The media in this post is not displayed to visitors. To view it, please log in.

If you read a headline that signs of intelligent life were found on the moon, you might suspect a hoax. But they are there! Humans have dumped a lot of stuff on the moon, both in person and via uncrewed rockets. So after the apocalypse, what strange things will some alien exo-archaeologist find on our only natural satellite?
The Obvious
Of course, we’ve left parts of rockets, probes, and rovers. Only the top part of the Apollo Lunar Excursion Module left the moon. (See for yourself in the Apollo 17 ascent video below.) The bottoms are still there, along with the lunar rovers and a bunch of other science instruments and tools. There are boots and cameras, as you might expect.
But what about the strange things? As of 2012, NASA compiled a list of all known lunar junk that originated on Earth. The list starts with material from the non-Apollo US programs like the Surveyor and Lunar Prospector missions. Next up is the Apollo stuff, which is actually quite a bit: an estimated 400,000 pounds, we’ve heard. This ranges from the entire descent stage and lunar overshoes to urine bags. There are even commemorative patches and a gold olive branch.
After that, the list shows what’s known to be on the surface from the Russian space program, along with objects of Chinese, Indian, Japanese, and European origin.
youtube.com/embed/9HQfauGJaTs?…
The Sentimental
 An Apollo 1 patch made its way to the moon.
An Apollo 1 patch made its way to the moon.
Charles Duke on Apollo 16 left a framed family photo on the Moon’s surface with an inscription on the back. We figure if you go looking for it now, the sun will have bleached it white, but we appreciate the sentiment.
There are several objects meant to commemorate fallen astronauts and cosmonauts, including an Apollo 1 mission patch. You may recall that a fire during training killed all three of Apollo 1’s crew.
Lunar Prospector brought a portion of the ashes of Gene Shoemaker, a geologist who trained Apollo astronauts, to the moon. The capsule of ashes holds a quote from Romeo and Juliet:
And, when he shall dieTake him and cut him out in little stars
And he will make the face of heaven so fine
That all the world will be in love with night,
And pay no worship to the garish sun.
 A half-dollar-sized disc has 73 goodwill messages from world leaders.
A half-dollar-sized disc has 73 goodwill messages from world leaders.
To date, Shoemaker is the only person who has remains on the moon.
While not exactly sentimental, NASA did send a silicon disc to the moon with Apollo 11 containing goodwill messages from 73 countries. The whole thing is about the size of a US half dollar, so if you want to read the messages, you might be better off reading the associated document.
Making tiny silicon wafers with finely-detailed etchings was pretty high tech in the late 1960s. GCA Corp used a reduction camera to make a negative photomask containing all the letters plus an inscription around its edge at its final size. This mask was given to Sprague, who etched it.
The Odd
One of the strange things on the NASA list is a falcon feather. That was left by Apollo 15’s Davis Scott, who carried out the classic experiment of dropping a feather and a hammer to note that they fell at the same speed, even in the weak gravity of the moon. The feather was from Baggin, the Air Force Academy’s mascot, and remains on the lunar surface today.
youtube.com/embed/ZVfhztmK9zI?…
Speaking of Baggin, there are 96 bags of human waste sitting up there. Probably best not to bring that up the next time you and your partner are gazing at the romantic moon overhead.
The Unconfirmed
Forrest Myers created a small ceramic wafer with tiny artwork from six artists, like Andy Warhol, titled “Moon Museum.” The tile features six drawings, including a stylized “AW” (Warhol), a line (Robert Rauschenberg), a black square (David Novros), a diagram (John Chamberlain), Mickey Mouse (Claes Oldenburg), and an interlocking design (Myers). Apparently, Novros and Chamberlain were inspired by circuit diagrams of some kind.
Bell Labs created the wafer. However, NASA failed to approve the project, and Myers sought an alternative.
Reportedly, Myers gave the chip to an unnamed Apollo 12 engineer who affixed it to the leg of the lunar module. However, NASA has not confirmed this, so we don’t know for sure if it is up there or not. Perhaps if you get to the neighborhood, you can check it out and let us know?
To the Dump
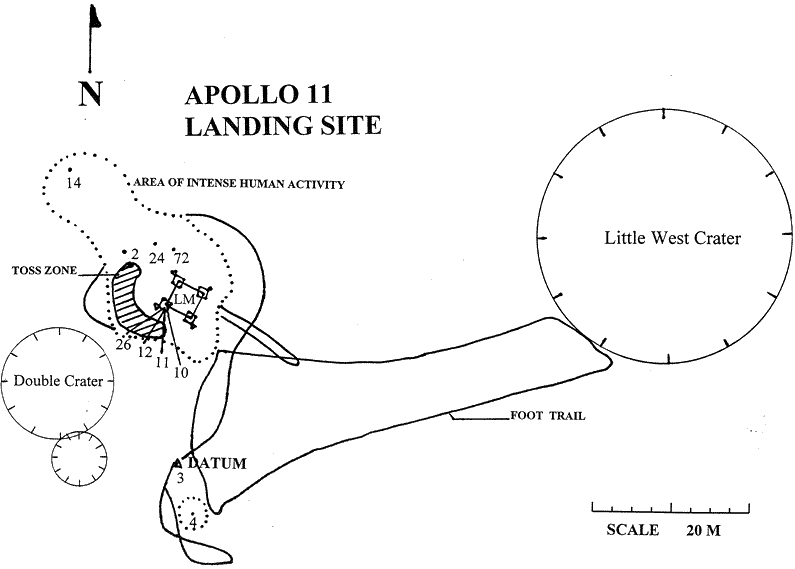
 Apollo 11 Landing Site Map from The Lunar Legacy Project (note “toss zone” to the left).
Apollo 11 Landing Site Map from The Lunar Legacy Project (note “toss zone” to the left).
You might wonder why so much stuff was left, but if you think about it, it makes sense. The rockets can only bring back so much stuff. Every camera you leave behind means more moon rocks you can bring home. You can buy a new camera, but you can’t buy more moon rocks.
According to the Lunar Legacy Project, Apollo 11, and presumably the other missions, had designated toss zones. (We guess “dumps” didn’t sound good.)
If you are looking for a more up-to-date list, the Wikipedia article can help fill in the gaps, at least for vehicles. There’s been quite a bit added since the NASA list, including items from the UAE, Israel, and Luxembourg. Plus, there are many new additions from other countries.
With the advent of high-resolution orbital cameras, you can see some of the landing sites better than ever. For example, the video below shows the Apollo 17 site imaged by the Lunar Reconnaissance Orbiter Camera.
youtube.com/embed/LIui93E8kkE?…
Of course, we are on our way back to the moon, and so are other space programs. So there will probably be even more human debris on the moon soon. It is only a matter of time before lunar waste management becomes a hot topic.
Title image “Map of artificial objects on the Moon” by [Footy2000]
hackaday.com/2026/04/22/what-h…

 - Collegamento all'originale")















InfoSecSherpa
in reply to Lorenzo Franceschi-Bicchierai • • •