 - Collegamento all'originale")
Digital Crime: La violenza sessuale virtuale
Art.609-bis c.p. : Chiunque, con violenza o minaccia o mediante abuso di autorità costringe taluno a compiere o subire atti sessuali è punito con la reclusione da sei a dodici anni.
Alla stessa pena soggiace chi induce taluno a compiere o subire atti sessuali:
1) abusando delle condizioni di inferiorità fisica o psichica della persona offesa al momento del fatto;
2) traendo in inganno la persona offesa per essersi il colpevole sostituito ad altra persona.
Nei casi di minore gravità la pena è diminuita in misura non eccedente i due terzi.
Il contenuto della norma
Un tema relativamente nuovo è quello della violenza sessuale realizzata a distanza attraverso le tecnologie dell’informazione. Sempre più frequenti, infatti, sono i casi in cui un soggetto, attraverso l’installazione di una web cam chiede prestazioni sessuali ad altra persona o impone alla stessa di assistere a suoi atti di autoerotismo.
Sul piano giuridico, non essendovi norma specifica, occorre necessariamente far riferimento all’art.609-bis, che punisce, come violenza sessuale, la condotta di colui che con violenza o minaccia o mediante abuso di autorità costringa taluno a compiere o subire atti sessuali e quella di colui che induca un altro soggetto a compiere o subire atti sessuali abusando delle condizioni di inferiorità fisica o psichica della persona offesa al momento del fatto o traendo in inganno la persona offesa per essersi il colpevole sostituito ad altra persona.
Vista la formulazione dell’art.609- bis si è posto il problema di comprendere se sia ipotizzabile una violenza sessuale attraverso la rete.
La Giurisprudenza, come illustriamo di seguito, pare dare al momento risposta affermativa.
Cosa dice la giurisprudenza
Risponde di violenza sessuale – e non di estorsione – colui che, dietro la minaccia di diffusione di video sessualmente espliciti, costringa la vittima ad inviargli su Whatsapp foto delle proprie parti intime ( Cass., Sez. II, sent. n. 41985/21).
Perfeziona la fattispecie di violenza sessuale la condotta consistente nell’invio di una serie di messaggi whatsapp allusivi e sessualmente espliciti ad una minorenne , costringendola a realizzare selfie da contenuti intimi da inviare al soggetto agente, con la minaccia di pubblicare la chat su un social network (Cass.,Sez.III,sent.n.25266/20).
La Corte di Cassazione ha confermato la condanna per violenza sessuale realizzata mediante l’utilizzo di social network e webcam. Nel caso di specie, in particolare, il soggetto, attraverso le suddette tecnologie, aveva compiuto atti di autoerotismo dopo essersi assicurato che alcune minori lo avrebbero guardato attraverso webcam (Cass., Sez. III, sent. n. 16616/15).
In relazione all’art. 609-bis, c.1, c.p. si è più volte ribadito che il reato di violenza sessuale non sia esclusivamente caratterizzato dal contatto corporeo, potendosi estrinsecare anche nel compimento di atti di autoerotismo effettuati a seguito di costrizione o induzione ( Cass. , Sez.III, sent.n.37076/12).
Si è esclusa la possibilità di applicare “automaticamente” ai casi di violenza sessuale virtuale la circostanza attenuante speciale del fatto di lieve entità. Si è a tal riguardo precisato, infatti, che, ai fini dell’accertamento della diminuente prevista dall’art. 609 – bis, c. 3, c.p., debba farsi riferimento, oltre che alla materialità del fatto, a tutte le modalità che hanno caratterizzato la condotta criminosa, nonché al danno arrecato alla parte lesa, anche e soprattutto in considerazione dell’età della stessa o di altre condizioni psichiche in cui versi (Cass., Sez.III, sent.n.16615/15; Cass., Sez.III, sent. n. 45604/07).
L'articolo Digital Crime: La violenza sessuale virtuale proviene da il blog della sicurezza informatica.
Lavoro, la lotta contro il caporalato si vince anche col ritorno dello Stato
@Notizie dall'Italia e dal mondo
Il nuovo articolo di @Valori.it
Quali sono le radici del caporalato in Italia e perché un rinnovato ruolo dei poteri pubblici potrebbe aiutarci a renderlo un ricordo
L'articolo Lavoro, la lotta contro il caporalato si vince anche col ritorno dello Stato valori.it/caporalato-storia-st…
Notizie dall'Italia e dal mondo reshared this.
Kylian Mbappé, il calciatore che ferma l’avanzata del neofascismo
@Notizie dall'Italia e dal mondo
Il nuovo articolo di @Valori.it
In Francia Mbappé sposta voti con le sue dichiarazioni. In Italia Spalletti va alla festa del partito neofascista al governo
L'articolo Kylian Mbappé, il calciatore che ferma l’avanzata del neofascismo proviene da Valori.
Notizie dall'Italia e dal mondo reshared this.
Misconceptions About Loops, or: Static Code Analysis is Hard

When thinking about loops in programming languages, they often get simplified down to a conditions section and a body, but this belies the dizzying complexity that emerges when considering loop edge cases within the context of static analysis. A paper titled Misconceptions about Loops in C by [Martin Brain] and colleagues as presented to SOAP 2024 conference goes through a whole list of false assumptions when it comes to loops, including for languages other than C. Perhaps most interesting is the conclusion that these ‘edge cases’ are in fact a lot more common than generally assumed, courtesy of how creative languages and their users can be when writing their code, with or without dragging in the meta-language of C’s preprocessor.
Assumptions like loop equivalence can fall apart when considering the CFG ( control flow graph) interpretation versus a parse tree one where the former may e.g. merge loops. There are also doozies like assuming that the loop body will always exist, that the first instruction(s) in a loop are always the entry point, and the horrors of estimating loop exits in the context of labels, inlined functions and more. Some languages have specific loop control flow features that differ from C (e.g. Python’s for/else and Ada’s loop), all of which affect a static analysis.
Ultimately, writing a good static analysis tool is hard, and there are plenty of cases where it’s likely to trip up and give an invalid result. A language which avoids ambiguity (e.g. Ada) helps immensely here, but for other languages it helps to write your code as straightforward as possible to give the static analysis tool a fighting chance, or just get really good at recognizing confused static analysis tool noises.
(Heading image: Control flow merges can create multiple loop entry
edges (Credit: Martin Brand, et al., SOAP 2024) )


Looking At Standard-Cell Design in the Pentium processor
")
Whereas the CPUs and similar ASICs of the 1970s had their transistors laid out manually, with the move from LSI to VLSI, it became necessary to optimize the process of laying out the transistors and the metal interconnects between them. This resulted in the development of standard-cells: effectively batches of transistors with each a specific function that could be chained together. First simple and then more advanced auto-routing algorithms handled the placement and routing of these standard elements, leading to dies with easily recognizable structures under an optical microscope. Case in point an original (P54C) Intel Pentium, which [Ken Shirriff] took an in-depth look at.

Using a by now almost unimaginably large 600 nm process, the individual elements of these standard cells including their PMOS and NMOS components within the BiCMOS process can be readily identified and their structure reverse-engineered. What’s interesting about BiCMOS compared to CMOS is that the former allows for the use of bipolar junction transistors, which offer a range of speed, gain and output impedance advantages that are beneficial for some part of a CPU compared to CMOS. Over time BiCMOS’ advantages became less pronounced and was eventually abandoned.
All in all, this glimpse at the internals of a Pentium processor provides a fascinating snapshot of high-end Intel semiconductor prowess in the early 1990s.
(Top image: A D flip-flop in the Pentium. Credit: [Ken Shirriff] )
Building A Cassette Deck Controller To Save a Locked Out Car Stereo

Cars have had DRM-like measures for longer than you might think. Go back to the 1990s, and coded cassette decks were a common way to stop thieves being able to use stolen stereos. Sadly, they became useless if you ever lost the code. [Simon] had found a deck in great condition that was locked out, so he set about building his own controller for it.
The build relies on the cassette transport of a car stereo and a VFD display, but everything else was laced together by Simon. It’s a play-only setup, with no record, seeing as its based on an automotive unit. [Simon]’s write up explains how he reverse engineered the transport, figuring out how the motors and position sensors worked to control the playback of a cassette.
[Simon] used an Atmega microcontroller as the brains of the operation, which reads the buttons of the original deck via an ADC pin to save I/O for other tasks. The chip also drives the VFD display for user feedback, and handles auto reverse too. The latter is thanks to the transport’s inbuilt light barriers, which detect the tape’s current status. On the audio side, [Simon] whipped up his own head amplifier to process the signal from the tape head itself.
Fundamentally, it’s a basic build, but it does work. We’ve seen other DIY tape decks before, too. There’s something about this format that simply refuses to die. The fans just won’t let Compact Cassette go down without a fight. Video after the break.
Hackable Ham Radio Gives Up Its Mechanical Secrets

Reverse-engineered schematics are de rigeur around these parts, largely because they’re often the key to very cool hardware hacks. We don’t get to see many mechanical reverse-engineering efforts, though, which is a pity because electronic hacks often literally don’t stand on their own. That’s why these reverse-engineered mechanical diagrams of the Quansheng UV-K5 portable amateur radio transceiver really caught our eye.
Part of the reason for the dearth of mechanical diagrams for devices, even one as electrically and computationally hackable as the UV-K5, is that mechanical diagrams are a lot less abstract than a schematic or even firmware. Luckily, this fact didn’t daunt [mdlougheed] from putting a stripped-down UV-K5 under a camera for a series of images to gather the raw data needed by photogrammetry package RealityCapture. The point cloud was thoughtfully scaled to match the dimensions of the radio’s reverse-engineered PC board, so the two models can work together.
The results are pretty impressive, especially for a first effort, and should make electromechanical modifications to the radio all the easier to accomplish. Hats off to [mdlougheed] for the good work, and let the mechanical hacks begin.
Stoltenberg annuncia un impegno congiunto per l’industria della Difesa
[quote]È iniziato il summit di Washington, annuale riunione dei capi di Stato e di governo dei 32 Paesi membri dell’Alleanza Atlantica. Col vertice, si terrà anche il Nato Public Forum, di cui Formiche è il media partner italiano: si tratta di una serie di interviste e panel in cui i
Due gravi vulnerabilità sono state rilevate su Citrix NetScaler Console, Agent e SVM
Nella giornata di oggi, dopo la pubblicazione delle due CVE CVE-2024-5491 e CVE-2024-5492 come riportato nel nostro precedente articolo, Citrix Netscaler pubblica ulteriori due CVE. Si tratta di ulteriori due bug di sicurezza che affliggono i prodotti NetScaler Console (precedentemente noto come NetScaler ADM), NetScaler SVM e NetScaler Agent.
Le vulnerabilità coinvolte sono:
- CVE-2024-6235: Divulgazione di informazioni sensibili (CVSSv4 Severità Critical 9.4)
- CVE-2024-6236: Negazione del servizio (CVSSv4 Severità High 7.1)
Versioni Interessate
Le versioni seguenti dei prodotti NetScaler sono soggette alle vulnerabilità:
- NetScaler Console: Versioni precedenti a 14.1-25.53
- NetScaler SVM: Versioni precedenti a 14.1-25.53, 13.1-53.17, 13.0-92.31
- NetScaler Agent: Versioni precedenti a 14.1-25.53, 13.1-53.22, 13.0-92.31
Riepilogo delle Vulnerabilità
- CVE-2024-6235: Questa vulnerabilità può consentire la divulgazione di informazioni sensibili agli attaccanti che hanno accesso all’IP della console NetScaler. È classificata con un punteggio CVSS v4.0 di 9.4, indicando un alto rischio di compromissione dei dati sensibili.
- CVE-2024-6236: Questa vulnerabilità comporta una negazione del servizio agli utenti che hanno accesso all’IP della console NetScaler, all’IP dell’agente NetScaler e all’IP SVM. Ha un punteggio CVSS v4.0 di 7.1, indicando un rischio moderato ma significativo di interruzione del servizio.
Azioni Consigliate per i Clienti da parte di Citric Netscaler
Cloud Software Group consiglia vivamente ai clienti di NetScaler Console di adottare le seguenti misure:
- Installare immediatamente le versioni aggiornate di NetScaler Console, SVM e Agent:
- NetScaler Console 14.1-25.53 e successive, 13.1-53.22 e successive, 13.0-92.31 e successive
- NetScaler SVM 14.1-25.53 e successive, 13.1-53.17 e successive, 13.0-92.31 e successive
- NetScaler Agent 14.1-25.53 e successive, 13.1-53.22 e successive, 13.0-92.31 e successive
Questi aggiornamenti sono fondamentali per mitigare i rischi associati alle vulnerabilità CVE-2024-6235 e CVE-2024-6236, proteggendo così l’infrastruttura di rete e i dati sensibili gestiti tramite NetScaler Console.
Conclusione
La sicurezza delle infrastrutture IT è di primaria importanza. Agendo tempestivamente e applicando le patch consigliate, i clienti di NetScaler possono migliorare significativamente la sicurezza e la resilienza contro le minacce informatiche emergenti.
Restate protetti e informati, insieme possiamo rafforzare la difesa contro le vulnerabilità del ransomware e altre minacce digitali.
L'articolo Due gravi vulnerabilità sono state rilevate su Citrix NetScaler Console, Agent e SVM proviene da il blog della sicurezza informatica.
Etiopia, rapiti almeno 100 studenti mentre viaggiavano da Amhara verso Addis Abeba
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Etiopia, secondo quanto riferito, almeno 100 studenti sono stati rapiti da un gruppo armato non identificato mentre viaggiavano in autobus dalla
Notizie dall'Italia e dal mondo reshared this.
Supercon Call For Proposals Extended: July 16th

Ever since the first Supercon, people have submitted talk proposals at the very last minute, and some even in the minutes after the last minute. We know how it is – we are fully licensed procrastineers ourselves. So with an eye toward tradition, we’re extending the Call for Speakers and the Call for Workshops one more week, until July 16th.

In other news, [Voja] has an alpha version of the badge finished, so all that’s left is 90% of the work disguised as 10%. Some people have asked for clues, and what we’ll say at this point is that “Simple Add Ons have underutilized I2C pins”.
Expect tickets to go on sale in the next weeks – early bird tickets sell out fast. Keep your eyes on Hackaday for the announcement post when it goes live. Or, you can skip straight to the front of the line by giving a talk. But you can’t give a talk if you don’t submit your proposal first. Get on it now, because we’re not going to extend the CFP twice!
Keep Your Lungs Clean and Happy with a DIY Supplied-Air Respirator

The smell of resin SLA printing is like the weather — everybody complains about it, but nobody does anything about it. At least until now, as [Aris Alder] tackles the problem with an affordable DIY supplied-air respirator.
Now, we know what you’re thinking, anything as critical as breathing is probably best left to the professionals. While we agree in principle, most solutions from reputable companies would cost multiple thousands of dollars to accomplish, making it hard to justify for a home gamer who just doesn’t want to breathe in nasty volatile organic compounds. [Aris] starts the video below with a careful examination of the different available respirator options, concluding that a supplied air respirator (SAR) is the way to go.
His homebrew version consists of an affordable, commercially available plastic hood with a built-in visor. Rather than an expensive oil-free compressor to supply the needed airflow, he sourced a low-cost inline duct fan and placed it outside the work zone to pull in fresh air. Connecting the two is low-cost polyethylene tubing and a couple of 3D printed adapters. This has the advantage of being very lightweight and less likely to yank the hood off your head, and can be replaced in a few seconds when it inevitably punctures.
Another vital part of the kit is a pulse oximeter, which [Aris] uses to make sure he’s getting enough oxygen. His O2 saturation actually goes up from his baseline when the hood is on and powered up, which bodes well for the system. Every time we pick up the welding torch or angle grinder we wish for something like this, so it might just be time to build one.
youtube.com/embed/QJFC11fIUls?…
Thanks to [Zane Atkins] for the tip.
Solar Dynamics Observatory: Our Solar Early Warning System

Ever since the beginning of the Space Age, the inner planets and the Earth-Moon system have received the lion’s share of attention. That makes sense; it’s a whole lot easier to get to the Moon, or even to Mars, than it is to get to Saturn or Neptune. And so our probes have mostly plied the relatively cozy confines inside the asteroid belt, visiting every world within them and sometimes landing on the surface and making a few holes or even leaving some footprints.
But there’s still one place within this warm and familiar neighborhood that remains mysterious and relatively unvisited: the Sun. That seems strange, since our star is the source of all energy for our world and the system in general, and its constant emissions across the electromagnetic spectrum and its occasional physical outbursts are literally a matter of life and death for us. When the Sun sneezes, we can get sick, and it has the potential to be far worse than just a cold.
While we’ve had a succession of satellites over the last decades that have specialized in watching the Sun, it’s not the easiest celestial body to observe. Most spacecraft go to great lengths to avoid the Sun’s abuse, and building anything to withstand the lashing our star can dish out is a tough task. But there’s one satellite that takes everything that the Sun dishes out and turns it into a near-constant stream of high-quality data, and it’s been doing it for almost 15 years now. The Solar Dynamics Observatory, or SDO, has also provided stunning images of the Sun, like this CGI-like sequence of a failed solar eruption. Images like that have captured imaginations during this surprisingly active solar cycle, and emphasized the importance of SDO in our solar early warning system.
Living With a Star
In a lot of ways, SDO has its roots in the earlier Solar and Heliospheric Observer, or SOHO, the wildly successful ESA solar mission. Launched in 1995, SOHO is stationed in a halo orbit at Lagrange point L1 and provides near real-time images and data on the sun using a suite of twelve science instruments. Originally slated for a two-year science program, SOHO continues operating to this day, watching the sun and acting as an early warning for coronal mass ejections (CME) and other solar phenomena.
Although L1, the point between the Earth and the Sun where the gravitation of the two bodies balances, provides an unobstructed view of our star, it has disadvantages. Chief among these is distance; at 1.5 million kilometers, simply getting to L1 is a much more expensive proposition than any geocentric orbit. The distance also makes radio communications much more complicated, requiring the specialized infrastructure of the Deep Space Network (DSN). SDO was conceived in part to avoid some of these shortcomings, as well as to leverage what was learned on SOHO and to extend some of the capabilities delivered by that mission.
SDO stemmed from Living with a Star (LWS), a science program that kicked off in 2001 and was designed to explore the Earth-Sun system in detail. LWS identified the need for a satellite that could watch the Sun continuously in multiple wavelengths and provide data on its atmosphere and magnetic field at an extremely high rate. These requirements dictated the specifications of the SDO mission in terms of orbital design, spacecraft engineering, and oddly enough, a dedicated communications system.
Geosynchronous, With a Twist
Getting a good look at the Sun for space isn’t necessarily as easy as it would seem. For SDO, designing a suitable orbit was complicated by the stringent and somewhat conflicting requirements for continuous observations and constant high-bandwidth communications. Joining SOHO at L1 or setting up shop at any of the other Lagrange points was out of the question due to the distances involved, leaving a geocentric orbit as the only viable alternative. A low Earth orbit (LEO) would have left the satellite in the Earth’s shadow for half of each revolution, making continuous observation of the Sun difficult.
To avoid these problems, SDO’s orbit was pushed out to geosynchronous Earth orbit (GEO) distance (35,789 km) and inclined to 28.5 degrees relative to the equator. This orbit would give SDO continuous exposure to the Sun, with just a few brief periods during the year where either Earth or the Moon eclipses the Sun. It also allows constant line-of-sight to the ground, which greatly simplifies the communications problem.
youtube.com/embed/9jRllaVCc00?…
Science of the Sun

The main body of SDO has a pair of solar panels on one end and a pair of steerable high-gain dish antennas on the other. The LWS design requirements for the SDO science program were modest and focused on monitoring the Sun’s magnetic field and atmosphere as closely as possible, so only three science instruments were included. All three instruments are mounted to the end of the spaceframe with the solar panels, to enjoy an unobstructed view of the Sun.
Of the three science packages, the Extreme UV Variability Experiment, or EVE, is the only instrument that doesn’t image the full disk of the Sun. Rather, EVE uses a pair of multiple EUV grating spectrographs, known as MEGS-A, and MEGS-B, to measure the extreme UV spectrum from 5 nm to 105 nm with 0.1 nm resolution. MEGS-A uses a series of slits and filters to shine light onto a single diffraction grating, which spreads out the Sun’s spectrum across a CCD detector to cover from 5 nm to 37 nm. The MEGS-A CCD also acts as a sensor for a simple pinhole camera known as the Solar Aspect Monitor (SAM), which directly measures individual X-ray photons in the 0.1 nm to 7 nm range. MEGS-B, on the other hand, uses a pair of diffraction gratings and a CCD to measure EUV from 35 nm to 105 nm. Both of these instruments capture a full EUV spectrum every 10 seconds.
To study the corona and chromosphere of the Sun, the Atmospheric Imaging Assembly (AIA) uses four telescopes to create full-disk images of the sun in ten different wavelengths from EUV to 450 nm. The 4,096 by 4,096 sensor gives the AIA a resolution of 0.6 arcseconds per pixel, and the optics allow imaging out to almost 1.3 solar radii, to capture fine detail in the thin solar atmosphere. AIA also visualizes the Sun’s magnetic fields as the hot plasma gathers along lines of force and highlights them. Like all the instruments on SDO, the AIA is built with throughput in mind; it can gather a full data set every 10 seconds.
For a deeper look into the Sun’s interior, the Helioseismic and Magnetic Imager (HMI) measures the motion of the Sun’s photosphere and magnetic field strength and polarity. The HMI uses a refracting telescope, an image stabilizer, a series of tunable filters that include a pair of Michelson interferometers, and a pair of 4,096 by 4,096-pixel CCD image detectors. The HMI captures full-disk images of the Sun known as Dopplergrams, which reveal the direction and velocity of movement of structures in the photosphere. The HMI is also capable of switching a polarization filter into the optical path to produce magnetograms, which use the polarization of light as a proxy for magnetic field strength and polarity.
Continuous Data, and Lots of It
Like all the SDO instruments, HMI is built with data throughput in mind, but with a twist. Helioseismology requires accumulating data continuously over long observation periods; the original 5-year mission plan included 22 separate HMI runs lasting for 72 consecutive days, during which 95% of the data had to be captured. So not only must HMI take images of the Sun every four seconds, it has to reliably and completely package them up for transmission to Earth.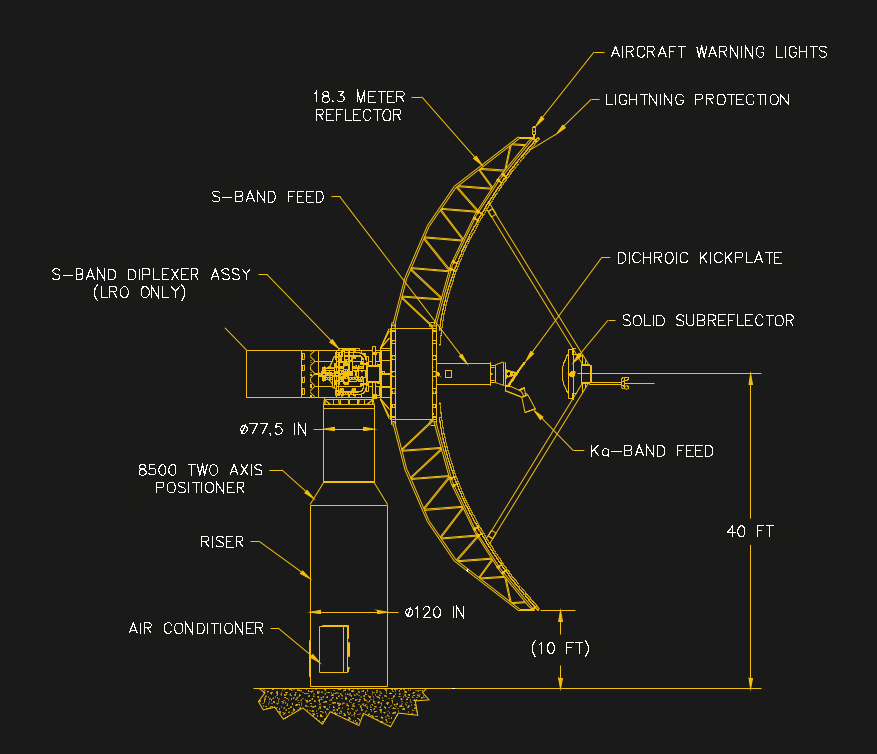
While most space programs try to leverage existing communications infrastructure, such as the Deep Space Network (DSN), the unique demands of SDO made a dedicated communications system necessary. The SDO communication system was designed to meet the throughput and reliability needs of the mission, literally from the ground up. A dedicated ground station consisting of a pair of 18-meter dish antennas was constructed in White Sands, New Mexico, a site chosen specifically to reduce the potential for rainstorms to attenuate the Ka-band downlink signal (26.5 to 50 GHz). The two antennas are located about 5 km apart within the downlink beamwidth, presumably for the same reason; storms in the New Mexico desert tend to be spotty, making it more likely that at least one site always has a solid signal, regardless of the weather.
To ensure that all the downlinked data gets captured and sent to the science teams, a complex and highly redundant Data Distribution System (DDS) was also developed. Each dish has a redundant pair of receivers and servers with RAID5 storage arrays, which feed a miniature data center of twelve servers and associated storage. A Quality Compare Processing (QCP) system continually monitors downlinked data quality from each instrument aboard SDO and stores the best available data in a temporary archive before shipping it off to the science team dedicated to each instrument in near real-time.
The numbers involved are impressive. The SDO ground stations operate 24/7 and are almost always unattended. SDO returns about 1.3 TB per day, so the ground station has received almost 7 petabytes of images and data and sent it on to the science teams over the 14 years it’s been in service, with almost all of it being available nearly the instant it’s generated.
As impressive as the numbers and the engineering behind them may be, it’s the imagery that gets all the attention, and understandably so. NASA makes all the SDO data available to the public, and almost every image is jaw-dropping. There are also plenty of “greatest hits” compilations out there, including a reel of the X-class flares that resulted in the spectacular aurorae over North America back in mid-May.
youtube.com/embed/G2OXPWgjUmI?…
Like many NASA projects, SDO has far exceeded its planned lifespan. It was designed to catch the midpoint of Solar Cycle 24, but has managed to stay in service through the solar minimum of that cycle and into the next, and is now keeping a close watch on the peak of Solar Cycle 25.
Sudan, l’inviato ONU invita l’esercito sudanese e la RSF a colloqui indiretti a Ginevra
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
L’inviato personale del Segretario Generale delle Nazioni Unite, Ramtane Lamamra, ha invitato l’esercito sudanese e le Forze di Rapid
Notizie dall'Italia e dal mondo reshared this.
Etiopia, appello per intervento conto la violenza di genere in Tigray, incolpando il governo
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Ventisette organizzazioni della società civile con sede nella regione del Tigray chiedono un’azione urgente da parte delle
Notizie dall'Italia e dal mondo reshared this.
Dal Delta IV Heavy allo spazio profondo. Tra spie, satelliti e galassie!
Il 9 luglio alle 20 ora italiana si aprirà la finestra di lancio per il nuovo Ariane6, che dallo spazioporto di Kourou, nella Guyana francese, ripartirà in orbita l’Europa. Prima però di celebrare il nuovo lanciatore europeo con un articolo dedicato, celebriamo l’ultimo lancio del Delta IV Heavy della ULA. Il 9 aprile scorso alle 18:53 ora italiana, il lanciatore statunitense e’ decollato per l’ultima volta portando in orbita un carico riservato per conto del National Reconnaissance Office. Questo lancio ci fornisce l’occasione per raccontare una storia poco conosciuta, una storia che ha per protagonisti spie, satelliti in orbita e galassie lontanissime nello spazio e nel tempo.
Il Delta IV Heavy era una lanciatore non riutilizzabile della azienda ULA (United Launch Alliance, un consorzio formato da Lockheed-Martin e Boeing), fu lanciato per la prima volta nel 2004 anche se il primo lancio non fu propriamente un successo: infatti a causa di alcuni malfunzionamento e del conseguente dello stadio principale non permisero il raggiungimento dell’orbita programmata.
Il Delta IV Heavy aveva delle dimensioni considerevoli, l’altezza era 72 metri e il diametro di 5, con 4 motori alimentati da idrogeno ed ossigeno liquido. Questa 4 motori in configurazione Heavy gli consentirono prestazioni facendolo essere il lanciatore, sulla carta, più potente per l’orbita bassa: da specifiche presentava una capacità di carico di 29 tonnellate (il Falcon Heavy di SpaceX sulla carta è più potente, ma solo se usato in configurazione expendable).
Tra i lanci più notevoli sicuramente troviamo il lancio di qualifica della capsula Orion della NASA, e il lancio della sonda Parker Solar Probe, che dal 2025 raggiungerà la distanza minima dal Sole (circa 7 milioni di chilometri) e che, anche grazie al lancio operato dal Delta IV Heavy, è l’oggetto più veloce mai costruito dell’uomo: raggiungerà nel periodo di massimo avvicinamento alla nostra stella, una velocità di 690000 km/h!
Ma la nostra storia non riguarda il lanciatore, bensì il payload, il carico che lanciatore porta in orbita. Dando un’occhiata alla lista della missioni operate con un Delta IV Heavy, notiamo che 12 lanci su 16 hanno la sigla NROL-xx con un numero progressivo; la sigla sta per National Reconnaissance Office Launch, cioè lanci eseguiti con un carico gestito dalla NRO l’agenzia federale statunitense incaricata di progettare, costruire, lanciare e gestire i satelliti da ricognizione per attività’ di intelligence (principalmente IMINT, SIGINT E MASINT).
L’ultimo lancio di cui il Delta IV Heavy è stato protagonista ha messo in orbita un satellite siglato come Orion, una classe di satelliti spia come destinati alla SIGINT, cioè la raccolta di informazioni mediante l’intercettazione di segnali (intesi sia come comunicazioni dirette tra persone sia come segnali elettromagnetici non usati direttamente nelle comunicazioni vocali). Tra i carichi che compaiono nella lista dei payload messi in orbita con il Delta IV Heavy troviamo anche i satelliti KH-11 Kennen, e sono quelli per noi più interessanti. Questi satelliti hanno un disegno molto familiare per gli appassionati di attività spaziali. Anche se il design e i dettagli tecnici delle varie classi di satelliti spia sono ovviamente classificati, dai grafici trapelati possiamo vedere che i KH-1 Kennen… sono essenzialmente l’Hubble Space Telescope. L’aspetto è davvero molto simile, e non è un caso.

Possibile layout dei satelliti KH-11 Kennen
Hubble Space Telescope
L’Hubble Space Telescope, fu lanciato nel 1990, e ci ha dato modo di fare grandiose scoperte: grazie alle sue osservazioni fu prodotto l’Hubble Deep Field una delle fotografie più profonde dell’Universo. Hubble inquadrò per dieci giorni consecutivi, dal 18 al 28 dicembre 1995, una regione di cielo nella costellazione dell’Orsa Maggiore ritenuta libera da “interferenze” che potessero compromettere l’elevata risoluzione di Hubble.
In questo minuscolo angolo di cielo (2.6 minuti d’arco, equivalente ad una pallina da tennis vista a 100 metri di distanza) Hubble scoprì più di 3000 galassie, alcune distanti 12 miliardi di anni luce! Questa prima osservazione (a cui seguirono altri campi profondi, il più recente Hubble eXtreme Deep Field del 2012) si rivelò una pietra miliare nello studio dell’universo primordiale e fu possibile grazie alle straordinarie caratteristiche tecniche dell’Hubble.

La prima idea di un telescopio spaziale si fa risalire al 1923 quando Hermann Oberth, uno dei padri dell’astronautica, propose nel suo volume Die Rakete zu den Planetenräumen (The Rocket into Planetary Space) l’’idea di un telescopio portato nello spazio per mezzo di un missile.
Il progetto del telescopio spaziale Hubble prese forma ufficialmente con lo stanziamento dei fondi da parte del Congresso americano nel 1978, con lancio previsto per il 1983. Dopo vari sforamenti di budget e ritardi, il lancio di Hubble avvenne il 24 aprile 1990 a bordo dello Shuttle Discovery (STS-31). Dalle immagini del lancio si vede benissimo che Hubble entrava perfettamente nella baia di carico dello space shuttle. Anche questo non è un caso.
Il progetto dello Space Shuttle iniziò alla fine degli anni ’60, quando ormai il programma Apollo era avviato alla sua conclusione dopo aver raggiunto gli obiettivi tecnologici ma soprattutto politici per cui era nato: dimostrare la superiorità nei confronti dell’Unione Sovietica. L’obiettivo era la costruzione di un sistema di volo che fosse riutilizzabile almeno in parte, per poter mettere in orbita bassa carichi scientifici e non solo. Il primo volo fu quello dell’Enterprise nel 1977, e la prima missione orbitale fu la STS-1 del 12 aprile 1981 con il Columbia.
Hubble fu messo in orbita nel 1990 e come dicevamo si adattava perfettamente alla baia di carico del Columbia; questo perché il dipartimento della Difesa partecipò e “incoraggiò” moltissimo la progettazione dello Space Shuttle. In base agli accordi, il Dipartimento della Difesa contribuì con fondi, personale e conoscenza al progetto ma in cambio ottenne dalla NASA che la baia di carico dell’orbiter (la componente riutilizzabile, il velivolo che per sineddoche chiamiamo Space Shuttle) avesse caratteristiche specifiche e si adattasse alle esigenze della NRO. L’agenzia e lo spionaggio in generale furono anche protagonisti nel design di Hubble: infatti lo specchio da 2.4 m di Hubble fu ridotto dai 3 metri iniziali proprio per venire incontro alle esigenze operative della NRO, sempre in cambio di fondi e conoscenze tecniche.
La “donazione” del 2012 e i piani futuri
La “collaborazione” tra NASA e NRO è proficua, non solo relativamente alla progettazione dei KH-11 Kennen ed Hubble, ma anche per i futuri telescopi spaziali. E’ necessario però un passo indietro di una decina di anni.
Ormai in servizio dal 1990 e oggetto di numerose missioni di manutenzione (la più famosa nel 1993, per correggere difetti all’ottica) Hubble andava incontro ad un degrado di performance. Anche se la vita media operativa e le prestazioni fossero andate ben oltre le aspettative, tuttavia nei primi anni 2000 appariva chiaro che l’elettronica e i sistemi in generale non avrebbero resistito a lungo alle condizioni estreme dello spazio e le prestazioni erano in calo. Nel corso del 2011 l’NRO rese noto alla NASA la disponibilità di due satelliti spia considerati dall’agenzia troppo obsoleti per l’osservazione della Terra a fini strategici, e li mise a disposizione a patto che le ottiche non fossero usate per l’osservazione della Terra e che a Houston si pensasse in autonomia a ripristinare la parte elettronica, che per motivi facilmente intuibili fu rimossa dai satelliti.
I due satelliti furono ufficialmente donati nel 2012 e la NASA decise così di costruire sulla base di quei due satelliti i futuri telescopi per l’osservazione del cosmo. Uno dei due al momento non è stato ancora utilizzato ma si sa che l’altro è stato usato come base, in particolare le ottiche, per il telescopio rinominato Nancy Grace Roman Space Telescope (precedente noto come Wide-Field Infrared Survey Telescope o WFIRST).

Questo satellite, il cui lancio è previsto per il 2027 avrà come come obiettivo quello di rispondere ad una vasta gamma di domande tra cui la ricerca di pianeti extra solari, la scoperta eventuale dell’energia oscura, testare con maggiore precisione la Relatività Generale. Neanche a dirlo Nancy Grace Roman fu tra le principali sostenitrici del progetto Hubble: ben prima che diventasse un progetto ufficiale della NASA, Nancy Roman teneva conferenze pubbliche promuovendo il valore scientifico del telescopio. Dopo l’approvazione del progetto, divenne la scienziata responsabile del programma, organizzando il comitato direttivo incaricato di rendere fattibili le esigenze degli astronomi e scrivendo numerosi report per il Congresso americano nel corso degli anni ’70 per sostenere il continuo finanziamento del telescopio.
L'articolo Dal Delta IV Heavy allo spazio profondo. Tra spie, satelliti e galassie! proviene da il blog della sicurezza informatica.
L’exploit POC per l’RCE di VMware vCenter Server è ora disponibile Online!
Un ricercatore indipendente di sicurezza informatica ha rilasciato un exploit Proof-of-Concept (PoC) per sfruttare la vulnerabilità RCE CVE-2024-22274. Tale bug di sicurezza affligge la popolare utility di gestione di macchine virtuali e nodi ESXi conosciuto come VMware vCenter Server.
Panoramica della vulnerabilità
L’exploit consente ad un attore malintenzionato autenticato sulla shell dell’appliance vCenter di sfruttare questa vulnerabilità per eseguire comandi arbitrari sul sistema operativo sottostante con privilegi di “root”. Pertanto alla vulnerabilità viene assegnato un livello di gravità alto (7.2 punti sulla scala CVSSv3).
Il documento descrive la vulnerabilità CVE-2024-22274 nel software VMware vCenter. Questa vulnerabilità critica permette a un attaccante remoto non autenticato di eseguire codice arbitrario sul sistema target, sfruttando una falla nell’autenticazione del servizio vSphere Web Client. La compromissione può portare al controllo completo del sistema, con gravi implicazioni per la sicurezza dell’infrastruttura IT. Si consiglia vivamente di applicare le patch di sicurezza fornite da VMware per mitigare questa minaccia e proteggere i sistemi vulnerabili.

Mitigazione
In linea con le dichiarazioni del Vendor, si consiglia di aggiornare alla versione 7.0 U3q per quanto riguarda vCenter Server 7.0 ed alla versione 8.0 U2b per quanto riguarda vCenter Server 8.0, già sanate dallo stesso nel bollettino di sicurezza VMSA-2024-0011 pubblicato nel mese di Maggio 2024.
Attualmente non è previsto alcun workaround per mitigare la minaccia.
Si consiglia inoltre di non esporre pubblicamente le interfacce di gestione dei sistemi e di adottare il principio del privilegio minimo ,quindi di esporre solo ed esclusivamente i servizi necessari.
L'articolo L’exploit POC per l’RCE di VMware vCenter Server è ora disponibile Online! proviene da il blog della sicurezza informatica.
Etiopia, il primo ministro in visita in Port Sudan
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Il primo ministro etiope Abiy Ahmed Ali oggi 9 luglio 2024, è arrivato a Port Sudan per visita ufficiale di lavoro, secondo quanto riportato dai media statali. A seguito del conflitto in Sudan , il governo
Notizie dall'Italia e dal mondo reshared this.
Etiopia e Sud Sudan, nuovo accordo per oleodotto verso Gibuti
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Etiopia e il Sud Sudan hanno recentemente stretto un accordo significativo per rafforzare la difesa e il commercio costruendo un nuovo oleodotto. L’accordo, finalizzato il 6 luglio 2024 tra
Notizie dall'Italia e dal mondo reshared this.
Sudan, i rifugiati del Tigray e i campi di accoglienza occupati da forze armate
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Sul sito dell’ AICS il 5 agosto 2022, data recuperata grazie a WebArchive perché oggi, 9 luglio 2024, in quella pagina risulta solo il titolo. “Consegnate
Notizie dall'Italia e dal mondo reshared this.
Italia e Nato, verso un ruolo strategico nel Mediterraneo. Parla Calovini
[quote]Mancano una manciata di ore all’inizio del summit annuale della Nato. Nel 75simo anniversario dell’Alleanza Atlantica, i suoi 32 capi di Stato e di governo si riuniranno a Washington per discutere di sfide presenti e prospettive future, come delineato dal segretario generale, Jens
Etiopia, seconda revisione dell’accordo di cessazione ostilità per il Tigray
L'articolo proviene dal blog di @Davide Tommasin ዳቪድ ed è stato ricondiviso sulla comunità Lemmy @Notizie dall'Italia e dal mondo
Ethiopia, oggi 9 luglio 2024, inizia la seconda revisione strategica dell’attuazione dell’accordo di Pretoria sulla cessazione delle ostilità. Secondo un
Notizie dall'Italia e dal mondo reshared this.
Developing and prioritizing a detection engineering backlog based on MITRE ATT&CK

Detection is a traditional type of cybersecurity control, along with blocking, adjustment, administrative and other controls. Whereas before 2015 teams asked themselves what it was that they were supposed to detect, as MITRE ATT&CK evolved, SOCs were presented with practically unlimited space for ideas on creating detection scenarios.
With the number of scenarios becoming virtually unlimited, another question inevitably arises: “What do we detect first?” This and the fact that SOC teams forever play the long game, having to respond with limited resources to a changing threat landscape, evolving technology and increasingly sophisticated malicious actors, makes managing efforts to develop detection logic an integral part of any modern SOC’s activities.
The problem at hand is easy to put into practical terms: the bulk of the work done by any modern SOC – with the exception of certain specialized SOC types – is detecting, and responding to, information security incidents. Detection is directly associated with preparation of certain algorithms, such as signatures, hard-coded logic, statistical anomalies, machine learning and others, that help to automate the process. The preparation consists of at least two processes: managing detection scenarios and developing detection logic. These cover the life cycle, stages of development, testing methods, go-live, standardization, and so on. These processes, like any others, require certain inputs: an idea that describes the expected outcome at least in abstract terms.
This is where the first challenges arise: thanks to MITRE ATT&CK, there are too many ideas. The number of described techniques currently exceeds 200, and most are broken down into several sub-techniques – MITRE T1098 Account Manipulation, for one, contains six sub-techniques – while SOC’s resources are limited. Besides, SOC teams likely do not have access to every possible source of data for generating detection logic, and some of those they do have access to are not integrated with the SIEM system. Some sources can help with generating only very narrowly specialized detection logic, whereas others can be used to cover most of the MITRE ATT&CK matrix. Finally, certain cases require activating extra audit settings or adding selective anti-spam filtering. Besides, not all techniques are the same: some are used in most attacks, whereas others are fairly unique and will never be seen by a particular SOC team. Thus, setting priorities is both about defining a subset of techniques that can be detected with available data and about ranking the techniques within that subset to arrive at an optimized list of detection scenarios that enables detection control considering available resources and in the original spirit of MITRE ATT&CK: discovering only some of the malicious actor’s atomic actions is enough for detecting the attack.
A slight detour. Before proceeding to specific prioritization techniques, it is worth mentioning that this article looks at options based on tools built around the MITRE ATT&CK matrix. It assesses threat relevance in general, not in relation to specific organizations or business processes. Recommendations in this article can be used as a starting point for prioritizing detection scenarios. A more mature approach must include an assessment of a landscape that consists of security threats relevant to your particular organization, an allowance for your own threat model, an up-to-date risk register, and automation and manual development capabilities. All of this requires an in-depth review, as well as liaison between various processes and roles inside your SOC. We offer more detailed maturity recommendations as part of our SOC consulting services.
MITRE Data Sources
Optimized prioritization of the backlog as it applies to the current status of monitoring can be broken down into the following stages:
- Defining available data sources and how well they are connected;
- Identifying relevant MITRE ATT&CK techniques and sub-techniques;
- Finding an optimal relation between source status and technique relevance;
- Setting priorities.
A key consideration in implementing this sequence of steps is the possibility of linking information that the SOC receives from data sources to a specific technique that can be detected with that information. In 2021, MITRE completed its ATT&CK Data Sources project, its result being a methodology for describing a data object that can be used for detecting a specific technique. The key elements for describing data objects are:
- Data Source: an easily recognizable name that defines the data object (Active Directory, application log, driver, file, process and so on);
- Data Components: possible data object actions, statuses and parameters. For example, for a file data object, data components are file created, file deleted, file modified, file accessed, file metadata, and so on.
MITRE Data Sources

Virtually every technique in the MITRE ATT&CK matrix currently contains a Detection section that lists data objects and relevant data components that can be used for creating detection logic. A total of 41 data objects have been defined at the time of publishing this article.
MITRE most relevant data components
The column on the far right in the image above (Event Logs) illustrates the possibilities of expanding the methodology to cover specific events received from real data sources. Creating a mapping like this is not one of the ATT&CK Data Sources project goals. This Event Logs example is rather intended as an illustration. On the whole, each specific SOC is expected to independently define a list of events relevant to its sources, a fairly time-consuming task.
To optimize your approach to prioritization, you can start by isolating the most frequent data components that feature in most MITRE ATT&CK techniques.
The graph below presents the up-to-date top 10 data components for MITRE ATT&CK matrix version 15.1, the latest at the time of writing this.
The most relevant data components (download)
For these data components, you can define custom sources for the most results. The following will be of help:
- Expert knowledge and overall logic. Data objects and data components are typically informative enough for the engineer or analyst working with data sources to form an initial judgment on the specific sources that can be used.
- Validation directly inside the event collection system. The engineer or analyst can review available sources and match events with data objects and data components.
- Publicly available resources on the internet, such as Sensor Mappings to ATT&CK, a project by the Center for Threat-Informed Defense, or this excellent resource on Windows events: UltimateWindowsSecurity.
That said, most sources are fairly generic and typically connected when a monitoring system is implemented. In other words, the mapping can be reduced to selecting those sources which are connected in the corporate infrastructure or easy to connect.
The result is an unranked list of integrated data sources that can be used for developing detection logic, such as:
- For Command Execution: OS logs, EDR, networked device administration logs and so on;
- For Process Creation: OS logs, EDR;
- For Network Traffic Content: WAF, proxy, DNS, VPN and so on;
- For File Modification: DLP, EDR, OS logs and so on.
However, this list is not sufficient for prioritization. You also need to consider other criteria, such as:
- The quality of source integration. Two identical data sources may be integrated with the infrastructure differently, with different logging settings, one source being located only in one network segment, and so on.
- Usefulness of MITRE ATT&CK techniques. Not all techniques are equally useful in terms of optimization. Some techniques are more specialized and aimed at detecting rare attacker actions.
- Detection of the same techniques with several different data sources (simultaneously). The more options for detecting a technique have been configured, the higher the likelihood that it will be discovered.
- Data component variability. A selected data source may be useful for detecting not only those techniques associated with the top 10 data components but others as well. For example, an OS log can be used for detecting both Process Creation components and User Account Authentication components, a type not mentioned on the graph.
Prioritizing with DeTT&CT and ATT&CK Navigator
Now that we have an initial list of data sources available for creating detection logic, we can proceed to scoring and prioritization. You can automate some of this work with the help of DeTT&CT, a tool created by developers unaffiliated with MITRE to help SOCs with using MITRE ATT&CK for scoring and comparing the quality of data sources, coverage and detection scope according to MITRE ATT&CK techniques. The tool is available under the GPL-3.0 license.
DETT&CT supports an expanded list of data sources as compared to the MITRE model. This list is implemented by design and you do not need to redefine the MITRE matrix itself. The expanded model includes several data components, which are parts of MITRE’s Network Traffic component, such as Web, Email, Internal DNS, and DHCP.
You can install DETT&CT with the help of two commands: git clone and pip install -r. This gives you access to DETT&CT Editor: a web interface for describing data sources, and DETT&CT CLI for automated analysis of prepared input data that can help with prioritizing detection logic and more.
The first step in identifying relevant data sources is describing these. Go to Data Sources in DETT&CT Editor, click New file and fill out the fields:
- Domain: the version of the MITRE ATT&CK matrix to use (enterprise, mobile or ICS).
- This field is not used in analytics; it is intended for distinguishing between files with the description of sources.
- Systems: selection of platforms that any given data source belongs to. This helps to both separate platforms, such as Windows and Linux, and specify several platforms within one system. Going forward, keep in mind that a data source is assigned to a system, not a platform. In other words, if a source collects data from both Windows and Linux, you can leave one system with two platforms, but if one source collects data from Windows only, and another, from Linux only, you need to create two systems: one for Windows and one for Linux.
After filling out the general sections, you can proceed to analyzing data sources and mapping to the MITRE Data Sources. Click Add Data Source for each MITRE data object and fill out the relevant fields. Follow the link above for a detailed description of all fields and example content on the project page. We will focus on the most interesting field: Data quality. It describes the quality of data source integration as determined according to five criteria:
- Device completeness. Defines infrastructure coverage by the source, such as various versions of Windows or subnet segments, and so on.
- Data field completeness. Defines the completeness of data in events from the source. For example, information about Process Creation may be considered incomplete if we see that a process was created, but not the details of the parent process, or for Command Execution, we see the command but not the arguments, and so on.
- Defines the presence of a delay between the event happening and being added to a SIEM system or another detection system.
- Defines the extent to which the names of the data fields in an event from this source are consistent with standard naming.
- Compares the period for which data from the source is available for detection with the data retention policy defined for the source. For instance, data from a certain source is available for one month, whereas the policy or regulatory requirements define the retention period as one year.
A detailed description of the scoring system for filling out this field is available in the project description.
It is worth mentioning that at this step, you can describe more than just the top 10 data components that cover the majority of the MITRE ATT&CK techniques. Some sources can provide extra information: in addition to Process Creation, Windows Security Event Log provides data for User Account Authentication. This extension will help to analyze the matrix without limitations in the future.
After describing all the sources on the list defined earlier, you can proceed to analyze these with reference to the MITRE ATT&CK matrix.
The first and most trivial analytical report identifies the MITRE ATT&CK techniques that can be discovered with available data sources one way or another. This report is generated with the help of a configuration file with a description of data sources and DETT&CT CLI, which outputs a JSON file with MITRE ATT&CK technique coverage. You can use the following command for this:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> -l
The resulting JSON is ready to be used with the MITRE ATT&CK matrix visualization tool, MITRE ATT&CK Navigator. See below for an example.
MITRE ATT&CK coverage with available data sources

This gives a literal answer to the question of what techniques the SOC can discover with the set of data sources that it has. The numbers in the bottom right-hand corner of some of the cells reflect sub-technique coverage by the data sources, and the colors, how many different sources can be used to detect the technique. The darker the color, the greater the number of sources.
DETT&CT CLI can also generate an XLSX file that you can conveniently use as the integration of existing sources evolves, a parallel task that is part of the data source management process. You can use the following command to generate the file:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> -e
The next analytical report we are interested in assesses the SOC’s capabilities in terms of detecting MITRE ATT&CK techniques and sub-techniques while considering the scoring of integrated source quality as done previously. You can generate the report by running the following command:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> --yaml
This generates a DETT&CT configuration file that both contains matrix coverage information and considers the quality of the data sources, providing a deeper insight into the level of visibility for each technique. The report can help to identify the techniques for which the SOC in its current shape can achieve the best results in terms of completeness of detection and coverage of the infrastructure.
This information too can be visualized with MITRE ATT&CK Navigator. You can use the following DETT&CT CLI command for this:
python dettect.py v -ft output/<techniques-administration-file.yaml> -l
See below for an example.
MITRE ATT&CK coverage with available sources considering their quality

For each technique, the score is calculated as an average of all relevant data source scores. For each data source, it is calculated from specific parameters. The following parameters have increased weight:
- Device completeness;
- Data field completeness;
- Retention.
To set up the scoring model, you need to modify the project source code.
It is worth mentioning that the scoring system presented by the developers of DETT&CT tends to be fairly subjective in some cases, for example:
- You may have one data source out of the three mentioned in connection with the specific technique. However, in some cases, one data source may not be enough even to detect the technique on a minimal level.
- In other cases, the reverse may be true, with one data source giving exhaustive information for complete detection of the technique.
- Detection may be based on a data source that is not currently mentioned in the MITRE ATT&CK Data Sources or Detections for that particular technique.
In these cases, the DETT&CT configuration file techniques-administration-file.yaml can be adjusted manually.
Now that the available data sources and the quality of their integration have been associated with the MITRE ATT&CK matrix, the last step is ranking the available techniques. You can use the Procedure Examples section in the matrix, which defines the groups that use a specific technique or sub-technique in their attacks. You can use the following DETT&CT command to run the operation for the entire MITRE ATT&CK matrix:
python dettect.py g
In the interests of prioritization, we can merge the two datasets (technique feasibility considering available data sources and their quality, and the most frequently used MITRE ATT&CK techniques):
python dettect.py g -p PLATFORM -o output/<techniques-administration-
file.yaml> -t visibility
The result is a JSON file containing techniques that the SOC can work with and their description, which includes the following:
- Detection ability scoring;
- Known attack frequency scoring.
See the image below for an example.
Technique frequency and detection ability

As you can see in the image, some of the techniques are colored shades of red, which means they have been used in attacks (according to MITRE), but the SOC has no ability to detect them. Other techniques are colored shades of blue, which means the SOC can detect them, but MITRE has no data on these techniques having been used in any attacks. Finally, the techniques colored shades of orange are those which groups known to MITRE have used and the SOC has the ability to detect.
It is worth mentioning that groups, attacks and software used in attacks, which are linked to a specific technique, represent retrospective data collected throughout the period that the matrix has existed. In some cases, this may result in increased priority for techniques that were relevant for attacks, say, from 2015 through 2020, which is not really relevant for 2024.
However, isolating a subset of techniques ever used in attacks produces more meaningful results than simple enumeration. You can further rank the resulting subset in the following ways:
- By using the MITRE ATT&CK matrix in the form of an Excel table. Each object (Software, Campaigns, Groups) contains the property Created (date when the object was created) that you can rely on when isolating the most relevant objects and then use the resulting list of relevant objects to generate an overlap as described above:
python dettect.py g -g sample-data/groups.yaml -p PLATFORM -o
output/<techniques-administration-file.yaml> -t visibility - By using the TOP ATT&CK TECHNIQUES project created by MITRE Engenuity.
TOP ATT&CK TECHNIQUES was aimed at developing a tool for ranking MITRE ATT&CK techniques and accepts similar inputs to DETT&CT. The tool produces a definition of 10 most relevant MITRE ATT&CK techniques for detecting with available monitoring capabilities in various areas of the corporate infrastructure: network communications, processes, the file system, cloud-based solutions and hardware. The project also considers the following criteria:
- Choke Points, or specialized techniques where other techniques converge or diverge. Examples of these include T1047 WMI, as it helps to implement a number of other WMI techniques, or T1059 Command and Scripting Interpreter, as many other techniques rely on a command-line interface or other shells, such as PowerShell, Bash and others. Detecting this technique will likely lead to discovering a broad spectrum of attacks.
- Prevalence: technique frequency over time.
MITRE ATT&CK technique ranking methodology in TOP ATT&CK TECHNIQUES

Note, however, that the project is based on MITRE ATT&CK v.10 and is not supported.
Finalizing priorities
By completing the steps above, the SOC team obtains a subset of MITRE ATT&CK techniques that feature to this or that extent in known attacks and can be detected with available data sources, with an allowance for the way these are configured in the infrastructure. Unfortunately, DETT&CT does not offer any way of creating a convenient XLSX file with an overlap between techniques used in attacks and those that the SOC can detect. However, we have a JSON file that can be used to generate the overlap with the help of MITRE ATT&CK Navigator. So, all you need to do for prioritization is to parse the JSON, say, with the help of Python. The final prioritization conditions may be as follows:
- Priority 1 (critical): Visibility_score >= 3 and Attacker_score >= 75. From an applied perspective, this isolates MITRE ATT&CK techniques that most frequently feature in attacks and that the SOC requires minimal or no preparation to detect.
- Priority 2 (high): (Visibility_score < 3 and Visibility_score >= 1) and Attacker_score >= 75. These are MITRE ATT&CK techniques that most frequently feature in attacks and that the SOC is capable of detecting. However, some work on logging may be required, or monitoring coverage may not be good enough.
- Priority 3 (medium): Visibility_score >= 3 and Attacker_score < 75. These are MITRE ATT&CK techniques with medium to low frequency that the SOC requires minimal or no preparation to detect.
- Priority 4 (low): (Visibility_score < 3 and Visibility_score >= 1) and Attacker_score < 75. These are all other MITRE ATT&CK techniques that feature in attacks and the SOC has the capability to detect.
As a result, the SOC obtains a list of MITRE ATT&CK techniques ranked into four groups and mapped to its capabilities and global statistics on malicious actors’ actions in attacks. The list is optimized in terms of the cost to write detection logic and can be used as a prioritized development backlog.
Prioritization extension and parallel tasks
In conclusion, we would like to highlight the key assumptions and recommendations for using the suggested prioritization method.
- As mentioned above, it is not fully appropriate to use the MITRE ATT&CK statistics on the frequency of techniques in attacks. For more mature prioritization, the SOC team must rely on relevant threat data. This requires defining a threat landscape based on analysis of threat data, mapping applicable threats to specific devices and systems, and isolating the most relevant techniques that may be used against a specific system in the specific corporate environment. An approach like this calls for in-depth analysis of all SOC activities and links between processes. Thus, when generating a scenario library for a customer as part of our consulting services, we leverage Kaspersky Threat Intelligence data on threats relevant to the organization, Managed Detection and Response statistics on detected incidents, and information about techniques that we obtained while investigating real-life incidents and analyzing digital evidence as part of Incident Response service.
- The suggested method relies on SOC capabilities and essential MITRE ATT&CK analytics. That said, the method is optimized for effort reduction and helps to start developing relevant detection logic immediately. This makes it suitable for small-scale SOCs that consist of a SIEM administrator or analyst. In addition to this, the SOC builds what is essentially a detection functionality roadmap, which can be used for demonstrating the process, defining KPIs and justifying a need for expanding the team.
Lastly, we introduce several points regarding the possibilities for improving the approach described herein and parallel tasks that can be done with tools described in this article.
You can use the following to further improve the prioritization process.
- Grouping by detection. On a basic level, there are two groups: network detection or detection on a device. Considering the characteristics of the infrastructure and data sources in creating detection logic for different groups helps to avoid a bias and ensure a more complete coverage of the infrastructure.
- Grouping by attack stage. Detection at the stage of Initial Access requires more effort, but it leaves more time to respond than detection at the Exfiltration stage.
- Criticality coefficient. Certain techniques, such as all those associated with vulnerability exploitation or suspicious PowerShell commands, cannot be fully covered. If this is the case, the criticality level can be used as an additional criterion.
- Granular approach when describing source quality. As mentioned earlier, DETT&CT helps with creating quality descriptions of available data sources, but it lacks exception functionality. Sometimes, a source is not required for the entire infrastructure, or there is more than one data source providing information for similar systems. In that case, a more granular approach that relies on specific systems, subnets or devices can help to make the assessment more relevant. However, an approach like that calls for liaison with internal teams responsible for configuration changes and device inventory, who will have to at least provide information about the business criticality of assets.
Besides improving the prioritization method, the tools suggested can be used for completing a number of parallel tasks that help the SOC to evolve.
- Expanding the list of sources. As shown above, the coverage of the MITRE ATT&CK matrix requires diverse data sources. By mapping existing sources to techniques, you can identify missing logs and create a roadmap for connecting or introducing these sources.
- Improving the quality of sources. Scoring the quality of data sources can help create a roadmap for improving existing sources, for example in terms of infrastructure coverage, normalization or data retention.
- Detection tracking. DETT&CT offers, among other things, a detection logic scoring feature, which you can use to build a detection scenario revision process.
securelist.com/detection-engin…




Attacco “Adversary-in-the-Middle” su Microsoft 365
Nel luglio 2024, Field Effect ha scoperto una campagna di attacchi “Adversary-in-the-Middle” (AiTM) rivolta a Microsoft 365 (M365). Questo tipo di attacco compromette le email aziendali (BEC) utilizzando tecniche avanzate per intercettare e dirottare le credenziali degli utenti durante il processo di autenticazione.
Metodo di Attacco
- Osservazione Iniziale: L’analisi ha rivelato l’uso sospetto della stringa user agent ‘axios/1.7.2’, associata a tentativi di accesso da ISP noti per attività malevole.
- Strumento Utilizzato – Axios: Axios è un client HTTP legittimo per browser e node.js, sfruttato dagli attaccanti per imitare le richieste di login degli utenti legittimi. Axios permette di intercettare, trasformare e cancellare richieste e risposte HTTP, facilitando il furto delle credenziali.
- Origine degli Attacchi: Molte richieste provenivano da Hostinger International Limited e Global Internet Solutions LLC, spesso utilizzati da attori malevoli russi.
- Compromissione MFA: Gli attaccanti hanno superato l’autenticazione a più fattori (MFA), suggerendo l’accesso non solo alle password ma anche ai codici MFA degli utenti. Questo è stato possibile tramite l’intercettazione dei token di autenticazione durante il processo di login.
Catena di Attacco
- Phishing: Le vittime ricevevano email di phishing che le inducevano a visitare domini malevoli. Questi domini presentavano pagine di login M365 fasulle costruite con Axios, progettate per apparire autentiche.
- Raccolta delle Credenziali: Quando l’utente inseriva le proprie credenziali sulla pagina fasulla, Axios le intercettava e le utilizzava per autenticarsi sulla vera pagina M365 in tempo reale.
- Dirottamento delle Sessioni: Gli attaccanti utilizzavano le credenziali raccolte e i token di sessione per accedere agli account delle vittime, aggirando l’MFA. Questo permetteva loro di accedere alle email e ai dati sensibili dell’azienda.
Tecniche Specifiche Utilizzate
- Imitazione delle Richieste HTTP: Gli attaccanti utilizzavano Axios per creare richieste HTTP che imitavano quelle degli utenti legittimi, consentendo loro di intercettare le credenziali senza destare sospetti.
- Intercettazione in Tempo Reale: Axios permetteva agli attaccanti di intercettare le credenziali in tempo reale, facendole passare dalla pagina fasulla al sito legittimo di M365. Questo includeva anche la cattura dei token MFA, permettendo loro di autenticarsi come se fossero l’utente legittimo.
- Utilizzo di ISP Malevoli: Gli attaccanti sfruttavano ISP noti per attività malevole per mascherare la loro origine e rendere più difficile l’identificazione delle attività sospette.
- Phishing Avanzato: Le email di phishing erano progettate per sembrare comunicazioni legittime da M365, aumentando la probabilità che le vittime inserissero le proprie credenziali senza sospetti.

Indicatori di Compromissione (IoC)
- User Agent Strings:
- axios/1.7.2
- axios/1.7.1
- axios/1.6.8
- BAV2ROPC
- Fornitori di Hosting:
- Hostinger International Limited (AS47583)
- Global Internet Solutions LLC (AS207713)
- Domini di Phishing:
- lsj.logentr[.]com
- okhyg.unsegin[.]com
- ldn3.p9j32[.]com
- Indirizzi IP:
- 141.98.233[.]86
- 154.56.56[.]200
- e molti altri elencati nel rapporto.
Mitigazione e Difesa
- Monitoraggio dei Log: Ricercare tentativi di login con gli IoC sopra elencati.
- Rotazione delle Credenziali: Uscire dai sistemi compromessi e cambiare le credenziali.
- Implementazione MFA: Assicurarsi che MFA sia attivo su tutti gli account e monitorare le anomalie.
- Formazione sul Phishing: Educare i dipendenti a riconoscere email di phishing e a non inserire credenziali in siti sospetti.
Conclusione
Questa campagna di attacchi AiTM su M365 dimostra la crescente sofisticazione delle tecniche di BEC. La difesa richiede un approccio integrato che includa il monitoraggio continuo delle attività sospette e l’educazione degli utenti sulle minacce di phishing. Implementare rigorose misure di sicurezza e rimanere vigili sono essenziali per proteggere le infrastrutture aziendali da tali minacce.
L'articolo Attacco “Adversary-in-the-Middle” su Microsoft 365 proviene da il blog della sicurezza informatica.

Citrix Netscaler ADC e Gateway afflitti da una grave falla di DOS e Open Redirect
NetScaler ADC (precedentemente Citrix ADC) e il NetScaler Gateway (precedentemente Citrix Gateway) sono soluzioni consolidate per la distribuzione di applicazioni e l’accesso sicuro alle risorse aziendali. Questi dispositivi sono ampiamente utilizzati per migliorare le prestazioni delle applicazioni e garantire un accesso controllato e sicuro ai dati sensibili.
Sono state identificate due vulnerabilità critiche in NetScaler ADC e NetScaler Gateway. Le Versioni Interessate Le seguenti versioni supportate di NetScaler ADC e NetScaler Gateway sono vulnerabili:
- NetScaler ADC e NetScaler Gateway 14.1 prima della versione 14.1-25.53
- NetScaler ADC e NetScaler Gateway 13.1 prima della versione 13.1-53.17
- NetScaler ADC e NetScaler Gateway 13.0 prima della versione 13.0-92.31
- NetScaler ADC 13.1-FIPS prima della versione 13.1-37.183
- NetScaler ADC 12.1-FIPS prima della versione 12.1-55.304
- NetScaler ADC 12.1-NDcPP prima della versione 12.1-55.304
Nota: La versione 12.1 di NetScaler ADC e NetScaler Gateway è ora End Of Life (EOL) e pertanto vulnerabile. Si consiglia ai clienti di aggiornare i loro dispositivi alle versioni supportate.
Sommario delle Vulnerabilità NetScaler ADC e NetScaler Gateway presentano le seguenti vulnerabilità:
- CVE-2024-5491: Vulnerabilità di Denial of Service che colpisce gli appliance ADC o Gateway configurati con SNMP (NSIP/SNIP).
- CWE: Improrer restriction delle operazioni all’interno dei limiti di un buffer di memoria
- Punteggio Base CVSS v4.0: 7.1
- CVE-2024-5492: Vulnerabilità di reindirizzamento aperto che consente a un attaccante remoto e non autenticato di reindirizzare gli utenti verso siti web arbitrari.
- CWE: Reindirizzamento URL verso siti non attendibili (‘Open Redirect’)
- Punteggio Base CVSS v4.0: 5.1
Azioni Consigliate per i Clienti Cloud Software Group consiglia vivamente ai clienti interessati di NetScaler ADC e NetScaler Gateway di installare immediatamente le versioni aggiornate pertinenti:
- NetScaler ADC e NetScaler Gateway versione 14.1-25.53 e successive
- NetScaler ADC e NetScaler Gateway versione 13.1-53.17 e successive di 13.1
- NetScaler ADC e NetScaler Gateway versione 13.0-92.31 e successive di 13.0
- NetScaler ADC versione 13.1-FIPS 13.1-37.183 e successive
- NetScaler ADC versione 12.1-FIPS 12.1-55.304 e successive
- NetScaler ADC versione 12.1-NDcPP 12.1-55.304 e successive
Cloud Software Group desidera esprimere gratitudine nei confronti di Nanyu Zhong di VARAS@IIE e di Mauro Dini per il loro prezioso contributo nel garantire la sicurezza dei clienti Citrix.
Nel frattempo, Citrix sta informando attivamente i propri clienti e partner riguardo a queste importanti questioni di sicurezza tramite un bollettino pubblicato sul Citrix Knowledge Center, accessibile al seguente indirizzo: support.citrix.com/securitybul….
L'articolo Citrix Netscaler ADC e Gateway afflitti da una grave falla di DOS e Open Redirect proviene da il blog della sicurezza informatica.
Questa è la seconda #estate che, anziché stare in #spiaggia con un bikini o un intero sportivo (leggi: attillato), preferisco combinare il top a triangolo del bikini con un paio di bermudoni.
Combo comodissima e a prova di "fuoriuscite" dalle mutandine striminzite del bikini.
Diversi conoscenti si sono permessi di disapprovare, perché se sei anche solo vagamente magra dovresti fare vedere la mercanzia.
Ma io non sono in vetrina, sono in spiaggia! La mia priorità non è né essere figa, né venire guardata. È stare stravaccata comoda e rilassarmi.
Paolo Monella reshared this.


rag. Gustavino Bevilacqua reshared this.
Michele Ainis – Capocrazia
L'articolo Michele Ainis – Capocrazia proviene da Fondazione Luigi Einaudi.
Politica interna, europea e internazionale reshared this.
Samsung Killed The Online Service, This 20 Dollar Dongle Brings It Back

Around 2010 or so, Samsung cameras came with an online service: Social Network Services. It enabled pictures to be unloaded wirelessly to social media with minimum hassle, which back then wasn’t quite as easily accomplished as it is today. Sadly they shuttered the service in 2021, leaving that generation of cameras, like so many connected devices, orphaned. Now along comes [Ge0rG] with a replacement, replicating the API on a $20 LTE dongle.
The dongle in question is one we featured a couple of years ago, packing a Linux-capable computer of similar power to a Raspberry Pi Zero alongside its cell modem. The camera can connect to the device, and a photo can be sent in a Mastodon post. It’s something of a modern version of the original, but for owners of the affected cameras it’s a useful recovery of a lost service.
It’s surprising in a way that we’ve not heard more of these dongles, as they do represent a useful opportunity. That we haven’t should be seen as a measure of the success of the Raspberry Pi and other boards like it, just as it’s no longer worth hacking old routers for Linux hardware projects, so there’s less of a need to do the same here.
CODE Talks: A More Competitive Europe Starts with Open Digital Ecosystems [Advocacy Lab Content]
On 22 May, the Coalition for Open Digital Ecosystems (CODE) hosted "CODE Talks: A More Competitive Europe Starts with Open Digital Ecosystems."
Xandr, azienda di tecnologia pubblicitaria di proprietà di Microsoft, accusata di violazioni della privacy nell'UE
Il broker pubblicitario Xandr (un'affiliata di Microsoft) raccoglie e condivide i dati personali di milioni di europei per ottenere pubblicità mirate e dettagliate. Ciò consente a Xandr di mettere all'asta spazi pubblicitari a migliaia di inserzionisti. Ma: anche se alla fine agli utenti viene mostrato un solo annuncio, tutti gli inserzionisti ricevono i loro dati. Questi possono includere dettagli personali riguardanti la salute, la sessualità o le opinioni politiche degli utenti. Inoltre, nonostante venda il suo servizio come "mirato", l'azienda detiene informazioni piuttosto casuali: a quanto pare il denunciante è sia uomo che donna, impiegato e disoccupato. Questo potrebbe permettere a Xandr di vendere spazi pubblicitari a più aziende che pensano di rivolgersi a un gruppo specifico. Alcuni dettagli sono ancora sconosciuti, poiché Xandr ha anche rifiutato di soddisfare la richiesta di accesso e cancellazione del denunciante. noyb ha ora presentato un reclamo GDPR.
Il denunciante sarebbe un individuo italiano non identificato. Il reclamo è stato presentato ai sensi del Regolamento generale sulla protezione dei dati (GDPR) dell'Unione Europea, il che significa che, se prevale, potrebbe portare a multe fino al 4% del fatturato annuo globale di Microsoft, l'entità madre di Xandr.
noyb.eu/it/microsofts-xandr-gr…

Xandr di Microsoft concede i diritti GDPR a un tasso dello 0%
noyb ha presentato un reclamo GDPR per questioni di trasparenza, diritto di accesso e utilizzo di informazioni inesatte sugli utentinoyb.eu
reshared this
IRAN. Pezeshkian ha poco potere ma sa come parlare alla popolazione
@Notizie dall'Italia e dal mondo
Pezeshkian è diventato presidente perché ha compreso che la riconciliazione con la parte silenziosa della società è un passo indispensabile per realizzare gli obiettivi del suo possibile governo
L'articolo IRAN. Pezeshkian ha poco potere ma sa come parlare alla
Notizie dall'Italia e dal mondo reshared this.
Lifting Zmiy: il gruppo che colpisce i sistemi SCADA e controlla gli ascensori
Gli esperti del centro di ricerca sulle minacce informatiche Solar 4RAYS del Solar Group hanno parlato di una serie di attacchi da parte del gruppo di hacker filogovernativo Lifting Zmiy, mirati ad agenzie governative russe e aziende private. Gli aggressori hanno posizionato i loro server di controllo su apparecchiature hackerate che fanno parte dei sistemi SCADA utilizzati, ad esempio, per controllare gli ascensori.
Gli esperti si sono imbattuti per la prima volta in questo gruppo alla fine del 2023, quando uno dei canali Telegram filo-ucraini ha pubblicato informazioni sull’hacking di un’organizzazione statale russa. Gli esperti hanno partecipato alle indagini su questo attacco contro un anonimo appaltatore IT di un’organizzazione governativa russa e nei sei mesi successivi hanno studiato altri tre incidenti, anch’essi associati alle attività di Lifting Zmiy.
Lo schema degli hacker si ripete di attacco in attacco: la penetrazione iniziale è stata effettuata indovinando le password, poi gli aggressori hanno preso piede nel sistema e hanno sviluppato l’attacco principalmente utilizzando vari strumenti open source, tra cui:
- Reverse SSH – shell inversa per la gestione dei sistemi infetti e la fornitura di payload aggiuntivi;
- Backdoor SSH – per intercettare le password per le sessioni di accesso remoto;
- GSocket – un’utilità per creare una connessione remota a un sistema attaccato, aggirando alcune soluzioni di sicurezza.

L’utilizzo di questo software accomuna tutti gli attacchi Lifting Zmiy studiati, nonché l’ubicazione dei server di controllo: gli aggressori li hanno posizionati sui controller del produttore russo Tekon-Avtomatika, che servono al controllo e all’invio, comprese le apparecchiature degli ascensori.
In totale sono stati scoperti più di una dozzina di dispositivi infetti e al momento della pubblicazione dello studio otto di essi erano ancora in uno stato di compromissione. Il firmware per questi dispositivi è universale e funziona sul kernel Linux che, insieme alla possibilità di scrivere plugin LUA personalizzati, offre agli aggressori ampie opportunità di sfruttamento.
“Crediamo che durante l’attacco Lifting, Zmiy abbia approfittato delle informazioni pubblicate pubblicamente sulle imperfezioni di sicurezza dei dispositivi Tekon-Avtomatika e abbia sfruttato le vulnerabilità esistenti del sistema per ospitare su di essi una parte del server C2, che è stata utilizzata in ulteriori attacchi contro i loro obiettivi principali, ” scrivono gli esperti.
I ricercatori scrivono che l’obiettivo principale di Lifting Zmiy sono i dati riservati delle organizzazioni attaccate. E dopo aver raggiunto l’obiettivo, o se è impossibile penetrare più in profondità nell’infrastruttura dell’organizzazione vittima, gli hacker intraprendono azioni distruttive: cancellano i dati nei sistemi a loro disposizione.
È interessante notare che nella maggior parte degli incidenti il gruppo si è collegato a sistemi infetti da indirizzi IP di diversi provider di hosting, ma nell’attacco a un’azienda informatica, su cui gli esperti hanno indagato nell’inverno del 2024, la loro tattica è cambiata. Hanno utilizzato indirizzi IP di un pool di proprietà del provider Starlink. Secondo i dati pubblici, questi indirizzi IP sono utilizzati dai terminali Starlink che operano in Ucraina.
In generale, sulla base di una serie di indizi, gli esperti di Solar 4RAYS ritengono che il gruppo Lifting Zmiy sia originario dell’Europa dell’Est.
“Al momento della nostra ricerca, Lifting Zmiy è ancora molto attiva: utilizzando i nostri sistemi troviamo costantemente nuovi elementi della loro infrastruttura. Pertanto, raccomandiamo alle organizzazioni che utilizzano sistemi SCADA simili a quelli attaccati dagli aggressori di prestare la massima attenzione nel garantire la propria sicurezza informatica. Inoltre, in tutti i casi esaminati, l’accesso all’infrastruttura è stato ottenuto tramite la consueta attacco di forza bruta nelle password, quindi le aziende dovrebbero verificare ancora una volta l’affidabilità delle loro politiche relative alle password e, come minimo, introdurre l’autenticazione a due fattori”, commenta Dmitry. Marichev, un esperto del centro di ricerca sulle minacce informatiche Solar 4RAYS.
L'articolo Lifting Zmiy: il gruppo che colpisce i sistemi SCADA e controlla gli ascensori proviene da il blog della sicurezza informatica.
Making EV Motors, And Breaking Up with Rare Earth Elements

Rare earth elements are used to produce magnets with very high strength that also strongly resist demagnetization, their performance is key to modern motors such as those in electric vehicles (EVs). The stronger the magnets, the lighter and more efficient a motor can be. So what exactly does it take to break up with rare earths?
Rare earth elements (REEs) are actually abundant in the Earth’s crust, technically speaking. The problem is they are found in very low concentrations, and inconveniently mixed with other elements when found. Huge amounts of ore are required to extract useful quantities, which requires substantial industrial processing. The processes involved are ecologically harmful and result in large amounts of toxic waste.
Moving away from rare earth magnets in EV motors would bring a lot of benefits, but poses challenges. There are two basic approaches: optimize a motor for non-rare-earth magnets (such as iron nitrides), or do away with permanent magnets entirely in favor of electromagnets (pictured above). There are significant engineering challenges to both approaches, and it’s difficult to say which will be best in the end. But research and prototypes are making it increasingly clear that effective REE-free motors are perfectly feasible. Breaking up with REEs and their toxic heritage would be much easier when their main benefit — technological performance — gets taken off the table as a unique advantage.