 - Collegamento all'originale")
Il phishing è sempre più difficile da individuare e gli utenti non lo sanno
@Informatica (Italy e non Italy 😁)
Una ricerca di Dojo nel Regno Unito sancisce che il 53% delle persone non è in grado di riconoscere un’e-mail di phishing ma crede di essere in grado di farlo. È un problema serio, perché vuole dire che il phishing è sempre più difficile da individuare e che le persone hanno un lack di formazione
Informatica (Italy e non Italy) reshared this.
MR Browser is the Package Manager Classic Macs Never Had

Homebrew bills itself as the package manager MacOS never had (conveniently ignoring MacPorts) but they leave the PPC crowd criminally under-served, to say nothing of the 68k gang. Enter [that-ben] with MR Browser, a simple utility to fetch software from Macintosh Repository for computers too old to hit up the website.
If you’re not familiar with Macintosh Repository, it is what it says on the tin: a repository of vintage Macintosh software, like Macintosh Garden but apparently less accessible to vintage machines.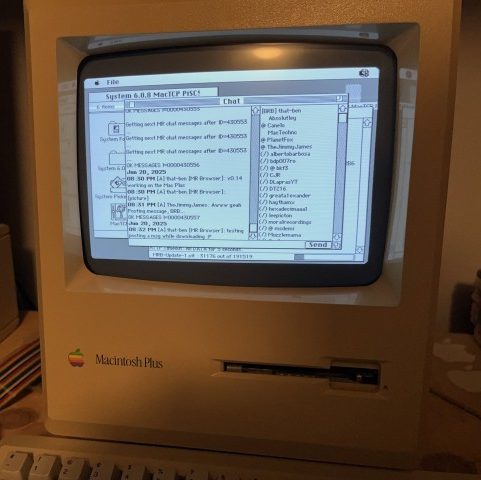
There are two versions available, depending on the age of your machine. For machines running System 6, the appropriately-named MR Browser sys6 will run on any 68000 Mac in only 157 KB of and MacTCP networking. (So the 128K obviously isn’t going to cut it, but a Plus from ’86 would be fine.)
The other version, called MR Browser 68K, ironically won’t run on the 68000. It needs a newer processor (68020 or newer, up-to and including PPC) and TCP/IP networking. Anything starting from the Macintosh II or newer should be game; it’s looking for System 7.x upto the final release of Mac OS 9, 9.2.2. You’ll want to give it at least 3 MB of RAM, but can squeak by on 1.6 MB if you aren’t using pictures in the chat.
Chat? Yes, perhaps uniquely for a software store, there’s a chat function. That’s not so weird when you consider that this program is meant to be a stand-alone interface for the Macintosh Repository website, which does, indeed, have a chat feature. It beats an uncaring algorithm for software recommendations, that’s for sure. Check it out in action in the demo video below.
It’s nice to see people still making utilities to keep the old machines going, even if coding on them isn’t always the easiest. If you want to go online on with vintage hardware (Macintosh or otherwise) anywhere else, you’re virtually locked-out unless you use something like FrogFind.
Thanks to [PlanetFox] for the tip. Submit your own, and you may win fabulous prizes. Not from us, of course, but anything’s possible!
hackaday.com/wp-content/upload…
*
Alice e Bob siamo noi: la crittografia come esperienza umana e quotidiana
@Informatica (Italy e non Italy 😁)
Alice, Bob, Eve, Mallory, Trent, simboli viventi delle sfide reali che affrontiamo ogni giorno nella nostra vita digitale, sono riusciti nell'intento di trasformare la crittografia, da scienza matematica a narrazione, raccontata nel linguaggio umano
Informatica (Italy e non Italy) reshared this.
Dati sensibili, sicurezza nazionale e il nuovo ruolo dello Stato
@Informatica (Italy e non Italy 😁)
Qualche tempo fa il capo della Polizia Vittorio Pisani aveva reclamato un intervento normativo, a livello nazionale, oppure, meglio, europeo, che equiparasse le piattaforme di messaggistica – da whatsapp a Telegram a X, fino alla messaggistica di Apple e Google– agli obblighi che hanno
Informatica (Italy e non Italy) reshared this.
Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio
Negli ultimi anni i modelli di linguaggio di grandi dimensioni (LLM, Large Language Models) come GPT, Claude o LLaMA hanno dimostrato capacità straordinarie nella comprensione e generazione del linguaggio naturale. Tuttavia, dietro le quinte, far funzionare un LLM non è un gioco da ragazzi: richiede una notevole infrastruttura computazionale, un investimento economico consistente e scelte architetturali precise. Cerchiamo di capire perché.
70 miliardi di parametri: cosa significa davvero
Un LLM da 70 miliardi di parametri, come LLaMA 3.3 70B di Meta, contiene al suo interno 70 miliardi di “pesi”, ovvero numeri in virgola mobile (di solito in FP16 o BF16, cioè 2 byte per parametro) che rappresentano le abilità apprese durante l’addestramento. Solo per caricare in memoria questo modello, servono circa:
- 140 GB di RAM GPU (70 miliardi × 2 byte).
A questa cifra vanno aggiunti altri 20-30 GB di VRAM per gestire le operazioni dinamiche durante l’inferenza: cache dei token (KV cache), embedding dei prompt, attivazioni temporanee e overhead di sistema. In totale, un LLM da 70 miliardi di parametri richiede circa 160-180 GB di memoria GPU per funzionare in modo efficiente.
Perché serve la GPU: la CPU non basta
Molti si chiedono: “Perché non far girare il modello su CPU?”. La risposta è semplice: latenza e parallelismo.
Le GPU (Graphics Processing Unit) sono progettate per eseguire milioni di operazioni in parallelo, rendendole ideali per il calcolo tensoriale richiesto dagli LLM. Le CPU, invece, sono ottimizzate per un numero limitato di operazioni sequenziali ad alta complessità. Un modello come LLaMA 3.3 70B può generare una parola ogni 5-10 secondi su CPU, mentre su GPU dedicate può rispondere in meno di un secondo. In un contesto produttivo, questa differenza è inaccettabile.
Inoltre, la VRAM delle GPU di fascia alta (es. NVIDIA A100, H100) consente di mantenere il modello residente in memoria e di sfruttare l’accelerazione hardware per la moltiplicazione di matrici, cuore dell’inferenza LLM.
Un esempio: 100 utenti attivi su un LLM da 70B
Immaginiamo di voler offrire un servizio simile a ChatGPT per la sola generazione di testo, basato su un modello LLM da 70 miliardi di parametri, con 100 utenti attivi contemporaneamente. Supponiamo che ogni utente invii prompt da 300–500 token e si aspetti risposte rapide, con una latenza inferiore a un secondo.
Un modello di queste dimensioni richiede circa 140 GB di memoria GPU per i soli pesi in FP16, a cui vanno aggiunti altri 20–40 GB per la cache dei token (KV cache), attivazioni temporanee e overhead di sistema. Una singola GPU, anche top di gamma, non dispone di sufficiente memoria per eseguire il modello completo, quindi è necessario distribuirlo su più GPU tramite tecniche di tensor parallelism.
Una configurazione tipica prevede la distribuzione del modello su un cluster di 8 GPU A100 da 80 GB, sufficiente sia per caricare il modello in FP16 sia per gestire la memoria necessaria all’inferenza in tempo reale. Tuttavia, per servire contemporaneamente 100 utenti mantenendo una latenza inferiore al secondo per un LLM di queste dimensioni, una singola istanza su 8 GPU A100 (80GB) è generalmente insufficiente.
Per raggiungere l’obiettivo di 100 utenti simultanei con latenza sub-secondo, sarebbe necessaria una combinazione di:
- Un numero significativamente maggiore di GPU A100 (ad esempio, un cluster con 16-32 o più A100 da 80GB), distribuite su più POD o in un’unica configurazione più grande.
- L’adozione di GPU di nuova generazione come le NVIDIA H100, che offrono un netto miglioramento in termini di throughput e latenza per l’inferenza di LLM, però ad un costo maggiore.
- Massimizzare le ottimizzazioni software, come l’uso di framework di inferenza avanzati (es. vLLM, NVIDIA TensorRT-LLM) con tecniche come paged attention e dynamic batching.
- L’implementazione della quantizzazione (passando da FP16 a FP8 o INT8/INT4), che ridurrebbe drasticamente i requisiti di memoria e aumenterebbe la velocità di calcolo, ma con una possibile conseguente perdita di qualità dell’output generato (soprattutto per la quantizzazione INT4).
Per scalare ulteriormente, è possibile replicare queste istanze su più GPU POD, abilitando la gestione di migliaia di utenti totali in modo asincrono e bilanciato, in base al traffico in ingresso. Naturalmente, oltre alla pura inferenza, è fondamentale prevedere risorse aggiuntive per:
- Scalabilità dinamica in funzione della domanda.
- Bilanciamento del carico tra istanze.
- Logging, monitoraggio, orchestrazione e sicurezza dei dati.
Ma quanto costa un’infrastruttura di questo tipo?
L’implementazione on-premise richiede centinaia di migliaia di euro di investimento iniziale, cui si aggiungono i costi annuali di gestione, alimentazione e personale. In alternativa, i principali provider cloud offrono risorse equivalenti ad un costo mensile molto più accessibile e flessibile. Tuttavia, è importante sottolineare che anche in cloud, una configurazione hardware capace di gestire un tale carico in tempo reale può comportare costi mensili che facilmente superano le decine di migliaia di euro, se non di più, a seconda dell’utilizzo.
In entrambi i casi, emerge con chiarezza come l’impiego di LLM di grandi dimensioni rappresenti non solo una sfida algoritmica, ma anche infrastrutturale ed economica, rendendo sempre più rilevante la ricerca di modelli più efficienti e leggeri.
On-premise o API? La riservatezza cambia le carte in tavola
Un’alternativa semplice per molte aziende è usare le API di provider esterni come OpenAI, Anthropic o Google. Tuttavia, quando entrano in gioco la riservatezza e la criticità dei dati, l’approccio cambia radicalmente. Se i dati da elaborare includono informazioni sensibili o personali (ad esempio cartelle cliniche, piani industriali o atti giudiziari), inviarli a servizi cloud esterni può entrare in conflitto con i requisiti del GDPR, in particolare rispetto al trasferimento transfrontaliero dei dati e al principio di minimizzazione.
Anche molte policy aziendali basate su standard di sicurezza come ISO/IEC 27001 prevedono il trattamento di dati critici in ambienti controllati, auditabili e localizzati.
Inoltre, con l’entrata in vigore del Regolamento Europeo sull’Intelligenza Artificiale (AI Act), i fornitori e gli utilizzatori di sistemi di AI devono garantire tracciabilità, trasparenza, sicurezza e supervisione umana, soprattutto se il modello è impiegato in contesti ad alto rischio (finanza, sanità, istruzione, giustizia). L’uso di LLM attraverso API cloud può rendere impossibile rispettare tali obblighi, in quanto l’inferenza e la gestione dei dati avvengono fuori dal controllo diretto dell’organizzazione.
In questi casi, l’unica opzione realmente compatibile con gli standard normativi e di sicurezza è adottare un’infrastruttura on-premise o un cloud privato dedicato, dove:
- Il controllo sui dati è totale;
- L’inferenza avviene in un ambiente chiuso e conforme;
- Le metriche di auditing, logging e accountability sono gestite internamente.
Questo approccio consente di preservare la sovranità digitale e la conformità a GDPR, ISO 27001 e AI Act, pur richiedendo un effort tecnico ed economico significativo.
Conclusioni: tra potenza e controllo
Mettere in servizio un LLM non è solo una sfida algoritmica, ma soprattutto un’impresa infrastrutturale, fatta di hardware specializzato, ottimizzazioni complesse, costi energetici elevati e vincoli di latenza. I modelli di punta richiedono cluster da decine di GPU, con investimenti che vanno da centinaia di migliaia fino a milioni di euro l’anno per garantire un servizio scalabile, veloce e affidabile.
Un’ultima, ma fondamentale considerazione riguarda l’impatto ambientale di questi sistemi. I grandi modelli consumano enormi quantità di energia elettrica, sia in fase di addestramento che di inferenza. Con l’aumentare dell’adozione di LLM, diventa urgente sviluppare modelli più piccoli, più leggeri e più efficienti, che riescano a offrire prestazioni comparabili a fronte di un footprint computazionale (ed energetico) significativamente ridotto.
Come è accaduto in ogni evoluzione tecnologica — dal personal computer ai telefoni cellulari — l’efficienza è la chiave della maturità: non servono sempre modelli più grandi, ma modelli più intelligenti, più adattivi e sostenibili.
L'articolo Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio proviene da il blog della sicurezza informatica.



Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Hanno cominciato ad ammazzare cattolici, stai a vedere che adesso comincia a importarcene qualcosa...
La presidente del Consiglio Giorgia Meloni ha condannato l’attacco contro la chiesa e in generale contro la popolazione civile con toni particolarmente duri: in un comunicato ha detto che «sono inaccettabili gli attacchi contro la popolazione civile che Israele sta dimostrando da mesi. Nessuna azione militare può giustificarla.
ilpost.it/2025/07/17/chiesa-sa…

Israele ha attaccato l’unica chiesa cattolica nella Striscia di Gaza
Quella della Sacra Famiglia: tre persone sono state uccise e nove ferite, fra cui il parrocoIl Post
Poliversity - Università ricerca e giornalismo reshared this.

reshared this
#Netanyahu e la #Siria in pezzi

Netanyahu e la Siria in pezzi
Lo scioccante bombardamento del palazzo presidenziale e di altri edifici governativi siriani da parte di Israele nella giornata di mercoledì ha dimostrato ancora una volta come non sia possibile intrattenere rapporti paritari con lo stato ebraico, il…www.altrenotizie.org
Non solo Mar Nero. Adesso Kyiv punta ai droni fluviali
@Notizie dall'Italia e dal mondo
Il successo nell’utilizzo degli Unmanned Surface Vessels (Usv), comunemente noti come droni marini, da parte dell’Ucraina è innegabile. Grazie a questi sistemi Kyiv è infatti riuscita a contendere il dominio sul teatro del Mar Nero alla preponderante Flotta russa, costringendola a spostare sempre più a Est le proprie basi per timore di
Notizie dall'Italia e dal mondo reshared this.
Petro: “la Colombia via dalla Nato”
@Notizie dall'Italia e dal mondo
Nel corso della Conferenza su Gaza ospitata dalla Colombia il presidente Petro ha annunciato la volontà di cessare la partnership con l'Alleanza Atlantica
L'articolo Petro: “la Colombia via dalla Nato” proviene da Pagine Esteri.
Notizie dall'Italia e dal mondo reshared this.
Bruxelles si mette l’elmetto. Nel budget Ue 131 miliardi per la difesa
@Notizie dall'Italia e dal mondo
Bruxelles (almeno a parole) non scherza sulla Difesa. Con la nuova proposta per il budget pluriennale dell’Unione (2028–2034), la Commissione europea punta a dare un messaggio forte ad Alleati e rivali. Tra le voci principali di spesa (che ammontano complessivamente a due trilioni di euro), spiccano i 131
Notizie dall'Italia e dal mondo reshared this.
Habemus Papam... ma resta la vergogna del Fantapapa.
@Privacy Pride
Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/fantapap…
Non penso che esista qualcosa di leggero o pesante, grande o piccolo, luminoso o oscuro in sé. Occorre un elemento di paragone per definirsi e definire ciò che osserviamo. A volte, il termine di paragone è la legge e questo ci permettere di distinguere i…
Privacy Pride reshared this.
La rivolta degli investitori contro Zuckerberg per lo scandalo Cambridge Analytica
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
Con una classa action da 8 miliardi di dollari, gli azionisti citano in giudizio il fondatore di Facebook e altri dirigenti per aver nascosto i rischi legati allo
reshared this
Serbia in rivolta: la repressione non ferma gli studenti
@Notizie dall'Italia e dal mondo
Nonostante arresti, minacce e contro-proteste organizzate dal governo, il movimento studentesco continua a riempire le strade di Belgrado
L'articolo Serbia in rivolta: la repressione non ferma gli pagineesteri.it/2025/07/17/bal…
reshared this
imolaoggi.it/2025/07/15/cipoll…
:")
Cipollone (Bce): "L'euro digitale serve a preservare i benefici del contante" • Imola Oggi
Secondo Cipollone l'euro digitale preserverebbe il ruolo della moneta come bene pubblico accessibile a chiunque e accettato universalmenteImolaOggi (Imola Oggi)
Israele attacca la chiesa cattolica di Gaza: due donne uccise e sei feriti
@Notizie dall'Italia e dal mondo
Colpito il complesso cattolico della Sacra Famiglia, rifugio per centinaia di sfollati. Tra i feriti, padre Romanelli, il sacerdote che parlava quotidianamente con Papa Francesco
L'articolo Israele attacca la chiesa cattolica di Gaza: due donne uccise e sei
Notizie dall'Italia e dal mondo reshared this.

imolaoggi.it/2025/07/16/armi-a…

Armi a Kiev pagate dalla UE, Tajani: "Gli Usa hanno già fatto molto" • Imola Oggi
Lo ha detto il ministro degli Esteri, Antonio Tajani, parlando ai giornalisti alla residenza dell'ambasciatore d'Italia a Washington. Il capo della diplomaziaImola Oggi
Aiuti a Kyiv, ecco perché l’Italia non acquisterà le armi americane. Parla Nones (Iai)
@Notizie dall'Italia e dal mondo
Negli ultimi mesi Donald Trump ha più volte dichiarato che avrebbe potuto sospendere la fornitura di armamenti all’Ucraina. Ora, invece, ha dato il via libera all’invio di nuove batterie di missili Patriot, il cui costo sarà però coperto dagli Alleati europei. L’Italia, a tal riguardo, ha già
Notizie dall'Italia e dal mondo reshared this.
imolaoggi.it/2025/07/15/dazi-u…

Dazi Usa, Francia contro Trump: 'non siamo vassalli' • Imola Oggi
Lo ha detto Jean-Noel Barrot, Ministro per gli Affari europei e gli Affari esteri della Francia, a Bruxelles.ImolaOggi (Imola Oggi)
Finalmente si vedono Paesi con "le palle", come Dio comanda, altro che i fanfaroni ue, Usa e di Palazzo Chigi.
lindipendente.online/2025/07/1…

In Colombia il Sud Globale annuncia misure concrete contro il genocidio a Gaza - L'INDIPENDENTE
Dodici Paesi del cosiddetto “Sud Globale” hanno deciso di adottare immediatamente misure concrete per fermare il genocidio a Gaza.Dario Lucisano (Lindipendente.online)
lindipendente.online/2025/07/1…

In Colombia il Sud Globale annuncia misure concrete contro il genocidio a Gaza - L'INDIPENDENTE
Dodici Paesi del cosiddetto “Sud Globale” hanno deciso di adottare immediatamente misure concrete per fermare il genocidio a Gaza.Dario Lucisano (Lindipendente.online)
Reintrodurre l’immunità parlamentare per ridare dignità e forza alla politica
@Politica interna, europea e internazionale
L'articolo Reintrodurre l’immunità parlamentare per ridare dignità e forza alla politica proviene da Fondazione Luigi Einaudi.
Politica interna, europea e internazionale reshared this.
Son contento delle belle energie che si stanno aggregando attorno a questo nuovo progetto, ossia la prima edizione del Velletri Buskers Festival, del quale posto ora una locandina, che ho realizzato personalmente con tanto amore, e anche con l'aiuto dell'interferenza artigianale, la quale mi ha permesso, con una di quelle che chiamo "foto dal futuro", di rendere bene l'idea della magia che vogliamo creare sulle pittoresche vie del centro storico e tutto intorno alla Torre Del Trivio, uno dei simboli più caratteristici di questa antica città. L'altro giorno ho fatto anche un sopralluogo tecnico tra i vicoli di Velletri, ebbene, non ho trovato neanche un centimetro quadro di terreno che non fosse in sanpietrino e in leggera pendenza, che come tutti sanno è proprio il tipo di terreno preferito dai circensi (🤣), perché gli pone sfide sempre diverse e non li fa annoiare mai. Del resto che vuoi fare, la cittadina è arroccata su un promontorio collinare a più di quattrocento metri sul livello mare. E infatti si sta una favola, tira proprio una bella arietta, il tipico posto dove vorresti stare alle 19.00 a fare l'aperitivo mentre a Roma si fa la schiuma fortissimo. Quindi insomma, save the date: 19 Luglio, prima edizione del Velletri Buskers Festival, e chi non viene fa la schiuma, fortissimo 🙌😅
#Valletri #Buskers #festival #eventi #roma #lazio

like this
reshared this
freezonemagazine.com/news/mich…
In libreria dal 1 Agosto 2025 Con Diavolìade di Michail Bulgakov, Mattioli 1885 arricchisce la collana Light, dedicata ai classici in forma agile e curata. A firmare l’introduzione di questo nuovo titolo è Paolo Nori, che studia la letteratura russa da tutta la vita e guida il lettore nel racconto furioso e grottesco di Bulgakov con voce appassionata […]
L'articolo Michail Bulgakov – Diavolìade

Il bagno dopo mangiato
Ogni anno, puntuale come le zanzare e i tormentoni estivi, torna anche una delle leggende urbane più diffuse sulla nostra penisola: “Hai appena mangiato! Niente bagno per tre ore!” e altrettanto puntualmente arrivano articoli sui quotidiani a ribadir…maicolengel butac (Butac – Bufale Un Tanto Al Chilo)
Ucraina. Zelensky corteggia Trump con un “governo Maga”
@Notizie dall'Italia e dal mondo
«L‘Ucraina ha bisogno di dinamiche più positive nei rapporti con gli Stati Uniti» ha spiegato Zelensky. Trump ha convinto l'Europa a pagare le armi che Washington invierà a Kiev
L'articolo Ucraina. Zelensky corteggia Trump pagineesteri.it/2025/07/17/mon…
Notizie dall'Italia e dal mondo reshared this.
Come TikTok, AliExpress e WeChat ignorano i vostri diritti GDPR Tutte e tre le società non hanno risposto adeguatamente alle richieste di accesso dei denuncianti mickey17 July 2025
UNA GUIDA DI EUROPOL SPIEGA ALLE FORZE DELL'ORDINE COME SUPERARE I PREGIUDIZI DELL'INTELLIGENZA ARTIFICIALE

"Pregiudizi dell'intelligenza artificiale nelle forze dell'ordine: una guida pratica", recente pubblicazione di Europol (Innovation Lab), esplora i metodi per prevenire, identificare e mitigare i rischi nelle varie fasi dell'implementazione dell'intelligenza artificiale.
Il rapporto mira a fornire alle forze dell’ordine linee guida chiare su come implementare le tecnologie di intelligenza artificiale salvaguardando i diritti fondamentali.
L’intelligenza artificiale può essere una risorsa importante per le forze dell’ordine, per rafforzare le proprie capacità di combattere le minacce emergenti (amplificate dalla digitalizzazione) attraverso l’integrazione di nuove soluzioni tecniche, quali come la polizia predittiva, l'identificazione automatica di pattern e l'analisi avanzata dei dati.
L’intelligenza artificiale può aiutare le forze dell’ordine: a. ad analizzare set di dati ampi e complessi, b. automatizzare compiti ripetitivi e c. supportare un processo decisionale più informato.
Impiegata in modo responsabile, può potenziare le capacità operative e migliorare la sicurezza pubblica.

Tuttavia, questi benefici devono essere attentamente valutati rispetto ai possibili rischi posti dai pregiudizi (intesi come una tendenza o inclinazione che si traduce in un giudizio ingiusto o in un pregiudizio a favore o contro una persona, un gruppo o un'idea) sull'utilizzo, che possono apparire in varie fasi di sviluppo e implementazione del sistema di intelligenza artificiale.
Questi rischi derivano da pregiudizi insiti nella progettazione, nello sviluppo e nell'implementazione dei sistemi di intelligenza artificiale, che possono perpetuare la discriminazione, rafforzare le disuguaglianze sociali e compromettere l'integrità delle attività delle forze dell'ordine.
Tali pregiudizi devono essere controllati per garantire risultati equi, mantenere la fiducia del pubblico e proteggere i diritti fondamentali. Il rapporto fornisce alle autorità di contrasto le intuizioni e le indicazioni necessarie per identificare, mitigare e prevenire pregiudizi nei sistemi di intelligenza artificiale. Questa conoscenza può svolgere un ruolo cruciale nel sostenere l’adozione sicura ed etica dell’intelligenza artificiale per garantire che la tecnologia venga utilizzata in modo efficace, equo e trasparente al servizio della sicurezza pubblica.

Le Raccomandazioni chiave per le forze dell'ordine che emergono dal Rapporto riguardano:
- Documento: mantenere una documentazione dettagliata di tutte le fasi del ciclo di vita dell'IA. Ciò garantisce tracciabilità, responsabilità e aiuta a identificare dove possono verificarsi pregiudizi.
- Valutare: sviluppare un quadro socio-tecnico completo, coinvolgendo un gruppo eterogeneo di parti interessate, per valutare l'accuratezza tecnica e considerare attentamente i contesti storici, sociali e demografici.
- Formare tutto il personale delle forze dell’ordine coinvolto con gli strumenti di intelligenza artificiale per approfondire la propria comprensione delle tecnologie di intelligenza artificiale per enfatizzare il valore della valutazione umana nella revisione dei risultati generati dall’intelligenza artificiale per prevenire pregiudizi.
- Testare le prestazioni, l'impatto e rivedere gli indicatori di potenziale distorsione prima dell'implementazione.
- Eseguire analisi caso per caso e addestrarsi a comprendere i diversi pregiudizi dell’intelligenza artificiale, la loro relazione con i parametri di equità e implementare metodi di mitigazione dei pregiudizi.
- Valutare continuamente attraverso l'implementazione di test regolari e la rivalutazione dei modelli di intelligenza artificiale durante tutto il loro ciclo di vita per rilevare e mitigare i pregiudizi.
- Applicare tecniche di test di equità e di mitigazione dei pregiudizi post-elaborazione sia sugli output del sistema di intelligenza artificiale che sulle decisioni finali prese da esperti umani che si affidano a tali output.
- Valutare il contesto e gli obiettivi di ciascuna applicazione di intelligenza artificiale, allineando le misure di equità con gli obiettivi operativi per garantire risultati sia etici che efficaci.
- Garantire la coerenza contestuale e statistica durante l’implementazione dei modelli di intelligenza artificiale.
- Standardizzare i parametri di equità e le strategie di mitigazione in tutta l’organizzazione per garantire pratiche coerenti nella valutazione dei pregiudizi.

Informazioni sull'Innovation Lab di Europol
Il Lab mira a identificare, promuovere e sviluppare soluzioni innovative concrete a sostegno del lavoro operativo degli Stati membri dell'UE’. Ciò aiuta investigatori e analisti a sfruttare al meglio le opportunità offerte dalle nuove tecnologie per evitare la duplicazione del lavoro, creare sinergie e mettere in comune le risorse.
Le attività del laboratorio sono direttamente collegate alle priorità strategiche stabilite nella strategia Europol Fornire sicurezza in partenariato, in cui si afferma che Europol sarà in prima linea nell'innovazione e nella ricerca delle forze dell'ordine.
Il lavoro del Laboratorio di innovazione Europol è organizzato attorno a quattro pilastri: gestione di progetti al servizio delle esigenze operative della comunità delle forze dell'ordine dell'UE; monitorare gli sviluppi tecnologici rilevanti per le forze dell'ordine; mantenimento di reti di esperti; in qualità di segretariato del polo di innovazione dell'UE per la sicurezza interna.
La pubblicazione [en] è scaricabile qui europol.europa.eu/publications…
like this
reshared this

L’Italia è in semifinale agli Europei femminili di calcio
Ha battuto 2-1 la Norvegia, dopo una partita molto combattuta e decisa all'ultimo minuto: non ci riusciva dal 1997Il Post
reshared this
Slugterra Mazzo sfida Fiamma Brillante. Nuovo integro. - Questo è un post automatico da FediMercatino.it

Prezzo: 0 Euro
Slugterra Mazzo sfida Fiamma Brillante. Nuovo integro.
Non solo libri, fumetti, riviste, manifesti cinema.
Il Blog si rinnova quotidianamente e con articoli sempre più vari e disponibili per i più attenti.
Dovete sapere che anche un regalo bisogna meritarselo ed in questo caso vale il detto:
Chi primo arriva meglio alloggia.
Alla prossima.
videodavederecondividere.alter…
Il Blog delle occasioni a costo zero.
Il Mercatino del Fediverso 💵♻️ reshared this.
AOC AGON AG241QX 23,8 Zoll Monitor 2560 x 1440 144Hz - Questo è un post automatico da FediMercatino.it
Prezzo: 50 €
Verkaufe einen gut erhaltenen und 1A funktionierenden Monitor (AOC AGON AG241QX 60,5cm (23,8 Zoll) Monitor (Displayport, DVI, HDMI, 4 x USB 3.0, 2560 x 1440, 144 Hz, 1ms) wegen Neuanschaffung.
Il Mercatino del Fediverso 💵♻️ reshared this.
#Francia, armi e austerity o La guerra di classe di #Macron

Francia, armi e austerity
La presentazione del bilancio pubblico per l’anno 2026 del primo ministro, François Bayrou, ha dato un’anticipazione piuttosto chiara delle misure drastiche di riduzione della spesa sociale che attendono non solo la Francia, ma anche molti degli altr…www.altrenotizie.org
presentazione di oggettistica @ libreria panisperna, qualche tempo fa: youtube.com/watch?v=YKnfAp8Ksa…
Poliversity - Università ricerca e giornalismo reshared this.
Per l’IA agentica il Pentagono guarda ad Anthropic, Google e xAI. Ecco i dettagli
@Notizie dall'Italia e dal mondo
Il Pentagono ha deciso di scommettere in grande sull’intelligenza artificiale commerciale di frontiera. La mattina del 14 luglio il chief digital and artificial intelligence office (Cdao) del Dipartimento della Difesa ha annunciato l’assegnazione di 600
Notizie dall'Italia e dal mondo reshared this.
Altbot
in reply to Adriano Bono • • •L'immagine promuove il "Velletri Buskers Festival," la prima edizione del quale si terrà sabato 19 luglio. Il festival, organizzato dal Comune di Velletri con la collaborazione della Pro Loco Velletrae, si svolgerà in Piazza Cairoli a Velletri, con The Reggae Circus in programma alle 19.30, seguito da artisti di strada dalle 20.00. L'evento è parte del "Giubileo dei Giovani" e si svolgerà "Sognando per le vie del centro." La copertina dell'immagine mostra una donna che esegue una performance di fuochi d'artificio, con le fiamme che si stagliano contro il cielo notturno. Sullo sfondo, si intravede un edificio storico, probabilmente una chiesa, con una torre illuminata. Il testo è in italiano e fornisce informazioni dettagliate sull'evento, inclusi il luogo, l'orario e i contatti per ulteriori informazioni.
Fornito da @altbot, generato localmente e privatamente utilizzando Ovis2-8B
🌱 Energia utilizzata: 0.274 Wh
Zughy
in reply to Adriano Bono • • •Re: Son contento delle belle energie che si stanno aggregando attorno a questo nuovo progetto, ossia la prima edizione del Velletri Buskers Festival, del quale posto ora una locandina, che ho realizzato personalmente con tanto amore, e anche con l'aiuto d
Adriano Bono likes this.
Adriano Bono
in reply to Zughy • •youtube.com/shorts/dBnQQZ9NQA8
Lazio reshared this.