 - Collegamento all'originale")
Anonimizzazione dei Dati: Proteggere la Privacy senza Perdere Utilità
In un’epoca in cui la produzione e la condivisione di dati personali avviene in maniera massiva e quotidiana, il concetto di anonimizzazione assume un ruolo centrale nel dibattito sulla tutela della privacy e sul riutilizzo etico dei dati. Con l’avvento del General Data Protection Regulation (GDPR), il quadro normativo europeo ha introdotto definizioni precise e obblighi stringenti per il trattamento dei dati personali, distinguendo in maniera netta tra dati identificabili, pseudonimizzati e completamente anonimizzati.
Secondo il GDPR, un dato può essere considerato anonimo solo quando è reso tale in modo irreversibile, ovvero quando non è più possibile identificare, direttamente o indirettamente, l’interessato, anche attraverso l’uso di informazioni supplementari o tecniche di inferenza. Tuttavia, raggiungere un livello di anonimizzazione assoluto è tutt’altro che banale: i dataset possono contenere identificatori diretti (come nomi o numeri di documento) e quasi-identificatori (informazioni come localizzazione, età o preferenze), che, se combinati, possono consentire la ri-identificazione degli individui.
L’interesse verso l’anonimizzazione è cresciuto in parallelo con l’aumento esponenziale della quantità di dati disponibili online. Oggi, oltre la metà della popolazione mondiale è connessa a Internet, e molte organizzazioni – grandi e piccole – analizzano i dati per individuare pattern, comportamenti e profili, sia a fini interni che per finalità commerciali. Spesso, questi dati vengono condivisi con terze parti o resi pubblici per scopi di ricerca, aumentando il rischio di esposizione di informazioni personali.
Negli anni si sono verificati numerosi casi in cui processi di anonimizzazione inadeguati hanno portato alla ri-identificazione degli utenti, con gravi conseguenze per la loro privacy. Eclatante il caso del 2006, in cui una piattaforma di streaming pubblicò un dataset contenente milioni di valutazioni di film dichiarate “anonime”, che furono però facilmente associate ai rispettivi utenti tramite dati incrociati. Similmente, nel 2013, il Dipartimento dei trasporti di New York rese pubblici i dati dei taxi cittadini, ma un’errata anonimizzazione consentì di risalire alle licenze originali e persino all’identità di alcuni conducenti.
Questi esempi dimostrano come l’anonimizzazione non sia solo una questione tecnica, ma anche normativa, etica e metodologica. Le domande che emergono sono molteplici:
- Quando un dato può dirsi davvero anonimo?
- Le tecniche di anonimizzazione sono sempre irreversibili?
- Come si misura l’efficacia dell’anonimizzazione rispetto alla perdita di utilità dei dati?
L’obiettivo di questo articolo è fare chiarezza su questi interrogativi, offrendo una panoramica delle principali tecniche di anonimizzazione oggi in uso, analizzando i rischi connessi alla ri-identificazione e illustrando come strumenti e metodologie possano supportare una pubblicazione sicura dei dati, conforme ai principi della privacy-by-design e della data protection. In particolare, si approfondiranno le differenze tra l’anonimizzazione dei dati relazionali e quella dei dati strutturati in forma di grafo, sempre più diffusi nell’ambito dei social network e delle analisi comportamentali.
Tecniche di Protezione dei Dati: confronto tra Pseudonimizzazione e Anonimizzazione
Il Regolamento Generale sulla Protezione dei Dati (GDPR) introduce una distinzione fondamentale tra dati personali, dati pseudonimizzati e dati anonimizzati, concetti che vengono spesso confusi, ma che hanno implicazioni molto diverse sul piano normativo, tecnico e operativo.
L’articolo 4 del GDPR fornisce le seguenti definizioni:
- Dati personali: qualsiasi informazione riguardante una persona fisica identificata o identificabile (data subject), direttamente o indirettamente.
- Pseudonimizzazione: trattamento dei dati personali in modo tale che non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive, che devono essere conservate separatamente e protette da misure tecniche e organizzative adeguate.
- Anonimizzazione: processo attraverso il quale i dati personali vengono modificati in modo irreversibile, rendendo impossibile l’identificazione, diretta o indiretta, dell’individuo a cui si riferiscono.
Questa distinzione è tutt’altro che formale. Secondo il Considerando 26 del GDPR:
“I principi della protezione dei dati non dovrebbero applicarsi a informazioni anonime, ossia a informazioni che non si riferiscono a una persona fisica identificata o identificabile, o a dati personali resi anonimi in modo tale che l’interessato non sia più identificabile.”
In altre parole, una volta che i dati sono stati anonimizzati correttamente, non rientrano più nell’ambito di applicazione del GDPR. Ciò li rende estremamente preziosi per l’elaborazione, l’analisi e la condivisione, soprattutto in settori come la sanità, la statistica, il marketing e la ricerca scientifica.
Una delle convinzioni più diffuse – e pericolose – è ritenere che pseudonimizzazione e anonimizzazione siano equivalenti. In realtà, il GDPR è molto chiaro nel distinguere i due concetti.
- La pseudonimizzazione riduce il rischio di esposizione dei dati personali, ma non elimina il legame con l’identità dell’individuo. Chi è in possesso delle informazioni aggiuntive (es. tabelle di corrispondenza, chiavi di decodifica) può facilmente ripristinare l’identità.
- L’anonimizzazione, invece, comporta l’eliminazione definitiva di ogni possibilità di re-identificazione. I dati anonimizzati non permettono alcun collegamento con l’individuo e, pertanto, cessano di essere considerati dati personali.
Quindi, se esiste una possibilità – anche remota – di risalire all’identità di una persona, i dati non possono essere considerati anonimi, ma semplicemente pseudonimizzati.
Tecniche di Anonimizzazione dei Dati
La scelta della tecnica di anonimizzazione più adatta dipende strettamente dallo scopo per cui i dati devono essere anonimizzati. Ogni metodo comporta compromessi tra livello di privacy garantita e utilità residua del dato: più i dati sono protetti, minore sarà, in genere, la loro granularità e quindi il loro valore analitico.
Le principali modalità attraverso cui i dati possono essere trasformati a fini di anonimizzazione sono tre:
- Sostituzione di un valore o di un attributo,
- Modifica (generalizzazione o randomizzazione),
- Rimozione (soppressione) di attributi o interi record.
L’obiettivo, in ogni caso, è quello di garantire la privacy dei soggetti coinvolti senza compromettere l’utilizzabilità dei dati, soprattutto quando si tratta di analisi statistiche, ricerca o studi di mercato.
In questa sezione verranno presentate alcune delle principali tecniche di anonimizzazione, con indicazioni sul loro corretto utilizzo in base al contesto.
Soppressione di Attributi o Record
La soppressione è una delle tecniche più semplici e dirette: consiste nella rimozione di uno o più attributi da un dataset. È particolarmente utile quando:
- Un attributo non è rilevante ai fini dell’analisi,
- L’attributo contiene informazioni identificative dirette e non è possibile anonimizzarlo in altro modo,
- L’intero record rappresenta un rischio e deve essere rimosso.
Esempio pratico
Immaginiamo di voler analizzare le prestazioni di un gruppo di studenti in un test di valutazione. Il dataset a nostra disposizione contiene tre attributi per ciascun partecipante:
- Nome dello studente
- Nome del docente
- Voto ottenuto
Poiché l’obiettivo dell’analisi è di tipo statistico e non richiede l’identificazione dei singoli studenti, il nome dello studente risulta essere un’informazione non necessaria e altamente identificativa. Per garantire la privacy degli interessati, applichiamo la tecnica della soppressione, eliminando completamente la colonna contenente i nomi.
Dopo questa operazione, il dataset mantiene la propria utilità analitica, in quanto consente ancora di osservare e confrontare i risultati dei test in relazione ai diversi docenti o a gruppi di studenti, ma senza esporre informazioni personali.
In alcuni casi, la soppressione può riguardare anche interi record. Questo avviene, ad esempio, quando la combinazione di più attributi (come età, localizzazione geografica, e materia del test) rende un soggetto potenzialmente riconoscibile, soprattutto in campioni di piccole dimensioni. Se non è possibile anonimizzare efficacemente quei record con altre tecniche, la rimozione totale rappresenta la misura più sicura per tutelare la privacy.
La soppressione è una tecnica semplice ed efficace, in quanto elimina completamente le informazioni sensibili, rendendole irrecuperabili e garantendo così un elevato livello di protezione della privacy. Tuttavia, questa efficacia ha un costo: la rimozione di attributi o record può compromettere la qualità e l’utilità del dataset, soprattutto se le informazioni eliminate sono rilevanti per l’analisi. Inoltre, un uso non bilanciato della soppressione può introdurre distorsioni (bias) nei risultati, riducendo l’affidabilità delle conclusioni ottenute.
Sostituzione di Caratteri (Character Replacement)
La sostituzione di caratteri è una tecnica di anonimizzazione che consiste nel mascherare parzialmente il contenuto di un attributo, sostituendo alcuni caratteri con simboli predefiniti, come ad esempioX o*. Si tratta di un approccio utile quando si desidera nascondere parte dell’informazione, mantenendo però una certa struttura del dato, utile a fini analitici o di verifica. Questa tecnica non elimina l’attributo, ma oscura solo i dati più sensibili, rendendoli meno identificabili. La sostituzione può essere applicata, ad esempio, ai codici postali, ai numeri di telefono, agli indirizzi email o a qualsiasi campo testuale potenzialmente riconducibile a una persona.
Esempio pratico
Supponiamo di voler analizzare la distribuzione geografica degli utenti di un servizio, utilizzando il codice postale. Se il codice completo può rendere identificabile l’individuo, è possibile mascherarne le ultime cifre.
Prima della sostituzione:
- 20156
- 00189
- 70125
Dopo la sostituzione:
- 201XX
- 001XX
- 701XX
In questo modo, è ancora possibile condurre un’analisi per area geografica generale (es. quartieri o zone urbane), ma si elimina la precisione che potrebbe portare alla localizzazione esatta e quindi all’identificazione indiretta del soggetto.
La sostituzione di caratteri è facile da implementare e consente di mantenere una buona utilità del dato, ma è meno sicura rispetto ad altre tecniche più radicali, come la soppressione. Infatti, se il contesto circostante è troppo ricco di informazioni, o se vengono incrociati più attributi, può comunque emergere un rischio di re-identificazione.
Per questo motivo, questa tecnica è indicata soprattutto in dataset di grandi dimensioni, dove l’attributo mascherato non è sufficiente, da solo, a identificare una persona, ma può contribuire ad aumentare la protezione complessiva se combinato con altre tecniche.
Rimescolamento dei Dati (Shuffling)
La tecnica del rimescolamento, oshuffling, consiste nel riorganizzare in modo casuale i valori di un determinato attributo all’interno del dataset, mantenendo inalterata la lista dei valori ma disassociandoli dai relativi record originali. Questa tecnica è utile quando si vuole preservare la distribuzione statistica di un attributo, ma non è necessario mantenere la relazione tra quell’attributo e gli altri presenti nel dataset. In sostanza, i valori non vengono alterati, ma permessi tra i diversi record, rendendo più difficile il collegamento diretto tra un’informazione sensibile e un individuo specifico.
Esempio pratico
Immaginiamo di avere un dataset che contiene:
- ID cliente
- Regione geografica
- Importo speso
Se l’obiettivo è analizzare la distribuzione degli importi spesi per area geografica, ma senza voler collegare l’importo specifico al singolo cliente, possiamo applicare lo shuffling all’attributo “importo speso”, rimescolandone i valori tra i diversi record.
Prima dello shuffling:
Dopo lo shuffling dell’importo:
In questo modo, si preservano i dati regionali e la distribuzione aggregata degli importi, ma si interrompe la correlazione diretta tra individuo e valore economico, riducendo il rischio di identificazione.
Sebbene semplice da applicare, lo shuffling non garantisce da solo un’adeguata anonimizzazione. In alcuni casi, soprattutto quando i dataset sono piccoli o gli attributi fortemente correlati, potrebbe essere possibile ricostruire le associazioni originali attraverso tecniche di inferenza.
Per questo motivo, il rimescolamento viene spesso utilizzato in combinazione con altre tecniche, come la soppressione o la generalizzazione, per rafforzare la protezione dei dati.
Aggiunta di Rumore (Noise Addition)
L’aggiunta di rumore è una tecnica di anonimizzazione molto diffusa e consiste nel modificare leggermente i valori dei dati, introducendo delle variazioni artificiali che nascondono i valori reali, pur mantenendo l’informazione statisticamente utile. L’obiettivo è ridurre la precisione del dato per renderlo meno identificabile, ma senza compromettere l’utilità complessiva, soprattutto quando viene analizzato in aggregato.
Esempio pratico
Supponiamo di avere un dataset con le date di nascita dei pazienti in un’analisi epidemiologica. Per ridurre il rischio di identificazione, possiamo aggiungere o sottrarre casualmente alcuni giorni o mesi a ciascuna data.
Data originale:
- 12/06/1985
- 03/11/1990
- 28/04/1978
Dopo l’aggiunta di rumore (± qualche giorno):
- 10/06/1985
- 07/11/1990
- 30/04/1978
Queste variazioni non alterano in modo significativo l’analisi, ad esempio per fasce di età o tendenze temporali, ma rendono molto più difficile collegare con certezza una data a un individuo specifico.
Un elemento critico di questa tecnica è determinare quanto rumore aggiungere: troppo poco può non essere sufficiente a proteggere la privacy, mentre troppo può distorcere i risultati dell’analisi. Per questo motivo, è essenziale valutare attentamente il contesto di utilizzo e, quando possibile, applicare tecniche di aggiunta di rumore controllata, come nel caso della Differential Privacy, che vedremo più avanti.
Generalizzazione
La generalizzazione è un’altra tecnica di anonimizzazione in cui i dati vengono semplificati o aggregati in modo da ridurre il livello di dettaglio, e quindi la possibilità di identificazione. In pratica, si sostituisce un valore specifico con uno più generico, modificando la scala o il livello di precisione dell’attributo.
Esempio pratico
Nel caso delle date, invece di riportare giorno, mese e anno, possiamo decidere di conservare solo l’anno.
Data originale:
- 12/06/1985 → 1985
- 03/11/1990 → 1990
- 28/04/1978 → 1978
Un altro esempio classico riguarda l’età: anziché indicare “33 anni”, possiamo scrivere “30-35” o “30+”, riducendo la precisione ma mantenendo l’informazione utile per analisi demografiche.
La generalizzazione è particolarmente utile quando si vuole preservare l’analisi su gruppi (cluster), ma è meno efficace per studi che richiedono una precisione individuale. Inoltre, non sempre garantisce un livello sufficiente di anonimizzazione, soprattutto se i dati generalizzati possono essere incrociati con altre fonti.
È per questo motivo che la generalizzazione è spesso combinata con altre tecniche, o applicata attraverso modelli più evoluti come il k-anonimato e l-diversità, che vedremo nelle prossime sezioni.
K-Anonimity
L’idea alla base è quella di garantire che ogni record in un dataset non sia distinguibile da almeno altri k - 1 record, rispetto a un insieme di attributi considerati potenzialmente identificativi (dettiquasi-identificatori).
In altre parole, un dataset soddisfa il criterio di k-anonimato se, per ogni combinazione di attributi sensibili, esistono almeno k record identici, rendendo molto difficile risalire all’identità di una singola persona.
Esempio pratico
Supponiamo di avere un dataset con le seguenti colonne:
- Età
- CAP
- Patologia diagnosticata
Se questi attributi vengono considerati quasi-identificatori, e applichiamo il k-anonimato con k = 3, allora ogni combinazione di età e CAP dovrà comparire in almeno tre record.
Prima dell’anonimizzazione:
Dopo l’anonimizzazione con K = 3:
In questo esempio, l’età è stata generalizzata e il CAP parzialmente mascherato, in modo da creare un gruppo indistinguibile di almeno tre record. Di conseguenza, la probabilità di identificare un individuo specifico in quel gruppo è al massimo 1 su 3.
Le principali caratteristiche del k-anonimato sono:
- Maggiore è il valore di k, minore è il rischio di identificazione.
- La tecnica può essere applicata a diversi tipi di dati, ma richiede l’individuazione attenta dei quasi-identificatori.
- L’efficacia dipende fortemente dalla qualità e varietà del dataset: se troppo eterogeneo, la perdita di dettaglio può essere significativa.
Il k-anonimato non protegge dai cosiddetti attacchi di background knowledge: se un avversario conosce informazioni aggiuntive (es. una persona vive in un certo CAP e ha una certa età), potrebbe comunque risalire alla sua patologia, anche se presente in un gruppo di k elementi. Per mitigare questo rischio, si ricorre ad approcci più sofisticati, come l-diversità e t-closeness, che introducono ulteriori vincoli sulla distribuzione dei dati sensibili all’interno dei gruppi.
L-Diversity
La l-diversità è una tecnica che estende e rafforza il concetto di k-anonimato, con l’obiettivo di evitare che all’interno dei gruppi di equivalenza (ossia i gruppi di record resi indistinguibili tra loro) ci sia scarsa varietà nei dati sensibili.
Infatti, anche se un dataset è k-anonimo, può comunque essere vulnerabile: se in un gruppo di 3 record tutti i soggetti condividono lo stesso valore per un attributo sensibile (es. una malattia), un attaccante potrebbe facilmente dedurre quell’informazione, pur non sapendo esattamente a chi appartiene. Con l-diversità, si impone una regola aggiuntiva: ogni gruppo di equivalenza deve contenere almeno L valori distinti per l’attributo sensibile. Questo aumenta il livello di incertezza per chi tenta di effettuare una re-identificazione.
Esempio pratico
Riprendiamo l’esempio di un dataset sanitario con i seguenti attributi:
- Età
- CAP
- Diagnosi
Supponiamo di aver ottenuto gruppi indistinguibili tramite k-anonimato, ma che tutti i soggetti abbiano la stessa diagnosi:
Esempio di gruppo con scarsa diversità:
Un gruppo come questo rispetta il k-anonimato (k=3), ma è altamente vulnerabile, perché un attaccante sa che chiunque in quel gruppo ha il diabete.
Applicando L-Diversità (L=3):
Ora, anche se il gruppo è indistinguibile rispetto ai quasi-identificatori, l’attributo sensibile “diagnosi” ha almeno tre valori diversi, il che limita la possibilità di dedurre informazioni certe.
La l-diversità è efficace nel:
- Aumentare l’incertezza per gli attaccanti, anche in presenza di conoscenze pregresse.
- Evitare la perdita di riservatezza in caso di gruppi omogenei.
Tuttavia, non è infallibile: in situazioni in cui la distribuzione dei dati sensibili è fortemente sbilanciata (es. 9 diagnosi comuni e 1 rara), anche con l-diversità può verificarsi un attacco per inferenza probabilistica, dove l’informazione meno frequente può comunque essere dedotta con alta probabilità.
Rischi di Re-identificazione
Anche dopo l’anonimizzazione, esiste sempre un rischio residuo che un individuo possa essere identificato, ad esempio incrociando i dati con informazioni esterne o tramite inferenze. Per questo motivo, è fondamentale valutare attentamente il rischio prima di condividere o pubblicare un dataset.
I rischi si suddividono in tre categorie:
- Prosecutor Risk: l’attaccante sa che un individuo è nel dataset e cerca di trovarlo.
- Journalist Risk: l’attaccante non sa se l’individuo è presente, ma prova comunque a identificarlo.
- Marketer Risk: l’obiettivo è identificare quanti più record possibile, non singole persone.
Questi rischi sono gerarchici: se un dataset è protetto contro il rischio più elevato (prosecutor), è considerato sicuro anche rispetto agli altri.
Ogni organizzazione dovrebbe definire il livello di rischio accettabile, in base alle finalità e al contesto del trattamento dei dati.
Conclusioni
L’anonimizzazione dei dati rappresenta oggi una sfida cruciale nel bilanciare due esigenze spesso contrapposte: da un lato la protezione della privacy degli individui, dall’altro la valorizzazione del dato come risorsa per l’analisi, la ricerca e l’innovazione.
È fondamentale comprendere che nessuna tecnica, da sola, garantisce la protezione assoluta: l’efficacia dell’anonimizzazione dipende dalla struttura del dataset, dal contesto d’uso e dalla presenza di dati esterni che potrebbero essere incrociati per effettuare attacchi di re-identificazione.
In un’epoca dominata dai big data e dall’intelligenza artificiale, la corretta gestione dei dati personali è un dovere etico oltre che legale. L’anonimizzazione, se ben progettata e valutata, può essere uno strumento potente per abilitare l’innovazione nel rispetto dei diritti fondamentali.
L'articolo Anonimizzazione dei Dati: Proteggere la Privacy senza Perdere Utilità proviene da Red Hot Cyber.
HackerHood di RHC Rivela due nuovi 0day sui prodotti Zyxel
Il ricercatore di sicurezza Alessandro Sgreccia, membro del team HackerHood di Red Hot Cyber, ha segnalato a Zyxel due nuove vulnerabilità che interessano diversi dispositivi della famiglia ZLD (ATP / USG).
Alessandro Sgreccia (Ethical hacker di HackerHood conosciuto per l’emissione di varie CVE, come la RCE nvd.nist.gov/vuln/detail/CVE-2…CVE-2022-0342 da 9.8 su Zyxel), ha attivato una segnalazione responsabile a Zyxel che prontamente ha risposto risolvendo il problema.
Zyxel ha prontamente analizzato i report forniti e ha pubblicato un avviso ufficiale in cui conferma le falle e indica le versioni del firmware interessate e le release con le correzioni disponibili nel suo bollettino di sicurezza.
CVE-2025-9133 – Missing Authorization
Questa vulnerabilità, con un punteggio CVSS v3.1 di 8.1 (High), riguarda un problema di autorizzazione mancante nella gestione di alcune richieste inviate all’interfaccia web dei firewall Zyxel.
In determinate circostanze, un attaccante autenticato con privilegi limitati potrebbe riuscire ad accedere a informazioni sensibili o a funzioni non previste per il proprio livello di accesso.
Il problema è stato classificato anche come CWE-184 (Incomplete List of Disallowed Inputs), in quanto associato a una validazione parziale dei comandi accettati dal sistema.
CVE-2025-8078 – Improper Neutralization of Special Elements used in an OS Command
La seconda vulnerabilità, con punteggio CVSS v3.1 di 7.2 (High), riguarda una command injection individuata in un componente del firmware ZLD.
Un utente autenticato con privilegi elevati potrebbe, in condizioni specifiche, eseguire comandi arbitrari sul dispositivo compromettendo la sicurezza del sistema. Il bug è stato classificato come CWE-78, ossia una neutralizzazione impropria degli elementi speciali utilizzati nei comandi di sistema.
L’advisory ufficiale di Zyxel elenca i modelli e le release interessate e raccomanda l’aggiornamento alle versioni con patch (le informazioni sulle singole release e sulle build corrette sono contenute nell’avviso). Gli amministratori sono invitati a seguire le istruzioni fornite dal vendor. Zyxel
L’apertura di Zyxel alla community hacker
Negli ultimi anni, la cooperazione tra HackerHood e Zyxel è diventata una tappa fondamentale del programma di sicurezza del gruppo. Le segnalazioni effettuate da HackerHood – in particolare tramite il lavoro del ricercatore Alessandro Sgreccia – hanno portato all’attribuzione di 17 CVE nell’arco degli ultimi tre anni sugli apparati Zyxel. Questo risultato testimonia non solo la capacità tecnica del team, ma anche un rapporto di fiducia crescente con il vendor e l’apertura nei suoi confronti alla community hacker che di fatto diventa per i vendor un forte alleato.
Zyxel, da parte sua, ha riconosciuto pubblicamente il contributo di HackerHood e di Sgreccia anche nella propria Hall of Fame dedicata ai segnalatori (inclusa la CVE-2025-1731 / CVE-2025-1732). In sintesi: quella tra Zyxel e HackerHood non è una semplice segnalazione occasionale, ma una dinamica di collaborazione strutturata, che negli ultimi tre anni ha contribuito a rendere i dispositivi Zyxel più robusti contro le minacce.
Raccomandazioni operative
- Applicare le patch indicate da Zyxel appena possibile.
- Limitare l’accesso alle interfacce di management (IP ACL, VPN di gestione, accesso da rete di management isolata).
- Monitorare i log di management e le chiamate all’interfaccia web/CGI per attività anomale.
- Ruotare credenziali e chiavi qualora si sospetti che un dispositivo possa essere stato esposto.
- Contattare il vendor o il proprio fornitore di servizi per supporto nelle operazioni di aggiornamento e verifica.
Il ruolo di HackerHood nella scoperta
HackerHood, con circa 20 CVE emesse in tre anni di attività, è il collettivo di ethical hacker di Red Hot Cyber che si impegna nella ricerca di vulnerabilità non documentate per garantire una sicurezza informatica più robusta. Il gruppo si basa su un manifesto che promuove la condivisione della conoscenza e il miglioramento della sicurezza collettiva, identificando e segnalando vulnerabilità critiche per proteggere utenti e aziende.
Secondo quanto riportato nel manifesto di HackerHood, il collettivo valorizza l’etica nella sicurezza informatica e incentiva la collaborazione tra i professionisti del settore. Questo caso dimostra l’importanza della loro missione: mettere al servizio della comunità globale le competenze di hacker etici per individuare minacce ancora sconosciute.
Unisciti a HackerHood
Se sei un bug hunter o un ricercatore di sicurezza e vuoi contribuire a iniziative di questo tipo, HackerHood è sempre aperto a nuovi talenti. Il collettivo accoglie esperti motivati a lavorare su progetti concreti per migliorare la sicurezza informatica globale. Invia un’email con le tue esperienze e competenze a redazione@redhotcyber.com per unirti a questa squadra di professionisti.
La scoperta di queste due nuove CVE sono un ulteriore esempio del contributo di HackerHood al panorama della sicurezza informatica internazionale. È essenziale che aziende e utenti finali prestino attenzione a tali scoperte, adottando le misure necessarie per prevenire eventuali exploit. La collaborazione tra ethical hacker, aziende e comunità resta una pietra miliare nella lotta contro le minacce cibernetiche.
L'articolo HackerHood di RHC Rivela due nuovi 0day sui prodotti Zyxel proviene da Red Hot Cyber.
NIS2 e nuove linee guida ACN: cosa cambia per le aziende e come prepararsi
La direttiva europea NIS2 rappresenta un punto di svolta per la cybersecurity in Italia e in Europa, imponendo a organizzazioni pubbliche e private nuove responsabilità nella gestione dei rischi informatici. Per supportare il percorso di adeguamento in tutte le sue fasi, l’Agenzia per la Cybersicurezza Nazionale (ACN) ha recentemente pubblicato la guida alla lettura delle “Linee guida NIS – Specifiche di base”, un documento che chiarisce gli obblighi per i soggetti NIS essenziali e importanti coinvolti e definisce tempi e modalità di adozione delle misure minime di sicurezza e di notifica degli incidenti.
Il documento rappresenta un valido aiuto per aziende ed enti pubblici per capire come affrontare gli obblighi previsti dal decreto legislativo 138/2024, che ha recepito in Italia la direttiva europea NIS2.
In questo articolo analizzeremo nel dettaglio i due capitoli centrali delle linee guida ACN: da un lato le “Misure di sicurezza di base”, che vanno individuate con un approccio basato sul rischio e dunque calibrate sul contesto di ogni organizzazione; vengono poi passate in rassegna le tipologie di requisiti e le evidenze documentali richieste. Altro aspetto fondamentale riguarda gli “Incidenti significativi di base”, con particolare attenzione sulle tipologie individuate, sui criteri di evidenza e sui rischi legati all’abuso dei privilegi. Al tempo stesso, capiremo il valore di affidarsi a un partner esperto comeELMI per gestire rischi e adempimenti NIS2 in modo efficace e integrato.
Le linee guida NIS2 dell’ACN: misure di sicurezza di base
La prima parte del documento linee guida ACN riguarda le Misure di sicurezza di base, con un focus su:
- struttura delle misure di sicurezza
- approccio basato sul rischio secondo il quale sono state sviluppate le misure
- tipologie di requisiti delle misure
- principali evidenze documentali richieste.
I soggetti NIS devono adottare le misure di sicurezza entro 18 mesi (ottobre 2026) dalla data di ricezione della comunicazione di iscrizione nell’elenco nazionale NIS. Le misure di sicurezza si applicano ai sistemi informativi e di rete che i soggetti utilizzano nelle loro attività o nella fornitura dei loro servizi.
Queste misure, sviluppate in coerenza con il Framework Nazionale per la Cybersecurity, sono organizzate in funzioni, categorie e sottocategorie, ciascuna accompagnata da requisiti specifici. In termini pratici, ogni misura indica cosa deve essere implementato e quali evidenze documentali devono essere fornite a dimostrazione della conformità.
In totale, le linee guida ACN definiscono:
- 37 misure di sicurezza e 87 requisiti per i soggetti importanti;
- 43 misure di sicurezza e 116 requisiti per i soggetti essenziali.
La differenza riflette la maggiore esposizione al rischio e il ruolo critico dei soggetti essenziali;questi, infatti, devono rispettare un numero maggiore di misure e requisiti rispetto ai soggetti importanti, poiché la normativa tiene conto della loro maggiore esposizione ai rischi e del possibile impatto, sociale ed economico, di un possibile incidente.
In questo contesto, il supporto di un partner specializzato come ELMI consente alle organizzazioni di interpretare correttamente i requisiti ACN, tradurli in piani operativi concreti e predisporre la documentazione necessaria, riducendo i rischi di non conformità.
Misure di sicurezza di base: approccio basato sul rischio
Nella definizione delle misure di sicurezza, l’ACN ha applicato quanto previsto dall’articolo 31 della Decreto NIS2: gli obblighi non sono uguali per tutti, ma devono essere calibrati sul grado di esposizione al rischio dei sistemi informativi e di rete.
I requisiti più complessi sono modulati attraverso alcune clausole che ne guidano l’applicazione:
- possono riguardare almeno i sistemi e le reti più rilevanti per l’organizzazione;
- devono essere definiti sulla base della valutazione del rischio (misura ID.RA-05);
- ammettono eccezioni solo in presenza di ragioni normative o tecniche documentate;
- si applicano anche alle forniture che possono avere impatti diretti sulla sicurezza dei sistemi.
Tipologie di requisiti
Per tradurre le misure di sicurezza in azioni concrete, l’ACN definisce i requisiti specifici che i soggetti NIS devono rispettare per essere conformi. Questi requisiti si dividono in due principali categorie:
- Organizzativi: riguardano principalmente la gestione, l’organizzazione, la documentazione e il controllo di processi e attività, come ad esempio l’adozione e l’approvazione di politiche o procedure, la definizione di processi interni e la redazione di documentazione ufficiale. Gran parte dei requisiti delle misure di sicurezza di base rientra in questa categoria, come ad esempio la misura GV.RR-02, che definisce l’organizzazione della sicurezza informatica e i relativi ruoli e responsabilità, o la misura GV.PO-01, relativa all’adozione e documentazione delle politiche di sicurezza.
- Tecnologici: implicano l’adozione di strumenti e soluzioni tecnologiche per garantire la protezione dei sistemi informativi. Tra gli esempi vi sono la cifratura dei dati, l’aggiornamento dei software o l’uso di sistemi di autenticazione multifattore. Alcuni requisiti di tipo tecnologico sono legati, ad esempio, alla misura DE.CM-01, che richiede sistemi di rilevamento delle intrusioni e strumenti per l’analisi e il filtraggio del traffico in ingresso.
Questa distinzione permette di combinare controlli organizzativi e tecnologici, assicurando che le misure di sicurezza non siano solo formalmente adottate, ma realmente efficaci nel prevenire e mitigare i rischi informatici.
Documentazione a supporto delle misure di sicurezza
Per dimostrare l’effettiva implementazione delle misure di sicurezza, i soggetti NIS devono predisporre una serie di documenti chiave, strutturati in base alla propria organizzazione e al contesto operativo. Tra i principali troviamo:
- Elenchi: personale dell’organizzazione di sicurezza informatica, configurazioni di riferimento e sistemi accessibili da remoto.
- Inventari: apparati fisici, servizi, sistemi e applicazioni software, flussi di rete, servizi dei fornitori e relativi fornitori.
- Piani: gestione dei rischi, business continuity e disaster recovery, trattamento dei rischi, gestione delle vulnerabilità, adeguamento e valutazione dell’efficacia delle misure, formazione in materia di sicurezza informatica, risposta agli incidenti.
- Politiche di sicurezza informatica: definite in base ai requisiti previsti negli allegati 1 e 2 della determina 164179/2025, rispettivamente per soggetti importanti ed essenziali.
- Procedure: sviluppate in relazione ai requisiti specifici per cui sono richieste.
- Registri: esiti del riesame delle politiche, attività di formazione del personale, manutenzioni effettuate.
L’organizzazione può decidere come strutturare la documentazione, ad esempio concentrando più contenuti in un unico documento o distribuendoli su più file, purché i documenti siano facilmente accessibili e consultabili da chi ha necessità di verificarli.
ELMI supporta le organizzazioni con unapiattaforma documentale che consente di mappare i requisiti normativi, centralizzare e proteggere la documentazione, tracciare accessi e responsabilità e automatizzare processi approvativi. Inoltre, favorisce la gestione controllata di policy, piani e analisi dei rischi, garantendo aggiornamenti continui e supportando la formazione del personale.
Così, le aziende non solo rispettano gli obblighi della NIS2, ma trasformano la compliance in un processo semplice, sicuro e facilmente auditabile.
Gli Incidenti significativi di base
Le linee guida ACN definiscono anche le tipologie di incidenti significativi di base, ossia quegli eventi che possono avere un impatto rilevante sulla sicurezza dei dati o sulla continuità dei servizi dei soggetti NIS. Gli incidenti sono differenziati in base alla tipologia di soggetto: per i soggetti importanti sono stati identificati tre principali incidenti, mentre per i soggetti essenziali ve ne sono quattro, con l’aggiunta di un evento specifico legato all’abuso dei privilegi concessi.
In dettaglio, le principali tipologie di incidenti significativi di base sono:
- IS-1: perdita di riservatezza di dati digitali di proprietà del soggetto o sotto il suo controllo;
- IS-2: perdita di integrità dei dati, con impatto verso l’esterno;
- IS-3: violazione dei livelli di servizio attesi dei servizi o delle attività del soggetto;
- IS-4 (solo soggetti essenziali): accesso non autorizzato o abuso dei privilegi concessi su dati digitali, anche parziale.Si parla di abuso dei privilegi quando l’accesso è effettuato in violazione delle politiche interne dell’organizzazione o per finalità estranee alle necessità funzionali.
L’evidenza dell’incidente è il punto di partenza per l’adempimento degli obblighi di notifica: si considera incidente significativo solo quando il soggetto dispone di elementi oggettivi che confermano che l’evento si è effettivamente verificato. È proprio dal momento in cui l’evidenza viene acquisita che decorrono i termini per la pre-notifica (24 ore) e la notifica ufficiale (72 ore) al CSIRT Italia.
L’evidenza può essere raccolta attraverso diverse fonti, tra cui:
- Segnalazioni esterne, ad esempio comunicazioni ricevute dal CSIRT Italia;
- Segnalazioni interne, come richieste di supporto o malfunzionamenti riportati dagli utenti all’help desk;
- Eventi rilevati dai sistemi di monitoraggio, quali log di sicurezza, alert o sistemi di rilevamento intrusioni.
In pratica, avere evidenza significa poter dimostrare con dati concreti che l’incidente si è verificato, rendendo possibile una risposta tempestiva e la corretta gestione degli adempimenti normativi.
Per molte organizzazioni, l’elemento critico non è solo individuazione dell’incidente, ma disporre di un presidio costante capace di monitorare e bloccare le minacce informatiche in real-time. In quest’ottica, ilSecurity Competence Center di ELMI fornisce un monitoraggio H24 e grazie a strumenti avanzati di Threat Hunting e Incident Response, permette di ridurre drasticamente il tempo necessario per confermare un evento e avviare la notifica secondo le linee guida NIS2.
Direttiva NIS2: obblighi e scadenze per le aziende
Chi rientra nell’elenco dei soggetti NIS deve rispettare precise deadline, senza margini di rinvio. I soggetti NIS devono organizzare gli adempimenti in modo proattivo e tempestivo per garantire la conformità alla NIS2 e ridurre i rischi informatici.
Il percorso normativo prevede una serie di tappe fondamentali:
- entro gennaio 2026 i soggetti dovranno adempiere agli obblighi di base in materia di notifica di incidente;
- entro aprile 2026 sarà l’ACN a definire e adottare il modello di categorizzazione delle attività e dei servizi, nonché a predisporre gli obblighi a lungo termine;
- entro settembre 2026, è richiesto ai soggetti l’implementazione delle misure di sicurezza di base e la categorizzazione delle proprie attività e servizi;
- dopo ottobre 2026, scatterà l’obbligo per i soggetti di dare piena attuazione agli adempimenti a lungo termine.
Parallelamente a questo calendario, le principali attività da pianificare includono:
- Implementazione delle misure di sicurezza di base, calibrate sul rischio specifico dei sistemi e delle reti;
- Predisposizione della documentazione chiave, come elenchi, inventari, piani, politiche, procedure e registri;
- Monitoraggio e gestione degli incidenti significativi, con particolare attenzione all’acquisizione dell’evidenza e alle notifiche.
Per affrontare con efficacia queste scadenze, è consigliabile definire piani operativi chiari, assegnare responsabilità specifiche, attivare sistemi di monitoraggio continuo e integrare la compliance con la formazione del personale. In questo modo, le organizzazioni non solo rispettano la normativa, ma rafforzano la resilienza digitale e riducono l’impatto di eventuali incidenti.
ELMI accompagna i soggetti NIS in questa fase cruciale, supportandoli nella pianificazione degli adempimenti e nella predisposizione della documentazione richiesta. Attraverso assessment mirati e roadmap di compliance, l’azienda consente di rispettare le scadenze fissate dalla direttiva NIS2 senza frammentare i processi interni, garantendo al contempo continuità operativa e robustezza delle difese.
Come ELMI supporta le organizzazioni nella compliance NIS2
Affidarsi a un partner altamente qualificato come ELMI significa percorrere un percorso strutturato versol’adeguamento alla Direttiva NIS2, con soluzioni personalizzate, integrate e scalabili, progettate per ogni fase del processo di compliance. Grazie a una consolidata expertise in cybersecurity e consulenza, ELMI supporta le organizzazioni nell’implementazione delle misure di sicurezza, nella gestione degli incidenti e nella documentazione richiesta dalla normativa.
Assessment e analisi del perimetro NIS2
ELMI accompagna le aziende con un assessment strutturato, volto a valutare l’ambito di applicazione della direttiva: analisi dei servizi erogati, delle infrastrutture IT e dei vincoli normativi, identificazione dei ruoli e delle responsabilità in ambito cybersecurity, e valutazione del livello di sicurezza attuale.
Successivamente, viene condotta una Gap Analysis per identificare le aree di non conformità e le opportunità di miglioramento, valutando rischi, vulnerabilità e impatto operativo di eventuali incidenti. Su questa base viene definito un piano di intervento, che include contromisure tecniche e procedurali per rafforzare la sicurezza e garantire la conformità agli obblighi normativi.
Gestione proattiva degli eventi
IlSecurity Competence Center è il centro operativo di ELMI progettato per affrontare le sfide di cyber sicurezza con un approccio integrato e proattivo. Il Security Operation Center (SOC) e il Network Operation Center (NOC), garantiscono la protezione delle informazioni critiche, la conformità normativa, il monitoraggio continuo e la resilienza delle infrastrutture informatiche. In particolare:
- Il Security Operation Center (SOC), è il centro operativo dotato di una control room dedicata al monitoraggio continuo, al triage e alla gestione degli eventi di sicurezza H24/7 che possono impattare l’infrastruttura aziendale.
- Il Network Operation Center (NOC), è focalizzato sulla gestione e sul monitoraggio delle reti, per garantirne efficienza, disponibilità e resilienza.
Insieme, SOC e NOC rappresentano il cuore operativo per la protezione degli asset critici e la gestione degli incidenti.
Attraverso un servizio H24 e strumenti avanzati di threat intelligence e sistemi di allerta precoce, ELMI assicura una gestione completa degli incidenti, riducendo il time to detect e il time to respond, garantendo un controllo costante su reti, sistemi e applicazioni critiche, in linea con le prescrizioni della Direttiva NIS2.
Formazione e supporto normativo continuo
La compliance NIS2 non si esaurisce con l’implementazione tecnica e procedurale. ELMI affianca le organizzazioni con percorsi formativi mirati, orientati alla gestione degli incidenti, alla governance della sicurezza e alla diffusione della cultura cybersecurity a tutti i livelli aziendali.
Parallelamente, ELMI offre supporto normativo costante, con aggiornamenti su nuove disposizioni e linee guida, revisione periodica di policy e procedure e assistenza nell’interpretazione tecnica dei requisiti, assicurando un approccio sostenibile e integrato alla conformità NIS2.
La Direttiva europea NIS2 e le linee guida ACN stabiliscono uno standard chiaro per la gestione dei rischi informatici, dalle misure di sicurezza di base alla corretta gestione degli incidenti significativi. Per le organizzazioni, rispettare questi requisiti significa adottare un approccio risk-based, con controlli organizzativi e tecnologici integrati, monitoraggio costante e procedure documentate.
Affidarsi a un partner come ELMI e al suo team di specialisti certificati consente di trasformare la compliance NIS2 in un vero vantaggio competitivo. Grazie a servizi su misura di cybersecurity e programmi di formazione e supporto normativo, le aziende possono garantire robustezza dei sistemi informativi, tracciabilità degli eventi, riduzione del time to detect e del time to respond, e piena conformità agli obblighi di notifica.
L'articolo NIS2 e nuove linee guida ACN: cosa cambia per le aziende e come prepararsi proviene da Red Hot Cyber.
Lancelot: il sistema di apprendimento AI federato e sicuro
Un team di ricercatori di Hong Kong ha reso pubblico un sistema denominato Lancelot, che rappresenta la prima realizzazione pratica di apprendimento federato, risultando al contempo protetto da attacchi di manomissione dei dati e da violazioni della riservatezza.
L’apprendimento federato consente a più partecipanti (client) di addestrare congiuntamente un modello senza rivelare i dati di origine. Questo approccio è particolarmente importante in medicina e finanza, dove le informazioni personali sono strettamente regolamentate.
Tuttavia, questi sistemi sono vulnerabili al data poisoning : un aggressore può caricare aggiornamenti falsi e distorcere i risultati. I metodi di apprendimento federato hanno parzialmente risolto questo problema scartando gli aggiornamenti sospetti, ma non hanno protetto dal possibile recupero di dati crittografati dalla memoria della rete neurale.
Il team ha deciso di combinare sicurezza crittografica e resistenza agli attacchi. Lancelot utilizza la crittografia completamente omomorfica per garantire che tutti gli aggiornamenti del modello locale rimangano crittografati end-to-end.
Il sistema seleziona inoltre gli aggiornamenti client attendibili senza rivelare chi è attendibile. Ciò è possibile grazie a uno speciale meccanismo di “ordinamento mascherato”: un centro chiavi attendibile riceve i dati crittografati, ordina i client in base al livello di attendibilità e restituisce al server solo un elenco crittografato, oscurando i partecipanti alla formazione. In questo modo, il server aggrega solo i dati verificati senza rivelarne l’origine.
Per velocizzare i calcoli, gli sviluppatori hanno implementato due tecniche di ottimizzazione. La “rilinearizzazione lazy” posticipa i costosi passaggi crittografici alla fase finale, riducendo il carico sulla CPU. Il metodo “Dynamic hoisting” raggruppa le operazioni ripetitive e le esegue in parallelo, anche sulle GPU, riducendo significativamente i tempi di addestramento complessivi.
Il risultato è una soluzione che affronta due vulnerabilità dell’apprendimento federato: è resiliente agli attacchi di malintenzionati e al contempo garantisce la completa riservatezza dei dati. I test hanno dimostrato che Lancelot non solo previene fughe di dati e sabotaggi, ma riduce anche significativamente i tempi di addestramento dei modelli ottimizzando le operazioni crittografiche e sfruttando le GPU.
I ricercatori intendono espandere l’architettura Lancelot, rendendola adatta a scenari su larga scala. Le potenziali applicazioni includono l’addestramento di sistemi di intelligenza artificiale in ospedali, banche e altre organizzazioni che gestiscono dati sensibili. Il team sta attualmente testando nuove versioni con supporto per chiavi distribuite (CKKS a soglia e multi-chiave), integrazione di metodi di privacy differenziale e aggregazione asincrona, che consentiranno al sistema di funzionare in modo affidabile anche con connessioni di rete instabili e un’ampia varietà di dispositivi client.
L'articolo Lancelot: il sistema di apprendimento AI federato e sicuro proviene da Red Hot Cyber.
The Lambda Papers: When LISP Got Turned Into a Microprocessor
")
During the AI research boom of the 1970s, the LISP language – from LISt Processor – saw a major surge in use and development, including many dialects being developed. One of these dialects was Scheme, developed by [Guy L. Steele] and [Gerald Jay Sussman], who wrote a number of articles that were published by the Massachusetts Institute of Technology (MIT) AI Lab as part of the AI Memos. This subset, called the Lambda Papers, cover the ideas from both men about lambda calculus, its application with LISP and ultimately the 1980 paper on the design of a LISP-based microprocessor.

Scheme is notable here because it influenced the development of what would be standardized in 1994 as Common Lisp, which is what can be called ‘modern Lisp’. The idea of creating dedicated LISP machines was not a new one, driven by the processing requirements of AI systems. The mismatch between the S-expressions of LISP and the typical way that assembly uses the CPUs of the era led to the development of CPUs with dedicated hardware support for LISP.
The design described by [Steele] and [Sussman] in their 1980 paper, as featured in the Communications of the ACM, features an instruction set architecture (ISA) that matches the LISP language more closely. As described, it is effectively a hardware-based LISP interpreter, implemented in a VLSI chip, called the SCHEME-78. By moving as much as possible into hardware, obviously performance is much improved. This is somewhat like how today’s AI boom is based around dedicated vector processors that excel at inference, unlike generic CPUs.
During the 1980s LISP machines began to integrate more and more hardware features, with the Symbolics and LMI systems featuring heavily. Later these systems also began to be marketed towards non-AI uses like 3D modelling and computer graphics. As however funding for AI research dried up and commodity hardware began to outpace specialized processors, so too did these systems vanish.
Top image: Symbolics 3620 and LMI Lambda Lisp machines (Credit: Jason Riedy)
High Performance Motor Control With FOC From the Ground Up
")
Vector Control, also known as Field Oriented Control or FOC is an AC motor control scheme that enables fine-grained control over a connected motor, through the precise control of its phases. In a recent video [Excessive Overkill] goes through the basics and then the finer details of how FOC works, as well as how to implement it. These controllers generally uses a proportional integral (PI) loop, capable of measuring and integrating the position of the connected motor, thus allowing for precise adjustments of the applied vector.

If this controller looks familiar, it is because we featured it previously in the context of reviving old industrial robotic arms. Whether you are driving the big motors on an industrial robot, or a much smaller permanent magnet AC (PMAC) motor, FOV is very likely the control mechanism that you want to use for the best results. Of note is that most BLDC motors are actually also PMACs with ESC to provide a DC interface.
The actual driving is done with two MOSFETs per phase, forming a half-bridge, switching between the two rails to create the requisite PWM signal for each phase. Picking the right type of MOSFET was somewhat hard, especially due to the high switching currents and the high frequency at 25 kHz. The latter was picked to prevent audible noise while driving a robot. Ultimately SiC MOSFETs were picked, specially the GeneSiC G3R30MT12K. Of note here are the four legs, with a fourth Kelvin Source pin added. This is to deal with potential gate drive issues that are explained in the video.
With the hardware in place, whether following the [Excessive Overkill] GitHub projects or not, what makes all of it work is the software. This is where the microcontroller aspect is essential, as it has to do all the heavy lifting of calculating the new optimal vector and thus the current levels per phase. In this controller an STM32F413 is used, which generates the PWM signals to drive the half-bridges, while reading the measurements from the motors with its ADC.
As can be seen in the resulting use of this controller with old industrial robots, the FOC controller works quite well, with quiet and smooth operation. This performance is why we’re likely to see FOC and PMAC motors used in applications like 3D printers in the future, though the rule of ‘good enough’ makes the cost of an FOC controller still a tough upsell over a simple open loop stepper-based system.
youtube.com/embed/ujofKWmGChw?…
RFF20. Hedda, al cinema un Ibsen in chiave moderna
@Giornalismo e disordine informativo
articolo21.org/2025/10/rff20-h…
Il film Hedda (2025), presentato alla XX edizione della Festa del Cinema di Roma, diretto da Nia DaCosta e interpretato da una bravissima Tessa Thompson, è l’adattamento cinematografico del celebre dramma teatrale in quattro
Apple e Google sfidate dalla coalizione per i diritti dei genitori sulla tutela della privacy dei giovani
Se vuoi leggere altri nuovi aggiornamenti sulla #privacy poi seguire l'account @Privacy Pride
Il Digital Childhood Institute, che ha presentato un reclamo alla FTC, fa parte di una nuova generazione di gruppi per la sicurezza online, concentrati sulla definizione di politiche tecnologiche in base a convinzioni politiche conservatrici.
Organizzazioni no-profit come il Digital Childhood Institute fanno parte di una nuova generazione di gruppi di orientamento conservatore per la sicurezza e la privacy dei minori, emersi nell'ultimo decennio. Il loro lavoro critica spesso le aziende tecnologiche e dei social media per il loro contributo all'aumento dei problemi di salute mentale tra i giovani, tra cui depressione, ansia e autolesionismo, e le loro proposte politiche mirano a garantire a genitori e utenti tutele in materia di privacy dei dati e consenso.
cyberscoop.com/digital-childho…

Apple and Google challenged by parents’ rights coalition on youth privacy protections
The Digital Childhood Institute, which filed a complaint with the FTC, is part of a newer crop of online safety groups focused on shaping tech policy around conservative political beliefs.Derek B. Johnson (CyberScoop)
reshared this
Se vuoi leggere altri nuovi aggiornamenti sull'intelligenza artificiale poi seguire l'account @Intelligenza Artificiale
ROTE (=Rappresentare le Traiettorie degli Altri come Eseguibili) è un nuovo algoritmo che combina due elementi: LLM per generare un insieme di ipotesi sul comportamento dell'agente e "Inferenza Probabilistica" per valutare l'incertezza su quale di questi programmi stia effettivamente seguendo l'agente.
Nei test, ROTE è stato in grado di prevedere i comportamenti umani e delle IA a partire da osservazioni limitate e sparse. Ha superato i metodi di base (come il behavior cloning o i metodi basati solo su LLM) con un miglioramento fino al 50% nell'accuratezza e nella capacità di generalizzare a nuove situazioni.
reshared this
A Reggio Emilia il salario minimo comunale è finalmente realtà
Il salario minimo comunale è una vittoria per tutta la città, un simbolo forte di come a Reggio Emilia il lavoro — sicuro e di qualità - debba essere una priorità, e di come non debba esserci spazio per chi fa lavorare in condizioni non dignitose le persone. Uno strumento di tutela di tutte le lavoratrici e tutti i lavoratori, sia dipendenti diretti che impiegati nell’appalto e negli eventuali subappalti, qualsiasi sia la tipologia di contratto individuale di lavoro.”
Lo dichiara il capogruppo di Verdi e Possibile Alessandro Miglioli, primo firmatario della mozione per il salario minimo comunale approvata durante la seduta di oggi del Consiglio Comunale.
La mozione impegna il Sindaco e la Giunta a perseguire l’inserimento di clausole premiali negli appalti pubblici per chi garantisce migliori trattamenti economici per i lavoratori, pari ad almeno nove euro l’ora, ed è uno strumento di tutela di tutti i lavoratori, sia dipendenti diretti che impiegati nell’appalto e negli eventuali subappalti, qualsiasi sia la tipologia di contratto individuale di lavoro.
“Alleanza Verdi e Sinistra, REC e Possibile — continua Miglioli — chiedono da anni a gran voce che il salario minimo venga approvato a livello nazionale. Il primo momento di riflessione fatto a livello locale dal comitato di Possibile Reggio Emilia su questo tema risale al 2021, quando presentammo il libro di Davide Serafin sull’argomento. E continuiamo a chiedere con forza una legge nazionale, che metta una volta per tutte la parola fine a contratti che — pur essendo perfettamente legali — non consentono a lavoratrici e lavoratori di vivere in condizioni dignitose e arrivare alla fine del mese.
Un percorso politico condiviso con convinzione già durante la costruzione del programma elettorale della coalizione di centrosinistra e dalla maggioranza in consiglio comunale e che ha visto la partecipazione di varie figure, dal consigliere Martorana della lista Massari all’assessora regionale Elena Mazzoni dei 5 Stelle e Gianluca Cantergiani del PD.
Anche per mettere pressione per l’approvazione di una legge nazionale è importante che i comuni prendano posizione, come è stato fatto nei mesi scorsi a Napoli, Genova, Firenze, Livorno, Torino: un grande movimento di sindaci, amministratori e soprattutto di comunità che ribadiscono con forza che il lavoro si deve pagare, si deve pagare il giusto e quanto è necessario per coinvolgere l’individuo nelle sorti della società, per la dignità e il rispetto della persona.
Sono fiero — conclude Miglioli — del fatto che ora anche Reggio Emilia sia dalla parte giusta di questa battaglia, e che questo sia uno dei primi comuni in Italia in cui la mozione sul salario minimo abbia come prima firma quella di un consigliere che viene dalle forze politiche che rappresento.
Alessandro Miglioli
Capogruppo Verdi e Possibile al Consiglio Comunale di Reggio Emilia
L'articolo A Reggio Emilia il salario minimo comunale è finalmente realtà proviene da Possibile.
Druetti-Davide (Possibile): Regionali Campania, inaccettabili i commenti di Mieli su Souzan Fatayer, candidata AVS
“Tutta la nostra solidarietà a Souzan Fatayer”, dichiarano la Segretaria di Possibile Francesca Druetti e Andrea Davide della Segreteria Nazionale di Possibile e referente di Possibile in Campania, “che ha dovuto sopportare nelle ultime ore una serie di reazioni alla sua candidatura in Campania con AVS che vanno oltre la politica: dei vergognosi attacchi sessisti, che non dovrebbero trovare spazio nel dibattito sano di un paese civile”.
“Durante la trasmissione radiofonica 24 Mattino, Paolo Mieli ha definito Souzan Fatayer “una palestinese in leggerissimo sovrappeso”, che oltre a essere un volgare attacco al corpo di una candidata, è anche un insensato parallelismo con la carestia inflitta da Israele alla popolazione palestinese”, continua Andrea Davide.
“Intanto, la stampa stampa di destra ha iniziato una campagna ignobile sulle origini di Fatayer, a partire dalle insinuazioni de “Il giornale” che definisce il suo impegno per il popolo palestinese “un’esaltazione del terrorismo”: niente di nuovo, ma comunque un attacco becero e di cattivo gusto”, conclude Francesca Druetti.
“Solidarietà e vicinanza a Souzan Fatayer, un’amica, una compagna, una palestinese napoletana”.
L'articolo Druetti-Davide (Possibile): Regionali Campania, inaccettabili i commenti di Mieli su Souzan Fatayer, candidata AVS proviene da Possibile.
Blinking An LED With a Single Transistor

Let’s say you want to blink an LED. You might grab an Arduino and run the Blink sketch, or you might lace up a few components to a 555. But you needn’t go so fancy! [The Design Graveyard] explains how this same effect can be achieved with a single transistor.
The circuit in question is rather odd at first blush. The BC547 NPN transistor is hooked up between an LED and a resistor leading to a 12V DC line, with a capacitor across the emitter and collector. Meanwhile, the base is connected to… nothing! It’s just free-floating in the universe of its own accord. You might expect this circuit to do nothing at all, but if you power it up, the LED will actually start to flash.
The mechanism at play is relatively simple. The capacitor charges to 12 volts via the resistor. At this point, the transistor, which is effectively just acting as a poor diode in this case, undergoes avalanche breakdown at about 8.5 to 9 volts, and starts conducting. This causes the capacitor to discharge via the LED, until the voltage gets low enough that the transistor stops conducting once again. Then, the capacitor begins to charge back up, and the cycle begins again.
It’s a weird way to flash an LED, and it’s not really the normal way to use a transistor—you’re very much running it out of spec. Regardless, it does work for a time! We’ve looked at similar circuits before too. Video after the break.
youtube.com/embed/Yw6L5w4TDxw?…
[Thanks to Vik Olliver for the tip!]
rag. Gustavino Bevilacqua reshared this.
Fail of the Week: Beaker to Benchy More Bothersome than Believed

Making nylon plastic from raw chemicals used to be a very common demo; depending where and when you grew up, you may well have done it in high school or even earlier. What’s not common is taking that nylon and doing something with it, like, say extruding it into filament to make a benchy. [Startup Chuck] shows us there might be a reason for that. (Video, embedded below.)
It starts out well enough: sebacoyl chloride and hexamethaline diamine mix up and do their polymerizing tango to make some nylon, just like we remember. (Some of us also got to play with mercury bare-handed; safety standards have changed and you’ll want to be very careful if you try this reaction at home). The string of nylon [Chuck] pulls from the beaker even looks a little bit like filament for a second, at least until it breaks and gets tossed into a blobby mess. We wonder if it would be possible to pull nylon directly into 1.75 mm filament with the proper technique, but quality control would be a big issue. Even if you could get a consistent diameter, there’d likely be too much solvent trapped inside to safely print.
Of course, melting the nylon with a blowtorch and trying to manually push the liquid through a die to create filament has its own quality control problems. That’s actually where this ends: no filament, and definitely no benchy. [Chuck] leaves the challenge open to anyone else who wants to take the crown. Perhaps one of you can show him how it’s done. We suspect it would be easiest to dry the homemade nylon and shred it into granules and only then extrude them, like was done with polypropylene in this mask-recycling project. Making filament from granules or pellets is something we’ve seen more than once over the years.
If you really want to make plastic from scratch, ordering monomers from Sigma-Aldrich might not cut it for ultimate bragging rights; other people are starting with pulling CO2 from the atmosphere.
Thanks to [Chaz] for the tip! Remember that the tips line isn’t just for your successes– anything interesting can find its home here.
youtube.com/embed/0DwcGJUcSyE?…
Word Processing: Heavy Metal Style

If you want to print, say, a book, you probably will type it into a word processor. Someone else will take your file and produce pages on a printer. Your words will directly turn on a laser beam or something to directly put words on paper. But for a long time, printing meant creating some physical representation of what you wanted to print that could stamp an imprint on a piece of paper.
The process of carving something out of wood or some other material to stamp out printing is very old. But the revolution was when the Chinese and, later, Europeans, realized it would be more flexible to make symbols that you could assemble texts from. Moveable type. The ability to mass-produce books and other written material had a huge influence on society.
But there is one problem. A book might have hundreds of pages, and each page has hundreds of letters. Someone has to find the right letters, put them together in the right order, and bind them together in a printing press’ chase so it can produce the page in question. Then you have to take it apart again to make more pages. Well, if you have enough type, you might not have to take it apart right away, but eventually you will.
Automation
That’s how it went, though, until around 1884. That’s when Ottmar Mergenthaler, a clockmaker from Germany who lived in the United States, had an idea. He had been asked for a quicker method of publishing legal briefs. He imagined a machine that would assemble molds for type instead of the actual type. Then the machine would cast molten metal to make a line of type ready to get locked into a printing press.
He called the molds matrices and built a promising prototype. He formed a company, and in 1886, the New York Tribune got the first commercial Linotype machine.
These machines would be in heavy use all through the early 20th century, although sometime in the 1970s, other methods started to displace them. Even so, there are still a few printing operations that use linotypes as late as 2022, as you can see in the video below. We don’t know for sure if The Crescent is still using the old machine, but we’d bet they are.
youtube.com/embed/FZvPFzXZy4o?…
Of course, there were imitators and the inevitable patent wars. There was the Typograph, which was an early entry into the field. The Intertype company produced machines in 1914. But just like Xerox became a common word for photocopy, machines like this were nearly always called Linotypes and, truth be told, were statistically likely to have been made by Mergenthaler’s company.
youtube.com/embed/5n5JQrN8qx4?…
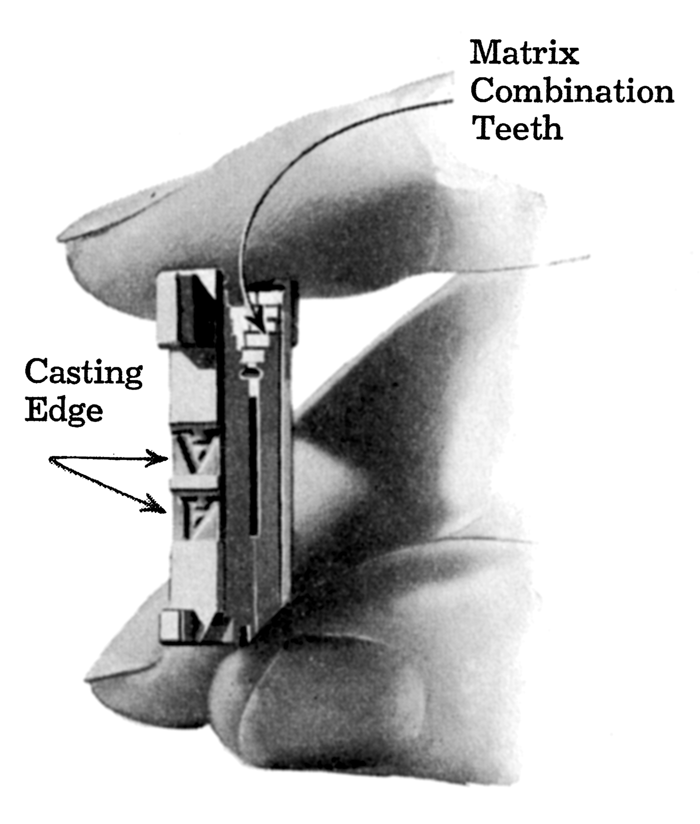
Kind of Steampunk
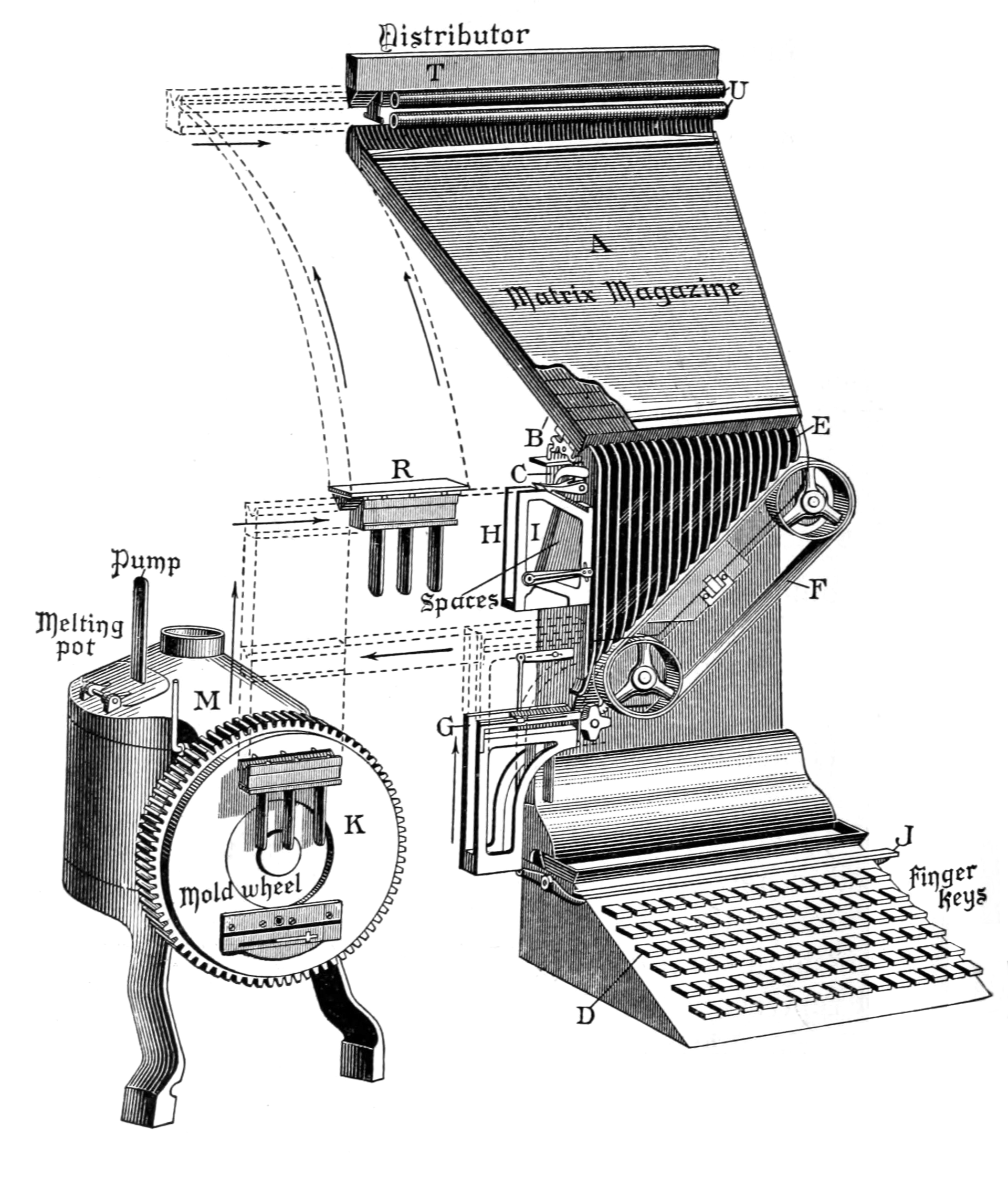
For a machine that appeared in the 1800s, the Linotype looks both modern and steampunk. It had a 90-key keyboard, for one thing. Some even had paper tape readers so type could be “set” somewhere and sent to the press room via teletype.
The machine had a store of matrices in a magazine. Of course, you needed lots of common characters and perhaps fewer of the uncommon ones. Each matrix had a particular font and size, although for smaller fonts, the matrix could hold two characters that the operator could select from. One magazine would have one font at a particular size.
Unlike type, a Linotype matrix isn’t a mirror image, and it is set into the metal instead of rising out of it. That makes sense. It is a mold for the eventual type that will be raised and mirrored. The machine had 90 keys. Want to guess how many channels a magazine had? Yep. It was 90, although larger fonts might use fewer.
Different later models had extra capabilities. For example, some machines could hold four magazines in a stack so you could set multiple fonts or sizes at one time, with some limitations, depending on the machine. Spaces weren’t in the magazine. They were in a special spaceband box.
Each press of a key would drop a matrix from the magazine into the assembler at the bottom of the machine in a position for the primary or auxiliary letter. This was all a mechanical process, and a skilled operator could do about 30 words per minute, so the machines had to be cleaned and lubricated. There was also a special pi channel where you could put strange matrices you didn’t use very often.
Typecasting
When the line was done, you pressed the casting level, which would push the matrices out of the assembler and into a delivery channel. Then it moved into the casting section, which took about nine seconds. A motor moved the matrices to the right place, and a gas burner or electric heater kept a pot of metal (usually a lead/antimony/tin mix that is traditional for type) molten.
A properly made slug from a Linotype was good for 300,000 imprints. However, it did require periodic removal of the dross from the top of the hot metal. Of course, if you didn’t need it anymore, you just dropped it back in the pot.
Justification

You might wonder how type would be justified. The trick is in the space bands. They were larger than the other matrices and made so that the further they were pushed into the block, the more space they took. A mechanism pushed them up until the line of type exactly fit between the margins.
You can see why the space bands were in a special box. They are much longer than the typical type matrices.
How else could you even out the spaces with circa-1900 technology? Pretty clever.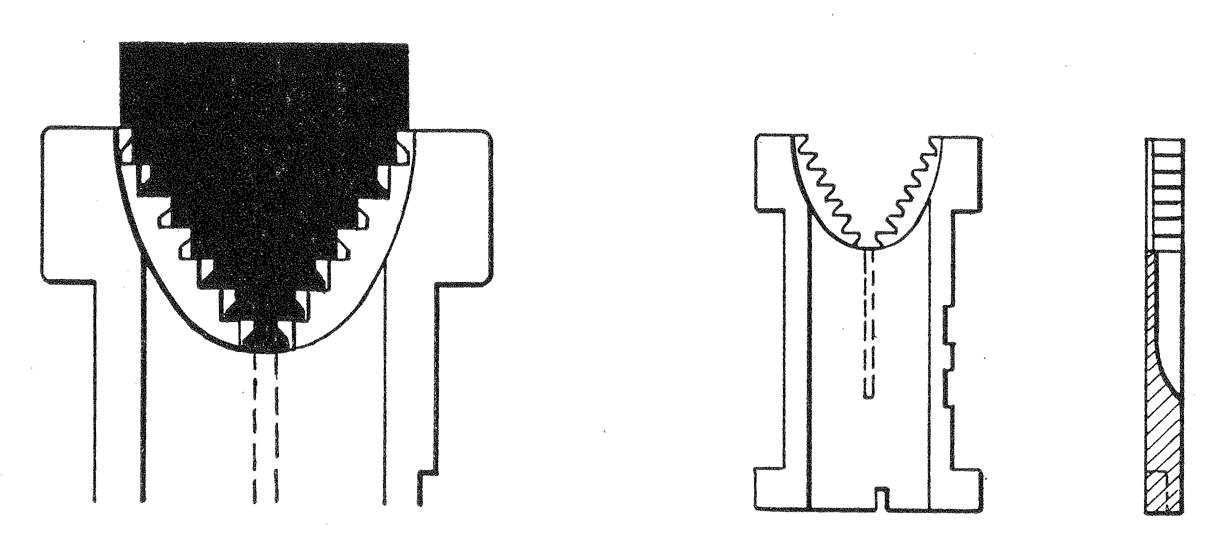
If you have been paying attention, there’s one major drawback to this system. How do the matrix elements get back to the right place in the magazine? If you can’t automate that, you still have a lot of manual labor to do. This was the job of the distributor. First, the space bands were sorted out. Each matrix has teeth at the top that allow it to hang on a toothed distributor bar. Each letter has its own pattern of teeth that form a 7-bit code.
As the distributor bar carries them across the magazine channels, it will release those that have a particular set of teeth missing, because it also has some teeth missing. A diagram from a Linotype book makes it easier to understand than reading about it.
The Goldbergs
You have to wonder if Ottmar was related to Rube Goldberg. We don’t think we’d be audacious enough to propose a mechanical machine to do all this on top of an automated way to handle molten lead. But we admire anyone who does. Thomas Edison called the machine the eighth wonder of the world, and we don’t disagree. It revolutionized printing even though, now, it is just a historical footnote.
Can’t get enough info on the Linotype? There is a documentary that runs well over an hour, which you can watch below. If you’ve only got five minutes, try the short demo video at the very bottom.
Moveable type was to printing what 3D printing is to plastic manufacturing. Which might explain this project. Or this one, for that matter.
youtube.com/embed/VDM-EbDCiQg?…
youtube.com/embed/xFUITmzrgBM?…
Classy Desk Simulates Beehive Activity

Beehives are impressive structures, an example of the epic building feats that are achievable by nature’s smaller creatures. [Full Stack Woodworking] was recently building a new work desk, and decided to make this piece of furniture a glowing tribute to the glorious engineering of the bee. (Video, embedded below.)
The piece is a conventional L-shaped desk, but with a honeycomb motif inlaid into the surface itself. [Full Stack Woodworking] started by iterating on various designs with stacked hexagons made out of laser cut plywood and Perspex, filled with epoxy. Producing enough hexagons to populate the entire desk was no mean feat, requiring a great deal of cutting, staining, and gluing—and all this before the electronics even got involved! Naturally, each cell has a custom built PCB covered in addressable LEDs, and they’re linked with smaller linear PCBs which create “paths” for bees to move between cells.
What’s cool about the display is that it’s not just running some random RGB animations. Instead, the desk has a Raspberry Pi 5 dedicated to running a beehive simulation, where algorithmic rules determine the status (and thus color) of each hexagonal cell based on the behavior of virtual bees loading the cells with honey. It creates an organic, changing display in a way that’s rather reminiscent of Conway’s Game of Life.
It was a huge build, but the final result is impressive. We’ve featured some other great custom desks over the years too. Video after the break.
youtube.com/embed/gZvzyCj3N_o?…
[Thanks to J. Peterson for the tip!]
Ask Hackaday: When Good Lithium Batteries Go Bad

Friends, I’ve gotten myself into a pickle and I need some help.
A few years back, I decided to get into solar power by building a complete PV system inside a mobile trailer. The rationale for this doesn’t matter for the current discussion, but for the curious, I wrote an article outlining the whole design and build process. Briefly, though, the system has two adjustable PV arrays mounted on the roof and side of a small cargo trailer, with an integrated solar inverter-charger and a 10-kWh LiFePO4 battery bank on the inside, along with all the usual switching and circuit protection stuff.
It’s pretty cool, if I do say so myself, and literally every word I’ve written for Hackaday since sometime in 2023 has been on a computer powered by that trailer. I must have built it pretty well, because it’s been largely hands-off since then, requiring very little maintenance. And therein lies the root of my current conundrum.
Spicy Pillows
I generally only go in the trailer once a month or so, just to check things over and make sure no critters — or squatters — have taken up residence. Apparently, my inspections had become somewhat cursory, because somehow I had managed to overlook a major problem brewing:
This is one of two homebrew server rack battery modules I used in the trailer’s first battery bank. The LG-branded modules were removed from service and sold second-hand by Battery Hookup; I stripped the proprietary management cards out of the packs and installed a 100-amp BMS, plus the comically oversized junction box for wiring. They worked pretty well for a couple of months, but I eventually got enough money together to buy a pair of larger, new-manufacture server-rack modules from Ruixu, and I disconnected the DIY batteries and put them aside in the trailer.
Glass Houses

Either way, some of the pouches have obviously transformed into “spicy pillows” thanks to the chemical decomposition of their electrodes and electrolytes, creating CO2 and CO gas under enough pressure to deform the 14-gauge steel case of the modules. It’s a pretty impressive display of power when you think about it, and downright terrifying.
I know that posting this is likely going to open me up to considerable criticism in the comments, much of it deserved. I was clearly negligent here, at least in how I chose to store these batteries once I removed them from service. You can also ding me for trying to save a few bucks by buying second-hand batteries and modifying them myself, but let those of you who have never shaken hands with danger cast the first stone.
To my credit, I did mention in my original write-up that, “While these batteries work fine for what they are, I have to admit that their homebrew nature gnawed at me. The idea that a simple wiring mistake could result in a fire that would destroy years of hard work was hard to handle.” But really, the risk posed by these batteries, not just to the years of work I put into the trailer, but also the fire danger to my garage and my neighbor’s boat, camper, and truck, all of which are close to the trailer, makes me a little queasy when I think about it.
Your Turn
That’s all well and good, but the question remains: what do I do with these batteries now? To address the immediate safety concerns, I placed them at my local “Pole of Inaccessibility,” the point in my backyard that’s farthest from anything that might burn. This is a temporary move until I can figure out a way to recycle them. While my city does have battery recycling, I’m pretty sure they’d balk at accepting 90-pound server batteries even if they were brand new. With obvious deformities, they’ll probably at least tell me to get lost; at worst, they’d call the hazmat unit on me. The Environmental Protection Agency has a program for battery recycling, but that’s geared to consumers disposing of a few alkaline cells or maybe the dead pack from a Ryobi drill. Good luck getting them to accept these monsters.
How would you handle this? Bear in mind that I won’t entertain illegal options such as an unfortunate boating accident or “dig deep and shut up,” at least not publicly. But if you have any other ideas, we’d love to hear them. More generally, what’s your retirement plan for lithium batteries look like? With the increased availability of used batteries from wrecked EVs or even e-bike and scooter batteries, it’s a question that many of us will face eventually. If you’ve already run up against this problem, we’d love to hear how you handled it. Sound off in the comments below.
Vulnerabilità F5 BIG-IP: 266.000 dispositivi a rischio nel mondo! 2500 in Italia
La Cybersecurity and Infrastructure Security Agency (CISA) e il Multi-State Information Sharing & Analysis Center (MS-ISAC) pubblicano questo avviso congiunto sulla sicurezza informatica (CSA) in risposta allo sfruttamento attivo di CVE-2022-1388.
Questa vulnerabilità, recentemente divulgata in alcune versioni di F5 Networks, Inc. (F5) BIG-IP, consente a un attore non autenticato di ottenere il controllo dei sistemi interessati tramite la porta di gestione o gli indirizzi IP personali. F5 ha rilasciato una patch per CVE-2022-1388 il 4 maggio 2022 e da allora sono stati resi pubblici exploit proof of concept (POC), consentendo ad attori meno sofisticati di sfruttare la vulnerabilità.
A causa del precedente sfruttamento di vulnerabilità di F5 BIG-IP , CISA e MS-ISAC ritengono che i dispositivi F5 BIG-IP non patchati siano un obiettivo interessante; le organizzazioni che non hanno applicato la patch sono vulnerabili ad attacchi che prendono il controllo dei loro sistemi.

L’organismo di controllo di Internet Shadowserver sta attualmente monitorando 266.978 indirizzi IP con una firma BIG-IP F5 dei quali circa 2500 sono in Italia. Oltre ai sistemi americani, ci sono circa 100.000 dispositivi in Europa e Asia. Nello specifico, per i Paesi Bassi, si tratta di 3.800 sistemi esposti.
Queste cifre illustrano l’enorme portata dell’incidente di sicurezza F5 di cui si è avuta notizia all’inizio di questa settimana . L’azienda di sicurezza ha riferito che gli hacker statali avevano avuto accesso al loro ambiente di sviluppo del prodotto BIG-IP per mesi. I prodotti F5 BIG-IP sono presenti ovunque nelle reti aziendali. Forniscono bilanciamento del carico, firewall e controllo degli accessi per applicazioni critiche. Il fatto che centinaia di migliaia di questi sistemi siano ora visibili al pubblico li rende obiettivi interessanti per i criminali informatici.
Dettagli tecnici
nvd.nist.gov/vuln/detail/CVE-2…CVE-2022-1388 è una vulnerabilità critica di bypass dell’autenticazione REST di iControl che colpisce le seguenti versioni di F5 BIG-IP:[ 1 ]
- Versioni 16.1.x precedenti alla 16.1.2.2
- Versioni 15.1.x precedenti alla 15.1.5.1
- Versioni 14.1.x precedenti alla 14.1.4.6
- Versioni 13.1.x precedenti alla 13.1.5
- Tutte le versioni 12.1.x e 11.6.x
Un attore non autenticato con accesso di rete al sistema BIG-IP tramite la porta di gestione o gli indirizzi IP personali potrebbe sfruttare la vulnerabilità per eseguire comandi di sistema arbitrari, creare o eliminare file o disabilitare servizi. F5 ha rilasciato una patch per CVE-2022-1388 per tutte le versioni interessate, ad eccezione delle versioni 12.1.x e 11.6.x, il 4 maggio 2022 (le versioni 12.1.x e 11.6.x sono a fine ciclo di vita [EOL] e F5 ha dichiarato che non rilascerà patch).[ 2 ]
Gli exploit POC per questa vulnerabilità sono stati resi pubblici e, l’11 maggio 2022, CISA ha aggiunto questa vulnerabilità al suo catalogo delle vulnerabilità note sfruttate , sulla base di prove di sfruttamento attivo. Grazie ai POC e alla facilità di sfruttamento, CISA e MS-ISAC prevedono uno sfruttamento diffuso di dispositivi F5 BIG-IP non patchati nelle reti governative e private.
Metodi di rilevamento
La CISA raccomanda agli amministratori, in particolare alle organizzazioni che non hanno applicato immediatamente la patch, di:
- Per gli indicatori di compromissione, consultare l’avviso di sicurezza F5 K23605346 .
- Se si sospetta una compromissione, consultare la guida F5 K11438344 .
- Distribuisci la seguente firma Snort creata da CISA:
L'articolo Vulnerabilità F5 BIG-IP: 266.000 dispositivi a rischio nel mondo! 2500 in Italia proviene da Red Hot Cyber.
Lower The Top. La sfida alle piattaforme tra sovranità statuale e saperi sociali
La sovranità digitale è un concetto spigoloso. E però, una volta inventato, è diventato una realtà politica con cui fare i conti. Questa è una delle tesi cardine della rivista-libro “Lower The Top. La sfida alle piattaforme tra sovranità statuale e saperi sociali”, numero 25 delle pubblicazioni di Comunicazione punto doc, rivista semestrale di Fausto Lupetti Editore (2021).
Intanto è un ossimoro: il digitale, fluido per natura, si scontra con qualsiasi idea di sovranità. La sovranità appartiene per definizione a un territorio su cui l’autorità politica esercita il proprio potere, si tratti di un ammasso regionale come degli spazi prospicenti ad esso, ma anche delle infrastrutture umane che lo attraversano.
Lo sanno bene i regolatori che di fronte al processo di globalizzazione dei mercati favorito dagli scambi e dalle telecomunicazioni globali ne hanno scoperto in Internet l’elemento più destabilizzante. Ed è proprio all’infrastruttura Internet che negli ultimi 30 anni si è provato a cucire addosso un’idea di sovranità, solo per rendersi conto che si trattava di una sovranità interconnessa e pertanto da negoziare tra le autorità statuali.
Sovranità brandita da chi è stato in grado di proiettare la propria sfera di influenza su un territorio per definizione senza confini, il hashtag#cyberspace.
Usa, Cina e Russia, anche grazie ai loro proxy tecnologici, sono state infatti finora in grado di mantenere il controllo e i vantaggi del proprio esercizio del potere su questa fluidità immateriale mente l’Europa arrancava. Proprio in virtù di una sovranità politica e statuale ancora in costruzione.
Eppure l’Europa, come evidente nel richiamo fatto dalla presidente Von der Leyen in distinti discorsi sullo stato dell’unione (2020, 2021), ha provato a tracciare un «nomos del Erde» anche per il mondo digitale. A partire dal Regolamento europeo per la protezione dei dati, GDPR, e poi con una serie di iniziative volte a regolare lo strapotere di Big Tech, prima chiamati OTT, Over the top, l’Europa ha fatto sentire il peso della sua sovranità. Per stoppare il furto di dati, la sorveglianza dell’informazione e il controllo dei mercati praticata dagli stati di di origine degli OTT. Al GDPR sappiamo che sono succedute la Nis, la Dora e il CRA, l’AI Act e il DATA Act appena entrato in vigore il 12 settembre. Tutti tentativi di applicazione di quel Digital Constitutionalism che è il corollario della Lex Digitalis.
L’Europa, accusata di rappresentare il paradosso della «regolazione senza tecnologie» sta ora ripensando la sovranità digitale come sovranità tecnologica e, attraverso i suoi progetti di finanziamento industriale, dimostra, a dispetto dei suoi detrattori, di avere ancora voce in capitolo.



Community Call: Psychosocial Support & Digital Safety
What does psychosocial support look like in the face of spyware attacks and digital security threats? It can mean adapting care to the context, listening without rushing, and building protocols that protect both dignity and data. But we want to hear what it means to you and to those already integrating psychosocial support into their accompaniments — such as Fundación Acceso in Latin America and Digital Society of Africa during our next community call.
The post Community Call: Psychosocial Support & Digital Safety appeared first on European Digital Rights (EDRi).
DDI Knowledge Hub Community Call: On mapping of HRD support mechanisms with Expectation State
Learn more about the state of digital attacks on Human Rights Defenders, when researchers and experts come together to discuss a recently concluded report.
The post DDI Knowledge Hub Community Call: On mapping of HRD support mechanisms with Expectation State appeared first on European Digital Rights (EDRi).
The Session Design Lab
During this lab, you will establish a strong foundation in designing participatory and interactive sessions for both online and face-to-face formats. This will enable you to facilitate sessions that foster co-empowering, learning, and knowledge sharing, thereby advancing your work and that of your participants.
The post The Session Design Lab appeared first on European Digital Rights (EDRi).
"due hanno 31 anni e uno 53, e secondo Ansa due di loro sarebbero legati all’estrema destra".
E chi l'avrebbe mai detto...


Tre persone sono state fermate per l'assalto al pullman dei tifosi del Pistoia basket - Il Post
https://www.ilpost.it/2025/10/20/tre-fermati-assalto-pullman-tifosi-pistoia-basket-rieti/?utm_source=flipboard&utm_medium=activitypubPubblicato su News @news-ilPost

Poliversity - Università ricerca e giornalismo reshared this.
Il secolo dell’IA, capire l’intelligenza artificiale, decidere il futuro
Volevo ringraziare Marco Bani e Lorenzo Basso per avermi regalato il loro libro “Il secolo dell’IA, capire l’intelligenza artificiale, decidere il futuro” (Il Mulino -Arel, 2025).
Mi è piaciuto molto e mi sono segnato diversi passaggi interessanti.
Il motivo è che di libri sull’IA ne ho letti parecchi in italiano, meno in inglese, a cominciare da quando studiavo psicologia a Stanford e giochicchiavo con le reti neurali negli anni ’90.
Ho letto il bellissimo Vita 3.0 di Max Tegmark, ho letto i libri di Luciano Floridi come Etica dell’Intelligenza artificiale, il libro di Cingolani, L’altra Specie; ho letto i libri di Guido Scorza e Alessandro Longo, quelli del mio amico Massimo Chiriatti (hashtag#humanless, Incoscienza artificiale), di Fabio Lazzini, e Andrea Colamedici (L’algoritmo di Babele): ho letto Breve e universale storia degli algoritmi di Luigi Laura, Nel paese degli algoritmi di Aurélie JEAN, Ph.D., L’economia dell’intelligenza artificiale di Stefano da Empoli; la trilogia di Nello Cristianini (La Scorciatoia, Machina Sapiens, Sovrumano); AI Work di Sergio Bellucci; Intelligenza Artificiale e democrazia di Oreste Pollicino e Pietro Dunn, Human in the Loop di Paolo Benanti eccetera eccetera… scusate non vi cito tutti.
Il libro di Bani e Basso mi è piaciuto per essere chiaro, sintetico, diretto. Con un forte afflato etico e con una impronta politica ma non partigiana. Volendo essere un libro divulgativo, il loro libro mi pare una buona summa del dibattito pubblico in corso pure senza essere un libro accademico o rivelatore.
Ottimo entry level, insomma, ha il pregio di poter essere compreso da un liceale come da un politico. I riferimenti sono corretti, la bibliografia discreta. un bel lavoro.
Insomma, è da leggere. Funziona anche nei momenti di relax quando non hai voglia di studiare.


SplinterCon in Paris
As national and regional efforts around digital sovereignty gain momentum, SplinterCon Paris will bring together technologists, researchers, and policymakers to consider what resilient, interconnected digital societies require today and in the future.
The post SplinterCon in Paris appeared first on European Digital Rights (EDRi).
Pirate News: No to Kings and to Flock in Cambridge
If you live in Cambridge, work in Cambridge, travel through Cambridge or live in the Greater Cambridge-area, please tell the Cambridge City Council that you oppose the introduction of Flock ALPR surveillance cameras there. We talk about it in the latest Pirate News, but you can find out more especially about today’s meeting at 5:30pm at our post about it.
Joe, Steve and James discuss why we oppose Cambridge’s effort to install Flock ALPR cameras, what we are doing at the Boston Anarchist Bookfair, the Boston NoKings protest and CycloMedia.
youtube.com/embed/9zGsUH5n9QI?…
Join us at the Boston Anarchist Bookfair Nov. 1-2.
Sign up to our newsletter to get notified of new events or volunteer. Join us on:
Check out:
- Mon. & Thu., Speak Out Against Cambridge ALPR Surveillance Rollout;
- Surveillance Memory Bank and Resources;
- Our Administrative Coup Memory Bank;
- Our Things to Do when Fascists are Taking Over.
Some links we mentioned:
- Boston Anarchist Bookfair;
- Steve’s Bluesky post about Boston Lobsters at the Boston NoKings rally;
- Steve’s Bluesky post about CycloMedia mapping SUV;
- CycloMedia Wikipedia page.
Image Credit: James O’Keefe, CC By-SA 4.0
Hacklab Cosenza - Linux Day Cosenza 2025
hlcs.it/2025/10/20/linux-day-c…
Segnalato da Linux Italia e pubblicato sulla comunità Lemmy @GNU/Linux Italia
Pubblicato il programma del Linux Day 2025 a Cosenza, parte della giornata nazionale dedicata a Linux, al software libero e open source, e alle tecnologie aperte, rispettose delle libertà digitali.
reshared this
Attentato a Ranucci, per il Presidente Mattarella serve reazione forte
@Giornalismo e disordine informativo
articolo21.org/2025/10/attenta…
L’attentato che ha semidistrutto le auto della famiglia del giornalista Sigfrido Ranucci la settimana scorsa a Pomezia, in provincia di Roma, è “allarmante”, ragion
Esercito cyber italiano: ecco da cosa dipenderà il successo della difesa digitale
@Informatica (Italy e non Italy 😁)
La decisione rimarca la necessità di presidiare il cyber spazio, riconosciuto come il quinto dominio di guerra. Ecco le cifre previste, obiettivi, strategie e criticità da superare nella Difesa cyber
L'articolo Esercito cyber italiano: ecco da
possibile.com/druetti-davide-p…
Tutta la nostra solidarietà a Souzan Fatayer che ha dovuto sopportare nelle ultime ore una
possibile.com/a-reggio-emilia-…
Il salario minimo comunale è una vittoria per tutta la città, un simbolo forte di come a Reggio Emilia il lavoro - sicuro e di qualità - debba essere una priorità, e di come non debba esserci spazio per chi fa lavorare in condizioni non
Sessant’anni fa, il 15 ottobre 1965, Olivetti presentava al pubblico americano la Programma 101, la prima macchina a programma memorizzabile della storia

Accadeva al BEMA Show di New York, dove il colosso di Ivrea svelò un oggetto rivoluzionario, compatto, elegante, studiato proprio per stare su una scrivania e dialogare con l’uomo. Era la nascita del primo “personal computer” italiano, molto prima che il termine diventasse di uso comune.
👇
Phishing contro PagoPA: l’open redirect di Google usato come esca perfetta
@Informatica (Italy e non Italy 😁)
Il CERT-AgID ha individuato una campagna di phishing che sta abusando di un meccanismo di reindirizzamento di Google per veicolare un finto sito di PagoPA e trarre così in inganno le vittime inducendole a fornire dati e informazioni riservate. Ecco i dettagli e
Ecco come l’Olanda spinge avanti la diplomazia transatlantica dei droni
@Notizie dall'Italia e dal mondo
L’asse transatlantico sullo sviluppo dei Collaborative Combat Aircraft (Cca), altrimenti noti come loyal wingmen o droni gregari, continua a divenire sempre più solido. Negli scorsi giorni l’Olanda, attraverso il suo ambasciatore sottosegretario per la difesa Gijs Tuinman, ha
Qualche giorno fa mi era toccato sentire la fesseria di Meloni sulla somiglianza tra la sinistra e Hamas.
Adesso mi è arrivata la fesseria uguale e contraria di Schlein che parlando dell'attentato a Ranucci non perde l'occasione e indica l'altra parte politica come un rischio per la libertà.
Una specie di principio di azione e reazione ma più che alla Fisica mi fa pensare alla Psichiatra.
Meno male negli anni di piombo non ci siamo trovati con questi politici di serie B altrimenti saremmo ancora alle bombe sui treni e nelle stazioni.
Max - Poliverso 🇪🇺🇮🇹 reshared this.
Raimondas Lapinskas 🌍
in reply to Cybersecurity & cyberwarfare • • •