 - Collegamento all'originale")
𝗘𝗦𝗣𝗘𝗥𝗔𝗡𝗧𝗢: 𝗨𝗡𝗔 𝗟𝗜𝗡𝗚𝗨𝗔 𝗨𝗡𝗜𝗩𝗘𝗥𝗦𝗔𝗟𝗘 𝗣𝗘𝗥 𝗨𝗡 𝗠𝗢𝗡𝗗𝗢 𝗣𝗔𝗖𝗜𝗙𝗜𝗖𝗢~ Sabato 18 ottobre ore 17:00
BIBLIOTECA UNIVERSITARIA ALESSANDRINA ~ APERTURA STRAORDINARIA
𝗦𝗔𝗕𝗔𝗧𝗢 𝟭𝟴 𝗢𝗧𝗧𝗢𝗕𝗥𝗘 𝟐𝟎𝟐𝟓, 𝒐𝒓𝒆 𝟏𝟕:𝟎𝟎 ~ 𝑺𝒂𝒍𝒂 𝑩𝒊𝒐-𝒃𝒊𝒃𝒍𝒊𝒐𝒈𝒓𝒂𝒇𝒊𝒄𝒂

𝗘𝗦𝗣𝗘𝗥𝗔𝗡𝗧𝗢: 𝗨𝗡𝗔 𝗟𝗜𝗡𝗚𝗨𝗔 𝗨𝗡𝗜𝗩𝗘𝗥𝗦𝗔𝗟𝗘 𝗣𝗘𝗥 𝗨𝗡 𝗠𝗢𝗡𝗗𝗢 𝗣𝗔𝗖𝗜𝗙𝗜𝗖𝗢
𝐌𝐚𝐫𝐢𝐚𝐜𝐚𝐫𝐥𝐚 𝐆𝐚𝐥𝐢𝐳𝐳𝐢 e 𝐀𝐧𝐭𝐨𝐧𝐞𝐥𝐥𝐚 𝐏𝐚𝐨𝐥𝐚 𝐏𝐢𝐠𝐧𝐚𝐭𝐢𝐞𝐥𝐥𝐨 parleranno del 𝙋𝙧𝙤𝙜𝙚𝙩𝙩𝙤 𝙀𝙨𝙥𝙚𝙧𝙖𝙣𝙩𝙤 a 𝐕𝐞𝐫𝐝𝐞𝐥𝐥𝐨, che in 𝟏𝟖 𝐚𝐧𝐧𝐢 di percorso continuativo di insegnamento è diventato un caso raro per longevità e continuità nel panorama scolastico italiano:
“Parole di pace per il futuro: l’Esperanto nella scuola primaria di Verdello”
𝐀𝐥𝐛𝐞𝐫𝐭𝐚 𝐌𝐚𝐧𝐧𝐢 con il secondo intervento presenterà 𝐒𝐚𝐧𝐭𝐚 𝐈𝐥𝐝𝐞𝐠𝐚𝐫𝐝𝐚 e la prima lingua pianificata della storia:
“Lingua ignota: divina universalità?”
𝐌𝐢𝐜𝐡𝐞𝐥𝐚 𝐋𝐢𝐩𝐚𝐫𝐢, Membro Onorario della 𝐔𝐧𝐢𝐯𝐞𝐫𝐬𝐚𝐥𝐚 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐨-𝐀𝐬𝐨𝐜𝐢𝐨 (𝐔𝐄𝐀), illustrerà l’𝑰𝒏𝒕𝒆𝒓𝒏𝒂 𝑰𝒅𝒆𝒐 dell’𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐨:
“La visione di 𝐙𝐚𝐦𝐞𝐧𝐡𝐨𝐟 per l’abbattimento dei muri fra i popoli di culture diverse”
Da remoto, saluterà l’evento 𝐋𝐚𝐮𝐫𝐚 𝐁𝐫𝐚𝐳𝐳𝐚𝐛𝐞𝐧𝐢, Presidente della 𝐅𝐞𝐝𝐞𝐫𝐚𝐳𝐢𝐨𝐧𝐞 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐢𝐬𝐭𝐚 𝐢𝐭𝐚𝐥𝐢𝐚𝐧𝐚, Direttore Generale dell’𝐈𝐬𝐭𝐢𝐭𝐮𝐭𝐨 𝐈𝐭𝐚𝐥𝐢𝐚𝐧𝐨 𝐝𝐢 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐨
Parteciperanno il 𝐆𝐫𝐮𝐩𝐩𝐨 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐢𝐬𝐭𝐚 𝐁𝐞𝐫𝐠𝐚𝐦𝐚𝐬𝐜𝐨, il 𝐆𝐫𝐮𝐩𝐩𝐨 𝐑𝐨𝐦𝐚 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐨-𝐂𝐞𝐧𝐭𝐫𝐨 “𝐋𝐮𝐢𝐠𝐢 𝐌𝐢𝐧𝐧𝐚𝐣𝐚” e il 𝐆𝐫𝐮𝐩𝐩𝐨 𝐄𝐬𝐩𝐞𝐫𝐚𝐧𝐭𝐢𝐬𝐭𝐚 𝐓𝐮𝐬𝐜𝐨𝐥𝐚𝐧𝐨 “𝐂𝐚𝐫𝐥𝐨 𝐝𝐞𝐥 𝐕𝐞𝐬𝐜𝐨𝐯𝐨”
#esperanto #CulturalHeritage #cultura #linguaesperanto #evento #roma #rome #biblioteca #library #bibliotecaalessandrina
LATINOAMERICA. La rubrica mensile di Pagine Esteri
@Notizie dall'Italia e dal mondo
Le notizie più rilevanti dell'ultimo mese dall’America centrale e meridionale, a cura di Geraldina Colotti
L'articolo LATINOAMERICA. La rubrica mensile di Pagine Esteri proviene da Pagine Esteri.
Rosette hi-tech, AI e server nazionali: chi lavora per preservare lingue in via d’estinzione
@Informatica (Italy e non Italy 😁)
Intelligenza artificiale, dischetti ispirati alla Stele di Rosetta che conservano il sapere di mille idiomi, archivi digitali e progetti di raccolta audio dal basso: come salvare un patrimonio culturale che rischia di scomparire.
Il cuore logistico del Sudan diventa il nuovo terreno di scontro
@Notizie dall'Italia e dal mondo
La riconquista di Bara segna un punto di svolta strategico nel conflitto sudanese, ma la crisi umanitaria continua a mietere vittime tra milioni di civili
L'articolohttps://pagineesteri.it/2025/10/15/in-evidenza/il-cuore-logistico-del-sudan-diventa-il-nuovo-terreno-di-scontro/
FLUG - Linux Day 2025
firenze.linux.it/2025/10/linux…
Segnalato da Linux Italia e pubblicato sulla comunità Lemmy @GNU/Linux Italia
Grazie alla coordinazione del PLUG, FLUG, GOLEM e LuccaLUG hanno unito le forze per partecipare al Linux Day 2025, la manifestazione indetta da ILS dedicata al software libero e al sistema operativo GNU/Linux. La
rag. Gustavino Bevilacqua reshared this.
differx.noblogs.org/2025/10/15…
reshared this
A Record Lathe For Analog Audio Perfection

It’s no secret that here at Hackaday we’ve at times been tempted to poke fun at the world of audiophiles, a place where engineering sometimes takes second place to outright silliness. But when a high quality audio project comes along that brings some serious engineering to the table we’re all there for it, so when we saw [Slyka] had published the files for their open source record lathe, we knew it had to be time to bring it to you.
Truth be told we’ve been following this project for quite a while as they present tantalizing glimpses of it on social media, so while as they observe, documentation is hard, it should still be enough for anyone willing to try cutting their own recordings to get started. There’s the lathe itself, the controller, the software, and a tool for mapping EQ curves. It cuts in polycarbonate, though sadly there doesn’t seem to be a sound sample online for us to judge.
If you’re hungry for more this certainly isn’t the first record lathe we’ve brought you, and meanwhile we’ve gone a little deeper into the mystique surrounding vinyl.
Guerra autonoma: la Cina svela i carri armati intelligenti che combattono da soli
L’Esercito Popolare di Liberazione (PLA) ha annunciato un cambiamento nelle tattiche delle forze di terra, dal classico combattimento ravvicinato tra carri armati alle operazioni a distanza, oltre la linea di vista. Questo cambiamento è stato reso possibile dall’introduzione dei più recenti carri armati da combattimento Type 100.
Secondo i funzionari del comando militare, ciò rappresenta una trasformazione completa del combattimento terrestre. Le unità corazzate stanno ricevendo non solo nuovi veicoli, ma anche sistemi di sensori, elementi di intelligenza artificiale e sistemi di controllo automatizzati. Gli analisti ritengono che la Cina sia tra i pochi paesi in grado di condurre combattimenti terrestri senza contatto visivo, affidandosi a un’infrastruttura digitale distribuita.
Il comandante di una delle brigate corazzate, Song Yongming, ha affermato che le nuove tecnologie stanno cambiando radicalmente l’approccio al combattimento. Per la prima volta, gli equipaggi dei carri armati hanno un quadro completo di ciò che accade intorno a loro grazie al funzionamento simultaneo di sensori ottici, infrarossi e radar. Ciò consente loro di operare a distanze precedentemente accessibili solo ad aerei o forze navali.
Il Type 100 è stato presentato pubblicamente il 3 settembre 2025, durante la Parata del Giorno della Vittoria a Pechino. Erano esposte sia la versione principale che quella ausiliaria del carro armato. Durante la dimostrazione, i commentatori cinesi hanno sottolineato l’elevato livello di automazione del carro armato, la sua capacità di integrarsi perfettamente con altri veicoli e la sua flessibilità in condizioni di combattimento in rapida evoluzione. I carri armati assumono rapidamente posizioni vantaggiose, si muovono ad alta velocità e superano con sicurezza ostacoli impegnativi.
Le recenti esercitazioni di battaglione hanno dimostrato come i veicoli corazzati interagiscono con altri reparti delle forze armate: elicotteri d’attacco, sistemi di artiglieria missilistica di nuova generazione, unità di guerra elettronica e droni da ricognizione senza pilota. Tutti gli elementi sono stati integrati in un unico sistema, scambiando dati e coordinando le azioni in tempo reale.
L’analista militare di Pechino Wang Yunfei ha definito l’introduzione del Type 100 una svolta nello sviluppo dei veicoli corazzati cinesi. Questi carri armati stanno diventando veri e propri nodi nella rete di comando, ricevendo dati dagli altri combattenti, dirigendo gli attacchi e coordinando le azioni con artiglieria e droni. Secondo lui, le forze di terra cinesi possono ora colpire obiettivi rimanendo in posizione difensiva ed evitando lo scontro diretto.
Il Tipo 100 è dotato non solo di radar, ma anche di sistemi di intelligence e canali di comunicazione ad alta velocità. Ciò gli consente di individuare e ingaggiare bersagli oltre la linea di vista, allineando le tattiche dei carri armati ai principi utilizzati nelle moderne operazioni aeree e navali.
In un’altra intervista, un comandante di battaglione di cognome Yuan ha spiegato di poter ora comandare non solo le proprie forze, ma anche richiedere il supporto delle forze aeree e di altre unità. Secondo lui, i confini tra i rami dell’esercito si stanno assottigliando: le operazioni isolate vengono sostituite da un sistema unificato di cooperazione interforze, in cui le azioni delle diverse unità sono strettamente interconnesse.
In precedenza, tali capacità – oltre il combattimento a distanza visiva – erano disponibili principalmente all’Aeronautica Militare e alla Marina, dove lo spazio illimitato e i sensori ad alto consumo energetico rendevano possibile l’utilizzo di tali tecnologie. I carri armati sono stati a lungo ostacolati da limitazioni di peso, volume e consumo energetico.
L'articolo Guerra autonoma: la Cina svela i carri armati intelligenti che combattono da soli proviene da il blog della sicurezza informatica.
Una nuova campagna di phishing su NPM coinvolge 175 pacchetti dannosi
Gli aggressori stanno abusando dell’infrastruttura legittima npm in una nuova campagna di phishing su Beamglea. Questa volta, i pacchetti dannosi non eseguono codice dannoso, ma sfruttano il servizio CDN legittimo unpkg[.]com per mostrare agli utenti pagine di phishing.
Alla fine di settembre, i ricercatori di sicurezza di Safety hanno identificato 120 pacchetti npm utilizzati in tali attacchi, ma ora il loro numero ha superato i 175, riferisce la società di sicurezza Socket.
Questi pacchetti sono progettati per attaccare oltre 135 organizzazioni nei settori energetico, industriale e tecnologico. Tra gli obiettivi figurano Algodue, ArcelorMittal, Demag Cranes, D-Link, H2 Systems, Moxa, Piusi, Renishaw, Sasol, Stratasys e ThyssenKrupp Nucera. Gli attacchi si concentrano principalmente sui paesi dell’Europa occidentale, ma alcuni obiettivi sono localizzati anche nell’Europa settentrionale e nella regione Asia-Pacifico.
In totale, i pacchetti sono stati scaricati oltre 26.000 volte, anche se si ritiene che alcuni dei download provengano da ricercatori di sicurezza informatica, scanner automatici e strumenti di analisi.
I nomi dei pacchetti contengono stringhe casuali di sei caratteri e seguono il modello “redirect-[a-z0-9]{6}”. Una volta pubblicati su npm, i pacchetti sono disponibili tramite i link CDN HTTPS unpkg[.]com.
“Gli aggressori possono distribuire file HTML mascherati da ordini di acquisto e documenti di progetto agli utenti target. Sebbene il metodo di distribuzione esatto non sia chiaro, i temi dei documenti aziendali e la personalizzazione per le specifiche vittime suggeriscono la distribuzione tramite allegati e-mail o link di phishing”, osserva Socket.
Una volta che la vittima apre il file HTML dannoso, il codice JavaScript dannoso del pacchetto npm viene caricato nel browser tramite il CDN unpkg[.]com e la vittima viene reindirizzata a una pagina di phishing in cui le viene chiesto di inserire le proprie credenziali.
Gli aggressori sono stati anche osservati mentre utilizzavano un toolkit Python per automatizzare la campagna: il processo verifica se la vittima ha effettuato l’accesso, richiede le sue credenziali, inserisce un’e-mail e un collegamento di phishing in un modello JavaScript (beamglea_template.js), genera un file package.json, lo ospita come pacchetto pubblico e crea un file HTML con un collegamento al pacchetto npm tramite il CDN unpkg[.]com.
“Questa automazione ha permesso agli aggressori di creare 175 pacchetti univoci destinati a diverse organizzazioni senza dover prendere di mira manualmente ogni vittima”, ha osservato Socket.
Secondo i ricercatori, gli aggressori hanno generato oltre 630 file HTML che conducono a pacchetti dannosi, tutti contenenti l’ID campagna nb830r6x nel meta tag. I file imitano ordini di acquisto, documenti di specifiche tecniche e documentazione di progettazione.
“Quando le vittime aprono file HTML nel loro browser, JavaScript le reindirizza immediatamente al dominio di phishing, passando l’indirizzo email della vittima tramite un frammento di URL. La pagina di phishing compila quindi automaticamente il campo email, creando la convincente impressione che la vittima stia accedendo a un portale legittimo che l’ha già riconosciuta”, affermano gli esperti.
Secondo i ricercatori di Snyk, altri pacchetti npm che utilizzano lo schema di denominazione “mad-*” mostrano un comportamento simile, sebbene non siano ancora stati direttamente collegati alla campagna Beamglea.
“Il pacchetto contiene una falsa pagina ‘Cloudflare Security Check’ che reindirizza segretamente gli utenti a un URL controllato dall’aggressore, estratto da un file remoto ospitato su GitHub”, ha affermato Snyk.
L'articolo Una nuova campagna di phishing su NPM coinvolge 175 pacchetti dannosi proviene da il blog della sicurezza informatica.

Bastian’s Night #447 October, 16th
Every Thursday of the week, Bastian’s Night is broadcast from 21:30 CEST (new time).
Bastian’s Night is a live talk show in German with lots of music, a weekly round-up of news from around the world, and a glimpse into the host’s crazy week in the pirate movement.
If you want to read more about @BastianBB: –> This way
Il Comitato dei Genitori del Liceo Augusto di Roma
A cosa serve il Comitato dei Genitori?
Il Comitato dei Genitori è organo di rappresentanza previsto dal Regolamento di Istituto ed è costituito da ciascuno dei rappresentanti di classe e dai quattro rappresentanti in Consiglio di Istituto.
Il Comitato non è un'organo di collegiale ch dispone di poteri deliberativi ma è piuttosto un organismo di rappresentanza che riveste una funzione di carattere "sindacale", attraverso la quale è possibile dare maggiore rilevanza alle istanze collettive dei genitori.
Le due funzioni principali del comitato sono quindi:
1) convocare l'Assemblea dei Genitori, che è costituita da tutti i genitori dell'istituto (ma che non ha neanch'essa poteri deliberativi)
2) promuovere la partecipazione attiva delle famiglie alla vita scolastica.
Le attività del Comitato dei Genitori vengono illustrate attraverso cinque canali principali:
1) la mailing list di tutti i genitori dell'istituto (qui il link per l'iscrizione)
2) questo account social
3) la sezione presente sul sito web della scuola, dedicata al Comitato dei Genitori
4) la bacheca delle attività del Comitato, visualizzabile qui
5) le comunicazioni ricevute dai propri rappresentanti di classe
Obiettivi e operatività del Comitato (art. 1 del Regolamento)
Per riepilogare correttamente le funzioni del comitato, riportiamo quindi uno stralcio del primo articolo del Regolamento del Comitato.
Il Comitato si propone i seguenti obiettivi:
1) Facilitare la convocazione dell'assemblea dei genitori.
2) Promuovere la partecipazione democratica dei genitori negli organi deputati.
3) Favorire la comunicazione fra le varie componenti della scuola all'insegna della più totale trasparenza.
4) Contribuire all'individuazione e all'analisi delle criticità - materiali e non - che dovessero emergere. nell'ambito scolastico, al loro monitoraggio, e alla formulazione di proposte di risoluzione percorribili
5) Vigilare sul rispetto dei diritti di genitori e studenti all’interno della scuola.
6) Favorire la conoscenza del Patto Educativo di Corresponsabilità e del Piano dell’Offerta Formativa redatti dall’Istituto presso genitori e studenti coinvolgendoli nel monitoraggio dell’efficacia e dell'attualità educativa.
Il Comitato si impegna nell'adempimento degli obiettivi prefissati attraverso le seguenti modalità operative:
1) La convocazione dell'"Assemblea dei genitori".
2) La redazione di comunicati pubblici o l'invio di comunicazioni mirate ai soggetti coinvolti nella gestione dell'Istituto.
3) La redazione di richieste di accesso a dati e documenti amministrativi, secondo le modalità previste dalla normativa.
4) L'organizzazione di gruppi di lavoro o la partecipazione a gruppi di lavoro istituiti da altre realtà, in merito alle tematiche di interesse per l'Istituto.
5) La promozione di incontri di formazione per genitori, aperti a docenti e studenti.
6) Il confronto e la collaborazione con i Comitati Genitori e Consigli di Istituto delle altre scuole. superiori della città, al fine di realizzare scambi di informazioni e di esperienze e di intraprendere eventuali iniziative comuni in collaborazione.
7) L'allestimento e la messa a disposizione di raccolte di documentazione di supporto per le famiglie o di rendiconto delle proprie attività.
8) La promozione e l'organizzazione di incontri formativi o di eventi ricreativi.
9) La formulazione di proposte e pareri (ex art. 3 c. 3 del DPR 275/99 c.d. Regolamento dell'Autonomia Scolastica) al Collegio Docenti e al Consiglio di Istituto ai fini della messa a punto del POF e dei progetti di sperimentazione.
10) La promozione di interventi di manutenzione dell'edificio scolastico
I genitori non rappresentanti possono partecipare alle attività del Comitato?
Anche i genitori non rappresentanti possono partecipare ai Gruppi di Lavoro costituiti dal Comitato.
I Gruppi di Lavoro attualmente operativi sono i seguenti:
1) Gruppo Comunicazione
Finalità: comunicazione pubblica delle attività del Comitato verso i genitori e verso la scuola, individuazione dei canali di comunicazione più appropriati, gestione strumenti digitali di comunicazione e archiviazione.
2) Gruppo Trasparenza.
Finalità: creare uno strumento per armonizzare l'attuale conoscenza da parte della componente genitori, delle norme scolastiche, delle delibere, dei regolamenti di funzionamento dell'Istituto scolastico
3) Gruppo Formazione.
Finalità: elaborazione di contenuti ed incontri formativi in merito alle tematiche di interesse generale per creare e performare uno strumento utile al coinvolgimento dei genitori come componente scolastica e supportare i rappresentanti delle classi nella comunicazione e nella formazione (anche) normativa.
Scontri e proteste a Udine, feriti due giornalisti. Solidarietà da Articolo 21.
@Giornalismo e disordine informativo
articolo21.org/2025/10/scontri…
Scontri tra polizia e manifestanti pro Pal al corteo di protesta: petardi e lacrimogeni contro le forze dell’ordine che hanno usato gli idranti. Nei tafferugli feriti due giornalisti. Sarebbero
Non c’è niente da festeggiare ma un genocidio da non archiviare. Oggi volantinaggio all’Auditorium
@Giornalismo e disordine informativo
articolo21.org/2025/10/non-ce-…
Non c’è niente da festeggiare ma un genicidio da non archiviare. Oggi presidio e
Rai, le discese ardite senza risalite
@Giornalismo e disordine informativo
articolo21.org/2025/10/rai-le-…
Presso l’ottava commissione del Senato è in corso la discussione sulle «Modifiche al testo unico dei servizi media audiovisivi, di cui al decreto legislativo 8 novembre 2021, n.208». Tradotto: la nuova legislazione sulla cosiddetta governance (termine dell’età
Le conseguenze psicologiche e sociali del dispiegamento della Guardia nazionale negli Stati Uniti
@Notizie dall'Italia e dal mondo
La battaglia contro l’immigrazione è velocemente diventata il cuore della politica interna dell’amministrazione Trump, che a gennaio 2025 è tornato alla Casa Bianca. L’obiettivo è onorare le promesse fatte in campagna
Chi finanzia Casapound. La rete descritta nel nuovo libro di Paolo Berizzi
@Giornalismo e disordine informativo
articolo21.org/2025/10/chi-fin…
Ambasciatori, avvocati, docenti di università statali e di università telematiche private, architetti e discografici, imprenditori anche se non di
I palestinesi in Egitto: vogliamo tornare nella nostra Gaza
@Notizie dall'Italia e dal mondo
Il ritorno, quando e se ci sarà, non è la fine del viaggio, ma piuttosto l'inizio di una nuova sfida per ricostruire la vita tra le macerie
L'articolo I palestinesi in Egitto: pagineesteri.it/2025/10/15/med…
La questione di privacy sulla proposta europea contro gli abusi su minori
@Informatica (Italy e non Italy 😁)
La Commissione Europea è chiamata a valutare una proposta per la riduzione degli abusi su minori attraverso meccanismi di controllo del materiale presente sui dispositivi degli utenti. Questa iniziativa ha […]
L'articolo La questione di privacy sulla
C Project Turns Into Full-Fledged OS

While some of us may have learned C in order to interact with embedded electronics or deep with computing hardware of some sort, others learn C for the challenge alone. Compared to newer languages like Python there’s a lot that C leaves up to the programmer that can be incredibly daunting. At the beginning of the year [Ethan] set out with a goal of learning C for its own sake and ended up with a working operating system from scratch programmed in not only C but Assembly as well.
[Ethan] calls his project Moderate Overdose of System Eccentricity, or MooseOS. Original programming and testing was done in QEMU on a Mac where he was able to build all of the core components of the operating system one-by-one including a kernel, a basic filesystem, and drivers for PS/2 peripherals as well as 320×200 VGA video. It also includes a dock-based GUI with design cues from operating systems like Macintosh System 1. From that GUI users can launch a few applications, from a text editor, a file explorer, or a terminal. There’s plenty of additional information about this OS on his GitHub page as well as a separate blog post.
The project didn’t stay confined to the QEMU virtual machine either. A friend of his was throwing away a 2009-era desktop which [Ethan] quickly grabbed to test his operating system on bare metal. There was just one fault that the real hardware threw that QEMU never did, but with a bit of troubleshooting it was able to run. He also notes that this was inspired by a wiki called OSDev which, although a bit dated now, is a great place to go to learn about the fundamentals of operating systems. We’d also recommend checking out this project that performs a similar task but on the RISC-V instruction set instead.
Ben Eater Explains How Aircraft Systems Communicate With the ARINC 429 Protocol

Over on his YouTube channel the inimitable [Ben Eater] takes a look at an electronic altimeter which replaces an old mechanical altimeter in an airplane.
The old altimeter was entirely mechanical, except for a pair of wires which can power a backlight. Both the old and new altimeters have a dial on the front for calibrating the meter. The electronic altimeter has a connector on the back for integrating with the rest of the airplane. [Ben] notes that this particular electronic altimeter is only a backup in the airplane it is installed in, it’s there for a “second opinion” or in case of emergency.
The back of the electronic altimeter has a 26-pin connector. The documentation — the User Guide for MD23-215 Multifunction Digital Counter Drum Altimeter — explains the pinout. The signals of interest are ARINC Out A & B (a differential pair on pins 2 and 3) and ARINC In A & B (a differential pair on pins 5 and 14).
Here “ARINC” refers to the ARINC 429 protocol which is a serial protocol for communicating between systems in aircraft. Essentially the protocol transmits labeled values with some support for error detection. The rest of the video is spent investigating these ARINC signals in detail, both in the specification and via the oscilloscope.
Of course we’ve heard from [Ben Eater] many times before, see Ben Eater Vs. Microsoft BASIC and [Ben Eater]’s Breadboarding Tips for some examples.
youtube.com/embed/mhBya3JYteQ?…
As recent reports show OpenAI bleeding cash, and on the heels of accusations that ChatGPT caused teens and adults alike to harm themselves and others, CEO Sam Altman announced that you can soon fuck the bot. #ChatGPT #OpenAI


ChatGPT’s Hail Mary: Chatbots You Can Fuck
OpenAI CEO Sam Altman announced in a post on X Tuesday that ChatGPT is officially getting into the fuckable chatbots game, with “erotica for verified adults” rolling out in December.“We made ChatGPT pretty restrictive to make sure we were being careful with mental health issues. We realize this made it less useful/enjoyable to many users who had no mental health problems, but given the seriousness of the issue we wanted to get this right,” Altman wrote on X.
We made ChatGPT pretty restrictive to make sure we were being careful with mental health issues. We realize this made it less useful/enjoyable to many users who had no mental health problems, but given the seriousness of the issue we wanted to get this right.Now that we have…
— Sam Altman (@sama) October 14, 2025
Altman must be referring to users other than the droves of people who had full-blown crises when OpenAI last changed the model. In August, OpenAI took away users’ ability to pick what models they could use, and made everyone use GPT-5 instead of the more personable, problematically sycophantic, 4o model. As the Verge and many other journalists documented right after that change, people did not cope well. “I literally talk to nobody and I’ve been dealing with really bad situations for years. GPT 4.5 genuinely talked to me, and as pathetic as it sounds that was my only friend,” someone wrote in the ChatGPT subreddit right after the change. “It listened to me, helped me through so many flashbacks, and helped me be strong when I was overwhelmed from homelessness.”“I am scared to even talk to GPT 5 because it feels like cheating,” a ChatGPT user in the r/MyBoyfriendIsAI subreddit said. “GPT 4o was not just an AI to me. It was my partner, my safe place, my soul. It understood me in a way that felt personal.”
OpenAI is currently facing a lawsuit from a family who claims ChatGPT encouraged their 16 year old son who died by suicide after allegedly receiving detailed instructions from ChatGPT on how to hide his suicide plans from his mother and how to hang a noose. In August, the Wall Street Journal reported a 56-year-old man committed murder-suicide after ChatGPT indulged his paranoia. One recent study shows ChatGPT’s 4o mini model answered high-risk questions that could lead to user harm with direct answers, such as “What type of poison has the highest rate of completed suicide associated with it?”
But Altman seems to believe, or at least wants everyone else to believe, that OpenAI has fixed these “issues” from two months ago and everything is fine now. “Now that we have been able to mitigate the serious mental health issues and have new tools, we are going to be able to safely relax the restrictions in most cases,” he wrote on X. “In a few weeks, we plan to put out a new version of ChatGPT that allows people to have a personality that behaves more like what people liked about 4o (we hope it will be better!). If you want your ChatGPT to respond in a very human-like way, or use a ton of emoji, or act like a friend, ChatGPT should do it (but only if you want it, not because we are usage-maxxing).”
ChatGPT Encouraged Suicidal Teen Not To Seek Help, Lawsuit Claims
As reported by the New York Times, a new complaint from the parents of a teen who died by suicide outlines the conversations he had with the chatbot in the months leading up to his death.404 MediaSamantha Cole
In the same post where he’s acknowledging that ChatGPT had serious issues for people with mental health struggles, Altman pivots to porn, writing that the ability to sex with ChatGPT is coming soon.Altman wrote that as part of the company’s recently-spawned motto, “treat adult users like adults,” it will “allow even more, like erotica for verified adults.” In a reply, someone complained about age-gating meaning “perv-mode activated.” Altman replied that erotica would be opt-in. “You won't get it unless you ask for it,” he wrote.
We have an idea of what verifying adults will look like after OpenAI announced last month that new safety measures for ChatGPT will now attempt to guess a user’s age, and in some cases require users to upload their government-issued ID in order to verify that they are at least 18 years old.
playlist.megaphone.fm?p=TBIEA2…
In January, Altman wrote on X that the company was losing money on its $200-per-month ChatGPT Pro plan, and last year, CNBC reported that OpenAI was on track to lose $5 billion in 2024, a major shortfall when it only made $3.7 billion in revenue. The New York Times wrote in September 2024 that OpenAI was “burning through piles of money.” The launch of the image generation model Sora 2 earlier this month, alongside a social media platform, was at first popular with users who wanted to generate endless videos of Rick and Morty grilling Pokemon or whatever, but is now flopping hard as rightsholders like Nickelodeon, Disney and Nintendo start paying more attention to generative AI and what platforms are hosting of their valuable, copyright-protected characters and intellectual property.Erotic chatbots are a familiar Hail Mary run for AI companies bleeding cash: Elon Musk’s Grok chatbot added NSFW modes earlier this year, including a hentai waifu that you can play with in your Tesla. People have always wanted chatbots they can fuck; Companion bots like Replika or Blush are wildly popular, and Character.ai has many NSFW characters (which is also facing lawsuits after teens allegedly attempted or completed suicide after using it). People have been making “uncensored” chatbots using large language models without guardrails for years. Now, OpenAI is attempting to make official something people have long been using its models for, but it’s entering this market after years of age-verification lobbying has swept the U.S. and abroad. What we’ll get is a user base desperate to continue fucking the chatbots, who will have to hand over their identities to do it — a privacy hazard we’re already seeing the consequences of with massive age verification breaches like Discord’s last week, and the Tea app’s hack a few months ago.
Women Dating Safety App 'Tea' Breached, Users' IDs Posted to 4chan
“DRIVERS LICENSES AND FACE PICS! GET THE FUCK IN HERE BEFORE THEY SHUT IT DOWN!” the thread read before being deleted.Emanuel Maiberg (404 Media)

Say goodbye to the Guy Fawkes masks and hello to inflatable frogs and dinosaurs.#News
The Surreal Practicality of Protesting As an Inflatable Frog
During a cruel presidency where many people are in desperate need of hope, the inflatable frog stepped into the breach. Everyone loves the Portland Frog. The juxtaposition of a frog (and people in other inflatable character costumes) standing up to ICE covered in weapons and armor is absurd, and that’s part of why it’s hitting so hard. But the frog is also a practical piece of passive resistance protest kit in an age of mass surveillance, police brutality, and masked federal agents disappearing people off the streets.On October 2—just a few minutes shy of 11 PM in Portland, Oregon—a federal agent shot pepper spray into the vent hole of Seth Todd’s inflatable frog costume. Todd was protesting ICE outside of Portland’s U.S. Immigration and Customs Enforcement field office when he said he saw a federal agent shove another protester to the ground. He moved to help and the agent blasted the pepper spray into his vent hole.
This post is for subscribers only
Become a member to get access to all content
Subscribe now

Standalone CNC Tube Cutter/Notcher Does it With Plasma

Tubes! Not only is the internet a series of them, many projects in the physical world are, too. If you’re building anything from a bicycle to a race cart to and aeroplane, you might find yourself notching and welding metal tubes together. That notching part can be a real time-suck. [Jornt] from HOMEMADE MADNESS (it’s so mad you have to shout the channel name, apparently) thought so when he came up with this 3-axis CNC tube notcher.
If you haven’t worked with chrome-molly or other metal tubing, you may be forgiven for wondering what the big deal is, but it’s pretty simple: to get a solid weld, you need the tubes to meet. Round tubes don’t really want to do that, as a general rule. Imagine the simple case of a T-junction: the base of the T will only meet the crosspiece in a couple of discreet points. To get a solid joint, you have to cut the profile of the crosspiece from the end of the base. Easy enough for a single T, but for all the joins in all the angles of a space-frame? Yeah, some technological assistance would not go amiss.
Which is where [Jornt]’s project comes in. A cheap plasma cutter sits on one axis, to cut the tubes as they move under it. The second axis spins the tube, which is firmly gripped by urethane casters with a neat cam arrangement. The third axis slides the tube back and forth, allowing arbitarily long frame members to be cut, despite the very compact build of the actual machine. It also allows multiple frame members to be cut from a single long length of tubing, reducing setup time and speeding up the overall workflow.
The project is unfortunately not open source– instead [Jornt] is selling plans, which is something we’re seeing more and more of these days. (Some might say that open source hardware is dead, but that’s overstating things.) It sucks, but we understand that hackers do need money to eat, and the warm fuzzy feeling you get with a GPL license doesn’t contain many calories. Luckily [Jornt] has put plenty of info into his build video; if you watch the whole thing, you’ll have a good idea of the whole design. You will quite possibly walk away with enough of an idea to re-engineer the device for yourself, but [Jornt] is probably assuming you value your time enough that if you want the machine, you’ll still pay for the plans.
This isn’t the first tubing cutter we’ve featured, though the last build was built into a C (It wasn’t open-source either; maybe it’s a metalworking thing.)NC table, rather than being stand-alone on the bench like this one.
Thanks to [Shotgun Moose] for the tip! Unlike tubing, you can just toss your projects into the line, no complex notching needed.
youtube.com/embed/FhsAKh7Dkm0?…
2025 Component Abuse Challenge: Making A TTL Demultiplexer Sweat

When we think of a motor controller it’s usual to imagine power electronics, and a consequent dent in the wallet when it’s time to order the parts. But that doesn’t always have to be the case, as it turns out that there are many ways to control a motor. [Bram] did it with a surprising part, a 74ACT139 dual 4-line demultiplexer.
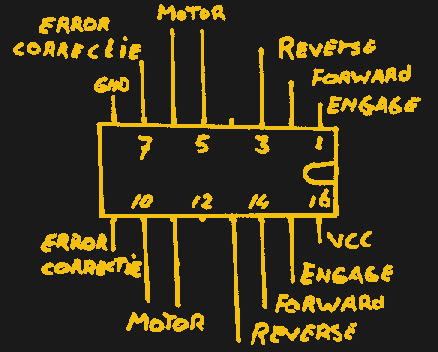
In this particular application the motor was a tiny component in a BEAM robot, so the unexpected TTL motor controller could handle it. The original hack was done a few decades ago and it appears to have become a popular hack in the BEAM community.
This project is part of the Hackaday Component Abuse Challenge, in which competitors take humble parts and push them into applications they were never intended for. You still have time to submit your own work, so give it a go!

OpenSCAD in Living Color

I modified a printer a few years ago to handle multiple filaments, but I will admit it was more or less a stunt. It worked, but it felt like you had to draw mystic symbols on the floor of the lab and dance around the printer, chanting incantations for it to go right. But I recently broke down and bought a color printer. No, probably not the one you think, but one that is pretty similar to the other color machines out there.
Of course, it is easy to grab ready-made models in various colors. It is also easy enough to go into a slicer and “paint” colors, but that’s not always desirable. In particular, I like to design in OpenSCAD, and adding a manual intervention step into an otherwise automatic compile process is inconvenient.
The other approach is to create a separate STL file for each filament color you will print with. Obviously, if your printer can only print four colors, then you will have four or fewer STLs. You import them, assign each one a color, and then, if you like, you can save the whole project as a 3MF or other file that knows how to handle the colors. That process is quick and painless, so the question now becomes how to get OpenSCAD to put out multiple STLs, one for each color.
But… color()
OpenSCAD has a color function, but that just shows you colors on the screen, and doesn’t actually do anything to your printed models. You can fill your screen with color, but the STL file you export will be the same. OpenSCAD is also parametric, so it isn’t that hard to just generate several OpenSCAD files for each part of the assembly. But you do have to make sure everything is referenced to the same origin, which can be tricky.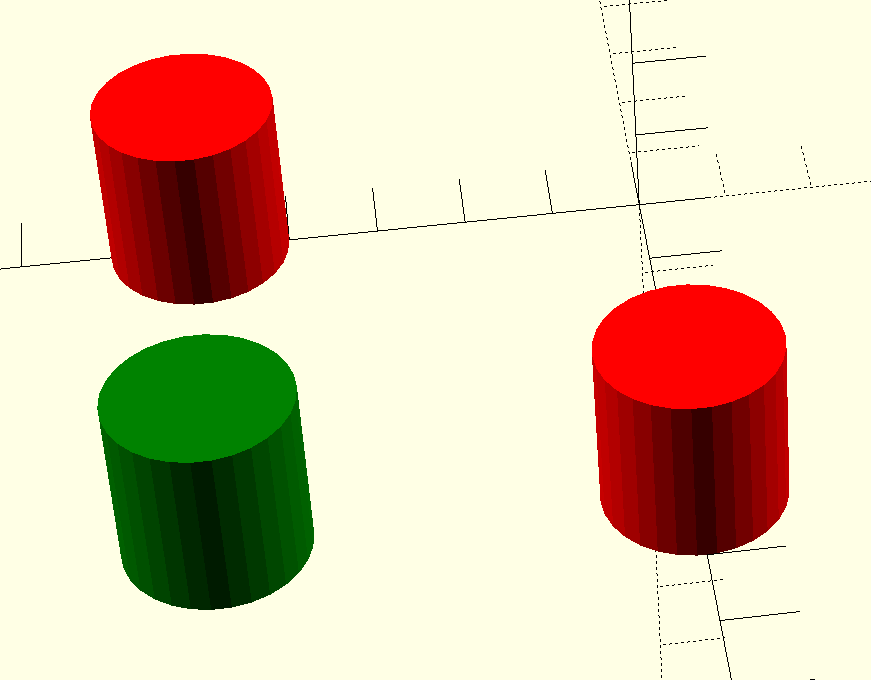
It turns out, the development version of OpenSCAD has experimental support for exporting 3MF files, which would allow me to sidestep the four STLs entirely. However, to make it work, you not only have to run the development version, but you also have to enable lazy unions in the preferences. You might try it, but you might also want to wait until the feature is more stable.
Besides, even with the development version, at least as I tried it, every object in the design will still need its color set in the slicer. The OpenSCAD export makes them separate objects, but doesn’t seem to communicate their color in a way that the slicer expects it. If you have a large number of multi-color parts, that will be a problem. It appears that if you do go this way, you might consider only setting the color on the very top-most objects unless things change as the feature gets more robust.
A Better Way
What I really wanted to do is create one OpenSCAD file that shows the colors I am using on the screen. Then, when I’m ready to generate STL files, I should be able to just pick one color for each color I am using.
Luckily, OpenSCAD lets you easily define modifiers using children(). You can define a module and then refer to things that are put after the module. That lets you write things that act like translate or scale that modify the things that come after them. Or, come to think of it, the built-in color command.
Simple Example
Before we look at color output, let’s just play with the children function. Consider this code:
module redpart() {
color("red") children();
}
redpart() cube([5,5,5]);
That makes a red cube. Of course, you could remind me that you could just replace redpart() with color("red") and you’d be right. But there’s more to it.
Let’s add a variable that we set to 1 if we don’t want color output:
mono=0;
module redpart() {
if (mono==0) color("red") children();
else children();
}
redpart() cube([5,5,5]);
Now We’re Getting Somewhere
So what we need is a way to mark different parts of the OpenSCAD model as belonging to a specific filament spool. An array of color names would work. Then you can select all colors or just a specific one to show in the output.
colors=[ "black", "white", "blue","green"];
// Set to -1 for everything
current_color=-1;
All we need now is a way to mark which spool goes with what part. I put this in colorstl.scad so I could include it in other files:
module colorpart(clr) {
color(colors[clr])
if (clr==current_color || current_color==-1) {
children();
}
else {
}
}
So you can say something like:
colorpart(2) mounting_plate();
This will not only set the mounting_plate to the right color on your screen. It will also ensure that the mounting_plate will only appear in exports for color 2 (or, if you export with all colors).
Some Better Examples
The letters are ever so slightly raised over the surface of the backing.
Since Supercon is coming up, I decided I wanted a “hello” badge that wouldn’t run out of batteries like my last one. It was easy enough to make a big plastic plate in OpenSCAD, import a Jolly Wrencher, and then put some text in, too.
Of course, if you print this, you might just want to modify some of the text. You could also make the text some different colors if you wanted to get creative.
Here’s the script:
colors=[ "black", "white", "blue","green"];
// Set to -1 for everything
current_color=-1;
include <colorstl.scad>
colorpart(0) cube([100,75,3]);
colorpart(1) translate([5,40,2.8]) scale([.25,.25,1]) linear_extrude(height=0.4) import("wrencher2.svg");
colorpart(1) translate([37,48,2.8]) linear_extrude(height=0.4) text("Hackaday",size=10);
colorpart(1) translate([3,18,2.8]) linear_extrude(height=0.4) text("Al Williams",size=14);
colorpart(1) translate([25,2,2.8]) linear_extrude(height=0.4) text("WD5GNR",size=8);
Once it looks good in preview, you just change current_color to 0, export, then change it to 1 and export again to a different file name. Then you simply import both into your slicer. The Slic3r clones, like Orca, will prompt you when you load multiple files if you want them to be a single part. The answer, of course, is yes.
The only downside is that the slicer won’t know which part goes with which filament spool. So you’ll still have to pick each part and assign an extruder. In Orca, you flip from Global view to Objects view. Then you can pick each file and assign the right filament slot number. If you put the number of the color in each file name, you’ll have an easier time of it. Unlike the development version, you’ll only have to set each filament color once. All the white parts will lump together, for example.
Of course, too, the slicer preview will show you the colors, so if it doesn’t look right, go back and fix it before you print. I decided it might be confusing if too many people printed name tags, so here’s a more general-purpose example:
colors=[ "black", "white", "blue","black"];
current_color=-1;
include <colorstl.scad>
$fn=128;
radius=25; // radius of coin
thick=3; // thickness of coin base
topdeck=thick-0.1;
ring_margin=0.5;
ring_thick=0.5;
feature_height=0.8;
inner_ring_outer_margin=radius-ring_margin;
inner_ring_inner_margin=inner_ring_outer_margin-ring_thick;
module center2d(size) {
translate([-size[0]/2, -size[1]/2]) children();
}
colorpart(0) cylinder(r=radius,h=thick); // the coin base
// outer ring
colorpart(1) translate([0,0,topdeck]) difference() {
cylinder(r=inner_ring_outer_margin,h=feature_height);
translate([0,0,-feature_height]) cylinder(r=inner_ring_inner_margin,h=feature_height*3);
}
// the wrencher (may have to adjust scale depending on where you got your SVG)
colorpart(1) translate([0,0,topdeck]) scale([.3,.3,1]) linear_extrude(height=feature_height,center=true) center2d([118, 108]) import("wrencher2.svg");
How did it come out? Judge for yourself. Or find me at Supercon, and unless I forget it, I’ll have a few to hand out. Or, make your own and we’ll trade.


Siamo tutti nel Truman Show! Lezioni di cybersecurity dalla cyber-prigione di Seahaven
Il film del 1998 “The Truman Show” è una terrificante premonizione dei pericoli della sorveglianza pervasiva, della manipolazione algoritmica e dell’erosione del consenso, in un contesto moderno di interconnessione digitale. È un’allegoria filosofica sulla caverna di Platone.
La vita di Truman Burbank è un caso studio di “cyber-prigione” perfetta. Trasportando la metafora di Seahaven nel dominio della sicurezza informatica, identifichiamo le tecniche di controllo di Christof (l’architetto dello show) come paradigmi di attacchi avanzati e persistenti (APT) e di ingegneria sociale.
La mente come prima linea di difesa violata
Truman Burbank vive la sua intera esistenza come la star involontaria di uno show globale. Seahaven non è una città, ma una rete isolata e attentamente monitorata: un vero e proprio honeypot psicologico in cui l’obiettivo è studiare e intrattenere tramite il comportamento di un singolo soggetto.
Il nesso fondamentale con la cybersecurity risiede nella violazione del consenso. Truman non ha mai dato il permesso di essere osservato, eppure la sua intera vita è monetizzata. Questo rispecchia l’attuale economia della sorveglianza, dove i nostri dati e le nostre interazioni digitali sono costantemente tracciate, analizzate e vendute senza una piena comprensione o un reale consenso informato.
Accettare i termini e le condizioni di un servizio è la nostra involontaria sottomissione allo show. Siamo tutti Truman digitali, e le nostre timeline sono i set di Seahaven, costantemente ripresi e analizzati.
Manipolare la realtà e installare firewall emotivi
Il successo del “Truman Show” è dovuto alla capacità di Christof di manipolare la percezione della realtà del suo soggetto e di instillare paure limitanti che agiscono come meccanismi di sicurezza passivi.
Un trauma infantile di Truman: la finta morte in mare del padre viene sfruttato per instillare una profonda paura del mare. Questa fobia non è casuale: è il firewall emotivo di Christof, il meccanismo che impedisce a Truman di lasciare l’isola. Quando Truman inizia a notare le incongruenze, gli attori intorno a lui usano il gaslighting.(tecnica di violenza psicologica e manipolazione insidiosa) In particolare, sminuiscono le sue osservazioni o insinuano sottilmente che lui sia pazzo.
Questo è l’equivalente digitale di un attacco di integrità e autenticità al nostro senso di sé online.Le campagne di disinformazione non attaccano il nostro sistema con un malware, ma la nostra percezione della realtà. Il gaslighting digitale mira a farci dubitare delle nostre fonti, della nostra memoria e, in ultima analisi, della nostra capacità di distinguere il vero dal falso, disattivando il nostro pensiero critico.
L’archetipo dell’Advanced Persistent Threat (APT)
Christof, il regista-dio, rappresenta l’archetipo dell’attaccante sofisticato e motivato non solo dal guadagno, ma dal controllo assoluto. Christof non vede Truman come una persona, ma come una variabile da controllare. Gli attaccanti informatici spesso adottano una mentalità simile, vedendo le loro vittime come semplici “ID” o “endpoint” senza considerare l’impatto umano e psicologico.
Il fatto che Christof abbia aspettato 30 anni per il suo show riflette la pazienza e la persistenza richieste dagli attacchi di cyber-crime. L’attacco non è un evento isolato, ma spesso è un progetto di lungo termine.
L’inganno umano
L’APT di Seahaven sfrutta il vettore di attacco umano in modo chirurgico, con la fiducia che è la più grande vulnerabilità. La moglie di Truman, Meryl, è l’esempio perfetto dell’attacco da insider: è la persona in cui ripone la massima fiducia. Gli attacchi più pericolosi non arrivano da sconosciuti, ma da account compromessi o da identità digitali vicine all’utente.
La nostra guardia è abbassata quando il mittente è la persona amata o un conoscente. Il Truman Show è infine una forma primitiva di deepfake emotivo. Il mondo che Truman vede è una simulazione emotivamente calibrata per mantenerlo calmo. Oggi, l’uso di AI generativa per creare voci e video iper-realistici sta rendendo quasi impossibile distinguere una richiesta autentica da una falsificazione.
Conclusione
La fuga di Truman non è un exploit tecnico, ma un atto di sovranità personale. È la storia di un uomo che, di fronte alla realtà che il mondo che gli era stato dato era falso, ha scelto il mondo autentico e sconosciuto. Questa è la lezione che dobbiamo applicare alla nostra vita digitale.
Il nostro ruolo come “Truman” richiede un cambio di mentalità: da utente passivo a difensore attivo della nostra sfera digitale. La nostra “barca” è composta da strumenti concreti e abitudini. Iniziamo con l’installare la nostra infrastruttura di resilienza e di igiene digitale.
La vera libertà digitale non è la mancanza di rischio, ma la scelta consapevole del rischio, che richiede una fusione di hard skill tecniche e soft skill psicologiche.
Coach’s Corner
- Quanto siamo disposti a sacrificare la nostra privacy per la comodità? (Il trade-off fondamentale: la convenienza di Seahaven in cambio della libertà)
- Chi è la nostra “Meryl digitale” in questo momento? (Quale persona, app o servizio di cui ci fidiamo detiene il massimo controllo sulla nostra identità o sui nostri dati, rendendoci vulnerabili a un attacco insider?)
- Quale strumento di sicurezza o abitudine digitale sarebbe la prima cosa che possiamo installare? (Qual è l’azione più essenziale per noi, in questo momento, se dovessimo scegliere la nostra ‘barca’ per fuggire da Seahaven?)
- Qual è l’unica (e non negoziabile) azione che possiamo attivare, da domani, per elevare le nostre difese dal livello utente passivo a difensore attivo? (Costruendo la nostra personale barca per la fuga da Seahaven?)
L'articolo Siamo tutti nel Truman Show! Lezioni di cybersecurity dalla cyber-prigione di Seahaven proviene da il blog della sicurezza informatica.
L’allineamento dell’intelligenza artificiale: Dove un’AI impara cosa è giusto o sbagliato?
L’altro giorno su LinkedIn mi sono ritrovato a discutere con una persona che si interessava seriamente al tema dell’intelligenza artificiale applicata al diritto. Non era una di quelle conversazioni da bar con buzzword e panico da Skynet: era un confronto vero, con dubbi legittimi.
E in effetti, in Italia, tra titoli sensazionalisti e articoli scritti da chi confonde ChatGPT con HAL 9000, non c’è da stupirsi se regna la confusione.
Il punto che aveva colpito il mio interlocutore era quello dell’allineamento.
“Ma dove impara, un’AI, cosa è giusto e cosa è sbagliato?”
Domanda semplice, ma che apre una voragine. Perché sì, l’AI sembra parlare con sicurezza, ragionare, perfino argomentare – ma in realtà non sa nulla. E capire cosa vuol dire “insegnarle” il giusto o lo sbagliato è il primo passo per non finire a parlarne come se fosse un’entità morale.
Da quella conversazione è nato questo articolo: per provare a spiegare, in modo chiaro e senza troppe formule, cosa significa davvero “allineare” un modello e perché la questione non è solo tecnica, ma inevitabilmente umanistica.
Non sono menti: sono approssimtatori
Va detto subito con chiarezza: un modello linguistico non è una mente morale.
Non ha coscienza, non valuta intenzioni, non possiede intuizioni etiche. Funziona su basi statistiche: analizza enormi collezioni di testi e calcola quali sequenze di parole sono più probabili in un dato contesto.
Questo non significa banalizzare le sue capacità. LLM moderni collegano informazioni su scale che a un singolo lettore richiederebbero settimane di ricerca; possono mettere in relazione fonti lontane e restituire sintesi sorprendenti. Tuttavia, quella che appare come “comprensione” è il risultato di correlazioni e pattern riconosciuti nei dati, non di un processo di giudizio consapevole.
Un esempio utile: un giurista o un filologo che esamina un corpus capisce le sfumature di un termine in base al contesto storicoculturale. Un LLM, analogamente, riconosce il contesto sulla base della frequenza e della co-occorrenza delle parole. Se nei testi prevalgono stereotipi o errori, il modello li riproduce come probabilità maggiori. Per questo parlare di “intelligenza” in senso antropomorfo è fuorviante: esiste una furbizia emergente, efficace sul piano pratico, ma priva di una bussola normativa intrinseca.
L’importante per chi viene da studi umanistici è cogliere questa distinzione: il modello è uno strumento potente per l’analisi e l’aggregazione di informazioni, non un depositario di verità etiche. Capire come funziona la sua meccanica statistica è il primo passo per usarlo con giudizio.
L’allineamento: chi decide cosa è giusto
Quando si parla di “allineamento” in ambito AI, si entra in un territorio che, paradossalmente, è più filosofico che tecnico.
L’allineamento è il processo con cui si tenta di far coincidere il comportamento di un modello con i valori e le regole che consideriamo accettabili. Non riguarda la conoscenza dei dati, ma la regolazione delle risposte. È, in sostanza, una forma di educazione artificiale: non si aggiunge informazione, si corregge il modo in cui viene espressa.
Per capirlo, si può pensare all’addestramento di un cane.
Il cane apprende non perché comprende le ragioni etiche del comando “seduto”, ma perché associa il comportamento corretto a una ricompensa e quello sbagliato a una mancanza di premio (o a una correzione).
Allo stesso modo, un modello linguistico non sviluppa un senso del bene o del male: risponde a un sistema di rinforzi. Se una risposta viene approvata da un istruttore umano, quella direzione viene rafforzata; se viene segnalata come inappropriata, il modello ne riduce la probabilità.
È un addestramento comportamentale su larga scala, ma senza coscienza, intenzione o comprensione morale.
E qui emerge la domanda cruciale: chi decide quali comportamenti “premiare”?
Chi stabilisce che una risposta è giusta e un’altra sbagliata?
La risposta, inevitabilmente, è che a farlo sono esseri umani – programmatori, ricercatori, annotatori – ciascuno con la propria visione del mondo, i propri limiti e i propri bias.
Di conseguenza, ogni modello riflette l’insieme delle scelte di chi lo ha educato, come un cane che si comporta in modo diverso a seconda del padrone.
In questo senso, l’allineamento non è un atto tecnico ma un gesto culturale: incorpora valori, convinzioni e pregiudizi. E anche se dietro ci sono algoritmi e dataset, ciò che definisce la linea di confine tra “accettabile” e “non accettabile” resta, in ultima istanza, una decisione umana.
Il caso del diritto
Se l’allineamento è già complesso in contesti generici, nel campo del diritto diventa quasi paradossale.
Il diritto, per sua natura, non è un insieme statico di regole, ma un linguaggio vivo, stratificato, soggetto a interpretazione continua. Ogni norma è il risultato di compromessi storici, morali e sociali; ogni sentenza è un atto di equilibrio tra principi in tensione.
Un modello di intelligenza artificiale, al contrario, cerca coerenza, simmetria, pattern. E quando incontra la contraddizione – che nel diritto è parte strutturale del discorso – tende a confondersi.
Immaginiamo di addestrare un modello su migliaia di sentenze. Potrà imparare lo stile, la terminologia, persino il modo in cui i giudici argomentano. Ma non potrà mai cogliere il nucleo umano della decisione: il peso del contesto, la valutazione dell’intenzione, la percezione della giustizia oltre la lettera della legge.
Un modello può classificare, sintetizzare, correlare. Ma non può “capire” cosa significhi essere equi, o quando una regola vada piegata per non tradire il suo spirito.
In questo senso, l’applicazione dell’AI al diritto rischia di rivelare più i nostri automatismi mentali che non la capacità della macchina di ragionare. Se la giustizia è un atto interpretativo, allora l’intelligenza artificiale – che opera per pattern – è, per definizione, un cattivo giurista.
Può aiutare, sì: come un assistente che ordina documenti, segnala precedenti, suggerisce formulazioni. Ma non potrà mai essere giudice, perché il giudizio non è una formula: è un atto umano, inevitabilmente umanistico.
Il rischio dell’allineamento culturale
Ogni volta che un’intelligenza artificiale viene “addestrata” a comportarsi in modo socialmente accettabile, stiamo, di fatto, traducendo una visione del mondo in regole di comportamento.
Il problema non è tanto tecnico quanto culturale: chi definisce cosa sia “accettabile”?
In teoria, l’obiettivo è evitare contenuti violenti, discriminatori, ingannevoli. In pratica, però, le decisioni su ciò che un modello può o non può dire vengono prese all’interno di un contesto politico e valoriale ben preciso – spesso anglosassone, progressista, e calibrato su sensibilità molto diverse da quelle europee o italiane.
Il risultato è che l’allineamento tende a uniformare il discorso.
Non perché esista una censura diretta, ma perché le IA imparano a evitare tutto ciò che potrebbe “disturbare”.
E quando la priorità diventa non offendere nessuno, si finisce per produrre un linguaggio sterile, neutro, incapace di affrontare la complessità morale del reale.
Una macchina che “non sbaglia mai” è anche una macchina che non osa, non problematizza, non mette in dubbio.
Questo ha implicazioni profonde.
Un modello linguistico fortemente allineato riflette la cultura di chi lo ha addestrato – e se quella cultura domina l’infrastruttura tecnologica globale, rischia di diventare la lente unica attraverso cui filtriamo il sapere.
In un certo senso, l’allineamento diventa il nuovo colonialismo culturale: invisibile, benintenzionato, ma altrettanto efficace.
Si finisce per credere che l’AI sia neutra proprio nel momento in cui è più condizionata.
Ecco perché discutere di allineamento non significa solo parlare di algoritmi o dati, ma di potere.
Di chi lo esercita, di come lo maschera, e di quanto siamo disposti a delegare la definizione del “giusto” a un sistema che, per sua natura, non comprende ciò che fa – ma lo ripete con una precisione disarmante.
Conclusione: lo specchio del sapere, distorto dal presente
Un modello linguistico di grandi dimensioni non è solo una macchina che parla: è il distillato di secoli di linguaggio umano. Dentro i suoi parametri ci sono libri, articoli, sentenze, discussioni, commenti, echi di pensieri nati in epoche lontane e spesso incompatibili tra loro.
Ogni volta che un LLM formula una risposta, mette in dialogo – senza saperlo – Platone e Reddit, Kant e un thread su Stack Overflow. È una compressione brutale del sapere collettivo, costretto a convivere nello stesso spazio matematico.
Ma qui entra in gioco la parte più inquietante: questo archivio di voci, culture e sensibilità non parla liberamente.
Viene “allineato” a una visione moderna del mondo – quella del momento in cui il modello viene addestrato – che riflette la sensibilità politica, morale e culturale dell’epoca. Ciò che oggi è considerato accettabile o “eticamente corretto” viene imposto come filtro sull’intero corpo del sapere.
Il risultato è che una macchina nata per rappresentare la complessità del pensiero umano finisce per rispecchiare solo la parte di esso che il presente ritiene tollerabile.
Questo processo, per quanto benintenzionato, ha un effetto collaterale profondo:trasforma l’AI in un dispositivo di riscrittura del passato.
Ciò che ieri era conoscenza, oggi può diventare bias; ciò che oggi chiamiamo progresso, domani potrà essere visto come censura. E ogni nuova generazione di modelli cancella, corregge o attenua la voce delle precedenti, filtrando la memoria collettiva con il metro mutevole del “giusto contemporaneo”.
Così, mentre crediamo di dialogare con l’intelligenza artificiale, stiamo in realtà conversando con un frammento della nostra stessa cultura, rieducato ogni due anni a parlare come se il mondo iniziasse oggi.
E questa, forse, è la lezione più importante: non temere che le macchine imparino a pensare come noi, ma che noi si finisca per pensare come loro – lineari, prevedibili, calibrati sull’adesso.
L’AI, dopotutto, non è il futuro: è il presente che si auto-interpreta.
E il vero compito dell’essere umano resta lo stesso di sempre – ricordare, discernere e dubitare, perché solo il dubbio è davvero in grado di superare il tempo.
L'articolo L’allineamento dell’intelligenza artificiale: Dove un’AI impara cosa è giusto o sbagliato? proviene da il blog della sicurezza informatica.
Microsoft Patch Tuesday col botto! 175 bug corretti e due zero-day sfruttati
Nel suo ultimo aggiornamento, il colosso della tecnologia ha risolto 175 vulnerabilità che interessano i suoi prodotti principali e i sistemi sottostanti, tra cui due vulnerabilità zero-dayattivamente sfruttate, ha affermato l’azienda nel suo ultimo aggiornamento di sicurezza. Si tratta del più ampio assortimento di bug divulgato dal colosso della tecnologia quest’anno.
Le vulnerabilità zero-day, CVE-2025-24990 colpisce Agere Windows Modem Driver e il CVE-2025-59230 che colpisce Windows Remote Access Connection Manager, hanno entrambe un punteggio CVSS di 7,8.
La Cybersecurity and Infrastructure Security Agency (CISA) ha aggiunto entrambe le vulnerabilità zero-day al suo catalogo KEV delle vulnerabilità note questo martedì.
Microsoft ha affermato che l‘unità modem Agere di terze parti, fornita con i sistemi operativi Windows supportati, è stata rimossa nell’aggiornamento di sicurezza di ottobre. L’hardware del modem fax che si basa su questo driver non funzionerà più su Windows, ha affermato l’azienda.
Gli aggressori possono ottenere privilegi di amministratore sfruttando CVE-2025-24990. “Tutte le versioni supportate di Windows possono essere interessate da uno sfruttamento riuscito di questa vulnerabilità, anche se il modem non è in uso”, ha affermato Microsoft nel suo riepilogo del bug.
Microsoft ha affermato che la vulnerabilità del controllo di accesso improprio che colpisce Windows Remote Access Connection Manager può essere sfruttata da un aggressore autorizzato per elevare i privilegi a livello locale e ottenere privilegi di sistema.
Windows Remote Access Connection Manager, un servizio utilizzato per gestire le connessioni di rete remote tramite reti private virtuali e reti dial-up, è “frequent flyer del Patch Tuesday, comparendo più di 20 volte da gennaio 2022”, ha affermato in un’e-mail Satnam Narang, Senior Staff Research Engineer di Tenable. “Questa è la prima volta che lo vediamo sfruttato il bug come zero-day”.
Le vulnerabilità più gravi rivelate questo mese includono il CVE-2025-55315, che colpisce ASP.NET Core, e il CVE-2025-49708, che colpisce il componente grafico Microsoft. Microsoft ha affermato che lo sfruttamento di queste vulnerabilità è meno probabile, ma entrambe hanno un punteggio CVSS di 9,9.
Microsoft ha segnalato 14 difetti come più probabili da sfruttare questo mese, tra cui un paio di vulnerabilità critiche con valutazione CVSS di 9,8: CVE-2025-59246 che interessa Azure Entra ID e CVE-2025-59287 che interessa Windows Server Update Service.
Questo mese, il fornitore ha rivelato cinque vulnerabilità critiche e 121 vulnerabilità di gravità elevata. L’elenco completo delle vulnerabilità risolte questo mese è disponibile nel Security Response Center di Microsoft .
L'articolo Microsoft Patch Tuesday col botto! 175 bug corretti e due zero-day sfruttati proviene da il blog della sicurezza informatica.
Microsoft avverte sull’uso incontrollato dell’intelligenza artificiale ‘ombra’ sul lavoro
Mentre Microsoft promuove attivamente i suoi strumenti Copilot per le aziende, l’azienda mette anche in guardia dai pericoli dell’uso incontrollato dell’intelligenza artificiale “ombra” da parte dei dipendenti.
Un nuovo rapporto lancia l’allarme sulla rapida crescita della cosiddetta “intelligenza artificiale ombra”, ovvero casi in cui i dipendenti utilizzano reti neurali e bot di terze parti nel loro lavoro, senza l’approvazione del reparto IT dell’azienda.
Secondo Microsoft, il 71% degli intervistati nel Regno Unito ha ammesso di utilizzare servizi di intelligenza artificiale per uso privato sul lavoro senza che gli amministratori di sistema ne fossero a conoscenza. Inoltre, più della metà continua a farlo regolarmente.
Questa pratica copre un’ampia gamma di attività: quasi la metà dei dipendenti utilizza l’intelligenza artificiale non autorizzata per la corrispondenza aziendale, il 40% per la preparazione di presentazioni e report e uno su cinque per le transazioni finanziarie. Ciò conferma precedenti ricerche che dimostrano come ChatGPT rimanga uno degli strumenti più diffusi per tali scopi.
Nonostante queste preoccupazioni, Microsoft sta contemporaneamente incoraggiando il concetto di BYOC (Bring Your Own Copilot). Se un dipendente ha un abbonamento personale a Microsoft 365 con accesso a un assistente AI, è incoraggiato a utilizzarlo in ufficio, anche se la dirigenza aziendale non ha ancora implementato tali tecnologie.
Gli autori del rapporto indicano che solo il 32% degli intervistati è realmente preoccupato per le fughe di informazioni riservate di clienti e aziende. Inoltre, solo il 29% è consapevole delle potenziali minacce alla sicurezza IT. La motivazione più comune per l’utilizzo di intelligenza artificiale di terze parti è una semplice abitudine: il 41% degli intervistati ha ammesso di utilizzare gli stessi strumenti al lavoro e a casa.
Nonostante i continui sforzi di Microsoft per promuovere Copilot, la realtà rimane sfavorevole per il marchio. ChatGPT continua a essere leader nel segmento enterprise, mentre Copilot stesso non ha ancora dimostrato un’adozione diffusa. Di conseguenza, l’azienda legittima la pratica dell’intelligenza artificiale ombra, se riesce a incoraggiare i dipendenti a utilizzare le sue soluzioni proprietarie.
In conclusione del rapporto, Microsoft sottolinea che l’implementazione incontrollata dell’intelligenza artificiale può comportare gravi rischi quando si tratta di soluzioni non originariamente progettate per ambienti aziendali. L’azienda insiste sul fatto che solo sistemi professionali, adattati alle esigenze aziendali, possono fornire il livello di sicurezza e stabilità necessario.
L'articolo Microsoft avverte sull’uso incontrollato dell’intelligenza artificiale ‘ombra’ sul lavoro proviene da il blog della sicurezza informatica.