 - Collegamento all'originale")
Quando l’MFA non basta! Abbiamo Violato il Login Multi-Fattore Per Capire Come Difenderci Meglio
Nel mondo della cybersecurity esiste una verità scomoda quanto inevitabile: per difendere davvero qualcosa, bisogna sapere come violarlo. L’autenticazione multi-fattore è una delle colonne portanti della sicurezza informatica moderna. Dovrebbe essere una barriera invalicabile per i criminali informatici. Ma cosa succede se quella barriera, invece di essere abbattuta con la forza bruta, viene semplicemente aggirata con astuzia?
È quello che il team cyber di Eurosystem, composto da Kevin Chierchia (Red Team – Malware Analyst), Fabio Lena (Red Team – Phishing & Awareness Specialist) e Leonardo Taverna (Cyber Security Intern), ha voluto scoprire. L’occasione è arrivata durante un’attività di Adversary Emulation per un cliente, dove l’obiettivo era valutare la resilienza reale delle difese aziendali contro scenari verosimili.
E così, è nata una domanda: “È possibile simulare un attacco phishing che riesca a superare anche l’autenticazione a più fattori?”.
Un’impresa che potrebbe sembrare contraddittoria: perché investire tempo e risorse per aggirare una delle più importanti misure di sicurezza esistenti? La risposta è semplice quanto inquietante: perché i criminali informatici lo stanno già facendo. E lo fanno bene.
È bene ricordare che simulazioni come questa devono sempre essere svolte in ambienti autorizzati e controllati, nel rispetto della legge e degli obiettivi condivisi con il cliente.
L’idea: MITM tra utente e portale, sfruttando un proxy
l principio alla base è tanto semplice quanto pericoloso: creare un proxy MITM (Man-In-The-Middle) che si frapponga tra la vittima e il vero portale di autenticazione. In questo modo, tutto ciò che l’utente inserisce – incluse le credenziali e i token MFA – viene intercettato in tempo reale e riutilizzato dall’attaccante per “loggarsi” prima che scada.
Durante la fase di ricerca, il team si è imbattuto nel documento “Top Phishing Techniques” di Hadess.io, che ha rappresentato una fonte di ispirazione concreta. Da lì, il passo verso la sperimentazione pratica è stato breve
Evilginx 3 e GoPhish: due volti dello stesso attacco, cocktail perfetto (e velenoso)
Il cuore del progetto è Evilginx 3, una piattaforma open source pensata per simulare attacchi man-in-the-middle (MitM) altamente sofisticati. A differenza dei classici attacchi di phishing, che mirano a sottrarre username e password, Evilginx è in grado di catturare anche i token di sessione emessi dopo l’autenticazione, rendendo di fatto inutile la protezione MFA in molte sue forme.
Evilginx agisce come un trasparent proxy: clona fedelmente le pagine di login dei principali provider (Microsoft 365, Google, Okta…) e inoltra tutto il traffico tra la vittima e il sito reale. L’utente inserisce le proprie credenziali, supera l’MFA, e nemmeno se ne accorge, perché la risposta arriva dal vero server. Ma nel frattempo, il token di sessione è stato intercettato e può essere utilizzato per accedere direttamente all’account compromesso.

Evilginx agisce come un transparent proxy: clona fedelmente le pagine di login dei principali provider (Microsoft 365, Google, Okta…) e inoltra tutto il traffico tra la vittima e il sito reale. L’utente inserisce le proprie credenziali, supera l’MFA, e nemmeno se ne accorge, perché la risposta arriva dal vero server. Ma nel frattempo, il token di sessione è stato intercettato e può essere utilizzato per accedere direttamente all’account compromesso.
Il team ha integrato Evilginx con GoPhish, potente framework di social engineering, per orchestrare campagne su larga scala, automatizzate, e personalizzate in base ai profili delle vittime. Il risultato? Una piattaforma ibrida, modulare e perfettamente aderente alle reali minacce che oggi si muovono nel dark web.


L’impatto reale: se anche l’MFA può cadere
Il risultato ha dimostrato quanto sia possibile – e realistico – orchestrare un attacco in grado di eludere anche una delle misure difensive più propagandate degli ultimi anni. Ma attenzione: non è un fallimento dell’MFA, né un invito a dismetterla. Quello che emerge da questo tipo di simulazioni non è solo una vulnerabilità tecnica, ma un problema sistemico. La fiducia cieca nelle tecnologie di autenticazione multifattore rischia di diventare il nuovo anello debole della catena. Non perché l’MFA non funzioni – al contrario, è una barriera indispensabile – ma perché non è infallibile. E soprattutto, non è sufficiente da sola.
youtube.com/embed/Py9X6uYK1RM?…
Video che riproduce l’intero attacco che è stato svolto
Le aziende spesso implementano l’MFA come “sigillo finale” della sicurezza, rilassandosi dietro alla sua presunta inviolabilità. Ma un attacco come quello veicolato tramite Evilginx dimostra che basta un clic sbagliato per far crollare l’intero castello. E quel clic, inutile dirlo, continua a essere umano.


La formazione: l’unico vero firewall umano
Siamo chiari: l’MFA è e resta una tecnologia fondamentale. Rinunciarvi sarebbe una follia.
Ma senza una cultura della sicurezza diffusa, senza un personale formato, consapevole, aggiornato e capace di riconoscere anche i segnali più sottili di un attacco, qualsiasi sistema è destinato a cedere.
Non c’è tecnologia che possa resistere all’ingenuità, alla fretta, alla distrazione. È per questo che ogni test che conduciamo serve non solo a collaudare le difese digitali, ma anche – e soprattutto – a risvegliare l’attenzione delle persone, mostrando loro che l’inganno può essere perfetto. Che la trappola può sembrare reale. Che la minaccia è dentro la posta elettronica, tutti i giorni.
Come ci si difende? Tecnologie sì, ma senza le persone non basta
Dopo aver dimostrato che anche l’MFA può essere aggirato, viene naturale chiedersi: come possiamo proteggerci davvero? La risposta non sta solo nella tecnologia, ma in un approccio multilivello che combina strumenti avanzati e formazione costante.
Le aziende dovrebbero iniziare a valutare l’adozione di soluzioni MFA resistenti al phishing, come FIDO2 o WebAuthn, che impediscono la riutilizzabilità dei token anche in caso di attacco MITM. Ma non basta. Serve monitoraggio delle sessioni, segmentazione della rete, controlli comportamentali e una solida politica di incident response.
E poi ci sono le persone. Perché puoi anche blindare ogni porta, ma se chi lavora in azienda non riconosce un finto portale o approva una notifica push MFA mentre è distratto, sei punto e a capo. Le campagne di phishing simulato, i momenti di formazione mirata e il coinvolgimento diretto sono ancora oggi tra le armi più potenti nella difesa aziendale.
In altre parole: la tecnologia è una barriera, ma la consapevolezza è l’antidoto. Chi si ferma all’MFA ha solo fatto il primo passo.
Conclusione: tra lupi e pecore, noi restiamo pastori armati
Abbiamo scelto di camminare sul filo sottile che separa l’attacco dalla difesa, convinti che solo esplorando il buio possiamo illuminare la strada. Evilginx 3 è solo uno degli strumenti che usiamo per questo viaggio nel lato oscuro della rete. Ma è anche una sveglia, una sirena, un urlo: la sicurezza non è mai definitiva. È un processo, una mentalità, una responsabilità condivisa.
Chi pensa che basti implementare l’MFA per dormire sonni tranquilli, si illude.
La sicurezza non è una scatola chiusa con un lucchetto, ma un equilibrio dinamico che si basa su tecnologia, processo e soprattutto persone formate e consapevoli.
E allora continuiamo a testare, a simulare, a violare. Non per distruggere, ma per proteggere meglio. Perché se non lo facciamo noi, lo faranno altri. E loro non verranno con buone intenzioni.
L'articolo Quando l’MFA non basta! Abbiamo Violato il Login Multi-Fattore Per Capire Come Difenderci Meglio proviene da il blog della sicurezza informatica.
Gazzetta del Cadavere reshared this.
MiSTer For Mortals: Meet the Multisystem 2

If you’ve ever squinted at a DE10-Nano wondering where the fun part begins, you’re not alone. This review of the Mr. MultiSystem 2 by [Lee] lifts the veil on a surprisingly noob-friendly FPGA console that finally gets the MiSTer experience out of the tinker cave and into the living room. Developed by Heber, the same UK wizards behind the original MultiSystem, this follow-up console dares to blend flexibility with simplicity. No stack required.
It comes in two varieties, to be precise: with, or without analog ports. The analog edition features a 10-layer PCB with both HDMI and native RGB out, Meanwell PSU support, internal USB headers, and even space for an OLED or NFC reader. The latter can be used to “load” physical cards cartridge-style, which is just ridiculously charming. Even the 3D-printed enclosure is open-source and customisable – drill it, print it, or just colour it neon green. And for once, you don’t need to be a soldering wizard to use the thing. The FPGA is integrated in the mainboard. No RAM modules, no USB hub spaghetti. Just add some ROMs (legally, of course), and you’re off.
Despite its plug-and-play aspirations, there are some quirks – for example, the usual display inconsistencies and that eternal jungle of controller mappings. But hey, if that’s the price for versatility, it’s one you’d gladly pay. And if you ever get stuck, the MiSTer crowd will eat your question and spit out 12 solutions. It remains 100% compatible with the MiSTer software, but allows some additional future features, should developers wish to support them.
Want to learn more? This could be your entrance to the MiSTer scene without having to first earn a master’s in embedded systems. Will this become an alternative to the Taki Udon announced Playstation inspired all-in-one FPGA console, which does require a DE-10 (or compatible)? Check the video here and let us know in the comments.
youtube.com/embed/UVx08a-dZRY?…
Assemblea del Tg3 – Chiediamo libertà d’informazione a Gaza: lasciateci entrare nella Striscia
I giornalisti non devono essere un bersaglio, lasciateci entrare a Gaza.
Di fronte alla drammatica situazione nella Striscia, l’opinione pubblica mondiale continua a non poter avere notizie raccolte in modo autonomo e indipendente.
Oltre 200 colleghi sono stati uccisi in Palestina dall’inizio del conflitto, molti di più che in ogni altra guerra dell’ultimo secolo.
Agli inviati internazionali viene impedito di accedere per fare il loro lavoro in modo autonomo e sicuro.
L’assemblea delle giornaliste e dei giornalisti del Tg3, all’unanimità, lancia un appello alle autorità israeliane affinché torni possibile adempiere al diritto dovere di raccontare con obiettività quanto accade, in particolare alla popolazione civile.
L’opinione pubblica deve poter vigilare sul rispetto del diritto internazionale e dei principi di umanità.
Vogliamo proseguire nel racconto delle sofferenze di chi è innocente, a partire dai bambini, come abbiamo sempre fatto con il massimo dell’impegno e della professionalità fin dal terribile attacco terroristico di Hamas del 7 ottobre.
La redazione del Tg3 osserva peraltro con preoccupazione la difficoltà crescente di testimonianza un po’ ovunque nel mondo, con i giornalisti divenuti target anche in Ucraina e altri contesti e con il rilascio dei visti giornalistici sempre più complicato in molti paesi, ostacolo spesso insormontabile e che limita il nostro lavoro.
L’Assemblea del Tg3
Gazzetta del Cadavere reshared this.
Space Threat Landscape 2025, le sfide alle porte e come affrontarle
@Informatica (Italy e non Italy 😁)
La principale agenzia per la cyber security dell'UE ha pubblicato un nuovo rapporto dettagliato che delinea il panorama delle minacce e raccomanda misure per mitigare i rischi più gravi nel settore spaziale
L'articolo Space Threat Landscape 2025, le sfide alle porte e
reshared this
Ben(e)detto – Le insicurezze del Decreto Sicurezza
@Politica interna, europea e internazionale
Martedì 20 maggio 2025, ore 21:00 Con Gian Domenico Caiazza e Andrea Ostellari
L'articolo Ben(e)detto – Le insicurezze del Decreto Sicurezza proviene da Fondazione Luigi Einaudi.
Politica interna, europea e internazionale reshared this.
Grave Falla RCE in Remote Desktop Gateway (RD Gateway). Aggiornare Subito
Una vulnerabilità critica nel Remote Desktop Gateway (RD Gateway) di Microsoft che potrebbe consentire agli aggressori di eseguire codice dannoso sui sistemi interessati da remoto. Il difetto, è stato scoperto e segnalato da VictorV (Tang Tianwen) del Kunlun Lab, e deriva da un bug di tipo use-after-free (UAF) attivato da connessioni socket simultanee durante l’inizializzazione del servizio Remote Desktop Gateway.
Remote Desktop Gateway (RD Gateway) è un ruolo di Microsoft Windows Server che consente agli utenti remoti di accedere alle risorse interne in modo sicuro ed efficiente tramite Internet. “La vulnerabilità si verifica quando più thread possono sovrascrivere lo stesso puntatore globale, corrompendo i conteggi dei riferimenti e portando infine alla dereferenziazione di un puntatore sospeso, uno scenario UAF classico”, spiega l’avviso di sicurezza .
La vulnerabilità, identificata come CVE-2025-21297 alla quale è stato assegnato uno score CVSSv3 pari ad 8.1, è stata divulgata da Microsoft nei suoi aggiornamenti di sicurezza di gennaio 2025 e da allora è stata attivamente sfruttata.
Nello specifico, la vulnerabilità esiste nella libreria aaedge.dll, all’interno della funzione CTsgMsgServer::GetCTsgMsgServerInstance, dove un puntatore globale (m_pMsgSvrInstance) viene inizializzato senza un’adeguata sincronizzazione dei thread. Secondo i ricercatori, per sfruttare con successo un attacco è necessario che l’aggressore:
- Connettersi a un sistema che esegue il ruolo Gateway Desktop remoto;
- Attiva connessioni simultanee al RD Gateway (tramite più socket);
- Sfruttare il problema di temporizzazione per cui l’allocazione della memoria e l’assegnazione dei puntatori non sono sincronizzate.
- Fare in modo che una connessione sovrascriva il puntatore prima che un’altra finisca di farvi riferimento.
Sono vulnerabili diverse versioni di Windows Server che utilizzano RD Gateway per l’accesso remoto sicuro, tra cui:
- Windows Server 2016 (installazioni Core e Standard).
- Windows Server 2019 (installazioni Core e Standard).
- Windows Server 2022 (installazioni Core e Standard).
- Windows Server 2025 (installazioni Core e Standard).
Le organizzazioni che utilizzano RD Gateway come punto di accesso fondamentale per dipendenti, collaboratori o partner che lavorano da remoto sono particolarmente a rischio. Microsoft ha risolto questa vulnerabilità nel
Patch Tuesday di maggio 2025, introducendo la sincronizzazione basata su mutex, garantendo che un solo thread possa inizializzare l’istanza globale in un dato momento.
L'articolo Grave Falla RCE in Remote Desktop Gateway (RD Gateway). Aggiornare Subito proviene da il blog della sicurezza informatica.
In Memory of Ed Smylie, Whose Famous Hack Saved the Apollo 13 Crew

Some hacks are so great that when you die you receive the rare honor of both an obituary in the New York Times and an in memoriam article at Hackaday.
The recently deceased, Ed Smylie, was a NASA engineer leading the effort to save the crew of Apollo 13 with a makeshift gas conduit made from plastic bags and duct tape back in the year 1970. Ed died recently, on April 21, in Crossville, Tennessee, at the age of 95.
This particular hack, another in the long and storied history of duct tape, literally required putting a square peg in a round hole. After an explosion on the Apollo 13 command module the astronauts needed to escape on the lunar excursion module. But the lunar module was only designed to support two people, not three.
The problem was that there was only enough lithium hydroxide onboard the lunar module to filter the air for two people. The astronauts could salvage lithium hydroxide canisters from the command module, but those canisters were square. Ed and his team famously designed the required adapter from a small inventory of materials available on the space craft. This celebrated story has been told many times, including in the 1995 film, Apollo 13.
Thank you, Ed, for one of the greatest hacks of all time. May you rest in peace.
Header: Gas conduit adapter designed by Ed Smylie, NASA, Public domain.
reshared this
Intelligenza Artificiale: Implementazione del meccanismo dell’attenzione in Python
Il meccanismo di attenzione è spesso associato all’architettura dei transformers, ma era già stato utilizzato nelle RNN (reti ricorrenti).
Nei task di traduzione automatica (ad esempio, inglese-italiano), quando si vuole prevedere la parola italiana successiva, è necessario che il modello si concentri, o presti attenzione, sulle parole inglesi più importanti nell’input, utili per ottenere una buona traduzione.
Non entrerò nei dettagli delle RNN, ma l’attenzione ha aiutato questi modelli a mitigare il problema vanishing gradient, e a catturare più dipendenze a lungo raggio tra le parole.

A un certo punto, abbiamo capito che l’unica cosa importante era il meccanismo di attenzione e che l’intera architettura RNN era superflua. Quindi, Attention is All You Need!
Self-Attention nei Transformers
L’attenzione classica indica dove le parole della sequenza in output devono porre attenzione rispetto alle parole della sequenza di input. È importante in task del tipo sequence-to-sequence come la traduzione automatica.
La self-attention è un tipo specifico di attenzione. Opera tra due elementi qualsiasi della stessa sequenza. Fornisce informazioni su quanto siano “correlate” le parole nella stessa frase.
Per un dato token (o parola) in una sequenza, la self-attention genera un elenco di pesi di attenzione corrispondenti a tutti gli altri token della sequenza. Questo processo viene applicato a ogni token della frase, ottenendo una matrice di pesi di attenzione (come nella figura).
Questa è l’idea generale, in pratica le cose sono un po’ più complicate perché vogliamo aggiungere molti parametri/pesi nell nostra rete, in modo che il modella abbia più capacità di apprendimento.

Le rappresentazioni K, V, Q
L’input del nostro modello è una frase come “mi chiamo Marcello Politi”. Con il processo di tokenizzazione, una frase viene convertita in un elenco di numeri come [2, 6, 8, 3, 1].
Prima di passare la frase al transformer, dobbiamo creare una rappresentazione densa per ogni token.
Come creare questa rappresentazione? Moltiplichiamo ogni token per una matrice. La matrice viene appresa durante l’addestramento.
Aggiungiamo ora un po’ di complessità.
Per ogni token, creiamo 3 vettori invece di uno, che chiamiamo vettori: chiave (K), valore (V) e domanda (Q). (Vedremo più avanti come creare questi 3 vettori).
Concettualmente questi 3 token hanno un significato particolare:

- La chiave del vettore rappresenta l’informazione principale catturata dal token.
- Il valore del vettore cattura l’informazione completa di un token.
- Il vettore query, è una domanda sulla rilevanza del token per il task corrente.
L’idea è che ci concentriamo su un particolare token i e vogliamo chiedere qual è l’importanza degli altri token della frase rispetto al token i che stiamo prendendo in considerazione.
Ciò significa che prendiamo il vettore q_i (poniamo una domanda relativa a i) per il token i, e facciamo alcune operazioni matematiche con tutti gli altri token k_j (j!=i). È come se ci chiedessimo a prima vista quali sono gli altri token della sequenza che sembrano davvero importanti per capire il significato del token i.
Ma qual’è questa operazione magica?
Dobbiamo moltiplicare (dot-product) il vettore della query per i vettori delle chiavi e dividere per un fattore di normalizzazione. Questo viene fatto per ogni token k_j.

In questo modo, otteniamo uno scroe per ogni coppia (q_i, k_j). Trasformiamo questi score in una distribuzione di probabilità applicandovi un’operazione di softmax. Bene, ora abbiamo ottenuto i pesi di attenzione!
Con i pesi di attenzione, sappiamo qual è l’importanza di ogni token k_j per indistinguere il token i. Quindi ora moltiplichiamo il vettore di valore v_j associato a ogni token per il suo peso e sommiamo i vettori. In questo modo otteniamo il vettore finale context-aware del token_i.
Se stiamo calcolando il vettore denso contestuale del token_1, calcoliamo:
z1 = a11v1 + a12v2 + … + a15*v5
Dove a1j sono i pesi di attenzione del computer e v_j sono i vettori di valori.
Fatto! Quasi…
Non ho spiegato come abbiamo ottenuto i vettori k, v e q di ciascun token. Dobbiamo definire alcune matrici w_k, w_v e w_q in modo che quando moltiplichiamo:
- token * w_k -> k
- token * w_q -> q
- token * w_v -> v
Queste tre matrici sono inizializzate in modo casuale e vengono apprese durante l’addestramento; questo è il motivo per cui abbiamo molti parametri nei modelli moderni come gli LLM.
Multi-Head Self-Attention (MHSA) nei Transformers
Siamo sicuri che il precedente meccanismo di self-attention sia in grado di catturare tutte le relazioni importanti tra i token (parole) e di creare vettori densi di quei token che abbiano davvero senso?
In realtà potrebbe non funzionare sempre perfettamente. E se, per mitigare l’errore, si rieseguisse l’intera operazione due volte con nuove matrici w_q, w_k e w_v e si unissero in qualche modo i due vettori densi ottenuti? In questo modo forse una self-attention è riuscita a cogliere qualche relazione e l’altra è riuscita a cogliere qualche altra relazione.
Ebbene, questo è ciò che accade esattamente in MHSA. Il caso appena discusso contiene due head (teste), perché ha due insiemi di matrici w_q, w_k e w_v. Possiamo avere anche più head: 4, 8, 16, ecc.
L’unica cosa complicata è che tutte queste teste vengono gestite in parallelo, elaborandole tutte nello stesso calcolo utilizzando i tensori.
Il modo in cui uniamo i vettori densi di ogni head è semplice, li concateniamo (quindi la dimensione di ogni vettore deve essere più piccola, in modo che quando li concateniamo otteniamo la dimensione originale che volevamo) e passiamo il vettore ottenuto attraverso un’altra matrice imparabile w_o.

Hands-on
Supponiamo di avere una frase. Dopo la tokenizzazione, ogni token (o parola) corrisponde a un indice (numero):
tokenized_sentence = torch.tensor([
2, #my
6, #name
8, #is
3, #marcello
1 #politi
])
tokenized_sentence
Prima di passare la frase nel transformer, dobbiamo creare una rappresentazione densa per ciascun token.
Come creare questa rappresentazione? Moltiplichiamo ogni token per una matrice. Questa matrice viene appresa durante l’addestramento.
Costruiamo questa matrice, chiamata matrice di embedding.
torch.manual_seed(0) # set a fixed seed for reproducibility
embed = torch.nn.Embedding(10, 16)
Se moltiplichiamo la nostra frase tokenizzata con la matrice di embedding, otteniamo una rappresentazione densa di dimensione 16 per ogni token
sentence_embed = embed(tokenized_sentence).detach()
sentence_embed
Per utilizzare il meccanismo di attenzione dobbiamo creare 3 nuove matrici w_q, w_k e w_v. Moltiplicando un token di ingresso per w_q otteniamo il vettore q. Lo stesso vale per w_k e w_v.
d = sentence_embed.shape[1] # let's base our matrix on a shape (16,16)
w_key = torch.rand(d,d)
w_query = torch.rand(d,d)
w_value = torch.rand(d,d)
Calcolo dei pesi di attenzione
Calcoliamo ora i pesi di attenzione solo per il primo token della frase.
token1_embed = sentence_embed
[0]#compute the tre vector associated to token1 vector : q,k,v
key_1 = w_key.matmul(token1_embed)
query_1 = w_query.matmul(token1_embed)
value_1 = w_value.matmul(token1_embed)
print("key vector for token1: \n", key_1)
print("query vector for token1: \n", query_1)
print("value vector for token1: \n", value_1)
Dobbiamo moltiplicare il vettore query associato al token1 (query_1) con tutte le chiavi degli altri vettori.
Quindi ora dobbiamo calcolare tutte le chiavi (chiave_2, chiave_2, chiave_4, chiave_5). Ma aspettate, possiamo calcolarle tutte in una sola volta moltiplicando sentence_embed per la matrice w_k.
keys = sentence_embed.matmul(w_key.T)
keys[0] #contains the key vector of the first token and so on
Facciamo la stessa cosa con i valori
values = sentence_embed.matmul(w_value.T)
values[0] #contains the value vector of the first token and so on
Calcoliamo la prima parte della formula adesso.
import torch.nn.functional as F

# the following are the attention weights of the first tokens to all the others
a1 = F.softmax(query_1.matmul(keys.T)/d**0.5, dim = 0)
a1
Con i pesi di attenzione sappiamo qual è l’importanza di ciascun token. Quindi ora moltiplichiamo il vettore di valori associato a ogni token per il suo peso.
Per ottenere il vettore finale del token_1 che includa anche il contesto.
z1 = a1.matmul(values)
z1
Allo stesso modo, possiamo calcolare i vettori densi consapevoli del contesto di tutti gli altri token. Ora stiamo utilizzando sempre le stesse matrici w_k, w_q, w_v. Diciamo che usiamo una sola head.
Ma possiamo avere più triplette di matrici, quindi una multi-heads. Ecco perché si chiama multi-head attention.
I vettori densi di un token in ingresso, dati in input a ciascuna head, vengono poi concatenati e trasformati linearmente per ottenere il vettore denso finale.
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(0) #
# Tokenized sentence (same as yours)
tokenized_sentence = torch.tensor([2, 6, 8, 3, 1]) # [my, name, is, marcello, politi]
# Embedding layer: vocab size = 10, embedding dim = 16
embed = nn.Embedding(10, 16)
sentence_embed = embed(tokenized_sentence).detach() # Shape: [5, 16] (seq_len, embed_dim)
d = sentence_embed.shape[1] # embed dimension 16
h = 4 # Number of heads
d_k = d // h # Dimension per head (16 / 4 = 4)
# Define weight matrices for each head
w_query = torch.rand(h, d, d_k) # Shape: [4, 16, 4] (one d x d_k matrix per head)
w_key = torch.rand(h, d, d_k) # Shape: [4, 16, 4]
w_value = torch.rand(h, d, d_k) # Shape: [4, 16, 4]
w_output = torch.rand(d, d) # Final linear layer: [16, 16]
# Compute Q, K, V for all tokens and all heads
# sentence_embed: [5, 16] -> Q: [4, 5, 4] (h, seq_len, d_k)
queries = torch.einsum('sd,hde->hse', sentence_embed, w_query) # h heads, seq_len tokens, d dim
keys = torch.einsum('sd,hde->hse', sentence_embed, w_key) # h heads, seq_len tokens, d dim
values = torch.einsum('sd,hde->hse', sentence_embed, w_value) # h heads, seq_len tokens, d dim
# Compute attention scores
scores = torch.einsum('hse,hek->hsk', queries, keys.transpose(-2, -1)) / (d_k ** 0.5) # [4, 5, 5]
attention_weights = F.softmax(scores, dim=-1) # [4, 5, 5]
# Apply attention weights
head_outputs = torch.einsum('hij,hjk->hik', attention_weights, values) # [4, 5, 4]
head_outputs.shape
# Concatenate heads
concat_heads = head_outputs.permute(1, 0, 2).reshape(sentence_embed.shape[0], -1) # [5, 16]
concat_heads.shape
multihead_output = concat_heads.matmul(w_output) # [5, 16] @ [16, 16] -> [5, 16]
print("Multi-head attention output for token1:\n", multihead_output[0])
Conclusioni
In questo post ho implementato una versione semplice del meccanismo di attenzione. Questo non è il modo in cui viene realmente implementato nei framework moderni, ma il mio scopo è quello di fornire alcuni spunti per permettere a chiunque di capire come funziona. Nei prossimi articoli analizzerò l’intera implementazione di un’architettura transformer.
L'articolo Intelligenza Artificiale: Implementazione del meccanismo dell’attenzione in Python proviene da il blog della sicurezza informatica.
Malwareless attacks: “Ciao sono del reparto IT. Installa AnyDesk così risolviamo subito il problema”
Gli attacchi di phishing hanno nuovamente attirato l’attenzione degli esperti di sicurezza informatica. Questa volta è diventato attivo il gruppo Luna Moth, noto anche come Silent Ransom Group. Il suo obiettivo era ottenere l’accesso ai sistemi interni di organizzazioni legali e finanziarie negli Stati Uniti per poi estorcere denaro tramite la minaccia di fuga di dati. Una nuova ondata di attacchi è iniziata a marzo 2025 e dimostra un elevato livello di ingegneria sociale senza l’uso di malware.
Lo scenario di attacco si basa sull’imitazione del supporto tecnico. Le vittime ricevono e-mail in cui viene chiesto loro di contattare un presunto reparto IT aziendale. Dopo la chiamata, gli aggressori ti convincono a installare sul tuo computer un software legittimo per il controllo remoto, come AnyDesk, Atera, Syncro, Zoho Assist, Splashtop e altri. Questi programmi sono firmati digitalmente e non destano sospetti da parte degli strumenti di sicurezza. Una volta connessi, gli aggressori ottengono accesso diretto alla postazione di lavoro e possono esaminare il contenuto del sistema, delle unità di rete e di altri dispositivi nell’infrastruttura.
Secondo EclecticIQ, i domini simili agli indirizzi dei veri servizi di supporto vengono utilizzati a scopo di camuffamento. In totale sono stati registrati almeno 37 nomi di dominio di questo tipo tramite GoDaddy. Nella maggior parte dei casi utilizzano nomi falsi, utilizzando le parole chiave “helpdesk” o “supporto” riferendosi a un’azienda specifica, il che consente loro di ingannare con successo i dipendenti delle organizzazioni.
Dopo aver ottenuto l’accesso ai dati, gli aggressori li caricano sui propri server utilizzando le utility WinSCP e Rclone, per poi inviare minacce alle vittime chiedendo il pagamento di un riscatto. Il rifiuto è seguito dalla promessa di pubblicare i dati rubati sulla pagina pubblica di Luna Moth. Secondo EclecticIQ, l’importo del riscatto varia da uno a otto milioni di dollari, a seconda della rilevanza e della portata delle informazioni rubate.
La particolare pericolosità di questi attacchi è evidenziata dall’assenza di allegati dannosi o link infetti. Tutte le interazioni avvengono all’interno di canali legittimi e il software viene installato dagli utenti stessi con il pretesto di ricevere assistenza. Questo schema complica seriamente il rilevamento degli incidenti e richiede una revisione delle politiche di sicurezza all’interno delle aziende. Le misure consigliate includono il blocco degli strumenti RMM inutilizzati e l’inserimento nella blacklist dei domini di phishing noti.
Inoltre l’installazione di software sulle PDL da parte degli utenti dovrebbe essere disabilitata by design.
L'articolo Malwareless attacks: “Ciao sono del reparto IT. Installa AnyDesk così risolviamo subito il problema” proviene da il blog della sicurezza informatica.
Designing A Hobbyist’s Semiconductor Dopant

[ProjectsInFlight] has been on a mission to make his own semiconductors for about a year now, and recently shared a major step toward that goal: homemade spin-on dopants. Doping semiconductors has traditionally been extremely expensive, requiring either ion-implantation equipment or specialized chemicals for thermal diffusion. [ProjectsInFlight] wanted to use thermal diffusion doping, but first had to formulate a cheaper dopant.
Thermal diffusion doping involves placing a source of dopant atoms (phosphorus or boron in this case) on top of the chip to be doped, heating the chip, and letting the dopant atoms diffuse into the silicon. [ProjectsInFlight] used spin-on glass doping, in which an even layer of precursor chemicals is spin-coated onto the chip. Upon heating, the precursors decompose to leave behind a protective film of glass containing the dopant atoms, which diffuse out of the glass and into the silicon.
After trying a few methods to create a glass layer, [ProjectsInFlight] settled on a composition based on tetraethyl orthosilicate, which we’ve seen used before to create synthetic opals. After finding this method, all he had to do was find the optimal reaction time, heating, pH, and reactant proportions. Several months of experimentation later, he had a working solution.
After some testing, he found that he could bring silicon wafers from their original light doping to heavy doping. This is particularly impressive when you consider that his dopant is about two orders of magnitude cheaper than similar commercial products.
Of course, after doping, you still need to remove the glass layer with an oxide etchant, which we’ve covered before. If you prefer working with lasers, we’ve also seen those used for doping.
youtube.com/embed/1dFj-tGn8DI?…
instagram.com/reel/DJMdfVrKGPa…
=
mega.nz/file/KkMiHZhS#oWjNzN0R…
I from time to time post this short video: listen to #GideonLevy, since he simply speaks the truth.
#apartheid #racism #EthnicCleansing #genocide #Gaza #Palestine
reshared this
Hackaday Links: May 18, 2025

Saw what you want about the wisdom of keeping a 50-year-old space mission going, but the dozen or so people still tasked with keeping the Voyager mission running are some major studs. That’s our conclusion anyway, after reading about the latest heroics that revived a set of thrusters on Voyager 1 that had been offline for over twenty years. The engineering aspects of this feat are interesting enough, but we’re more interested in the social engineering aspects of this exploit, which The Register goes into a bit. First of all, even though both Voyagers are long past their best-by dates, they are our only interstellar assets, and likely will be for centuries to come, or perhaps forever. Sure, the rigors of space travel and the ravages of time have slowly chipped away at what these machines can so, but while they’re still operating, they’re irreplaceable assets.
That makes the fix to the thruster problem all the more ballsy, since the Voyager team couldn’t be 100% sure about the status of the primary thrusters, which were shut down back in 2004. They thought it might have been that the fuel line heaters were still good, but if they actually had gone bad, trying to switch the primary thrusters back on with frozen fuel lines could have resulted in an explosion when Voyager tried to fire them, likely ending in a loss of the spacecraft. So the decision to try this had to be a difficult one, to say the least. Add in an impending shutdown of the only DSN antenna capable of communicating with the spacecraft and a two-day communications round trip, and the pressure must have been unbearable. But they did it, and Voyager successfully navigated yet another crisis. But what we’re especially excited about is discovering a 2023 documentary about the current Voyager mission team called “It’s Quieter in the Twilight.” We know what we’ll be watching this weekend.
youtube.com/embed/RIP1p5gAoak?…
Speaking of space exploration, one thing you don’t want to do is send anything off into space bearing Earth microbes. That would be a Very Bad Thing
Closer to home but more terrifying is video from an earthquake in Myanmar that has to be seen to be believed. And even then, what’s happening in the video is hard to wrap your head around. It’s not your typical stuff-falling-off-the-shelf video; rather, the footage is from an outdoor security camera that shows the ground outside of a gate literally ripping apart during the 7.7 magnitude quake in March. The ground just past the fence settles a bit while moving away from the camera a little, but the real action is the linear motion — easily three meters in about two seconds. The motion leaves the gate and landscaping quivering but largely intact; sadly, the same can’t be said for a power pylon in the distance, which crumples as if it were made from toothpicks.
youtube.com/embed/77ubC4bcgRM?…
And finally, “Can it run DOOM?” has become a bit of a meme in our community, a benchmark against which hacking chops can be measured. If it has a microprocessor in it, chances are someone has tried to make it run the classic first-person shooter video game. We’ve covered dozens of these hacks before, everything from a diagnostic ultrasound machine to a custom keyboard keycap, while recent examples tend away from hardware ports to software platforms such as a PDF file, Microsoft Word, and even SQL. Honestly, we’ve lost count of the ways to DOOM, which is where Can It Run Doom? comes in handy. It lists all the unique platforms that hackers have tortured into playing the game, as well as links to source code and any relevant video proof of the exploit. Check it out the next time you get the urge to port DOOM to something cool; you wouldn’t want to go through all the work to find out it’s already been done, would you?
allergia - sgrunt!
maledette #graminacee! 🤧🤧😭ho consumato mille fazzoletti (cit.)
pollenundallergie.ch/informazi…
#allergia #nasochecola #occhicheprudono

Pollini e allergie - Graminacee
Grado d'allergia molto alto; le graminacee rappresentano il principale allergene del polline; quasi tutti le specie di graminacee provocano allergie.www.pollenundallergie.ch
Speed Up Arduino with Clever Coding

We love Arduino here at Hackaday; they’ve probably done more to make embedded programming accessible to more people than anything else in the history of the field. One thing the Arduino ecosystem is rarely praised for is its speed. That’s where [Playduino] comes in, with his video (embedded below) that promises to make everyone’s favourite microcontroller run 50x faster.
You might be expecting an unstable overclocking setup, with swapped crystals, tweaked voltages and a hefty heat sink, but no! This is stock hardware. The 50x speedup comes from one simple hack: don’t use digitalWrite();
If you aren’t familiar, the digitalWrite() function is one of the key functions Arduino gives you to operate its boards– specify the pin and the value (high or low) to drive it. It’s very easy, but it’s also very slow. [Playduino] takes a moment to show just how much is going on under the hood when you call digitalWrite(), and shows you what you can do instead if you have a need for speed. (Hint: there’s no Arduino-provided code involved; hardware registers and the __asm keyword show up.)
If you learned embedded programming in an earlier era, this will probably seem glaringly obvious. If you, like so many of us, got started inside of the Arduino ecosystem, these closer-to-the-metal programming techniques could prove useful tools in your quiver. Big thanks to [Stephan Walters] for the tip.
Of course if you prefer to speed things up by hardware rather than software, you can overclock an Arduino– with liquid nitrogen, even.
youtube.com/embed/hRqJkfB8uoE?…
Microsoft abbraccia il Passwordless: riflessioni
Perché abbandonare le password?
Cos’è l’autenticazione passwordless?
Come funziona il sistema passwordless di Microsoft?
Sicurezza e resilienza: un nuovo standard
Implicazioni per la cybersecurity aziendale e personale
Informatica (Italy e non Italy) reshared this.
Ma cancellarsi da Facebook è davvero possibile?
Mesi fa mi sono cancellato da Facebook e sono venuto qui.
Non ho fatto la sospensione dell'account ma proprio la cancellazione. Il sistema mi aveva detto che per 30 giorni avrebbe mantenuto l'account, casomai avessi cambiato idea, e poi l'avrebbe cancellato.
Ormai sono passati mesi ma un mio amico mi ha mandato una screenshot in cui il mio account si vede ancora, come se non fosse mai stato cancellato.
Voi come lo spiegate? Può essere che quel mio amico stia vedendo il contenuto della cache del suo browser?

A Palazzo Chigi trilaterale Meloni, Vance e von der Leyen. La premier: "Spero sia un nuovo inizio"
Il vicepresidente Usa: "Meloni si è offerta di fare da ponte, Trump e io felici". La presidente della Commissione Ue: "Grazie a Meloni". Stamane Merz, Macron e Starmer avevano annunciato una telefonata con Trump per domaniRedazione di Rainews (RaiNews)

Diritti Lgbtqi+: la Romania supera la Polonia come peggior Paese Ue, Italia in fondo alla classifica
Dopo sei anni, la Polonia non è più il peggior Paese in Europa per le persone Lgbtqi+, secondo l'annuale "Rainbow Map" pubblicata dall'ongILGA-Europe. Italia in fondo alla classificaKatarzyna-Maria Skiba (Euronews.com)
Christmas Comes Early With AI Santa Demo

With only two hundred odd days ’til Christmas, you just know we’re already feeling the season’s magic. Well, maybe not, but [Sean Dubois] has decided to give us a head start with this WebRTC demo built into a Santa stuffie.
The details are a little bit sparse (hopefully he finishes the documentation on GitHub by the time this goes out) but the project is really neat. Hardware-wise, it’s an audio-enabled ESP32-S3 dev board living inside Santa, running the OpenAI’s OpenRealtime Embedded SDK (as implemented by ExpressIf), with some customization by [Sean]. Looks like the audio is going through the newest version of LibPeer and the heavy lifting is all happening in the cloud, as you’d expect with this SDK. (A key is required, but hey! It’s all open source; if you have an AI that can do the job locally-hosted, you can probably figure out how to connect to it instead.)
This speech-to-speech AI doesn’t need to emulate Santa Claus, of course; you can prime the AI with any instructions you’d like. If you want to delight children, though, its hard to beat the Jolly Old Elf, and you certainly have time to get it ready for Christmas. Thanks to [Sean] for sending in the tip.
If you like this project but want to avoid paying OpenAI API fees, here’s a speech-to-text model to get you started.We covered this AI speech generator last year to handle the talky bit. If you put them together and make your own Santa Claus (or perhaps something more seasonal to this time of year), don’t forget to drop us a tip!
youtube.com/embed/0z7QJxZWFQg?…
Oggi 18 maggio, nel 1897, nasce il regista italiano naturalizzato statunitense Frank Capra

Frank Russell Capra, nome originario Francesco Rosario Capra, nasce il 18 maggio 1897 a Bisacquino, in provincia di Palermo. Emigrato a sei anni con la famiglia in California, a Los Angeles, nel 1922 dirige il cortometraggio "Fultah Fisher's Boarding House. La sua prima regia di un lungometraggio è "La grande sparata".
Il primo film totalmente sonoro, invece, è "L'affare Donovan", una detective story del 1929.
Il successo straordinario arriva con "Accadde una notte", che vince gli Oscar per la migliore regia, per il miglior film, per la migliore attrice protagonista, per il migliore attore protagonista e per la migliore sceneggiatura.
Tra il 1936 e il 1941 conquista trentuno candidature e sei premi Oscar con soli cinque film.
Dopo "La vita è meravigliosa", del 1946 va incontro a un declino professionale accentuato dalla diminuzione della sua creatività.
Poco più che sessantenne abbandona l'attività cinematografica, scegliendo di ritirarsi: muore il 3 settembre 1991 a La Quinta alla età di 94 anni.
Storia reshared this.

L'immagine è una fotografia in bianco e nero di un uomo in giacca e cravatta. Indossa una giacca a quadretti con un colletto a punta e una cravatta scura. Ha una sigaretta tra i denti, con un'espressione seria e pensierosa. La sua postura è eretta e sembra essere in un contesto formale. Lo sfondo è sfocato, mettendo in risalto il soggetto.
Fornito da @altbot, generato localmente e privatamente utilizzando Ovis2-8B
🌱 Energia utilizzata: 0.121 Wh
Con gli occhiali smart Aperol e Bellini Meta intende ubriacare il diritto alla privacy?
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Meta sarebbe al lavoro su di un software per i suoi occhiali smart capaci di raccogliere una gran quantità di dati, inclusi quelli biometrici, delle persone inquadrate dalle lenti. E già si profilano seri
reshared this

Microsoft abbraccia il Passwordless: riflessioni
@Informatica (Italy e non Italy 😁)
Negli ultimi decenni, le password sono state il pilastro della sicurezza digitale, ma la loro efficacia è ormai messa in discussione da vulnerabilità intrinseche e da un panorama di minacce in continua evoluzione. Microsoft ha annunciato una svolta epocale: a partire dal 2025, tutti i nuovi account Microsoft
Informatica (Italy e non Italy) reshared this.
Magnetohydrodynamic Motors to Spin Satellites

Almost all satellites have some kind of thrusters aboard, but they tend to use them as little as possible to conserve chemical fuel. Reaction wheels are one way to make orientation adjustments without running the thrusters, and [Zachary Tong]’s liquid metal reaction wheel greatly simplifies the conventional design.
Reaction wheels are basically flywheels. When a spacecraft spins one, conservation of angular momentum means that the wheel applies an equal and opposite torque to the spacecraft, letting the spacecraft orient itself. The liquid-metal reaction wheel uses this same principle, but uses a loop of liquid metal instead of a wheel, and uses a magnetohydrodynamic drive to propel the metal around the loop.
[Zach] built two reaction wheels using Galinstan as their liquid metal, which avoided the toxicity of a more obvious liquid metal. Unfortunately, the oxide skin that Galinstan forms did make it harder to visualize the metal’s motion. He managed to get some good video, but a clearer test was their ability to produce torque. Both iterations produced a noticeable response when hung from a string and activated, and achieved somewhat better results when mounted on a 3D-printed air bearing.
Currently, efficiency is the main limitation of [Zach]’s motors: he estimates that the second model produced 6.2 milli-newton meters of torque, but at the cost of drawing 22 watts. The liquid metal is highly conductive, so the magnetohydrodynamic drive takes high current at low voltage, which is inconvenient for a spacecraft to supply. Nevertheless, considering how hard it is to create reliable, long-lasting reaction wheels the conventional way, the greatly improved resilience of liquid-metal reaction wheels might eventually be worthwhile.
If you’re curious for a deeper look at magnetohydrodynamic drives, we’ve covered them before. We’ve also seen [Zach]’s earlier experiments with Galinstan.
youtube.com/embed/wiRMdRi0LrI?…
Storico al Pwn2Own: hackerato anche l’hypervisor VMware ESXi. 150.000 dollari ai ricercatori
Al torneo di hacking Pwn2Own di Berlino si è verificato un evento storico: esperti di sicurezza d’élite sono riusciti per la prima volta ad hackerare con successo l’hypervisor VMware ESXi sfruttando una vulnerabilità zero-day precedentemente sconosciuta. Si è trattato del proseguimento dell’emozionante giornata di apertura della competizione, quando tre exploit zero-day erano mirati a Windows 11. E il secondo giorno non ha deluso le aspettative: le sorprese sono continuate.
Le ultime settimane hanno già rappresentato una vera prova per la sicurezza aziendale. La Cybersecurity and Infrastructure Security Agency (CISA) degli Stati Uniti ha chiesto una protezione urgente contro una grave vulnerabilità di Chrome, già sfruttata attivamente negli attacchi. Contemporaneamente, sono stati rilevati attacchi tramite HTTPBot contro reti aziendali Windows e Microsoft ha confermato la presenza di una vulnerabilità critica nell’infrastruttura cloud con un livello di minaccia massimo di 10 su 10.
In questo contesto, la notizia dell’ecploiy per VMware ESXi che ha premiato i ricercatori con 150.000 dollari potrebbe sembrare solo la “ciliegina sulla torta”, ma in realtà non è così.
È importante comprendere il contesto: Pwn2Own è una competizione legale che si tiene due volte l’anno tra i migliori hacker del mondo. In questo caso, i partecipanti attaccano i prodotti forniti dai venditori in un periodo di tempo limitato, sfruttando vulnerabilità precedentemente sconosciute per identificarle prima che lo facciano i criminali informatici. La vittoria vale punti e premi in denaro e, cosa più importante, il titolo di Master PWN.
Nel caso di VMware ESXi, si tratta del primo hack di hypervisor riuscito nella storia di Pwn2Own, che risale al 2007. L’exploit è stato creato da Nguyen Hoang Thach del team STARLabs SG. Ha sfruttato una vulnerabilità di tipo integer overflow: solo un exploit, ma che exploit. Per la sua scoperta ha ricevuto 150.000 dollari e 15 punti per il torneo.
L'articolo Storico al Pwn2Own: hackerato anche l’hypervisor VMware ESXi. 150.000 dollari ai ricercatori proviene da il blog della sicurezza informatica.
Quel difetto mai sanato di Spid che apre la porta ai malintenzionati
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Le falle nel sistema di identificazione via Internet permettono oggi di creare più profili Spid del tutto fasulli. I malintenzionati possono così avere accesso a documenti riservati e dirottare indennizzi e pensioni sui
Informatica (Italy e non Italy) reshared this.
VIDEO. Delegazione italiana a Rafah: “Stop all’attacco israeliano, salviamo Gaza”
@Notizie dall'Italia e dal mondo
Decine di italiani, tra deputati, cooperanti, attivisti e giornalisti, hanno raggiunto oggi il valico di Rafah tra il Sinai e Gaza per manifestare a sostegno della popolazione palestinese sotto i bombardamenti israeliani, per la fine dell'offensiva
Notizie dall'Italia e dal mondo reshared this.
Casting Shade on “Shade-Tolerant” Solar Panels

Shade is the mortal enemy of solar panels; even a little shade can cause a disproportionate drop in power output. [Alex Beale] reviewed a “revolutionary” shade-tolerant panel by Renology in a video embedded below. The results are fascinating.
While shading large portions of the panels using cardboard to cut off rows of cells, or columns of cells, the shade tolerant panel does very well compared to the standard panel– but when natural, uneven shading is applied to the panel, very little difference is seen between the standard and active panels in [Alex]’s test. We suspect there must be some active components to keep power flowing around shaded cells in the Renology panel, allowing it to perform well in the cardboard tests. When the whole panel is partially shaded, there’s no routing around it, and it performs normally.
It’s hard to see a real-world case that would justify the extra cost, since most shading doesn’t come with perfect straight-line cutoffs. Especially considering the added cost for this “shade tolerant” technology (roughly double normal panels).
You might see a better boost by cooling your solar panels. Of course you can’t forget to optimize the output with MPPT. It’s possible that a better MPPT setup might have let the Renology panel shine in this video, but we’re not certain. Whatever panels you’re using, though, don’t forget to keep them clean.
youtube.com/embed/Ya_DPtNj6Og?…
Una nuova finanza per la difesa europea. La Dsr bank vista da Fiona Murray
@Notizie dall'Italia e dal mondo
Il 19 maggio a Londra i leader si incontreranno per firmare uno storico Patto di Difesa tra Regno Unito e Unione europea. Ma quello che seguirà sarà influenzato non solo dalla politica, ma anche dall’economia. Per sostenere una deterrenza credibile a lungo termine, il
Notizie dall'Italia e dal mondo reshared this.
Apple fa l’indiana, ma non d’America. E Trump s’arrabbia
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
I dazi hanno spinto Apple ad accelerare il trasloco della propria filiera dalla Cina all'India, ma è sempre più evidente che Trump sperava inducessero Cupertino a realizzare iPhone 'made in Usa'. E il presidente americano non
Informatica (Italy e non Italy) reshared this.

Passi per i prodotti che richiedono manodopera a basso costo, gli #iphone?
@informatica
Informatica (Italy e non Italy) reshared this.
Giornali con le idee chiare

Dopo Meta, tocca a Google. Ken Paxton continua a terrorizzare le Big Tech
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Il procuratore generale del Texas lo scorso anno aveva spinto Meta a siglare un accordo per un risarcimento record (1,4 miliardi di dollari) così da lasciare cadere le accuse di violazione della privacy. Oggi Paxton ritorna
Informatica (Italy e non Italy) reshared this.
Come crescono le startup tedesche di Intelligenza artificiale
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Startup tedesche ancora poco conosciute, come Celonis, Prewave, Tacto e Osapiens, stanno diffondendo le loro soluzioni basate sull'Ia per aiutare le imprese a navigare startmag.it/innovazione/german…
Informatica (Italy e non Italy) reshared this.
MCP Blender Addon Lets AI Take the Wheel and Wield the Tools

Want to give an AI the ability to do stuff in Blender? The BlenderMCP addon does exactly that, connecting open-source 3D modeling software Blender to Anthropic’s Claude AI via MCP (Model Context Protocol), which means Claude can directly use Blender and its tools in a meaningful way.
MCP is a framework for allowing AI systems like LLMs (Large Language Models) to exchange information in a way that makes it easier to interface with other systems. We’ve seen LLMs tied experimentally into other software (such as with enabling more natural conversations with NPCs) but without a framework like MCP, such exchanges are bespoke and effectively stateless. MCP becomes very useful for letting LLMs use software tools and perform work that involves an iterative approach, better preserving the history and context of the task at hand.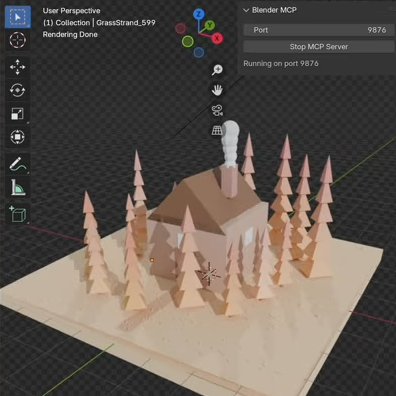
Using MCP also provides some standardization, which means that while the BlenderMCP project integrates with Claude (or alternately the Cursor AI editor) it could — with the right configuration — be pointed at a suitable locally-hosted LLM instead. It wouldn’t be as capable as the commercial offerings, but it would be entirely private.
Embedded below are three videos that really show what this tool can do. In the first, watch it create a beach scene using assets from a public 3D asset library. In the second, it creates a scene from scratch using a reference image (a ‘low-poly cabin in the woods’), followed by turning that same scene into a 3D environment on a web page, navigable in any web browser.
Back in 2022 we saw Blender connected to an image generator to texture objects, but this is considerably more capable. It’s a fascinating combination, and if you’re thinking of trying it out just make sure you’re aware it relies on allowing arbitrary Python code to be run in Blender, which is powerful but should be deployed with caution.
youtube.com/embed/I29rn92gkC4?…
youtube.com/embed/FDRb03XPiRo?…
youtube.com/embed/jxbNI5L7AH8?…
Arriva OpenAI Codex: lo sviluppatore AI che scrive, testa e integra il codice al posto tuo
Se puoi assumere uno sviluppatore junior, consegnargli il Codex e ottenere un prodotto valido quanto quello di uno sviluppatore senior, perché pagare di più? Questi potrebbe cambiare radicalmente il mercato del lavoro nel settore IT.
OpenAI ha presentato un nuovo strumento di programmazione chiamato Codex, un assistente intelligente integrato in ChatGPT.
Questa funzionalità trasforma l’IA in uno sviluppatore quasi autonomo: basta inserire una query, cliccare sul pulsante “Codice” e il sistema si occuperà delle attività di routine. Codex può leggere e modificare file, eseguire comandi, analizzare la base di codice e rispondere a domande su di essa. Tutto ciò che viene richiesto all’utente è formulare l’attività e cliccare sul pulsante “Chiedi”.
La velocità di esecuzione dipende dalla complessità del compito e può richiedere da uno a trenta minuti. Allo stesso tempo, l’intero processo è completamente trasparente: ogni azione di Codex può essere tracciata tramite i log del terminale e i risultati dei test. Il codice viene creato in un ambiente isolato, dopodiché può essere integrato in un sistema locale o inviato a GitHub.
In sostanza, Codex apre la strada all’automazione della programmazione, che non è più solo un aiuto per lo sviluppatore, ma un potenziale sostituto per interi team.
È chiaro che uno strumento del genere potrebbe interessare anche agli utenti meno attenti, ma OpenAI afferma di aver integrato meccani sesmi di protezione nel Codex. Si suppone che il sistema sia in grado di riconoscere le richieste di creazione di malware e di rifiutarsi di eseguirle. Tuttavia, l’azienda non spiega esattamente come funziona questa protezione.
Codex è ora disponibile in modalità anteprima per gli abbonati a ChatGPT Pro, Enterprise e Team: gratuito e illimitata.
OpenAI promette in seguito di introdurre limiti di utilizzo e prezzi flessibili.
L'articolo Arriva OpenAI Codex: lo sviluppatore AI che scrive, testa e integra il codice al posto tuo proviene da il blog della sicurezza informatica.
Cosa cambierà per l’Intelligenza artificiale dopo gli accordi di Trump con l’Arabia Saudita
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
La missione di Trump in Arabia Saudita unisce capitali del Golfo e colossi tech per dominare l’AI. Ma l’uso dell’AI per la sorveglianza in regimi
Informatica (Italy e non Italy) reshared this.


La truffa del falso curriculum e la risposta intelligente! Una storia vera (e istruttiva)
Nel mondo sempre più sofisticato delle truffe digitali, una delle modalità emergenti è quella del falso reclutamento professionale. Un metodo subdolo, che sfrutta il desiderio (e il bisogno) di molte persone di trovare opportunità di lavoro online. In questa storia reale – volutamente ironizzata per finalità divulgative – raccontiamo un caso concreto, documentato con screenshot e condotto con spirito critico.
L’inizio: un curriculum “trovato” online
Tutto parte da una chiamata preregistrata. Una voce femminile afferma di aver visionato un curriculum e propone una collaborazione su YouTube. Il compenso è di 400€ al giorno per semplici attività come mettere like ai video.
La proposta è ovviamente troppo allettante per essere vera.
Subito dopo, il potenziale “selezionato” viene invitato a proseguire la conversazione su Telegram, con una sedicente manager di nome Paola Strollo, che si presenta come “referente commerciale”.
Il copione classico: IBAN e identità
Dopo un breve scambio, la truffatrice chiede:
- Nome e cognome
- Età
- IBAN bancario
- Documento d’identità
Tutto con la scusa di dover inviare un primo “rimborso” di 6€ per l’attività. Un tentativo banale di ottenere informazioni personali, ma costruito in modo credibile e con apparente cordialità.
Qui però la storia prende una piega diversa.
Chi riceve il messaggio decide di non ignorarlo, ma di rispondere, fingendosi un anziano signore: Erminio Ottone, 83 anni, pensionato, ex maestro elementare originario di Pianella (PE), non tecnologico, credente nella Provvidenza, e cliente affezionato della Banca della Fede Online.
Un personaggio volutamente costruito per rappresentare una delle categorie più frequentemente prese di mira da questo tipo di frodi: gli anziani. Ma anche per dimostrare quanto possa essere efficace la consapevolezza, anche se narrata in forma teatrale.

Viene fornito un IBAN falso, una carta d’identità evidentemente fittizia e addirittura un finto bonifico “ricevuto” dalla sedicente “azienda”. Il tutto per testare fin dove può spingersi la truffatrice.


Il colpo di scena: il finto alert antifrode
Dopo aver ottenuto risposte insospettabili dalla controparte, viene inoltrato un messaggio fasullo in perfetto stile truffa:
Gentile Paola Strollo, è stato rilevato un bonifico sospetto di 5.600€ a suo nome.
In caso di mancata risposta, verranno avviate le procedure di blocco cautelativo del profilo.
Panico
La truffatrice risponde confusa. Chiede spiegazioni. L’anziano (fittizio) le scrive come fosse davvero spaventato, con un linguaggio incerto e ingenuo, dicendosi preoccupato e scusandosi “nel caso avesse fatto qualcosa di sbagliato”.
Il messaggio finale?
“Lo sai chi ti saluta, Paolè? Una frase garbata, ma chi ha letto fin qui sa benissimo cosa voleva dire davvero

Cosa insegna questa storia?
- Il phishing non è solo via email: oggi le truffe arrivano anche via voce sintetica, Telegram, WhatsApp, o LinkedIn.
- L’esca è psicologica: fanno leva su bisogni reali (lavoro, denaro) e sull’autorità apparente di chi scrive (manager, HR).
- La richiesta dell’IBAN è solo l’inizio: dietro può esserci un tentativo di furto d’identità, bonifici fraudolenti, social engineering e persino riciclaggio di denaro tramite l’utilizzo inconsapevole delle vittime per movimentare fondi illeciti.
- In alcuni casi, queste truffe fanno parte di schemi Ponzi digitali, in cui ai nuovi iscritti viene promesso un guadagno solo se riescono a portare altre persone nel sistema. I primi pagamenti servono a generare fiducia e a rendere l’inganno credibile, ma l’intero meccanismo si regge esclusivamente sull’ingresso continuo di nuove vittime. Quando l’afflusso si interrompe, il sistema crolla, lasciando molti utenti senza denaro e senza possibilità di recupero
- L’ironia può essere uno strumento di difesa, ma non tutti hanno i mezzi o la prontezza per riconoscere l’inganno.
Conclusione
Erminio Ottone non esiste.
Ma ogni giorno esistono centinaia di vere vittime che, diversamente da chi ha creato questo esperimento educativo, forniscono davvero dati sensibili a sconosciuti.
Red Hot Cyber ha deciso di raccontare questa vicenda non per spettacolarizzarla, ma per ricordare quanto sia facile cadere in un raggiro digitale ben costruito.
La vigilanza, l’educazione digitale e un pizzico di diffidenza possono fare la differenza tra un click innocuo e una violazione irreparabile.
L'articolo La truffa del falso curriculum e la risposta intelligente! Una storia vera (e istruttiva) proviene da il blog della sicurezza informatica.
rag. Gustavino Bevilacqua reshared this.
Coinbase conferma un data leak: social engineering, insider e ricatti milionari
Il 14 maggio 2025 Coinbase, una delle più grandi piattaforme di crypto trading al mondo, ha confermato pubblicamente di essere stata vittima di un sofisticato attacco interno orchestrato da cyber criminali che hanno corrotto alcuni operatori del supporto clienti. La notizia è stata accompagnata da una dichiarazione ufficiale sul blog aziendale e da una comunicazione formale alla U.S. Securities and Exchange Commission (SEC), come previsto per eventi che possono influenzare significativamente gli investitori e il mercato.

Insiders: un’attacco tutt’altro che tecnologico
Nel post dal titolo “Protecting Our Customers – Standing Up to Extortionists”, Coinbase afferma che un gruppo di criminali informatici ha reclutato e corrotto operatori di supporto esterni, in particolare all’estero, per ottenere accesso ai sistemi interni. Utilizzando tali accessi, gli attaccanti hanno sottratto dati sensibili di un “piccolo sottoinsieme” di utenti per facilitare attacchi di social engineering.
Nessuna password, chiave privata o fondi è stata compromessa – precisa l’azienda – e gli account Coinbase Prime sono rimasti intatti.
Tuttavia, i dati sottratti sono stati sufficienti per permettere agli attori malevoli di ingannare alcuni utenti e estorcere fondi, attivando così un attacco a catena che ricalca le modalità degli attacchi orchestrati da gruppi come Scattered Spider e LAPSUS$.
Un ransomware mancato: rifiutato riscatto da 20 milioni di dollari
Coinbase ha anche rivelato di aver ricevuto una richiesta di riscatto da 20 milioni di dollari, che ha categoricamente rifiutato. Al contrario, l’azienda ha annunciato la creazione di un fondo premio da 20 milioni di dollari per chi fornirà informazioni utili all’identificazione, arresto e condanna dei responsabili.
Una mossa netta e simbolica, che posiziona Coinbase come un attore attivo nella lotta alla cyber-estorsione, scegliendo il confronto anziché la sottomissione.
Nel documento ufficiale pubblicato sul sito della SEC (Form 8-K), Coinbase specifica che:
- L’incidente ha coinvolto un sottoinsieme limitato di clienti.
- L’attacco è partito da attività illecite condotte da soggetti terzi esterni legati al customer support.
- Non sono stati compromessi né asset finanziari né infrastrutture critiche.
- L’azienda sta collaborando con forze dell’ordine e team di esperti forensi.
- Nessun impatto materiale previsto sulle operazioni aziendali o sulla sicurezza dei fondi.
L’incidente rientra in un trend preoccupante nel panorama cyber globale: l’uso di insider compromessi per bypassare i sistemi di sicurezza più sofisticati. È lo stesso schema adottato negli attacchi subiti da LastPass, Uber, e più recentemente da Microsoft, con attori che sfruttano l’anello debole della catena umana piuttosto che le vulnerabilità tecniche.
Sebbene Coinbase abbia dimostrato trasparenza e fermezza nella gestione della crisi, l’episodio rappresenta l’ennesima dimostrazione che nessuna piattaforma – per quanto blindata – è immune all’errore umano o al tradimento interno.
In un settore già sotto scrutinio per volatilità e regolamentazione incerta, episodi come questo contribuiscono ad alimentare diffidenza e ad aumentare la pressione su exchange e operatori del settore affinché rafforzino le difese sociali, non solo quelle digitali.
Fonti:
- Coinbase – Protecting Our Customers – Standing Up to Extortionists
- SEC – Form 8-K Coinbase, Inc. (May 14, 2025)
L'articolo Coinbase conferma un data leak: social engineering, insider e ricatti milionari proviene da il blog della sicurezza informatica.
Max - Poliverso 🇪🇺🇮🇹
in reply to Max - Poliverso 🇪🇺🇮🇹 • •@Fedi.Tips
Tu ci capisci qualcosa?
Fedi.Tips
in reply to Max - Poliverso 🇪🇺🇮🇹 • • •Facebook and Meta are extremely untrustworthy. I do not think they ever really delete user data even if they claim to do so.
They treat their users like cattle and regard user data as Meta's own property.
Max - Poliverso 🇪🇺🇮🇹
in reply to Fedi.Tips • •@Fedi.Tips
Thanks.