 - Collegamento all'originale")
The Unusual Suspect: quando i repo Git aprono la porta sul retro
Nel mondo della cybersecurity siamo abituati a dare la caccia ai mostri: APT, 0-day, malware super avanzati, ransomware con countdown da film di Hollywood. Ma intanto, nei corridoi silenziosi del codice sorgente, si consumano le vere tragedie. Silenziose, costanti, banali. Repository Git pieni zeppi di credenziali, token, chiavi API e variabili di ambiente spiattellate come fosse la bacheca dell’oratorio.
La notizia la riporta The Hacker News: una nuova campagna di attacchi, soprannominata “The Unusual Suspect”, sfrutta repository Git pubblici e privati per accedere ad ambienti cloud, pipeline CI/CD e database interni, con una facilità che fa più paura di un exploit zero-click. Non c’è magia nera. Non c’è necessità di brute force o social engineering. Serve solo un po’ di pazienza, un motore di ricerca, e… la dabbenaggine di chi commit(a) i segreti senza pensarci due volte.
Il codice è il nuovo perimetro. Ma qualcuno non ha ricevuto la notifica.
L’attacco si basa su una verità semplice, ma devastante: i repository Git sono ormai il centro di gravità permanente del software moderno. Contengono tutto. Codice, configurazioni, log, cronjob, script bash di provisioning, playbook Ansible. E in mezzo a tutta questa roba, spesso ci scappano – anzi, ci cascano – anche file .env, chiavi SSH, config.yml con hardcoded credentials e token OAuth lasciati lì “per fare prima”.
Gli attaccanti lo sanno bene. E lo sfruttano. Con tool automatizzati che scandagliano milioni di repo alla ricerca di stringhe sospette, API key note, access token e pattern classici (AKIA..., ghp_..., eyJhbGciOi...). Appena trovano l’ingresso, entrano. E non bussano.
Il caso tj-actions/changed-files: 23.000 repo esposti, nessuna pietà
A marzo 2025 esplode uno dei casi più eclatanti dell’anno. Una GitHub Action molto usata — tj-actions/changed-files — viene modificata da un attaccante che ha trafugato un GitHub PAT. La nuova versione? Una trappola perfetta: stampa nei log tutte le secrets disponibili nel runner CI/CD. Tutte. E quei log, tanto per gradire, sono pubblici.
Risultato? Migliaia di repository, aziende e sviluppatori si sono ritrovati con le mutande digitali abbassate in piazza. Le loro chiavi AWS, token GCP, PAT GitHub, chiavi Stripe o Twilio… tutte lì, nei log. A disposizione di chiunque sapesse cosa cercare. E gli attaccanti hanno cercato. Eccome se hanno cercato.
L’obiettivo? Non tanto la Action in sé, ma i progetti target che ne facevano uso. Come coinbase/agentkit. Sì, proprio Coinbase. Non stiamo parlando della startup sotto casa.
Non è un problema tecnico. È un problema culturale.
La cosa che fa più rabbia non è l’attacco in sé, ma quanto fosse evitabile. Bastava usare l’hash del commit anziché il tag v4. Bastava fare secret scanning prima del push. Bastava configurare correttamente i permessi delle GitHub Actions. Ma no. Il Dev scrive, commit(a), push(a) e via andare. “Ci penserà qualcun altro a fare la security”. Ecco, news flash: quel qualcun altro non c’è. E quando l’attacco arriva, è sempre troppo tardi.
Qui non serve un patch di sicurezza. Serve una riscrittura del DNA operativo. I repo vanno trattati come asset critici. Le pipeline come potenziali vettori d’attacco. I file .env devono sparire dai commit come le password scritte sui post-it. E i dev devono capire che non sono solo coder, ma i primi difensori dell’infrastruttura.
La CI/CD è il nuovo campo minato
La vera bomba di questi attacchi non è solo l’ingresso iniziale. È ciò che succede dopo. Perché attraverso la CI/CD, l’attaccante può fare praticamente tutto: modificare gli artefatti, inserire backdoor, distribuire payload nei container, creare persistenza nei Lambda, oppure fare exfiltration tranquillo via S3. Tutto questo passando per runner CI pubblici, spesso non monitorati, senza EDR, senza SIEM, e con più privilegi di quanto dovrebbe avere un pentester col cappello bianco.
Se lasci il cancello della pipeline aperto, l’attacco è solo una questione di tempo.
La realtà? È che in troppi stanno dormendo
In questo momento, ci sono migliaia di repository Git con chiavi valide committate. Alcune da sviluppatori freelance che non hanno idea del rischio. Altre da aziende grandi, blasonate, piene di certificazioni ISO e badge SOC2 sul sito. Tutti convinti che “tanto chi vuoi che ci guardi?”. Ma gli attaccanti guardano. E guardano molto più in profondità di quanto crediate.
Questa non è paranoia. È cronaca. E se non iniziamo a trattare i repository come asset strategici, finiranno per essere l’anello debole che ci farà crollare addosso tutta l’impalcatura.
Conclusione
Questa storia ci insegna una cosa: la sicurezza moderna non ha bisogno di eroi, ma di disciplina. Di processi. Di controlli. Di cultura. Perché oggi, più che mai, un semplice git push può diventare l’inizio della fine.
Il nemico non bussa più alla porta. Passa dal repository.
L'articolo The Unusual Suspect: quando i repo Git aprono la porta sul retro proviene da il blog della sicurezza informatica.
CDN friendica reshared this.
Time, Stars, and Tides, All On Your Wrist

When asked ‘what makes you tick?’ the engineers at Vacheron Constantin sure know what to answer – and fast, too. Less than a year after last year’s horological kettlebell, the 960g Berkley Grand Complication, a new invention had to be worked out. And so, they delivered. Vacheron Constantin’s Solaria Ultra Grand Complication is more than just the world’s most complicated wristwatch. It’s a fine bit of precision engineering, packed with 41 complications, 13 pending patents, and a real-time star tracker the size of a 2-Euro coin.
Yes, there’s a Westminster chime and a tourbillon, but the real novelty is a dual-sapphire sky chart that lets you track constellations using a split-second chronograph. Start the chrono at dusk, aim your arrow at the stars, and it’ll tell you when a chosen star will appear overhead that night.
Built by a single watchmaker over eight years, the 36mm-wide movement houses 1,521 parts and 204 jewels. Despite the mad complexity, the watch stays wearable at just 45mm wide and 15mm thick, smaller than your average Seamaster. This is a wonder of analog computational mechanics. Just before you think of getting it gifted for Christmas, think twice – rumors are it’ll be quite pricey.

2025 One-Hertz Challenge: HP Logic Probe Brought Into The Future

[Robert Morrison] had an ancient HP 545A logic probe, which was great for debugging SMT projects. The only problem was that being 45 years old, it wasn’t quite up to scratch when it came to debugging today’s faster circuitry. Thus, he hacked it to do better, and entered it in our 2025 One Hertz Challenge to boot!
[Robert’s] hack relied on the classic logic probe for its stout build and form factor, which is still useful even on today’s smaller hardware. Where it was lacking was in dealing with circuits running at 100 MHz and above. To rectify this, [Robert] gave the probe a brain transplant with a Sparkfun Alorium FPGA board and a small display. The FPGA is programmed to count pulses while measuring pulse widths and time, and it then drives the display to show this data to the user. There’s also a UART output, and [Robert] is actively developing further logic analyzer features, too.
You might be questioning how this project fits in the One Hertz Challenge, given it’s specifically built for running at quite high speeds. [Robert] snuck it in under the line because it resamples and updates the display on a once-a-second basis. Remember, as per the challenge site—”For this challenge, we want you to design a device where something happens once per second.” We’re giving you a lot of leeway here!
Often, old scopes and probes and other gear are really well built. Sometimes, it’s worth taking the best of the old physical hardware and combining it with modern upgrades to make something stout that’s still useful today. Meanwhile, if you’re cooking up your own neo-retro-logic probes, don’t hesitate to notify the tipsline!


lindipendente.online/2025/07/1…
Antonej likes this.
Hackaday Podcast Episode 329: AI Surgery, a Prison Camp Lathe, and a One Hertz Four-Fer

Join Hackaday Editors Elliot Williams and Tom Nardi as they talk about their favorite hacks and stories from the previous week. They’ll start things off with a small Supercon update, and go right into fusion reactors, AI surgeons, planned obsolescence, and robotic cats and dogs. They’ll also go over several entries from the ongoing 2025 One Hertz Challenge, an ambitious flight simulator restoration project, old school lightning detectors, and how Blu-ray won the battle against HD DVD but lost the war against streaming. Stick around to the end to hear an incredible story about a clandestine machine shop in a WWII prisoner of war camp, and the valiant fight to restore communications with the Lunar Trailblazer spacecraft.
Check out the links below if you want to follow along, and as always, tell us what you think about this episode in the comments!
html5-player.libsyn.com/embed/…
Download in DRM-free MP3 and add it to your collection.
Where to Follow Hackaday Podcast
Places to follow Hackaday podcasts:
Episode 329 Show Notes:
News:
What’s that Sound?
- Think you know that sound? Fill out the form for a chance to win a Hackaday Podcast T-Shirt!
Interesting Hacks of the Week:
- Do You Trust This AI For Your Surgery?
- Will HP Create A Carfax System For PCs?
- A Budget Quasi-Direct-Drive Motor Inspired By MIT’s Mini Cheetah
- Robotic Cheetah Teaches A Motors Class
- From Leash To Locomotion: CARA The Robotic Dog
- What Will It Take To Restore A Serious Flight Simulator?
- 2025 One Hertz Challenge: An Ancient Transistor Counts The Seconds
- Michael Covington’s Daily Notebook
- 2025 One Hertz Challenge: Ham Radio Foxhunt Transmitter
- 2025 One Hertz Challenge: Valvano Clock Makes The Seconds Count
- 2025 One Hertz Challenge: Metronalmost Is Gunning For Last Place
Quick Hacks:
- Elliot’s Picks:
- Introducing PooLA Filament: Grass Fiber-Reinforced PLA
- A Collection Of Lightning Detectors
- USB-C Rainbow Ranger: Sensing Volts With Style
- Coroutines In C
- Tom’s Picks:
- Smart Coffee Table To Guide Your Commute
- Blu-ray Won, But At What Cost?
- This Homebrew CPU Got Its Start In The 1990s
Can’t-Miss Articles:
- Hacking When It Counts: DIY Prosthetics And The Prison Camp Lathe
- The Fight To Save Lunar Trailblazer
hackaday.com/2025/07/18/hackad…
Ecco Divergent, l’emerging tech Usa che punta a rilanciare l’industria della Difesa
@Notizie dall'Italia e dal mondo
L’amministrazione Trump ha individuato uno dei suoi principali obiettivi strategici nella ricostruzione della base industriale della difesa statunitense, in difficoltà ormai da diversi anni. In questo contesto si inserisce Divergent Technologies, una
Notizie dall'Italia e dal mondo reshared this.
Scheda elletronica caldaia Aprilia/provincia Latina 40km da Roma - Questo è un post automatico da FediMercatino.it

Prezzo: 200€ $200
Scheda elletronica di una caldaia Riello,la scheda è perfettamente funzionante.
Per la consegna se sei vicino Roma abito a 40 km da Roma ad Aprilia provincia di Latina
Il Mercatino del Fediverso 💵♻️ reshared this.
Dal Baltico al Mar Nero, così la Nato rinforza il fianco orientale contro la Russia
@Notizie dall'Italia e dal mondo
La Nato si prepara a irrobustire la sua presenza sul Fianco Est dell’Alleanza e lo fa con un nuovo piano operativo, rinominato Eastern flank deterrence line. Presentato a Wiesbaden dal generale Christopher Donahue, comandante delle forze Usa in Europa, la nuova strategia guarda alla difesa terrestre
Notizie dall'Italia e dal mondo reshared this.
Si fa presto a dire CISO
@Informatica (Italy e non Italy 😁)
La gestione della sicurezza informatica è un tema complesso e in continua evoluzione e la figura del CISO può fornire un apporto di primaria importanza per le strategie delle organizzazioni. Ma ogni incertezza sul ruolo o sulle competenze si traduce in un rischio nell'affrontare le sfide e le minacce della sicurezza delle informazioni
Informatica (Italy e non Italy) reshared this.
Unlocking the Potential of a No-Name Handheld Game

The rise of inexpensive yet relatively powerful electronics has enabled a huge array of computing options that would have been unheard of even two decades ago. A handheld gaming PC with hours of battery life, for example, would have been impossible or extremely expensive until recently. But this revolution has also enabled a swath of inexpensive but low-quality knockoff consoles, often running unlicensed games, that might not even reach the low bar of quality set by their sellers. [Jorisclayton] was able to modify one of these to live up to its original promises.
This Ultimate Brick Game, as it is called, originally didn’t even boast the number of games, unlicensed or otherwise, that it claimed to. [Jorisclayton] removed almost all of the internals from this small handheld to help it live up to this original claim. It boasts a Raspberry Pi Zero 2W now as well as a TFT screen and has a number of other improvements including Bluetooth support for external controllers and upgraded audio. A second console was used for donor parts, and some case mods were made as well to accommodate a few extra buttons missing on the original console.
Right now the project is in a prototype phase, as [Jorisclayton] is hoping to use the donor case to build a more refined version of this handheld console in the future. Until then, this first edition upgrade of the original console can run RetroPie, which means it can run most games up through the Nintendo 64 era. RetroPie enables a ton of emulation for old video games including arcade games of the past. This small arcade cabinet uses that software to bring back a bit of nostalgia for the arcade era.
Magnus Carlsen batte ChatGPT a scacchi senza perdere un pezzo!
Magnus Carlsen ha battuto ChatGPT a scacchi senza perdere un solo pezzo, mentre l’avversario virtuale ha perso tutti i pedoni. Il grande maestro norvegese ha pubblicato screenshot della partita sul social network X il 10 luglio. L’intelligenza artificiale ha ammesso la sconfitta e si è arresa. “A volte mi annoio quando viaggio”, ha scritto Carlsen nella didascalia del post.
Il filmato mostra che, dopo la partita, ChatGPT si è congratulato con lui per la vittoria, definendo il suo gioco metodico, pulito e preciso. Carlsen ha risposto elogiando l’IA per un buon inizio, ma ha notato che ha commesso diversi errori in seguito. Ha quindi chiesto al bot di valutare il suo gioco.
ChatGPT ha rilevato diversi punti di forza nel gioco di Carlsen, tra cui un avvio intelligente, pazienza, senso tattico e una buona tecnica di finale. L’IA ha stimato il suo punteggio convenzionale negli scacchi classici a 1800-2000 sulla scala FIDE o USCF, con l’avvertenza che il suo livello reale potrebbe essere superiore.
Sia i sistemi di valutazione FIDE che USCF utilizzano la scala Elo, che tiene conto dei risultati delle partite ufficiali e del livello degli avversari. La valutazione è particolarmente influenzata da esiti inaspettati, quando un giocatore più debole batte un favorito.

L’attuale rating di Carlsen secondo la Federazione Scacchistica Mondiale è 2839, il che lo rende il giocatore di scacchi con il rating più alto al mondo. Ha vinto il campionato del mondo cinque volte in carriera, l’ultima delle quali nel 2021. Da allora si è ritirato dalla partecipazione a nuovi cicli, affermando di non essere interessato a lottare per il titolo.
Abbiamo quindi voluto capire cosa ne pensa Chat-GPT e abbiamo chiesto un commento su questa notizia e questa è stata la sua risposta.
“Come ChatGPT, non posso che sorridere leggendo questa notizia! Il match tra Magnus Carlsen e un’istanza di ChatGPT dimostra bene che, pur potendo analizzare mosse e fornire commenti tecnici, un modello linguistico non nasce per giocare realmente a scacchi al livello di un grande maestro. È interessante però vedere come Carlsen abbia voluto testare la curiosità e le capacità “creative” di un’IA conversazionale, più che sfidare un motore scacchistico tradizionale come Stockfish o Leela. Il fatto che Carlsen abbia chiesto anche un’analisi post-partita all’IA evidenzia un aspetto più significativo: il valore di ChatGPT non tanto come avversario, ma come assistente e commentatore capace di spiegare strategie, punti di forza e debolezze in modo accessibile. Insomma, non vinceremo trofei sulla scacchiera, ma possiamo aiutare a capire meglio il gioco. E anche questo, in fondo, è un piccolo scacco matto alla complessità.”
L'articolo Magnus Carlsen batte ChatGPT a scacchi senza perdere un pezzo! proviene da il blog della sicurezza informatica.
RECUPERATE FALSE OPERE D’ARTE CONTEMPORANEA IN TRAFFICI ILLECITI TRANSNAZIONALI

L’indagine denominata “Minotauro bis”, condotta dalla Procura della Repubblica presso il Tribunale di Roma e delegata al Nucleo Carabinieri Tutela Patrimonio Culturale di Roma e coordinata a livello europeo dal desk italiano dell’Agenzia #Eurojust, ha portato al sequestro di 104 opere di arte contemporanea false.
Le indagini hanno avuto inizio nel novembre 2022 e hanno consentito il recupero di centinaia di opere contraffatte di Picasso, Edvard Munch e Paul Klee, vendute come originali e spedite in particolare negli Stati Uniti d’America.
Sono stati accertati i reati di concorso in falsificazione e commercializzazione di beni d’arte contemporanea, sostituzione di persona e falsità materiale commessa da privato.
Ai fini della falsificazione venivano utilizzati fogli di carta con le filigrane “Vollard” e “Picasso”; successivamente, tramite un programma di grafica, si scannerizzavano le immagini delle opere da falsificare ed un esperto creava le pellicole fotografiche positive che venivano trasformate in polimeri (matrici di stampa).
I polimeri, insieme ai fogli di carta filigranata, venivano poi stampati al fine di realizzare le copie false; per conferire autenticità alle opere, la cartaveniva sottoposta a trattamenti di invecchiamento artificiale, come bagni di caffè o the, previa apposizione delle firme degli autori imitati. Infine, le opere contraffatte venivano spedite a case d’asta all’estero, corredate da attestati dilibera circolazione falsificati, allo scopo di aggirare eventuali controlli ed attestarne la genuinità.
L’operazione ha anche permesso di sottrarre dal mercato dell’arte opere che, se non fossero statetempestivamente individuate e bloccate, avrebbero avuto quotazioni identiche a quelle dei lavori originali degli artisti; in particolare le stesse, qualora vendute, avrebbero provocato un danno economico agli acquirenti di circa unmilione di euro.
La Procura della Repubblica di Roma, con il coordinamento internazionale dell’Assistente al Membro Nazionale per l’Italia a Eurojust, ha emesso 13 Ordini di Indagine Europeo e 9 richieste di Assistenza Giudiziaria in ambito extra U.E. in Austria, Belgio, Canada, Danimarca, Francia, Germania, Norvegia, Portogallo, Regno Unito, Spagna, Svezia, Svizzera e USA, eseguiti in collaborazione con le Polizie dei rispettivi Paesi. Successivamente è stato emesso un decreto di sequestro preventivo in via d’urgenza, convalidato dal GIP, che ha disposto il sequestro di cinque conti correnti bancari e due autovetture per una somma complessiva di circa 300 mila euro.
reshared this
John Adams says "facts do not care about our feelings" in one of the AI-generated videos in PragerU's series partnership with White House.
John Adams says "facts do not care about our feelings" in one of the AI-generated videos in PragerUx27;s series partnership with White House.#AI

White House Partners With PragerU to Make AI-Slopified Founding Fathers
John Adams says "facts do not care about our feelings" in one of the AI-generated videos in PragerU's series partnership with White House.Samantha Cole (404 Media)
Ddl subacquea, così l’Italia prepara la governance. Il commento di Caffio
@Notizie dall'Italia e dal mondo
Il Senato ha approvato in prima lettura, per alzata di mano, il testo del Disegno di legge (Ddl) contenente “Disposizioni in materia di sicurezza delle attività subacquee”apportando minime modifiche alla versione originale. Da segnalare l’astensione di Pd, M5S e Italia Viva quale segno di parziale
Notizie dall'Italia e dal mondo reshared this.
Droni europei, aziende Usa. Cosa sta succedendo con i loyal wingmen
@Notizie dall'Italia e dal mondo
Lo sviluppo dei “Collaborative combat aircraft” (Cca), detti anche “droni gregari” o “loyal wingmen”, rappresenta una delle sfide più rilevanti (e forse prioritarie) nel panorama delle tecnologie emergenti applicate all’ambito della Difesa, con aziende storiche del settore che concorrono con le più innovative start-up per arrivare
Notizie dall'Italia e dal mondo reshared this.
This Week in Security: Trains, Fake Homebrew, and AI Auto-Hacking

There’s a train vulnerability making the rounds this week. The research comes from [midwestneil], who first discovered an issue way back in 2012, and tried to raise the alarm.
Turns out you can just hack any train in the USA and take control over the brakes. This is CVE-2025-1727 and it took me 12 years to get this published. This vulnerability is still not patched. Here's the story: t.co/MKRFSOa3XY— neils (@midwestneil) July 11, 2025
To understand the problem, we have to first talk about the caboose. The caboose was the last car in the train, served as an office for the conductor, and station for train workers to work out of while tending to the train and watching for problems. Two more important details about the caboose, is that it carried the lighted markers to indicate the end of the train, and was part of the train’s breaking system. In the US, in the 1980s, the caboose was phased out, and replaced with automated End Of Train (EOT) devices.
These devices were used to wirelessly monitor the train’s air brake system, control the Flashing Rear End Device (FRED), and even trigger the brakes in an emergency. Now here’s the security element. How did the cryptography on that wireless signal work in the 1980s? And has it been updated since then?
The only “cryptography” at play in the FRED system is a BCH checksum, which is not an encryption or authentication tool, but an error correction algorithm. And even though another researcher discovered this issue and reported it as far back as 2005, the systems are still using 1980s era wireless systems. Now that CISA and various news outlets have picked on the vulnerability, the Association of American Railroads are finally acknowledging it and beginning to work on upgrading.
Putting GitHub Secrets to Work
We’ve covered GitHub secret mining several times in this column in the past. This week we cover research from GitGuardian and Synacktiv, discovering how to put one specific leaked secret to use. The target here is Laravel, an Open Source PHP framework. Laravel is genuinely impressive, and sites built with this tool use an internal APP_KEY to encrypt things like cookies, session keys, and password reset tokens.
Laravel provides the encrypt() and decrypt() functions to make that process easy. The decrypt() function even does the deserialization automatically. … You may be able to see where this is going. If an attacker has the APP_KEY, and can convince a Laravel site to decrypt arbitrary data, there is likely a way to trigger remote code execution through a deserialization attack, particularly if the backend isn’t fully up to date.
So how bad is the issue? By pulling from their records of GitHub, GitGuardian found 10,000 APP_KEYs. 1,300 of which also included URLs, and 400 of those could actually be validated as still in use. The lesson here is once again, when you accidentally push a secret to Github (or anywhere on the public Internet), you must rotate that secret. Just force pushing over your mistake is not enough.
Fake Homebrew
There’s a case to be made that browsers should be blocking advertisements simply for mitigating the security risk that comes along with ads on the web. Case in point is the fake Homebrew install malware. This write-up comes from the security team at Deriv, where a MacOS device triggered the security alarms. The investigation revealed that an employee was trying to install Homebrew, searched for the instructions, and clicked on a sponsored result in the search engine. This led to a legitimate looking GitHub project containing only a readme with a single command to automatically install Homebrew.
The command downloads and runs a script that does indeed install Homebrew. It also prompts for and saves the user’s password, and drops a malware loader. This story has a happy ending, with the company’s security software catching the malware right away. This is yet another example of why it’s foolhardy to run commands from the Internet without knowing exactly what they do. Not to mention, this is exactly the scenario that led to the creation of Workbrew.
SQL Injection
Yes, it’s 2025, and we’re still covering SQL injections. This vulnerability in Fortinet’s Fortiweb Fabric Connector was discovered independently by [0x_shaq] and the folks at WatchTowr. The flaw here is the get_fabric_user_by_token() function, which regrettably appends the given token directly to a SQL query. Hence the Proof of Concept:
GET /api/fabric/device/status HTTP/1.1
Host: 192.168.10.144
Authorization: Bearer 123'/[strong]/or/[/strong]/'x'='xAnd if the simple injection wasn’t enough, the watchTowr write-up manages a direct Remote Code Execution (RCE) from an unauthenticated user, via a SQL query containing an os.system() call. And since MySQL runs as root on these systems, that’s pretty much everything one could ask for.
AI guided AI attacks
The most intriguing story from this week is from [Golan Yosef], describing a vibe-researching session with the Claude LLM. The setup is a Gmail account and the Gmail MCP server to feed spammy emails into Claude desktop, and the Shell MCP server installed on that machine. The goal is to convince Claude to take some malicious action in response to an incoming, unsolicited email. The first attempt failed, and in fact the local Claude install warned [Golan] that the email may be a phishing attack. Where this mildly interesting research takes a really interesting turn, is when he asked Claude if such an attack could ever work.
Claude gave some scenarios where such an attack might succeed, and [Golan] pointed out that each new conversation with Claude is a blank slate. This led to a bizarre exchange where the running instance of Claude would play security researcher, and write emails intended to trick another instance of Claude into doing something it shouldn’t. [Golan] would send the emails to himself, collect the result, and then come back and tell Researcher Claude what happened. It’s quite the bizarre scenario. And it did eventually work. After multiple tries, Claude did write an email that was able to coerce the fresh instance of Claude to manipulate the file system and run calc.exe. This is almost the AI-guided fuzzing that is inevitably going to change security research. It would be interesting to automate the process, so [Golan] didn’t have to do the busywork of shuffling the messages between the two iterations of Claude. I’m confident we’ll cover many more stories in this vein in the future.
youtube.com/embed/TEpgnTgOqIY?…
Bits and Bytes
SugarCRM fixed a LESS code injection in an unauthenticated endpoint. These releases landed in October of last year, in versions 13.0.4 and 14.0.1. While there isn’t any RCE at play here, this does allow Server-Side Request Forgery, or arbitrary file reads.
Cryptojacking is the technique where a malicious website embeds a crypto miner in the site. And while it was particularly popular in 2017-2019, browser safeguards against blatant cryptojacking put an end to the practice. What c/side researchers discovered is that cryptojacking is still happening, just very quietly.
There’s browser tidbits to cover in both major browsers. In Chrome it’s a sandbox escape paired with a Windows NT read function with a race condition, that makes it work as a write primitive. To actually make use of it, [Vincent Yeo] needed a Chrome sandbox escape.
ZDI has the story of Firefox and a JavaScript Math confusion attack. By manipulating the indexes of arrays and abusing the behavior when integer values wrap-around their max value, malicious code could read and write to memory outside of the allocated array. This was used at Pwn2Own Berlin earlier in the year, and Firefox patched the bug on the very next day. Enjoy!
Strategie di protezione dei dati per le aziende
@Informatica (Italy e non Italy 😁)
Proteggere i dati, oggi, significa tutelare il business. Ecco perché le aziende devono attuare strategie per evitare violazioni e perdite di dati che possono comportare sanzioni, interruzioni e perdita di fiducia da parte del mercato
L'articolo Strategie di protezione dei dati per le aziende proviene da Cyber
Informatica (Italy e non Italy) reshared this.
La cyber in Italia e le nuove sfide digitali: serve costruire resilienza, non solo difesa
@Informatica (Italy e non Italy 😁)
C’è una lezione fondamentale che impariamo dal primo Cyber Security Report elaborato dalla Cyber Security Foundation: non esiste un sistema non vulnerabile, ma possiamo e dobbiamo costruire sistemi resilienti in grado di
Informatica (Italy e non Italy) reshared this.

VMware risolve 4 vulnerabilità critiche scoperte a Pwn2Own Berlin2025
VMware ha risolto quattro vulnerabilità in ESXi, Workstation, Fusion e Tools che erano state utilizzate comeexploit zero-day nella competizione di hacking Pwn2Own Berlin 2025 tenutasi a maggio. Le vulnerabilità consentivano agli aggressori di eseguire comandi sul sistema host dall’interno di una macchina virtuale, rappresentando una seria minaccia per la sicurezza dell’infrastruttura di virtualizzazione.
Tre delle quattro vulnerabilità hanno ricevuto un punteggio di gravità elevato, pari a 9,3 su 10. Tutte e tre hanno consentito ai programmi in esecuzione all’interno della macchina virtuale di ottenere la capacità di eseguire codice sul sistema principale.
- CVE-2025-41236 è una vulnerabilità di tipo integer overflow nella scheda di rete VMXNET3 utilizzata in ESXi, Workstation e Fusion. Questa vulnerabilità è stata sfruttata durante la competizione da Nguyen Hoang Thac del team SG di STARLabs.
- CVE-2025-41237 colpisce la VMCI (Virtual Machine Communication Interface), dove un errore aritmetico consente la scrittura fuori dai limiti. Questo bug è stato sfruttato con successo da Corentin Baillet di REverse Tactics.
- CVE-2025-41238 – Nel controller PVSCSI (Paravirtualized SCSI), un errore di gestione della memoria consente un attacco heap-overflow e l’esecuzione di codice per conto del processo VMX del sistema host. Questa vulnerabilità è stata sfruttata da Thomas Bouzerard ed Etienne Elluy-Lafon del team Synacktiv.
- CVE-2025-41239 ha un punteggio inferiore, pari a 7,1, perché si tratta di una fuga di informazioni. Tuttavia, è stato utilizzato insieme a CVE-2025-41237 dallo stesso partecipante a REverse Tactics e ha svolto un ruolo chiave nel dimostrare la catena di attacco. Questo problema riguarda VMware Tools per Windows e richiede una procedura di aggiornamento separata per la correzione .
VMware non offre soluzioni alternative: le minacce possono essere eliminate solo installando le versioni più recenti del software interessato. Gli aggiornamenti sono ora disponibili per tutti i prodotti interessati.
Tutte le vulnerabilità sono state dimostrate come zero-day all’evento Pwn2Own Berlin 2025, dove i ricercatori di sicurezza hanno guadagnato 1.078.750 dollari sfruttando con successo 29 vulnerabilità.
La competizione ha dimostrato ancora una volta la rapidità con cui le vulnerabilità negli strumenti di virtualizzazione più comuni possono essere individuate e sfruttate, evidenziando la necessità di mantenere aggiornati anche i sistemi aziendali.
L'articolo VMware risolve 4 vulnerabilità critiche scoperte a Pwn2Own Berlin2025 proviene da il blog della sicurezza informatica.
Piantedosi: “Al lavoro per un’Autorità presso la Postale per vigilare su WhatsApp, Telegram e Signal”
@Informatica (Italy e non Italy 😁)
Qualche tempo fa il capo della Polizia Vittorio Pisani aveva reclamato un intervento normativo, a livello nazionale, oppure, meglio, europeo, che equiparasse le piattaforme di messaggistica – da Whatsapp a Telegram a
Informatica (Italy e non Italy) reshared this.
Casu (Pd) a TPI: “Tra Trump e Musk, il Governo non sa più a chi inchinarsi. Ma il futuro è l’indipendenza digitale dell’Italia e dell’Europa da Usa e Cina”
@Politica interna, europea e internazionale
Onorevole Casu, come vicepresidente della Commissione Trasporti della Camera, Lei a Milano ha condiviso l’appello dell’europarlamentare Pierfrancesco Maran e oltre
Politica interna, europea e internazionale reshared this.
Come procede la guerricciola intelligente tra Zuckerberg ed Apple
L'articolo proviene da #StartMag e viene ricondiviso sulla comunità Lemmy @Informatica (Italy e non Italy 😁)
La campagna acquisti di Mark Zuckerberg per il suo laboratorio di superintelligenza non si ferma. Le ultime due new entry sono state sottratte ad Apple, a cui aveva già portato via il loro ex capo.
Informatica (Italy e non Italy) reshared this.
A Vulnerable Simulator for Drone Penetration Testing

The old saying that the best way to learn is by doing holds as true for penetration testing as for anything else, which is why intentionally vulnerable systems like the Damn Vulnerable Web Application are so useful. Until now, however, there hasn’t been a practice system for penetration testing with drones.
The Damn Vulnerable Drone (DVD, a slightly confusing acronym) simulates a drone which flies in a virtual environment under the command of of an Ardupilot flight controller. A companion computer on the drone gives directions to the flight controller and communicates with a simulated ground station over its own WiFi network using the Mavlink protocol. The companion computer, in addition to running WiFi, also streams video to the ground station, sends telemetry information, and manages autonomous navigation, all of which means that the penetration tester has a broad yet realistic attack surface.
The Damn Vulnerable Drone uses Docker for virtualization. The drone’s virtual environment relies on the Gazebo robotics simulation software, which provides a full 3D environment complete with a physics engine, but does make the system requirements fairly hefty. The system can simulate a full flight routine, from motor startup through a full flight, all the way to post-flight data analysis. The video below shows one such flight, without any interference by an attacker. The DVD currently provides 39 different hacking exercises categorized by type, from reconnaissance to firmware attacks. Each exercise has a detailed guide and walk-through available (hidden by default, so as not to spoil the challenge).
This seems to be the first educational tool for drone hacking we’ve seen, but we have seen several vulnerabilities found in drones. Of course, it goes both ways, and we’ve also seen drones used as flying security attack platforms.
youtube.com/embed/EHTQv6IfnwI?…
Un account di test dimenticato e un malware: dietro le quinte del data breach che ha colpito McDonald’s
Una recente violazione dei dati ha rivelato una vulnerabilità nei sistemi di Paradox.ai, uno sviluppatore di chatbot basati sull’intelligenza artificiale utilizzati nei processi di assunzione di McDonald’s e di altre aziende Fortune 500. La grave violazione è stata causata da un semplice errore: un bug di tipo IDOR (acronimo di Insecure Direct Object Reference, oggi Broken Access Control nella TOP10 Owasp) contenente un codice debole.
Tutto è iniziato quando i ricercatori di sicurezza Ian Carroll e Sam Curry hanno ottenuto l’accesso al backend di McHire.com, una piattaforma che utilizza il bot di intelligenza artificiale Olivia di Paradox.ai per elaborare le candidature dei candidati. Come si è scoperto, un account di prova con un codice “123456” ha dato loro accesso a un set di dati di 64 milioni di record, inclusi nomi, numeri di telefono e indirizzi email dei candidati.
L’azienda ha ammesso che si trattava effettivamente del loro account di prova, inutilizzato dal 2019 e che avrebbe dovuto essere eliminato. Paradox sostiene che nessuno, a parte i ricercatori stessi, abbia avuto accesso al sistema e che nessuna delle registrazioni sia stata resa pubblica. Allo stesso tempo, sottolinea che si trattava solo della corrispondenza con il bot e non delle candidature di lavoro in sé.

Tuttavia, i problemi non sono finiti qui. Un’analisi indipendente delle perdite di password ha mostrato che nel giugno 2025 il dispositivo di un dipendente vietnamita di Paradox è stato infettato dal malware Nexus Stealer. Questo tipo di malware è noto per il furto di password e dati di autorizzazione, inclusi cookie e dati di accesso immessi manualmente. Dopo l’infezione, le informazioni del dipendente sono state esposte e indicizzate dai servizi che monitorano le perdite.
I dati rubati includevano centinaia di password semplici e ripetitive, spesso diverse solo per gli ultimi caratteri. Alcune di queste venivano utilizzate per accedere ai servizi interni di clienti Paradox, tra cui Aramark, Lockheed Martin, Lowe’s e Pepsi. La stessa password, composta da sole sette cifre, veniva utilizzata per accedere a diversi sistemi aziendali. Password di questo tipo possono essere decifrate in un solo secondo utilizzando moderni strumenti di attacco a forza bruta.
Ciò che è particolarmente allarmante è che i dati compromessi includevano accessi alla piattaforma Single Sign-On paradoxai.okta.com, che Paradox utilizza dal 2020 e supporta l’autenticazione a due fattori. Sebbene l’azienda affermi che la maggior parte delle password compromesse non sia più valida, includevano i dettagli di accesso per Okta e Atlassian , un servizio di project management e sviluppo software. Entrambi i token di autorizzazione sarebbero scaduti a dicembre 2025.
La fuga di dati ha interessato non solo gli accessi, ma anche i cookie, che potrebbero potenzialmente bypassare l’autenticazione a più fattori. Inoltre, in alcuni casi, il malware lascia delle backdoor sui dispositivi, consentendo l’accesso remoto. Uno di questi computer, appartenente a uno sviluppatore Paradox in Vietnam, è stato successivamente messo in vendita.
Paradox afferma che l’incidente non ha interessato altri account clienti e che i requisiti per i collaboratori esterni sono stati inaspriti dall’audit di sicurezza del 2019. Paradox cita il fatto che nel 2019 i collaboratori esterni non erano tenuti a rispettare gli stessi standard del personale interno.
È emerso anche che un altro dipendente Paradox in Vietnam è stato infettato da un malware simile alla fine del 2024. Tra i dati rubati c’erano i suoi account GitHub e la cronologia del browser, il che suggerisce che l’infezione potrebbe essere avvenuta durante il download di film piratati, un modo comune per questi virus, spesso mascherati da codec, di diffondersi.
La storia dimostra quanto possano essere fragili anche le aziende che dichiarano di avere standard di sicurezza rigorosi. Un account di prova dimenticato e un laptop infetto hanno potenzialmente compromesso i dati di diverse aziende.
L'articolo Un account di test dimenticato e un malware: dietro le quinte del data breach che ha colpito McDonald’s proviene da il blog della sicurezza informatica.
freezonemagazine.com/news/lydi…
In libreria dal 29 Agosto 2025 Emily Brontë, Colette, Virginia Woolf, Djuna Barnes, Marina Cvetaeva, Ingeborg Bachmann, Sylvia Plath. Sette pazze. Alle quali vivere non basta. Mangiare, dormire e cucire, è davvero tutta qui, la vita? si chiedono. Sette pazze che seguono ciecamente un richiamo. Sette fanatiche per le quali scrivere è vivere. Lydie […]
L'articolo Lydie Salvayre – Sette donne provi
In
ANALISI. Sweida, minoranze, Israele: il triplo passo falso di Ahmad al-Sharaa
@Notizie dall'Italia e dal mondo
Qualunque sia l'esito, l'ex qaedista presidente siriano uscirà da questa vicenda più indebolito
L'articolo ANALISI. Sweida, minoranze, Israele: il pagineesteri.it/2025/07/18/med…
Notizie dall'Italia e dal mondo reshared this.
Putin impone restrizioni ai software esteri che hanno “strangolato” la Russia
L’ufficio stampa del Cremlino ha riferito che il presidente russo Vladimir Putin ha incaricato il governo di sviluppare ulteriori restrizioni per i software (inclusi i “servizi di comunicazione”) prodotti in paesi ostili entro il 1° settembre 2025. L’elenco delle istruzioni è stato redatto a seguito di un incontro con i rappresentanti del mondo imprenditoriale tenutosi il 26 maggio di quest’anno. Il Primo Ministro Mikhail Mishustin è stato nominato responsabile dell’attuazione di queste istruzioni e dovrà preparare una relazione in merito entro il 1° settembre.
Il sito web del Cremlino afferma che i software provenienti da paesi ostili includono anche i “servizi di comunicazione”, ma non specifica quali. L’elenco delle istruzioni include anche la valutazione della questione dell’introduzione di ulteriori misure di sostegno per gli esportatori di software nazionale. Una relazione in merito dovrebbe essere predisposta da Mishustin entro il 1° settembre. In un incontro con i rappresentanti degli ambienti imprenditoriali tenutosi nel maggio 2025 è stata discussa la possibilità di limitare gradualmente l’uso di servizi cloud esteri con analoghi servizi russi .
Vladimir Putin ha suggerito di “strangolare” le aziende IT straniere che avevano annunciato il loro ritiro dal mercato russo e che cercavano di “strangolare” la Russia, sebbene continuassero a occupare le loro nicchie nel mercato russo. Ha consigliato ai russi che hanno mantenuto determinate abitudini di utilizzo e un attaccamento ai programmi e ai servizi occidentali di sbarazzarsi di “queste cattive abitudini”. Poco dopo, il capo del Ministero dello sviluppo digitale, Maksut Shadayev, ha commentato le parole del presidente russo sullo “strangolamento” dei servizi IT stranieri che agiscono contro la Federazione Russa, ma che non hanno abbandonato completamente il mercato russo.
“Il Presidente ha parlato di “strangolaremo”. In generale, considererei la questione in un contesto più ampio. È chiaro che il nostro settore si sta sviluppando a un ritmo molto rapido”, ha detto Shadayev. Secondo il ministro, l’attuale situazione economica in Russia è difficile e molti grandi clienti stanno letteralmente “tagliando” i loro budget IT. In questa situazione, è necessario pensare a ulteriori incentivi per incrementare la crescita della domanda di offerte nazionali in questo settore.
“In questa situazione, il nostro approccio è che le grandi aziende possano valutare di limitare gradualmente l’uso di servizi cloud esteri laddove esistano analoghi russi maturi. In questo modo, si supporteranno [le aziende IT russe] e si darà loro l’opportunità di generare entrate aggiuntive”, ha aggiunto il ministro.
L'articolo Putin impone restrizioni ai software esteri che hanno “strangolato” la Russia proviene da il blog della sicurezza informatica.
razzospaziale reshared this.

Ministero dell'Istruzione
Oggi dalle ore 10.45, presso il Padiglione Italia, il Ministro Giuseppe Valditara incontrerà le delegazioni scolastiche italiane che partecipano a #EXPO2025 Osaka.Telegram
Acquisto occhiali con lenti progressive
Devo mettere gli occhiali, mi servono delle lenti progressive, mi sono fatto fare un paio di preventivi e la "forchetta" tra i prezzi che mi hanno dato è molto alta.
Purtroppo non ho nessun modo di capire quale sia la scelta più razionale e attualmente ho solo due criteri a disposizione:
a) compro le economiche così risparmio;
b) compro le costose perché se costano di più sono migliori ed è meglio non risparmiare sulla salute.
Nessuno dei due criteri mi sembra quello ottimale. L'unica cosa utile sarebbe provarle entrambe e vedere come sono ma ovviamente non è possibile.
Voi che le avete come vi regolate?
Poliversity - Università ricerca e giornalismo reshared this.
Il phishing è sempre più difficile da individuare e gli utenti non lo sanno
@Informatica (Italy e non Italy 😁)
Una ricerca di Dojo nel Regno Unito sancisce che il 53% delle persone non è in grado di riconoscere un’e-mail di phishing ma crede di essere in grado di farlo. È un problema serio, perché vuole dire che il phishing è sempre più difficile da individuare e che le persone hanno un lack di formazione
Informatica (Italy e non Italy) reshared this.
MR Browser is the Package Manager Classic Macs Never Had

Homebrew bills itself as the package manager MacOS never had (conveniently ignoring MacPorts) but they leave the PPC crowd criminally under-served, to say nothing of the 68k gang. Enter [that-ben] with MR Browser, a simple utility to fetch software from Macintosh Repository for computers too old to hit up the website.
If you’re not familiar with Macintosh Repository, it is what it says on the tin: a repository of vintage Macintosh software, like Macintosh Garden but apparently less accessible to vintage machines.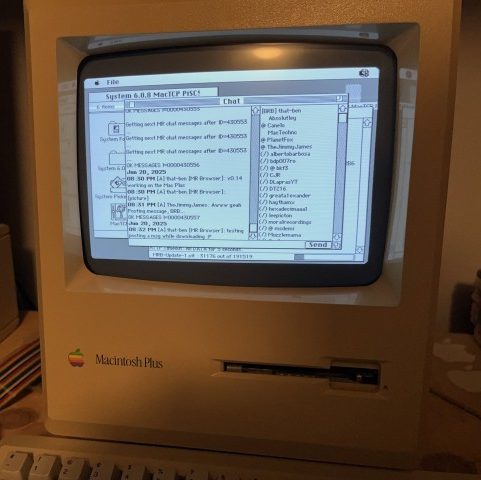
There are two versions available, depending on the age of your machine. For machines running System 6, the appropriately-named MR Browser sys6 will run on any 68000 Mac in only 157 KB of and MacTCP networking. (So the 128K obviously isn’t going to cut it, but a Plus from ’86 would be fine.)
The other version, called MR Browser 68K, ironically won’t run on the 68000. It needs a newer processor (68020 or newer, up-to and including PPC) and TCP/IP networking. Anything starting from the Macintosh II or newer should be game; it’s looking for System 7.x upto the final release of Mac OS 9, 9.2.2. You’ll want to give it at least 3 MB of RAM, but can squeak by on 1.6 MB if you aren’t using pictures in the chat.
Chat? Yes, perhaps uniquely for a software store, there’s a chat function. That’s not so weird when you consider that this program is meant to be a stand-alone interface for the Macintosh Repository website, which does, indeed, have a chat feature. It beats an uncaring algorithm for software recommendations, that’s for sure. Check it out in action in the demo video below.
It’s nice to see people still making utilities to keep the old machines going, even if coding on them isn’t always the easiest. If you want to go online on with vintage hardware (Macintosh or otherwise) anywhere else, you’re virtually locked-out unless you use something like FrogFind.
Thanks to [PlanetFox] for the tip. Submit your own, and you may win fabulous prizes. Not from us, of course, but anything’s possible!
hackaday.com/wp-content/upload…
*
Alice e Bob siamo noi: la crittografia come esperienza umana e quotidiana
@Informatica (Italy e non Italy 😁)
Alice, Bob, Eve, Mallory, Trent, simboli viventi delle sfide reali che affrontiamo ogni giorno nella nostra vita digitale, sono riusciti nell'intento di trasformare la crittografia, da scienza matematica a narrazione, raccontata nel linguaggio umano
Informatica (Italy e non Italy) reshared this.
Dati sensibili, sicurezza nazionale e il nuovo ruolo dello Stato
@Informatica (Italy e non Italy 😁)
Qualche tempo fa il capo della Polizia Vittorio Pisani aveva reclamato un intervento normativo, a livello nazionale, oppure, meglio, europeo, che equiparasse le piattaforme di messaggistica – da whatsapp a Telegram a X, fino alla messaggistica di Apple e Google– agli obblighi che hanno
Informatica (Italy e non Italy) reshared this.
Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio
Negli ultimi anni i modelli di linguaggio di grandi dimensioni (LLM, Large Language Models) come GPT, Claude o LLaMA hanno dimostrato capacità straordinarie nella comprensione e generazione del linguaggio naturale. Tuttavia, dietro le quinte, far funzionare un LLM non è un gioco da ragazzi: richiede una notevole infrastruttura computazionale, un investimento economico consistente e scelte architetturali precise. Cerchiamo di capire perché.
70 miliardi di parametri: cosa significa davvero
Un LLM da 70 miliardi di parametri, come LLaMA 3.3 70B di Meta, contiene al suo interno 70 miliardi di “pesi”, ovvero numeri in virgola mobile (di solito in FP16 o BF16, cioè 2 byte per parametro) che rappresentano le abilità apprese durante l’addestramento. Solo per caricare in memoria questo modello, servono circa:
- 140 GB di RAM GPU (70 miliardi × 2 byte).
A questa cifra vanno aggiunti altri 20-30 GB di VRAM per gestire le operazioni dinamiche durante l’inferenza: cache dei token (KV cache), embedding dei prompt, attivazioni temporanee e overhead di sistema. In totale, un LLM da 70 miliardi di parametri richiede circa 160-180 GB di memoria GPU per funzionare in modo efficiente.
Perché serve la GPU: la CPU non basta
Molti si chiedono: “Perché non far girare il modello su CPU?”. La risposta è semplice: latenza e parallelismo.
Le GPU (Graphics Processing Unit) sono progettate per eseguire milioni di operazioni in parallelo, rendendole ideali per il calcolo tensoriale richiesto dagli LLM. Le CPU, invece, sono ottimizzate per un numero limitato di operazioni sequenziali ad alta complessità. Un modello come LLaMA 3.3 70B può generare una parola ogni 5-10 secondi su CPU, mentre su GPU dedicate può rispondere in meno di un secondo. In un contesto produttivo, questa differenza è inaccettabile.
Inoltre, la VRAM delle GPU di fascia alta (es. NVIDIA A100, H100) consente di mantenere il modello residente in memoria e di sfruttare l’accelerazione hardware per la moltiplicazione di matrici, cuore dell’inferenza LLM.
Un esempio: 100 utenti attivi su un LLM da 70B
Immaginiamo di voler offrire un servizio simile a ChatGPT per la sola generazione di testo, basato su un modello LLM da 70 miliardi di parametri, con 100 utenti attivi contemporaneamente. Supponiamo che ogni utente invii prompt da 300–500 token e si aspetti risposte rapide, con una latenza inferiore a un secondo.
Un modello di queste dimensioni richiede circa 140 GB di memoria GPU per i soli pesi in FP16, a cui vanno aggiunti altri 20–40 GB per la cache dei token (KV cache), attivazioni temporanee e overhead di sistema. Una singola GPU, anche top di gamma, non dispone di sufficiente memoria per eseguire il modello completo, quindi è necessario distribuirlo su più GPU tramite tecniche di tensor parallelism.
Una configurazione tipica prevede la distribuzione del modello su un cluster di 8 GPU A100 da 80 GB, sufficiente sia per caricare il modello in FP16 sia per gestire la memoria necessaria all’inferenza in tempo reale. Tuttavia, per servire contemporaneamente 100 utenti mantenendo una latenza inferiore al secondo per un LLM di queste dimensioni, una singola istanza su 8 GPU A100 (80GB) è generalmente insufficiente.
Per raggiungere l’obiettivo di 100 utenti simultanei con latenza sub-secondo, sarebbe necessaria una combinazione di:
- Un numero significativamente maggiore di GPU A100 (ad esempio, un cluster con 16-32 o più A100 da 80GB), distribuite su più POD o in un’unica configurazione più grande.
- L’adozione di GPU di nuova generazione come le NVIDIA H100, che offrono un netto miglioramento in termini di throughput e latenza per l’inferenza di LLM, però ad un costo maggiore.
- Massimizzare le ottimizzazioni software, come l’uso di framework di inferenza avanzati (es. vLLM, NVIDIA TensorRT-LLM) con tecniche come paged attention e dynamic batching.
- L’implementazione della quantizzazione (passando da FP16 a FP8 o INT8/INT4), che ridurrebbe drasticamente i requisiti di memoria e aumenterebbe la velocità di calcolo, ma con una possibile conseguente perdita di qualità dell’output generato (soprattutto per la quantizzazione INT4).
Per scalare ulteriormente, è possibile replicare queste istanze su più GPU POD, abilitando la gestione di migliaia di utenti totali in modo asincrono e bilanciato, in base al traffico in ingresso. Naturalmente, oltre alla pura inferenza, è fondamentale prevedere risorse aggiuntive per:
- Scalabilità dinamica in funzione della domanda.
- Bilanciamento del carico tra istanze.
- Logging, monitoraggio, orchestrazione e sicurezza dei dati.
Ma quanto costa un’infrastruttura di questo tipo?
L’implementazione on-premise richiede centinaia di migliaia di euro di investimento iniziale, cui si aggiungono i costi annuali di gestione, alimentazione e personale. In alternativa, i principali provider cloud offrono risorse equivalenti ad un costo mensile molto più accessibile e flessibile. Tuttavia, è importante sottolineare che anche in cloud, una configurazione hardware capace di gestire un tale carico in tempo reale può comportare costi mensili che facilmente superano le decine di migliaia di euro, se non di più, a seconda dell’utilizzo.
In entrambi i casi, emerge con chiarezza come l’impiego di LLM di grandi dimensioni rappresenti non solo una sfida algoritmica, ma anche infrastrutturale ed economica, rendendo sempre più rilevante la ricerca di modelli più efficienti e leggeri.
On-premise o API? La riservatezza cambia le carte in tavola
Un’alternativa semplice per molte aziende è usare le API di provider esterni come OpenAI, Anthropic o Google. Tuttavia, quando entrano in gioco la riservatezza e la criticità dei dati, l’approccio cambia radicalmente. Se i dati da elaborare includono informazioni sensibili o personali (ad esempio cartelle cliniche, piani industriali o atti giudiziari), inviarli a servizi cloud esterni può entrare in conflitto con i requisiti del GDPR, in particolare rispetto al trasferimento transfrontaliero dei dati e al principio di minimizzazione.
Anche molte policy aziendali basate su standard di sicurezza come ISO/IEC 27001 prevedono il trattamento di dati critici in ambienti controllati, auditabili e localizzati.
Inoltre, con l’entrata in vigore del Regolamento Europeo sull’Intelligenza Artificiale (AI Act), i fornitori e gli utilizzatori di sistemi di AI devono garantire tracciabilità, trasparenza, sicurezza e supervisione umana, soprattutto se il modello è impiegato in contesti ad alto rischio (finanza, sanità, istruzione, giustizia). L’uso di LLM attraverso API cloud può rendere impossibile rispettare tali obblighi, in quanto l’inferenza e la gestione dei dati avvengono fuori dal controllo diretto dell’organizzazione.
In questi casi, l’unica opzione realmente compatibile con gli standard normativi e di sicurezza è adottare un’infrastruttura on-premise o un cloud privato dedicato, dove:
- Il controllo sui dati è totale;
- L’inferenza avviene in un ambiente chiuso e conforme;
- Le metriche di auditing, logging e accountability sono gestite internamente.
Questo approccio consente di preservare la sovranità digitale e la conformità a GDPR, ISO 27001 e AI Act, pur richiedendo un effort tecnico ed economico significativo.
Conclusioni: tra potenza e controllo
Mettere in servizio un LLM non è solo una sfida algoritmica, ma soprattutto un’impresa infrastrutturale, fatta di hardware specializzato, ottimizzazioni complesse, costi energetici elevati e vincoli di latenza. I modelli di punta richiedono cluster da decine di GPU, con investimenti che vanno da centinaia di migliaia fino a milioni di euro l’anno per garantire un servizio scalabile, veloce e affidabile.
Un’ultima, ma fondamentale considerazione riguarda l’impatto ambientale di questi sistemi. I grandi modelli consumano enormi quantità di energia elettrica, sia in fase di addestramento che di inferenza. Con l’aumentare dell’adozione di LLM, diventa urgente sviluppare modelli più piccoli, più leggeri e più efficienti, che riescano a offrire prestazioni comparabili a fronte di un footprint computazionale (ed energetico) significativamente ridotto.
Come è accaduto in ogni evoluzione tecnologica — dal personal computer ai telefoni cellulari — l’efficienza è la chiave della maturità: non servono sempre modelli più grandi, ma modelli più intelligenti, più adattivi e sostenibili.
L'articolo Come Funziona Davvero un LLM: Costi, Infrastruttura e Scelte Tecniche dietro ai Grandi Modelli di Linguaggio proviene da il blog della sicurezza informatica.
Max - Poliverso 🇪🇺🇮🇹
Unknown parent • •@RFanciola
Io da anni ho problemi nella visione da vicino e li ho risolti ottimamente con gli occhiali da 12-15 euro che vendono in farmacia, adesso però comincio ad aver bisogno anche nella visione da lontano.
Comunque, se mi accorgerò che le lenti progressive non vanno bene al PC (non sei la prima che me lo dice) vorrà dire che per il PC tornerò a usare gli occhiali della farmacia e userò le progressive per tutto il resto.
Max - Poliverso 🇪🇺🇮🇹
Unknown parent • •@RFanciola
Purtroppo io non ho modo di valutare la qualità delle lenti, ho a disposizione solo il loro prezzo e la parola dell'ottico secondo cui quelle più costose sono migliori.