 - Collegamento all'originale")
Acquisto occhiali con lenti progressive
Devo mettere gli occhiali, mi servono delle lenti progressive, mi sono fatto fare un paio di preventivi e la "forchetta" tra i prezzi che mi hanno dato è molto alta.
Purtroppo non ho nessun modo di capire quale sia la scelta più razionale e attualmente ho solo due criteri a disposizione:
a) compro le economiche così risparmio;
b) compro le costose perché se costano di più sono migliori ed è meglio non risparmiare sulla salute.
Nessuno dei due criteri mi sembra quello ottimale. L'unica cosa utile sarebbe provarle entrambe e vedere come sono ma ovviamente non è possibile.
Voi che le avete come vi regolate?
Poliversity - Università ricerca e giornalismo reshared this.
Il phishing è sempre più difficile da individuare e gli utenti non lo sanno
@Informatica (Italy e non Italy 😁)
Una ricerca di Dojo nel Regno Unito sancisce che il 53% delle persone non è in grado di riconoscere un’e-mail di phishing ma crede di essere in grado di farlo. È un problema serio, perché vuole dire che il phishing è sempre più difficile da individuare e che le persone hanno un lack di formazione
Informatica (Italy e non Italy 😁) reshared this.
MR Browser is the Package Manager Classic Macs Never Had

Homebrew bills itself as the package manager MacOS never had (conveniently ignoring MacPorts) but they leave the PPC crowd criminally under-served, to say nothing of the 68k gang. Enter [that-ben] with MR Browser, a simple utility to fetch software from Macintosh Repository for computers too old to hit up the website.
If you’re not familiar with Macintosh Repository, it is what it says on the tin: a repository of vintage Macintosh software, like Macintosh Garden but apparently less accessible to vintage machines.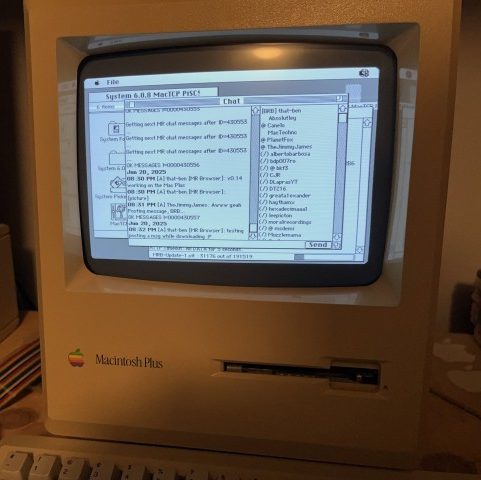
There are two versions available, depending on the age of your machine. For machines running System 6, the appropriately-named MR Browser sys6 will run on any 68000 Mac in only 157 KB of and MacTCP networking. (So the 128K obviously isn’t going to cut it, but a Plus from ’86 would be fine.)
The other version, called MR Browser 68K, ironically won’t run on the 68000. It needs a newer processor (68020 or newer, up-to and including PPC) and TCP/IP networking. Anything starting from the Macintosh II or newer should be game; it’s looking for System 7.x upto the final release of Mac OS 9, 9.2.2. You’ll want to give it at least 3 MB of RAM, but can squeak by on 1.6 MB if you aren’t using pictures in the chat.
Chat? Yes, perhaps uniquely for a software store, there’s a chat function. That’s not so weird when you consider that this program is meant to be a stand-alone interface for the Macintosh Repository website, which does, indeed, have a chat feature. It beats an uncaring algorithm for software recommendations, that’s for sure. Check it out in action in the demo video below.
It’s nice to see people still making utilities to keep the old machines going, even if coding on them isn’t always the easiest. If you want to go online on with vintage hardware (Macintosh or otherwise) anywhere else, you’re virtually locked-out unless you use something like FrogFind.
Thanks to [PlanetFox] for the tip. Submit your own, and you may win fabulous prizes. Not from us, of course, but anything’s possible!
hackaday.com/wp-content/upload…
*
Alice e Bob siamo noi: la crittografia come esperienza umana e quotidiana
@Informatica (Italy e non Italy 😁)
Alice, Bob, Eve, Mallory, Trent, simboli viventi delle sfide reali che affrontiamo ogni giorno nella nostra vita digitale, sono riusciti nell'intento di trasformare la crittografia, da scienza matematica a narrazione, raccontata nel linguaggio umano
Informatica (Italy e non Italy 😁) reshared this.
Dati sensibili, sicurezza nazionale e il nuovo ruolo dello Stato
@Informatica (Italy e non Italy 😁)
Qualche tempo fa il capo della Polizia Vittorio Pisani aveva reclamato un intervento normativo, a livello nazionale, oppure, meglio, europeo, che equiparasse le piattaforme di messaggistica – da whatsapp a Telegram a X, fino alla messaggistica di Apple e Google– agli obblighi che hanno
Informatica (Italy e non Italy 😁) reshared this.
Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio
Negli ultimi anni i modelli di linguaggio di grandi dimensioni (LLM, Large Language Models) come GPT, Claude o LLaMA hanno dimostrato capacità straordinarie nella comprensione e generazione del linguaggio naturale. Tuttavia, dietro le quinte, far funzionare un LLM non è un gioco da ragazzi: richiede una notevole infrastruttura computazionale, un investimento economico consistente e scelte architetturali precise. Cerchiamo di capire perché.
70 miliardi di parametri: cosa significa davvero
Un LLM da 70 miliardi di parametri, come LLaMA 3.3 70B di Meta, contiene al suo interno 70 miliardi di “pesi”, ovvero numeri in virgola mobile (di solito in FP16 o BF16, cioè 2 byte per parametro) che rappresentano le abilità apprese durante l’addestramento. Solo per caricare in memoria questo modello, servono circa:
- 140 GB di RAM GPU (70 miliardi × 2 byte).
A questa cifra vanno aggiunti altri 20-30 GB di VRAM per gestire le operazioni dinamiche durante l’inferenza: cache dei token (KV cache), embedding dei prompt, attivazioni temporanee e overhead di sistema. In totale, un LLM da 70 miliardi di parametri richiede circa 160-180 GB di memoria GPU per funzionare in modo efficiente.
Perché serve la GPU: la CPU non basta
Molti si chiedono: “Perché non far girare il modello su CPU?”. La risposta è semplice: latenza e parallelismo.
Le GPU (Graphics Processing Unit) sono progettate per eseguire milioni di operazioni in parallelo, rendendole ideali per il calcolo tensoriale richiesto dagli LLM. Le CPU, invece, sono ottimizzate per un numero limitato di operazioni sequenziali ad alta complessità. Un modello come LLaMA 3.3 70B può generare una parola ogni 5-10 secondi su CPU, mentre su GPU dedicate può rispondere in meno di un secondo. In un contesto produttivo, questa differenza è inaccettabile.
Inoltre, la VRAM delle GPU di fascia alta (es. NVIDIA A100, H100) consente di mantenere il modello residente in memoria e di sfruttare l’accelerazione hardware per la moltiplicazione di matrici, cuore dell’inferenza LLM.
Un esempio: 100 utenti attivi su un LLM da 70B
Immaginiamo di voler offrire un servizio simile a ChatGPT per la sola generazione di testo, basato su un modello LLM da 70 miliardi di parametri, con 100 utenti attivi contemporaneamente. Supponiamo che ogni utente invii prompt da 300–500 token e si aspetti risposte rapide, con una latenza inferiore a un secondo.
Un modello di queste dimensioni richiede circa 140 GB di memoria GPU per i soli pesi in FP16, a cui vanno aggiunti altri 20–40 GB per la cache dei token (KV cache), attivazioni temporanee e overhead di sistema. Una singola GPU, anche top di gamma, non dispone di sufficiente memoria per eseguire il modello completo, quindi è necessario distribuirlo su più GPU tramite tecniche di tensor parallelism.
Una configurazione tipica prevede la distribuzione del modello su un cluster di 8 GPU A100 da 80 GB, sufficiente sia per caricare il modello in FP16 sia per gestire la memoria necessaria all’inferenza in tempo reale. Tuttavia, per servire contemporaneamente 100 utenti mantenendo una latenza inferiore al secondo per un LLM di queste dimensioni, una singola istanza su 8 GPU A100 (80GB) è generalmente insufficiente.
Per raggiungere l’obiettivo di 100 utenti simultanei con latenza sub-secondo, sarebbe necessaria una combinazione di:
- Un numero significativamente maggiore di GPU A100 (ad esempio, un cluster con 16-32 o più A100 da 80GB), distribuite su più POD o in un’unica configurazione più grande.
- L’adozione di GPU di nuova generazione come le NVIDIA H100, che offrono un netto miglioramento in termini di throughput e latenza per l’inferenza di LLM, però ad un costo maggiore.
- Massimizzare le ottimizzazioni software, come l’uso di framework di inferenza avanzati (es. vLLM, NVIDIA TensorRT-LLM) con tecniche come paged attention e dynamic batching.
- L’implementazione della quantizzazione (passando da FP16 a FP8 o INT8/INT4), che ridurrebbe drasticamente i requisiti di memoria e aumenterebbe la velocità di calcolo, ma con una possibile conseguente perdita di qualità dell’output generato (soprattutto per la quantizzazione INT4).
Per scalare ulteriormente, è possibile replicare queste istanze su più GPU POD, abilitando la gestione di migliaia di utenti totali in modo asincrono e bilanciato, in base al traffico in ingresso. Naturalmente, oltre alla pura inferenza, è fondamentale prevedere risorse aggiuntive per:
- Scalabilità dinamica in funzione della domanda.
- Bilanciamento del carico tra istanze.
- Logging, monitoraggio, orchestrazione e sicurezza dei dati.
Ma quanto costa un’infrastruttura di questo tipo?
L’implementazione on-premise richiede centinaia di migliaia di euro di investimento iniziale, cui si aggiungono i costi annuali di gestione, alimentazione e personale. In alternativa, i principali provider cloud offrono risorse equivalenti ad un costo mensile molto più accessibile e flessibile. Tuttavia, è importante sottolineare che anche in cloud, una configurazione hardware capace di gestire un tale carico in tempo reale può comportare costi mensili che facilmente superano le decine di migliaia di euro, se non di più, a seconda dell’utilizzo.
In entrambi i casi, emerge con chiarezza come l’impiego di LLM di grandi dimensioni rappresenti non solo una sfida algoritmica, ma anche infrastrutturale ed economica, rendendo sempre più rilevante la ricerca di modelli più efficienti e leggeri.
On-premise o API? La riservatezza cambia le carte in tavola
Un’alternativa semplice per molte aziende è usare le API di provider esterni come OpenAI, Anthropic o Google. Tuttavia, quando entrano in gioco la riservatezza e la criticità dei dati, l’approccio cambia radicalmente. Se i dati da elaborare includono informazioni sensibili o personali (ad esempio cartelle cliniche, piani industriali o atti giudiziari), inviarli a servizi cloud esterni può entrare in conflitto con i requisiti del GDPR, in particolare rispetto al trasferimento transfrontaliero dei dati e al principio di minimizzazione.
Anche molte policy aziendali basate su standard di sicurezza come ISO/IEC 27001 prevedono il trattamento di dati critici in ambienti controllati, auditabili e localizzati.
Inoltre, con l’entrata in vigore del Regolamento Europeo sull’Intelligenza Artificiale (AI Act), i fornitori e gli utilizzatori di sistemi di AI devono garantire tracciabilità, trasparenza, sicurezza e supervisione umana, soprattutto se il modello è impiegato in contesti ad alto rischio (finanza, sanità, istruzione, giustizia). L’uso di LLM attraverso API cloud può rendere impossibile rispettare tali obblighi, in quanto l’inferenza e la gestione dei dati avvengono fuori dal controllo diretto dell’organizzazione.
In questi casi, l’unica opzione realmente compatibile con gli standard normativi e di sicurezza è adottare un’infrastruttura on-premise o un cloud privato dedicato, dove:
- Il controllo sui dati è totale;
- L’inferenza avviene in un ambiente chiuso e conforme;
- Le metriche di auditing, logging e accountability sono gestite internamente.
Questo approccio consente di preservare la sovranità digitale e la conformità a GDPR, ISO 27001 e AI Act, pur richiedendo un effort tecnico ed economico significativo.
Conclusioni: tra potenza e controllo
Mettere in servizio un LLM non è solo una sfida algoritmica, ma soprattutto un’impresa infrastrutturale, fatta di hardware specializzato, ottimizzazioni complesse, costi energetici elevati e vincoli di latenza. I modelli di punta richiedono cluster da decine di GPU, con investimenti che vanno da centinaia di migliaia fino a milioni di euro l’anno per garantire un servizio scalabile, veloce e affidabile.
Un’ultima, ma fondamentale considerazione riguarda l’impatto ambientale di questi sistemi. I grandi modelli consumano enormi quantità di energia elettrica, sia in fase di addestramento che di inferenza. Con l’aumentare dell’adozione di LLM, diventa urgente sviluppare modelli più piccoli, più leggeri e più efficienti, che riescano a offrire prestazioni comparabili a fronte di un footprint computazionale (ed energetico) significativamente ridotto.
Come è accaduto in ogni evoluzione tecnologica — dal personal computer ai telefoni cellulari — l’efficienza è la chiave della maturità: non servono sempre modelli più grandi, ma modelli più intelligenti, più adattivi e sostenibili.
L'articolo Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio proviene da il blog della sicurezza informatica.
GR Valle d'Aosta del 18/07/2025 ore 07:20
GR Regionale Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 18/07/2025 - 07:20




FPF, Demand Progress file ethics complaint against Judge Edward Artau
On Thursday, Demand Progress and Freedom of the Press Foundation (FPF) filed an ethics complaint against Edward L. Artau, a Florida judge who was nominated by President Donald Trump to a federal district court after delivering a favorable ruling for Trump in his defamation lawsuit against the Pulitzer Board. The ethics complaint asks the D.C. Court of Appeals and the Florida Judicial Qualifications Commission to investigate Artau for potentially breaking rules requiring judges to recuse themselves to avoid conflicts of interest, remain impartial, avoid impropriety, and avoid giving false statements.
Politico reported that Artau, who sought for Trump to nominate him shortly after the president won the 2024 presidential election, later ruled in Trump’s favor as part of a panel of state appellate judges deciding whether to allow the president’s lawsuit against the Pulitzer Prize Board to move forward. After joining a favorable panel ruling for Trump, and after going out of his way to write a gratuitous solo concurrence praising the lawsuit’s claims on the merits, Artau was nominated to be a judge on South Florida’s U.S. trial court. Artau later gave an incomplete and misleading testimony about these events to the Senate Judiciary Committee while under oath.
“A federal judge’s goal should be upholding the law and the American people’s confidence in the judiciary, not delivering whatever the president wants so that they can get a job,” said Emily Peterson-Cassin, director of corporate power at Demand Progress. “Judge Ed Artau’s behind-closed-doors jockeying for his nomination, his failure to recuse himself from the Pulitzer lawsuit and his misleading testimony to the Senate all raise bright red flags that need to be investigated.”
Seth Stern, director of advocacy at Freedom of the Press Foundation, said: “Judges should be safeguarding us against President Trump’s frivolous attacks on the free press, the First Amendment and the rule of law. Instead, Judge Artau seems eager to facilitate Trump’s unconstitutional antics in exchange for a job. That’s far from the level of integrity that the Rules of Professional Conduct demand. Attorney disciplinary commissions need to rise to this moment and not tolerate ethical violations that impact not only individuals before the court but our entire democracy.”
Read the Complaint here or below.
freedom.press/static/pdf.js/we…
Next board meeting will take place on 05.08.2025 at 14:00 UTC
Our next PPI board meeting will take place on 05.08.2025 at 14:00 UTC / 16:00 CEST.
All official PPI proceedings, Board meetings included, are open to the public. Feel free to stop by. We’ll be happy to have you.
Where:jitsi.pirati.cz/PPI-Board
The prior meeting was unfortunately delayed.
Prior to that meeting a SCENE meeting is scheduled on July 22 at 7 pm/ UTC 9 pm CEST.
All of our meetings are posted to our calendar: pp-international.net/calendar/
We look forward to seeing visitors.
Thank you for your support,
The Board of PPI



TGR Valle d'Aosta del 17/07/2025 ore 19:30
TGR Valle d'Aosta. Le ultime notizie della regione Valle d'Aosta aggiornate in tempo reale. - Edizione del 17/07/2025 - 19:30

Mangelnde Fehlerkultur, Racial Profiling: Polizeibeauftragter legt ersten Jahresbericht vor
netzpolitik.org/2025/mangelnde…

Пираты любят мемы
Пиратская партия Германии на сайте Пиратского Интернационала обратила внимание на важную проблему: корпорации преследуют людей за создание мемов, не имеющих коммерческой цели.
Мемы, пародии и интернет-фольклор — важная часть современной культуры. Они рождаются в сетевых сообществах, переосмысливают медиа и становятся новым языком общения. Но так называемые правообладатели пытаются приватизировать даже те образы, которые давно стали частью общественного достояния.
В России, как и во всём мире, люди сталкиваются с аналогичными проблемами. Правообладатели активно подают в суд за использование мемов, даже если они созданы для развлечения. Например, «Си Ди Лэнд Контакт», приватизировавший Ждуна, несколько раз судился за его использование, Москвариум заявил о намерении зарегистрировать товарный знак «Рыбов показываем», петербургский предприниматель пытался, впрочем, безуспешно, зарегистрировать товарный знак «Как тебе такое, Илон».
Эта мировая практика показывает, как устаревшие законы о так называемом авторском праве, которое в первую очередь защищает не автора, а правообладателя, то есть, того, кто первым подберёт плохо лежащее, подавляют творчество и свободное выражение.
Пиратская партия России всецело поддерживает позицию ПП Германии.
Публикуем перевод их заявления:
Культура мемов — это здорово! Пираты обожают мемы. Мемы помогают людям делиться идеями и шутками. Но некоторые жадные создатели корпоративного контента нападают на тех, кто их создаёт. Они подают в суд на тех, кто создаёт мемы без какой-либо коммерческой цели. Мы должны дать этому отпор!Один явный случай произошел в Германии. Фанаты создали мемы о героине детской книги Конни. Издатель разослал письма с требованием прекратить противоправные действия. Они угрожали аккаунту в <запрещённой в РФ соцсети с фотографиями>. И им это удалось. Они закрыли аккаунт. Они ограничили свободу слова. Они уничтожили собственное творение. Мемы позволили бы Конни выжить. Конни умрёт. Спасите Конни!
Хотя в Германии особенно строго относятся к «нарушению авторских прав», эта проблема носит глобальный характер и не ограничивается только мемами.
Такие случаи случаются в мире искусства. Disney разослал официальные уведомления о фан-арте.
Такие случаи происходят в игровой индустрии. Nintendo закрывает игры, созданные на основе их контента.
В музыкальной индустрии такое случается. Музыканты подают в суд на других музыкантов за ремиксы своих треков.
Они происходят в социальных сетях. Поклонников событий в Южной Корее предостерегли по поводу мемов о военном положении.
Мемы — это здорово! Переделки игр — это здорово! Ремиксы — это здорово! Протесты в социальных сетях — это здорово! Так общество развивается и создаёт новые формы самовыражения. Знания — производны. Мы учимся на истории и создаём новые версии, которые немного отличаются, но лучше.
Давайте потребуем защиты мемов! Ни один материал не должен быть заморожен авторским правом!
Вся история искусства — это цепочка заимствований, переосмыслений и новых интерпретаций. Шекспир перерабатывал старые сюжеты, музыканты делали каверы, а кинорежиссёры снимали ремейки. Сегодня цифровые технологии позволяют людям создавать новые формы искусства на основе существующих произведений, но корпорации хотят запретить это, превратив культуру в «закрытый клуб».
Наша цель — культура, которая принадлежит людям и авторам, а не так называемым правообладателям!
Вступайте в Пиратскую партию России и присоединяйтесь к борьбе за свободные мемы, открытые лицензии и право на ремиксы. Вместе мы сможем остановить цензуру и сохранить интернет как пространство творчества.
Сообщение Пираты любят мемы появились сначала на Пиратская партия России | PPRU.
Copyright - «Рыбов показываем»: Москвариум планирует запатентовать популярный интернет-мем
Новости в сфере интеллектуальной собственности, информация о патентах.Консультации квалифицированных специалистов.Подборка нормативно - правовых актов по авторскому праву и смежным правамCopyright
Raid israeliano sulla chiesa della Sacra Famiglia a Gaza: ferito padre Romanelli
@Giornalismo e disordine informativo
articolo21.org/2025/07/raid-is…
Raid dell’esercito israeliano sulla chiesa della Sacra Famiglia a Gaza City, unico luogo di culto cattolico della Striscia: due le
Giornalismo e disordine informativo reshared this.
Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Hanno cominciato ad ammazzare cattolici, stai a vedere che adesso comincia a importarcene qualcosa...
La presidente del Consiglio Giorgia Meloni ha condannato l’attacco contro la chiesa e in generale contro la popolazione civile con toni particolarmente duri: in un comunicato ha detto che «sono inaccettabili gli attacchi contro la popolazione civile che Israele sta dimostrando da mesi. Nessuna azione militare può giustificarla.
ilpost.it/2025/07/17/chiesa-sa…

Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Quella della Sacra Famiglia: tre persone sono state uccise e nove ferite, fra cui il parrocoIl Post
Poliversity - Università ricerca e giornalismo reshared this.

reshared this
#Netanyahu e la #Siria in pezzi

Netanyahu e la Siria in pezzi
Lo scioccante bombardamento del palazzo presidenziale e di altri edifici governativi siriani da parte di Israele nella giornata di mercoledì ha dimostrato ancora una volta come non sia possibile intrattenere rapporti paritari con lo stato ebraico, il…www.altrenotizie.org
Non solo Mar Nero. Adesso Kyiv punta ai droni fluviali
@Notizie dall'Italia e dal mondo
Il successo nell’utilizzo degli Unmanned Surface Vessels (Usv), comunemente noti come droni marini, da parte dell’Ucraina è innegabile. Grazie a questi sistemi Kyiv è infatti riuscita a contendere il dominio sul teatro del Mar Nero alla preponderante Flotta russa, costringendola a spostare sempre più a Est le proprie basi per timore di
Notizie dall'Italia e dal mondo reshared this.
Petro: “la Colombia via dalla Nato”
@Notizie dall'Italia e dal mondo
Nel corso della Conferenza su Gaza ospitata dalla Colombia il presidente Petro ha annunciato la volontà di cessare la partnership con l'Alleanza Atlantica
L'articolo Petro: “la Colombia via dalla Nato” proviene da Pagine Esteri.
Notizie dall'Italia e dal mondo reshared this.
Starlink, Tesla und X: Deutschland zahlte über 21 Millionen Euro an Elon Musk
netzpolitik.org/2025/starlink-…

I giornalisti uccisi non hanno bisogno solo di “memoria”, hanno bisogno di impegno
@Giornalismo e disordine informativo
articolo21.org/2025/07/i-giorn…
Per onorare la memoria dei giornalisti uccisi serve verità e giustizia. Il governo agisca di conseguenza. I giornalisti uccisi non
Giornalismo e disordine informativo reshared this.
Bruxelles si mette l’elmetto. Nel budget Ue 131 miliardi per la difesa
@Notizie dall'Italia e dal mondo
Bruxelles (almeno a parole) non scherza sulla Difesa. Con la nuova proposta per il budget pluriennale dell’Unione (2028–2034), la Commissione europea punta a dare un messaggio forte ad Alleati e rivali. Tra le voci principali di spesa (che ammontano complessivamente a due trilioni di euro), spiccano i 131
Notizie dall'Italia e dal mondo reshared this.
Habemus Papam... ma resta la vergogna del Fantapapa.
@Privacy Pride
Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/fantapap…
Non penso che esista qualcosa di leggero o pesante, grande o piccolo, luminoso o oscuro in sé. Occorre un elemento di paragone per definirsi e definire ciò che osserviamo. A volte, il termine di paragone è la legge e questo ci permettere di distinguere i…
Privacy Pride reshared this.
La rivolta degli investitori contro Zuckerberg per lo scandalo Cambridge Analytica
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Con una classa action da 8 miliardi di dollari, gli azionisti citano in giudizio il fondatore di Facebook e altri dirigenti per aver nascosto i rischi legati allo
reshared this
Serbia in rivolta: la repressione non ferma gli studenti
@Notizie dall'Italia e dal mondo
Nonostante arresti, minacce e contro-proteste organizzate dal governo, il movimento studentesco continua a riempire le strade di Belgrado
L'articolo Serbia in rivolta: la repressione non ferma gli pagineesteri.it/2025/07/17/bal…
reshared this
imolaoggi.it/2025/07/15/cipoll…
:")
Cipollone (Bce): "L'euro digitale serve a preservare i benefici del contante" • Imola Oggi
Secondo Cipollone l'euro digitale preserverebbe il ruolo della moneta come bene pubblico accessibile a chiunque e accettato universalmenteImolaOggi (Imola Oggi)
Israele attacca la chiesa cattolica di Gaza: due donne uccise e sei feriti
@Notizie dall'Italia e dal mondo
Colpito il complesso cattolico della Sacra Famiglia, rifugio per centinaia di sfollati. Tra i feriti, padre Romanelli, il sacerdote che parlava quotidianamente con Papa Francesco
L'articolo Israele attacca la chiesa cattolica di Gaza: due donne uccise e sei
Notizie dall'Italia e dal mondo reshared this.

La quiete senza la tempesta
@Giornalismo e disordine informativo
articolo21.org/2025/07/la-quie…
La relazione annuale svoltasi nella mattinata di ieri alla sala Koch del Senato dal presidente dell’Autorità per le garanzie nelle comunicazioni Giacomo Lasorella di per sé non fa una piega. O, meglio, una piega la fa nel passaggio sul copyright, che evoca una difficoltà a incidere
Giornalismo e disordine informativo reshared this.
imolaoggi.it/2025/07/16/armi-a…

Armi a Kiev pagate dalla UE, Tajani: "Gli Usa hanno già fatto molto" • Imola Oggi
Lo ha detto il ministro degli Esteri, Antonio Tajani, parlando ai giornalisti alla residenza dell'ambasciatore d'Italia a Washington. Il capo della diplomaziaImola Oggi
Aiuti a Kyiv, ecco perché l’Italia non acquisterà le armi americane. Parla Nones (Iai)
@Notizie dall'Italia e dal mondo
Negli ultimi mesi Donald Trump ha più volte dichiarato che avrebbe potuto sospendere la fornitura di armamenti all’Ucraina. Ora, invece, ha dato il via libera all’invio di nuove batterie di missili Patriot, il cui costo sarà però coperto dagli Alleati europei. L’Italia, a tal riguardo, ha già
Notizie dall'Italia e dal mondo reshared this.
RFanciola
in reply to Max 🇪🇺🇮🇹 • • •Max 🇪🇺🇮🇹
in reply to RFanciola • •@RFanciola
Io da anni ho problemi nella visione da vicino e li ho risolti ottimamente con gli occhiali da 12-15 euro che vendono in farmacia, adesso però comincio ad aver bisogno anche nella visione da lontano.
Comunque, se mi accorgerò che le lenti progressive non vanno bene al PC (non sei la prima che me lo dice) vorrà dire che per il PC tornerò a usare gli occhiali della farmacia e userò le progressive per tutto il resto.
RFanciola
in reply to Max 🇪🇺🇮🇹 • • •Max 🇪🇺🇮🇹
in reply to RFanciola • •@RFanciola
Purtroppo io non ho modo di valutare la qualità delle lenti, ho a disposizione solo il loro prezzo e la parola dell'ottico secondo cui quelle più costose sono migliori.
RFanciola
in reply to Max 🇪🇺🇮🇹 • • •Al posto suo mi rivolgerei a un secondo ottico e chiederei magari un parere al mio oculista. In ogni caso faccia attenzione allo spessore delle lenti, che ha un'inflienza importante sul prezzo. E non rinunci al trattamento anti-riflesso.
Max 🇪🇺🇮🇹 likes this.