ve seen similar tests done by the community — like this one using worm gears — but it’s also neat to see how institutional science approaches the same problem. If you need oodles of cycles but not a lot of torque, maybe skip the spurs and print a magnetic gearbox. Alternatively you break out the grog and the sea shanties and print yourself a capstan.
OMGCable: la sottile linea rossa tra penetration testing e sorveglianza occulta
Nel 2021, durante una delle mie esplorazioni sul confine sempre più sfumato tra hardware e cybersecurity, scrivevo un articolo dal titolo che oggi suona quasi profetico: “Anche un cavo prende vita”.
Allora si parlava degli albori del progetto OMG Cable: un innocuo cavo USB che, nascosto dietro l’aspetto di un semplice accessorio di ricarica, celava un cuore digitale capace di compiere operazioni di compromissione da far impallidire molti malware tradizionali.
E proprio in questi giorni, a distanza di quattro anni, mi è capitato di averne uno tra le mani, reale, fisico, pronto all’uso, inserito in un’attività di penetration test commissionata a un team che supporto.
Questa volta non si trattava di teoria, né di un test da laboratorio, ma di un vero scenario aziendale in cui l’obiettivo era colpire e far riflettere.
Il risultato è stato sorprendente. L’innocuo cavetto lasciato su una scrivania ha fatto il suo sporco lavoro in pochi secondi, dimostrando ancora una volta come la sicurezza fisica sia la porta d’ingresso più sottovalutata e più pericolosa di molte infrastrutture digitali.
E così, mentre riprendevo in mano quel cavo camuffato, non ho potuto fare a meno di tornare con la mente a quell’articolo del 2021. Ma questa volta con una consapevolezza in più: l’OMG Cable non è più una curiosità tecnologica. È una realtà operativa. E lo è oggi, qui, nel 2025.
Cos’è davvero l’OMGCable?
Immagina di avere tra le mani un cavo USB. Niente di strano: può essere USB-A, USB-C, Lightning, o magari un ibrido. Ha l’aspetto perfetto, identico all’originale Apple o Samsung. Funziona come un vero cavo: ricarica, trasferisce dati, collega dispositivi. Ma quello che non si vede è tutto il resto.
Dentro quel guscio di plastica, apparentemente innocuo, si nasconde un microcontrollore Wi-Fi programmabile. Non un giocattolo da maker, ma un modulo studiato con maniacale attenzione all’invisibilità.
Attraverso un’interfaccia accessibile da browser – o direttamente da uno smartphone – è possibile connettersi al cavo, caricare script, inviare comandi, aprire shell, trasferire file. E il tutto può essere fatto da remoto, senza che l’utente finale si accorga di nulla.
Una volta collegato a un computer, l’OMG Cable si comporta come una tastiera umana. Inietta comandi. Simula input. Può aprire terminali, eseguire codice, scaricare payload. E se questo non bastasse, può anche rilevare la geolocalizzazione, attivarsi solo in determinate aree, registrare sequenze di tasti, o cancellare la sua memoria con un comando di autodistruzione.
L’utilizzo legittimo: uno strumento da red team
In mano a un professionista del settore, questo strumento è semplicemente straordinario. Chi lavora in ambito red team lo sa bene: le simulazioni di attacco devono essere realistiche, efficaci e soprattutto imprevedibili.
Inserire un OMG Cable in uno scenario controllato permette di testare la sicurezza fisica, la consapevolezza del personale, l’efficacia delle policy aziendali.
Durante una simulazione di attacco mirato, il cavo può essere lasciato strategicamente in un’area comune, o usato da un operatore per valutare la risposta dei sistemi di difesa in caso di intrusione fisica.
In ambito formativo, poi, è uno strumento didattico eccezionale. Niente sensibilizza più di un attacco riuscito: far vedere a un dipendente che bastano due secondi per compromettere un sistema con un semplice cavo può cambiare radicalmente il suo approccio alla sicurezza.
Ma il confine è pericolosamente sottile
Tutto questo però ha un rovescio inquietante. Perché la stessa potenza che lo rende uno strumento utile e legittimo in ambito professionale, lo rende anche pericolosamente facile da abusare.
L’OMG Cable non richiede conoscenze avanzate per essere usato. Bastano pochi clic e una connessione Wi-Fi. Non serve scrivere malware, aggirare antivirus, bypassare protezioni. È sufficiente collegarlo.
E qui si apre un abisso. Perché chiunque, e dico chiunque, può acquistarlo online. Non ci sono controlli, né registrazioni. Nessun limite. Nessun avviso legale che accompagni l’acquisto.
Immagina una sala riunioni. Un collaboratore lascia un cavo attaccato a una presa. Un altro collega, ignaro, lo utilizza per collegare il proprio laptop. In quel momento, l’attaccante, che può essere seduto al bar a cento metri di distanza, apre una shell, esegue comandi, esfiltra dati. Tutto in silenzio. Nessuna finestra. Nessun allarme.
E immagina ora uno scenario domestico. O peggio, relazionale. Un cavo “dimenticato” in casa di qualcuno. Una tastiera invisibile che registra tutto. Che invia tutto. Che controlla tutto.
Non siamo lontani dalla fantascienza. Siamo esattamente lì.
Le implicazioni legali sono gravi. Ma chi le conosce?
In molti Paesi – Italia inclusa – strumenti come questo, se utilizzati per registrare comunicazioni senza consenso, possono rientrare nel reato di intercettazione illecita.
La legge italiana, ad esempio, punisce severamente l’uso di dispositivi atti a captare comunicazioni o informazioni private.
Eppure, l’OMG Cable non è soggetto ad alcun tipo di regolamentazione. Non esistono avvisi legali, licenze, autorizzazioni. Lo compri come un caricabatterie da viaggio.
Il problema, quindi, è duplice: da un lato la tecnologia corre veloce e propone soluzioni sempre più potenti. Dall’altro, la cultura e la consapevolezza di chi la utilizza restano pericolosamente indietro.
Serve una nuova etica. E serve ora.
Nel nostro mondo ci piace categorizzare: white hat, grey hat, black hat. Ma la realtà è molto più complessa. Uno strumento come l’OMG Cable mette in crisi queste categorie. Perché il confine tra uso etico e abuso criminale si gioca tutto sul contesto.
Ed è proprio questo contesto che manca. Le scuole, le aziende, i responsabili della sicurezza devono iniziare a includere l’etica hacker tra i temi fondamentali.
Non basta più insegnare a difendersi da un attacco. Bisogna anche insegnare perché certi attacchi non devono essere condotti.
Perché oggi, chiunque può essere un attaccante. E se non gli spieghi il confine, non è detto che lo riconosca da solo.
Ma allora come ci si difende?
Non esiste una risposta semplice. Non basta installare un antivirus o blindare i firewall. Il pericolo, in questo caso, entra dalla porta principale, con il consenso implicito dell’utente.
Bisogna rivedere le policy. Bisogna formare le persone. Bisogna controllare i dispositivi fisici con lo stesso rigore con cui si analizza un pacchetto di rete.
Il concetto di sicurezza fisica, da sempre sottovalutato nel digitale, oggi torna prepotentemente d’attualità.
Serve un cambio di paradigma. Una cultura nuova. Una consapevolezza che metta l’essere umano, con i suoi errori, le sue abitudini, le sue ingenuità, al centro della strategia difensiva.
Una conclusione che non conclude
L’OMG Cable non è il male. Non è il colpevole. È uno specchio. Riflette chi lo usa e per cosa lo usa.
È uno strumento potentissimo, che può fare bene o può fare male. Dipende da noi.
Ma una cosa è certa: chi lavora in cybersecurity non può permettersi di ignorarlo.
Perché la prossima compromissione potrebbe arrivare non da un allegato di phishing, non da una vulnerabilità CVE, ma da un semplice cavo lasciato sulla scrivania.
Nel 2021 scrivevo che anche il cavo ha una vita.
Oggi aggiungo: sta a noi decidere che direzione prenderà quella vita.
L'articolo OMGCable: la sottile linea rossa tra penetration testing e sorveglianza occulta proviene da il blog della sicurezza informatica.