 - Collegamento all'originale")
#Scuola, aumenti e arretrati in arrivo per docenti e ATA.
Qui tutti i dettagli ➡️mim.gov.

Ministero dell'Istruzione
#Scuola, aumenti e arretrati in arrivo per docenti e ATA. Qui tutti i dettagli ➡️https://www.mim.gov.Telegram
Assessing SIEM effectiveness

A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
Methodology for assessing SIEM effectiveness
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
- Composition and scope of connected data sources
- Coverage of data sources
- Data flows from existing sources
- Correctness of data normalization
- Detection logic operability
- Detection logic accuracy
- Detection logic coverage
- Use of contextual data
- SIEM technical integration into SOC processes
- SOC analysts’ handling of alerts in the SIEM
- Forwarding of alerts, security event data, and incident information to other systems
- Deployment architecture and documentation
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
- Issues with detection logic due to incorrect data normalization. A correlation rule with the condition
deviceCustomString1 not contains <string>triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts. - When analyzing coverage for a specific source type, we discovered that the SIEM was only monitoring 5% of all such sources deployed in the infrastructure. However, extending that coverage would increase system load and storage requirements. Therefore, besides connecting additional sources, it would be necessary to scale resources for specific modules (storage, collectors, or the correlator).
The effectiveness assessment consists of several stages:
- Collect and analyze documentation, if available. This allows assessing SIEM objectives, implementation settings (ideally, the deployment settings at the time of the assessment), associated processes, and so on.
- Interview system engineers, analysts, and administrators. This allows assessing current tasks and the most pressing issues, as well as determining exactly how the SIEM is being operated. Interviews are typically broken down into two phases: an introductory interview, conducted at project start to gather general information, and a follow-up interview, conducted mid-project to discuss questions arising from the analysis of previously collected data.
- Gather information within the SIEM and then analyze it. This is the most extensive part of the assessment, during which Kaspersky experts are granted read-only access to the system or a part of it to collect factual data on its configuration, detection logic, data flows, and so on.
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
Issues arising from SIEM operations
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
- Performance issues, meaning operational errors in various system components. These problems are typically resolved by technical support, but to prevent them, it is worth periodically checking system health status.
- Efficiency issues – when the system functions normally but seemingly adds little value or is not used to its full potential. This is usually due to the customer using the system capabilities in a limited way, incorrectly, or not as intended by the developer.
- Detection issues – when the SIEM is operational and continuously evolving according to defined processes and approaches, but alerts are mostly false positives, and the system misses incidents. For the most part, these problems are related to the approach taken in developing detection logic.
Key observations from the assessment
Event source inventory
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
- High Priority – sources associated with:
- Remote access provision
- External services accessible from the internet
- External perimeter
- Endpoint operating systems
- Information security tools
- Medium Priority – sources associated with:
- Remote access management within the perimeter
- Internal network communication
- Infrastructure availability
- Virtualization and cloud solutions
- Low Priority – sources associated with:
- Business applications
- Internal IT services
- Applications used by various specialized teams (HR, Development, PR, IT, and so on)
Monitoring data flow from sources
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
- Checking collector health. Find the status of collectors (see the support website for the steps to do this in Kaspersky SIEM) and identify those with a status of
Offline,Stopped,Disabled, and so on. - Checking the event flow. In Kaspersky SIEM, this can be done by gathering statistics using the following query (counting the number of events received from each collector over a specific time period):
SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Event source coverage
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM [code]eventsGROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)[/code]SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM [code]eventsGROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)[/code]
We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Retaining raw data
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
Normalization
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
- The event flow is not being normalized at all.
- Events are only partially normalized – this is particularly relevant for custom, non-out-of-the-box normalizers.
- The normalizer being used only parses headers, such as
syslog_headers, placing the entire event body into a single field, this field most often beingMessage. - An outdated default normalizer is being used.
How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
- First, check which normalizers supplied with the SIEM the organization uses and whether their versions are up to date. In our assessments, we frequently encounter auditd events being normalized by the outdated normalizer,
Linux audit and iptables syslog v2for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source. - Execute the query:
SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Detection logic coverage
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
- The name of the detection logic. With a standardized approach to naming correlation rules, the name can indicate the associated source or at least provide a brief description of what it detects.
- The use of fields within the rules, such as
DeviceVendor,DeviceProduct(another argument for including these fields in the normalizer),Name,DeviceAction,DeviceEventCategory,DeviceEventClassID, and others. These can help identify the actual source.
Excessive alerts generated by the detection logic
One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
Lack of integration with indicators of compromise
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
- At the data source level. Some sources, such as NGFWs, add this information to events involving relevant objects.
- At the SIEM native functionality level. For example, Kaspersky SIEM integrates with CyberTrace indicators, which add object reputation information at the moment of processing an event from a source.
- At the detection logic level. Information about IoCs is stored in various active lists, and correlation rules match objects against these to enrich the event.
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
The SIEM is not kept up to date
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
Other issues with SIEM implementation and operation
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
- Mismatch between license capacity and actual SIEM load. The problem is almost always the absence of events from sources, rather than an incorrect initial assessment of the organization’s needs.
- Lack of user rights management within the system (for example, every user is assigned the administrator role).
- Poor organization of customizable SIEM resources (rules, normalizers, filters, and so on). Examples include chaotic naming conventions, non-optimal grouping, and obsolete or test content intermixed with active content. We have encountered confusing resource names like
[dev] test_Add user to admin group_final2. - Use of out-of-the-box resources without adaptation to the organization’s infrastructure. To maximize a SIEM’s value, it is essential at a minimum to populate exception lists and specify infrastructure parameters: lists of administrators and critical services and hosts.
- Disabled native integrations with external systems, such as LDAP, DNS, and GeoIP.
Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
Conclusion
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.
Keebin’ with Kristina: the One With the Ultimate Portable Split

What do you look for in a travel keyboard? For me, it has to be split, though this condition most immediately demands a carrying solution of some kind. Wirelessness I can take or leave, so it’s nice to have both options available. And of course, bonus points if it looks so good that people interrupt me to ask questions.

You’ll see a couple of really neat features, like swing-out tenting feet, a trackpoint, rotary encoders, and the best part of all — a carrying case that doubles as a laptop stand. Sweet!
Eight years in the making, this is the fifth in a series, thus the name: the P stands for Portability; the S for Split. [kleshwong] believes that 36 keys is just right, as long as you have what you need on various layers.
So, do what you can in the like/share/subscribe realm so we can all see the GitHub come to pass, would you? Here’s the spot to watch, and you can enjoy looking through the previous versions while you wait with your forks and stars.
youtube.com/embed/DrDmi9TS-7Q?…
Via reddit
Loongcat40 Has Custom OLED Art
I love me a monoblock split, and I’m speaking to you from one now. They’re split, but you can just toss them across the desk when it’s time to say, eat dinner or carve pink erasers with linoleum tools, and they stay perfectly split and aligned for when you want to pull them back into service.

In between the halves you’ll find a 2.08″ SH1122 OLED display with lovely artwork by [suh_ga]. Yes, that art is baked into the firmware, free of charge.
Loongcat40 is powered by a Raspi Pico and qualifies as a 40%. The custom case is gasket-mounted and 3D-printed.
[Christian Lo] aka [sporewoh] is no stranger to the DIY keyboard game. You may recognize that name as the builder of some very tiny keyboards, so the Loongcat40 is actually kind of huge by comparison.
Via reddit
The Centerfold: WIP Goes with the Flow

Via reddit
Do you rock a sweet set of peripherals on a screamin’ desk pad? Send me a picture along with your handle and all the gory details, and you could be featured here!
Historical Clackers: the Double-Index Pettypet Typewriter
Perhaps the first thing you will notice about the Pettypet after the arresting red color is the matching pair of finger cups. More on this in a minute.
Information is minimal according to The Antikey Chop, and they have collected all that is factual and otherwise about the Pettypet. It debuted in 1930, and was presumably whisked from the world stage the same year.
The Pettypet was invented by someone named Podleci who hailed from Vienna, Austria. Not much else is known about this person. And although the back of the frame is stamped “Patented in all countries — Patents Pending”, the original patent is unknown.
Although it looks like a Bennett, this machine is 25% larger than a Bennett. Those aren’t keycaps, just legends for the two finger cups. You select the character you want, and then press down to print. That cute little red button in the middle is the Spacebar. On the far left, there are two raised Shift buttons, one for capitals and the other for figures.
Somewhat surprisingly, this machine uses a print wheel to apply the type, and a small-looking but otherwise standard two-spool ribbon. There are more cute red buttons on the sides to change the ribbon’s direction. There’s no platen to speak of, just a strip of rubber.
The company name, Pettypet GmbH, and ‘Frankfurt, Germany’ are also stamped into the frame. In addition to this candy-apple red, the Pettypet came in green, blue, and brown. I’d love to see the blue.
Finally, 3D Printed Keyboards That Look Injection-Molded
hackaday.com/wp-content/upload…
Isn’t this lovely? It’s just so smooth! This is a Cygnus printed in PETG and post-processed using only sandpaper and a certain primer filler for car scratches.
About a month ago, [ErgoType] published a guide under another handle. It’s a short guide, and one worth reading. Essentially, [ErgoType], then [FekerFX] sanded it with 400 grit and wiped it down, then applied two coats of primer filler, waiting an hour between coats. Then it gets sanded until smooth.
Finally, apply two more coats, let those dry, and use 1000-grit sandpaper to wet-sand it, adding a drop of soap for a smoother time. Wipe it down again and apply a color primer, then spray paint it and apply a clear coat. Although it seems labor-intensive and time consuming, the results are totally worth it for something you’re going to have your hands on every day.
Got a hot tip that has like, anything to do with keyboards? Help me out by sending in a link or two. Don’t want all the Hackaday scribes to see it? Feel free to email me directly.
The Nokia N900 Updated For 2025

Can a long-obsolete Linux phone from 2009 be of use in 2025? [Yaky] has a Nokia N900, and is giving it a go.
Back in the 2000s, Nokia owned the mobile phone space. They had a smartphone OS even if they didn’t understand app distribution, they had the best cameras, screens, antennas, the lot. They threw it all away with inept management that made late-stage Commodore look competent, Apple and Android came along, and now a Nokia is a rarity. Out of this mess came one good thing though, the N900 was a Linux-based smartphone that became the go-to hacker mobile for a few years.
First up with this N900 is the long-dead battery. He makes a fake battery with a set of supercapacitors and resistors to simulate the temperature sensor, and is then able to power it from an external PSU. This is refined to a better fake battery using the connector from the original. The device also receives a USB-C port, though due to space constraints not the PD identifiers, making it (almost) modern.
Because it was a popular hacker device, it’s possible to upgrade the software on an N900. He’s given it U-Boot, and now it boots Linux form an SD card and functions as an online radio device.
That’s impressive hackability and longevity for a phone, if only we could have more like it.
Surviving the RAM Apocalypse With Software Optimizations

To the surprise of almost nobody, the unprecedented build-out of datacenters and the equipping of them with servers for so-called ‘AI’ has led to a massive shortage of certain components. With random access memory (RAM) being so far the most heavily affected and with storage in the form of HDDs and SSDs not far behind, this has led many to ask the question of how we will survive the coming months, years, decades, or however-long the current AI bubble will last.
One thing is already certain, and that is that we will have to make our current computer systems last longer, and forego simply tossing in more sticks of RAM in favor of doing more with less. This is easy to imagine for those of us who remember running a full-blown Windows desktop system on a sub-GHz x86 system with less than a GB of RAM, but might require some adjustment for everyone else.
In short, what can us software developers do differently to make a hundred MB of RAM stretch further, and make a GB of storage space look positively spacious again?
Just What Happened?
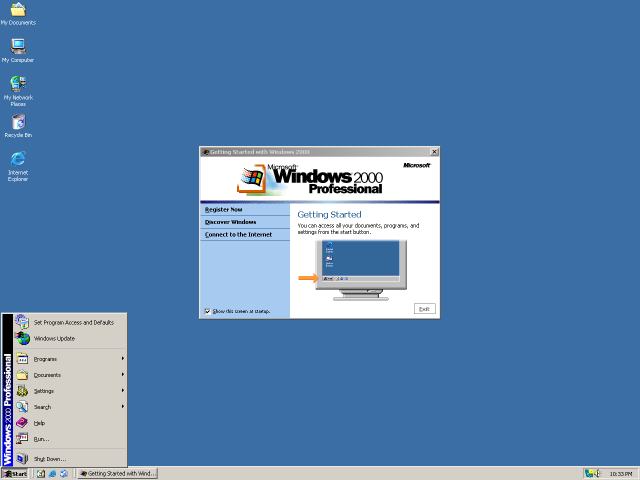
On these systems I could run a browser with many tabs open, alongside an office suite, an IDE, chat applications like IRC and ICQ, an email client, filesharing applications, and much more, without the system breaking a sweat. In the Duron 600 system I would eventually install a Matrox G550 AGP videocard to do some dual-monitor action, like watching videos or consulting documentation while browsing or programming at the same time.
Fast-forward a few decades and you cannot even install Windows on a 1 GB partition, and it requires more RAM than that. A quick check on the Windows 10 system that I’m typing this on shows that currently the Windows folder is nearly 27 GB in size and just the Thunderbird email client is gobbling up over 150 MB of RAM by itself. Compare this to the minimum Windows 2000 system requirements of a Pentium 133 MHz, 32 MB of RAM and 1 GB of free HDD space.
This raises the question of what the reason is for this increase, when that email client in the early 2000s had effectively the same features in a much smaller package, and Windows 2000 is effectively the same as Windows 7, 10 and now 11, at its core when it comes to its feature set.
The same is true for ‘fast and light’ options like Linux, which I had once running on a 486DX2-66 system, a system on which the average Linux distribution today won’t even launch the installer, unless you go for a minimalistic distro like Alpine Linux, which requires a mere 128 MB of RAM. Where does all this demand for extra RAM and disk storage come from? Is it just all lazy waste and bloat that merely fills up the available space like a noxious gas?
Asking The Right Questions
")
Storage and RAM requirements for software are linked in the sense that much of an application’s code and related resources are loaded into RAM at some point, but there is also the part of RAM that gets filled with data that the application generates while running. This gives us a lens to find out where the higher requirements come from.
In the case of Windows, the increase in minimum storage space requirements from 1 GB to 32 GB for Windows 10 can be explained by something that happened when Windows Vista rolled around along with changes to WinSxS, which is Windows’ implementation of side-by-side assembly.
By putting all core OS files in a single WinSxS folder and hard-linking them to various locations in the file system, all files are kept in a single location, with their own manifest and previous versions kept around for easy rollback. In Windows 2000, WinSxS was not yet used for the whole OS like this, mostly just to prevent ‘DLL Hell’ file duplication issues, but Vista and onwards leaned much more heavily into this approach as they literally dumped every single OS file into this folder.
While that by itself isn’t such an issue, keeping copies of older file versions ensured that with each Windows Update cycle the WinSxS folder grew a little bit more. This was confirmed in a 2008 TechNet blog post, and though really old files are supposed to be culled now, it clearly has ensured that a modern Windows installation grows to far beyond that of pre-Vista OSes.
Thus we have some idea of why disk storage size requirements are increasing, leading us to the next thing, which is the noticeable increase in binary size. This can be put down for a large part on increased levels of abstractions, both in system programming languages, as well as scripting languages and frameworks.
Losing Sight Of The Hardware
Over the past decades we have seen a major shift away from programming languages and language features that work directly with the hardware to ones that increasingly abstract away the hardware. This shift was obvious in the 90s already, with for example Visual Basic continuing the legacy of BASIC with a similar mild level of abstraction before Java arrived on the scene with its own virtual hardware platform that insisted that hardware was just an illusion that software developers ought to not bother with.
Subsequently we saw .NET, JavaScript, Python, and kin surge to the foreground, offering ‘easier programming’ and ‘more portable code’, yet at the same time increasing complexity, abstraction levels, as well as file sizes and memory usage. Most importantly, these languages abandoned the concept of programming the underlying hardware with as few levels of indirection as possible. This is something which has even become part of languages like C and C++, with my own loathing for this complexity and abstraction in C++ being very palpable.
In the case of a language like Python, it’s known to be exceedingly slow due to its architecture, which results in the atrocious CPython runtime as well as better, but far more complex alternatives. This is a software architecture that effectively ignores the hardware’s architecture, which thus results in bringing in a lot of unnecessary complexity. Languages such as JavaScript also make this mistake, with a heavy runtime that requires features such as type-checking and garbage collection that add complexity, while needing more code to enable features like Just-In-Time compilation to keep things still somewhat zippy.
With Java we even saw special JVM processor extensions being added to ARM processor with Jazelle direct bytecode execution (DBX) to make mobile games on cellphones programmed in J2ME not run at less than 1 FPS. Clearly if the software refuses to work with the hardware, the hardware has to adapt to the software.
By the time that you’re a few levels of abstraction, various ‘convenient frameworks’ and multiple layers of indirection down the proverbial rabbit hole, suddenly your application’s codebase has ballooned by a few 100k LoC, the final binary comes in at 100+ MB and dial-up users just whimper as they see the size of the installer. But at least now we know why modern-day Thunderbird uses more RAM than what an average PC would have had installed around 1999.
Not All Hope Is Lost
There’s no need to return to the days of chiseling raw assembly into stone tables like in the days when the 6502 and Z80 still reigned supreme. All we need to do to make the most of the RAM and storage we have, is to ask ourselves at each point whether there isn’t a more direct and less complex way. What this looks like will depend on the application, but the approach that I like to use with my own projects is that of the chronically lazy developer who doesn’t like writing more code than absolutely necessary, hates complexity because it takes effort and whose eyes glaze over at overly verbose documentation.
One could argue that there’s considerable overlap between KISS and laziness, in the sense that a handful of source files accompanied by a brief Makefile is simultaneously less work and less complex than a MB+ codebase that exceeds the capabilities of a single developer with a basic editor like Notepad++ or Vim. This incidentally is why I do not use IDEs but prefer to only rely on outrageously advanced features such as syntax highlighting and auto-indent. Using my brain for human-powered Intellisense makes for a good mental exercise.
I also avoid complex file formats like XML and their beefy parsers, preferring to instead use the INI format that’s both much easier to edit and parse. For embedding scripting languages I use the strongly-typed AngelScript, which is effectively scriptable C++ and doesn’t try any cute alternative architectures like Python or Lua do.
Rather than using bulky, overly bloated C++ frameworks like Boost, I use the much smaller and less complex Poco libraries, or my NPoco fork that targets FreeRTOS and similar embedded platforms. With my remote procedure call (RPC) framework NymphRPC I opted for a low-level, zero copy approach that tries to stick as closely to the CPU and memory system’s capabilities as feasible to do the work with the fewest resources possible.
While I’m not trying to claim that my approach is the One True Approach
Sure, I could probably have done something with MicroPython or so, but at the cost of a lot more storage and with far less performance. Which gets us back again to why modern day PCs need so much RAM and storage. It’s not a bug, but a feature of the system many of us opted for, or were told was the Modern Way
libxml2 Narrowly Avoids Becoming Unmaintained

In an excellent example of one of the most overused XKCD images, the libxml2 library has for a little while lost its only maintainer, with [Nick Wellnhofer] making good on his plan to step down by the end of the year.
While this might not sound like a big deal, the real scope of this problem is rather profound. Not only is libxml2 part of GNOME, it’s also used as dependency by a huge number of projects, including web browsers and just about anything that processes XML or XSLT. Not having a maintainer in the event that a fresh, high-risk CVE pops up would obviously be less than desirable.
As for why [Nick] stepped down, it’s a long story. It starts in the early 2000s when the original author [Daniel Veillard] decided he no longer had time for the project and left [Nick] in charge. It should be said here that both of them worked as volunteers on the project, for no financial compensation. This when large companies began to use projects like libxml2 in their software, and were happy to send bug reports. Beyond a single Google donation it was effectively unpaid work that required a lot of time spent on researching and processing potential security flaws sent in.
Of note is that when such a security report comes in, the expectation is that you as a volunteer software developer drop everything you’re working on and figure out the cause, fix and patched-by-date alongside filing a CVE. This rather than you getting sent a merge request or similar with an accompanying test case. Obviously these kind of cases seems to have played a major role in making [Nick] burn out on maintaining both libxml2 and libxslt.
Fortunately for the project two new developers have stepped up to take over as maintainers, but it should be obvious that such churn is not a good sign. It also highlights the central problem with the conflicting expectations of open source software being both totally free in a monetary fashion and unburdened with critical bugs. This is unfortunately an issue that doesn’t seem to have an easy solution, with e.g. software bounties resulting in mostly a headache.




fasci in giro
serena bortone: "nessuno parlerebbe di fascismo se evitassero di inneggiare alla decima mas, fare francobolli sui fascisti, picchiare un deputato in aula. basterebbe avere un minimo di decenza" (https://x.com/grande_flagello/status/1802299304628941244)
e vogliamo parlare dei busti dell'appeso, che la seconda carica dello stato si tiene in casa?
#fascismo #neofascismo #governo #governoitaliano #antifascismo #Resistenza
reshared this
decolonizzazione? dove?
ma gli studi decoloniali che ci stanno a fare, se non si vede quello che israhell ha fatto e fa da un secolo circa?
marcogiovenale.me/2025/08/03/c…
#israhell #colonialismo #genocidio #Palestinalibera #Palestina #gaza
reshared this

Donald Trump all’attacco della comunità somala negli Stati Uniti
Il presidente ha definito i somali “spazzatura” e ha mandato agenti dell’ufficio immigrazione in Minnesota, lo stato che ospita la più grande comunità somala del paese. LeggiAnnalisa Camilli (Internazionale)
Nicola Pizzamiglio likes this.

Leoncavallo: i giorni dello sgombero
“Leoncavallo, i giorni dello sgombero” / Alberto Grifi, Paola Pannicelli + Collettivo Video csoa Leoncavallo
reshared this
freezonemagazine.com/articoli/…
Se è vero, come è vero che i crimini contro l’umanità non vanno mai prescritti, e per questo viene chiesto alla magistratura di continuare a indagare, è vero che ognuno deve fare la sua parte perché non ci si dimentichi di ciò che è successo. Chi scrive su questi fatti drammatici, ad esempio, deve proseguire […]
L'articolo Safari Sarajevo:
È disponibile il nuovo numero della newsletter del Ministero dell’Istruzione e del Merito.

Ministero dell'Istruzione
#NotiziePerLaScuola È disponibile il nuovo numero della newsletter del Ministero dell’Istruzione e del Merito.Telegram
Ein-/Ausreisesystem: Neue EU-Superdatenbank startet mit Ausfällen und neuen Problemen
netzpolitik.org/2025/ein-ausre…

PODCAST. Le liste nere di Trump: Washington cancella il diritto di viaggiare anche degli italiani
@Notizie dall'Italia e dal mondo
Esiste un sistema che, ben oltre i confini degli Stati Uniti, limita il transito, l’ingresso e la libertà di movimento di persone ritenute indesiderate perché sostengono Paesi sanzionati da Washington, come il
Notizie dall'Italia e dal mondo reshared this.
Ecuador, l’arcipelago delle carceri: stragi, tubercolosi e la responsabilità dello Stato
@Notizie dall'Italia e dal mondo
Dal 2021 al 2025 almeno 816 persone sono morte violentemente nelle carceri ecuadoriane, mentre centinaia sono decedute per fame e tubercolosi. Tra stragi, militarizzazione e abbandono istituzionale, il sistema penitenziario si è
Notizie dall'Italia e dal mondo reshared this.
iCloud, Mega, and as a torrent. Archivists have uploaded the 60 Minutes episode Bari Weiss spiked.#News


Archivists Posted the 60 Minutes CECOT Segment Bari Weiss Killed
Archivists have saved and uploaded copies of the 60 Minutes episode new CBS editor-in-chief Bari Weiss ordered be shelved as a torrent and multiple file sharing sites after an international distributor aired the episode.The moves show how difficult it may be for CBS to stop the episode, which focused on the experience of Venezuelans deported to El Salvadorian mega prison CECOT, from spreading across the internet. Bari Weiss stopped the episode from being released Sunday even after the episode was reviewed and checked multiple times by the news outlet, according to an email CBS correspondent Sharyn Alfonsi sent to her colleagues.
“You may recall earlier this year when the Trump administration deported hundreds of Venezuelan men to El Salvador, a country most had no connection to,” the show starts, according to a copy viewed by 404 Media.
This post is for subscribers only
Become a member to get access to all content
Subscribe now

Rapido 904. La strage (dimenticata) di Natale
@Giornalismo e disordine informativo
articolo21.org/2025/12/rapido-…
C’è una strage spesso dimenticata tra quelle che hanno insanguinato l’Italia dal 1969 (Piazza Fontana) ed è quella del Rapido 904, ribattezzata la strage di Natale. L’attentato al treno che il 23 dicembre 1984 era partito dalla stazione di
reshared this
l'UE sempre più "mazzolata", ma bomber Pfizer & c pensano a giocare alla guerra.
Cina: dazi sui prodotti caseari UE
A partire da domani la Cina imporrà dazi dal 21,9% al 42,7% sui prodotti lattiero caseari dell’Unione Europea. Lo ha annunciato il ministro del Commercio cinese, che ha spiegato che la misura sarà temporanea e avrà lo scopo di compensare le perdite del settore in Cina. «I prodotti lattiero-caseari importati provenienti dall’UE ricevono sussidi», ha detto il ministro. «L’industria lattiero-casearia nazionale cinese ha subito danni sostanziali ed esiste un nesso causale tra i sussidi e il danno», ha aggiunto.

Andiamo a dire #NO a questo nuovo tentativo di spallata antidemocratica
@Giornalismo e disordine informativo
articolo21.org/2025/12/andiamo…
Tutto sbagliato. Innanzitutto non sono tutti gli avvocati di Siena a dire Sì ma soltanto (com’è scritto nell’articolo a differenza del titolo) quelli che
Giornalismo e disordine informativo reshared this.
Lo sgombero di Askatasuna e il ruolo dello Stato
@Giornalismo e disordine informativo
articolo21.org/2025/12/lo-sgom…
Il punto non è quanto ci piaccia o meno Askatasuna, quanto ci entusiasmino presupposto ideologico, finalità, obiettivi e metodi. Il punto è cosa deve tentare di fare la politica di fronte ad un fatto sociale così rilevante,
Giornalismo e disordine informativo reshared this.
Da un anno non mi rinnovano la tessera stampa turca. Perché?
@Giornalismo e disordine informativo
articolo21.org/2025/12/da-un-a…
“È da circa un anno che non ho ottenuto il rinnovo della mia tessera stampa turca, necessaria per la mia attività giornalistica, pubblica, in Turchia in qualità di corrispondente di Radio
Giornalismo e disordine informativo reshared this.
Marisa Kabas of The Handbasket joins the pod to talk about indie journalism, the industry, and what's going on in the federal government
Marisa Kabas of The Handbasket joins the pod to talk about indie journalism, the industry, and whatx27;s going on in the federal government#podcasts
Podcast: Marisa Kabas on Landing Big Scoops as an Independent Journalist
Marisa Kabas is the founder of The Handbasket, an independent newsletter and website that has been breaking stories left and right about government workers, the media business, and Trump’s mass deportation campaign. Please go subscribe to The Handbasket here!In this episode of the podcast, Jason and Marisa share notes Marisa about doing journalism without a big newsroom, how the media business has changed over the last decade, and why sources often prefer to talk to journalists who don’t work for mainstream media.
playlist.megaphone.fm?e=TBIEA5…
Stories discussed:
Truth, morality and independence in journalism under the second Trump regime
My full remarks to students and faculty at Grinnell College.The HandbasketMarisa Kabas
Listen to the weekly podcast on Apple Podcasts, Spotify, or YouTube. Become a paid subscriber for access to this episode's bonus content and to power our journalism. If you become a paid subscriber, check your inbox for an email from our podcast host Transistor for a link to the subscribers-only version! You can also add that subscribers feed to your podcast app of choice and never miss an episode that way. The email should also contain the subscribers-only unlisted YouTube link for the extended video version too. It will also be in the show notes in your podcast player.Or watch it here:
youtube.com/embed/e73spvZnc9s?…Move fast and break people
For Elon Musk's government, the psychological warfare is the point.Marisa Kabas (The Handbasket)

 The HandbasketMarisa Kabas
The HandbasketMarisa Kabas
 The HandbasketMarisa Kabas
The HandbasketMarisa Kabas
Flock left at least 60 of its people-tracking Condor PTZ cameras live streaming and exposed to the open internet.#Flock
Flock Exposed Its AI-Powered Cameras to the Internet. We Tracked Ourselves
I am standing on the corner of Harris Road and Young Street outside of the Crossroads Business Park in Bakersfield, California, looking up at a Flock surveillance camera bolted high above a traffic signal. On my phone, I am watching myself in real time as the camera records and livestreams me—without any password or login—to the open internet. I wander into the intersection, stare at the camera and wave. On the livestream, I can see myself clearly. Hundreds of miles away, my colleagues are remotely watching me too through the exposed feed.Flock left livestreams and administrator control panels for at least 60 of its AI-enabled Condor cameras around the country exposed to the open internet, where anyone could watch them, download 30 days worth of video archive, and change settings, see log files, and run diagnostics.
Unlike many of Flock’s cameras, which are designed to capture license plates as people drive by, Flock’s Condor cameras are pan-tilt-zoom (PTZ) cameras designed to record and track people, not vehicles. Condor cameras can be set to automatically zoom in on people’s faces as they walk through a parking lot, down a public street, or play on a playground, or they can be controlled manually, according to marketing material on Flock’s website. We watched Condor cameras zoom in on a woman walking her dog on a bike path in suburban Atlanta; a camera followed a man walking through a Macy’s parking lot in Bakersfield; surveil children swinging on a swingset at a playground; and film high-res video of people sitting at a stoplight in traffic. In one case, we were able to watch a man rollerblade down Brookhaven, Georgia’s Peachtree Creek Greenway bike path. The Flock camera zoomed in on him and tracked him as he rolled past. Minutes later, he showed up on another exposed camera livestream further down the bike path. The camera’s resolution was good enough that we were able to see that, when he stopped beneath one of the cameras, he was watching rollerblading videos on his phone.
0:00
/0:16
1×The exposure was initially discovered by YouTuber and technologist Benn Jordan and was shared with security researcher Jon “GainSec” Gaines, who recently found numerous vulnerabilities in several other models of Flock’s automated license plate reader (ALPR) cameras. They shared the details of what they found with me, and I verified many of the details seen in the exposed portals by driving to Bakersfield to walk in front of two cameras there while I watched myself on the livestream. I also pulled Flock’s contracts with cities for Condor cameras, pulled details from company presentations about the technology, and geolocated a handful of the cameras to cities and towns across the United States. Jordan also filmed himself in front of several of the cameras on the Peachtree Creek Greenway bike path. Jordan said he and Gaines discovered many of the exposed cameras with Shodan, an internet of things search engine that researchers regularly use to identify improperly secured devices.
youtube.com/embed/vU1-uiUlHTo?…
After finding links to the feed, “immediately, we were just without any username, without any password, we were just seeing everything from playgrounds to parking lots with people, Christmas shopping and unloading their stuff into cars,” Jordan told me in an interview. “I think it was like the first time that I actually got like immediately scared … I think the one that affected me most was as playground. You could see unattended kids, and that’s something I want people to know about so they can understand how dangerous this is.” In a YouTube video about his research, Jordan said he was able to use footage pulled from the exposed feed to identify specific people using open source investigation tools in order to show how trivially an exposure like this could be abused.Benn Jordan
Last year, Flock introduced AI features to Condor cameras that automatically zoom in on people as they walk by. In Flock’s announcement of this feature, it explained that this technology “zooms in on a suspect exiting one car, stealing an item from another, and returning to his vehicle. Every detail is captured, providing invaluable evidence for investigators.” On several of the exposed feeds, we saw Flock cameras repeatedly zooming in on and tracking random people as they walked by. The cameras can be controlled by AI or manually.The exposure highlights the fact that Flock is not just surveilling cars—it is surveilling people, and in some cases it is doing so in an insecure way, and highlight the types of places that its Condor cameras are being deployed. Condor cameras are part of Flock’s ever-expanding quest to “prevent crime,” and are sometimes integrated with its license plate cameras, its gunshot detection microphones, and its automated camera drones.
Cooper Quintin, senior staff technologist at the Electronic Frontier Foundation, told me the behavior he saw in videos we shared with him “shows that Flock's ambitions go far beyond license-plate surveillance. They want to be a nation-wide panopticon, watching everyone all the time. Flock's goal isn't to catch stolen cars, their goal is to have total surveillance of everyone all the time."
0:00
/1:03
1×The cameras were left not just livestreaming to the internet for anyone who could find the link, but in many cases their administrative portals were left open with no login credentials required whatsoever. On this portal, some camera settings could be changed, diagnostics could be run, and text logs of what the camera was doing were being streamed, too. Thirty days of the camera’s archive was left available for anyone to watch or download from any of the cameras that we found. We were not able to geolocate every camera that was left unprotected, but we found cameras at a New York City Department of Transportation parking lot, on a street corner in suburban New Orleans, in random cul-de-sacs, in a Lowes parking lot, in the parking lot of a skatepark, at a pool, outside a parking garage, at an apartment complex, outside a church, on a bike path, and at various street intersections around the country.
Quintin told me the situation reminds him of ALPR cameras from another company that were left unprotected a decade ago.
“This is not the first time we have seen ALPRs exposed on the public internet, and it won't be the last. Law enforcement agencies around the country have been all too eager to adopt mass surveillance technologies, but sometimes they have put little effort into ensuring the systems are secure and the sensitive data they collect on everyday people is protected,” Quintin said. “Law enforcement should not collect information they can’t protect. Surveillance technology without adequate security measures puts everyone’s safety at risk.”
It was not always clear which business or agency owned specific cameras that were left exposed, or what type of misconfiguration led to the exposure, though I was able to find a $348,000 Flock contract for Brookhaven, Georgia, which manages the Peachtree Creek Greenway, and includes 64 Condor cameras.
"This was a limited misconfiguration on a very small number of devices, and it has since been remedied," a Flock spokesperson told 404 Media. It did not answer questions about what caused the misconfiguration or how many devices ultimately were affected.
💡
Do you know anything else about surveillance? I would love to hear from you. Using a non-work device, you can message me securely on Signal at jason.404. Otherwise, send me an email at jason@404media.co.In response to Jordan and Gaines’ earlier research on vulnerabilities in other Flock cameras, Flock CEO Garrett Langley said in a LinkedIn post that “The Flock system has not been hacked. We secure customer data to the highest standard of industry requirements, including strict industry standard encryption. Flock’s cloud storage has never been compromised.” The exposure of these video feeds is not a hack of Flock’s system, but demonstrates a major misconfiguration of at least some cameras. It also highlights a major misconfiguration in its security that persisted for at least days.
“When I was making my last video [about Flock ALPR vulnerabilities], it was almost like a catchphrase where I'd say like, ‘I don't see how it could get any worse.’ And then something would happen where you'd be like, wow, they pulled it off. They made it worse,” Jordan said. “And then this is like the ultimate one. Because this is completely unrelated [to my earlier research] and I don’t really know how it could be any worse to be honest.”
In a 2023 video webinar introducing the Condor platform to police, Flock executives said the cameras are meant to be paired with their ALPR cameras and are designed to feed video to FlockOS, a police panel that allows cops to hop from camera to camera in real time across a mapped-out view of their city. In Bakersfield, which has 382 Flock cameras according to a transparency report, one of the Condor cameras we saw was located next to a mall that had at least two Flock ALPR cameras stationed at the entrances to the mall parking lot.Kevin Cox, a Flock consultant who used to work for the Grand Prairie, Texas Police Department, said in the webinar that he built an “intel center” with a high “density” of Flock cameras in that city. “I am passionate about this because I’ve lived it. The background behind video [Condor] with LPR is rich with arrests,” he said. “That rich experience of seeing what happened kind of brings it alive to [judges]. So video combined with the LPR evidence of placing a vehicle at the scene or nearby is an incredibly game changing experience into the prosecutorial chain of events.”
“You can look down a tremendous distance with our cameras, to the next intersection and the next intersection,” he said. “The camera will identify people, what they’re wearing, and cars up to a half a mile away. It’s that good.”
0:00
/0:08
1×Condor cameras in a Flock demo showing off its AI tracking features
In the webinar Cox pulled up a multiview panel of a series of cameras and took control of them, dragging, panning, and zooming on cameras and hopping between multiple cameras in real time. Cox suggested that police officers could either use Flock’s cameras to pinpoint a person at a place and time and then use it to request “cell tower dumps” from wireless companies, or could use cell GPS data to then go into the Flock system to track a person as they moved throughout a city. “If you can place that person’s cell phone and then the Condor video and Falcon LPR evidence, it would be next to impossible to beat that in court,” he said, adding that some towns may just want to have always-on, always recording video of certain intersections or town squares. “There’s endless endless uses to what we can do with these things.”
On the webinar, Seth Cimino, who was a police officer at the Citrus Heights, California police department at the time but now works directly for Flock, told participants that officers in his city enjoyed using the cameras to zoom in on crimes.
“There is an eagerness amongst our staff that are logged in that have their own Flock accounts to be able to monitor our ALPR and pan tilt zoom Condor cameras throughout the community, to a point where sometimes our officers are beating dispatch with the information,” he said. “If there’s an incident that occurs at a specific intersection or a short distance away where our Condor cameras can zoom in on that area, it allows for real time overwatch […] as I sit here right now with you—how cool is this? We just had a Flock alert here in the city. I mean, it just popped up on my screen!”
Samantha Cole contributed reporting.
Introducing Condor Live and Recorded Video
Respond with Confidence with a cutting-edge video camera that empowers officerswww.flocksafety.com




Macché autonomia e ricarica, il problema è l'assistenza - Vaielettrico
Macché autonomia e ricarica, il problema delle auto elettriche è l'assistenza. Il racconto di Renato con la sua Tesla.Redazione (Vaielettrico)
Pirate News: Section 230 Repeal? No!
youtube.com/@masspiratesSteve and James discuss a new bipartisan effort to sunset CDA Section 230, a Trump DOJ memorandum the claims recording ICE agents is violence and wish you all a happy holidays on our last pirate news for 2025.
youtube.com/embed/66viFR-abPQ?…
Sign up to our newsletter to get notified of new events or volunteer. Join us on:
Check out:
- Surveillance Memory Bank and Resources;
- Our Administrative Coup Memory Bank;
- Our Things to Do when Fascists are Taking Over.
Some links we mentioned:
- Senators Want To Hold The Open Internet Hostage, Demand Zuckerberg Write The Ransom Note;
- The Government Unconstitutionally Labels ICE Observers as Domestic Terrorists.
Image Credit: Cory Doctorow, CC By-SA 4.0, Source Image.

reshared this
Anlasslose Speicherung: Justizministerium veröffentlicht Gesetzentwurf zur Vorratsdatenspeicherung
netzpolitik.org/2025/anlasslos…


Esplosione a Mosca, chi era il generale Fanil Sarvarov e qual era il suo ruolo nell’esercito russo
Sarvarov era capo dell’Ufficio di Addestramento Operativo delle Forze Armate della Federazione Russa, una posizione chiave nello Stato Maggiore militare del Paese.Redazione Adnkronos (Adnkronos)

Nato, accuse alla Russia: "Sta sviluppando arma per colpire la rete Starlink"
Leggi su Sky TG24 l'articolo Nato, accuse alla Russia: 'Sta sviluppando arma per colpire la rete Starlink'Redazione Sky TG24 (Sky TG24)
L'ultimo TechDispatch esplora le sfide della privacy dei portafogli di identità digitale
Il #GarantePrivacy europeo (GEPD) ha pubblicato il suo ultimo TechDispatch , una serie di articoli che forniscono analisi dettagliate su nuove tecnologie e tendenze. Questo numero si concentra sui Digital Identity Wallet (DIW) e su come possiamo garantire che rimangano conformi ai principi di protezione dei dati.
(segui l'account @Privacy Pride per avere gli ultimi aggiornamenti sulla #privacy e la gestione dei dati personali)
Un DIW consente agli utenti di archiviare in modo sicuro dati di identità e credenziali in un repository digitale, consentendo l'accesso ai servizi sia nel mondo fisico che in quello digitale. Intitolata "Il percorso verso un approccio di protezione dei dati by design e by default", la nuova pubblicazione è una lettura essenziale per decisori politici e professionisti che desiderano garantire che lo sviluppo di DIW, come il futuro Portafoglio Europeo di Identità Digitale (EUDIW) , aderisca ai principi di Privacy by Design e by Default.
Per saperne di più sulle raccomandazioni del GEPD per un quadro normativo sull'identità digitale sicuro e rispettoso della privacy,
edps.europa.eu/data-protection…

TechDispatch #3/2025 - Digital Identity Wallets
The idea behind a Digital Identity Wallet (DIW) is to provide users with an easy way to store their identity data and credentials in a digital repository.European Data Protection Supervisor
reshared this
Bulgaria, una crisi senza uscita (parte prima). Cinque anni di instabilità e il collasso della politica
@Notizie dall'Italia e dal mondo
Le dimissioni dell’11 dicembre non sono un incidente ma l’esito di una crisi che dura dal 2020. Proteste, corruzione, inflazione, ingresso nell’euro e scontro istituzionale si innestano su un sistema incapace
Notizie dall'Italia e dal mondo reshared this.

Ministero dell'Istruzione
#NoiSiamoLeScuole questa settimana è dedicato a due nuove scuole, la “Falcone-Borsellino” di Monterenzio (BO) e la “Mustica” di Santa Sofia d’Epiro (CS) che, con i fondi del #PNRR finalizzati alla costruzione di nuove scuole, sono state demolite e ri…Telegram

Numero chiuso e test
@Politica interna, europea e internazionale
L'articolo Numero chiuso e test proviene da Fondazione Luigi Einaudi.
Politica interna, europea e internazionale reshared this.
VIDEO. GERUSALEMME. Israele abbatte palazzo a Silwan, 90 palestinesi senza casa
@Notizie dall'Italia e dal mondo
In Cisgiordania il governo Netanyahu ha legalizzato 19 avamposti coloniali a ridosso dei villaggi palestinesi
L'articolo pagineesteri.it/2025/12/22/med…
Notizie dall'Italia e dal mondo reshared this.

I tre più grandi problemi di Donald Trump
Il bilancio del 2025 in cinque articoli: in quello di oggi l’anno del presidente statunitense, che ha sovvertito l’ordine mondiale ma fatica a imporsi. LeggiPierre Haski (Internazionale)
Difesa, spazio e procurement. Quando il tempo diventa una capacità operativa
@Notizie dall'Italia e dal mondo
Negli anni il settore spaziale è passato da ambito specialistico, quasi esclusivamente istituzionale, a terreno centrale della competizione economica e tecnologica nonché dominio di contrasto militare. Questa trasformazione, spesso sintetizzata nel mondo civile
Notizie dall'Italia e dal mondo reshared this.
VIDEO. GERUSALEMME. Israele abbatte palazzo a Silwan, 90 palestinesi senza casa
@Notizie dall'Italia e dal mondo
In Cisgiordania il governo Netanyahu ha legalizzato 19 avamposti coloniali a ridosso dei villaggi palestinesi
L'articolo pagineesteri.it/2025/12/22/med…
Notizie dall'Italia e dal mondo reshared this.
freezonemagazine.com/articoli/…
Nel suo secondo romanzo, Maurizio Pratelli mette a punto, in modo piuttosto convincente, la propria capacità di narratore e lo stile di scrittura portando in scena un protagonista in bilico tra il peso del passato e la ricerca di un futuro ancora possibile. Andrea, soffocato da un lavoro che non sente suo e da una […]
L'articolo Maurizio Pratelli – Scendo prima
Kami
in reply to Andrea Russo • • •