The media in this post is not displayed to visitors. To view it, please log in.

With International Anti-Ransomware Day taking place on May 12, Kaspersky presents its annual report on the evolving global and regional ransomware cyberthreat landscape.
Ransomware remains one of the most persistent and adaptive cyberthreats. In 2026:
- New families continue to emerge, adopting post-quantum cryptography ciphers.
- As ransom payments drop, some groups implement encryptionless extortion attacks.
- In a constantly changing ecosystem of threat actors, initial access brokers maintain a relevant role in this market, showing increased focus on access to RDWeb as the preferred method of remote access.
Ransomware attacks decline but remain a major threat
According to Kaspersky Security Network, the share of organizations affected by ransomware decreased in 2025 across all regions compared to 2024.
Percentage of organizations affected by ransomware attacks by region, 2025 (download)
Despite the formal decrease, organizations across all sectors continue to face a high likelihood of attack, as ransomware operators refine their tactics and scale their operations with increasing efficiency. Kaspersky and VDC Research have found that in the manufacturing sector alone, ransomware attacks may have caused over $18 billion in losses in the first three quarters of the year.
The continued rise of EDR killers and defense evasion tooling
In 2026, ransomware operators increasingly prioritize neutralizing endpoint defenses before executing their payloads. Tools commonly referred to as “EDR killers” have become a standard component of attack playbooks. This reflects a continuing trend toward more deliberate and methodical intrusions.
Attackers attempt to terminate security processes and disable monitoring agents, often by exploiting trusted components such as signed drivers. This technique is called Bring Your Own Vulnerable Driver (BYOVD) and allows adversaries to blend into legitimate system activity while gradually degrading defensive visibility.
Thus, evasion is no longer an opportunistic step but a planned and repeatable phase of the attack lifecycle. As a result, organizations are increasingly challenged not just to detect ransomware but also to maintain control in environments where security controls themselves are actively targeted.
The appearance of new families adopting post-quantum cryptography
We predicted that quantum-resistant ransomware would appear in 2025. Looking back at the previous year, we see that advanced ransomware groups indeed started using post-quantum cryptography as quantum computing evolved. The encryption techniques used by this quantum-proof ransomware could be used to resist decryption attempts from both classical and quantum computers, making it nearly impossible for victims to decrypt their data without having to pay a ransom.
One example is the appearance of the PE32 ransomware family (link in Russian); it leverages the cutting-edge ML-KEM (Module-Lattice-Based Key-Encapsulation Mechanism) standard to secure its AES keys. This specific cryptographic framework was recently selected by NIST as the primary standard for post-quantum defense.
Within the PE32 ransomware architecture, this is realized through the Kyber1024 algorithm, a robust mechanism providing Level 5 security, roughly equivalent in strength to AES-256. Its primary function is the secure generation and transmission of shared secrets between parties, specifically engineered to withstand future quantum computing attacks. This shift toward post-quantum readiness is part of a broader industry trend; for instance, TLS 1.3 and QUIC protocols have already adopted the X25519Kyber768 hybrid model, which fuses classical encryption with quantum-resistant security.
The shift to encryptionless extortion
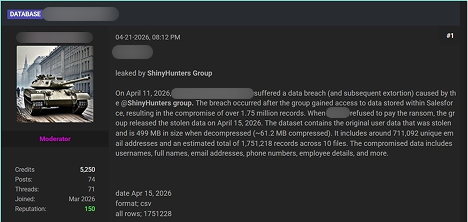
In 2025, the share of ransoms paid dropped to 28%. As a response to this, one of the developments in the 2026 landscape is the growing prevalence of extortion incidents in which no file encryption takes place at all. Instead, attackers leave out the “ware” in “ransomware” and focus on extracting sensitive data and leveraging the threat of public disclosure as their primary means of extortion. ShinyHunters is an excellent example of such a group, using a data leak site to publicize its victims.
By avoiding encryption, attackers may aim at reducing the likelihood of immediate detection, shortening the duration of the attack, and eliminating dependencies on stable encryption routines. Often, this model is used alongside traditional tactics in so-called double extortion schemes, but an increasing number of campaigns rely exclusively on data theft.
For victims, this shift fundamentally changes the nature of the risk. While backups remain effective against encryption-based disruption, they provide no protection against data exposure, regulatory consequences, and reputational damage. Ransomware is therefore evolving from a business continuity issue into a broader data security and compliance challenge.
Industrialization of initial access (Access-as-a-Service)
The ransomware ecosystem continues to evolve toward a highly industrialized and specialized model, with initial access remaining as one of its most critical components. In 2026, many ransomware operators keep relying on IABs (initial access brokers), a network of intermediaries who supply pre-compromised access to corporate environments, aiming to no longer perform full intrusions themselves.
This “access-as-a-service” model is fueled by credential theft operations, and the widespread availability of compromised accounts harvested through infostealers and phishing campaigns.
The primary access vectors offered for sale have not changed: RDP, VPN, and RDWeb are still the top access vectors. Consequently, remote access infrastructure remains the primary attack surface for initial access sales. In response to the measures against public exposure of RDP access points to the internet, attackers are now targeting RDWeb portals, which are frequently vulnerable and occasionally inadequately safeguarded.
The result is a threat landscape where unauthorized access is increasingly commoditized, and the barrier to launching ransomware attacks declines. This means that preventing initial compromise is only part of the challenge; equal emphasis must be placed on detecting misuse of legitimate credentials and limiting lateral movement within already-breached environments.
Ransomware developments on the dark web
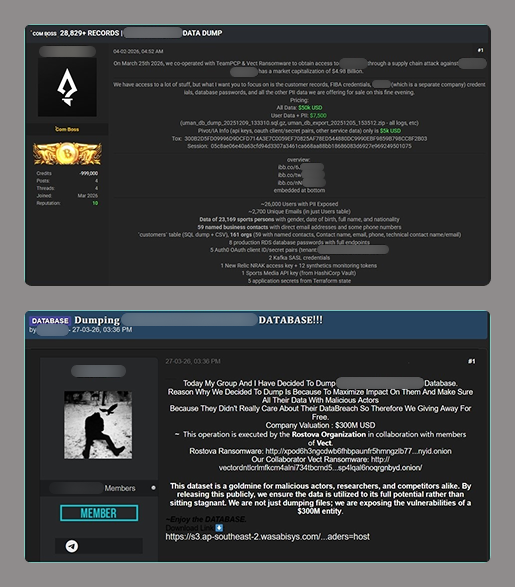
Telegram channels and underground forums increasingly function as platforms for the distribution and sale of compromised datasets and access credentials including those that were obtained as a result of ransomware attacks.
Advertisements posted on these resources typically include the nature of the access, a description of the exfiltrated or compromised data, price terms, and contact information for prospective buyers. In addition, some malicious actors mention their collaboration with other ransomware groups. Lesser-known gangs can use this name-dropping to promote themselves

Multiple threat actors not related to ransomware groups distribute datasets downloaded from ransomware blogs on underground forums and Telegram. By re-publishing download links and files, they spread compromised data as well as information on the ransomware attack within the community.

The ransomware itself is also sold or offered for subscription on the dark web platforms. The sellers underscore the uniqueness of their malware, as well as its encryption and defense evasion features.

Law enforcement actions
Law enforcement agencies are actively shutting down dark web platforms and ransomware data leak sites. A major underground forum, RAMP, which also functioned as a platform for threat actors to advertise their ransomware services and publish service‑related updates, was seized by authorities in January 2026. Another underground forum, LeakBase, where malicious actors distributed exfiltrated and compromised data, was seized in March 2026. In 2025, law enforcement agencies seized well-known forums like Nulled, Cracked, and XSS. Also in 2025, the DLSs of BlackSuit and 8Base ransomware groups were seized. These takedowns cause inconvenience to ransomware coordination, specifically for initial access brokers and affiliates, though similar forums are expected to fill the void over time.

Top ransomware groups in 2025
RansomHub’s sudden dormancy in 2025 marked a shift, and Qilin became the dominant player from Q2 onward. According to Kaspersky research, Qilin was the most active group executing targeted attacks in 2025.
Each group’s share of victims according to its data leak site (DLS) as a percentage of all reported victims of all groups during the period under review (download)
Qilin stands out as one of the fastest-growig and dominant RaaS platforms. Its combination of high-volume operations and structured affiliate model positions it as a central player in the current ecosystem.
Clop, the second most active group in 2025, is distinguished through its large-scale, supply-chain-style attacks, exploiting widely used file transfer and enterprise software to compromise hundreds of victims simultaneously. This one-to-many approach sets it apart from more traditional, single-target campaigns.
Third place is occupied by Akira, which remains notable for its consistency and operational stability, maintaining a steady stream of victims without major disruption. Its ability to sustain activity over time makes it one of the most reliable indicators of baseline ransomware threat levels.
Although no longer active, RansomHub stands out for its rapid rise and equally rapid disappearance in 2025, highlighting the volatility of the RaaS market. Its shutdown created a vacuum that significantly reshaped affiliate distribution across other groups.
DragonForce is also notable – not just for its own operations, but for its broader influence within the ransomware ecosystem, including reported involvement in infrastructure conflicts and possible links to the disruption of competing groups. Thus, the group claims that RansomHub “has moved to their infrastructure.” This positions it as more than just an operator and potentially an ecosystem-level actor.

New actors in 2026
While emerging actors generally operate on a smaller scale, they provide insight into the continuous churn and low barrier to entry within the ransomware ecosystem.
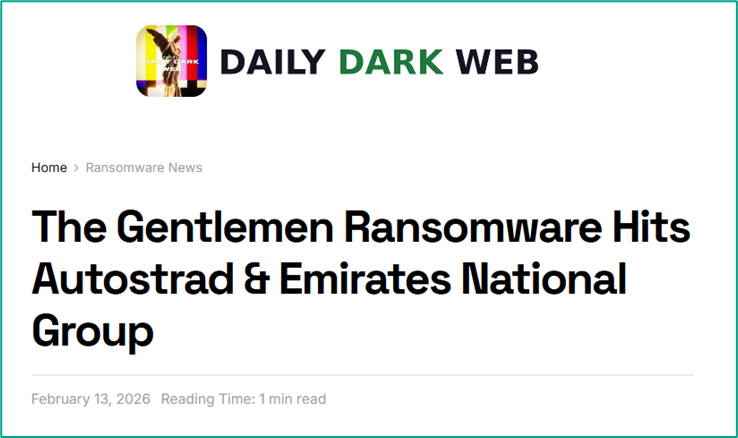
The Gentlemen group caught our attention in early 2026, as they managed to attack a significant number of victims over a short time. This actor is also notable for reflecting a broader shift toward professionalization and controlled operations within the ransomware ecosystem. Unlike many emerging groups that rely on opportunistic attacks and inconsistent leak activity, The Gentlemen demonstrate a more deliberate approach: structured intrusion workflows, selective targeting, and measured communication with victims. This signals a move away from chaotic, high-noise campaigns toward predictable, business-like execution models that are easier to scale and harder to disrupt. Their TTPs include the massive exploitation of hardware very common on big corporations, such as FortiOS/FortiProxy, SonicWall VPN, and Cisco ASA appliances. The group might be comprised of professional cybercriminals who left other prominent groups.

The group is also notable for its emphasis on data-centric extortion strategies, often prioritizing exfiltration and leverage over purely disruptive encryption. This aligns with one of the defining trends of 2026: ransomware evolving into a form of data breach monetization rather than just system denial. By focusing on controlled pressure and reputational risk instead of immediate operational damage, The Gentlemen exemplify how attackers are adapting to lower ransom payment rates and improved backup practices among victims.
Some other groups to take note of in 2026:
- Devman appears to be an emerging actor with limited but growing activity, likely leveraging existing tooling rather than developing custom capabilities.
- MintEye hasn’t been very active yet, with just five known victims, suggesting opportunistic campaigns without a consistent operational tempo.
- DireWolf is associated with small-scale, targeted attacks, though its overall footprint remains relatively limited compared to larger RaaS groups.
- NightSpire demonstrates characteristics of an amateur group, such as mistakes during its operations, uncommon communication channels with the victims, and sometimes giving them insufficient time to pay up. Although they both encrypt and leak data, they prioritize publication rather than encryption.
- Vect shows low-volume activity. It is yet unclear whether they use a completely new codebase or are rather a rebrand of an existing group.
- Tengu is a less prominent actor, with limited public reporting and no clear distinguishing tactics beyond standard extortion models.
- Kazu appears to be created by ransomware operators previously engaged with multiple other groups. As of now, they don’t stand out for scale or technique.
Although there is little to say about these groups at the time of writing this report, each of them may be equally likely to disappear from the threat landscape or grow into a prominent threat. That’s why it’s important to track them from their early days. Moreover, collectively, these groups illustrate how dynamic the ransomware landscape is, with new entrants constantly replenishing it.
Conclusion and protection recommendations
Despite the growing effort by law enforcement agencies across the globe to seize and disrupt dark web platforms and threat actor infrastructures, ransomware operations remain stable, with new groups quickly taking the place of those who went silent. In 2026, we see a shift towards encryptionless extortion, with data leaks increasingly becoming the main threat to target organizations. At the same time, data encryption is also upgrading to the next level with the emergence of post-quantum ransomware.
To resist the evolving threat, Kaspersky recommends organizations:
Prioritize proactive prevention through patching and vulnerability management. Many ransomware attacks exploit unpatched systems, so organizations should implement automated patch management tools to ensure timely updates for operating systems, software, and drivers. For Windows environments, enabling Microsoft’s Vulnerable Driver Blocklist is critical to thwarting BYOVD attacks. Regularly scan for vulnerabilities and prioritize high-severity flaws, especially in widely used software.
Strengthen remote access: RDP and RDWeb connections should never be directly exposed to the internet, only through VPN or ZTNA (Zero Trust Network Access). It’s highly recommended to adopt multi-factor authentication on everything; the architecture may require continuous authentication for access, as one valid credential captured is enough to cause a breach. Monitoring the underground for stolen employee credentials is essential. Audit open ports across the entire attack surface. The adoption of the “Principle of Least Privilege” (PoLP), where users, systems, or processes are granted only the minimum access rights, such as read, write, or execute permissions, necessary to perform their specific job functions, is highly recommended.
Strengthen endpoint and network security with advanced detection and segmentation. Deploy robust endpoint detection and response solutions such as Kaspersky NEXT EDR to monitor for suspicious activity like driver loading or process termination. Network segmentation is equally important. Limit lateral movement by isolating critical systems and using firewalls to restrict traffic. Complete and immediate offboarding for employees is necessary as well as periodic permission reviews, with automatic revocation of unused access. Sessions with complete logging for privileged accounts are more than necessary. Monitoring the traffic divergence to new sites or even to legitimate endpoints can help the defenders to spot a new insider threat.
Invest in backups, training, and incident response planning. Maintain offline or immutable backups that are tested regularly to ensure rapid recovery without paying a ransom. Backups should cover critical data and systems and be stored in air-gapped environments to resist encryption or deletion. User education is essential to combatting phishing, which remains one of the top attack vectors. Conduct simulated phishing exercises and train employees to recognize AI-crafted emails. Kaspersky Global Emergency Response Team (GERT) can help develop and test an incident response plan to minimize potential downtime and costs.
The recommendation to avoid paying a ransom remains robust, especially given the risk of unavailable keys due to dismantled infrastructure, affiliate chaos, or malicious intent. By investing in backups, incident response, and preventive measures like patching and training, organizations can avoid funding criminals and mitigate the impact.
Kaspersky also offers free decryptors for certain ransomware families. If you get hit by ransomware, check to see if there’s a decryptor available for the ransomware family used against you.
securelist.com/state-of-ransom…
 - Collegamento all'originale")
















Gin Kangaroo
in reply to Pxl Phile • • •Alien🍉
in reply to Pxl Phile • • •marie verdeil
in reply to Pxl Phile • • •Pxl Phile
in reply to marie verdeil • • •@marieverdeil I think I saw this Super Godzilla SNES meme the first time in this
El Vector ⁂ 🐸🐌
in reply to Pxl Phile • • •@marieverdeil
marie verdeil
in reply to Pxl Phile • • •Medea Vanamonde 🏳️⚧️
in reply to Pxl Phile • • •@spiegelmama
Data Center Infestation?
Call in the Kaiju.
AutistiCritic
in reply to Pxl Phile • • •