Con l’intensificarsi delle tensioni geopolitiche e l’adozione di tecnologie avanzate come l’intelligenza artificiale e il Web3 da parte dei criminali informatici, comprendere i meccanismi dell’underground cybercriminale di lingua russa diventa un vantaggio cruciale.
Milano, 14 aprile 2025 – Trend Micro, leader globale di cybersecurity, presenta “The Russian-Speaking Underground”, l’ultima ricerca dedicata all’underground cybercriminale di lingua russa, l’ecosistema che ha dato forma alla criminalità informatica globale negli ultimi dieci anni.
In un contesto caratterizzato da minacce informatiche in continua evoluzione, la ricerca offre uno sguardo unico e approfondito sui principali trend che stanno rimodellando l’economia sommersa: dagli effetti a lungo termine della pandemia alle conseguenze delle violazioni di massa e dei ransomware a doppia estorsione, fino all’esplosione di tecnologie accessibili come l’intelligenza artificiale e il Web3, senza dimenticare la crescente esposizione dei dati biometrici. Man mano che criminali informatici e professionisti della sicurezza diventano sempre più sofisticati, nuovi strumenti, tattiche e modelli di business alimentano livelli senza precedenti di specializzazione all’interno delle comunità clandestine. L’underground cybercriminale di lingua russa si distingue per la sua struttura organizzativa: forte collaborazione tra attori e profonde radici culturali, con propri codici etici, rigidi processi di selezione e complessi sistemi reputazionali.
“Non si tratta di un semplice marketplace, ma di una vera e propria società strutturata di cybercriminali, in cui lo status, la fiducia e l’eccellenza tecnica determinano la sopravvivenza e il successo”. Afferma Vladimir Kropotov, co-autore della ricerca e Principal Threat Researcher at Trend Micro.
“L’underground di lingua russa ha sviluppato una cultura distintiva, che unisce competenze tecniche di altissimo livello a rigidi codici di condotta, sistemi di fiducia basati sulla reputazione e un livello di collaborazione paragonabile a quello delle organizzazioni legittime”, ha aggiunto Fyodor Yarochkin, co-autore e Principal Threat Researchers at Trend Micro. “Non è solo una rete di criminali, ma una comunità resiliente e interconnessa, che si è adattata alla pressione globale e continua a influenzare l’evoluzione della criminalità informatica”.
La ricerca Trend Micro approfondisce le principali attività criminali, tra cui schemi di ransomware-as-a-service, campagne di phishing, brute forcing degli account e monetizzazione delle risorse Web3 rubate. Sono stati esaminati in dettaglio anche i servizi di intelligence gathering, sfruttamento della privacy e convergenza tra i domini cyber e fisici.
“I cambiamenti geopolitici hanno trasformato rapidamente l’underground cybercriminale”, conclude Vladimir. “I conflitti politici, l’ascesa dell’hacktivismo e i cambiamenti nelle alleanze hanno minato la fiducia e rimodellato le forme di collaborazione, favorendo nuovi legami con altri gruppi, compresi attori di lingua cinese. Le conseguenze di queste azioni si riflettono anche nell’Unione Europea, e sono in crescita”.
Con l’aumento delle tensioni geopolitiche e l’adozione di tecnologie sempre più avanzate come l’intelligenza artificiale e il Web3 da parte dei criminali informatici, comprendere i meccanismi dell’underground di lingua russa rappresenta un vantaggio cruciale come mai prima d’ora.
Il report di Trend Micro “The Russian-Speaking Underground” – il cinquantesimo della sua serie di ricerche sui mercati underground cybercriminali di tutto il mondo, iniziata oltre 15 anni fa – fornisce informazioni fondamentali e un contesto storico senza pari a team di intelligence sulle minacce, leader delle organizzazioni, Forze dell’Ordine e professionisti della sicurezza informatica, incaricati di proteggere le infrastrutture critiche, le risorse aziendali e la sicurezza nazionale.
Ulteriori informazioni sono disponibili a questo link
Trend Micro Trend Micro, leader globale di cybersecurity, è impegnata a rendere il mondo un posto più sicuro per lo scambio di informazioni digitali. Con oltre 30 anni di esperienza nella security, nel campo della ricerca sulle minacce e con una propensione all’innovazione continua, Trend Micro protegge oltre 500.000 organizzazioni e milioni di individui che utilizzano il cloud, le reti e i più diversi dispositivi, attraverso la sua piattaforma unificata di cybersecurity. La piattaforma unificata di cybersecurity Trend Vision One™ fornisce tecniche avanzate di difesa dalle minacce, XDR e si integra con i diversi ecosistemi IT, inclusi AWS, Microsoft e Google, permettendo alle organizzazioni di comprendere, comunicare e mitigare al meglio i rischi cyber. Con 7.000 dipendenti in 65 Paesi, Trend Micro permette alle organizzazioni di semplificare e mettere al sicuro il loro spazio connesso. www.trendmicro.com
vedo che nel mondo il bullismo impera... e che la dottrina trump pervade felicemente (per alcuni) tutto il mondo... quanta aria di libertà e di rispetto per la persona.
With vector network analyzers, the commercial offerings seem to come in two flavors: relatively inexpensive but limited capabilities, and full-featured but scary expensive. There doesn’t seem to be much middle ground, especially if you want something that performs well in the microwave bands.
Unless, of course, you build your own vector network analyzer (VNA). That’s what [Henrik Forsten] did, and we’ve got to say we’re even more impressed by the results than we were with his earlier effort. That version was not without its problems, and fixing them was very much on the list of goals for this build. Keeping the build affordable was also key, which resulted in some design compromises while still meeting [Henrik]’s measurement requirements.
The Bill of Materials includes dual-channel broadband RF mixer chips, high-speed 12-bit ADCs, and a fast FPGA to handle the torrent of data and run the digital signal processing functions. The custom six-layer PCB is on the large side and includes large cutouts for the directional couplers, which use short lengths of stripped coaxial cable lined with ferrite rings. To properly isolate signals between stages, [Henrik] sandwiched the PCB between a two-piece aluminum enclosure. Wisely, he printed a prototype enclosure and lined it with aluminum foil to test for fit and function before committing to milling the final version. He did note some leakage around the SMA connectors, but a few RF gaskets made from scraps of foil and solder braid did the trick.
This is a pretty slick build, especially considering he managed to keep the price tag at a very reasonable $300. It’s more expensive than the popular NanoVNA or its clones, but it seems like quite a bargain considering its capabilities.
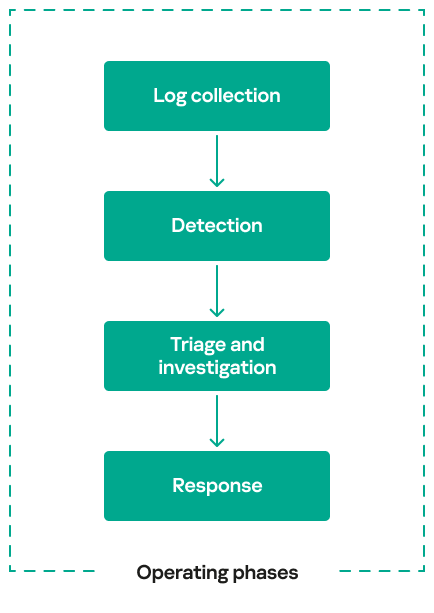
Security operations centers (SOCs) exist to protect organizations from cyberthreats by detecting and responding to attacks in real time. They play a crucial role in preventing security breaches by detecting adversary activity at every stage of an attack, working to minimize damage and enabling an effective response. To accomplish this mission, SOC operations can be broken down into four operating phases:
Each of these operating phases has a distinct role to play, and well-defined processes or procedures ensure a seamless handover of findings from one phase to the next. In practice, SOC processes and procedures at each operational phase often require continuous improvement over time.
Assessment observations: Common SOC issues
During our involvement in SOC technical assessments, adversary emulations, and incident response readiness projects across different regions, we evaluated each operating phase separately. Based on our assessments, we observed common challenges, weak practices, and recurring issues across these four key SOC capabilities.
Log collection
There are three main issues we have observed at this stage:
Lack of visibility coverage based on the MITRE DETT&CT framework – customers do not practice maintaining a visibility coverage matrix. Instead, they often maintain log source data as an Excel or similar spreadsheet that is not easily tracked. This means they don’t have a systematic approach to what data they are feeding into the SIEM and which TTPs can be detected in their environment. And in most cases, maintaining a continuous visibility matrix is also a challenge because log sources may disappear over time for a variety of reasons: agent termination, changes in log destination settings, device (e.g., firewall) replacement. This only leads to the degradation of the log visibility matrix.
Inefficient use of data for correlation – in many cases, relevant data is available to detect threats, but there are no correlation rules in place to leverage it for threat detection.
Correlation exists, but lacks the necessary data fields – while some rule sets are properly configured with the right logic to detect threats, the required data fields from log sources are missing, preventing the rules from being triggered. This critical issue can only be detected through a data quality assessment.
Detection
At this stage, we have seen the following issues during assessment procedures:
Over-reliance on vendor-provided rules – many customers rely heavily on the default rule sets in their SIEM and only tune them when alerts are triggered. Since the default content is not optimized, it often generates thousands of alerts. This reactive approach leads to excessive alert fatigue, making it difficult for analysts to focus on truly meaningful alerts.
Lack of detection alignment with the threat profile – the absence of a well-defined organizational threat profile prevents customers from focusing on the threats that are most likely to target them. Instead, they adopt a scattered approach to detection, like shooting in the dark rather than prioritizing relevant threats.
Poor use of threat intelligence feeds – we have encountered cases where endpoint logs do not contain file hash data. The log sources only provide filenames or file paths, but not the actual hash values, making it difficult for the SOC to correlate threat intelligence (TI) feeds that rely on file hashes. As a result, TI feeds are not operational because the required data field is not ingested into the SIEM.
Analytics deployment errors – one of the most challenging issues we see is when a well-designed detection rule is deployed incorrectly, causing threat detection to fail despite having the right analytics in place. We have found that there is no structured process for reviewing and validating rule deployments.
Triage and investigation
The most typical issues at this stage are:
Lack of a documented triage procedure – analysts often rely on generic, high-level response playbooks sourced from the internet, especially from unreliable sources, which slows or hinders the process of qualifying alerts as potential incidents. Without a structured triage procedure, they spend more time investigating each case instead of quickly assessing and escalating threats.
Unattended alerts – we also observed that many alerts were completely ignored by analysts. This likely stems from either a lack of skill in linking multiple alerts into a single incident, or analysts being swamped with high-severity alerts, causing them to overlook other relevant alerts.
Difficulty in correlating alerts – as noted in the previous observation, one of the biggest challenges is linking related alerts into a single incident. The lack of alert correlation makes it harder to see the full attack pattern, leading to disorganized alert diagnosis.
Default use of alert severity – SIEM default rules don’t take into account the context of the target system. Instead, they rely on the default severity in the rule, which is often set randomly or based on an engineer’s opinion without a clear process. This lack of context makes it harder to investigate and properly assess alerts.
Response
The challenges of the final operating phase are most often derived from the issues encountered in the previous stages.
Challenges in incident scoping – as mentioned earlier, the inability to properly correlate alerts leads to a fragmented understanding of attack patterns. This makes it difficult to see the bigger picture, resulting in inefficient incident handling and misjudged response efforts.
Increase in unnecessary escalations – this issue is particularly common in MSSP environments, where a lack of understanding of baseline behavior causes analysts to escalate benign cases. Without proper context, normal activities are mistaken for threats, resulting in wasted time and effort.
With these ongoing challenges, chaos will continue in SOC operations. As organizations adopt new security tools such as CASB and container security, both of which generate valuable detection data, and as digital transformation introduces even more technology, security operations will only become more complex, exacerbating these issues.
Taking the right and impactful approach
Enhancing SOC operations requires evaluating each operating phase from an investment perspective, with the detection phase having the greatest impact because it directly affects data quality, threat visibility, incident response efficiency, and the overall effectiveness of the SOC analyst. Investing in detection directly influences all the other operating phases, making it the foundation for improving all operating phases. The detection operating phase must be handled through a dedicated program that ensures log collection is purpose-driven, collecting only the data fields necessary for detection rather than unnecessarily driving up SIEM costs. This focused approach helps define what should be ingested into the SIEM while ensuring meaningful threat visibility.
Strengthening detection reduces false positives and false negatives, improves true positive rates, and enables the identification of attacker activity chains. A documented triage and investigation process streamlines the work of analysts, improving efficiency and reducing response time. Furthermore, effective incident scoping, guided by accurate detection of the cyber kill chain, enables a faster and more precise response. By prioritizing investment in detection and managing it through a structured approach, organizations can significantly improve SOC performance and resilience against evolving threats. This article focuses solely on SIEM-based detection management.
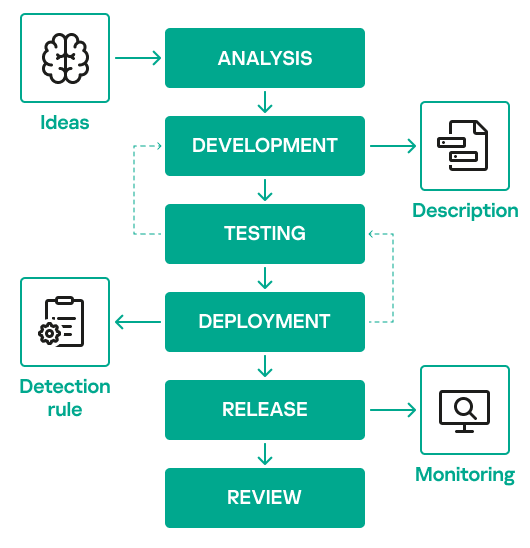
Detection engineering program
Before diving into the program-level approach, we will first present the detection engineering lifecycle that forms the foundation of the proposed program. The image below shows the stages of this lifecycle.
The detection engineering lifecycle shown here is typically followed when building detections, but its implementation often lacks well-defined processes or a dedicated team. A structured program must be put in place to ensure that the SOC’s investment and efforts in detection engineering are used efficiently.
When we talk about a program, it should be built on the following key elements:
A dedicated team responsible for driving the program
Well-defined processes and procedures to ensure consistency and effectiveness
The right tools to integrate with workflows, facilitate output handovers, and enable feedback loops across related processes
Meaningful metrics to measure the overall performance of the program.
We will discuss these performance measurement metrics in the final section of the article.
Team supporting detection engineering program
The key idea behind having a dedicated team is to take full control of the detection engineering (DE) lifecycle, from analysis to release, and ensure accountability for the program’s success. In a traditional SOC setup, deployment and release are often handled by SOC engineers. This can lead to deployment errors due to potential differences in the data models used by DE and SOC teams (raw log data vs. SIEM-optimized data), as well as deployment delays due to the SOC team being overloaded with other tasks. This, in turn, can indirectly impact the work of the detection team. However, the one responsibility that does not fall under the DE team is log onboarding. Since this process requires coordination with other teams, it should continue to be managed by SOC engineers to keep the DE team focused on its core objectives.
The DE team should start with at least three key roles:
The size of the team depends on factors related to the program’s objectives. For example, if the goal is to build a certain number of detection rules per month, the number of detection engineers required will vary accordingly. Similarly, if a certain number of rules need to be tested and deployed within a week, the team size must be adjusted to meet that demand.
The Detection Engineering Lead should communicate with SOC leadership to set the right expectations by outlining what goals can realistically be achieved based on the size and capacity of the DE team. A dedicated Detection QA role can be established as the need for testing, deployment, and release of detections grows.
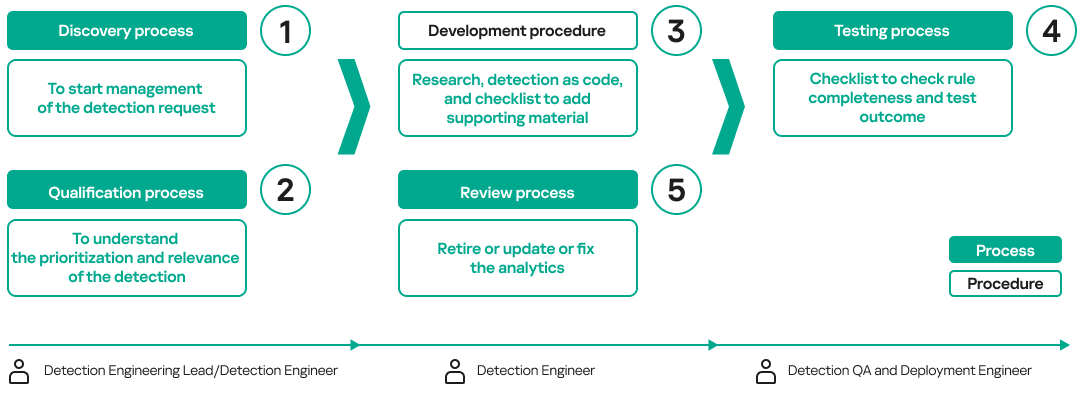
Process and procedures
Well-defined workflows, supported by structured processes and procedures, must be established to streamline detection engineering operations. The following image illustrates the necessary processes and procedures, along with the roles responsible for executing each workflow:
During the qualification process, the Detection Engineering Lead or Detection Engineer may discover that the data source needed to develop a detection is not available. In such cases, they should follow the log management process to request onboarding of the required data before proceeding with detection research and development. The testing process typically checks that the rule works by ensuring that the SIEM triggers an alert based on the required data fields.
Lastly, a validation process that is not part of the detection engineering lifecycle must be incorporated into the detection engineering program to assess its overall effectiveness. Ideally, this validation should be conducted by individuals outside the DE lifecycle or by an external service provider.
Proper planning is required that incorporates threat intelligence and an updated threat profile. In addition, the validation process should generate reports that outline:
What is working well
Areas that need improvement
Detection gaps identified
Tools
An essential element of the DE lifecycle is the use of tools to streamline processes and improve efficiency. Key tools include:
Ticketing platform – efficiently manages workflows, tracks progress from ticket creation to closure, and provides time-based metrics for monitoring.
Rules repository – platform for managing detection queries and code, supporting Detection-as-Code, using a unified rule format such as SIGMA, and implementing code development best practices in detection engineering, including features such as version control and change management.
Centralized knowledge base – dedicated space for documenting detection rules, descriptions, research notes, and other relevant information. See the best practices section below for more details on centralized documentation.
Communication platform – facilitates collaboration among DE team members, integrates with the ticketing system, and provides real-time notification of ticket status or other issues.
Lab environment – virtualized setup, including SIEM and relevant data sources, tools to simulate attacks for testing purposes. The core function of the lab is to test detection rules prior to release.
Best practices in detection engineering
Several best practices can significantly enhance your detection engineering program. Based on our experience, implementing these best practices will help you effectively manage your rule set while providing valuable support to security analysts.
Rule naming convention
When developing analytics or a rule, adhering to a proper naming convention provides a concrete framework. A rule name like “Suspicious file drop detected” may confuse the analyst and force them to dig deeper to understand the context of the alert that was triggered. It would be better to give a rule a name that provides complete context at first glance, such as “Initial Access | Suspicious file drop detected in user directory | Windows – Medium”. This example makes it easy for the analyst to understand:
At what stage of the attack the rule is triggered. In this case, it is Initial Access as per MITRE / Kill Chain Model.
Where exactly the file was dropped. In this case, the user directory was the target, which may mean that this probably involved user interaction, which is another sign that the attack was probably detected at an early stage.
What platform was attacked. In this case, it is Windows, which can help the analyst to quickly find the machine that triggered the alert.
Lastly, an alert priority can be set, which helps the analyst to prioritize accordingly. For this to work properly, SIEM’s priority levels should be aligned with the rule priorities defined by the detection engineering team. For example, a high priority in SIEM should correspond to a high-priority alert.
A consistent rule naming structure can help the detection engineering team to easily search, sort and manage existing rules, avoid creating duplicates with different names, etc.
The naming structure doesn’t necessarily have to look like the example above. The whole idea of this best practice is to find a good naming convention that not only helps the SOC analyst, but also makes managing detection rules easier and more convenient.
For example, while the rule name “Audit Log Deletion” gives a basic idea of what is happening, a more effective name would be: [High] – Audit Log Deletion in Internal Server Farm – Linux - Defense Evasion (1070.002). This provides better context, making it much more useful to the SOC team, and more keywords for the DE team to find this particular rule or filter rules if necessary.
Centralized knowledge base
Once a rule is created after thorough research, the detection team should manage it in a centralized platform (a knowledge base). This platform should not only store the rule name and logic, but also other key details. Important elements to consider:
Rule name/ID/description – rule name, unique ID, and a brief description of the rule.
Rule type/status – provides insight into the rule type (static, correlated, IoC-based, etc.) and the status (experimental, stable, retired, etc.).
Severity and confidence – seriousness of the threat triggering this rule and the likelihood of a true positive.
Research notes – possible public links, threat reports, used as a basis for creating the rule.
Data components used to detect the behavior – list of source and data fields used to detect activity.
Triage steps – provides steps to investigate the alert.
False positives – provides options where the alert could show false positive behavior.
Tags (CVE, Actors, Malware, etc.) – provide more context if the detection is linked to a behavior or artifact, specific to any APT group, or malware.
Make sure this centralized documentation is accessible to all SOC analysts.
Contextual tagging
As covered in the previous best practice, tags provide a great value in understanding the attack chain. That’s why we want to highlight them as a separate best practice.
The tags attached to the above detection rule are the result of the research done on the behavior of the attack when writing the detection rule. They help the analyst gain more context at the time the rule is triggered. In the example above, the analyst may suspect a potential initial access attempt related to QakBot or Black Basta ransomware. This also helps in reporting to security leadership that the SOC team successfully detected the initial ransomware behavior and was able to thwart the attack in the early stages of the kill chain.
Triage steps
A good practice is to include triage (or investigation steps) in detection rule documentation. Since the DE team has spent a lot of time understanding the threat, it is very important to document the precursors and possible next steps the attacker can take. The SOC analyst can quickly review these and provide incident qualification with confidence.
For the rule from the previous section, “Initial Access | Suspicious LNK files dropped in download folder | Windows – Medium”, the triage procedure is shown below.
MITRE has a project called the Technique Inference Engine, which provides a model for understanding other techniques an attacker is likely to use based on observed adversary behavior. This tool can be useful for both DE and SOC teams. By analyzing the attacker’s path, organizations can improve alert correlation and enhance scoping of incident/threats.
Baselining
Understanding the infrastructure and its baseline operations is a must, as it helps reduce the false positive rate. The detection engineering team must learn the prevention policies (to de-prioritize detection if already remediated), learn about the technologies deployed in the infrastructure, understand the network protocols being used and user behavior under normal circumstances.
For example, to detect T1480.002: Execution Guardrails: Mutual Exclusion sub-technique, MITRE recommends monitoring a “file creation” data component. According to the MITRE Data Sources framework, data components are possible actions with data objects and/or data objects statuses or parameters that may be relevant for threat detection. We discussed them in more detail in our detection prioritization article.
A simple rule for detecting such activity is to monitor lock file creation events in the /var/run folder, which stores temporary runtime data for running services. However, if you have done the baselining and found that the environment uses containers that also create lock files to manage runtime operations, you can filter out container-linked events to avoid triggering false positive alerts. This filter is easy to apply, and overall detection can be improved by baselining the infrastructure you are monitoring.
Finding the narrow corridors
Some indicators, such as file hashes or software tools are easy to change, while others are more difficult to replace. Detections based on such “narrow corridors” tend to have high true positive rates. To pursue this, detection should focus primarily on behavioral indicators, ensuring that attackers cannot easily evade detection by simply changing their tools or tactics. Priority should be given to behavior-based detection over tool-specific, software-dependent, or IoC-driven approaches. This aligns with the Pyramid of Pain model, which emphasizes detecting adversaries based on their tactics, techniques, and procedures (TTPs) rather than easily replaceable indicators. By prioritizing common TTPs, we can effectively identify an adversary’s modus operandi, making detection more resilient and impactful.
Universal rules
When planning a detection program from scratch, it is important not to ignore the universal threat detection rules that are mostly available in SIEM by default. Detection engineers should operationalize them as soon as possible and tune them according to feedback received from SOC analysts or what they have learned about the organization’s infrastructure during baselining activity.
Universal rules generally include malicious behavior associated with applications, databases, authentication anomalies, unusual remote access behavior, and policy violation rules (typically to monitor compliance requirements).
Some examples include:
Windows firewall settings modification detected
Use of unapproved remote access tools
Bulk failed database login attempts
Performance measurement
Every investment needs to be justified with measurable outcomes that demonstrate its value. That is why communicating the value of a detection engineering program requires the use of effective and actionable metrics that demonstrate impact and alignment with business objectives. These metrics can be divided into two categories: program-level metrics and technical-level metrics. Program-level metrics signal to security leadership that the program is well aligned with the company’s security objectives. Technical metrics, on the other hand, focus on how operational work is being carried out to maximize the detection engineering team’s operational efficiency. By measuring both program-level metrics and technical-level metrics, security leaders can clearly show how the detection engineering program supports organizational resilience while ensuring operational excellence.
Designing effective program-level metrics requires revisiting the core purpose for initiating the program. This approach helps identify metrics that clearly communicate success to security leadership. There are three metrics that can be very effective to measure the success at program level.
Time to Detect (TTD) – this metric is calculated as the time elapsed from the moment an attacker’s initial activity is observed until the time it is formally detected by the analyst. Some SOCs consider the time the alert is triggered on the SIEM as the detection time, but that is not really an actionable metric to consider. The time the alert is converted into a potential incident is the best option to consider for detection time by SOC analysts.
Although the initial detection of activity occurs at t1 (alert triggered), when malicious activity occurs, a series of events must be analyzed before qualifying the incident. This is why t3 is required to correctly qualify the detection as a potential threat. Additional metrics such as time to triage (TTT), which establishes how long it takes to qualify the incident, and time to investigate (TTI), which describes how long it takes to investigate the qualified incident, can also come in handy.
Time to detect compared to time to triage and time to investigate metrics
Signal-to-Noise Ratio (SNR) – this metric indicates the effectiveness of detection rules by measuring the balance between relevant and irrelevant information. It compares the number of true positive detections (correct alerts for real threats) to the number of false positives (incorrect or misleading alerts).
Where:
True positives: instances where a real threat is correctly detected False positives: incorrect alerts that do not represent real threats
A high SNR indicates that the system is generating more meaningful alerts (signal) compared to noise (false positives), thereby enhancing the efficiency of security operations by reducing alert fatigue and focusing analysts’ attention on genuine threats. Improving SNR is crucial to maximizing the performance and reliability of a detection program. SNR directly impacts the amount of SOC analyst effort spent on false positives, which in turn influences alert fatigue and the risk of professional burnout. Therefore, it is a very important metric to consider.
Threat Profile Alignment (TPA) – this metric evaluates how well detections are aligned with known adversarial tactics, techniques, and procedures (TTPs). This metric measures this by determining how many of the identified TTPs are adequately covered by unique detections (unique data components).
Total TTPs identified – this is the number of known adversarial techniques relevant to the organization’s threat model, typically derived from cyber threat intelligence threat profiling efforts Total TTPs covered with at least three unique detections (where possible) – this counts how many of the identified TTPs are covered by at least three distinct detection mechanisms. Having multiple detections for a given TTP enhances detection confidence, ensuring that if one detection fails or is bypassed, others can still identify the activity. Team efforts supporting the detection engineering program must also be measured to demonstrate progress. These efforts are reflected in technical-level metrics, and monitoring these metrics will help justify team scalability and address productivity challenges. Key metrics are outlined below:
Time to Qualify Detection (TTQD) – this metric measures the time required to analyze and validate the relevance of a detection for further processing. The Detection Engineering Lead assesses the importance of the detection and prioritizes it accordingly. The metric equals the time that has elapsed from when a ticket is raised to create a detection to when it is shortlisted for further research and implementation.
Time to Create Detection (TTCD) – this tracks the amount of time required to design, develop and deploy a new detection rule. It highlights the agility of detection engineering processes in responding to evolving threats.
Detection Backlog – the backlog refers to the number of pending detection rules awaiting review or consideration for detection improvement. A growing backlog might indicate resource constraints or inefficiencies.
Distribution of Rules Criticality (High, Medium, Low) – this metric shows the proportion of detection rules categorized by their criticality level. It helps in understanding the balance of focus between high-risk and lower-risk detections.
Detection Coverage (MITRE) – detection coverage based on MITRE ATT&CK indicates how well the detection rules cover various tactics, techniques, and procedures (TTPs) in the MITRE ATT&CK framework. It helps identify coverage gaps in the defense strategy. Tracking the number of unique detections that cover each specific technique is highly recommended, as it provides visibility into the threat profile alignment – a program level metric. If unique detections are not being built to detect gaps and the coverage is not increasing over time, it indicates an issue in the detection qualification process.
Share of Rules Never Triggered – this metric tracks the percentage of detection rules that have never been triggered since their deployment. It may indicate inefficiencies, such as overly specific or poorly implemented rules, and provides insight for rule optimization.
There are other relevant metrics, such as the proportion of behavior-based rules in the total set. Many more metrics can be derived from a general understanding of the detection engineering process and its purpose to support the DE program. However, program managers should focus on selecting metrics that are easy to measure and can be calculated automatically by available tools, minimizing the need for manual effort. Avoid using an excessive number of metrics, as this can lead to a focus on measurement only. Instead, prioritize a few meaningful metrics that provide valuable insight into the program’s progress and efforts. Choose wisely!
Eric Andersen – Blue River – Live in Tokyo 2012 freezonemagazine.com/articoli/… Per l’occasione di questo “momento Andersen” sono andato a rispolverare Today Is the Highway (1965) e, dopo sessant’anni, guardare il viso sorridente di Eric così come compariva sulla cover del suo album di debutto, con il berrettino di lana calato in testa, bavero alzato della pesante giacca in uno stile marinaio – mise che tradisce […] L'articolo Eric Andersen –
@Informatica (Italy e non Italy 😁) Con la pubblicazione di tre determinazioni cruciali, l’ACN ha di fatto dato il via alla seconda fase attuativa e operativa della NIS2. Un salto qualitativo nell’approccio alla cyber sicurezza nazionale che introduce un sistema formale di
@Notizie dall'Italia e dal mondo Nel caso dell'ultimo studente arrestato ieri negli Stati Uniti, il segretario di stato Rubio ha dichiarato che le proteste minacciando l'obiettivo di politica estera degli Stati Uniti di "risolvere il conflitto di
@Informatica (Italy e non Italy 😁) Un giro di forniture parallele aggira le sanzioni occidentali e porta i semiconduttori in Cina e Russia. Ecco come funziona. L'articolo Così si contrabbandano i microchip sotto restrizione proviene da Guerre di Rete.
Google ha distribuito un aggiornamento di emergenza per il browser Chrome in seguito all’individuazione di due gravi falle di sicurezza. Le vulnerabilità appena corrette avrebbero potuto permettere a cybercriminali di sottrarre informazioni sensibili e compromettere i dispositivi degli utenti, ottenendo accesso non autorizzato ai sistemi.
Le vulnerabilità interessano tutti gli utenti che utilizzano versioni obsolete di Google Chrome su piattaforme desktop. Tra questi rientrano privati, aziende ed enti governativi che utilizzano Chrome per la navigazione web e la gestione dei dati.
si tratta di due bug di sicurezza monitorati con il CVE-2025-3619 e il CVE-2025-3620, che interessano le versioni di Chrome precedenti alla 135.0.7049.95/.96 per Windows e Mac e alla 135.0.7049.95 per Linux. La più grave delle due, CVE-2025-3619, è un heap buffer overflow del nel componente Codecs di Chrome. Questa vulnerabilità può consentire agli aggressori di eseguire codice arbitrario sfruttando il modo in cui Chrome elabora determinati file multimediali, con il rischio di compromettere l’intero sistema e il furto di dati.
🚨 Threat Alert: Google Chrome Vulnerabilities CVE-2025-3619 and CVE-2025-3620
📅 Date: 2025-04-16
📌 Attribution: Elias Hohl (CVE-2025-3619), @retsew0x01 (CVE-2025-3620)
📝 Summary: Google released Chrome version 135.0.7049.95/.96 to patch two high-impact vulnerabilities:… — Syed Aquib (@syedaquib77) April 16, 2025
La seconda, CVE-2025-3620, è una falla di tipo “use-after-free” nel componente USB, che potrebbe essere sfruttata anche per eseguire codice dannoso o ottenere un accesso non autorizzato al sistema. Gli esperti di sicurezza avvertono che queste vulnerabilità sono particolarmente pericolose perché possono essere sfruttate da remoto: è sufficiente che l’utente visiti un sito web dannoso o interagisca con contenuti compromessi.
Una volta sfruttati, gli aggressori potrebbero rubare password, informazioni finanziarie e altri dati sensibili memorizzati nel browser o addirittura assumere il controllo del dispositivo interessato. L’aggiornamento verrà distribuito a livello globale nei prossimi giorni e settimane. Gli utenti che memorizzano password, dati di carte di credito o informazioni personali in Chrome sono particolarmente vulnerabili al furto di identità e alle frodi se il browser non viene aggiornato tempestivamente.
L’azienda ha temporaneamente limitato l’accesso alle informazioni dettagliate sui bug per proteggere gli utenti durante il rilascio dell’aggiornamento. Google attribuisce il merito della segnalazione delle vulnerabilità ai ricercatori di sicurezza esterni Elias Hohl e @retsew0x01, sottolineando l’importanza della collaborazione per mantenere la sicurezza del browser.
@Notizie dall'Italia e dal mondo Si è concluso il IX vertice della Comunità degli Stati americani e caraibici, l'organismo che rappresenta ancora una forte spina nel fianco per l'imperialismo Usa. L'articolo Celac, in Honduras il vertice ai pagineesteri.it/2025/04/16/ame…
I “relatori speciali” delle Nazioni Unite, esperti indipendenti che si occupano di controllare categorie specifiche di diritti all’interno dei paesi, hanno inviato una nuova comunicazione al governo italiano invitandolo ad abrogare il decreto Sicurezza (lo avevano già fatto a dicembre, quando ancora molte norme di questo decreto dovevano essere approvate all’interno di un disegno di legge). Tra le norme problematiche del “decreto Sicurezza” segnalate dall’ONU c’è proprio il reato di rivolta in carcere e nei CPR, definito «restrizione inutile e sproporzionata del diritto di protesta pacifica e di espressione» delle persone detenute.
We’ve all had times where we knew we had some part but we had to go searching for it all over as it wasn’t where we thought we put it. Organizing the numerous components, parts, and supplies that go into your projects can be a daunting task, especially if you use the same type of part at different times for different projects. It helps to have a framework to keep track of all the small details. Binner is an open source project that aims to allow you to easily maintain a database that can be customized to your use.
In a recent video for DigiKey, [Byte Sized Engineer] used Binner to track the locations of his components and parts in his freshly organized workshop. Binner already has the ability to read the labels used by well-known electronics suppliers via a barcode scanner, and uses that information to populate your inventory. It even grabs quantities and links in a datasheet for your newly added part. The barcode scanner can also be used to retrieve the contents of a location, so with a single scan Binner can bring up everything residing at that location.
Binner can be run locally so there isn’t the concern of putting in all the effort to build up your database just to have an internet outage make it inaccessible. Another cool feature is that it allows you to print labels, you can customize the fields to display the values you care about.
Canzoni per fantasmi freezonemagazine.com/articoli/… Alive in the superunknown First it steals your mind And then it steals your soul (Soundgarden, «Superunknown», 1994) Quando ero una ragazzina, non c’erano ancora i video musicali, però avevamo i 33 giri. Compravo un album (spesso di nascosto, perché i miei genitori trovavano discutibile il mio vizio di sputtanare i pochi soldi che […] L'articolo Canzoni per fantasmi proviene da FREE ZONE MAGAZIN Alive in the
@Informatica (Italy e non Italy 😁) Il Security Operations Center si conferma essenziale per la protezione delle infrastrutture digitali delle organizzazioni. In particolare, il Soc as a Service consente alle aziende di massimizzare il ROI (Return on investment) sfruttando i servizi SOC gestiti L'articolo Strategie di
@Informatica (Italy e non Italy 😁) L'ACN pubblica la determinazione 164179 con le specifiche tecniche per l'attuazione del decreto NIS2, definendo misure di sicurezza e requisiti per la notifica di incidenti. La determinazione, in vigore dal 30 aprile 2025, stabilisce
Fourlis Group, il gestore dei negozi IKEA in Grecia, Cipro, Romania e Bulgaria, ha dichiarato di aver subito un attacco ransomware prima del Black Friday del 27 novembre 2024, che ha causato danni per 20 milioni di euro (22,8 milioni di dollari).
L’incidente è stato segnalato il 3 dicembre 2024, quando l’azienda ha confermato che i problemi tecnici nei negozi online IKEA erano stati causati da un’influenza esterna dannosa. Sebbene il Gruppo Fourlis gestisca anche negozi Intersport, Foot Locker e Holland & Barrett nei paesi sopra elencati, l’impatto dell’attacco ha interessato principalmente le attività di IKEA.
“L’incidente ha causato interruzioni temporanee al rifornimento in negozio, principalmente nei negozi di articoli per la casa IKEA, e ha anche influenzato le operazioni di e-commerce tra dicembre 2024 e febbraio 2025”, afferma ora l’azienda in una nuova dichiarazione.
In una dichiarazione ai media locali, il CEO del gruppo Fourlis, Dimitris Valachis, ha affermato che i danni arrecati alle attività di vendita al dettaglio di IKEA dall’attacco sono stimati in 15 milioni di euro nel 2024 e altri 5 milioni di euro nel 2025. Valakhis ha inoltre sottolineato che l’azienda non ha pagato il riscatto agli aggressori e ha ripristinato il funzionamento dei sistemi interessati con l’aiuto di esperti di sicurezza informatica esterni. Hanno anche contribuito a respingere numerosi altri attacchi che hanno seguito il primo incidente.
Un’indagine sull’incidente non ha trovato prove di furto di dati, sebbene le autorità competenti per la protezione dei dati siano state informate dell’incidente. Sebbene siano trascorsi diversi mesi dall’attacco, nessun gruppo estorsivo ha rivendicato la responsabilità dell’accaduto. Si ritiene che gli hacker stiano zitti perché non sono riusciti a rubare alcun dato o perché sperano ancora di raggiungere un accordo privato con l’azienda interessata.
Noi di Red Hot Cyber lo diciamo da tempo: affidarsi esclusivamente a infrastrutture critiche gestite da enti statunitensi è un rischio per l’autonomia strategica europea. È anni che sosteniamo la necessità di creare un database europeo indipendente per la gestione delle vulnerabilità informatiche. Ad esempio, la Cina dispone già da tempo di un proprio sistema nazionale, operativo ed efficace, che le consente di mappare e gestire le vulnerabilità senza dipendere da entità esterne.
Ora che il programma CVE rischia il collasso per il mancato rinnovo dei fondi USA, diventa evidente quanto sia urgente costruire un’alternativa sovrana anche per l’Europa. Infatti l’accordo di finanziamento tra il governo degli Stati Uniti e l’organizzazione no-profit MITRE, responsabile del coordinamento del sistema Common Vulnerabilities and Exposures (CVE), terminerà oggi. Si tratta di un evento senza precedenti, che potrebbe compromettere seriamente una delle strutture portanti della sicurezza informatica a livello mondiale.
Da oltre due decenni, il sistema CVE costituisce uno strumento indispensabile per l’identificazione e la gestione delle falle di sicurezza. Il suo funzionamento si basa sull’assegnazione di codici univoci alle vulnerabilità note pubblicamente, offrendo così uno standard globale di riferimento per ricercatori, aziende e istituzioni.
Secondo quanto riferito da Yosry Barsoum, vicepresidente di MITRE e a capo del Center for Securing the Homeland (CSH), i fondi governativi destinati allo sviluppo e alla manutenzione del progetto CVE e di iniziative correlate, tra cui il Common Weakness Enumeration (CWE), non verranno rinnovati.
Barsoum ha lanciato un’allerta in una comunicazione ufficiale al consiglio di amministrazione del CVE, avvisando che un’interruzione del programma potrebbe generare effetti a catena: dai problemi nei database e nei bollettini di vulnerabilità a livello nazionale, fino all’impatto su strumenti di sicurezza, attività di incident response e settori critici dell’infrastruttura tecnologica.
Nonostante lo scenario preoccupante, Barsoum ha precisato che l’esecutivo statunitense continua a investire energie nel sostenere il ruolo centrale di MITRE all’interno del programma. Ha inoltre ribadito la volontà dell’organizzazione di contribuire alla protezione globale contro minacce come terrorismo e cybercrime.
Creato nel 1999 sotto l’egida del Dipartimento della Sicurezza Interna (DHS) e dell’agenzia CISA, il progetto CVE viene amministrato da MITRE e rappresenta oggi una colonna portante per la difesa informatica. Nel tentativo di contenere gli effetti di una possibile interruzione, la società VulnCheck, attiva come CVE Numbering Authority (CNA), ha deciso di riservare in anticipo 1.000 identificatori per l’anno 2025.
Anche Tim Peck, esperto in analisi delle minacce presso Securonix, ha espresso forti preoccupazioni: la mancanza di trasparenza nel processo di pubblicazione degli ID CVE rischierebbe di rallentare o impedire la divulgazione tempestiva delle vulnerabilità. Il progetto CWE, ha aggiunto, è essenziale per comprendere e classificare le debolezze nei software: un suo blocco comprometterebbe pratiche di sviluppo sicuro e sistemi di valutazione dei rischi. In sintesi, CVE non è semplicemente un catalogo, ma un punto di riferimento vitale per tutta la cybersecurity, dall’ambito open source a quello istituzionale e aziendale.
Si prevede che il prossimo kernel Linux 6.15 presenterà importanti miglioramenti nel sottosistema di crittografia, con ottimizzazioni particolarmente interessanti rivolte ai moderni processori Intel e AMD con architettura x86_64.
La scorsa settimana tutti gli aggiornamenti del codice crittografico erano già erano uniti al ramo di sviluppo principale.
Tra queste rientrano la rimozione dell’interfaccia di compressione legacy, un’API migliorata per lavorare con dati sparsi nella memoria (scatterwalk), il supporto per gli algoritmi Kerberos5, la rimozione del codice non necessario per i fallback SIMD, l’aggiunta di un nuovo identificatore di dispositivo PCI “0x1134” al driver AMD CCP (probabilmente per un dispositivo che non è stato ancora annunciato) e una serie di correzioni di bug. Ma l’aggiornamento principale che sarà evidente agli utenti abituali è la nuova implementazione di AES-CTR mediante l’istruzione VAES. Questo codice è ottimizzato per gli ultimi processori Intel e in particolar modo per AMD Zen 5. Questa particolare serie di patch è stata precedentemente segnalata come in grado di accelerare AES-CTR su Zen 5 fino a 3,3 volte rispetto alle implementazioni precedenti.
L’ottimizzazione si basa su una combinazione di AESNI, AVX e VAES, moderni set di istruzioni che accelerano la crittografia a livello hardware. L’autore dei miglioramenti è stato ancora una volta l’ingegnere di Google Eric Biggers, già noto per i suoi contributi all’accelerazione della crittografia in Linux. Si tratta di un proseguimento della tendenza riscontrata nelle recenti versioni del kernel, in cui sempre più algoritmi ricevono supporto per percorsi di esecuzione hardware efficienti, soprattutto sulle piattaforme x86_64.
Pertanto, gli utenti dei nuovi sistemi basati su AMD e Intel noteranno notevoli miglioramenti nelle prestazioni quando utilizzano la crittografia, soprattutto in scenari ad alta intensità di dati.
The General Instruments AY-3-8910 was a quite popular Programmable Sound Generator (PSG) that saw itself used in a wide variety of systems, including Apple II soundcards such as the Mockingboard and various arcade systems. In addition to the Yamaha variants (e.g. YM2149), two cut-down were created by GI: these being the AY-3-8912 and the AY-3-8913, which should have been differentiated only by the number of GPIO banks broken out in the IC package (one or zero, respectively). However, research by [fenarinarsa] and others have shown that the AY-3-8913 variant has some actual hardware issues as a PSG.
With only 24 pins, the AY-3-8913 is significantly easier to integrate than the 40-pin AY-3-8910, at the cost of the (rarely used) GPIO functionality, but as it turns out with a few gotchas in terms of timing and register access. Although the Mockingboard originally used the AY-3-8910, latter revisions would use two AY-3-8913 instead, including the MS revision that was the Mac version of the Mindscape Music Board for IBM PCs.
The first hint that something was off with the AY-3-8913 came when [fenarinarsa] was experimenting with effect composition on an Apple II and noticed very poor sound quality, as demonstrated in an example comparison video (also embedded below). The issue was very pronounced in bass envelopes, with an oscilloscope capture showing a very distorted output compared to a YM2149. As for why this was not noticed decades ago can likely be explained by that the current chiptune scene is pushing the hardware in very different ways than back then.
As for potential solutions, the [French Touch] project has created an adapter to allow an AY-3-8910 (or YM2149) to be used in place of an AY-3-8913.
Top image: Revision D PCB of Mockingboard with GI AY-3-8913 PSGs.
If we asked you to name Alexander Graham Bell’s greatest invention, you would doubtless say “the telephone”; it’s probably the only one of his many, many inventions most people could bring to mind. If you asked Bell himself, though, he would tell you his greatest invention was the photophone, and if the prolific [Nick Bild] doesn’t agree he’s at least intrigued enough to produce a replica of this 1880-vintage wireless telephone. Yes, 1880. As in, only four years after the telephone was patented.
It obviously did not catch on, and is not the sort of thing that comes to mind when we think “wireless telephone”. In contrast to the RF of the 20th century version, as you might guess from the name the photophone used light– sunlight, to be specific. In the original design, the transmitter was totally passive– a tube with a mirror on one end, mounted to vibrate when someone spoke into the open end of the tube. That was it, aside from the necessary optics to focus sunlight onto said mirror. [Nick Bild] skips this and uses a laser as a handily coherent light source, which was obviously not an option in 1880. As [Nick] points out, if it was, Bell certainly would have made use of it. The photophone receiver, 1880 edition. Speaker not pictured. The receiver is only slightly more complex, in that it does have electronic components– a selenium cell in the original, and in [Nick’s] case a modern photoresistor in series with a 10,000 ohm resistor. There’s also an optical difference, with [Nick] opting for a lens to focus the laser light on his photoresistor instead of the parabolic mirror of the original. In both cases vibration of the mirror at the transmitter disrupts line-of-sight with the receiver, creating an AM signal that is easily converted back into sound with an electromagnetic speaker.
The photophone never caught on, for obvious reasons — traditional copper-wire telephones worked beyond line of sight and on cloudy days–but we’re greatful to [Nick] for dredging up the history and for letting us know about it via the tip line. See his video about this project below.
[Geoffrey Litt] shows that getting an effective digital assistant that’s tailored to one’s own needs just needs a little DIY, and thanks to the kinds of tools that are available today, it doesn’t even have to be particularly complex. Meet Stevens, the AI assistant who provides the family with useful daily briefs. The back end? Little more than one SQLite table and a few cron jobs. A sample of Stevens’ notebook entries, both events and things to simply remember. Every day, Stevens sends a daily brief via Telegram that includes calendar events, appointments, weather notes, reminders, and even a fun fact for the day. Stevens isn’t just send-only, either. Users can add new entries or ask questions about items through Telegram.
It’s rudimentary, but [Geoffrey] already finds it far more useful than Siri. This is unsurprising, as it has been astutely observed that big tech’s digital assistants are designed to serve their makers rather than their users. Besides, it’s also fun to have the freedom to give an assistant its own personality, something existing offerings sorely lack.
Architecture-wise, the assistant has a notebook (the single SQLite table) that gets populated with entries. These entries come from things like reading family members’ Google calendars, pulling data from a public weather API, processing delivery notices from the post office, and Telegram conversations. With a notebook of such entries (along with a date the entry is expected to be relevant), generating a daily brief is simple. After all, LLMs (Large Language Models) are amazingly good at handling and formatting natural language. That’s something even a locally-installed LLM can do with ease.
[Geoffrey] says that even this simple architecture is super useful, and it’s not even a particularly complex system. He encourages anyone who’s interested to check out his project, and see for themselves how useful even a minimally-informed assistant can be when it’s designed with ones’ own needs in mind.
1) hai scritto Nicola Zingaretti, ma probabilmente intendevi Luca Zingaretti 2) non pubblicare solo i link, ma riporta il titolo del post e un breve riassunto.
A questo proposito, hai provato a utilizzare gli strumenti di Friendica per ripubblicare i post del tuo blog sul tuo account Friendica? Puoi dare un'occhiata al link seguente: informapirata.it/2024/07/25/w-…
Nella maggior parte dei lavori nell’ambito di Machine Learning, non si fa ricerca per migliorare l’architettura di un modello o per progettare una nuova loss function. Nella maggior parte dei casi si deve utilizzare ciò che già esiste e adattarlo al proprio caso d’uso.
È quindi molto importante ottimizzare il progetto in termini di architettura del software e di implementazione in generale. Tutto parte da qui: si vuole un codice ottimale, che sia pulito, riutilizzabile e che funzioni il più velocemente possibile. Threading è una libreria nativa di Python che non viene utilizzata così spesso come dovrebbe.
Riguardo i Thread
I thread sono un modo per un processo di dividersi in due o più attività in esecuzione simultanea (o pseudo-simultanea). Un thread è contenuto all’interno di un processo e thread diversi dello stesso processo condividono le stesse risorse.
In questo articolo non si parlo di multiprocessing, ma la libreria per il multiprocessing di Python funziona in modo molto simile a quella per il multithreading.
In generale:
Il multithreading è ottimo per i compiti legati all’I/O, come la chiamata di un’API all’interno di un ciclo for
Il multiprocessing è usato per i compiti legati alla CPU, come la trasformazione di più dati tabellari in una volta sola
Quindi, se vogliamo eseguire più cose contemporaneamente, possiamo farlo usando i thread. La libreria Python per sfruttare i thread si chiama threading.
Cominciamo in modo semplice. Voglio che due thread Python stampino qualcosa contemporaneamente. Scriviamo due funzioni che contengono un ciclo for per stampare alcune parole.
def print_hello(): for x in range(1_000): print("hello")
def print_world(): for x in range(1_000): print("world")
Ora, se li eseguo uno dopo l’altro, vedrò nel mio terminale 1.000 volte la parola “hello” seguita da 1.000 “world”.
Utilizziamo invece i thread. Definiamo due thread e assegniamo a ciascuno di essi le funzioni definite in precedenza. Poi avviamo i thread. Dovreste vedere la stampa di “hello” e “world” alternarsi sul vostro terminale.
Se prima di continuare l’esecuzione del codice si vuole aspettare che i thread finiscano, è possibile farlo utilizzando: join().
# wait for the threads to finish before continuing running the code thread_1.join() thread_2.join()
print("do other stuff")
Lock delle risorse dei thread
A volte può accadere che due o più thread modifichino la stessa risorsa, ad esempio una variabile contenente un numero.
Un thread ha un ciclo for che aggiunge sempre uno alla variabile e l’altro sottrae uno. Se eseguiamo questi thread insieme, la variabile avrà “sempre” il valore di zero (più o meno). Ma noi vogliamo ottenere un comportamento diverso. Il primo thread che prenderà possesso di questa variabile deve aggiungere o sottrarre 1 fino a raggiungere un certo limite. Poi rilascerà la variabile e l’altro thread sarà libero di prenderne possesso e di eseguire le sue operazioni.
import threading import time
x = 0 lock = threading.Lock()
def add_one(): global x, lock # use global to work with globa vars lock.acquire() while x -10: x = x -1 print(x) time.sleep(1) print("reached minimum") lock.release()
Nel codice sopra riportato, abbiamo due funzioni. Ciascuna sarà eseguita da un thread. Una volta avviata, la funzione bloccherà la variabile lock, in modo che il secondo thread non possa accedervi finché il primo non ha finito.
Possiamo ottenere un risultato simile a quello ottenuto sopra utilizzando i semafori. Supponiamo di voler far accedere a una funzione un numero totale di thread contemporaneamente. Ciò significa che non tutti i thread avranno accesso a questa funzione, ma solo 5, per esempio. Gli altri thread dovranno aspettare che alcuni di questi 5 finiscano i loro calcoli per avere accesso alla funzione ed eseguire lo script. Possiamo ottenere questo comportamento utilizzando un semaforo e impostando il suo valore a 5. Per avviare un thread con un argomento, possiamo usare args nell’oggetto Thread.
import time import threading
semaphore = threading.BoudnedSemaphore(value=5)
def func(thread_number): print(f"{thread_number} is trying to access the resource") semaphore.acquire()
print(f"{thread_number} granted access to the resource") time.sleep(12) #fake some computation
print(f"{thread_number} is releasing resource") semaphore.release()
if __name__ == "__main__": for thread_number in range(10): t = threading.Thread(target = func, args = (thread_number,) t.start() time.sleep(1)
Eventi
Gli eventi sono semplici meccanismi di segnalazione usati per coordinare i thread. Si può pensare a un evento come a un flag che si può selezionare o deselezionare, e gli altri thread possono aspettare che venga selezionato prima di continuare il loro lavoro.
Ad esempio, nel seguente esempio, il thread_1 che vuole eseguire la funzione “func” deve attendere che l’utente inserisca “sì” e scateni l’evento per poter terminare l’intera funzione.
import threading
event = threading.Event()
def func(): print("This event function is waiting to be triggered") event.wait() print("event is triggered, performing action now")
x = input("Do you want to trigger the event? \n") if x == "yes": event.set() else print("you chose not to trigger the event")
Daemon Thread
Si tratta semplicemente di thread che vengono eseguiti in background. Lo script principale termina anche se questo thread in background è ancora in esecuzione. Ad esempio, si può usare un thread demone per leggere continuamente da un file che viene aggiornato nel tempo.
Scriviamo uno script in cui un thread demone legge continuamente da un file e aggiorna una variabile stringa e un altro thread stampa su console il contenuto di tale variabile.
import threading import time
path = "myfile.txt" text = ""
def read_from_file(): global path, text while True: with open(path, "r") as f: text = f.read() time.sleep(4)
def print_loop(): for x in range(30): print(text) time.sleep(1)
Una coda è un insieme di elementi che obbedisce al principio first-in/first-out (FIFO). È un metodo per gestire strutture di dati in cui il primo elemento viene elaborato per primo e l’elemento più recente per ultimo.
Possiamo anche cambiare l’ordine di priorità con cui processiamo gli elementi della collezione. LIFO, ad esempio, sta per Last-in/First-out. Oppure, in generale, possiamo avere una coda di priorità in cui possiamo scegliere manualmente l’ordine. Se più thread vogliono lavorare su un elenco di elementi, ad esempio un elenco di numeri, potrebbe verificarsi il problema che due thread eseguano calcoli sullo stesso elemento. Vogliamo evitare questo problema. Perciò possiamo avere una coda condivisa tra i thread e, quando un thread esegue il calcolo su un elemento, questo elemento viene rimosso dalla coda. Vediamo un esempio.
import queue
q = queue.Queue() # it can also be a LifoQueue or PriorityQueue number_list = [10, 20, 30, 40, 50, 60, 70, 80]
for number in number_list: q.put(number)
print(q.get()) # -> 10 print(1.het()) # -> 20
Un esempio di thread in un progetto di Machine Learning
Supponiamo di lavorare a un progetto che richiede una pipeline di streaming e preelaborazione dei dati. Questo accade in molti progetti con dispositivi IoT o qualsiasi tipo di sensore. Un thread demone in background può recuperare e preelaborare continuamente i dati mentre il thread principale si concentra sull’inferenza.
Per esempio, in un caso semplice in cui devo sviluppare un sistema di classificazione delle immagini in tempo reale utilizzando il feed della mia telecamera. Imposterei il mio codice con 2 thread:
Recuperare le immagini dal feed della telecamera in tempo reale.
Passare le immagini a un modello di AI per l’inferenza.
import threading import time import queue import random
# Sfake image classifier def classify_image(image): time.sleep(0.5) # fake the model inference time return f"Classified {image}"
def camera_feed(image_queue, stop_event): while not stop_event.is_set(): # Simulate capturing an image image = f"Image_{random.randint(1, 100)}" print(f"[Camera] Captured {image}") image_queue.put(image) time.sleep(1) # Simulate time between captures
def main_inference_loop(image_queue, stop_event): while not stop_event.is_set() or not image_queue.empty(): try: image = image_queue.get(timeout=1) # Fetch image from the queue result = classify_image(image) print(f"[Model] {result}") except queue.Empty: continue
if __name__ == "__main__": image_queue = queue.Queue() stop_event = threading.Event()
try: main_inference_loop(image_queue, stop_event) except KeyboardInterrupt: print("Shutting down...") stop_event.set() # Signal the camera thread to stop finally: camera_thread.join() # Ensure the camera thread terminates properly print("All threads terminated.")
In questo semplice esempio, abbiamo:
Un thread demone: L’input della telecamera viene eseguito in background, in modo da non bloccare l’uscita del programma al completamento del thread principale.
Evento per il coordinamento: Questo evento stop_event consente al thread principale di segnalare al thread demone di terminare.
Coda per la comunicazione: image_queue assicura una comunicazione sicura tra i thread.
Conclusioni
In questo tutorial vi ho mostrato come utilizzare la libreria di threading in Python, affrontando concetti fondamentali come lock, semafori ed eventi, oltre a casi d’uso più avanzati come i thread daemon e le code.
Vorrei sottolineare che il threading non è solo skill tecnica, ma piuttosto una mentalità che consente di scrivere codice pulito, efficiente e riutilizzabile. Quando si gestiscono chiamate API, si elaborano flussi di dati di sensori o si costruisce un’applicazione di AI in tempo reale, il threading consente di costruire sistemi robusti, reattivi e pronti a scalare.
[Chris Cecil] had a problem. He had a Manncorp/Autotronik MC384V2 pick and place, and needed more feeders. The company was reluctant to support an older machine and wanted over $32,000 to supply [Chris] with more feeders. He contemplated the expenditure… but then came across another project which gave him pause. Could he make Siemens feeders work with his machine?
It’s one of those “standing on the shoulders of giants” stories, with [Chris] building on the work from [Bilsef] and the OpenPNP project. He came across SchultzController, which could be used to work with Siemens Siplace feeders for pick-and-place machines. They were never supposed to work with his Manncorp machine, but it seemed possible to knit them together in some kind of unholy production-focused marriage. [Chris] explains how he hooked up the Manncorp hardware to a Smoothieboard and then Bilsef’s controller boards to get everything working, along with all the nitty gritty details on the software hacks required to get everything playing nice.
For an investment of just $2,500, [Chris] has been able to massively expand the number of feeders on his machine. Now, he’s got his pick and place building more Smoothieboards faster than ever, with less manual work on his part.
We feature a lot of one-off projects and home production methods, but it’s nice to also get a look at methods of more serious production in bigger numbers, too. It’s a topic we follow with interest. Video after the break.
Una interessante spaccato storico sulle modalità di pubblicazione adottate, partendo da Hubzilla e Pterotype a #Ghost e #Wordpress con i suoi fantastici Plugin
ho sperimentato l'integrazione del mio progetto di pubblicazione di notizie con il Fediverse per quasi cinque anni. Ci sono stati diversi esperimenti, errori e momenti di insegnamento che mi hanno portato dove sono oggi. Voglio parlare di alcune delle cose che ho provato e del perché queste cose sono state importanti per me.
I wrote up an article on my personal (Ghost-powered!) blog about some of the work I’ve been doing to integrate our news publication at We Distribute into the #Fediverse.
This is the culmination of years and years of experiments, and we’re almost to a point where most of our ideas have been realized.
By the way, we take this opportunity to let @Sean Tilley and @Alex Kirk know that we tried the "Enable Mastodon Apps" plugin with #RaccoonforFriendica, which is an app developed for Friendica by @Dieguito 🦝 but is also compatible with Mastodon, but also allows you to write in simplified HTML with a very functional toolbar.
Well, it was wonderful to write formatted texts and with links from Raccoon for Friendica, even if I haven't managed to get the mentions to work yet.
Unfortunately, even if Raccoon allows you to publish posts with inline images, it can only do so with Friendica, while with the simple Mastodon API this is not possible.
If you’ve worked on a high-end mountain or road bike for any length of time, you have likely cursed the Presta valve. This humble century-old invention is the bane of many a home and professional mechanic. What if there is a better option? [Seth] decided to find out by putting four valves on a single rim.
The contenders include the aforementioned Presta, as well as Schrader, Dunlop and the young gun, Click. Schrader and Dunlop both pre-date Presta, with Schrader finding prevalence in cruiser bicycles along with cars and even aircraft. Dunlop is still found on bicycles in parts of Asia and Europe. Then came along Presta some time around 1893, and was designed to hold higher pressures and be lower profile then Schrader and Dunlop. It found prevalence among the weight conscious and narrow rimmed road bike world and, for better or worse, stuck around ever since.
But there’s a new contender from industry legend Schwalbe called Click. Click comes with a wealth of nifty modern engineering tricks including its party piece, and namesake, of a clicking mechanical locking system, no lever, no screw attachment. Click also fits into a Presta valve core and works on most Presta pumps. Yet, it remains to be seen weather Click is just another doomed standard, or the solution to many a cyclists greatest headache.
This isn’t the first time we’ve seen clever engineering going into a bike valve.
This week is a bit of a shorter Report, it’s a relatively quieter news week and some other work is taking up most of my attention this week. Still, there is a PeerTube roadmap for 2025, some more updates on how FediForum is moving forward and more.
The News
Framasoft has published their PeerTube roadmap for 2025. Last year, PeerTube’s big focus was on the consumer, with the launch of the PeerTube apps. This year, PeerTube’s improvement is on instance administrators. The organisation will work on building a set-wizard, making it easier for new instance admins to get started and configure the platform. Framasoft will also work on further customisation for instances, allowing admins to further tune how the instance looks for the end-users. There is also a lot of work being done on video channels, with the new features being the ability to transfer ownership of a channel, as well as having channels that are owned by multiple accounts. Framasoft also mentions they are working on shared lists of blocked accounts and instances, where admins can share information with other admins on which instances to block. And now that PeerTube is available on Android and iOS, other new platforms that PeerTube will come to is tablets and Android TVs.
The planned FediForum for early April was cancelled at the last minute. A group of attendees held the Townhall event that was held in its place to discuss how to move forward, and listen to people’s perspectives. The notes of the FediForum Townhall have now been published. Last week, the FediForum account posted: “Planned next steps: another townhall likely next week, and a rescheduled & adapted FediForum in May.” The organisers posted a survey for attendees on how to move forward as well. Jon Pincus has an extensive article, “On FediForum (and not just FediForum)” that places the entire situation of why FediForum was cancelled, in its larger context.
PieFed now allows people to limit who can DM them. By default only people on the same instance can receive DMs from each other. The Piefed/Lemmy/Mbin network has seen a rise on spam DMs which send gore images, and this is a helpful way of dealing with this harassment.
IFTAS wrote about how they are continuing their mission. The organisation recently had to wind down most of their high-profile projects due to a lack of funding. This is not the end of the entire organisation however, as IFTAS will continue with their Moderator Needs Assessment, the CARIAD domain observatory, which provides insight in the most commonly blocked domains and more, as well as the IFTAS Connect community for fediverse moderators.
A master’s thesis on the fediverse, which looks at the user activity and governance structures, with the main finding: “The findings reveal that instance size and active engagement—such as frequent posting and interacting with others—are the strongest predictors of user activity, while technical infrastructure plays a more supportive role rather than a determining one. Governance structures, such as moderation practices and community guidelines, show a weaker but positive correlation with user activity.”
Sean Tilley from WeDistribute writes how his work on ‘Integrating a News Publication Into the Fediverse’. Tilley has over a decade of experimentation on building journalistic outlets on fediverse platforms, and in this article he reflects on all the different case studies he has done over the years, and where WeDistribute is headed next.
Building a blog website on Lemmy. This personal website uses Lemmy as a backend for a personal blogging site, where the site is effectively a Lemmy client that looks like a blogging site.
That’s all for this week, thanks for reading! You can subscribe to my newsletter to get all my weekly updates via email, which gets you some interesting extra analysis as a bonus, that is not posted here on the website. You can subscribe below:
A dog may be man’s best friend, but many of us live with cats, fish, iguanas, or even wilder animals. And naturally, we like to share our hacks with our pets. Whether it’s a robot ball-thrower, a hamster wheel that’s integrated into your smart home system, or even just an automatic feeder for when you’re not home, we want to see what kind of projects that your animal friends have inspired you to pull off.
Of course, we have a couple thoughts about fun directions to take this contest, and we’ll be featuring entries along the way. Just to whet your whistle, here are our four honorable mention categories.
Pet Safety: Nothing is better than a hack that helps your pet stay out of trouble. If your hack contributes to pet safety, we want to see it.
Playful Pets: Some hacks are just for fun, and that goes for our pet hacks too. If it’s about amusing either your animal friend or even yourself, it’s a playful pet hack.
Cyborg Pets: Sometimes the hacks aren’t for your pet, but on your pet. Custom pet prosthetics or simply ultra-blinky LED accouterments belong here.
Home Alone: This category is for systems that aim to make your pet more autonomous. That’s not limited to vacation feeders – anything that helps your pet get along in this world designed for humans is fair game.
Inspiration
We’ve seen an amazing number of pet hacks here at Hackaday, from simple to wildly overkill. And we love them all! Here are a few of our favorite pet hacks past, but feel free to chime in the comments if you have one that didn’t make our short list.
Let’s start off with a fishy hack. Simple aquariums don’t require all that much attention or automation, so they’re a great place to start small with maybe a light controller or something that turns off your wave machine every once in a while. But when you get to the point of multiple setups, you might also want to spend a little more time on the automation. Or at least that’s how we imagine that [Blue Blade Fish] got to the point of a system with multiple light setups, temperature control, water level sensing, and more. It’s a 15-video series, so buckle in.
We had a lot of fun looking through Hackaday’s back-catalog of pet hacks, but we’re still missing yours! If you’ve got something you’d like us all to see, head on over to Hackaday.io and enter it in the contest. Fame, fortune, and a DigiKey gift certificate await!
 - Collegamento all'originale")








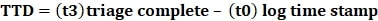

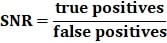

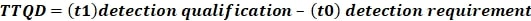
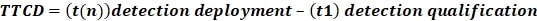
























Signor Amministratore ⁂
in reply to alessandro tenaglia • •Due osservazioni:
1) hai scritto Nicola Zingaretti, ma probabilmente intendevi Luca Zingaretti
2) non pubblicare solo i link, ma riporta il titolo del post e un breve riassunto.
A questo proposito, hai provato a utilizzare gli strumenti di Friendica per ripubblicare i post del tuo blog sul tuo account Friendica?
Puoi dare un'occhiata al link seguente: informapirata.it/2024/07/25/w-…