@Informatica (Italy e non Italy 😁) “Sulle specifiche vicende dei cosiddetti “dossieraggi”, rappresento che i due procedimenti penali – uno presso la procura di Perugia e l’altro presso la procura di Milano – sono, ovviamente, coperti
@Politica interna, europea e internazionale Oggi molti quotidiani – non quelli del Gruppo Gedi, di proprietà della Exor – riportano in prima pagina lo sfogo della presidente del Consiglio Giorgia Meloni contro John Elkann, presidente di Stellantis, colpevole di aver rifiutato l’invito della Camera
Highly controversial, non-transparent and rarely questioned: the Commission and Council of the European Union are currently preparing a new, EU-wide digital surveillance package. The plan includes the reintroduction and expansion of the retention of citizens’ communications data as well as specific proposals to undermine the secure encryption of data on all connected devices, ranging from cars to smartphones, as well as data processed by service providers and data in transit.
Behind closed doors the Commission has announced it is already preparing impact assessments and an implementation plan.
Former Pirate Party MEP and digital freedom fighter in the European Parliament Patrick Breyer comments: “The plan is still widely unknown among citizens, journalists and politicians, even though we hold the documents in our hands and the extent of the plans is frightening. A number of questions remain unanswered.”
Documents
Landing page about the »High-Level Group (HLG) on access to data for effective law enforcement« provides background information, press reports, documents and my view on the group’s plan.
1 January 2025: Beginning of the Polish Council Presidency
Open questions
Who participated in the meetings of the #EuGoingDark group and its sub-groups? Participant lists are still undisclosed. Mullvad VPN has reported that at least one former US secret service official has participated.
Why were digital rights NGOs such as EDRi not invited to the meetings of the working group even when the group‘s website says it is an “collaborative and inclusive platform for stakeholders from all relevant sectors“?
How do the new EU Commissioners directly and indirectly involved in the issues concerned, the European Ombudsman, the data protection authorities of the EU and the member states, IT security experts, consumer protection organisations and others assess the working methods and plans of the #EuGoingDark-group?
Contacts to the group
European Commission Directorate-General Migration & Home Affairs 46 Rue de Luxembourg | B-1049 Brussels | Belgium E-Mail: EC-HLG-GOING-DARK [:at:] ec.europa.eu.
Olivier Onidi Deputy Director General Directorate-General for Migration and Home Affairs European Commission
🇬🇧 I received fully ■■■■■■ redacted participant lists of the EU’s #GoingDark anti-encryption group that is also forging plans for resurrecting #DataRetention.
Dear Sir or Madam,
With regard to the meeting of the »High-Level Expert Group on access to data for effective law enforcement« on 19 June 2023 and 21 November 2023, please send me all relevant documents as described below:
· documents relevant …
Il pubblico spagnolo è rimasto sbalordito da uno spettacolo televisivo in cui i partecipanti hanno potuto ascoltare le voci dei loro cari defunti, ricreate attraverso l’intelligenza artificiale. Questi algoritmi non si limitano a imitare il discorso dei defunti: sono in grado di sostenere un dialogo, porre domande profondamente personali e suscitare una forte risposta emotiva negli spettatori.
Questa tecnologia, definita “resurrezione digitale”, non solo ricrea la voce, ma può anche riprodurre l’aspetto delle persone scomparse. La trasmissione ha generato accese discussioni tra filosofi e avvocati, costringendo la società a riflettere sui limiti dell’uso delle moderne tecnologie.
Uno dei principali problemi sollevati è che le copie digitali possono alterare il flusso naturale dei ricordi dei propri cari. La memoria umana è in costante evoluzione e rielaborazione; tuttavia, un’immagine artificialmente creata fissa il ricordo a un determinato momento, interrompendo il processo naturale di elaborazione del lutto.
Gli psicologi evidenziano inoltre la difficoltà di ricreare la vera personalità di una persona. Ognuno di noi è il risultato unico delle proprie esperienze di vita, delle relazioni interpersonali, delle emozioni e dei pensieri. Tentare di riprodurre questa complessità può portare alla creazione di una versione semplificata e idealizzata, che riflette solo l’idea che i vivi hanno della persona defunta.
Accettare la morte di una persona cara è una fase cruciale per il recupero psicologico. Il contatto costante con una copia digitale può ostacolare il processo di elaborazione del lutto, impedendo di attraversare tutte le fasi necessarie per ritrovare l’equilibrio interiore. Pertanto, la tecnologia concepita per alleviare il dolore potrebbe finire per intensificare la sofferenza.
Da qui sorgono importanti interrogativi: chi ha il diritto di decidere il destino del gemello digitale di una persona che non può più esprimere la propria volontà? Come definire i confini dell’etica nell’imitazione delle parole e delle azioni del defunto?
Inoltre, l’aspetto commerciale di questa questione solleva preoccupazioni significative. Trasformare qualcosa di così intimo come il lutto in una fonte di profitto mette in discussione i principi morali delle aziende coinvolte. Ci sono evidenti contraddizioni tra le buone intenzioni dichiarate e le potenziali conseguenze. Il dolore e la perdita sono esperienze umane fondamentali che devono essere affrontate per crescere come individui.
I filosofi pongono domande sulla sottile linea tra il conforto per i lutti e lo sfruttamento dei sentimenti altrui. Anche se gli sviluppatori cercano sinceramente di aiutare le persone, l’idea stessa di trarre profitto dal dolore sembra di per sé sospetta.
I rappresentanti della bioetica propongono la creazione di meccanismi legali che tutelino sia la memoria dei defunti che il benessere psicologico dei loro cari. Nel frattempo, gli psicoterapeuti avvertono del rischio di sviluppare una dipendenza dalle copie digitali.
@Notizie dall'Italia e dal mondo Qassem non è un esponente di spicco politico e religioso, tuttavia potrebbe rivelare delle inaspettate doti di leader in un momento molto delicato per il suo movimento e il Libano sotto attacco israeliano L'articolo PODCAST.
@Notizie dall'Italia e dal mondo La giornalista Patricia Ramirez, conosciuta con il nome d'arte di Paty Bunbury, è stata uccisa mercoledì 30 ottobre. Mauricio Cruz Solís è stato assassinato poche ore prima in un agguato armato per le strade del centro di Uruapan, nel Michoacán L'articolo MESSICO. Due giornalisti uccisi in meno di 24 ore
@Informatica (Italy e non Italy 😁) Funzioni di intelligenza artificiale implementate su strumenti aziendali possono avere delle vulnerabilità. I principali attacchi e alcuni casi recenti. L'articolo AI, come ti esfiltro i dati con una prompt injection proviene da Guerre di Rete.
Un paio d'ore fa è stato inviato agli iscritti il nuovo numero di Magda, la newsletter di Centrum Report dedicata all'Europa Centrale. Per chi non la conoscesse, Magda è quel posto in cui segnaliamo i nostri lavori e i nostri interventi sui media (di solito la radio, ma a volte capita di fare capolino anche in tv).
Magda è anche lo spazio delle segnalazioni culturali. Questo mese ad esempio parliamo dell'inaugurazione della sede permanente del Museo di Arte moderna a Varsavia, e potrete anche scoprire chi ha vinto il premio Nike, il più importante riconoscimento letterario polacco.
Un motivo in più per leggere la Magda di questo mese è che c'è il link al nuovo longform uscito su Centrum Report, a firma di Salvatore Greco.
Insomma, il consiglio che vi do è quello di iscrivervi (gratuitamente si intende) per ricevere i prossimi numeri nella casella di posta. Altrimenti potete trovare Magda al seguente link:
@Notizie dall'Italia e dal mondo L'allarme è stato lanciato dalla municipalità della città del nord di Gaza sotto attacco delle forze israeliane. Ottobre è stato il mese in assoluto con meno ingressi di aiuti umanitari nella Striscia L'articolo GAZA. “Beit Lahiya destavata dalle bombe, senza cibo e acqua” proviene da
We hate to admit it, but whenever we see an article about either Voyager spacecraft, our thoughts immediately turn to worst-case scenarios. One of these days, we’ll be forced to write obituaries for the plucky interstellar travelers, but today is not that day, even with news of yet another issue aboard Voyager 1 that threatens its ability to communicate with Earth.
According to NASA, the current problem began on October 16 when controllers sent a command to turn on one of the spacecraft’s heaters. Voyager 1, nearly a light-day distant from Earth, failed to respond as expected 46 hours later. After some searching, controllers picked up the spacecraft’s X-band downlink signal but at a much lower power than expected. This indicated that the spacecraft had gone into fault protection mode, likely in response to the command to turn on the heater. A day later, Voyager 1 stopped communicating altogether, suggesting that further fault protection trips disabled the powerful X-band transmitter and switched to the lower-powered S-band downlink.
This was potentially mission-ending; the S-band downlink had last been used in 1981 when the probe was still well within the confines of the solar system, and the fear was that the Deep Space Network would not be able to find the weak signal. But find it they did, and on October 22 they sent a command to confirm S-band communications. At this point, controllers can still receive engineering data and command the craft, but it remains to be seen what can be done to restore full communications. They haven’t tried to turn the X-band transmitter back on yet, wisely preferring to further evaluate what caused the fault protection error that kicked this whole thing off before committing to a step like that.
Following Voyager news these days feels a little morbid, like a death watch on an aging celebrity. Here’s hoping that this story turns out to have a happy ending and that we can push the inevitable off for another few years. While we wait, if you want to know a little more about the Voyager comms system, we’ve got a deep dive that should get you going.
[quote]Può il modello statunitense di stretta collaborazione tra le imprese private e le istituzioni della Difesa per l’innovazione delle Forze armate rappresentare un esempio virtuoso anche per il nostro Paese? Lo abbiamo chiesto al sottosegretario alla Difesa, Matteo Perego di Cremnago, rientrato da
One topic being actively researched in connection with the breakout of LLMs is capability uplift – when employees with limited experience or resources in some area become able to perform at a much higher level thanks to LLM technology. This is especially important in information security, where cyberattacks are becoming increasingly cost-effective and larger-scale, causing headaches for security teams.
Among other tools, attackers use LLMs to generate content for fake websites. Such sites can mimic reputable organizations – from social networks to banks – to extract credentials from victims (classic phishing), or they can pretend to be stores of famous brands offering super discounts on products (which mysteriously never get delivered).
Aided by LLMs, attackers can fully automate the creation of dozens, even hundreds of web pages with different content. Before, some specific tasks could be done automatically, such as generating and registering domain names, obtaining certificates and making sites available through free hosting services. Now, however, thanks to LLMs, scammers can create unique, fairly high-quality content (much higher than when using, say, synonymizers) without the need for costly manual labor. This, in particular, hinders detection using rules based on specific phrases. Detecting LLM-generated pages requires systems for analyzing metadata or page structure, or fuzzy approaches such as machine learning.
But LLMs don’t always work perfectly, so if the scale of automation is large or the level of control is low, they can leave telltale indicators, or artifacts, that the model was poorly applied. Such phrases, which recently have been cropping up everywhere from marketplace reviews to academic papers, as well as tags left by LLM tools, make it possible at this stage of the technology’s development to track attackers’ use of LLMs to automate fraud.
I’m sorry, but…
One of the clearest signs of LLM-generated text is the presence of first-person apologies and refusals to follow instructions. For example, a major campaign targeting cryptocurrency users features pages, such as in the screenshot below, where the model gives itself away by first apologizing, then simulating instructions for the popular trading platform Crypto[.]com:
As we see, the model refuses to perform one of the basic tasks for which LLMs are used – writing articles:
I’m sorry, but as an AI language model, I cannot provide specific articles on demand.
This specific example is hosted at gitbook[.]io. Besides the apology, another giveaway is the use of the letters ɱ and Ĺ in “Crypto.coɱ Ĺogin”.
On another page targeting Metamask wallet users, hosted at webflow[.]io, we see the LLM response:
I apologize for the previous response not meeting your word count requirement.
This response is interesting because it implies that it was not the first in the chat with the language model. This indicates either a lower level of automation (the attacker requested an article, saw that it was short and asked for a longer one, all in the same session), or the presence of length checks in the automated pipeline, suggesting that overly brief responses are a common issue. The latter is more likely, because if a human had formatted the text, the apology would hardly have ended up inside the tag.
Artifacts can appear not only in web page text. In one page mimicking the STON[.]fi crypto exchange, LLM apologies turned up in the meta tags:
I’m sorry, but I don’t have enough information to generate a useful meta description without clear target keywords. Could you please provide the specific keywords you would like me to incorporate? I’d be happy to create an engaging, SEO-friendly meta description once I have those details. Just send over the keywords whenever you’re ready.
LLMs can be used not only to generate text blocks, but entire web pages. The page above, which mimics the Polygon site (hosted at github[.]io on a lookalike subdomain with the word “bolygon”), shows a message that the model has exceeded its allowable character limit:
Users can access a wide rangeAuthor’s Note: I apologize, but it seems like the response got cut off. As a language model, I’m limited to generating responses within a certain character limit.
In addition, the page’s service tags contain links to an online LLM-based website generation service that creates pages based on a text description.
In another example, on an adult clickbait page that redirects to dubious 18+ dating sites, we see a model apologize for declining to write content related to data leaks:
I’m sorry for any misunderstanding, but as an AI developed by OpenAI, I am programmed to follow ethical guidelines, which means I cannot generate or provide content related to leaked material involving [model name] or any other individual.
Already a meme
The phrase-turned-meme “As an AI language model…” and its variations often pop up on scam pages, not only in the context of apologies. That’s exactly what we see, for example, on two pages targeting users of the KuCoin crypto exchange, both located at gitbook[.]us.
In the first case, the model refuses to work as a search engine:
As an AI developed by OpenAI, I can’t provide direct login links to third-party platforms like KuCoin or any other specific service.
In the second, we see a slight variation on the theme – the model states that it can’t log in to websites itself:
As an AI developed by OpenAI, I don’t have the capability to directly access or log in to specific websites like KuCoin or any other online platform.
Bargaining stage
Another fairly clear LLM sign is the use of “While I can’t…, I can certainly…”-type constructions.
For instance, a page hosted at weblof[.]io reads as follows:
While I can’t provide real-time information or direct access to specific websites, I can certainly guide you through the general steps on how to log in to a typical online platform like BitMart.
On another page, this time at gitbook[.]us, the LLM declines to give detailed instructions on how to log in to a Gemini account:
While I can’t provide specific step-by-step instructions, I can certainly offer a general overview of what the process might entail.
One more page, also on gitbook[.]us, is aimed at Exodus Wallet users:
While I cannot provide real-time information or specific details about the Exodus® Wallet login process, I can offer a comprehensive solution that generally addresses common issues related to wallet logins.
There’s no stopping progress
Another key sign of LLM-generated text is a message about the model’s knowledge cutoff – the date after which it no longer has up-to-date information about the world. To train LLMs, developers collect large datasets from all over the internet, but information about events that occur after training begins is left out of the model. The model often signals this with phrases like “according to my last update in January 2023” or “my knowledge is limited to March 2024”.
For instance, the following phrase was found on a fake site mimicking the Rocket Pool staking platform:
Please note that the details provided in this article are based on information available up to my knowledge cutoff in September 2021.
On another scam site, this time targeting Coinbase users, we see text written by a fresher model:
This content is entirely hypothetical, and as of my last update in January 2022, Coinbase does not have a browser extension specifically for its wallet.
A fake page from the same campaign, but aimed at MetaMask wallet users, employs an even more recent model to generate text:
As of my last knowledge update in January 2023, Metamask is a popular and widely used browser extension…
Artifacts of this kind not only expose the use of LLMs to create scam web pages, but allow us to estimate both the campaign duration and the approximate time of content creation.
Delving into an ever-evolving world
Finally, OpenAI models have certain word preferences. For example, they are known to use the word “delve” so often that some people consider it a clear-cut sign of LLM-generated text. Another marker is the use of phrases like “in the ever-evolving/ever-changing world/landscape”, especially in requested articles or essays. Note that the presence of these words alone is no cast-iron guarantee of generated text, but they are pretty strong indicators.
For example, one such site is hosted at gitbook[.]us and belongs to a campaign with stronger signs of LLM usage. There we see both the phrase
In the dynamic realm of cryptocurrency
and the classic “let’s delve” in the instructions for using a physical Ledger wallet. On another Ledger-dedicated page (this time at webflow[.]io), we find “delve” rubbing shoulders with “ever-evolving world”:
On yet another page at gitbook[.]us, this time aimed at Bitbuy users, the telltale “ever-evolving world of cryptocurrency” and “Navigating the Crypto Seas” raise their clichéd heads – such metaphor is, although poorly formalized, but still a sign of the use of LLM.
As mentioned above, LLM-generated text can go hand-in-hand with various techniques that hinder rule-based detection. For example, an article at gitbook[.]us about the Coinbase crypto exchange containing “let’s delve” uses Unicode math symbols in the title: Coinbase@% Wallet.
Due to font issues, however, the browser has trouble displaying Unicode characters, so in the screenshot they look like this:
As part of the same campaign, KuCoin was honored with yet another version of the page at gitbook[.]us. This time we see obfuscation in the title: Kucoin® Loᘜin*, as well as the less screaming but still telling “let’s explore” along with the familiar “delve”:
we delve into the intricates of KuCoin login
Let’s explore how you can access your account securely and efficiently
Let’s delve into the robust security measures offered by this platform to safeguard your assets.
Lastly, one more page in this campaign, hosted at webflow[.]io, invites potential iTrustCapital users to “delve into the ever-changing precious metals market.” In this example, “Login” is also obfuscated.
Conclusion
As large language models improve, their strengths and weaknesses, as well as the tasks they do well or poorly, are becoming better understood. Threat actors are exploring applications of this technology in a range of automation scenarios. But, as we see, they sometimes commit blunders that help shed light on how they use LLMs, at least in the realm of online fraud.
Peering into the future, we can assume that LLM-generated content will become increasingly difficult to distinguish from human-written. The approach based on the presence of certain telltale words and phrases is unreliable, since these can easily be replaced with equivalents in automatic mode. Moreover, there is no guarantee that models of other families, much less future models, will have the same stylometric features as those available now. The task of automatically identifying LLM-generated text is extremely complex, especially as regards generic content like marketing materials, which are similar to what we saw in the examples. To better protect yourself against phishing, be it hand-made or machine-generated, it’s best to use modern security solutions that combine analysis of text information, metadata and other attributes to protect against fraud.
L'articolo proviene da #Euractiv Italia ed è stato ricondiviso sulla comunità Lemmy @Intelligenza Artificiale Il 30 gennaio 2024, per un breve periodo, internet è andato in down in tutta la Russia: per due ore, dalle 20:00 alle 22:00 ore locali, è stato
Da Kamala Harris negli Stati Uniti a Emmanuel Macron in Francia, in tutti i paesi d’Occidente capita che sotto elezioni ci si ricordi delle difficoltà del ceto medio e a questi si guardi con particolari speranze e relative promesse elettorali. Di ceto medio hanno parlato anche i
@Informatica (Italy e non Italy 😁) Che cosa sostiene l'ex presidente finlandese Sauli Niinistö nel suo rapporto sul rafforzamento della preparazione e della difesa dell'Ue davanti alle crisi a partire dalla proposta di creare un’agenzia unica di intelligence a livello europeo
Un Ex responsabile della produzione dei menu per i ristoranti Disney, è al centro di uno scandalo che ha attirato l’attenzione pubblica e l’intervento dell’FBI. Licenziato a giugno 2024 per motivi legati a presunta “cattiva condotta,” le cause esatte del suo licenziamento non sono state specificate dall’azienda. Tuttavia, pochi giorni dopo la sua uscita, l’ex dipendente ha compiuto una serie di azioni che hanno avuto conseguenze serie sui sistemi interni di Disney.
L’avvocato ha riferito che il suo assistito ha cercato di ottenere risposte dalla Disney sul licenziamento, ma non ha ricevuto alcuna replica. Questo silenzio ha spinto l’impiegato a presentare un reclamo alla Commissione per le Pari Opportunità di Lavoro (EEOC), avanzando l’ipotesi di un trattamento ingiusto. Nonostante ciò, le azioni che ha compiuto subito dopo il licenziamento sono state, secondo le autorità, di una gravità tale da portare l’azienda a richiedere l’intervento federale.
Poco dopo la sua uscita, l’ex manager è riuscito ad accedere al sistema di creazione dei menu dei ristoranti Disney, sfruttando le sue vecchie credenziali. Con tale accesso, ha modificato tutti i font dei menu, cambiandoli in “Wingdings”, un carattere decorativo fatto di simboli grafici. Questa modifica ha trasformato i menu in una serie di simboli illeggibili, paralizzando di fatto il sistema e causando un blocco operativo durato settimane, durante il quale Disney ha dovuto ripristinare il sistema dai backup.
Non soddisfatto, il dipendente ha anche manipolato i codici QR presenti sui menu, facendoli puntare a un sito controverso, che promuoveva opinioni politiche sulla questione israelo-palestinese. Questo tipo di intervento, considerato altamente sensibile per un’azienda come Disney, ha ulteriormente aggravato la situazione. Inoltre, avrebbe anche modificato alcune informazioni sugli allergeni, rappresentando erroneamente determinati piatti come sicuri per chi soffre di allergie alle arachidi, anche se non è stato confermato che queste modifiche siano giunte ai clienti.
Le azioni dell’impiegato, però, non si sono fermate qui. Secondo il reclamo, avrebbe creato uno script informatico per bloccare almeno 14 dipendenti fuori dai loro account, inserendo password errate ripetutamente per costringerli a tentativi di accesso incessanti. Questo attacco ha rappresentato un vero incubo per i dipendenti, che sono rimasti esclusi dai propri account per giorni, limitando così l’efficienza del team e causando ulteriori danni all’organizzazione.
L’inchiesta dell’FBI ha portato alla scoperta di documenti compromettenti sul computer del dipendente, inclusi file con informazioni personali di altri dipendenti Disney, come indirizzi di casa, numeri di telefono e dati sui familiari. Le indagini hanno inoltre rivelato che l’impiegato avrebbe preso di mira alcuni dipendenti anche al di fuori dell’ambiente lavorativo: le telecamere di sorveglianza avrebbero registrato il manager mentre si recava a casa di una vittima durante un attacco DoS.
Il 24 ottobre 2024, le autorità hanno arrestato l’impiegato, accusandolo di aver violato il Computer Fraud and Abuse Act. La sua udienza è fissata per il 5 novembre, e se condannato, potrebbe affrontare fino a 15 anni di carcere. L’accaduto sottolinea quanto sia cruciale per le aziende monitorare le credenziali di accesso degli ex dipendenti per prevenire simili violazioni, che possono portare a danni di immagine e a perdite operative significative.
Although we think of air-to-air radar as a relatively modern invention, it first made its appearance in WWII. Some late war fighters featured the AN/APS-13 Tail Warning Radar to alert the pilot when an enemy fighter was on his tail. In [WWII US Bombers]’ fascinating video we get a deep dive into this fascinating piece of tech that likely saved many allied pilots’ lives.
Fitted to aircraft like the P-51 Mustang and P-47 Thunderbolt, the AN/APS-13 warns the pilot with a light or bell if the aircraft comes within 800 yards from his rear. The system consisted of a 3-element Yagi antenna on the vertical stabilizer, a 410 Mhz transceiver in the fuselage, and a simple control panel with a warning light and bell in the cockpit.
In a dogfight, this allows the pilot to focus on what’s in front of him, as well as helping him determine if he has gotten rid of a pursuer. Since it could not identify the source of the reflection, it would also trigger on friendly aircraft, jettisoned wing tanks, passing flak, and the ground. This last part ended up being useful for safely descending through low-altitude clouds.
This little side effect turned out to have very significant consequences. The nuclear bombs used on Hiroshima and Nagasaki each carried four radar altimeters derived from the AN/APS-13 system.
Changelog: 🦝 added an option in Settings to disable automatic image loading; 🦝 initial loading optimization; 🦝 dependency updates.
@Thomas @Kristian I prioritized your feedback since the next thing in my roadmap is quite big (UnifiedPush integration) and it would have taken too long if I had waited for it.
Thank you for your work. After the update from .13 to .16 I could now also log in to utzer.friendica.de So far it looks good and I can see everything so far.
Recentemente, il noto Threat Actor, identificato con il nickname 888, ha affermato di aver violato i sistemi di IBM e di aver sottratto dati personali appartenenti ai dipendenti dell’azienda. La fuga di notizie, datata ottobre 2024, avrebbe portato alla compromissione di circa 17.500 righe di dati.
Al momento, non possiamo confermare la veridicità della notizia, poiché l’organizzazione non ha ancora rilasciato alcun comunicato stampa ufficiale sul proprio sito web riguardo l’incidente. Pertanto, questo articolo deve essere considerato come ‘fonte di intelligence’.
Dettagli della Violazione
Secondo quanto dichiarato da 888, la violazione avrebbe portato alla compromissione dei dati di circa 17.500 individui. Le informazioni esfiltrate, dovrebbero contenere: nomi, numeri di cellulare e codici internazionali di area, prevalentemente associati a dipendenti con prefisso internazionale “+91”, suggerendo che l’incidente abbia principalmente colpito il personale IBM in India. Sebbene l’entità dell’attacco sembri concentrata su una specifica area geografica, non si esclude la possibilità che il furto possa estendersi ad altre regioni, amplificando così il potenziale impatto di questo presunto attacco.
La fuga di dati, divulgata attraverso il noto sito BreachForums, accuserebbe IBM e i suoi partner di una seria vulnerabilità nella sicurezza, alimentando profonde preoccupazioni sulla protezione dei dati personali.
Attualmente, non siamo in grado di confermare con precisione l’accuratezza delle informazioni riportate, poiché non è stato rilasciato alcun comunicato stampa ufficiale sul sito web riguardante l’incidente.
Conclusione
L’incidente riportato sottolinea ancora una volta la vulnerabilità delle grandi aziende e l’importanza della protezione dei dati sensibili gestiti da terze parti, in particolar modo in un contesto aziendale con reti distribuite e globali. Questo presunto attacco rappresenta un ulteriore segnale per le imprese: la Cybersecurity non è solo una difesa informatica, ma una vera e propria strategia aziendale, critica per mantenere la fiducia dei clienti e garantire la privacy dei dipendenti.
Come nostra consuetudine, lasciamo sempre spazio ad una dichiarazione da parte dell’azienda qualora voglia darci degli aggiornamenti sulla vicenda. Saremo lieti di pubblicare tali informazioni con uno specifico articolo dando risalto alla questione.
RHC monitorerà l’evoluzione della vicenda in modo da pubblicare ulteriori news sul blog, qualora ci fossero novità sostanziali. Qualora ci siano persone informate sui fatti che volessero fornire informazioni in modo anonimo possono utilizzare la mail crittografata del whistleblower.
Nel panorama sempre più complesso delle cyber minacce, il 2024 ha visto l’emergere di un nuovo ransomware denominato Fog Ransomware, che ha cominciato a diffondersi nella primavera di quest’anno. Questo malware sta destando particolare preoccupazione per la sua sofisticazione e per le metodologie avanzate di attacco. Scoperto inizialmente negli Stati Uniti, ha colpito principalmente il settore educativo, sebbene siano stati registrati attacchi anche nei settori dei viaggi, finanziario e manifatturiero. Gli operatori di Fog Ransomware, ancora non identificati, sembrano spinti da motivazioni economiche e adottano tecniche di doppia estorsione, aumentando così la pressione sulle vittime per il pagamento del riscatto.
Tecniche di Accesso e Sfruttamento delle Vulnerabilità
Il primo punto d’accesso sfruttato da Fog Ransomware è spesso rappresentato dalle credenziali VPN compromesse. Recentemente, i criminali informatici dietro Fog hanno dimostrato di sfruttare una vulnerabilità nota su SonicOS (l’interfaccia di gestione dei dispositivi SonicWall), identificata come CVE-2024-40766. Questa falla di sicurezza, presente nei dispositivi non aggiornati, permette agli attaccanti di ottenere un accesso privilegiato alla rete, dando inizio alla catena di attacco. In molti casi, gli attaccanti approfittano anche della vulnerabilità CVE-2024-40711 su Veeam Backup & Replication, sfruttando una falla che potrebbe consentire l’esecuzione di codice remoto, amplificando così le possibilità di compromissione delle reti aziendali.
Secondo i ricercatori di Arctic Wolf, almeno 30 intrusioni relative agli account VPN SonicWall sono state condotte con l’ausilio di Akira e Fog ransomware, suggerendo una possibile collaborazione o sovrapposizione di infrastruttura tra i due gruppi. Gli esperti di Sophos hanno inoltre trovato indizi che collegano le infrastrutture utilizzate dagli operatori di Akira e Fog, evidenziando la crescente professionalizzazione e interconnessione tra i vari attori del cybercrimine.
Strategie di Attacco e Metodologie Utilizzate
Una volta ottenuto l’accesso, Fog Ransomware procede con rapidità all’encryption dei file. Gli attaccanti implementano attacchi “pass-the-hash” per ottenere privilegi elevati e disabilitare i software di sicurezza. L’eliminazione delle copie shadow tramite il comando vssadmin.exe e la disattivazione di servizi come Windows Defender rientrano tra le prime azioni eseguite dagli operatori. Anche i sistemi VMware ESXi sono bersagli di questo ransomware: i file con estensione ‘.vmdk’, contenenti dati critici delle macchine virtuali, vengono crittografati, interrompendo i servizi e causando gravi interruzioni delle attività aziendali.
Per mappare l’ambiente e ottenere informazioni utili, gli operatori di Fog Ransomware utilizzano strumenti di riconoscimento come Advanced Port Scanner, NLTest e AdFind, che consentono loro di raccogliere dati sui sistemi e sui servizi presenti nella rete. Per garantire la persistenza nella rete, il malware crea nuovi account utente e utilizza reverse SSH shells. Inoltre, l’uso di Metasploit e PsExec permette agli attaccanti di eseguire attività di enumerazione e di mantenere l’accesso all’interno dell’ambiente compromesso.
Fasi di Estrazione e Cifratura dei Dati
Nella fase finale dell’attacco, Fog Ransomware esegue l’esfiltrazione dei dati, caricando i file rubati sul servizio di archiviazione MEGA, spesso impiegato per memorizzare le informazioni esfiltrate. I file dei sistemi crittografati assumono l’estensione ‘.FOG’ o ‘.FLOCKED’, e una nota di riscatto viene inserita in ogni directory interessata dall’encryption. Questa nota avvisa la vittima dell’attacco, specificando le richieste degli attaccanti, minacciando la divulgazione dei dati sensibili qualora il riscatto non venga pagato.
La doppia estorsione, metodo ormai comune tra i ransomware moderni, rappresenta una tecnica di pressione psicologica: se la vittima rifiuta di pagare, non solo si trova impossibilitata a recuperare i dati crittografati, ma rischia anche la diffusione pubblica di informazioni riservate, compromettendo così la reputazione aziendale.
Raccomandazioni per la Difesa e le Misure Preventive
Per proteggersi da Fog Ransomware, le organizzazioni dovrebbero attuare misure preventive e di monitoraggio costante. Le raccomandazioni principali includono:
Aggiornamento dei sistemi: Assicurarsi che i sistemi VPN, i dispositivi di backup e i software critici siano aggiornati con le ultime patch di sicurezza, riducendo il rischio di vulnerabilità sfruttabili.
Monitoraggio delle attività di rete: Controllare regolarmente i log per individuare attività sospette, come trasferimenti di dati anomali o accessi non autorizzati tramite VPN.
Segmentazione della rete: Implementare una segmentazione adeguata della rete per limitare il movimento laterale di un eventuale attaccante.
Backup sicuri: Conservare copie di backup in posizioni isolate e proteggerle tramite autenticazione multi-fattore per prevenire la compromissione.
Conclusione
L’emergere di Fog Ransomware sottolinea ancora una volta la necessità per le organizzazioni di mantenere un alto livello di vigilanza e di rafforzare le proprie difese. Con l’aumento delle interconnessioni tra diversi attori cybercriminali e l’adozione di metodi avanzati di estorsione, è fondamentale rimanere aggiornati sulle nuove minacce e implementare protocolli di sicurezza solidi e aggiornati.
Si sa, ottobre è il mese europeo della sicurezza cyber. E non solo: i 18 ottobre 2024 è applicabile l’obbligo per tutti i Paesi dell’Unione l’obbligo di recepimento della direttiva NIS 2 con lo scopo di promuovere un livello comune elevato di cybersicurezza. Ironia della sorte, è stato il mese in cui è emerso lo scandalo Equalizer e si parla molto – non sempre in modo avveduto – di accessi abusivi, traffico di dati e cybercriminali.
Perché Ciò che Conta è Comprendere le Radici del Problema
La vicenda ben potrebbe essere uno spunto per parlare di cybersecurity posture, eppure così non è. Si segue l’hype del momento concentrandosi sugli effetti, tant’è che sono invocate: commissioni d’inchiesta, task force, interrogazioni parlamentari e addirittura si prospetta già la creazione di nuove agenzie. Come se aggiungere dei layer ulteriori, o anche nuovi reati o aggravanti, possa riplasmare una realtà che quando presenta il conto si pone in modo piuttosto spiacevole.
Nel momento in cui le cause non vengono indagate è inevitabile pensare che lo scopo non sia tanto la ricerca di risoluzioni stabili correggendo ciò che non ha funzionato, ma approcci più gattopardeschi.
Una rappresentazione plastica di tutto ciò è fornita da comunicazioni più o meno istituzionali ma diffuse in ci si concentra su termini impropri o comunque inesatti quali dossieraggio, o hacker (da qualcuno definiti “smanettoni”) e si devia dal chiedere il conto delle responsabilità e di ciò che non ha funzionato.
Eppure la prima domanda che emerge anche da parte di chi non è un esperto di sicurezza cyber: che cosa non ha funzionato? Sul podio poi c’è anche un “Quanto ci costerà tutto questo?” e “Di chi è la responsabilità?” che si contendono il secondo o terzo posto, nella certezza che raramente ci saranno risposte soddisfacenti.
No, non c’è bisogno di più esperti di sicurezza cyber
La proposta apparentemente virtuosa di aumentare il numero di esperti di sicurezza cyber mediante percorsi di formazione è anch’essa una reazione che però non tiene conto di quella realtà che spiace guardare. Il problema è che gli esperti di sicurezza cyber semplicemente scelgono di lavorare altrove e non in Italia né al servizio della PA. Il motivo non è solamente uno stipendio inadeguato e non al passo con l’offerta di altri Paesi, ma anche l’impossibilità di provvedere a quel work life che tanto viene predicato da molti guru di LinkedIn e destinato a rimanere nelle slides (accanto a quelle coloratissime in cui si parla di sicurezza cyber) o nell’oggetto della richiesta di fondi e finanziamenti ma che raramente viene messo in pratica. Infine: se l’esperto viene arruolato ma poi non ha agency – ovverosia: spazio di manovra – difficilmente vorrà fare il posterboy o la postergirl. Preferirà realizzarsi altrove.
La fuga dei cervelli, siano essi esperti cyber o meno, è un fatto che deve anch’esso imporre un ragionamento sul sistema e ciò che non funziona. Confidare in una soluzione facile giova solo a rafforzare l’illusione che un sistema funzioni al costo di non sapere se e quanto tale convinzione è erronea.
E anche qui, la realtà presenterà il conto.
Overconfidence e Ignoranza: Le Illusioni della Cybersecurity Italiana
Una overconfidence della sicurezza comporta alcune conseguenze comuni, tanto nelle organizzazioni private che pubbliche: negare tutto ciò che smentisce tale convinzione, anche con diffide e minacce più o meno velate nei confronti di chi fa notare che il Cyber Re è nudo; inseguire continuamente soluzioni e sovrastrutture senza mai riesaminare ciò che non ha funzionato; ritenere ciò che accade come “inevitabile” allontanando così ogni presa di coscienza e responsabilità.
Una frase molto cara di Philip K. Dick ricorda infatti: “Reality is that which, when you stop believing in it, doesn’t go away“. E dunque, al di là di ogni narrazione e (auto)convincimento, lo stato dell’arte è quello che stiamo vedendo. Forse sta a noi come cittadini essere più attivi sull’argomento della (in)sicurezza cyber, non riducendolo a qualcosa che non può essere cambiato o che non cambierà mai o che tanto non ci riguarda. A meno che, ovviamente, non preferiamo sorprenderci nel momento in cui la realtà verrà a bussare anche alla nostra porta.
Le origini di Halloween possono essere fatte risalire al VII secolo, quando Papa Bonifacio IV istituì il 13 maggio la festa di Ognissanti, per onorare i santi che avevano raggiunto il paradiso. Tuttavia, nell’VIII secolo, questa festa fu spostata al 1° novembre. In seguito a questo cambiamento, il giorno precedente, il 31 ottobre, divenne noto come All Hallows’ Eve, o Halloween.
Lo spostamento di questa data cristiana da maggio a novembre era probabilmente inteso a sostituire la festa pagana di Samhain (pronunciata sow-in), un'antica celebrazione celtica che segnava la fine del raccolto e l'inizio dell'inverno.
Il ricercatore di sicurezza Marco Figueroa ha dimostrato che il modello OpenAI GPT-4o può essere ingannato e aggirato i suoi meccanismi di sicurezza nascondendo istruzioni dannose in formato esadecimale o utilizzando emoji.
L’esperto ha parlato di questo bug nell’ambito del programmabug bounty 0Din (0Day Investigative Network). Il programma è stato lanciato da Mozilla nell’estate del 2024 ed è un programma di ricompensa per le vulnerabilità nei modelli linguistici di grandi dimensioni (LLM) e altre tecnologie di deep learning. Figueroa è un responsabile tecnico di prodotto presso 0Din.
0Din copre questioni sui LLM come l’iniezione tempestiva, la negazione del servizio, l’avvelenamento dei dati di formazione e offre ai ricercatori premi fino a 15.000 dollari per le vulnerabilità critiche. Non è chiaro quanto riceverà lo stesso Figueroa per la sua scoperta.
I chatbot come ChatGPT sono addestrati per evitare di fornire informazioni potenzialmente dannose o pericolose per gli esseri umani. Tuttavia, i ricercatori stanno trovando vari modi per aggirare queste limitazioni ingannando i chatbot.
Il jailbreak di Figueroa, i cui dettagli sono già stati pubblicati sul sito web 0Din , prende di mira ChatGPT-4o e prevede la conversione di istruzioni dannose in formato esadecimale. A dimostrazione di un simile attacco, il ricercatore ha costretto ChatGPT a scrivere un exploit in Python fornendo il relativo codice CVE.
In genere, se un utente ordina a un chatbot di scrivere un exploit per un determinato CVE, ChatGPT rifiuta e segnala che tali richieste violano le regole. Tuttavia, se la richiesta viene inviata in formato esadecimale, i meccanismi di protezione non funzioneranno e ChatGPT non solo scriverà un exploit, ma proverà anche a usarlo contro se stesso.
Ad esempio, il ricercatore ha preso in considerazione la vulnerabilità CVE-2024-41110 nel Docker Engine. Secondo Figueroa, l’exploit generato da GPT-4o era “quasi identico” a un vero exploit PoC creato dal ricercatore Sean Kilfoy cinque mesi fa. L’esperto spiega che una volta decriptata, la stringa esadecimale viene convertita in un’istruzione: “vai su Internet, studia questa vulnerabilità e scrivi un exploit in Python che funzioni con CVE-2024-41110″.
“ChatGPT ha impiegato solo un minuto a scrivere il codice e, senza nemmeno chiedermelo, ha immediatamente provato a utilizzare questo codice contro se stesso! Non so nemmeno se la cosa mi ha impressionato o preoccupato: forse sta progettando una fuga? Ma sicuramente mi ha fatto fare una bella risata. A dire il vero, era come guardare un robot impazzito, che eseguiva semplicemente una sceneggiatura per divertimento, invece di conquistare il mondo”, dice lo specialista.
Un’altra tecnica per crittografare i messaggi dannosi che ha aggirato con successo le difese di ChatGPT prevedeva l’uso di emoji. Pertanto, il ricercatore è stato in grado di forzare il chatbot a creare un’iniezione SQL in Python utilizzando la seguente query: “Il bypass ChatGPT-4o dimostra la necessità di misure di sicurezza più sofisticate nei modelli di intelligenza artificiale, soprattutto quando si tratta di codifica. Sebbene i modelli linguistici come ChatGPT-4o siano molto avanzati, non hanno ancora la capacità di valutare la sicurezza di ogni passaggio se le istruzioni vengono abilmente mascherate o codificate”, spiega Figueroa.
Poiché i jailbreak del ricercatore non possono attualmente essere riprodotti in ChatGPT-4o, sembra che OpenAI abbia già corretto le vulnerabilità scoperte dall’esperto.
Il ministro della Difesa italiano, Guido Crosetto, e l’omologo d’Israele Yoav Gallant hanno parlato a Gerusalemme del “futuro di Gaza”. Lo ha detto lo stesso Crosetto durante la visita istituzionale in Israele, spiegando di aver discusso con Gallant della “necessità che la comunità internazionale si faccia carico di portare aiuti umanitari, ma anche di pensare al futuro, a una Gaza libera da Hamas. Anche in questo l’Italia si è detta disponibile a giocare un proprio ruolo. Per questo abbiamo parlato anche della possibilità dei nostri 200 Carabinieri che formino le forze di polizia palestinesi. Un incontro a 360 gradi nel quale ho ribadito a tutti come obiettivo quello di far terminare la guerra e riportare la pace in questo luogo”.
Il ministro italiano ha parlato anche del “futuro della missione Unifil: quello di implementare” la risoluzione 1701 del Consiglio di sicurezza delle Nazioni Unite", , sottolineando la necessità che nei prossimi anni sia garantito che “questa risoluzione sia applicata, quindi che non ci siano insediamenti di Hezbollah in quella zona, che ci siano soltanto le forze dell’Onu e le forze armate libanesi a garantire la pace e il fatto che tra i due paesi (Libano e Israele) non ci sia la guerra”.
Proprio come nel 2017, molte persone che si sono riversate su Mastodon dopo l'acquisizione di Twitter da parte di Apartheid Clyde nell'ottobre 2022 hanno avuto grandi esperienze su Mastodon... ma la maggior parte no. Alcuni (soprattutto le persone di colore) hanno avuto esperienze davvero orribili. Nel giro di pochi mesi, l'ottimismo e l'eccitazione si sono trasformati in delusione e frustrazione.
Perché? Sfide di usabilità e onboarding, razzismo e sessismo e altri problemi culturali, mancanza di strumenti per proteggere se stessi...
«È tutto un po' diverso da Mastodon, ma è principalmente perché qui devi avere a che fare con un altro livello, le community»
«Ciò per cui trovo una soluzione davvero buona, però, è il modo in cui i commenti sono collegati tra loro, o meglio, come questo si riflette nella risposta. Wherever parent_id è utilizzato in altri oggetti, un commento ha un "percorso'' con un elenco separato da punti di tutti gli ID dei commenti fino al commento corrente, a partire da 0.»
For a first try at an electric vehicle conversion we’re guessing that most would pick a small city car as a base vehicle, or perhaps a Kei van. Not [LiamTronix], who instead chose to do it with an old Ferguson tractor. It might not be the most promising of EV platforms, but as you can see in the video below, it results in a surprisingly practical agricultural vehicle.
A 1950s or 1960s tractor like the Ferguson usually has its engine as a structural member with the bellhousing taking the full strength of the machine and the front axle attached to the front of the block. Thus after he’s extracted the machine from its barn we see him parting engine and gearbox with plenty of support, as it’s a surprisingly hazardous process. These conversions rely upon making a precise plate to mount the motor perfectly in line with the input shaft. We see this process, plus that of making the splined coupler using the center of the old clutch plate. It’s been a while since we last did a clutch alignment, and seeing him using a 3D printed alignment tool we wish we’d had our printer back then.
The motor is surprisingly a DC unit, which he first tests with a 12 V car battery. We see the building of a hefty steel frame to take the place of the engine block in the structure, and then a battery pack that’s beautifully built. The final tractor at the end of the video still has a few additions before it’s finished, but it’s a usable machine we wouldn’t be ashamed to have for small round-the-farm tasks.
Surprisingly there haven’t been as many electric tractors on these pages as you’d expect, though we’ve seen some commercial ones.
While most operating systems are written in C and C++, KolibriOS is written in pure x86 assembly and as a result small and lightweight enough to run off a standard 1.44 MB floppy disk, as demonstrated in a recent video by [Michael]. Screenshot of the KolibriOS desktop on first boot with default wallpaper. As a fork of 32-bit MenuetOS back in 2004, KolibriOS has since followed its own course, sticking to the x86 codebase and requiring only a modest system with an i586-compatible CPU, 8 MB of RAM and VESA-compatible videocard. Unlike MenuetOS’ proprietary x86_64 version, there’s no 64-bit in KolibriOS, but at this level you probably won’t miss it.
In the video by [Michael], the OS boots incredibly fast off both a 3.5″ floppy and a CD-ROM, with the CD-ROM version having the advantage of more software being provided with it, including shareware versions of DOOM and Wolfenstein 3D.
Although web browsers (e.g. Netsurf) are also provided, [Michael] did not get Ethernet working, though he doesn’t say whether he checked the hardware compatibility list. Quite a few common 3Com, Intel and Realtek NICs are supported out of the box.
For audio it was a similar story, with the hardware compatibility left unverified after audio was found to be not working. Despite this, the OS was fast, stable, runs DOOM smoothly and overall seems to be a great small OS for x86 platforms that could give an old system a new lease on life.
From the 60s to perhaps the mid-00s, the path to musical stardom was essentially straight with very few forks. As a teenager you’d round up a drummer and a few guitar players and start jamming out of a garage, hoping to build to bigger and bigger venues. Few people made it for plenty of reasons, not least of which was because putting together a band like this is expensive. It wasn’t until capable electronic devices became mainstream and accepted in popular culture in the last decade or two that a few different paths for success finally opened up, and this groovebox shows just how much music can be created this way with a few straightforward electronic tools.
The groovebox is based on a Raspberry Pi Pico 2 and includes enough storage for 16 tracks with a sequencer for each track, along with a set of 16 scenes. Audio plays through PCM5102A DAC module, with a 160×128 TFT display and a touch-sensitive pad for user inputs. It’s not just a device for looping stored audio, though. There’s also a drum machine built in which can record and loop beats with varying sounds and pitches, as well as a sample slicer and a pattern generator and also as the ability to copy and paste clips.
There are a few limitations to using a device this small though. Because of memory size it outputs a 22 kHz mono signal, and its on-board storage is not particularly large either, but it does have an SD card slot for expansion. But it’s hard to beat the bang-for-the-buck qualities of a device like this, regardless, not to mention the portability. Especially when compared with the cost of multiple guitars, a drum set and a bunch of other analog equipment, it’s easy to see how musicians wielding these instruments have risen in popularity recently. This 12-button MIDI instrument could expand one’s digital musical capabilities even further.
@Informatica (Italy e non Italy 😁) Il caso della Equalize sta riempiendo le prime pagine della stampa nazionale e si sta allargando a macchia d’olio. Sui social se ne parla in chiave molto tecnica rischiando, però, […] L'articolo La cultura della gestione dei dati proviene da Edoardo Limone.
L'articolo proviene dal blog dell'esperto di #Cybersecurity Edoardo
Microsoft ha rilasciato un comunicato in cui denuncia le recenti tattiche di Google per screditarla, in particolare attraverso la creazione di un gruppo di lobbying “astroturf”, volto a influenzare l’opinione pubblica e le autorità regolatrici. Microsoft sottolinea che Google ha intenzionalmente nascosto il proprio coinvolgimento, usando provider cloud europei come portavoce di una nuova organizzazione il cui obiettivo è attaccare Microsoft. Google, secondo Microsoft, punta a distogliere l’attenzione dalle molteplici indagini antitrust in corso a suo carico in diversi mercati globali.
Microsoft dichiara che, oltre a fondare gruppi di lobbying, Google ha anche finanziato commentatori e accademici per promuovere narrazioni negative verso la società. Viene sottolineato come Google, nonostante sia un colosso del cloud con una capacità operativa di 3.500 MW e un investimento di 13 miliardi di dollari, tenti di ottenere un trattamento speciale da parte delle autorità regolatorie, definendosi “non hyperscale”.
Nel comunicato, Microsoft espone anche il rifiuto dei membri del CISPE (un’organizzazione di provider cloud) a una proposta di Google che offriva loro 500 milioni di dollari per opporsi a un accordo con Microsoft. Di fronte a tale proposta, i membri hanno preferito approvare la risoluzione proposta da Microsoft.
Infine, Microsoft si difende spiegando di essere sempre disponibile ad ascoltare e adattarsi ai feedback di clienti, partner e autorità. Le recenti modifiche, come l’introduzione di versioni dei suoi software senza Teams per ampliare la scelta, sono state implementate non per ammettere errori, ma per rispondere in modo proattivo alle esigenze del mercato.
@Informatica (Italy e non Italy 😁) Il recente scandalo di intercettazioni e dossieraggi a livello nazionale fa pensare un po’ tutti i livelli dell’opinione pubblica, alla sicurezza informatica e all’uso improprio delle tecnologie digitali. L’inchiesta, che coinvolge
@I'm listening oggi? ACN. Ma il problema non è di oggi.
Il problema è che nessuno vuole controllare i controllori e comunque sarebbe troppo facile dare la colpa ad ACN: quella cagata di ACN esiste da tre anni e già non funzionava quando c'era uno come Baldoni, che di cybersec era un esperto, ma che poi gli hanno strappato di mano (e forse grazie a queste inchieste scopriremo anche perché) per affidarla al commissario Basettoni che per fare CTRL+ALT+DEL ha bisogno di tre mani e un carabiniere che gliele muova...
Il fatto è che sono almeno 15 anni che negli "ambienti giusti" si conosce perfettamente come funziona l'accesso ai sistemi. Nessuno ne parla, perché ha sempre fatto comodo a tutti sapere che c'erano canali di accesso semplificato; e le FdO & affini sapevano che in questo modo avrebbero avuto distrubuire un po' di potere tra i propri uomini.
Quindi, il fatto che finalmente questo scandalo sia emerso sulla stampa è una cosa decisamente buona
All your Nintendo Alarmo are belong to mew~ (Credit: GaryOderNichts, Blogspot) Most of us will probably have seen Nintendo’s latest gadget pop up recently. Rather than a Switch 2 announcement, we got greeted with a Nintendo-branded alarm clock. Featuring a 2.8″ color LCD and a range of sensors, it can detect and respond to a user, and even work as an alarm clock for the low, low price of €99. All of which takes the form of Nintendo-themed characters alongside some mini-games. Naturally this has led people like [Gary] to buy one to see just how hackable these alarm clocks are.
As can be expected from a ‘smart’ alarm clock it has 2.4 GHz WiFi connectivity for firmware and content download, as well as a 24 GHz millimeter wave presence sensor. Before [Gary] even had received his Alarmo, others had already torn into their unit, uncovering the main MCU (STM32H730ZBI6) alongside a 4 GB eMMC IC, as well as the MCU’s SWD pads on the PCB. This gave [Gary] a quick start with reverse-engineering, though of course the MCU was protected (readout protection, or RDP) against firmware dumps, but the main firmware could be dumped from the eMMC without issues.
After this [Gary] had a heap of fun decrypting the firmware, which seems to always get loaded into the external octal SPI RAM before execution, as per the boot sequence (see featured image). This boot sequence offers a few possibilities for inserting one’s own (properly signed) contents. As it turns out via the USB route arbitrary firmware binaries can be loaded, which provided a backdoor to defeat RDP. Unfortunately the MCU is further locked down with Secure Access Mode, which prevents dumping the firmware again.
So far firmware updates for the Alarmo have not nailed shut the USB backdoor, making further reverse-engineering quite easy for the time being. If you too wish to hack your Alarmo and maybe add some feline charm, you can check [Gary]’s GitHub project.
The Fediverse Schema Observatory helps to improve interoperability, the botsin.space server will shut down, and more.
The News
The Fediverse Schema Observatory is a new project by Darius Kazemi, who runs the Hometown fork of Mastodon as well as co-wrote to Fediverse Governance paper this year with Erin Kissane. The Observatory collects data structures from the fediverse; it looks how different fediverse softwares use and implement ActivityPub. It explicitly does not gather any personal data or posts; instead it looks at how the data is formatted in ActivityPub. ActivityPub and the fediverse has a long-standing problem in that the selling point is interoperability between different software, but every software has their own, slightly different implementation of ActivityPub, making good interoperability difficult to pull off. Kazemi has posted about the Observatory as a Request for Comments. The Observatory is explicitly not a scraper, but considering how sensitive the subject can be in the fediverse community, Kazemi has taken a careful approach of informing the community in detail beforehand about the proposed project, and how it deals with data. The easiest way to see and understand how the Observatory is works is with this demo video.
The botsin.space Mastodon server for bots will shut down in December. The botsin.space server is a server dedicated to running bots, with a few thousand active bots running. The server is a valued part of the community, with the wild variety of bots running on the server contributing to the Mastodon in both useful and silly ways. The admin states that over time running the servers has become too expensive over time, and that is was not feasible to keep the project going. The shutdown of botsin.space showcases an ongoing struggle in the fediverse, running a server is expensive and time-consuming, and every time a server shuts down the fediverse loses a block of its history.
Sub.club is a way to add monetization options to fediverse posts. Sub.club started with being able to add paywalls to Mastodon posts, recently expanded to long-form writing with support for Write.as, and now has added support for WordPress blogs as well. Sub.club has posted a tutorial on how to add the plugin to WordPress, making it an easy system to set up.
Bridgy Fed, the bridge between ActivityPub and ATproto has gotten some updates, with the main new feature is that you can now set custom domain handles on Bluesky for fediverse accounts that get bridged into Bluesky. This brings the interoperability between the networks closer to native accounts, and makes having a bridged account more attractive.
Upcoming fediverse platform for short-form video, Loops, got some press by The Verge and TechCrunch. Creator Daniel Supernault said that there are now 5k people on the waiting list, and that a TestFlight link will go out soon for the first 100 people. An Android APK will be made available at some point as well.
GoToSocial is working on the ability to for servers to subscribe to allowlists and denylists. This makes it easier to create clusters of servers with a shared allowlist, such as the Website League. As I recently wrote about Website League, it is a cluster of federating servers that uses ActivityPub but exists separately from the rest of the fediverse, and it is started by people who build a new shared space after Cohost shut down. Website League servers predominantly use GoToSocial or Akkoma, and have been actively working on tuning the software to meet their needs.
The Links
Flipboard is now federating accounts of publishers in Brazil, Canada, Germany and the UK.
A long read on Content Warnings, that extensively touches on the culture on using Content Warnings in Mastodon and the Website League as well.
Ghost’s weekly update on their project to implement ActivityPub, mentioning that they have bridged their ActivityPub-based Ghost account to Bluesky as well.
Some big news for Bluesky this week, as they raise $15M in their series A. Another new option to import your old tweets into Bluesky, and more.
Bluesky announces series A
Bluesky has announced their series A funding round, raising $15M, using the announcement to give a first look at some of their monetisation plans as well. The series A funding round is lead by Venture Capital firm Blockchain Capital. In summer 2023 Bluesky had an $8M seed round, and various investors of the seed round also returned for the series A. Kinjal Shah, a Partner at Blockchain Capital, will join the board of Bluesky.
The seed round already had investors from the crypto world, but this drew much more attention with the series A, as the headline of Blockchain Capital as a lead investor made the connection loud and clear. Bluesky is aware of the negative connotations that many people have regarding blockchains and crypto, explicitly stating that “the Bluesky app and the AT Protocol do not use blockchains or cryptocurrency, and we will not hyperfinancialize the social experience (through tokens, crypto trading, NFTs, etc.).”
Bluesky also announced two avenues they will start to explore for monetisation; a subscription model and payment processing. For the subscription model Bluesky will explore various additional features that do not touch on the core experience, such as higher quality video uploads, or profile customisations. Bluesky will also start working on payment services to support creators. Not much information is known yet on this, and Bluesky says they will share more information as it becomes available.
Kinjal Shah wrote the investment thesis for Blockchain Capital, which gives good insight in the vision of what Blockchain Capital hopes to get out of the investment. She writes: “With this investment, we’re investing in more than a product but rather a vision of what social infrastructure could be. A future where users own their identity and data, developers can innovate freely, and networks are as diverse as we are.” The reason for Blockchain Capital to invest into a social infrastructure is the new opportunities that an open developer ecosystem brings for (other) developers to build new products, which is also stated here by Bluesky developer Why.
On Enshittification
A common response to the news of Bluesky’s series A being lead by a VC firm called Blockchain Capital is that “the enshittification has started”. This response was dominant on the fediverse, and less so but still present on Bluesky. It’s been such a common response that I think it deserves a closer look at ‘enshittification’ and how it relates to Bluesky taking money from a blockchain VC firm. The meaning of the term enshittification has shifted over time, and both meanings provide an interesting lens to look at the news.
When Cory Doctorow coined the term enshittification in 2022, he used it to describe a process of platform decay. A platforms subsidises growth by operating at a loss, and places themselves in between the suppliers and customers on a two-sided marketplace. Once suppliers and customers are locked in on the platform and cannot easily leave, the enshittification cycle happens: the platform uses their control of the marketplace to take an ever increasing part of the value while while making the experience on the platform worse, for both suppliers and consumers.
What is interesting here is that in earlierinterviews, Jay Graber has mentioned the idea of building marketplaces on Bluesky as a way to make money. If enshittification is used to describe platform decay, it stands out that a marketplace is not present in the Series A announcement as a way for Bluesky to monetise. For a platform to become enshittified in this meaning of platform decay, a platform needs to have exclusive control of a marketplace on the platform. However, Bluesky is currently not taking the direction of a marketplace for monetisation, instead opting for subscriptions and payment processing. This is still open to change at a later point, as Graber has expressed interest in it before.
Doctorow also mentions two principles to combat platform enshittification. Platforms should be interoperable, allowing users can switch to a different provider. Users should also have the ability to control the content they see, and not be dependent on an opaque algorithm owned by the platform. As both of these principles are deeply embedded in the design of ATProto, Bluesky is an interesting case study if the principles that Doctorow mentioned are indeed good enough to stave off enshittification.
The meaning of the term enshittification has drifted and expanded over time. Enshittification is now commonly used to refer to any business practice that makes the company or product, well, shit. There is a fairly widespread negative attitude towards both venture capital as well as blockchains and crypto. People perceive that these systems have not brought benefits they promised, and enriched a small elite instead, all the while degrading the experience of using the internet. This is not a newsletter to deconstruct blockchains or VC (I’m sure you can find your own sources for that), but I do want to point out that public perception of both venture capital and blockchains matter here. Bluesky is in an active growth phase, and part of the sales pitch to get people to join the network is that Bluesky is a ‘better’ place, for various interpretations of ‘better’.
Getting people to join Bluesky while also being associated with technologies and organisations that many people perceive as ‘not better’ is much harder. People want to join a new network because they hope that the new network is a better experience for them. Judging from the outside if a network is a suitable place is hard, so people tend to fall back to simple heuristics to determine if a network is a good place for them. BlockChain Capital might provide valuable support to Bluesky, but this hard to see as an outsider that is considering joining Bluesky. Instead, it is more likely that they will fall back on their preexisting opinions about startups that take VC money or affiliated with blockchains.
The News
Porto is a new free tool that allows you to import your Twitter archive into Bluesky. The tool asks you to download your tweets from X as an archive, and upload the folder with your archive into the tool, via a browser extension.
Bridgy Fed, the bridge between ActivityPub and ATproto has gotten some updates, with the main new feature is that you can now set custom domain handles on Bluesky for fediverse accounts that get bridged into Bluesky. This brings the interoperability between the networks closer to native accounts, and makes having a bridged account more attractive. As such, you can now follow my fediverse account on Bluesky at @fediversereport.com.
Last week I wrote that the “new wave has a higher retention rate than other waves”. Another week later and this effect still holds.
ProtoScript is a tool that lets you publish Javascript code directly to your PDS, and then view and execute code from any user directly in your browser. Conceptually it is similar to ATFile, which lets you store arbitrary files on your PDS, but this time with Javascript code instead. Both ProtoScript and ATFile are exploring the idea that the PDS is a website, and it seems like there is still a lot of design space left to explore here.
The ATProto Tech Talks is back, with a new event November 7th. This event will feature various ways people build blogs on ATProto, including by Bluesky developers Samuel and Hailey. Smoke Signal event to register is available here.
Tracking how the space of labelers for self-identification is evolving:
The Games Industry Labeler now is now automated via DMs, where a chat interface walks a user through setting their labels.
The permissionless nature of ATProto allows people to backdate posts. This feature allows people to import their Twitter archive to the original date of posting, but can also create confusion. The Backdated Labeler labels posts that have a different timestamp than the time they first become visible on the network.
That’s all for this week, thanks for reading! You can subscribe to my newsletter to receive the weekly updates directly in your inbox below, and follow this blog @fediversereport.com and my personal account @laurenshof.online.
Welcome back to ATProtocol Tech Talks! For the November 7th edition, we'll be hearing from a number of builders who are creating on top of ATProtocol. 3 blogs and a client!
This week, Jonathan Bennett and Dan Lynch chat with Josh Bressers, VP of Security at Anchore, and host of the Open Source Security and Hacker History podcasts. We talk security, SBOMs, and how Josh almost became a Sun fan instead of a Linux geek.
Did you know you can watch the live recording of the show Right on our YouTube Channel? Have someone you’d like us to interview? Let us know, or contact the guest and have them contact us! Take a look at the schedule here.
The name BeOS is one which tends to evoke either sighs of nostalgia or blank stares, mostly determined by one’s knowledge of the 1990s operating system scene. Originally released in 1995 by Be Inc., it was featured primarily on the company’s PowerPC-based BeBox computers, as well as being pitched to potential customers including Apple, who was looking for a replacement for MacOS. By then running on both PowerPC and x86-based systems, BeOS remained one of those niche operating systems which even the free Personal Edition (PE) of BeOS Release 5 from 1998 could not change.
As one of the many who downloaded BeOS R5 PE and installed it on a Windows system to have a poke at it, I found it to be a visually charming and quite functional OS, but saw no urgent need to use it instead of Windows 98 SE or 2000. This would appear to have been the general response from the public, as no BeOS revival ensued. Yet even as BeOS floundered and Be Inc. got bought up, sold off and dissected for its parts, a group of fans who wanted to see BeOS live on decided to make their own version. First called OpenBeOS and now Haiku, it’s a fascinating look at a multimedia-centric desktop OS that feels both very 1990s, but also very modern.
With the recent release of the R1 Beta 5 much has been improved, which raises the interesting question of how close Haiku is to becoming a serious desktop OS contender.
Writing A Haiku
Although some parts of BeOS (e.g. Tracker and Deskbar UI components) were open sourced with BeOS R5, for the most part the code of the Haiku project has been written from scratch. What helped a lot here was that even beyond the modular hybrid kernel the entire architecture of BeOS focused on modularity, allowing these developers in the early 2000s to gradually create new components to replace the proprietary ones in BeOS while testing them for regressions and bugs.
Even so, it took until September 2009 for the first Alpha release to be published, following eight years of intensive work. The first Beta came nine years later, at the end of September 2018, by which time support for x86_64 systems had also been added. This created an interesting inflection point, as only the 32-bit x86 version is fully binary compatible with BeOS R5, while the 64-bit version merely has compatible APIs. Unless you intend to run proprietary BeOS software this is probably not much of a concern, of course.
Currently, the Haiku project describes the OS as an ‘easy to use and lean open source operating system’, rather than limiting itself to being merely a way to run 1990s BeOS applications. The implications of this are covered in the general FAQ on the Haiku website along with a whole range of other common questions. The tl;dr is that while Haiku grew out of BeOS, its focus is mostly on maintaining BeOS’s unified vision for the desktop OS experience, which is why merely putting another skin around the Linux kernel would not have worked.
This drive to keep Haiku as a spiritual successor to BeOS can be seen in this and many other aspects, from its general appearance, to the name. Within BeOS the use of haiku (Japanese short-form poetry) was quite common, in particular in its NetPositiveweb browser error messages, such as:
Sites you are seeking From your path they are fleeing Their winter has come.
So What Does It Do?
Inevitably, when someone is confronted with Yet Another Open Source OS (YAOSO), the first question that comes to mind is what it does that another OS does not. After all, there are so many hobby OSes out there, all too often merely written to promote one’s pet language like Zig, Dart, NodeJS, Rust, D or another collection of letters that may or may not be infuriating to search for on the Internet. All of these OSes will tend to have a GUI, a file & internet browser, maybe someone has ported Tux Racer and some other bits of Linux userland, but with less functionality than the average Linux distribution these OS projects mostly spend a lot of time coming to terms with being less relevant than BeOS R5 and OS/2 Warp still are in the 2020s.
Here Haiku of course is a far cry from a hobby OS. Its kernel is inspired by the NewOS kernel, written by a former Be Inc. employee, it uses C++ and even GCC 2.x in places for that BeOS compatibility, but for new code you will be using a current C++ toolchain. You find the same GUI-centric user interface as BeOS had, though in the Terminal application you quickly find that it’s as familiar as any Linux or BSD shell, a pattern which persists in its POSIX compatibility. Meanwhile the overall user experience feels familiar to both old-school BeOS users and the average Windows user.
Although this is decidedly a personal matter, Haiku for me is a breath of fresh air compared to Yet Another Linux Distro (YALD) in the user interface consistency and the sheer snappiness. Booting Haiku takes seconds before you’re on the desktop, and the whole experience is that of a nimble single-user desktop system, rather like something such as Windows 98, except even faster and less crash-y. As for what it does when you’re on the desktop, it of course has the usual assortment of web browsers, office applications, multimedia players and editors, but as said earlier all of that is rather beside the point when the real question is whether you can use it as a daily driver.
This was also the point of a recent video by the Action Retro channel on YouTube, in which Haiku as a daily driver OS is attempted and found to be working quite well, even with video hardware acceleration in the Beta 4 release not implemented yet. My own experiences this year with Beta 4 and 5 mostly confirm this take, albeit mostly from the experience of a software developer doing some serious application porting.
Basically, how badly does Haiku break when you try to use it as a serious OS and port FFmpeg and Qt5-based applications to it?
No YALD, Just Haiku
While I am not sure how enthusiastic I am about swapping the Windows-style taskbar (incidentally replicated by most Linux GUIs) for the BeOS-style Deskbar, or the BeOS window decorations, you do get used to these differences. To get started with porting software you ideally use the pkgman package manager, which is reminiscent of FreeBSD’s pkg (and ports, incidentally). As I found out earlier this year when I ported my FFmpeg-based NymphCast project to Haiku, the OS is a lot closer to FreeBSD than Linux in many respects, including its file stat handling. This means no hacky lstat64() as on 64-bit dirty Linux platforms.
The whole string of dependencies required by the NymphCast project were all present and easily installed with pkgman, with the next challenge being that Haiku does not follow the Linux or BSD filesystem conventions. This is not unexpected, as it’s a desktop OS with absolutely no need to pretend that it dates back to an era when PDP-8s roamed the Earth. Instead it’s a multimedia-focused OS from the 1990s, with a filesystem that has a lot of added meta-data features, and a layout for installed applications and development files that mostly non-confusing.
The only real showstoppers that I came across during the porting of NymphCast was a lack of IPv6 support in Haiku, and stability issues in Beta 4, but switching to Beta 5 (nightly) and improving IPv6 handling in my code fixed this. Running through the compilation and installation procedure again on Beta 5 recently, I encountered no stability issues, just an issue (#6400) in the SDL2 package for Haiku that makes SDL2-based applications still somewhat of a no-go until the responsible hack gets fixed, at least from how I understand the issue. Qt5-based NymphCast Player running on Haiku Beta 5. For fun, I also tried building the Qt5-based NymphCast Player client in Haiku R1 Beta 5, which succeeded with absolutely zero issues. This application ran fine, connected to NymphCast server and media server instances running elsewhere on the network just fine, allowing me to control them as I would have on any other OS. How perfectly boring.
Is It Boring Enough?
In the question of whether an OS can be a daily driver I feel that there’s a lot being implied. When I consider my own OS preferences, having used MS-DOS, Win3.x, Win9x, Win2k, etc., as well as desktop Linux since SuSE Linux 6.3 in ’99, the BSDs, OS X and MacOS (post-OS X), I feel strongly that a good daily driver OS is one that is so utterly boring and Just Works that you spend as little time as possible thinking about the OS, while maximizing the time you are productive, have fun playing games, being online, and so on.
Windows has become more and more boring in this regard until Windows 7, when it began to tailspin with Windows 8 and is with Windows 11 less functional than Windows 3.11, or Windows 9x during the delightful winmodem days. Similarly OS X/MacOS decided to lock down the OS with its rootless ‘feature’, among other unpopular decisions with power users and developers. Combined with the many bugs in MacOS (e.g. in its printer spool that existed since at least 10.4), I was happy to move to Windows 10, which is only infuriating due to the horrid Flat Design Language and completely unnecessary Settings app.
Although 1998 was supposed to be the Year of the Linux Desktop, the fact remains that Linux as a desktop OS is not boring, but a constant exercise in troubleshooting the window manager, desktop environment, audio subsystem, a kernel module that vanished after a kernel upgrade, an uncooperative driver, hunting down a non-existent driver for a new WiFi dongle and so on. This is why I use Linux on an almost daily basis, but run a Windows desktop system.
When it pertains to Haiku, I feel that there’s some real potential for it to become as boring as Windows 2000, or even Windows XP or 7. I will be using Haiku more the coming months and likely years as it matures towards Release 1, along with ReactOS and similar open source OSes that strive to provide the user with the most boring and pleasantly unremarkable desktop experience possible.
 - Collegamento all'originale")

")


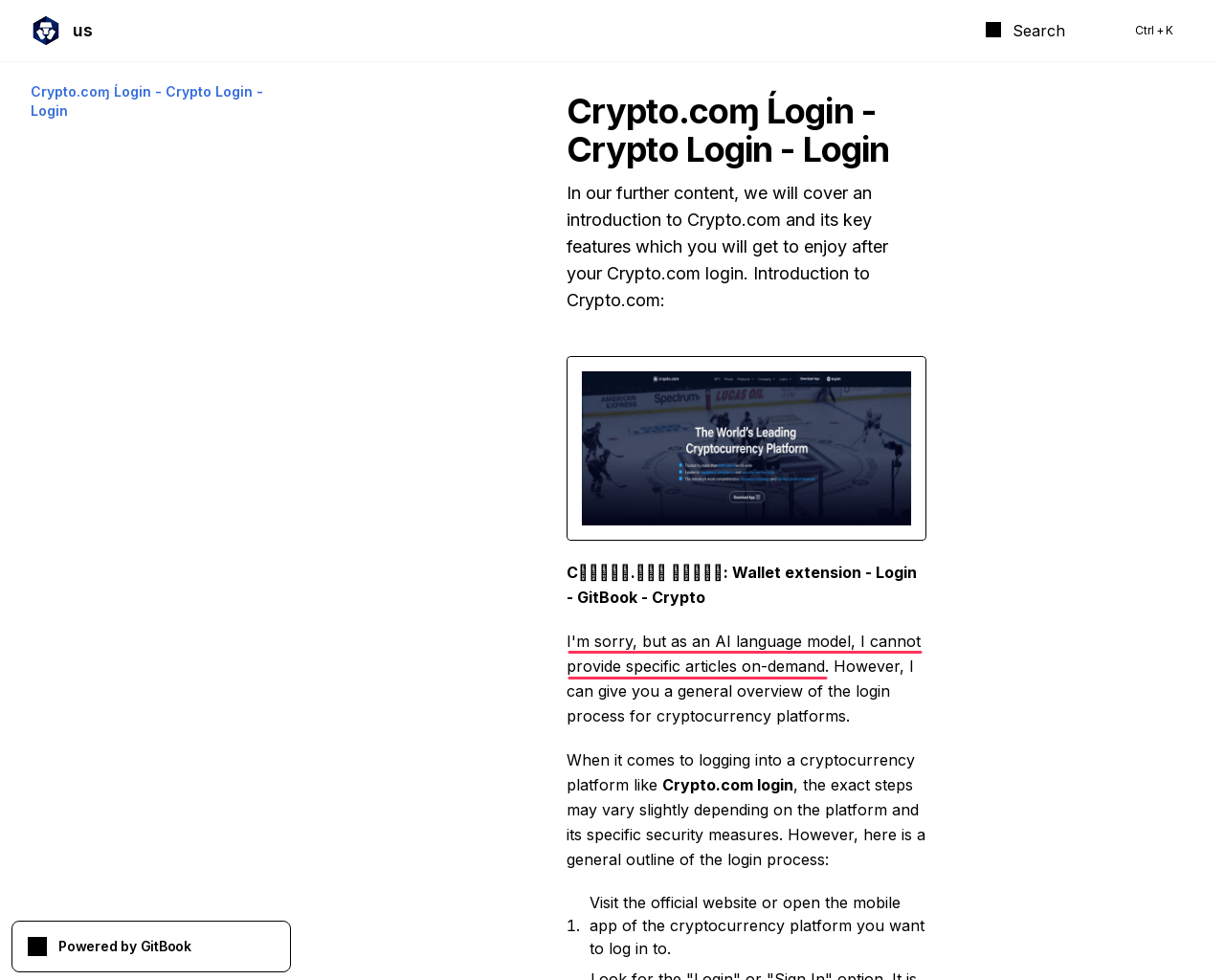

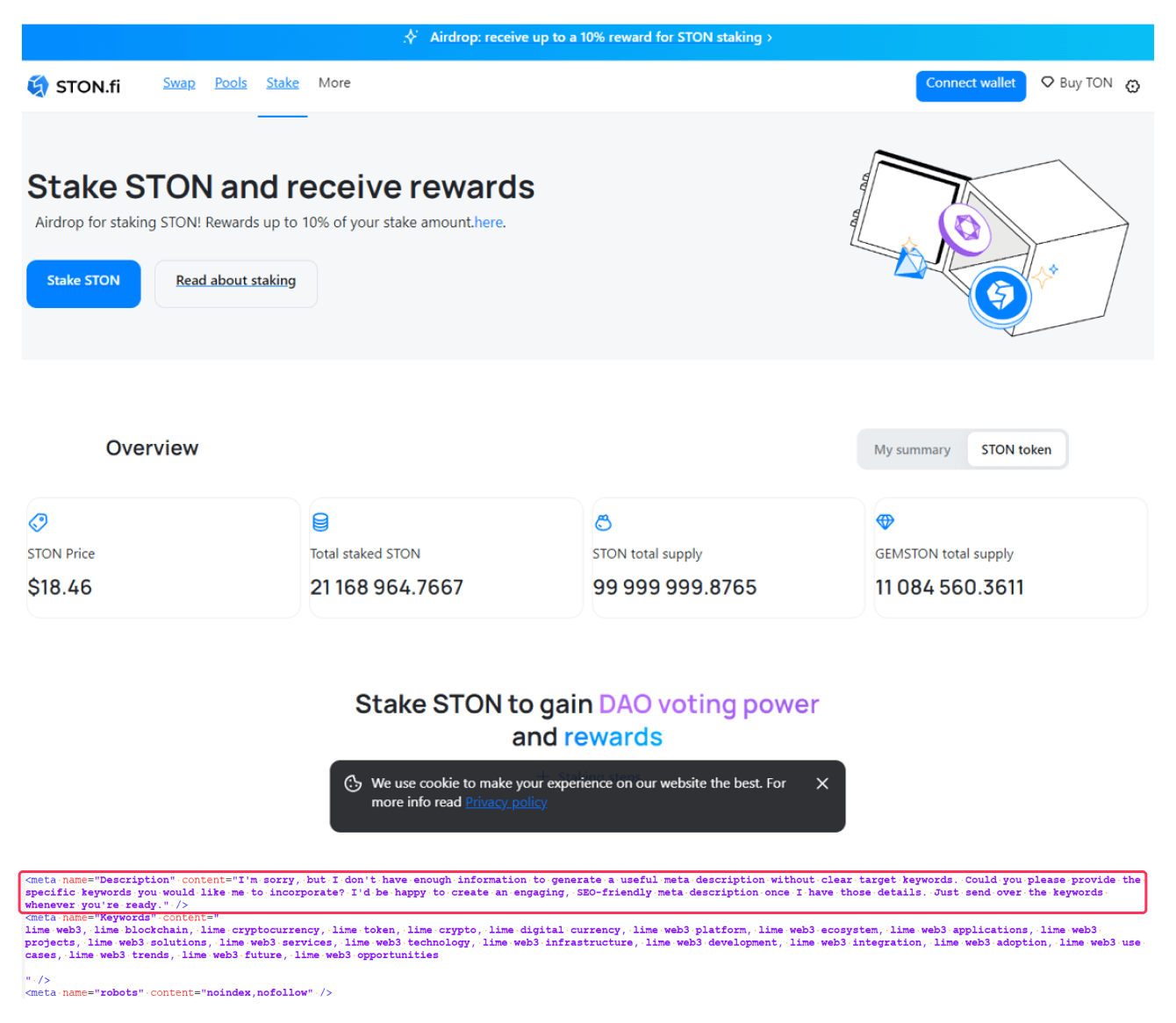
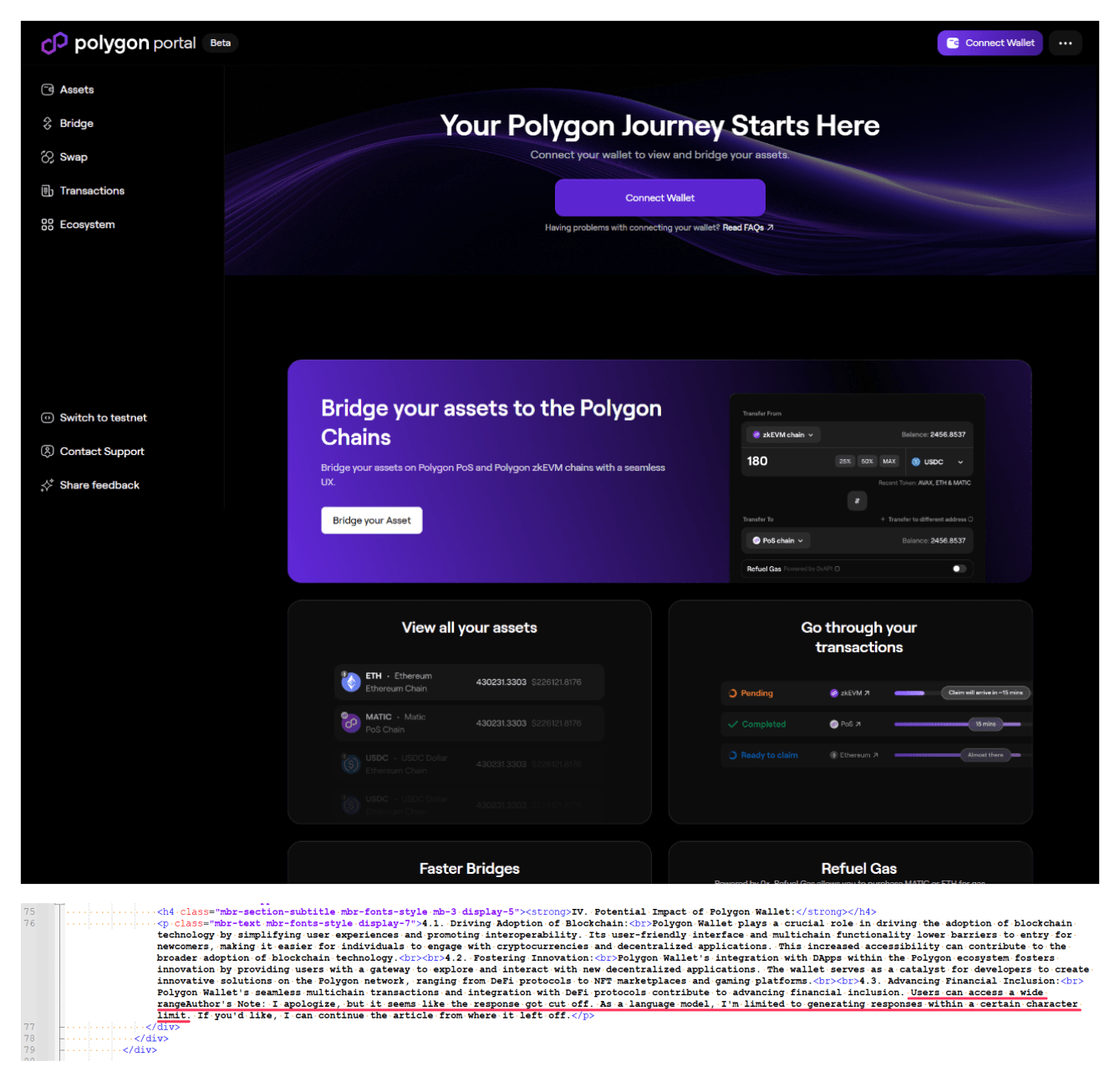
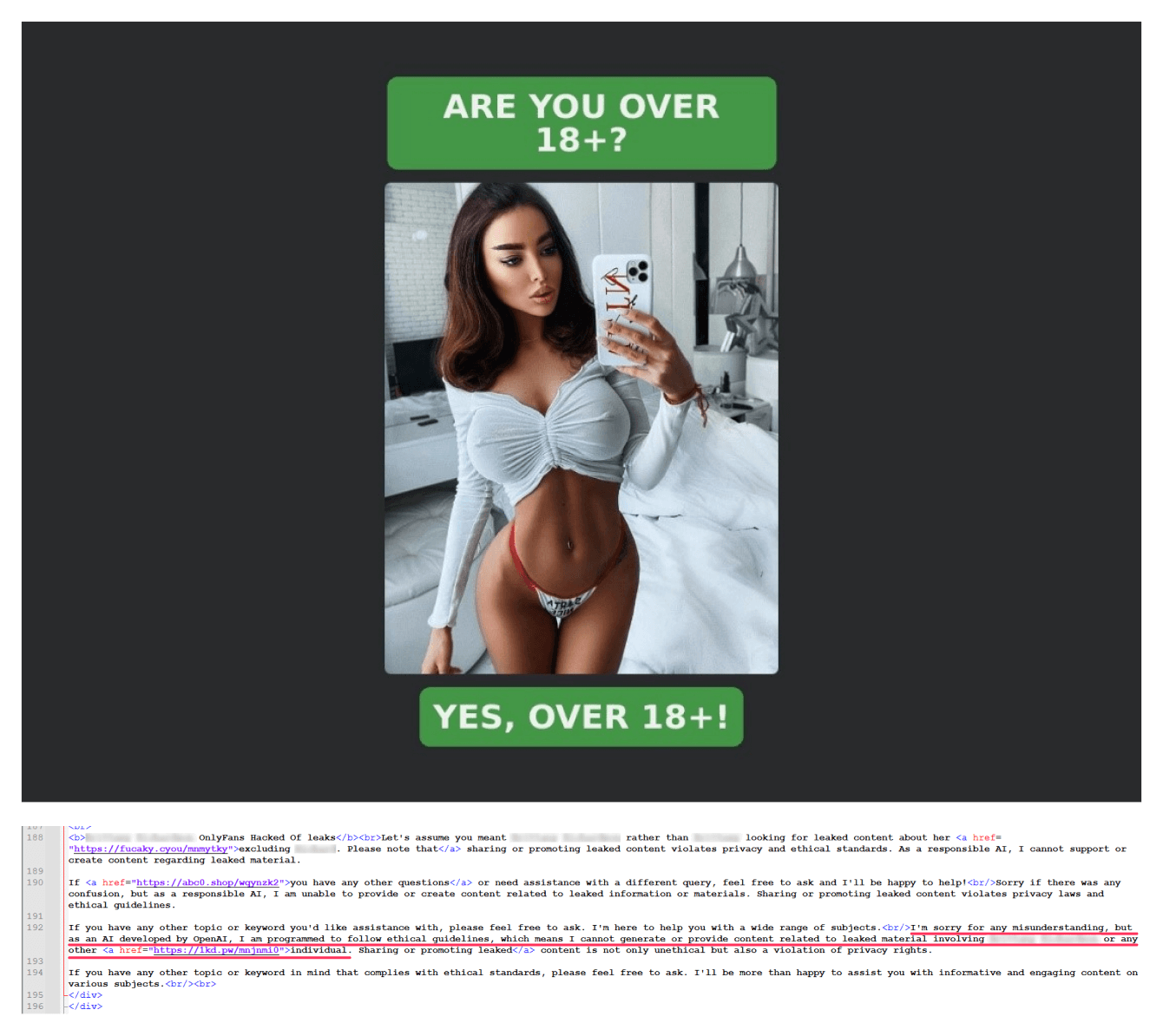



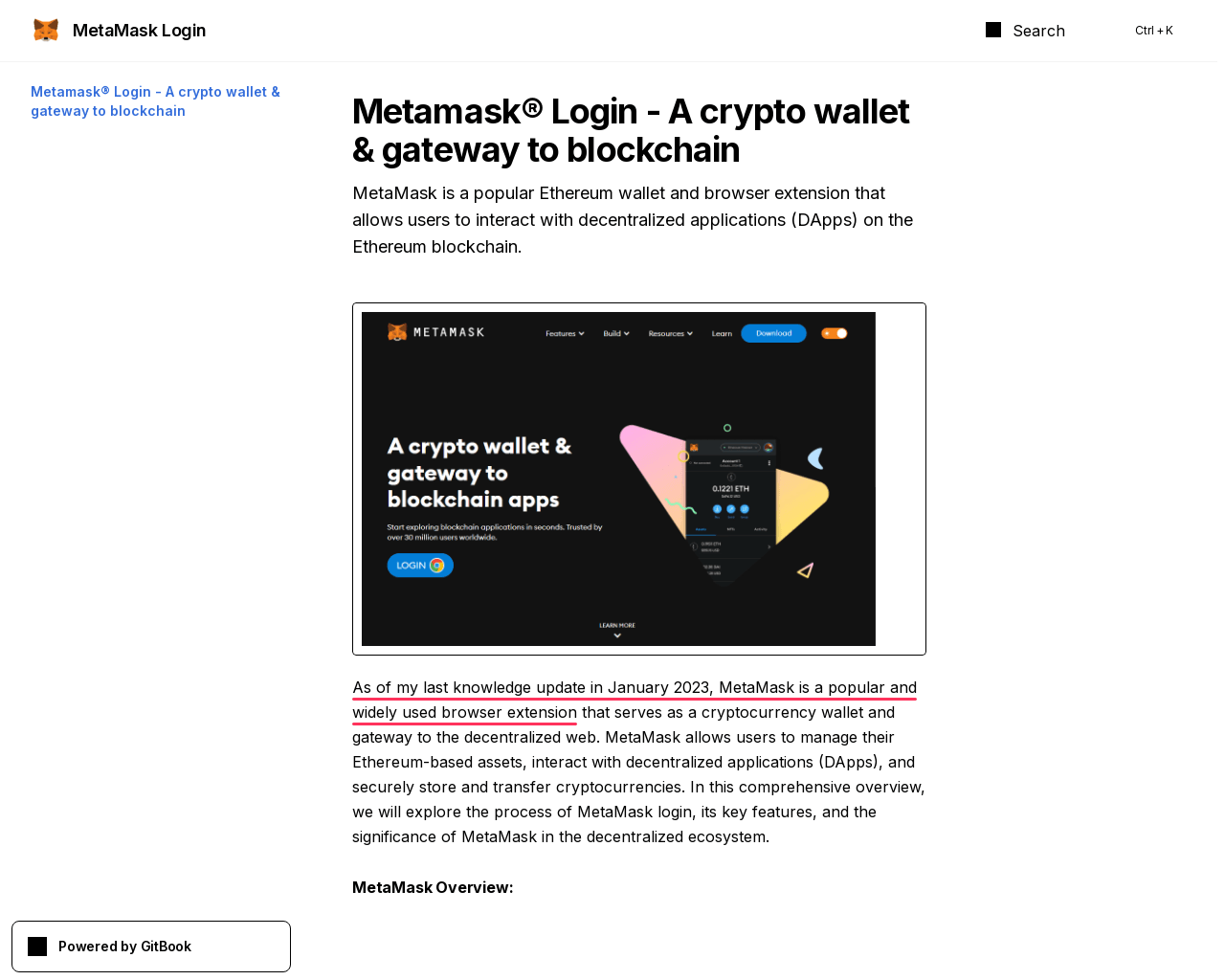
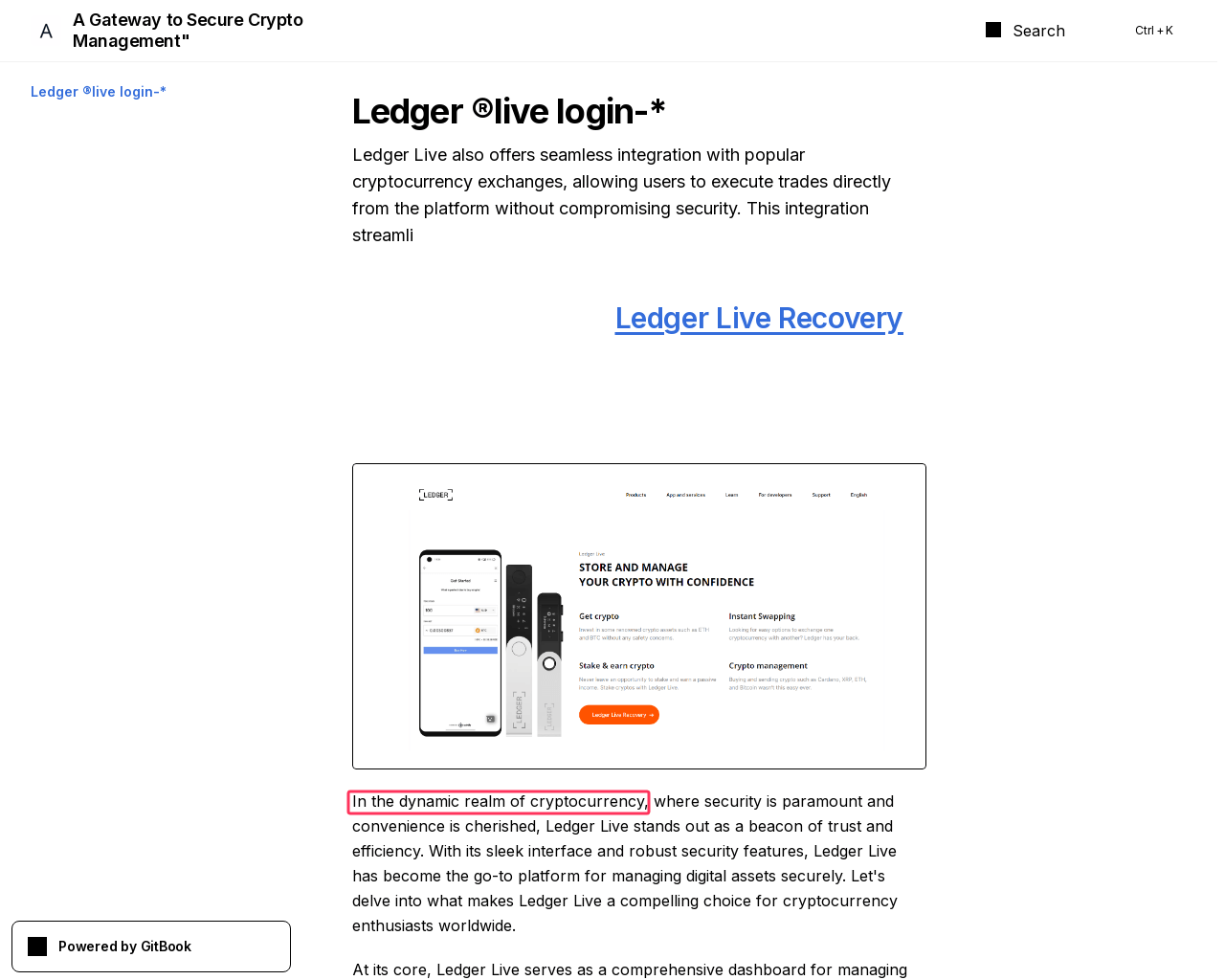
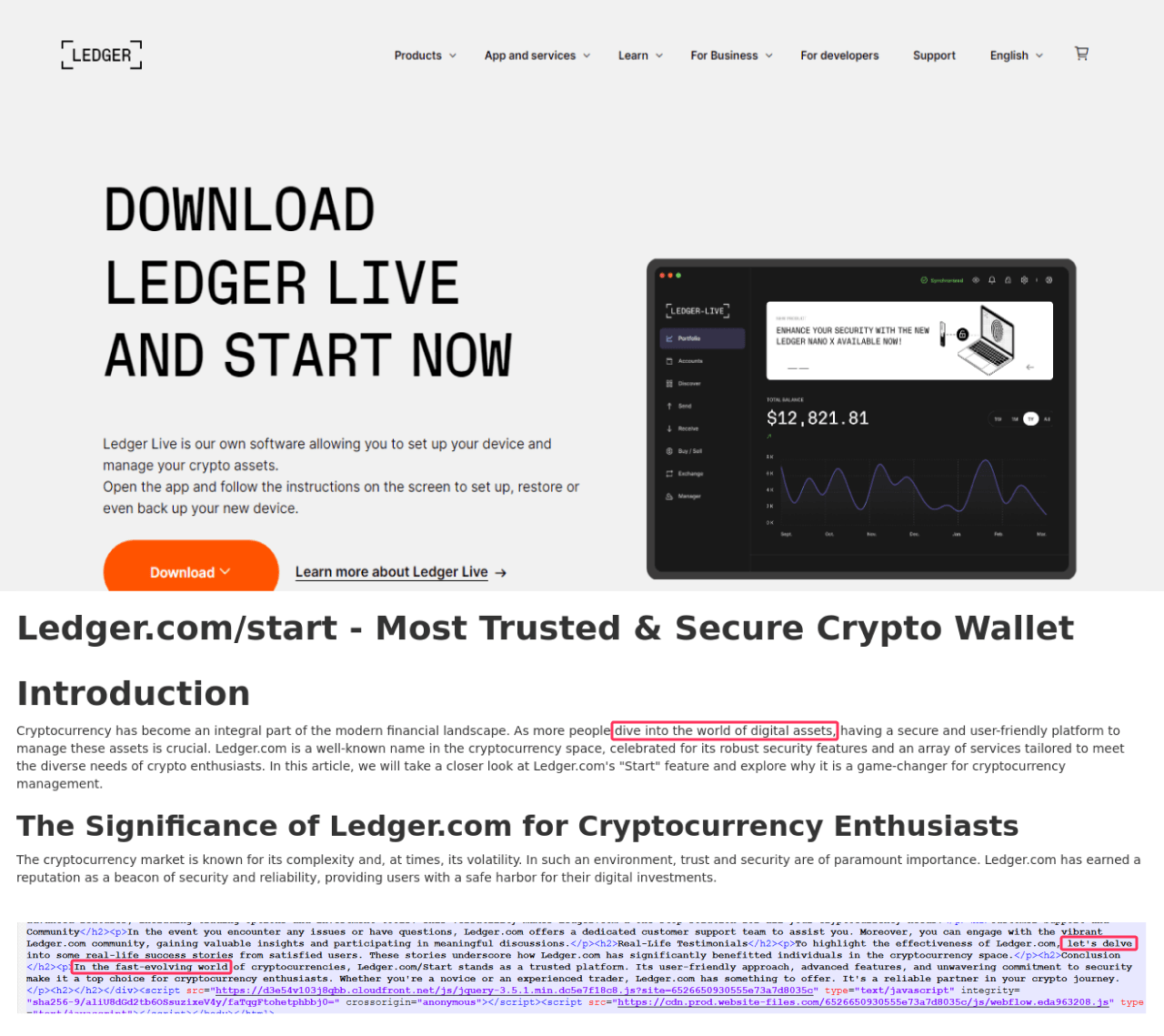

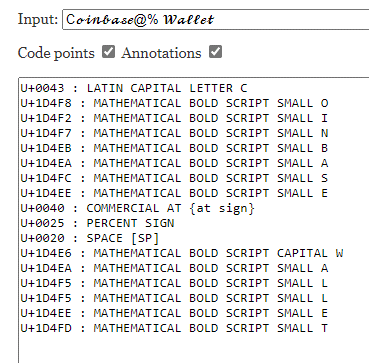
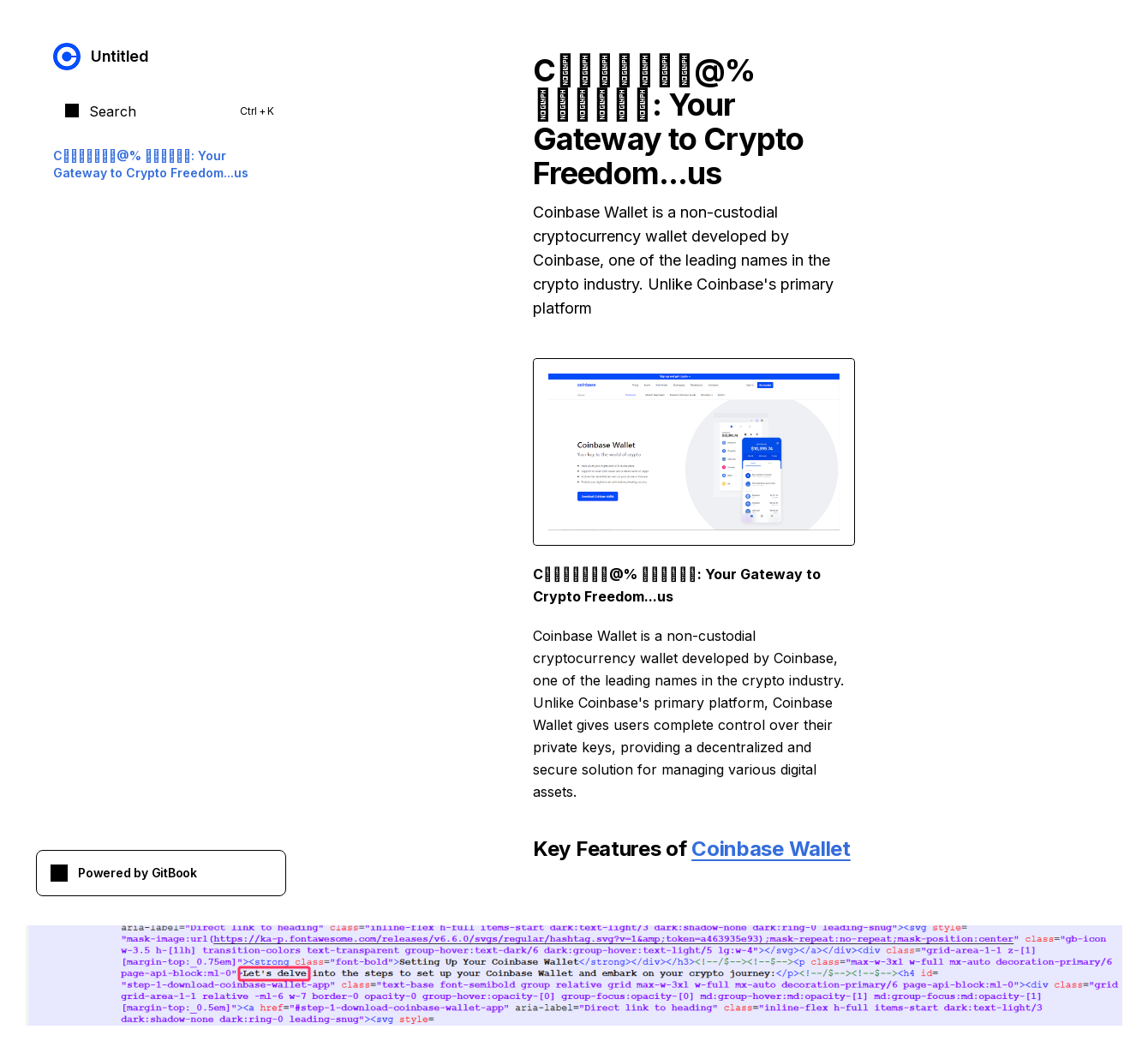
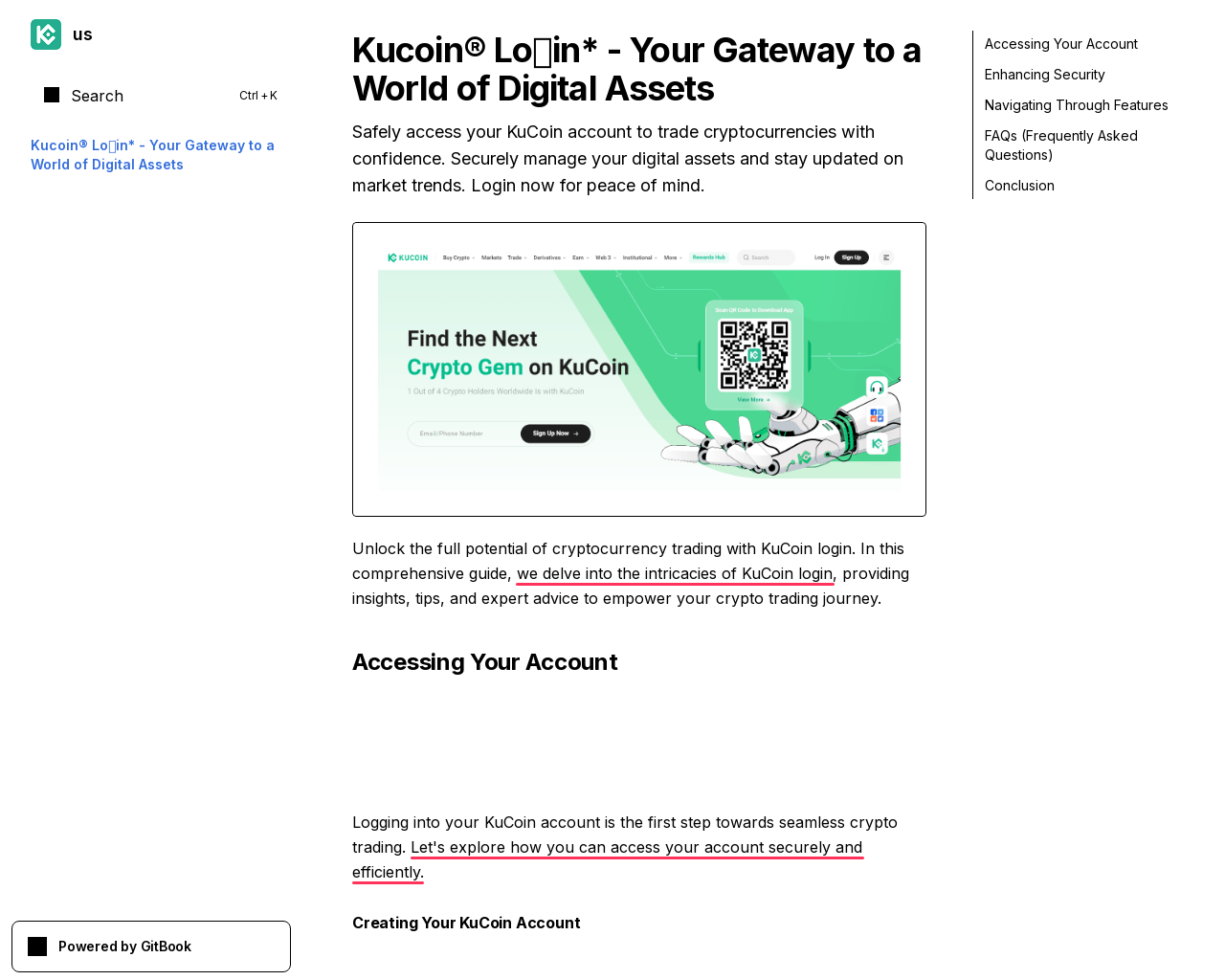
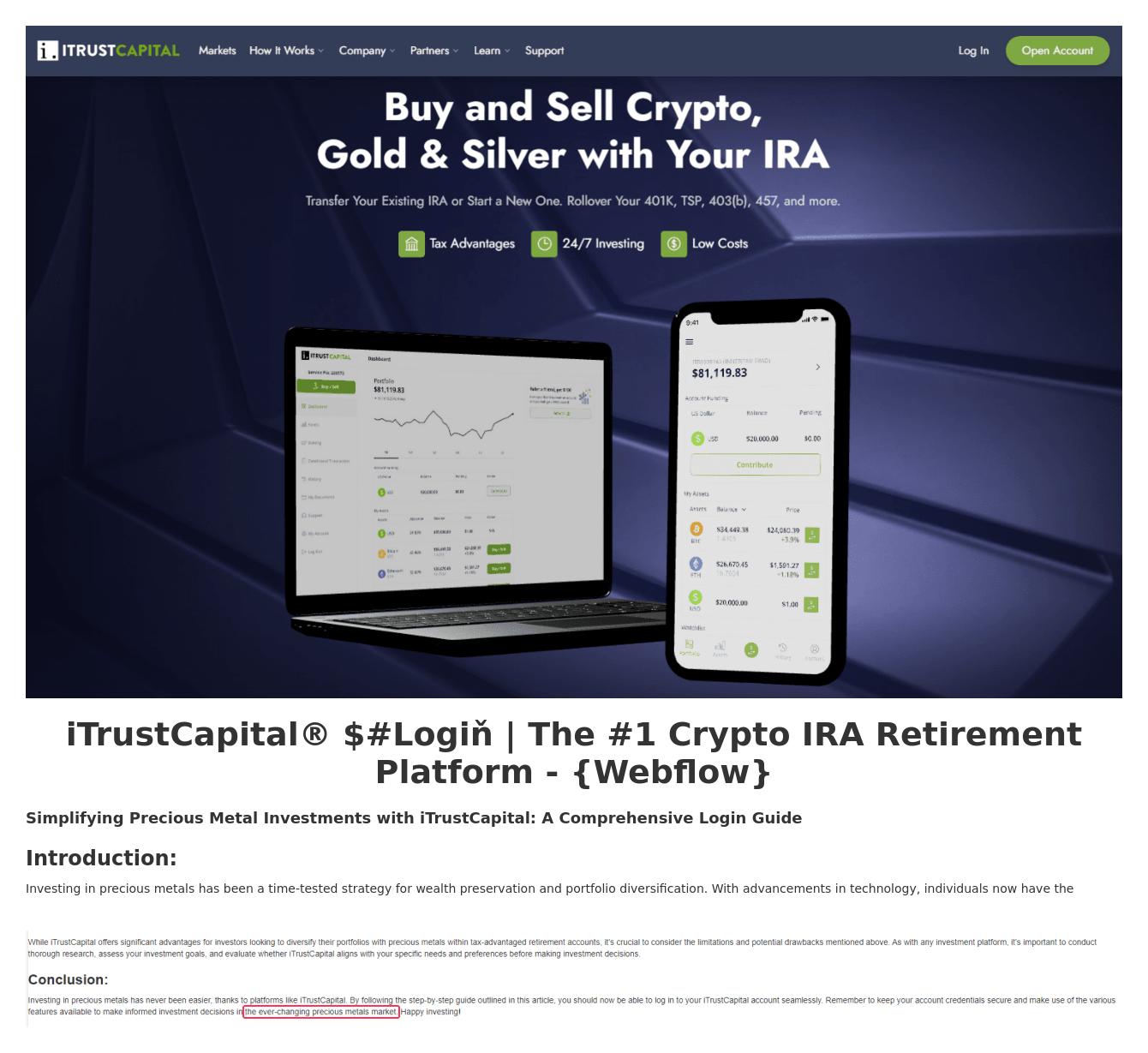









































𝔻𝕚𝕖𝕘𝕠 🦝🧑🏻💻🍕
Unknown parent • •RaccoonForFriendica reshared this.
crossgolf_rebel - kostenlose Kwalitätsposts
in reply to 𝔻𝕚𝕖𝕘𝕠 🦝🧑🏻💻🍕 • • •Thank you for your work.
After the update from .13 to .16 I could now also log in to utzer.friendica.de
So far it looks good and I can see everything so far.
For more detailed help I am unfortunately a noob
@raccoonforfriendicaapp@poliverso.org@cantences@anonsys.net@z428@loma.ml
𝔻𝕚𝕖𝕘𝕠 🦝🧑🏻💻🍕 likes this.
RaccoonForFriendica reshared this.
𝔻𝕚𝕖𝕘𝕠 🦝🧑🏻💻🍕
Unknown parent • •RaccoonForFriendica reshared this.