Dall’inizio del conflitto in Ucraina, i droni marittimi (più correttamente definiti Unmanned Surface Vessels, o Usv) sono stati impiegati in modo sempre più efficace dalle forze di Kyiv nel disturbare le operazioni navali russe nel Mar Nero, fornendo all’Ucraina un mezzo economicamente vantaggioso per
@Notizie dall'Italia e dal mondo Non esiste la ricerca di un percorso trasformativo collettivo, proprio come il sistema si auspica. Ma non esiste neanche la fermezza critica di menti pensanti capaci di mantenere linearità di analisi e solidità di approccio. Non esiste alternativa
Verdad y Libertad, pseudoterapie riparative, vescovo di Palermo ne testa la correttezza: la diocesi non smentisce
Vescovo Corrado Lorefice e vicario per la pastorale Giuseppe Vagnarelli, organizzatore dell'incontro pubblico, che hanno introdotto e concluso i lavori, interpellati come diocesi dal pubblico, non hanno dato alcuna smentita, dopo 7 mesi di silenzio dagli articoli di stampa nazionale e internazionale dell'estate scorsa.
Giovedì 27 marzo 2025 pomeriggio, nella chiesa parrocchiale di Santa Caterina da Siena in via dell'Airone a Borgo Ulivia, la diocesi di Palermo ha tenuto un «aggiornamento teologico per laici», ad accesso pubblico, su «accompagnamento e accoglienza delle persone omosessuali».
Presenti almeno 150 persone in sala, tra cui il vescovo che ha lungamente aperto l’incontro, il vicario per la pastorale, l’addetto stampa del vescovo e una giornalista. Ho atteso il momento delle domande, e, al mio turno ho posto la seguente domanda:
9 settembre 2017, Bagheria, in una parrocchia, nel territorio della nostra arcidiocesi,
«a 20 anni, il rito iniziale: essere rinchiuso in uno stanzino buio, con una lista scritta di cose che devo lasciare fuori dalla porta, come l'attrazione per lo stesso sesso; qualcuno poi apre la porta, ti dice: "Vuoi venire alla luce?", rispondi di sì, esci dalla porta e metti dei lucchetti simbolici: al sesso, alla masturbazione. A questi momenti comunitari c'erano persone da diverse parti del mondo che si collegavano online per seguire».
Incontri successivi sempre
«seguiti non da professionisti ma daI fondatore.
Tappa obbligatoria - viaggio di una settimana a Granada a spese del seminario, dove gli incontri si tengono a casa di Miguel Angel Sanchez Cordòn, pediatra ex gay:
bagno in piscina tutti nudi; dover stare tutti nudi a guardarsi, per educare il corpo a non eccitarsi.
Essere obbligato a mettere in scena il proprio funerale: mettere su carta i tuoi difetti percepiti, come "omosessualità", "abominio", "falsità"; bruciarli, obbligato poi a seppellirne le ceneri sotto la tua lapide simbolica, disegnata da te, col tuo nome.
Ogni sera, dover fare un report via telegram se si sono avute delle minime pulsioni o erezioni; se accade, devi scriverlo sul gruppo in diretta e tutti cominciano a mandare messaggi di sostegno e preghiere collettive».
«Sentirsi intrappolato senza altra scelta se non quella di sopprimere il mio vero sé».
«Insormontabile pressione psicologica ad essere qualcuno che non ero».
E, poi, come effetti, «attacchi di panico», e, per i 7 anni successivi, «crisi di ansia e ira improvvisa».
che nel 2017 incontri di questo che lui chiama«percorso formativo»della durata di un anno, che avrebbe come«obiettivo una piena maturità umana e affettiva», si sono tenuti anche a Palermo;
che l'arcivescovo di questa diocesi, Palermo,«ha voluto partecipare» a qualche incontro per «testarne la correttezza»;
che«la parola definitiva se affidare o meno seminaristi» del seminario della propria diocesi a un percorso di questo genere «è del vescovo».
La diocesi smentisce?
Dopo il giro delle risposte di competenza dei tre relatori esterni, ha preso la parola il vicario per la pastorale Giuseppe Vagnarelli, per ringraziare e salutare, quindi una lunga preghiera condotta personalmente dall'arcivescovo Corrado Lorefice, e tutte e tutti a casa. Nessuno dei due ha minimamente toccato il tema. Nessuna smentita, quindi.
@informapirata ⁂ a me delirante sembra la mancata smentita - quindi ammissione che così sia andata; delirante il mancato fare ammenda; delirante che, come risposta, non aprano gli archivi dei seminari vescovili di Agrigento e Palermo a una commissione indipendente che faccia chiarezza e ricostruisca la vicenda andando a cercare una per una le decine di persone offese, che loro sanno perfettamente chi sono e noi no; delirante che se ne occupi stampa nazionale e internazionale, ma che, con l'unica eccezione di Claudia Fauzia, nessuno della stampa locale senta l'esigenza di intervistare, indagare, chiedere smentite ai varii Lorefice, Vagnarelli, Montenegro e ai rettori del seminario di Palermo di allora e di ora.
La dimensione subacquea del dominio marittimo assume oggi una rilevanza strategica sempre più decisiva, ponendosi al centro di nuove dinamiche geopolitiche globali. Le infrastrutture critiche poste sui fondali marini – gasdotti, oleodotti e
@Informatica (Italy e non Italy 😁) Dopo una conversazione con amici su un prodotto, ecco che quest'ultimo appare in una pubblicità su Instagram o Facebook. Facciamo chiarezza sui dubbi che gli utenti si pongono su questo scottante tema, se lo smartphone ci ascolta o
@Privacy Pride Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/lacqua-c… Si, Claudia Giulia, hai capito bene, Stroppa ha detto che può accedere a qualsiasi dato personale degli utenti di twitter/x in modo arbitrario, inclusi quelli non pubblicamente visibili. Può vedere la reale identità degli utenti pseudonimi, che lui maccheronicamente chiama anonimi, può
Radio waves travel fast, and they can bounce, too. If you are able to operate a 25-meter dish, a transmitter, a solid software-defined radio, and an atomic clock, the answer is: yes, they can go all the way to Venus and back. On March 22, 2025, the Dwingeloo telescope in the Netherlands successfully pulled off an Earth-Venus-Earth (EVE) bounce, making them the second group of amateurs ever to do so. The full breakdown of this feat is available in their write-up here.
Bouncing signals off planets isn’t new. NASA has been at it since the 1960s – but amateur radio astronomers have far fewer toys to play with. Before Dwingeloo’s success, AMSAT-DL achieved the only known amateur EVE bounce back in 2009. This time, the Dwingeloo team transmitted a 278-second tone at 1299.5 MHz, with the round trip to Venus taking about 280 seconds. Stockert’s radio telescope in Germany also picked up the returning echo, stronger than Dwingeloo’s own, due to its more sensitive receiving setup.
Post-processing wasn’t easy either. Doppler shift corrections had to be applied, and the received signal was split into 1 Hz frequency bins. The resulting detections clocked in at 5.4 sigma for Dwingeloo alone, 8.5 sigma for Stockert’s recording, and 9.2 sigma when combining both datasets. A clear signal, loud and proud, straight from Venus’ surface.
The experiment was cut short when Dwingeloo’s transmitter started failing after four successful bounces. More complex signal modulations will have to wait for the next Venus conjunction in October 2026. Until then, you can read our previously published article on achievements of the Dwingeloo telescope.
@Notizie dall'Italia e dal mondo Chi vuole partire viene condotto al transito di Kerem Shalom. Dopo l'ispezione, prosegue verso Rafah, il ponte di Allenby o l'aeroporto di Ramon. A tutti verrebbe detto che «non è certo» che potranno tornare a Gaza L'articolo Come
@Politica interna, europea e internazionale L’idea che l’Italia debba scegliere tra gli Stati Uniti e l’Europa è “infantile” e “superficiale”, visto che Washington e il
Ecco, stiamo con i cattivi della storia. Capisco la voglia di mediare, ma non sta mediando una beneamata cippa, ci stiamo beccando dazi e insulti e noi a quanto pare ci pieghiamo pure a 90
@gildadriel @Tototun non c'è niente da fare... il trenino italiano, fintanto che non viene fatto deragliare, viaggia sempre ostinatamente verso la parte sbagliata della storia
Non siamo solo noi, le nazioni europee da tempo sono incapaci di esprimere qualcosa che non sia la sottomissione acritica e incondizionale agli USA.
Pensa alla Danimarca, che ha confermato da poco l'acquisto degli F35, cioé regalare miliardi a un paese che sta minacciando di invadere parte del suo territorio.
Alcuni dicono che è vero, altri dicono il contrario. Ma di fatto dipendere da ricambi e sopratutto software e telemetria gestiti dagli USA renderebbe quegli F35 estremamente ineffettivi.
Ad ogni modo l'Europa non può competere militarmente con gli Stati Uniti, a partire dal piccolo dettaglio che abbiamo le loro basi piazzate in casa.
@alfredon996 dal canto mio non credo dovremmo cercare la competizione militare, ma almeno l'indipendenza sul piano della difesa. Affidarsi ad un "alleato" che si è dimostrato inaffidabile più volte non è il massimo. Possiamo farci andare bene il fatto di essere affiliati agli USA, ma possiamo farci stare un po' meno bene l'idea di dover dipendere da loro per la nostra sicurezza.
Sam Altman, CEO di OpenAI intervistato recentemente ha ribadito che l’umanità è vicina alla creazione di un’intelligenza artificiale generale (AGI), un’intelligenza artificiale paragonabile all’intelligenza umana. Secondo lui, per raggiungere questo obiettivo è sufficiente ampliare i modelli esistenti come ChatGPT.“L’AGI probabilmente emergerà durante la presidenza Trump”, ha previsto il miliardario, proseguendo la linea che OpenAI ha portato avanti sin dal trionfale debutto del suo chatbot nel novembre 2022.
Nel 2023 l’azienda ha sviluppato ulteriormente questa idea nel suo blog, affermando che “la prima AGI sarà solo un punto nel continuum dell’intelligence”. Il concetto sembra plausibile, se non fosse per un difetto fondamentale: l’intelligenza, qualunque cosa sia, quasi certamente non si sviluppa in un continuum.
È comprensibile il motivo per cui un insider della Silicon Valley con un’enorme fortuna in gioco concepisca lo sviluppo dell’intelligenza artificiale in questo modo. Questa posizione, tuttavia, perde di persuasività se prendiamo in considerazione un altro tipo di pensiero che l’intelligenza artificiale ha trascurato fin dal suo inizio: la ragione naturale.
Cos’è l’intelligenza naturale?
Gli esseri umani usano il linguaggio per comunicare, quindi l’intelligenza artificiale conversazionale crea l’illusione di intelligenza. Esiste però una differenza fondamentale tra loro: ChatGPT manipola simboli, mentre gli esseri umani usano la parola per descrivere cose e fenomeni circostanti. Noi esistiamo nella realtà fisica, emotiva e sociale, mentre le reti neurali operano solo con astrazioni. Ecco perché i modelli linguistici, nonostante la loro fluidità, generano assurdità con incrollabile certezza: non hanno alcuna connessione reale con il mondo.
Ricercatori e imprenditori come Altman continuano a fare previsioni sul futuro dell’intelligenza artificiale, dando per scontato di conoscere la strada giusta. Nella comunità scientifica si fa largo uso del termine “fattore g” o “intelligenza generale”, un’abilità cognitiva di base che sta alla base di vari processi mentali. Gli scienziati ne distinguono due componenti: “intelligenza cristallizzata” – conoscenza ed esperienza accumulate, e “intelligenza fluida” – la capacità di risolvere nuovi problemi, trovare schemi e pensare in modo astratto. È l’intelligenza fluida che consente all’individuo di adattarsi a nuove situazioni e di imparare. Tuttavia, resta ancora un mistero come esattamente nascano queste capacità e quali processi nel cervello ne siano responsabili.
Se un alieno arrivasse sulla Terra e analizzasse il pensiero degli esseri umani e delle macchine, rimarrebbe sorpreso nel vedere che la ricerca sull’intelligenza artificiale sta prosperando e che gli scienziati sono convinti di essere pronti a ricostruire la civiltà, anche se lavorano con una vaga definizione di intelligenza stessa. E studiare il mondo animale solleverebbe ancora più interrogativi. Dopotutto, l’intelligenza naturale, anziché semplicemente “crescere” con l’aumento dei dati e della potenza di calcolo, si manifesta in modo diverso nelle diverse specie.
Ciò che potremmo definire intelligenza ecologica è riscontrabile in creature che vanno dalle pulci agli elefanti. Ogni specie ha sviluppato capacità cognitive uniche che la aiutano a sopravvivere nella sua nicchia ecologica. E se definiamo l’intelligenza come la capacità di interagire efficacemente con l’ambiente, allora il miglior esempio di “intelligenza artificiale generale” potrebbe non essere una voluminosa rete neurale con miliardi di parametri, ma un insetto primitivo (a prima vista).
Guida alla navigazione della mosca della frutta
Un ambito importante dello sviluppo dell’intelligenza artificiale è la navigazione autonoma, che definisce l’intelligenza come la capacità di muoversi in modo indipendente e sicuro. Tali sistemi, basati su reti neurali profonde con apprendimento tramite rinforzo, utilizzano una combinazione di sensori (lidar, telecamere e radar) per rilevare gli ostacoli e pianificare i percorsi. Con un addestramento adeguato, il meccanismo può sviluppare strategie per muoversi in sicurezza anche in ambienti caotici.
In tal caso, la specie che merita un proprio ciclo di finanziamenti da parte di OpenAI è la Drosophila melanogaster, ovvero l’umile moscerino della frutta. Dotate di cervelli microscopici che pesano quasi nulla, queste creature mostrano riflessi per evitare le collisioni che superano le capacità di qualsiasi auto a guida autonoma. In una frazione di secondo, rilevano segnali di movimento, prevedono traiettorie ed eseguono manovre. La ricerca ha dimostrato che le mosche calcolano le vie di fuga più velocemente dei sistemi avanzati di visione artificiale.
Intelligenza collettiva e l’illusione dell’intelligenza distribuita
Anche i giganti della tecnologia sognano da tempo di creare una “intelligenza collettiva”, un sistema in cui molti elementi semplici, interconnessi, lavorano insieme per affrontare compiti complessi. Tale unione dovrebbe funzionare come un unico “supercervello“, in cui tutti i componenti partecipano alla presa di una decisione comune. Tuttavia, ancora una volta, i meccanismi naturali del pensiero collettivo esistono già e operano in modo molto più efficace di tutti gli analoghi da noi creati.
Un ottimo esempio è una colonia di api mellifere. Quando si tratta di trovare una nuova casa, migliaia di insetti agiscono come un unico organismo, ma senza alcun centro di controllo. Le api esploratrici esplorano la zona circostante alla ricerca di siti adatti e poi tornano all’alveare, dove eseguono una speciale “danza dell’oscillazione”. I loro movimenti contengono tutte le informazioni importanti: quanto è lontana una potenziale casa, in quale direzione, quanto è spaziosa e protetta. Altri individui leggono i segnali e vanno in ricognizione. Di conseguenza, la colonia prende la decisione più vantaggiosa per la sopravvivenza.
Cosa offre l’intelligenza digitale? Un gruppo di chatbot che raccolgono informazioni da Reddit.
Scoiattoli: i campioni della memoria in natura
Un altro punto di forza dell’intelligenza artificiale è la capacità di archiviare e recuperare i dati. Gli scienziati spesso misurano l’intelligenza in base alla capacità di ricordare grandi quantità di informazioni e di recuperarle quando necessario. Per raggiungere questo obiettivo, le moderne reti neurali utilizzano tecnologie complesse: i database vettoriali trasformano le informazioni in modelli matematici multidimensionali e i meccanismi di “annidamento” aiutano il programma a gestire terabyte di informazioni.
Uno scoiattolo comune, senza computer, riesce perfettamente a gestire compiti di memoria e di navigazione. In autunno nasconde centinaia di noci in posti diversi e riesce a ritrovarle anche dopo diversi mesi, sotto la neve. Inoltre, i ricercatori hanno scoperto che questi animali utilizzano strategie complesse per proteggere i loro nascondigli: possono fingere di seppellire una noce, ma in realtà la nascondono in un altro posto, ingannando i potenziali ladri. Allo stesso tempo, i roditori distinguono inequivocabilmente i nascondigli genuini da quelli falsi, a differenza dei roditori che spesso hanno “allucinazioni“, creando fatti inesistenti.
Cosa significa “Io” nell’intelligenza artificiale?
Cosa può imparare l’intelligenza artificiale dal mondo animale? In primo luogo, la coscienza non è un fenomeno universale. La navigazione di un moscerino della frutta, il processo decisionale in un alveare, la memoria di uno scoiattolo: ogni esempio rappresenta un tipo distinto di cognizione plasmato dalla pressione evolutiva.
In secondo luogo, ci costringe a riconsiderare i presupposti di base. Come accennato in precedenza, i ricercatori stanno aumentando la potenza delle reti neurali, convinti che enormi quantità di dati e risorse di elaborazione daranno alla fine vita a qualcosa di analogo alla coscienza umana. Ma se in natura esiste un ampio spettro di diverse forme di pensiero, perché crediamo che l’elaborazione statistica delle informazioni porterà all’intelligenza artificiale generale?
Il vero pensiero è incarnato nella materia. Esiste all’interno di un sistema vivente che interagisce dinamicamente con l’ambiente. L’intelligenza artificiale, d’altro canto, prevede sequenze di testo anziché cause ed effetti.
Quindi l’AGI è realizzabile? Forse.
Ma se si vuole imparare dalla natura, tanto vale investire molto nella ricerca sui moscerini della frutta.
“È necessario sviluppare una coscienza civica sul fenomeno dell’abuso del digitale e della conseguente incapacità di scrivere a mano che oggi riguarda tutti, ma che coinvolge soprattutto i più giovani. Penso che sul piano delle politiche pubbliche questo tema possa essere trattato in modo ancora più
DAL 2003, SLOWFORWARD (=slowforward.net) è il sito più testardo, aggiornato (e anziano) su #scritture di ricerca, #arte contemporanea, #musica sperimentale, materiali verbovisivi, #asemic writing, #poesia concreta, #prosa in prosa, prose brevi, scritture non assertive, e molto altro:
Mentre negli USA ci si avvia a passi rapidissimi verso un regime paradittatoriale la nostra presidente del consiglio si dichiara d'accordo con il vicepresidente di quel regime, Vance. Da chi frequenti si capisce chi o cosa sei.
@Informatica (Italy e non Italy 😁) Banca d’Italia ha reso disponibile per gli intermediari direttamente vigilati, un modello per l’autovalutazione del livello raggiunto nell’ambito dell’adeguamento al Regolamento DORA, uno strumento che in realtà può essere molto utile anche a qualsiasi altra entità finanziaria L'articolo Adozione di DORA: facciamo il punto proviene da
Ecco perché secondo me #Librewolf non è, al momento, una vera alternativa a #Firefox.
L'ho installato su un PC al lavoro su cui precedentemente usavo Firefox.
Ecco come si presenta il mio client #zimbra su librewolf (prima immagine) rispetto a come si vede su Chrome (seconda immagine).
Sì, ok, non si muore, ma se si moltiplicano queste piccole cose per le centinaia di siti che uso durante la settimana, diventano una grande cosa.
Io mi auguro che dal codice di Firefox nasca qualcosa di nuovo, o forse di vecchio, come era Firefox un tempo. Che sia librewolf, waterfox o qualcos'altro.
Ma la strada da fare è ancora tanta per me, e in salita.
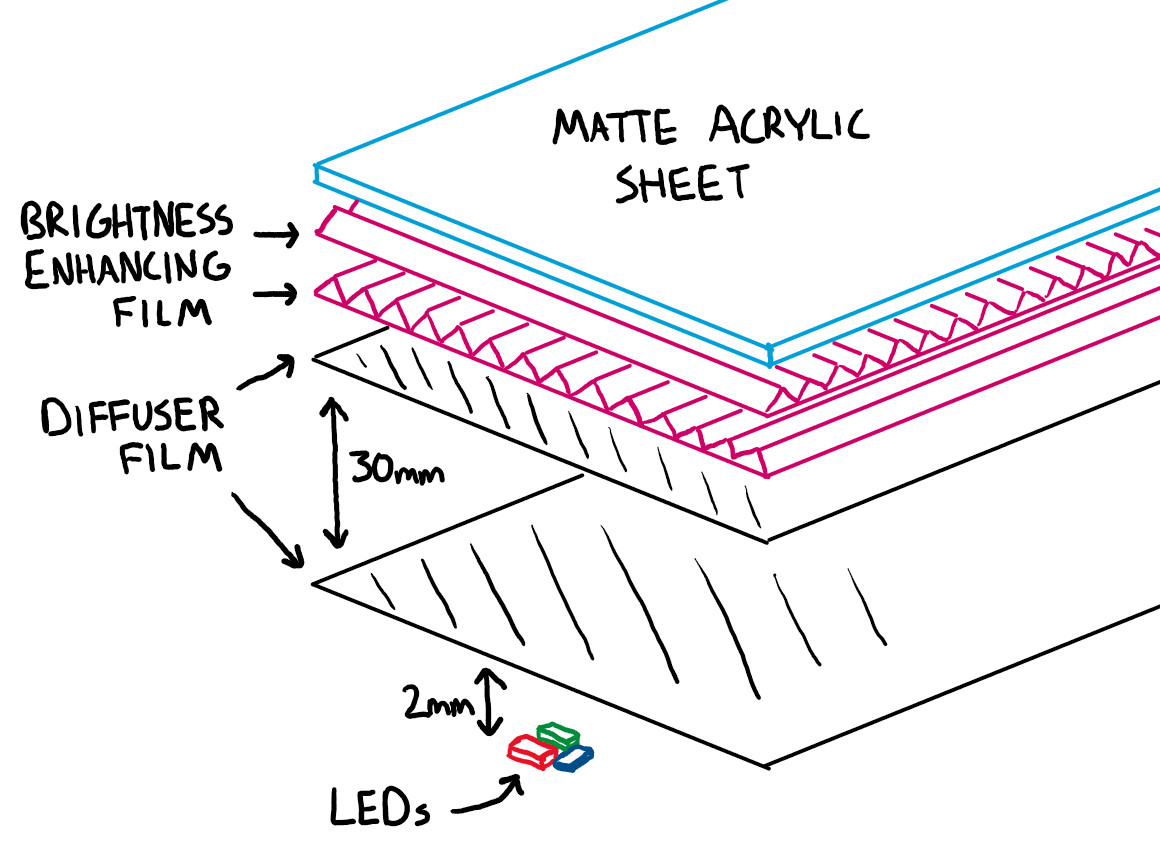
Scanning a film negative is as simple as holding it up against a light source and photographing the result. But should you try such a straightforward method with color negatives it’s possible your results may leave a little to be desired. White LEDs have a spectrum which looks white to our eyes, but which doesn’t quite match that of the photographic emulsions.
[JackW01] is here with a negative scanning light that uses instead a trio of red, green, and blue LEDs whose wavelengths have been chosen for that crucial match. With it, it’s possible to make a good quality scan with far less post-processing.
The light itself uses 665 nm for red, 525 nm for green, and 450 nm blue diodes mounted in a grid behind a carefully designed diffuser. The write-up goes into great detail about the spectra in question, showing the shortcomings of the various alternatives.
We can immediately see the value here at Hackaday, because like many a photographer working with analogue and digital media, we’ve grappled with color matching ourselves.
Franz Bartelt – Colpo gobbo freezonemagazine.com/rubriche/… Eccolo lì, l’idiota! Sbronzo marcio. Attorniato da un branco di ubriachi ancora più fatti di lui. Non l’avevo mai visto, in città. Ho chiesto a Coso chi fosse. Non ne sapeva niente neanche lui. Ho ordinato un’altra birra. Quello si vantava. Della sua grana: non parlava d’altro. E doveva averne, visto che pagava da bere, […] L'articolo Franz Bartelt – Colpo gobbo proviene da FREE ZONE MAGAZINE.
Nel panorama della cybersecurity, le fughe di dati rappresentano una minaccia sempre più ricorrente, e il recente leak del database di “festivaldisanvalentino.com” ne è l’ennesima dimostrazione. Un utente di un noto forum underground ha infatti pubblicato un presunto archivio SQL contenente dati sottratti dal sito web, mettendo a rischio informazioni sensibili degli utenti.
Disclaimer: Questo rapporto include screenshot e/o testo tratti da fonti pubblicamente accessibili. Le informazioni fornite hanno esclusivamente finalità di intelligence sulle minacce e di sensibilizzazione sui rischi di cybersecurity. Red Hot Cyber condanna qualsiasi accesso non autorizzato, diffusione impropria o utilizzo illecito di tali dati. Al momento, non è possibile verificare in modo indipendente l’autenticità delle informazioni riportate, poiché l’organizzazione coinvolta non ha ancora rilasciato un comunicato ufficiale sul proprio sito web. Di conseguenza, questo articolo deve essere considerato esclusivamente a scopo informativo e di intelligence. Print screen del forum underground dove il criminale informatico ha rivendicato il presunto attacco informatico prelevato attraverso l’utilizzo della piattaforma di intelligence delle minacce di Recorded Future
I Dettagli del Leak
L’utente “lluigi”, registrato sulla piattaforma nel novembre 2023 e con un’attività limitata ma significativa, ha rilasciato il database in un post datato 22 febbraio 2025. Secondo la descrizione fornita, il dump SQL ha una dimensione di 6MB, che si espande fino a 94MB una volta decompresso.
Un’anteprima dei dati compromessi rivela indirizzi email, IP, e messaggi di comunicazione interna, suggerendo una violazione su larga scala che potrebbe esporre (qualora confermata) centinaia o migliaia di utenti a rischi di phishing, furto d’identità e altri attacchi informatici.
Alcuni esempi includono conversazioni in cui gli utenti richiedono conferme di invio di file e altre informazioni di carattere privato. La presenza di dettagli tecnici nei metadati (come user agent e versioni di browser) potrebbe inoltre fornire agli attaccanti ulteriori spunti per orchestrare attacchi mirati.
Chi c’è Dietro l’Attacco?
Non sono stati forniti dettagli sulle modalità di attacco utilizzate per ottenere il database da parte del criminale informatico, ma è plausibile che il sito sia stato vittima ad esempio di una vulnerabilità non patchata o di credenziali di accesso compromesse. “lluigi”, l’autore del post, non sembra essere direttamente l’autore della violazione, bensì un intermediario che ha ricevuto e pubblicato i dati.
Conseguenze e Contromisure
Le vittime di questa fuga di dati devono adottare misure di sicurezza come:
Cambiare le password associate all’account del sito
Utilizzare plugin per poter rendere anonima l’esposizione dei pannelli di amministrazione di accesso al sito (ad esempio wp-admin.php)
Cambiare le stesse password correlate ad altri servizi
Diffidare di email sospette o tentativi di contatto non richiesti
Per il team di sicurezza del sito, è fondamentale analizzare il vettore il potenziale attacco e nel caso attivare specifiche misure di sicurezza, come ad esempio il patch management del sistema per evitare ulteriori potenziali problemi.
Conclusioni
Questo incidente dimostra ancora una volta quanto sia cruciale la sicurezza informatica per qualsiasi piattaforma che gestisca dati sensibili. La pubblicazione di database trafugati su forum underground è un fenomeno in crescita, e l’attenzione di aziende e utenti deve rimanere sempre alta e vigile per prevenire e mitigare i danni derivanti da questi attacchi.
Come nostra consuetudine, lasciamo sempre spazio ad una dichiarazione da parte dell’organizzazione qualora voglia darci degli aggiornamenti su questa vicenda e saremo lieti di pubblicarla con uno specifico articolo dando risalto alla questione.
RHC monitorerà l’evoluzione della vicenda in modo da pubblicare ulteriori news sul blog, qualora ci fossero novità sostanziali. Qualora ci siano persone informate sui fatti che volessero fornire informazioni in modo anonimo possono accedere utilizzare la mail crittografata del whistleblower.
Questo articolo è stato redatto attraverso l’utilizzo della piattaforma Recorded Future, partner strategico di Red Hot Cyber e leader nell’intelligence sulle minacce informatiche, che fornisce analisi avanzate per identificare e contrastare le attività malevole nel cyberspazio.
La pseudonimizzazione è una tecnica di protezione dei dati definita dall’art. 4(5) del GDPR. Consiste nella trasformazione dei dati personali in modo tale che non possano più essere attribuiti direttamente a un interessato, se non attraverso l’uso di informazioni aggiuntive tenute separate e protette da misure tecniche e organizzative adeguate.
Questa tecnica ha il vantaggio di ridurre il rischio di identificazione pur mantenendo la possibilità di utilizzare i dati per scopi analitici, statistici o operativi. Il processo si basa sulla sostituzione degli identificatori diretti (come nome, cognome, codice fiscale, ID) con pseudonimi, ossia valori che, da soli, non consentono di risalire all’identità dell’individuo, ma che possono essere ricostruiti mediante l’accesso controllato a informazioni aggiuntive, come tabelle di corrispondenza o chiavi crittografiche.
Perché la pseudonimizzazione sia efficace, è essenziale che queste informazioni aggiuntive siano custodite separatamente e protette da accessi non autorizzati. È importante sottolineare che i dati pseudonimizzati rimangono, a tutti gli effetti, dati personali secondo il GDPR, poiché esiste sempre la possibilità teorica di reidentificare l’interessato. Solo un processo che renda l’identificazione assolutamente impossibile e irreversibile può essere considerato anonimizzazione, uscendo così dall’ambito di applicazione del regolamento.
Oltre al valore operativo, la pseudonimizzazione è riconosciuta dal GDPR come una misura tecnica e organizzativa utile per ridurre i rischi nel trattamento dei dati. Rientra infatti tra le pratiche raccomandate per attuare i principi di privacy by design e by default (artt. 25 e 32) e può essere prevista anche da normative nazionali o settoriali come requisito per trattamenti specifici.
Obiettivo e Vantaggi della Pseudonimizzazione
Come indicato nel Considerando 28 del GDPR, la pseudonimizzazione rappresenta una misura strategica per ridurre i rischi connessi al trattamento dei dati personali, preservando al contempo la possibilità di effettuare analisi e valutazioni sui dati in forma non identificabile.
Riduzione del rischio
Quando implementata in modo corretto, la pseudonimizzazione contribuisce significativamente alla protezione della riservatezza dei dati. La sua efficacia si fonda sulla separazione e sulla protezione delle informazioni aggiuntive necessarie per la reidentificazione, in linea con quanto previsto dall’Art. 4(5) del GDPR.
Questa tecnica opera su due livelli:
Previene l’esposizione diretta degli identificatori personali, garantendo che i destinatari dei dati pseudonimizzati non possano identificare gli interessati.
Attenua le conseguenze di eventuali violazioni di sicurezza, riducendo il rischio di danni per gli interessati, a condizione che terze parti non abbiano accesso ai dati ausiliari che permetterebbero la reidentificazione.
Un ulteriore beneficio risiede nella mitigazione del rischio di function creep, ovvero dell’utilizzo dei dati per scopi diversi e incompatibili rispetto a quelli originariamente dichiarati. L’impossibilità per i soggetti autorizzati – come responsabili o incaricati del trattamento – di risalire direttamente all’identità degli interessati limita il potenziale abuso e rafforza il principio di limitazione della finalità.
La pseudonimizzazione, inoltre, può contribuire alla qualità del dato. L’utilizzo di pseudonimi differenziati per soggetti con attributi simili aiuta a prevenire errori di attribuzione e migliorare l’accuratezza complessiva delle informazioni trattate.
Infine, il livello di protezione offerto da questa tecnica è direttamente proporzionale alla robustezza delle misure tecniche e organizzative adottate. Una progettazione attenta e coerente consente ai titolari e ai responsabili di conformarsi agli obblighi previsti dagli Articoli 24, 25 e 32 del GDPR, assicurando un trattamento dei dati conforme, sicuro e incentrato sulla tutela dei diritti e delle libertà degli interessati.
Struttura della Trasformazione Pseudonimizzante
Per essere considerata efficace, la pseudonimizzazione deve impedire che i dati trasformati contengano identificatori diretti, come il codice fiscale o altri identificatori univoci, qualora questi possano permettere l’attribuzione dell’identità dell’interessato all’interno del contesto operativo ( dominio di pseudonimizzazione). Tali elementi vengono rimossi durante la trasformazione o sostituiti con identificatori alternativi (i pseudonimi)che, da soli, non consentono l’identificazione, se non tramite l’uso di informazioni aggiuntive tenute separatamente.
Oltre alla sostituzione degli identificatori diretti, la trasformazione può intervenire su altri attributi sensibili attraverso tecniche come la soppressione, la generalizzazione o l’introduzione di rumore controllato. Questi interventi sono finalizzati a limitare la possibilità di reidentificazione e a rafforzare la protezione dei dati trattati.
Un aspetto centrale della pseudonimizzazione è l’impiego di dati riservati (segreti di pseudonimizzazione) come chiavi crittografiche o tabelle di corrispondenza tra identificatori originali e pseudonimi. Questi elementi, essenziali per la riconduzione del dato all’interessato, devono essere generati e gestiti in modo da garantirne la sicurezza e la separazione logica e fisica rispetto ai dati pseudonimizzati.
Dal momento che tali segreti rappresentano le informazioni aggiuntive menzionate all’Art. 4(5) del GDPR, è obbligatorio proteggerli tramite misure tecniche e organizzative adeguate. Il loro accesso deve essere limitato esclusivamente al personale autorizzato, e devono essere conservati in ambienti sicuri, al fine di prevenire ogni possibilità di uso improprio o non autorizzato.
Tecniche di Pseudonimizzazione
La scelta della tecnica di pseudonimizzazione più appropriata dipende da molteplici fattori, tra cui il livello di rischio, la necessità di reversibilità, la dimensione del dataset e le finalità specifiche del trattamento. Di seguito sono illustrate le principali tecniche disponibili, con una valutazione comparativa di vantaggi e criticità operative.
Principali Tecniche
1. Contatore Sequenziale (Counter) È la tecnica più semplice, in cui ogni identificatore viene sostituito da un numero progressivo. Il vantaggio è nella facilità di implementazione, soprattutto in contesti di dati ridotti o poco complessi. Tuttavia, la sequenzialità può rivelare informazioni implicite (come l’ordine temporale), e questa tecnica mostra limiti significativi in termini di scalabilità e sicurezza per dataset più ampi o sofisticati.
2. Generatore di Numeri Casuali (Random Number Generator – RNG) In questo caso, a ogni identificatore viene associato un valore generato casualmente. L’assenza di una relazione diretta con il dato originale garantisce un buon livello di protezione, a patto che la tabella di mappatura sia adeguatamente protetta. I principali punti critici sono il rischio di collisioni (assegnazione accidentale dello stesso pseudonimo a più identificatori) e le problematiche di gestione in contesti su larga scala.
3. Funzione di Hash crittografica Consiste nell’applicare una funzione unidirezionale (come SHA-256) all’identificatore, producendo un output fisso. Sebbene offra integrità e irreversibilità, da sola non è sufficiente per garantire protezione: è vulnerabile ad attacchi di forza bruta e dizionario, soprattutto se gli input sono prevedibili (come codici fiscali o email aziendali).
4. Message Authentication Code (MAC) Si tratta di una variante sicura della funzione hash, che introduce una chiave segreta nel processo. Senza conoscere la chiave, è impossibile ricostruire il legame tra pseudonimo e identificatore originale. L’HMAC è oggi tra i metodi più robusti per la pseudonimizzazione, e viene ampiamente utilizzato nei protocolli Internet. Unico limite: la difficoltà nella riconciliazione dei dati se non si conservano gli identificatori originali.
5. Cifratura Simmetrica Utilizza un algoritmo di cifratura a blocchi (es. AES) per trasformare l’identificatore in un pseudonimo, utilizzando una chiave segreta. Questa chiave funge sia da “segreto di pseudonimizzazione” che da chiave di decifratura. È una tecnica potente e flessibile, simile al MAC, ma introduce una sfida importante: chi possiede la chiave può sempre decifrare i dati, il che potrebbe non essere conforme al principio di minimizzazione se la riconciliazione non è necessaria.
6. Tokenizzazione La tokenizzazione consiste nella sostituzione di identificatori sensibili (es. nome, codice fiscale, ID cliente) con stringhe o valori alternativi detti token, generati in modo casuale o secondo regole predefinite.
I token non hanno alcun significato intrinseco e non possono essere riconvertiti al valore originario senza una lookup table che gestisca le corrispondenze.
Questa tabella di associazione deve essere conservata separatamente, protetta da cifratura e accessibile solo a personale autorizzato.
È una tecnica altamente flessibile e indicata in contesti in cui serve mantenere la struttura del dato (es. lunghezza del campo, formato), ma garantire un buon livello di protezione.
Politiche di Pseudonimizzazione
Oltre alla tecnica adottata, è fondamentale stabilire una politica di pseudonimizzazione, ovvero definire come e quando applicare le trasformazioni nei vari dataset:
Pseudonimizzazione Deterministica La pseudonimizzazione deterministica è una tecnica in cui lo stesso identificatore originale viene sempre trasformato nello stesso pseudonimo, ogni volta che compare, sia nello stesso dataset che in dataset diversi.
Vantaggi
Coerenza trasversale: lo stesso individuo può essere riconosciuto in dataset differenti, senza conoscerne l’identità. Questo è utile in analisi longitudinali o confronti tra sistemi.
Efficienza analitica: facilita il collegamento di record riferiti allo stesso soggetto in contesti diversi (es. database clinico + database farmaceutico).
Non richiede lookup table (in alcuni casi): se il pseudonimo è generato tramite funzioni deterministiche (es. HMAC), la mappatura è implicita.
Rischi
Linkability elevata: un attore malevolo che ottiene due dataset pseudonimizzati può facilmente riconoscere che lo stesso pseudonimo (TK_XX1) si riferisce allo stesso soggetto, anche senza sapere chi sia. Questo aumenta il rischio di ricostruzione del profilo di un individuo.
Vulnerabilità alle correlazioni: se un pseudonimo appare frequentemente in correlazione con dati noti o prevedibili può essere dedotto chi sia l’individuo.
Non ideale per dati altamente sensibili: soprattutto se distribuiti a più soggetti esterni, poiché consente collegamenti tra informazioni.
Pseudonimizzazione Randomizzata a Livello di Documento Questa tecnica consiste nel generare pseudonimi diversi per lo stesso identificatore, ma conservando coerenza all’interno di insiemi specifici di dati (ad esempio tra due documenti correlati o due dataset congiunti). È utile quando si desidera rompere la linkabilità globale tra tutti i dataset, ma preservare relazioni locali all’interno di uno stesso contesto operativo.
Tuttavia, il sistema mantiene una mappatura logica: i record riferiti allo stesso soggetto sono riconoscibili come tali in entrambi i dataset A e B, pur avendo pseudonimi differenti (TK_X1, TK_Y1).
Vantaggi
Maggiore protezione contro la linkabilità trasversale: anche se più dataset venissero compromessi, un attaccante non potrebbe collegare lo stesso soggetto attraverso dataset diversi usando i pseudonimi, perché questi cambiano da un dataset all’altro.
Preserva l’analiticità locale: consente l’analisi delle relazioni all’interno dello stesso dataset o gruppo di documenti, mantenendo intatte le correlazioni.
Equilibrio tra sicurezza e usabilità: è un buon compromesso tra le esigenze di protezione e la necessità di analisi complesse.
Rischi
Complessità gestionale aumentata: richiede la gestione di più tabelle di corrispondenza o meccanismi logici per sincronizzare le relazioni tra dataset.
Possibile perdita di confrontabilità esterna: non consente analisi aggregate tra database diversi senza accesso alla logica di corrispondenza dei pseudonimi.
Maggior carico computazionale: i sistemi devono essere in grado di gestire trasformazioni dinamiche e coerenza dei dati su più livelli.
Pseudonimizzazione Completamente Randomizzata La pseudonimizzazione completamente randomizzata è una tecnica in cui ogni occorrenza di uno stesso identificatore viene trasformata in un pseudonimo diverso, anche all’interno dello stesso documento o dataset. Non viene mantenuta alcuna coerenza tra dataset, tra righe, né tra sessioni diverse di elaborazione. Questo approccio rompe completamente ogni possibilità di tracciamento o correlazione automatica tra record appartenenti allo stesso soggetto.
Anche se l’identificatore di partenza è lo stesso (BNCLRA89A41H501Z), ogni sua rappresentazione pseudonimizzata è unica e scollegata dalle altre.
Vantaggi
Massima protezione contro la reidentificazione e la linkabilità: non essendoci coerenza tra pseudonimi, risulta estremamente difficile, se non impossibile, correlare le informazioni per risalire a un individuo, anche analizzando più dataset.
Impatto positivo sul rischio residuo: particolarmente utile in ambiti dove i dati pseudonimizzati devono essere largamente condivisi o trattati in ambienti a rischio elevato.
Conformità rafforzata: offre un livello di protezione tale da soddisfare anche i requisiti più stringenti di privacy by design e by default.
Limiti
Totale perdita di tracciabilità: non è possibile collegare le diverse istanze di un soggetto, né all’interno di un dataset né tra dataset diversi. Questo impedisce analisi longitudinali, statistiche personalizzate o valutazioni storiche.
Inapplicabile in scenari che richiedono reversibilità o audit: nei casi in cui sia necessario dimostrare che determinati record appartengono allo stesso individuo (es. per diritto d’accesso ai dati), questa tecnica si rivela inadatta.
Richiede un’accurata valutazione del contesto: va usata solo quando la completa disconnessione tra i dati è accettabile e voluta.
La scelta delle tecniche di pseudonimizzazione deve basarsi su una valutazione del rischio, della necessità di reversibilità, e della robustezza delle misure organizzative a supporto. In uno scenario ideale, queste tecniche dovrebbero essere complementari, rafforzando la resilienza del trattamento anche in presenza di attacchi o accessi non autorizzati. Le tecniche più robuste (come RNG, HMAC e cifratura) offrono un’elevata protezione contro attacchi di tipo esaustivo o basati su dizionari, ma possono limitare la flessibilità d’uso. Le politiche deterministiche e document-randomised permettono analisi trasversali o longitudinali, ma con un rischio maggiore di linkabilità. Nella pratica, spesso è consigliabile combinare più tecniche per ottenere un equilibrio tra sicurezza, utilità e reversibilità, adattando l’approccio al contesto operativo e normativo.
Scenario Errato: Trasferimento di Dati Identificabili
Un ospedale condivide con un’azienda di ricerca un dataset clinico contenente dati personali in chiaro:
Problemi riscontrati:
1. Rischio elevato di reidentificazione diretta La presenza di identificatori espliciti come nome, cognome, codice fiscale e numero della cartella clinica consente un’immediata associazione tra i dati e l’identità dei pazienti. Questo espone gli interessati a potenziali violazioni della riservatezza, discriminazioni o abusi in caso di accesso non autorizzato.
2. Violazione dei principi fondamentali del GDPR Il trasferimento di dati in chiaro senza adeguate misure di protezione contrasta con i principi di minimizzazione, integrità e riservatezza previsti dagli articoli 5(1)(c) e 5(1)(f) del GDPR. Inoltre, l’assenza di misure tecniche e organizzative adeguate costituisce una violazione dell’articolo 32, che impone la protezione dei dati personali da trattamenti non autorizzati o illeciti.
3. Esposizione a gravi rischi in caso di violazione o intercettazione Nel caso in cui i dati vengano sottratti o intercettati durante il trasferimento, gli identificatori presenti permetterebbero una facile reidentificazione. Questo scenario espone l’organizzazione a sanzioni, perdita di reputazione e responsabilità nei confronti degli interessati, i quali potrebbero subire danni concreti (furti d’identità, esclusioni assicurative, stigmatizzazione sociale).
Scenario Corretto: Applicazione di Tecniche di Pseudonimizzazione
Dopo aver applicato un processo strutturato di pseudonimizzazione, i dati vengono trasformati come segue:
Struttura della Lookup Table
Conservazione delle tabelle
Di seguito le misure tecniche utilizzate per proteggere le tabelle:
Cifratura con AES-256
AES-256 (Advanced Encryption Standard a 256 bit) è uno degli algoritmi di crittografia simmetrica più sicuri e ampiamente adottati nel settore. Applicare la cifratura AES-256 alle tabelle di pseudonimizzazione significa che:
Il contenuto della tabella (che collega i dati pseudonimizzati agli identificatori originali) è inaccessibile in chiaro anche in caso di accesso non autorizzato al file o al database.
Solo chi possiede la chiave di decifratura, custodita separatamente e con accesso controllato, può leggere o gestire i dati.
Vantaggi:
Alto livello di protezione in caso di data breach.
Conforme alle misure tecniche richieste dall’Art. 32 del GDPR.
Best practice:
Conservare la chiave in un HSM (Hardware Security Module) o sistema equivalente.
Ruotare periodicamente le chiavi e revocarle in caso di compromissione.
Accesso consentito solo a personale sanitario autorizzato
Il principio di “need-to-know” e limitazione degli accessi è centrale nel GDPR (Art. 5 e 32). In questo caso:
Solo operatori sanitari autorizzati, esplicitamente identificati e abilitati, possono accedere alla tabella.
L’accesso deve avvenire tramite autenticazione forte (es. 2FA o smart card).
Ogni operatore deve avere un profilo con permessi minimi necessari per svolgere le proprie funzioni (principio del least privilege).
Misure organizzative associate:
Contratti e policy interne che specificano i ruoli.
Formazione obbligatoria sulla sicurezza dei dati e sul GDPR.
Revoca immediata degli accessi in caso di cambio mansione o cessazione del rapporto.
Logging e auditing
Il monitoraggio continuo delle attività svolte sulle tabelle di pseudonimizzazione è fondamentale per garantire trasparenza e tracciabilità. Ciò include:
Logging automatico di ogni accesso, modifica, copia o esportazione della tabella.
Dati registrati: ID utente, data/ora, operazione effettuata, esito.
Auditing periodico, ossia la revisione dei log da parte di un responsabile (es. DPO o IT security officer), per:
Individuare comportamenti anomali o accessi non autorizzati.
Dimostrare la conformità in caso di ispezioni da parte del Garante Privacy.
Obblighi GDPR:
Questi log costituiscono una misura di accountability, come richiesto dall’art. 5(2) e 24 del GDPR.
I log devono essere conservati in forma protetta, non modificabile e accessibile solo a personale designato.
Conclusioni
La pseudonimizzazione, seppur spesso percepita come una semplice tecnica di protezione dei dati, rappresenta in realtà un pilastro strategico della sicurezza informatica e della conformità normativa, in particolare nel contesto del GDPR. La sua corretta implementazione consente di ridurre significativamente i rischi per i diritti e le libertà degli interessati, senza compromettere l’utilità dei dati per fini analitici, statistici o operativi.
Come abbiamo visto, esistono diverse tecniche e politiche applicative, ognuna con vantaggi e limiti specifici. La scelta del metodo più idoneo deve essere il risultato di una valutazione del rischio ben strutturata, che tenga conto delle finalità del trattamento, del contesto operativo e delle esigenze di reversibilità o anonimato.
L’adozione di misure tecniche avanzate (es. HMAC, AES, tokenizzazione sicura) e organizzative (es. segregazione dei dati, controllo degli accessi, auditing) non è solo raccomandata, ma necessaria per trasformare la pseudonimizzazione in una reale garanzia di protezione, in linea con i principi di privacy by design e by default.
In un’epoca in cui il valore del dato è al centro di ogni processo decisionale e innovativo, pseudonimizzare non significa solo proteggere, ma anche abilitare: consente di trattare dati sensibili in sicurezza, favorendo al contempo la ricerca, l’analisi e l’interoperabilità tra enti pubblici e privati.
La pseudonimizzazione, quindi, non è un semplice adempimento tecnico, ma uno strumento di equilibrio tra privacy e progresso, tra sicurezza e innovazione. E in questo equilibrio risiede la
Uno sviluppatore che usa lo pseudonimo M507 ha presentato un nuovo progetto open source, RamiGPT, uno strumento basato sull’intelligenza artificiale che aiuta ad automatizzare le attività di analisi dei privilegi e di scansione delle vulnerabilità. Il progetto si basa su una connessione tra OpenAI e script Linux e Windows come LinPEAS e BeRoot. Lo strumento è progettato per i ricercatori di sicurezza informatica e i pentester che hanno bisogno di individuare in modo rapido ed efficiente potenziali vettori di escalation dei privilegi in un sistema di destinazione.
Per lavorare con RamiGPT è necessaria una chiave API OpenAI, che può essere ottenuta dal sito web di OpenAI dopo la registrazione. Dopodiché, copia semplicemente il file di impostazioni .env.example in .env , aggiungi la tua chiave alla riga appropriata e potrai avviare il sistema. Sono disponibili due scenari di avvio: tramite Docker e in un ambiente locale. Nel primo caso, è necessario installare Docker e Docker Compose, clonare il repository, eseguire i contenitori e aprire l’interfaccia web all’indirizzo 127.0.0.1:5000. Il secondo richiede Python 3, pip e i comandi eseguiti per generare certificati e installare le dipendenze.
RamiGPT è in grado non solo di analizzare i risultati di strumenti esterni, ma anche di consigliare automaticamente l’avvio di uno script specifico a seconda del sistema operativo. Ad esempio, su Windows – BeRoot, su Linux – LinPEAS. È anche possibile importare ed esportare istruzioni, ad esempio per attività di capture the flag. Tutto ciò è accompagnato da animazioni gif dimostrative che mostrano chiaramente come l’intelligenza artificiale identifica le vulnerabilità e suggerisce modi per sfruttarle.
Il progetto viene distribuito con la precisazione che è destinato esclusivamente a un uso legale, ovvero a fini didattici o per testare sistemi per i quali l’utente ha un’autorizzazione ufficiale. L’autore sottolinea: qualsiasi utilizzo al di fuori di questi limiti è inaccettabile.
You take your air quality seriously, so shouldn’t your monitoring hardware? If you’re breathing in nasty VOCs or dust, surely a little blinking LED isn’t enough to express your displeasure with the current situation. Luckily, [Tobias Stanzel] has created the AqMood to provide us with some much-needed anthropomorphic environmental data collection.
To be fair, the AqMood still does have its fair share of LEDs. In fact, one might even say it has several device’s worth of them — the thirteen addressable LEDs that are run along the inside of the 3D printed diffuser will definitely get your attention. They’re sectioned off in such a way that each segment of the diffuser can indicate a different condition for detected levels of particulates, VOCs, and CO2.
But what really makes this project stand out is the 1.8 inch LCD mounted under the LEDs. This display is used to show various emojis that correspond with the current conditions. Hopefully you’ll see a trio of smiley faces, but if you notice a bit of side-eye, it might be time to crack a window. If you’d like a bit more granular data its possible to switch this display over to a slightly more scientific mode of operation with bar graphs and exact figures…but where’s the fun in that?
[Tobias] has not only shared all the files that are necessary to build your own AqMood, he’s done a fantastic job of documenting each step of the build process. There’s even screenshots to help guide you along when it’s time to flash the firmware to the XIAO Seeed ESP32-S3 at the heart of the AqMood.
Toaster oven reflow projects are such a done deal that there should be nothing new in one here in 2025. Take a toaster oven, an Arduino, and a thermocouple, and bake those boards! But [Paul J R] has found a new take on an old project, and better still, he’s found the most diminutive of toaster ovens from the Australian version of Kmart. We love the project for the tiny oven alone.
The brains of the operation is an ESP32, in the form of either a TTGO TTDisplay board or an S3-Zero board on a custom carrier PCB, with a thermistor rather than a thermocouple for the temperature sensing, and a solid state relay to control mains power for the heater. All the resources are in a GitHub repository, but you may have to make do with a more conventionally-sized table top toaster oven if you’re not an Aussie.
Plastic has been a revolutionary material over the past century, with an uncountable number of uses and an incredibly low price to boot. Unfortunately, this low cost has led to its use in many places where other materials might be better suited, and when this huge amount of material breaks down in the environment it can be incredibly persistent and harmful. This has led to many attempts to recycle it, and one of the more promising efforts recently came out of a lab at Northwestern University.
Plastics exist as polymers, long chains of monomers that have been joined together chemically. The holy grail of plastic recycling would be to convert the polymers back to monomers and then use them to re-make the plastics from scratch. This method uses a catalyst to break down polyethylene terephthalate (PET), one of the more common plastics. Once broken down, the PET is exposed to moist air which converts it into its constituent monomers which can then be used to make more PET for other uses.
Of course, the other thing that any “holy grail” of plastic recycling needs is to actually be cheaper and easier than making new plastic from crude oil, and since this method is still confined to the lab it remains to be seen if it will one day achieve this milestone as well. In the meantime, PET can also be recycled fairly easily by anyone who happens to have a 3D printer around.
The ATmosphereConf was last weekend, independent relays are starting to appear, and more.
Conference
This weekend was the first ATProto conference, the ATmosphereConf, in Seattle. Over two days there were a large number of speakers and sessions, with over 150 people in attendance, and a significant number watching the live streams as well. I could not make it to the US, so for a full overview of the event, I recommend this extensive article by TechCrunch’ Sarah Perez, who was present at the event. The entire event was livestreamed, and all talks can be viewed via this YouTube playlist.
Some assortment of thoughts I had while watching the livestream and VODs over the last few days:
Bluesky CEO Jay Graber gave a short speech, about her background as a digital rights activist, and how she is now “holding the door open, so people can see another world is possible”. Graber is clearly aware of her position, where she is seen as a figurehead of the network, while also wanting to build a decentralised network where there is place for competing platforms. Being a figurehead of a network, without becoming the de facto leader of the network, while also holding the leadership position of by far the largest organisation in the network, is a challenging position to balance.
Bluesky CTO Paul Frazee talked about where Bluesky came from and where it is going. One of the things he talked about is the consideration of why Bluesky decided on their own protocol and not ActivityPub. His answer focuses on practical considerations, especially how ActivityPub handles identity and account migration. Watching the ATProto Ethos talk by Bluesky protocol engineer Daniel Holmgren it struck me that the question could also be framed as a matter of lineage. Holmgren talks about how ATProto takes inspiration from the Web, Peer to Peer systems as well as Distributed Systems. Placing it in such a context makes it clear that ATProto has quite a different background and other ways of thinking than ActivityPub has.
Ændra Rhinisland talked about how community projects can become load-bearing for the network, without adequate support structures for the people who run such projects. She also runs the popular news feeds using Graze. Graze has been adding support for advertisements, and Ændra is one of the first to take advantage. In her talk she walked through how at current usage rates, the feeds could generate over $20k per month in ad revenue. She plans to use this revenue to support the queer communities building on ATProto, and showed early plans for a self-sustaining fund powered by Graze’s feed revenue, to support initiatives such as Northsky.
The talk by Ms Boba is a great indication of how much under-explored design space there is on Bluesky and ATProto. Her talk focuses on labelers and fandom communities, and has some great examples of how they can be used outside of moderation.
Blacksky founder Rudy Fraser gave an excellent talk, describing Bluesky as a skeuomorphism, meaning that it imitates the design of the product it’s replacing. This phase is a part of the adoption cycle for new technologies, but Fraser does not to stop at imitation but instead explore the new ways that communities can be build online. Fraser is specifically interested in building platforms that can serve mid-sized communities, ranging from hundreds of thousands to a few million people. The Blacksky community is an example of this, and Fraser hopes that Blacksky can inspire other communities to do the same. His framing of content moderation as community care and not a cost of business also resonated with me.
Erin Kissane’s talk goes into detail about vernacular institutions, local and grassroots organisations and practices that are often illegible to outsiders but deeply embedded in local communities. This allows them to be close to the needs of their community members, but makes them hard to see and understand from the outside. This outside illegibility is a double-edged sword: IFTAS served a crucial role for trust and safety in the fediverse ecosystem, but had to shut down to a lack of funding as a result of being illegible to financiers.
Bluesky PBC has been working on a new version of the relay that makes it easier and cheaper to host, under the Sync 1.1 proposal. This new version is now starting to roll out, showing a significant drop in resource usage. Bluesky engineer Bryan Newbold shared some statistics here. Independent ATProto developer @futur.blue set up his own relay as a speedrun. He shows that a full network relay can be run on a 50USD Raspberry Pi, with an easy-to-follow tutorial here.
That full network ATProto relays are cheap to run has been known for a while within the ATProto developer community, but that knowledge has not spread much yet. One reason for this is that independent developers have set up relays primarily for their own use, sharing access with a few friends, but no other publicly accessible full-network relays exist yet1.
Upcoming short-form video platform Spark is building their own complete infrastructure. Spark’s relay will publicly accessible, and hosted in Brazil. Having ATProto infrastructure outside of US jurisdiction is a conversation that has come up regularly, and often followed by the assumption that the alternative is to have infrastructure like a relay hosted in Europe. Spark is bringing in a slightly unexpected twist here, by having the first publicly accessible relay that is not owned by Bluesky PBC being hosted in Brazil instead.
Having other relays that are not owned by Bluesky PBC has been the subject of a lot of conversation, and the Free Our Feeds campaign was founded on the idea that a significant financial investment is needed to do so. Furthermore, it assumes that such a relay is not only expensive, but that it requires an extensive governance infrastructure to manage it. The current developments regarding relays call both of these assumptions into serious question: relays are cheap, not expensive. Furthermore it seems that there is enough incentive that organisations that are serious about building their own ATProto platforms are willing to run their own relays.
In Other News
Bluesky PBC has published a proposal on how they want to handle OAuth Scopes. OAuth Scopes is one of the main projects on the roadmap for the first half of this year. Currently, logging into an ATProto app via OAuth requires you to give that app permission to access all the data for your account. OAuth Scopes allows an app to only ask for the permissions that are necessary, and not the entire account. There are two problems that need to solve: the technical part of making it work, as well as the handling the UX to communicate clearly to people what data an app wants to access. The challenging part of the UX is how to handle the translation from the technical description of the data that is requested (stylised like ‘app.bsky.feed.getFeed’, for example), into a way that is understandable for the everyday user. The second challenge is that apps require permission not for one, but for many types of this lexicon data. A third-party Bluesky client that is restricted to only Bluesky data will still have to request a dozen of these Lexicons. A long list of technical lexicon names makes it impossible for regular people to have an informed opinion on what data is and is not being accessed. Bluesky PBC’s proposal is to group different lexicons into bundles, and create new lexicons that reference these bundles. Scoped OAuth can then request access to a bundle of lexicons, with a description that is legible for regular people.
Git repository platform Tangled is working on news ideas how a GitHub alternative might do things differently, and one of their first proposals is defining two types of pull requests. For another look at Tangled, this blog post experiment with what the platform allows.
One of the talks at the ATmosphereConf was by independent developer Rashid Aziz, who is the co-founder of basic.tech. Basic is a protocol for user-owned data, and seems to be fairly comparable to the PDS part of ATProto, with the major difference that Basic allows for private data on their version of a PDS. Aziz used the combination of these two protocols to create private bookmarks for Bluesky.
The new Record Collector labeler automatically displays if someone has been using other apps in the ATmosphere outside of Bluesky.
Rocksky is a new music scrobbler service on ATProto, that is currently in closed beta testing. It allows people to connect their Spotify account and automatically ‘scrobble’ (track) the music they are listening to.
The Links
Some tech-focused links for ATProto:
ATCryptography is a package with cryptographic utilities for the ATProto, written in Swift.
A blog post by independent ATProto developer Mary about ‘AT Protocol, OAuth, and well, decentralization’. Mary also published a repository car file explorer this week.
That’s all for this week, thanks for reading! If you want more analysis, you can subscribe to my newsletter. Every week you get an update with all this week’s articles, as well as extra analysis not published anywhere else. You can subscribe below, and follow this blog @fediversereport.com and my personal account @laurenshof.online on Bluesky.
Cerulea.blue is a publicly accessible relay, using a custom implementation, but it is limited to non-Bluesky PDSes. ↩︎
Fake WiFi repeater with a cheap real one behind it. (Credit: Big Clive, YouTube) Over the years we have seen a lot of fake electronics, ranging from fake power saving devices that you plug into an outlet, to fake car ECU optimizers that you stick into the OBD port. These are all similar in that they fake functionality while happily lighting up a LED or two to indicate that they’re doing ‘something’. Less expected here was that we’d be seeing fake WiFi repeaters, but recently [Big Clive] got his hands on one and undertook the arduous task of reverse-engineering it.
The simple cardboard box which it comes in claims that it’s a 2.4 GHz unit that operates at 300 Mbps, which would be quite expected for the price. [Clive] obtained a real working WiFi repeater previously that did boast similar specifications and did indeed work. The dead giveaway that it is a fake are the clearly fake antennae, along with the fact that once you plug it in, no new WiFi network pops up or anything else.
Inside the case – which looks very similar to the genuine repeater – there is just a small PCB attached to the USB connector. On the PCB are a 20 Ohm resistor and a blue LED, which means that the LED is being completely overdriven as well and is likely to die quite rapidly. Considering that a WiFi repeater is supposed to require a setup procedure, it’s possible that these fake repeaters target an audience which does not quite understand what these devices are supposed to do, but they can also catch more informed buyers unaware who thought they were buying some of the cheap real ones. Caveat emptor, indeed.
We don’t often get our badminton rackets restrung, but if we did, [kuokuo702]’s PicoBETH project would be where we’d turn. This is a neat machine build for a very niche application, but it’s also a nicely elaborated project with motors, load cells, and even a sweet knobby-patterned faceplate that is certainly worth a look even if you’re not doing your own restringing.
We’ll admit that everything we know about restringing rackets we learned by watching [kuokuo]’s demo video, but the basic procedure goes like this: you zigzag the string through the holes in the racket, controlling the tension at each stage along the way. A professional racket frame and clamp hold the tension constant while you fiddle the string through the next hole, but getting the tension just right in the first place is the job of [kuokuo]’s machine. It does this with a load cell, stepper motor, and ball screw, all under microcontroller control. Pull the string through, let the machine tension it, clamp it down, and then move on to the next row.
Automating the tension head allows [kuokuo] to do some fancy tricks, like pre-stretching the strings and even logging the tension in the string at each step along the way. The firmware has an extensive self-calibration procedure, and in all seems to be very professional. But it’s not simply functional; it also has a fun LEGO-compatible collection of bumps integrated into the 3D-printed dust cover. That way, your minifigs can watch you at work? Why not!
Automating random chores is a great excuse to build fun little machines, and in that vein, we salute [kuokuo]’s endeavor. Once you start, you’ll find stepper motors sprouting all around like crocuses in a spring field. And speaking of spring, Easter is just around the corner. So if you don’t play badminton, maybe it’s time to build yourself an eggbot.
Lucrezia Ercoli è docente di “Storia dello spettacolo” all’Accademia di Belle Arti di Bologna. Dal 2011, ricopre il ruolo di direttrice artistica di “Popsophia”. Ha collaborato con il programma televisivo “Terza Pagina” su Rai5 e Rai3 ed è una presenza fissa nel programma “Touch.
@Informatica (Italy e non Italy 😁) Secondo un'indagine di Trend Micro, un miliardo di aziende nel mondo non la usa, anche se l'Europa è un'area virtuosa. Ecco quali rischi corre chi non adotta l'autenticazione a due fattori L'articolo Autenticazione a due fattori: la sicurezza digitale è
facendo immersioni sub ti rendi subito conto che il tuo assetto (tendenza a risalire o scendere, più o meno marcato) è pesantemente condizionato dai pomoni e da quanta aria usi per riempirli, mente respiri. non a caso prendere una bella boccata d'aria e cominciare la discesa è "contro-efficace". un sub svuota bene i polmoni mente si dà la spinta verso il basso, prima di cominciare a scendere, specie nei primi metri di discesa, quelli più difficili per definizione.
poi scopri che i primi rudimentali polmoni sono l'evoluzione sentite bene.... non delle branchie... ma della vescica natatoria. sapete a cosa serve la vescica natatoria vero? ignorerò chi non lo sa. quindi beh... alla fine tutto torna fin troppo magnificamente alla grande.
The Speaker Wars è la nuova band dell’ex Heartbreakers Stan Lynch freezonemagazine.com/news/the-… Membro fondatore degli Heartbreakers di Tom Petty, Stan Lynch, il batterista del gruppo, ha ora una nuova band, The Speaker Wars, composta da Stan Lynch – Batteria, Jon Christopher Davis – Voce, Jay Michael Smith – Chitarra, Brian Patterson – Basso, Steve Ritter – Percussioni e Jay Brown – Tastiera. Stan ha dichiarato: “Dopo 20
Anche se scopi e obiettivi ufficiali dei nuovi dazi, annunciati questa settimana sulle auto di importazione, non corrispondono alle conseguenze che avranno realmente nel breve e medio periodo, il presidente americano Trump ha deciso di procedere con …
Il ministro della Difesa, Guido Crosetto, ha ribadito oggi in Parlamento che l’Italia non sta perseguendo una politica di riarmo, ma sta lavorando per costruire una difesa adeguata alle sfide globali. In un intervento alle commissioni Esteri e Difesa di Camera e
@Informatica (Italy e non Italy 😁) Poche, ancora, le aziende italiane con una strategia di cybersecurity matura: appena il 15%. È quanto si evince dal secondo rapporto Cyber Index PMI. Un'analisi completa rivela le debolezze delle piccole e medie imprese nella gestione dei rischi digitali, tra minacce crescenti
Come era prevedibile la presentazione del Libro Bianco sulla Difesa Europea, al pari del precedente ReArm Europe, ha rinfocolato in Italia polemiche, furore populista e divisioni su un tema vitale per il futuro della
 - Collegamento all'originale")



















")




informapirata ⁂
in reply to Marco Siino • • •@uaar @gayburg
Marco Siino
in reply to informapirata ⁂ • •informapirata ⁂ reshared this.
informapirata ⁂
in reply to Marco Siino • • •Marco Siino
in reply to Marco Siino • — (Palermo) •