 - Collegamento all'originale")
NASA May Have Lost the MAVEN Mars Orbiter

When the orbit of NASA’s Mars Atmosphere and Volatile EvolutioN (MAVEN) spacecraft took it behind the Red Planet on December 6th, ground controllers expected a temporary loss of signal (LoS). Unfortunately, the Deep Space Network hasn’t heard from the science orbiter since. Engineers are currently trying to troubleshoot this issue, but without a sign of life from the stricken spacecraft, there are precious few options.
As noted by [Stephen Clark] over at ArsTechnica this is a pretty big deal. Even though MAVEN was launched in November of 2013, it’s a spring chicken compared to the other Mars orbiters. The two other US orbiters: Mars Reconnaissance Orbiter (MRO) and Mars Odyssey, are significantly older by around a decade. Of the two ESA orbiters, Mars Express and ExoMars, the latter is fairly new (2016) and could at least be a partial backup for MAVEN’s communication relay functionality with the ground-based units, in particular the two active rovers. ExoMars has a less ideal orbit for large data transfers, which would hamper scientific research.
With neither the Chinese nor UAE orbiters capable of serving as a relay, this puts the burden on a potential replacement orbiter, such as the suggested Mars Telecommunications Orbiter, which was cancelled in 2005. Even if contact with MAVEN is restored, it would only have fuel for a few more years. This makes a replacement essential if we wish to keep doing ground-based science missions on Mars, as well as any potential manned missions.
Gazzetta del Cadavere reshared this.






VERSO LA SEMPLIFICAZIONE DI PRIVACY, CYBERSECURITY E INTELLIGENZA ARTIFICIALE
Per vedere altri post come questo, segui la comunità @Informatica (Italy e non Italy 😁)
Se a breve va in porto il cosiddetto “Omnibus Digitale”, smetteranno di lamentarsi tutti quelli che negli ultimi trent’anni non hanno digerito gli adempimenti in materia di riservatezza dei dati e più
CheGuevaraRoma reshared this.
Trump e la guerra alle leggi AI statali: standard federale o deregulation mascherata?
@Informatica (Italy e non Italy 😁)
Trump annuncia un ordine esecutivo per limitare le leggi statali sull'IA, promettendo uno standard federale che non esiste. Stati come Florida e Minnesota si oppongono. Ecco che c’è da sapere, tra criticità costituzionali e sospetti di
Gazzetta del Cadavere reshared this.
Cisco fuga i dubbi sui vantaggi dell’autenticazione passwordless
@Informatica (Italy e non Italy 😁)
Cisco fa il punto sulla situazione e promuove a pieni voti l’autenticazione passwordless. Quali sono gli argomenti a favore e cosa è opportuno sapere per prendere una decisione consapevole, tenendo conto anche delle criticità
L'articolo Cisco fuga i dubbi sui vantaggi dell’autenticazione passwordless proviene da Cyber

"La Banca di Russia farà causa alla Ue per l'uso degli asset russi"
dopo aver imbracciato le armi adesso vogliono fare causa? che ridicoli.
valigiablu.it/brexit-regno-uni…
verrebbe quasi il sospetto che quando putin e trump pensano che per l'europa sarebbe meglio smantellare la UE non abbiamo a cuore gli interessi europei ma i loro... tipo spartirsi l'europa "alla vecchia maniera", tanto amata sicuramente da putin ma a quanto pare anche dal rivoluzionario e progressivo anti-sistema trump...

Il fallimento della Brexit: perché uscire dall'Europa non conviene - Valigia Blu
Negli ultimi giorni l’Unione Europea è stata presa di mira da Trump, Musk e Putin, in una convergenza politica e retorica che punta a indebolirne la legittimità. Ma l’esperienza della Brexit mostra cosa significa davvero allontanarsi dall’UE.Mattia Marasti (Valigia Blu)
BENIN. Il golpe sventato grazie all’intervento della Francia e dell’Ecowas
@Notizie dall'Italia e dal mondo
Per sventare il tentato golpe in Benin sono intervenute le truppe dell'Ecowas, un'alleanza regionale fedele a Parigi. La Francia non vuole perdere la sua residua influenza in Africa dopo l'avvicinamento a Mosca di Burkina Faso, Mali e Niger
L'articolo BENIN. Il golpe sventato grazie
NanoRemote: il malware che trasforma il cloud in un centro di comando e controllo
Un nuovo trojan multifunzionale per Windows chiamato NANOREMOTE utilizza un servizio di archiviazione file su cloud come centro di comando, rendendo la minaccia più difficile da rilevare e offrendo agli aggressori un canale persistente per rubare dati e fornire download aggiuntivi.
La minaccia è stata segnalata da Elastic Security Labs, che ha confrontato il malware con il già noto impianto FINALDRAFT, noto anche come Squidoor, che si basa su Microsoft Graph per comunicare con gli operatori.
Entrambi gli strumenti sono associati al cluster REF7707, segnalato come CL-STA-0049, Earth Alux e Jewelbug, e attribuiti ad attività di spionaggio cinese contro agenzie governative, appaltatori della difesa, società di telecomunicazioni, istituti scolastici e organizzazioni aeronautiche nel Sud-est asiatico e in Sud America.
Secondo Symantec, questo gruppo sta conducendo campagne segrete a lungo termine almeno dal 2023, tra cui un’infiltrazione durata cinque mesi in un’azienda IT in Russia. Il metodo esatto dell’infiltrazione iniziale di NANOREMOTE non è ancora stato determinato. La catena di attacco documentata utilizza il downloader WMLOADER, mascherato da componente di gestione degli arresti anomali dell’antivirus Bitdefender “BDReinit.exe“. Questo modulo decrittografa lo shellcode e lancia il payload principale: il trojan stesso.
NANOREMOTE è scritto in C++ e può raccogliere informazioni di sistema, eseguire comandi e file e trasferire dati tra il dispositivo infetto e l’infrastruttura dell’operatore tramite Google Drive . È inoltre configurato per comunicare tramite HTTP con un indirizzo IP hardcoded e non instradabile, attraverso il quale riceve attività e invia risultati. Gli scambi vengono effettuati tramite richieste POST con dati JSON, compressi tramite Zlib e crittografati in modalità AES-CBC con una chiave a 16 byte. Le richieste utilizzano un singolo percorso, “/api/client”, e la stringa di identificazione del client, “NanoRemote/1.0”.
Le principali funzionalità del Trojan sono implementate tramite un set di 22 gestori di comandi. Questi gestori gli consentono di raccogliere e trasmettere informazioni sull’host, gestire file e directory, svuotare la cache, avviare file eseguibili PE già presenti sul disco, terminare la propria operazione e caricare e scaricare file sul cloud, con la possibilità di mettere in coda, mettere in pausa, riprendere o annullare i trasferimenti.
Elastic Security Labs ha anche scoperto l’artefatto “wmsetup.log”, caricato su VirusTotal dalle Filippine il 3 ottobre 2025 e decifrato con successo dal modulo WMLOADER utilizzando la stessa chiave di crittografia.
Conteneva un impianto FINALDRAFT, a indicare uno sviluppo comune. Secondo il ricercatore principale Daniel Stepanic, l’identico loader e l’approccio unificato alla protezione del traffico sono ulteriori indicazioni di una base di codice e di un processo di build unificati per FINALDRAFT e NANOREMOTE, progettati per gestire payload diversi.
L'articolo NanoRemote: il malware che trasforma il cloud in un centro di comando e controllo proviene da Red Hot Cyber.
Following the digital trail: what happens to data stolen in a phishing attack

Introduction
A typical phishing attack involves a user clicking a fraudulent link and entering their credentials on a scam website. However, the attack is far from over at that point. The moment the confidential information falls into the hands of cybercriminals, it immediately transforms into a commodity and enters the shadow market conveyor belt.
In this article, we trace the path of the stolen data, starting from its collection through various tools – such as Telegram bots and advanced administration panels – to the sale of that data and its subsequent reuse in new attacks. We examine how a once leaked username and password become part of a massive digital dossier and why cybercriminals can leverage even old leaks for targeted attacks, sometimes years after the initial data breach.
Data harvesting mechanisms in phishing attacks
Before we trace the subsequent fate of the stolen data, we need to understand exactly how it leaves the phishing page and reaches the cybercriminals.
By analyzing real-world phishing pages, we have identified the most common methods for data transmission:
- Send to an email address.
- Send to a Telegram bot.
- Upload to an administration panel.
It also bears mentioning that attackers may use legitimate services for data harvesting to make their server harder to detect. Examples include online form services like Google Forms, Microsoft Forms, etc. Stolen data repositories can also be set up on GitHub, Discord servers, and other websites. For the purposes of this analysis, however, we will focus on the primary methods of data harvesting.
Data entered into an HTML form on a phishing page is sent to the cybercriminal’s server via a PHP script, which then forwards it to an email address controlled by the attacker. However, this method is becoming less common due to several limitations of email services, such as delivery delays, the risk of the hosting provider blocking the sending server, and the inconvenience of processing large volumes of data.
As an example, let’s look at a phishing kit targeting DHL users.
Phishing kit contents

The index.php file contains the phishing form designed to harvest user data – in this case, an email address and a password.
Phishing form imitating the DHL website

The data that the victim enters into this form is then sent via a script in the next.php file to the email address specified within the mail.php file.
Contents of the PHP scripts

Telegram bots
Unlike the previous method, the script used to send stolen data specifies a Telegram API URL with a bot token and the corresponding Chat ID, rather than an email address. In some cases, the link is hard-coded directly into the phishing HTML form. Attackers create a detailed message template that is sent to the bot after a successful attack. Here is what this looks like in the code:
Code snippet for data submission

Compared to sending data via email, using Telegram bots provides phishers with enhanced functionality, which is why they are increasingly adopting this method. Data arrives in the bot in real time, with instant notification to the operator. Attackers often use disposable bots, which are harder to track and block. Furthermore, their performance does not depend on the quality of phishing page hosting.
Automated administration panels
More sophisticated cybercriminals use specialized software, including commercial frameworks like BulletProofLink and Caffeine, often as a Platform as a Service (PaaS). These frameworks provide a web interface (dashboard) for managing phishing campaigns.
Data harvested from all phishing pages controlled by the attacker is fed into a unified database that can be viewed and managed through their account.
Sending data to the administration panel

These admin panels are used for analyzing and processing victim data. The features of a specific panel depend on the available customization options, but most dashboards typically have the following capabilities:
- Sorting of real-time statistics: the ability to view the number of successful attacks by time and country, along with data filtering options
- Automatic verification: some systems can automatically check the validity of the stolen data like credit cards and login credentials
- Data export: the ability to download the data in various formats for future use or sale
Example of an administration panel

Admin panels are a vital tool for organized cybercriminals.
One campaign often employs several of these data harvesting methods simultaneously.
Sending stolen data to both an email address and a Telegram bot

The data cybercriminals want
The data harvested during a phishing attack varies in value and purpose. In the hands of cybercriminals, it becomes a method of profit and a tool for complex, multi-stage attacks.
Stolen data can be divided into the following categories, based on its intended purpose:
- Immediate monetization: the direct sale of large volumes of raw data or the immediate withdrawal of funds from a victim’s bank account or online wallet.
- Banking details: card number, expiration date, cardholder name, and CVV/CVC.
- Access to online banking accounts and digital wallets: logins, passwords, and one-time 2FA codes.
- Accounts with linked banking details: logins and passwords for accounts that contain bank card details, such as online stores, subscription services, or payment systems like Apple Pay or Google Pay.
- Subsequent attacks for further monetization: using the stolen data to conduct new attacks and generate further profit.
- Credentials for various online accounts: logins and passwords. Importantly, email addresses or phone numbers, which are often used as logins, can hold value for attackers even without the accompanying passwords.
- Phone numbers, used for phone scams, including attempts to obtain 2FA codes, and for phishing via messaging apps.
- Personal data: full name, date of birth, and address, abused in social engineering attacks
- Targeted attacks, blackmail, identity theft, and deepfakes.
- Biometric data: voice and facial projections.
- Scans and numbers of personal documents: passports, driver’s licenses, social security cards, and taxpayer IDs.
- Selfies with documents, used for online loan applications and identity verification.
- Corporate accounts, used for targeted attacks on businesses.
We analyzed phishing and scam attacks conducted from January through September 2025 to determine which data was most frequently targeted by cybercriminals. We found that 88.5% of attacks aimed to steal credentials for various online accounts, 9.5% targeted personal data (name, address, and date of birth), and 2% focused on stealing bank card details.
Distribution of attacks by target data type, January–September 2025 (download)
Selling data on dark web markets
Except for real-time attacks or those aimed at immediate monetization, stolen data is typically not used instantly. Let’s take a closer look at the route it takes.
- Sale of data dumps
Data is consolidated and put up for sale on dark web markets in the form of dumps: archives that contain millions of records obtained from various phishing attacks and data breaches. A dump can be offered for as little as $50. The primary buyers are often not active scammers but rather dark market analysts, the next link in the supply chain. - Sorting and verification
Dark market analysts filter the data by type (email accounts, phone numbers, banking details, etc.) and then run automated scripts to verify it. This checks validity and reuse potential, for example, whether a Facebook login and password can be used to sign in to Steam or Gmail. Data stolen from one service several years ago can still be relevant for another service today because people tend to use identical passwords across multiple websites. Verified accounts with an active login and password command a higher price at the point of sale.
Analysts also focus on combining user data from different attacks. Thus, an old password from a compromised social media site, a login and password from a phishing form mimicking an e-government portal, and a phone number left on a scam site can all be compiled into a single digital dossier on a specific user. - Selling on specialized markets
Stolen data is typically sold on dark web forums and via Telegram. The instant messaging app is often used as a storefront to display prices, buyer reviews, and other details.
Offers of social media data, as displayed in TelegramThe prices of accounts can vary significantly and depend on many factors, such as account age, balance, linked payment methods (bank cards, online wallets), 2FA authentication, and service popularity. Thus, an online store account may be more expensive if it is linked to an email, has 2FA enabled, and has a long history, with a large number of completed orders. For gaming accounts, such as Steam, expensive game purchases are a factor. Online banking data sells at a premium if the victim has a high account balance and the bank itself has a good reputation.
The table below shows prices for various types of accounts found on dark web forums as of 2025*.
Category Price Average price Crypto platforms $60–$400 $105 Banks $70–$2000 $350 E-government portals $15–$2000 $82.5 Social media $0.4–$279 $3 Messaging apps $0.065–$150 $2.5 Online stores $10–$50 $20 Games and gaming platforms $1–$50 $6 Global internet portals $0.2–$2 $0.9 Personal documents $0.5–$125 $15 *Data provided by Kaspersky Digital Footprint Intelligence
- High-value target selection and targeted attacks
Cybercriminals take particular interest in valuable targets. These are users who have access to important information: senior executives, accountants, or IT systems administrators.
Let’s break down a possible scenario for a targeted whaling attack. A breach at Company A exposes data associated with a user who was once employed there but now holds an executive position at Company B. The attackers analyze open-source intelligence (OSINT) to determine the user’s current employer (Company B). Next, they craft a sophisticated phishing email to the target, purportedly from the CEO of Company B. To build trust, the email references some facts from the target’s old job – though other scenarios exist too. By disarming the user’s vigilance, cybercriminals gain the ability to compromise Company B for a further attack.Importantly, these targeted attacks are not limited to the corporate sector. Attackers may also be drawn to an individual with a large bank account balance or someone who possesses important personal documents, such as those required for a microloan application.

Takeaways
The journey of stolen data is like a well-oiled conveyor belt, where every piece of information becomes a commodity with a specific price tag. Today, phishing attacks leverage diverse systems for harvesting and analyzing confidential information. Data flows instantly into Telegram bots and attackers’ administration panels, where it is then sorted, verified, and monetized.
It is crucial to understand that data, once lost, does not simply vanish. It is accumulated, consolidated, and can be used against the victim months or even years later, transforming into a tool for targeted attacks, blackmail, or identity theft. In the modern cyber-environment, caution, the use of unique passwords, multi-factor authentication, and regular monitoring of your digital footprint are no longer just recommendations – they are a necessity.
What to do if you become a victim of phishing
- If a bank card you hold has been compromised, call your bank as soon as possible and have the card blocked.
- If your credentials have been stolen, immediately change the password for the compromised account and any online services where you may have used the same or a similar password. Set a unique password for every account.
- Enable multi-factor authentication in all accounts that support this.
- Check the sign-in history for your accounts and terminate any suspicious sessions.
- If your messaging service or social media account has been compromised, alert your family and friends about potential fraudulent messages sent in your name.
- Use specialized services to check if your data has been found in known data breaches.
- Treat any unexpected emails, calls, or offers with extreme vigilance – they may appear credible because attackers are using your compromised data.
securelist.com/what-happens-to…


OSINT nell'Indagine sull'assalto al Campidoglio degli Stati Uniti
@Privacy Pride
Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/osint-ca…
Dopo il grande pezzo sugli ecoceronti, Claudia torna a noi per regalarci una nuova perla dedicata all'OSINT. Non è roba da nerd, anzi, è qualcosa che ci appartiene culturalmente e che abbiamo imparato fin dai tempi dell'asilo.

freezonemagazine.com/articoli/…
Quando il talento incontra lo studio e la passione, allora nascono percorsi artistici dall’alto potenziale di sviluppo. Questo è il caso di Sara Gioielli, pianista e diplomata in canto jazz in quel Sancta Sanctorum che è il conservatorio di San Pietro a Majella di Napoli, straordinaria fucina di artisti e compositori fin dalla sua fondazione […]
L'articolo Sara Gioielli – Gioielli neri proviene da
la guerra è per veri duri, non per stracchini... che ormai significa non riconoscere che la guerra, come ogni attività, è tecnologica, e basata sulle competenze. ma loro pensano che basti stuprare un po' di civili per vincere.
qr.ae/pCgtXz
"Lo storico ha avvertito che se il Cremlino considerasse la sua campagna in Ucraina un successo, gli Stati baltici potrebbero essere il prossimo obiettivo. Ha ricordato le lezioni del passato: dopo la Prima Guerra Mondiale, inglesi e francesi non potevano credere che qualcuno volesse un'altra guerra, e quindi sottovalutarono Hitler.
"Abbiamo assistito a una cosa simile negli anni 2000 <...> Nessuno credeva che qualcuno avrebbe voluto un'altra guerra di terra sul territorio europeo. [Sotto Putin], la pura brutalità del metodo di guerra russo potrebbe benissimo essere riapplicata sul territorio europeo", ha concluso Beevor."

Avvento: p. Pasolini, “l’unità non si costruisce eliminando le differenze”, “gli algoritmi creano bolle”, no a “pensiero unico” - AgenSIR
"Ogni volta che l'unità si costruisce eliminando le differenze il risultato non è la comunione, è la morte".M.Michela Nicolais (AgenSIR)
Archeologia cristiana: lettera apostolica Leone XIV. Stasolla (Sapienza), “archeologo non è un custode del passato, ma un interprete del presente”
“La nostra disciplina è fatta di memoria, soprattutto di memoria collettiva, quella che unisce persone di cui ignoriamo le storie individuali e che permette di costruire identità condivise che è molto più della somma delle memorie personali”.
Consider This Pocket Machine For Your iPhone Backups

What if you find yourself as an iPhone owner, desiring a local backup solution — no wireless tech involved, no sending off data to someone else’s server, just an automatic device-to-device file sync? Check out [Giovanni]’s ios-backup-machine project, a small Linux-powered device with an e-ink screen that backs up your iPhone whenever you plug the two together with a USB cable.
The system relies on libimobiledevice, and is written to make simple no-interaction automatic backups work seamlessly. The backup status is displayed on the e-ink screen, and at boot, it shows up owner’s information of your choice, say, a phone number — helpful if the device is ever lost. For preventing data loss, [Giovanni] recommends a small uninterruptible power supply, and the GitHub-described system is married to a PiSugar board, though you could go without or add a different one, for sure. Backups are encrypted through iPhone internal mechanisms, so while it appears you might not be able to dig into one, they are perfectly usable for restoring your device should it get corrupted or should you need to provision a new phone to replace the one you just lost.
Easy to set up, fully open, and straightforward to use — what’s not to like? Just put a few off-the-shelf boards together, print the case, and run the setup instructions, you’ll have a pocket backup machine ready to go. Now, if you’re considering this as a way to decrease your iTunes dependency, you might as well check out this nifty tool that helps you get out the metadata for the music you’ve bought on iTunes.
, “andare oltre lo scivolo, raccontare un’Italia che lavora insieme” - AgenSIR")
Turn me on, turn me off: Zigbee assessment in industrial environments

We all encounter IoT and home automation in some form or another, from smart speakers to automated sensors that control water pumps. These services appear simple and straightforward to us, but many devices and protocols work together under the hood to deliver them.
One of those protocols is Zigbee. Zigbee is a low-power wireless protocol (based on IEEE 802.15.4) used by many smart devices to talk to each other. It’s common in homes, but is also used in industrial environments where hundreds or thousands of sensors may coordinate to support a process.
There are many guides online about performing security assessments of Zigbee. Most focus on the Zigbee you see in home setups. They often skip the Zigbee used at industrial sites, what I call ‘non-public’ or ‘industrial’ Zigbee.
In this blog, I will take you on a journey through Zigbee assessments. I’ll explain the basics of the protocol and map the attack surface likely to be found in deployments. I’ll also walk you through two realistic attack vectors that you might see in facilities, covering the technical details and common problems that show up in assessments. Finally, I will present practical ways to address these problems.
Zigbee introduction
Protocol overview
Zigbee is a wireless communication protocol designed for low-power applications in wireless sensor networks. Based on the IEEE 802.15.4 standard, it was created for short-range and low-power communication. Zigbee supports mesh networking, meaning devices can connect through each other to extend the network range. It operates on the 2.4 GHz frequency band and is widely used in smart homes, industrial automation, energy monitoring, and many other applications.
You may be wondering why there’s a need for Zigbee when Wi-Fi is everywhere? The answer depends on the application. In most home setups, Wi-Fi works well for connecting devices. But imagine you have a battery-powered sensor that isn’t connected to your home’s electricity. If it used Wi-Fi, its battery would drain quickly – maybe in just a few days – because Wi-Fi consumes much more power. In contrast, the Zigbee protocol allows for months or even years of uninterrupted work.
Now imagine an even more extreme case. You need to place sensors in a radiation zone where humans can’t go. You drop the sensors from a helicopter and they need to operate for months without a battery replacement. In this situation, power consumption becomes the top priority. Wi-Fi wouldn’t work, but Zigbee is built exactly for this kind of scenario.
Also, Zigbee has a big advantage if the area is very large, covering thousands of square meters and requiring thousands of sensors: it supports thousands of nodes in a mesh network, while Wi-Fi is usually limited to hundreds at most.
There are lots more ins and outs, but these are the main reasons Zigbee is preferred for large-scale, low-power sensor networks.
Since both Zigbee and IEEE 802.15.4 define wireless communication, many people confuse the two. The difference between them, to put it simply, concerns the layers they support. IEEE 802.15.4 defines the physical (PHY) and media access control (MAC) layers, which basically determine how devices send and receive data over the air. Zigbee (as well as other protocols like Thread, WirelessHART, 6LoWPAN, and MiWi) builds on IEEE 802.15.4 by adding the network and application layers that define how devices form a network and communicate.
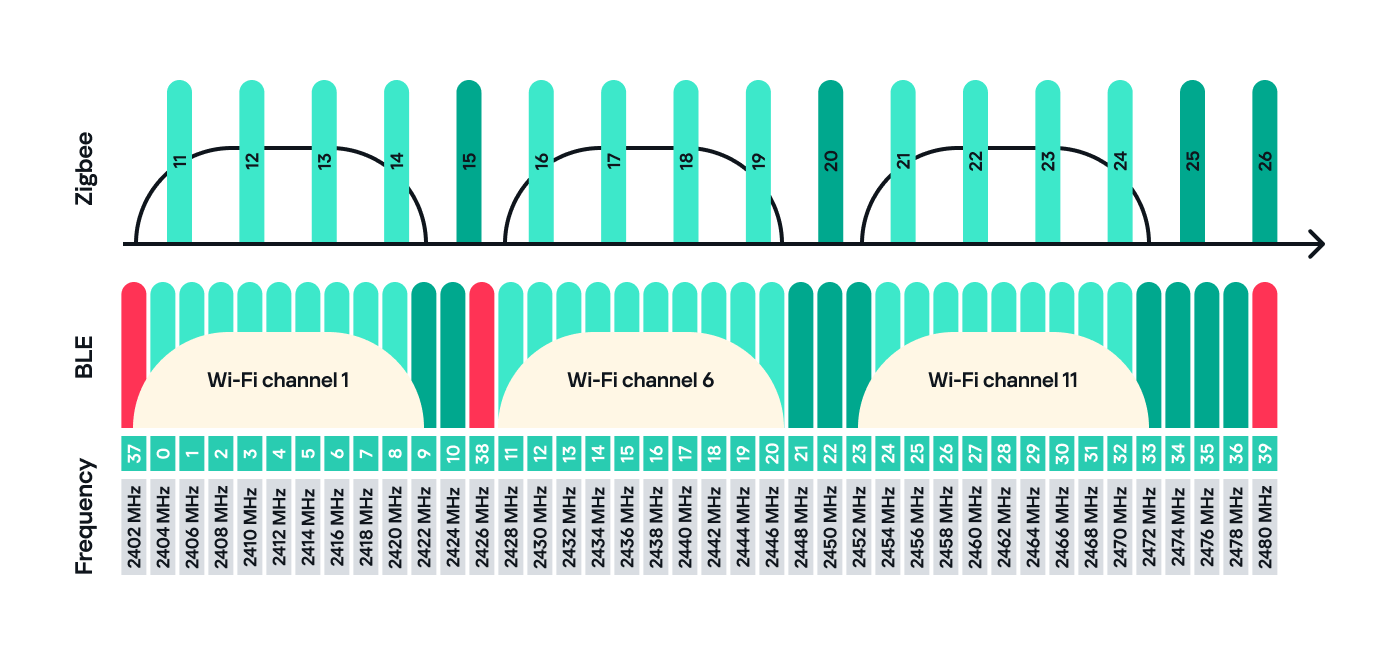
Zigbee operates in the 2.4 GHz wireless band, which it shares with Wi-Fi and Bluetooth. The Zigbee band includes 16 channels, each with a 2 MHz bandwidth and a 5 MHz gap between channels.
This shared frequency means Zigbee networks can sometimes face interference from Wi-Fi or Bluetooth devices. However, Zigbee’s low power and adaptive channel selection help minimize these conflicts.
Devices and network
There are three main types of Zigbee devices, each of which plays a different role in the network.
- Zigbee coordinator
The coordinator is the brain of the Zigbee network. A Zigbee network is always started by a coordinator and can only contain one coordinator, which has the fixed address 0x0000.
It performs several key tasks:- Starts and manages the Zigbee network.
- Chooses the Zigbee channel.
- Assigns addresses to other devices.
- Stores network information.
- Chooses the PAN ID: a 2-byte identifier (for example, 0x1234) that uniquely identifies the network.
- Sets the Extended PAN ID: an 8-byte value, often an ASCII name representing the network.
The coordinator can have child devices, which can be either Zigbee routers or Zigbee end devices.
- Zigbee router
The router works just like a router in a traditional network: it forwards data between devices, extends the network range and can also accept child devices, which are usually Zigbee end devices.
Routers are crucial for building large mesh networks because they enable communication between distant nodes by passing data through multiple hops. - Zigbee end device
The end device, also referred to as a Zigbee endpoint, is the simplest and most power-efficient type of Zigbee device. It only communicates with its parent, either a coordinator or router, and sleeps most of the time to conserve power. Common examples include sensors, remotes, and buttons.
Zigbee end devices do not accept child devices unless they are configured as both a router and an endpoint simultaneously.
Each of these device types, also known as Zigbee nodes, has two types of address:
- Short address: two bytes long, similar to an IP address in a TCP/IP network.
- Extended address: eight bytes long, similar to a MAC address.
Both addresses can be used in the MAC and network layers, unlike in TCP/IP, where the MAC address is used only in Layer 2 and the IP address in Layer 3.
Zigbee setup
Zigbee has many attack surfaces, such as protocol fuzzing and low-level radio attacks. In this post, however, I’ll focus on application-level attacks. Our test setup uses two attack vectors and is intentionally small to make the concepts clear.
In our setup, a Zigbee coordinator is connected to a single device that functions as both a Zigbee endpoint and a router. The coordinator also has other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE), while the endpoint has a relay attached that the coordinator can switch on or off over Zigbee. This relay can be triggered by events coming from any interface, for example, a Bluetooth command or an Ethernet message.
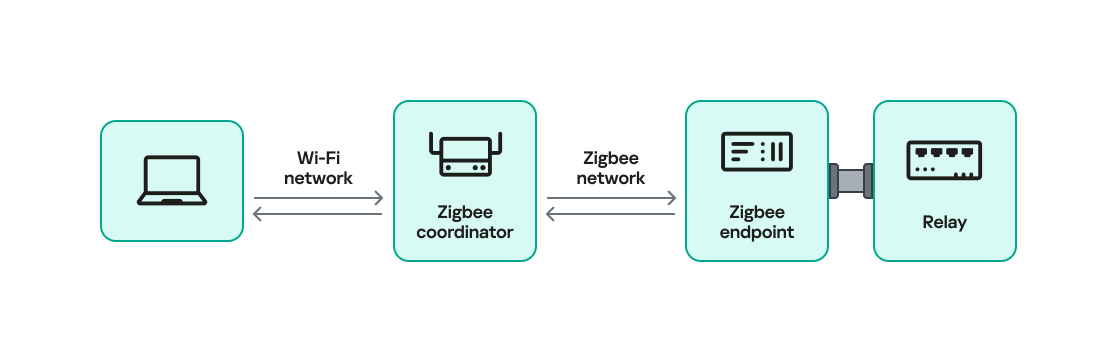
Our goal will be to take control of the relay and toggle its state (turn it off and on) using only the Zigbee interface. Because the other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE) are out of scope, the attack must work by hijacking Zigbee communication.
For the purposes of this research, we will attempt to hijack the communication between the endpoint and the coordinator. The two attack vectors we will test are:
- Spoofed packet injection: sending forged Zigbee commands made to look like they come from the coordinator to trigger the relay.
- Coordinator impersonation (rejoin attack): impersonating the legitimate coordinator to trick the endpoint into joining the attacker-controlled coordinator and controlling it directly.
Spoofed packet injection
In this scenario, we assume the Zigbee network is already up and running and that both the coordinator and endpoint nodes are working normally. The coordinator has additional interfaces, such as Ethernet, and the system uses those interfaces to trigger the relay. For instance, a command comes in over Ethernet and the coordinator sends a Zigbee command to the endpoint to toggle the relay. Our goal is to toggle the relay by injecting simulated legitimate Zigbee packets, using only the Zigbee link.
Sniffing
The first step in any radio assessment is to sniff the wireless traffic so we can learn how the devices talk. For Zigbee, a common and simple tool is the nRF52840 USB dongle by Nordic Semiconductor. With the official nRF Sniffer for 802.15.4 firmware, the dongle can run in promiscuous mode to capture all 802.15.4/Zigbee traffic. Those captures can be opened in Wireshark with the appropriate dissector to inspect the frames.
How do you find the channel that’s in use?
Zigbee runs on one of the 16 channels that we mentioned earlier, so we must set the sniffer to the same channel that the network uses. One practical way to scan the channels is to change the sniffer channel manually in Wireshark and watch for Zigbee traffic. When we see traffic, we know we’ve found the right channel.
After selecting the channel, we will be able to see the communication between the endpoint and the coordinator, though it will most likely be encrypted:
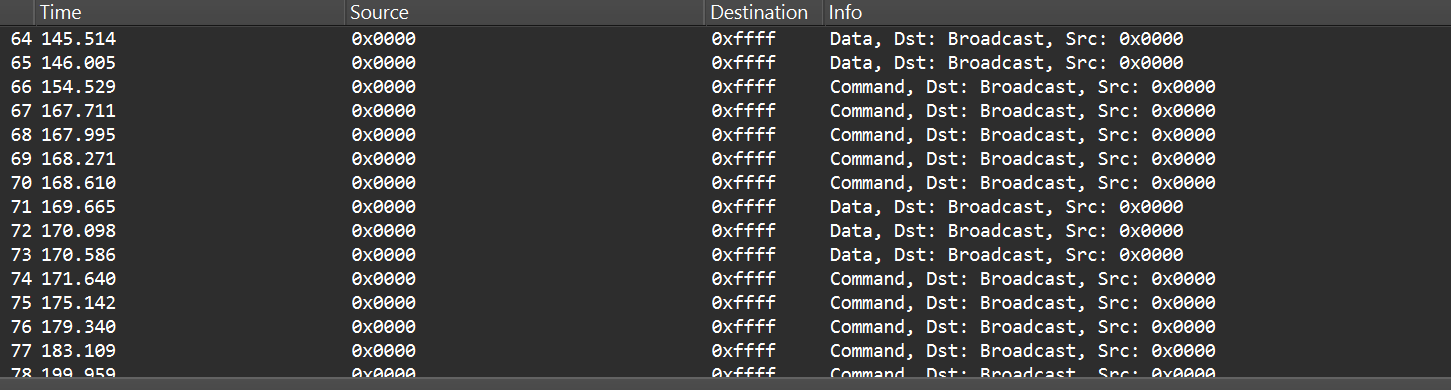
In the “Info” column, we can see that Wireshark only identifies packets as Data or Command without specifying their exact type, and that’s because the traffic is encrypted.
Even when Zigbee payloads are encrypted, the network and MAC headers remain visible. That means we can usually read things like source and destination addresses, PAN ID, short and extended MAC addresses, and frame control fields. The application payload (i.e., the actual command to toggle the relay) is typically encrypted at the Zigbee network/application layer, so we won’t see it in clear text without encryption keys. Nevertheless, we can still learn enough from the headers.
Decryption
Zigbee supports several key types and encryption models. In this post, we’ll keep it simple and look at a case involving only two security-related devices: a Zigbee coordinator and a device that is both an endpoint and a router. That way, we’ll only use a network encryption model, whereas with, say, mesh networks there can be various encryption models in use.
The network encryption model is a common concept. The traffic that we sniffed earlier is typically encrypted using the network key. This key is a symmetric AES-128 key shared by all devices in a Zigbee network. It protects network-layer packets (hop-by-hop) such as routing and broadcast packets. Because every router on the path shares the network key, this encryption method is not considered end-to-end.
Depending on the specific implementation, Zigbee can use two approaches for application payloads:
- Network-layer encryption (hop-by-hop): the network key encrypts the Application Support Sublayer (APS) data, the sublayer of the application layer in Zigbee. In this case, each router along the route can decrypt the APS payload. This is not end-to-end encryption, so it is not recommended for transmitting sensitive data.
- Link key (end-to-end) encryption: a link key, which is also an AES-128 key, is shared between two devices (for example, the coordinator and an endpoint).
The link key provides end-to-end protection of the APS payload between the two devices.
Because the network key could allow an attacker to read and forge many types of network traffic, it must be random and protected. Exposing the key effectively compromises the entire network.
When a new device joins, the coordinator (Trust Center) delivers the network key using a Transport Key command. That transport packet must be protected by a link key so the network key is not exposed in clear text. The link key authenticates the joining device and protects the key delivery.
The image below shows the transport packet:

There are two common ways link keys are provided:
- Pre-installed: the device ships with an installation code or link key already set.
- Key establishment: the device runs a key-establishment protocol.
A common historical problem is the global default Trust Center link key, “ZigBeeAlliance09”. It was included in early versions of Zigbee (pre-3.0) to facilitate testing and interoperability. However, many vendors left it enabled on consumer devices, and that has caused major security issues. If an attacker knows this key, they can join devices and read or steal the network key.
Newer versions – Zigbee 3.0 and later – introduced installation codes and procedures to derive unique link keys for each device. An installation code is usually a factory-assigned secret (often encoded on the device label) that the Trust Center uses to derive a unique link key for the device in question. This helps avoid the problems caused by a single hard-coded global key.
Unfortunately, many manufacturers still ignore these best practices. During real assessments, we often encounter devices that use default or hard-coded keys.
How can these keys be obtained?
If an endpoint has already joined the network and communicates with the coordinator using the network key, there are two main options for decrypting traffic:
- Guess or brute-force the network key. This is usually impractical because a properly generated network key is a random AES-128 key.
- Force the device to rejoin and capture the transport key. If we can make the endpoint leave the network and then rejoin, the coordinator will send the transport key. Capturing that packet can reveal the network key, but the transport key itself is protected by the link key. Therefore, we still need the link key.
To obtain the network and link keys, many approaches can be used:
- The well-known default link key, ZigBeeAlliance09. Many legacy devices still use it.
- Identify the device manufacturer and search for the default keys used by that vendor. We can find the manufacturer by:
- Checking the device MAC/OUI (the first three bytes of the 64-bit extended address often map to a vendor).
- Physically inspecting the device (label, model, chip markings).
- Extract the firmware from the coordinator or device if we have physical access and search for hard-coded keys inside the firmware images.
Once we have the relevant keys, the decryption process is straightforward:
- Open the capture in Wireshark.
- Go to Edit -> Preferences -> Protocols -> Zigbee.
- Add the network key and any link keys in our possession.
- Wireshark will then show decrypted APS payloads and higher-level Zigbee packets.
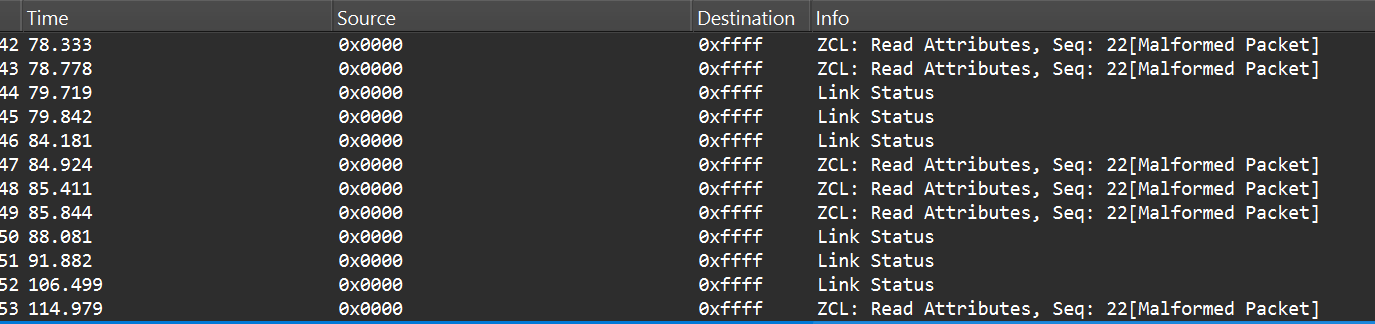
After successful decryption, packet types and readable application commands will be visible, such as Link Status or on/off cluster commands:
Choose your gadget
Now that we can read and potentially decrypt traffic, we need hardware and software to inject packets over the Zigbee link between the coordinator and the endpoint. To keep this practical and simple, I opted for cheap, widely available tools that are easy to set up.
For the hardware, I used the nRF52840 USB dongle, the same device we used for sniffing. It’s inexpensive, easy to find, and supports IEEE 802.15.4/Zigbee, so it can sniff and transmit.
The dongle runs the firmware we can use. A good firmware platform is Zephyr RTOS. Zephyr has an IEEE 802.15.4 radio API that enables the device to receive raw frames, essentially enabling sniffer mode, as well as send raw frames as seen in the snippets below.
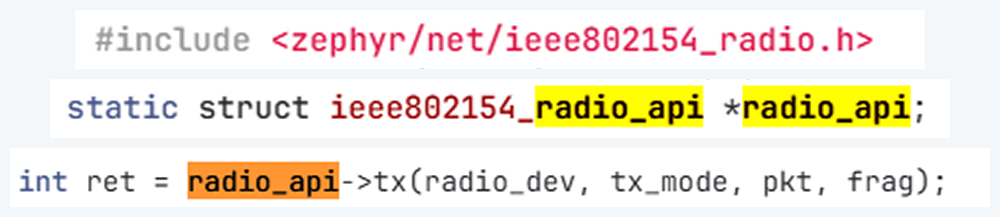
Using this API and other components, we created a transceiver implementation written in C, compiled it to firmware, and flashed it to the dongle. The firmware can expose a simple runtime interface, such as a USB serial port, which allows us to control the radio from a laptop.
At runtime, the dongle listens on the serial port (for example, /dev/ttyACM1). Using a script, we can send it raw bytes, which the firmware will pass to the radio API and transmit to the channel. The following is an example of a tiny Python script to open the serial port:
I used the Scapy tool with the 802.15.4/Zigbee extensions to build Zigbee packets. Scapy lets us assemble packets layer-by-layer – MAC → NWK → APS → ZCL – and then convert them to raw bytes to send to the dongle. We will talk about APS and ZCL in more detail later.
Here is an example of how we can use Scapy to craft an APS layer packet:
from scapy.layers.dot15d4 import Dot15d4, Dot15d4FCS, Dot15d4Data, Dot15d4Cmd, Dot15d4Beacon, Dot15d4CmdAssocResp
from scapy.layers.zigbee import ZigbeeNWK, ZigbeeAppDataPayload, ZigbeeSecurityHeader, ZigBeeBeacon, ZigbeeAppCommandPayload
Before sending, the packet must be properly encrypted and signed so the endpoint accepts it. That means applying AES-CCM (AES-128 with MIC) using the network key (or the correct link key) and adhering to Zigbee’s rules for packet encryption and MIC calculation. This is how we implemented the encryption and MIC in Python (using a cryptographic library) after building the Scapy packet. We then sent the final bytes to the dongle.
This is how we implemented the encryption and MIC:
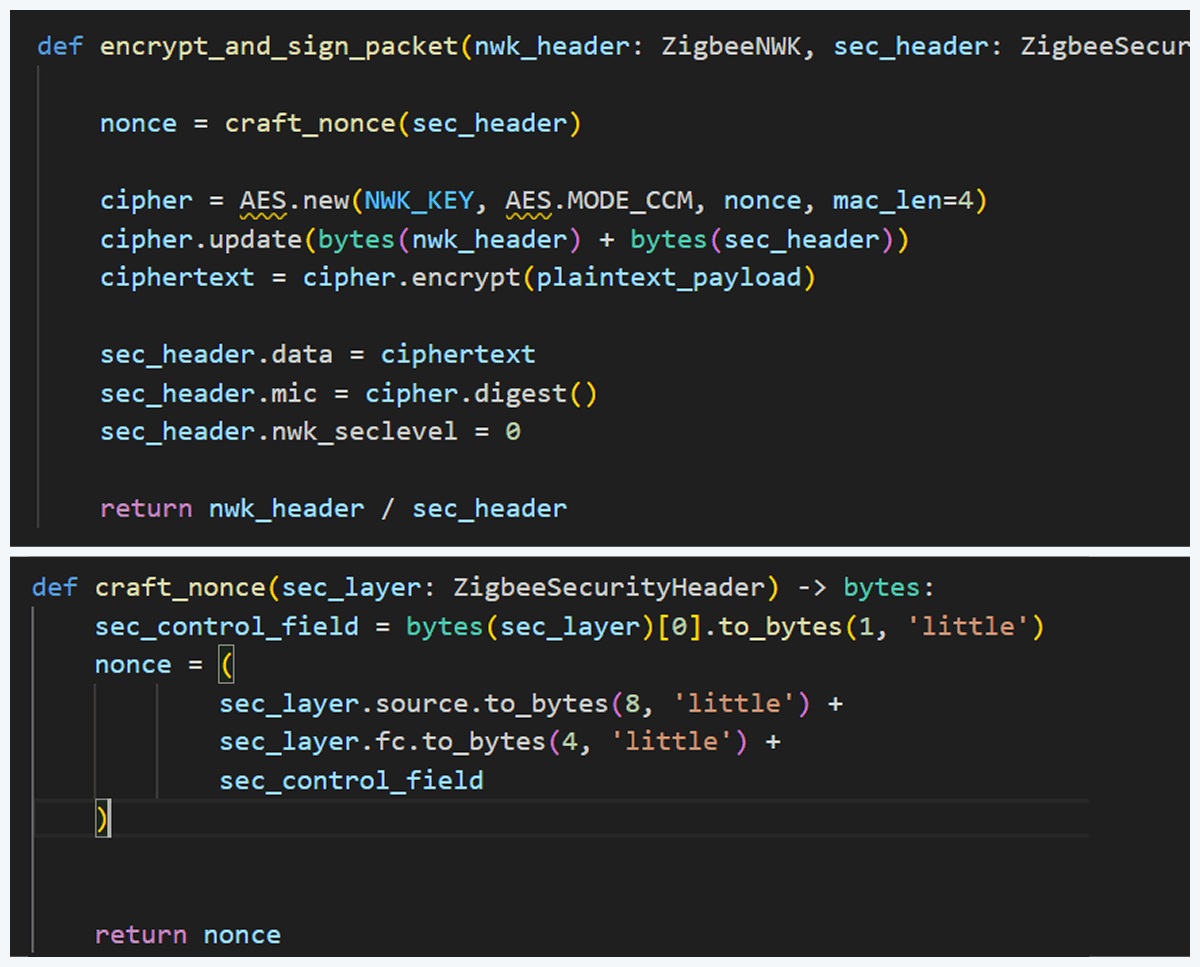
Crafting the packet
Now that we know how to inject packets, the next question is what to inject. To toggle the relay, we simply need to send the same type of command that the coordinator already sends. The easiest way to find that command is to sniff the traffic and read the application payload. However, when we look at captures in Wireshark, we can see many packets under ZCL marked [Malformed Packet].
A “malformed” ZCL packet usually means Wireshark could not fully interpret the packet because the application layer is non-standard or lacks details Wireshark expects. To understand why this happens, let’s look at the Zigbee application layer.
The Zigbee application layer consists of four parts:
- Application Support Sublayer (APS): routes messages to the correct profile, endpoint, and cluster, and provides application-level security.
- Application Framework (AF): contains the application objects that implement device functionality. These objects reside on endpoints (logical addresses 1–240) and expose clusters (sets of attributes and commands).
- Zigbee Cluster Library (ZCL): defines standard clusters and commands so devices can interoperate.
- Zigbee Device Object (ZDO): handles device discovery and management (out of scope for this post).
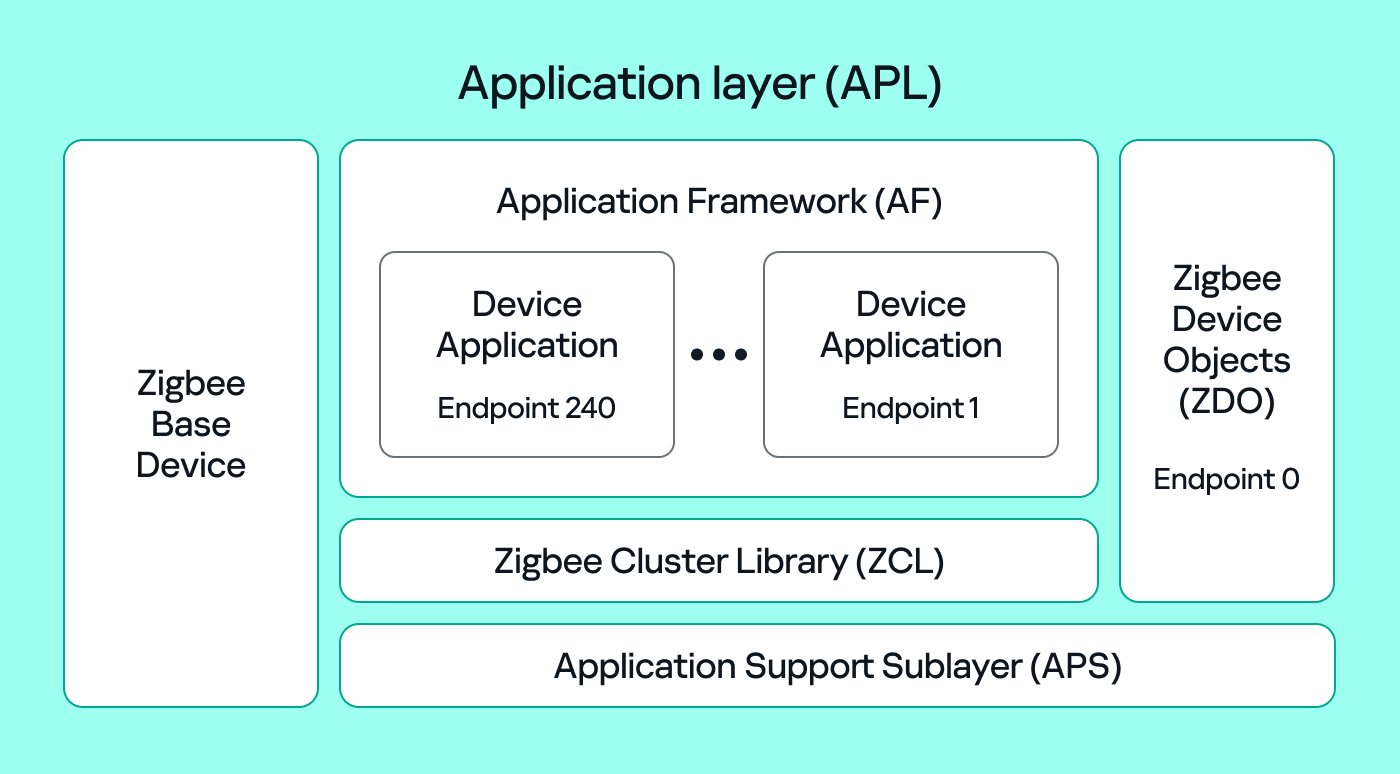
To make sense of application traffic, we must introduce three concepts:
- Profile: a rulebook for how devices should behave for a specific use case. Public (standard) profiles are managed by the Connectivity Standards Alliance (CSA). Vendors can also create private profiles for proprietary features.
- Cluster: a set of attributes and commands for a particular function. For example, the On/Off cluster contains On and Off commands and an OnOff attribute that displays the current state.
- Endpoint: a logical “port” on the device where a profile and clusters reside. A device can host multiple endpoints for different functions.
Putting all this together, in the standard home automation traffic we see APS pointing to the home automation profile, the On/Off cluster, and a destination endpoint (for example, endpoint 1). In ZCL, the byte 0x00 often means “Off”.
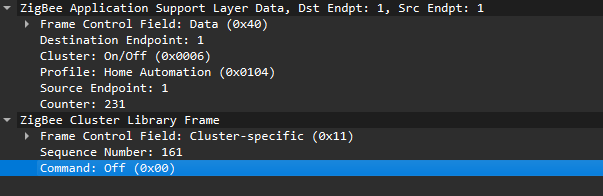
In many industrial setups, vendors use private profiles or custom application frameworks. That’s why Wireshark can’t decode the packets; the AF payload is custom, so the dissector doesn’t know the format.
So how do we find the right bytes to toggle the switch when the application is private? Our strategy has two phases.
- Passive phase
Sniff traffic while the system is driven legitimately. For example, trigger the relay from another interface (Ethernet or Bluetooth) and capture the Zigbee packets used to toggle the relay. If we can decrypt the captures, we can extract the application payload that correlates with the on/off action. - Active phaseWith the legitimate payload at hand, we can now turn to creating our own packet. There are two ways to do that. First, we need to replay or duplicate the captured application payload exactly as it is. This works if there are no freshness checks like sequence numbers. Otherwise, we have to reverse-engineer the payload and adjust any counters or fields that prevent replay. For instance, many applications include an application-level counter. If the device ignores packets with a lower application counter, we must locate and increment that counter when we craft our packet.

Another important protective measure is the frame counter inside the Zigbee security header (in the network header security fields). The frame counter prevents replay attacks; the receiver expects the frame counter to increase with each new packet, and will reject packets with a lower or repeated counter.
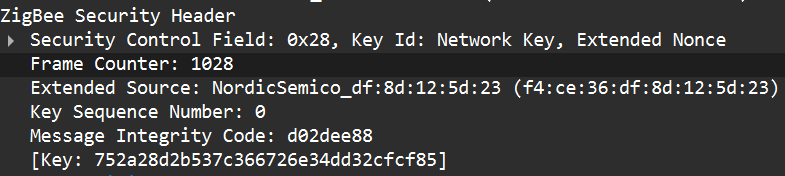
So, in the active phase, we must:
- Sniff the traffic until the coordinator sends a valid packet to the endpoint.
- Decrypt the packet, extract the counters and increase them by one.
- Build a packet with the correct APS/AF fields (profile, endpoint, cluster).
- Include a valid ZCL command or the vendor-specific payload that we identified in the passive phase.
- Encrypt and sign the packet with the correct network or link key.
- Make sure both the application counter (if used) and the Zigbee frame counter are modified so the packet is accepted.
The whole strategy for this phase will look like this:
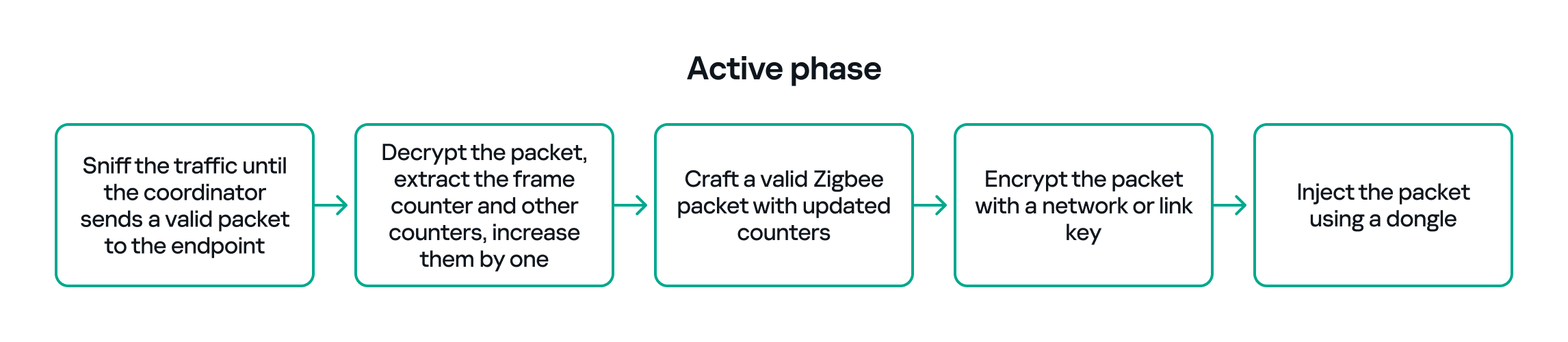
If all of the above are handled correctly, we will be able to hijack the Zigbee communication and toggle the relay (turn it off and on) using only the Zigbee link.
Coordinator impersonation (rejoin attack)
The goal of this attack vector is to force the Zigbee endpoint to leave its original coordinator’s network and join our spoofed network so that we can take control of the device. To do this, we must achieve two things:
- Force the endpoint to leave the original network.
- Spoof the original coordinator and trick the node into joining our fake coordinator.
Force leaving
To better understand how to manipulate endpoint connections, let’s first describe the concept of a beacon frame. Beacon frames are periodic announcements sent by a coordinator and by routers. They advertise the presence of a network and provide join information, such as:
- PAN ID and Extended PAN ID
- Coordinator address
- Stack/profile information
- Device capacity (for example, whether the coordinator can accept child devices)
When a device wants to join, it sends a beacon request across Zigbee channels and waits for beacon replies from nearby coordinators/routers. Even if the network is not beacon-enabled for regular synchronization, beacon frames are still used during the join/discovery process, so they are mandatory when a node tries to discover networks.
Note that beacon frames exist at both the Zigbee and IEEE 802.15.4 levels. The MAC layer carries the basic beacon structure that Zigbee then extends with network-specific fields.

Now, we can force the endpoint to leave its network by abusing how Zigbee handles PAN conflicts. If a coordinator sees beacons from another coordinator using the same PAN ID and the same channel, it may trigger a PAN ID conflict resolution. When that happens, the coordinator can instruct its nodes to change PAN ID and rejoin, which causes them to leave and then attempt to join again. That rejoin window gives us an opportunity to advertise a spoofed coordinator and capture the joining node.
In the capture shown below, packet 7 is a beacon generated by our spoofed coordinator using the same PAN ID as the real network. As a result, the endpoint with the address 0xe8fa leaves the network (see packets 14–16).

Choose me
After forcing the endpoint to leave its original network by sending a fake beacon, the next step is to make the endpoint choose our spoofed coordinator. At this point, we assume we already have the necessary keys (network and link keys) and understand how the application behaves.
To impersonate the original coordinator, our spoofed coordinator must reply to any beacon request the endpoint sends. The beacon response must include the same Extended PAN ID (and other fields) that the endpoint expects. If the endpoint deems our beacon acceptable, it may attempt to join us.
I can think of two ways to make the endpoint prefer our coordinator.
- Jam the real coordinator
Use a device that reduces the real coordinator’s signal at the endpoint so that it appears weaker, forcing the endpoint to prefer our beacon. This requires extra hardware. - Exploit undefined or vendor-specific behavior
Zigbee stacks sometimes behave slightly differently across vendors. One useful field in a beacon is the Update ID field. It increments when a coordinator changes network configuration.
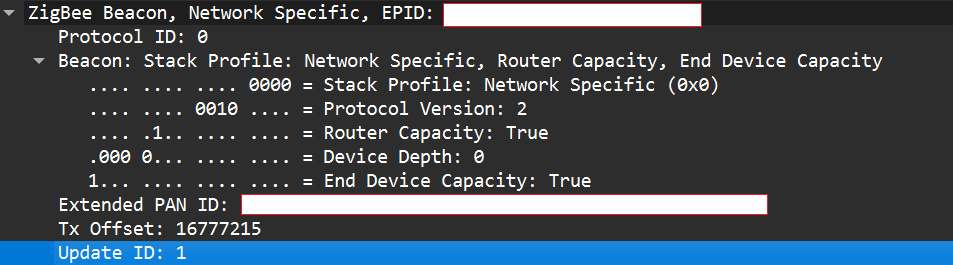
If two coordinators advertise the same Extended PAN ID but one has a higher Update ID, some stacks will prefer the beacon with the higher Update ID. This is undefined behavior across implementations; it works on some stacks but not on others. In my experience, sometimes it works and sometimes it fails. There are lots of other similar quirks we can try during an assessment.
Even if the endpoint chooses our fake coordinator, the connection may be unstable. One main reason for that is the timing. The endpoint expects ACKs for the frames it sends to the coordinator, as well as fast responses regarding connection initiation packets. If our responder is implemented in Python on a laptop that receives packets, builds responses, and forwards them to a dongle, the round trip will be too slow. The endpoint will not receive timely ACKs or packets and will drop the connection.
In short, we’re not just faking a few packets; we’re trying to reimplement parts of Zigbee and IEEE 802.15.4 that must run quickly and reliably. This is usually too slow for production stacks when done in high-level, interpreted code.
A practical fix is to run a real Zigbee coordinator stack directly on the dongle. For example, the nRF52840 dongle can act as a coordinator if flashed with the right Nordic SDK firmware (see Nordic’s network coordinator sample). That provides the correct timing and ACK behavior needed for a stable connection.
However, that simple solution has one significant disadvantage. In industrial deployments we often run into incompatibilities. In my tests I compared beacons from the real coordinator and the Nordic coordinator firmware. Notable differences were visible in stack profile headers:
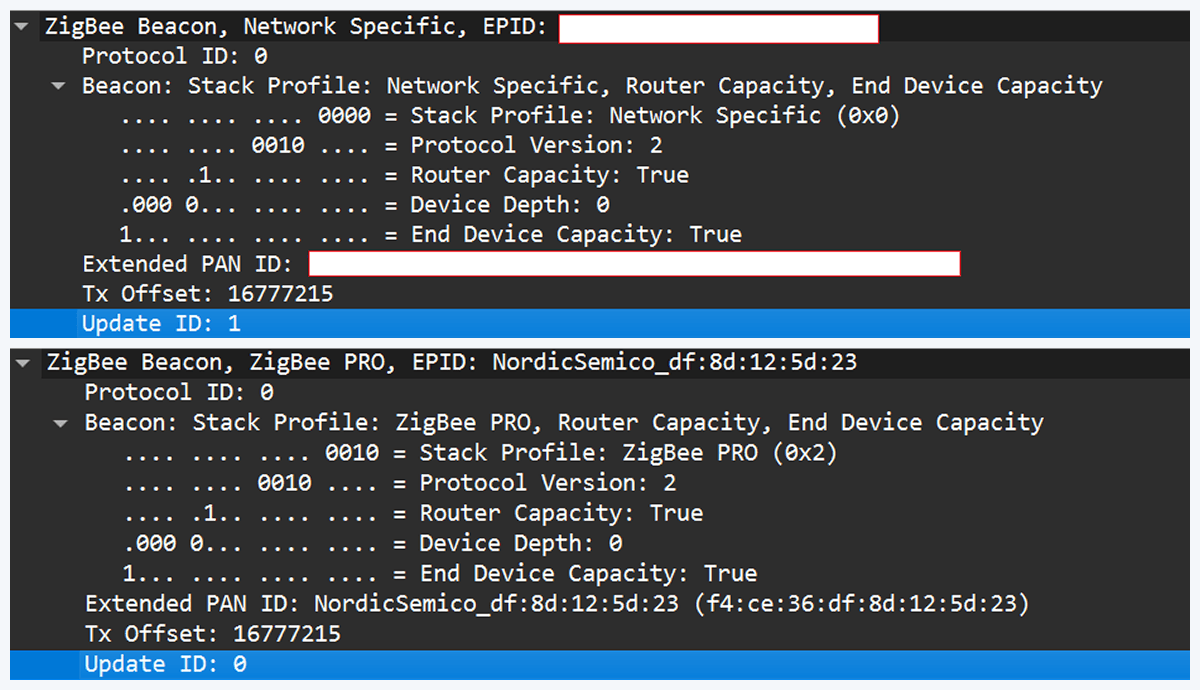
The stack profile identifies the network profile type. Common values include 0x00, which is a network-specific (private) profile, and 0x02, which is a Zigbee Pro (public) profile.
If the endpoint expects a network-specific profile (i.e., it uses a private vendor profile) and we provide Zigbee Pro, the endpoint will refuse to join. Devices that only understand private profiles will not join public-profile networks, and vice versa. In my case, I could not change the Nordic firmware to match the proprietary stack profile, so the endpoint refused to join.
Because of this discrepancy, the “flash a coordinator firmware on the dongle” fix was ineffective in that environment. This is why the standard off-the-shelf tools and firmware often fail in industrial cases, forcing us to continue working with and optimizing our custom setup instead.
Back to the roots
In our previous test setup we used a sniffer in promiscuous mode, which receives every frame on the air regardless of destination. Real Zigbee (IEEE 802.15.4) nodes do not work like that. At the MAC/802.15.4 layer, a node filters frames by PAN ID and destination address. A frame is only passed to upper layers if the PAN ID matches and the destination address is the node’s address or a broadcast address.
We can mimic that real behavior on the dongle by running Zephyr RTOS and making the dongle act as a basic 802.15.4 coordinator. In that role, we set a PAN ID and short network address on the dongle so that the radio only accepts frames that match those criteria. This is important because it allows the dongle to handle auto-ACKs and MAC-level timing: the dongle will immediately send ACKs at the MAC level.
With the dongle doing MAC-level work (sending ACKs and PAN filtering), we can implement the Zigbee logic in Python. Scapy helps a lot with packet construction: we can create our own beacons with the headers matching those of the original coordinator, which solves the incompatibility problem. However, we must still implement the higher-level Zigbee state machine in our code, including connection initiation, association, network key handling, APS/AF behavior, and application payload handling. That’s the hardest part.
There is one timing problem that we cannot solve in Python: the very first steps of initiating a connection require immediate packet responses. To handle this issue, we implemented the time-critical parts in C on the dongle firmware. For example, we can statically generate the packets for connection initiation in Python and hard-code them in the firmware. Then, using “if” statements, we can determine how to respond to each packet from the endpoint.
So, we let the dongle (C/Zephyr) handle MAC-level ACKs and the initial association handshake, but let Python build higher-level packets and instruct the dongle what to send next when dealing with the application level. This hybrid model reduces latency and maintains a stable connection. The final architecture looks like this:
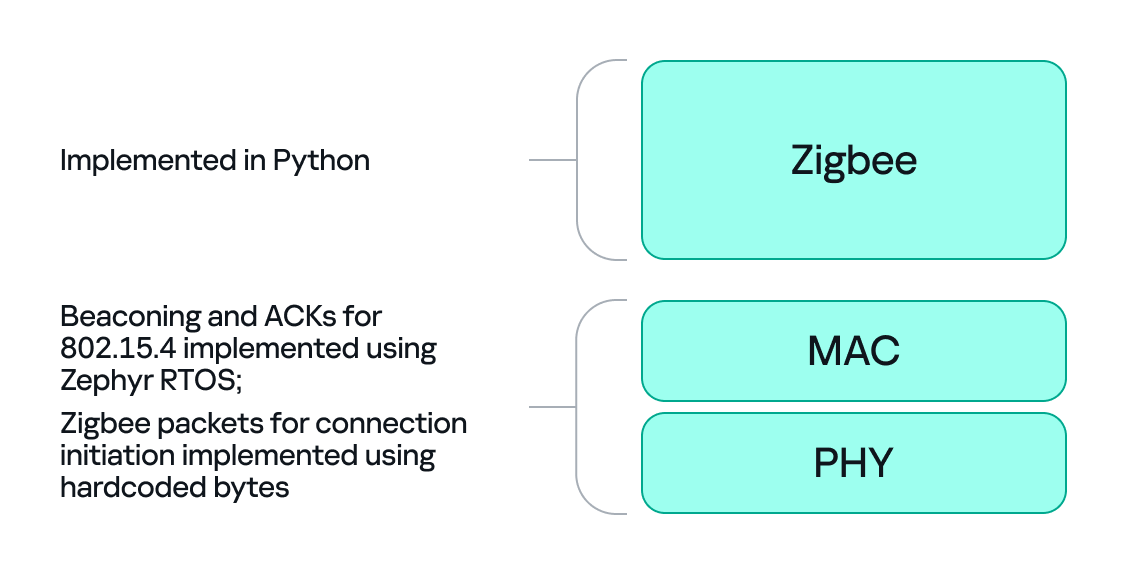
Deliver the key
Here’s a quick recap of how joining works: a Zigbee endpoint broadcasts beacon requests across channels, waits for beacon responses, chooses a coordinator, and sends an association request, followed by a data request to identify its short address. The coordinator then sends a transport key packet containing the network key. If the endpoint has the correct link key, it can decrypt the transport key packet and obtain the network key, meaning it has now been authenticated. From that point on, network traffic is encrypted with the network key. The entire process looks like this:

The sticking point is the transport key packet. This packet is protected using the link key, a per-device key shared between the coordinator (Trust Center) and the joining endpoint. Before the link key can be used for encryption, it often needs to be processed (hashed/derived) according to Zigbee’s key derivation rules. Since there is no trivial Python implementation that implements this hashing algorithm, we may need to implement the algorithm ourselves.
I implemented the required key derivation; the code is available on our GitHub.
Now that we’ve managed to obtain the hashed link key and deliver it to the endpoint, we can successfully mimic a coordinator.
The final success
If we follow the steps above, we can get the endpoint to join our spoofed coordinator. Once the endpoint joins, it will often remain associated with our coordinator, even after we power it down (until another event causes it to re-evaluate its connection). From that point on, we can interact with the device at the application layer using Python. Getting access as a coordinator allowed us to switch the relay on and off as intended, but also provided much more functionality and control over the node.
Conclusion
In conclusion, this study demonstrates why private vendor profiles in industrial environments complicate assessments: common tools and frameworks often fail, necessitating the development of custom tools and firmware. We tested a simple two-node scenario, but with multiple nodes the attack surface changes drastically and new attack vectors emerge (for example, attacks against routing protocols).
As we saw, a misconfigured Zigbee setup can lead to a complete network compromise. To improve Zigbee security, use the latest specification’s security features, such as using installation codes to derive unique link keys for each device. Also, avoid using hard-coded or default keys. Finally, it is not recommended to use the network key encryption model. Add another layer of security in addition to the network level protection by using end-to-end encryption at the application level.
Copia e Incolla e hai perso l’account di Microsoft 365! Arriva ConsentFix e la MFA è a rischio
Un nuovo schema chiamato “ConsentFix” amplia le capacità del già noto attacco social ClickFix e consente di dirottare gli account Microsoft senza password o autenticazione a più fattori. Per farlo, gli aggressori sfruttano un’applicazione Azure CLI legittima e le funzionalità di autenticazione OAuth , trasformando il processo di accesso standard in uno strumento di dirottamento.
ClickFix si basa sulla visualizzazione di istruzioni pseudo-sistema all’utente, chiedendogli di eseguire comandi o eseguire diversi passaggi, presumibilmente per correggere un errore o dimostrare la propria identità.
La variante “ConsentFix”, descritta dal team di Push Security, mantiene lo scenario generale dell’inganno, ma invece di installare malware, mira a rubare un codice di autorizzazione OAuth 2.0, che viene poi utilizzato per ottenere un token di accesso all’interfaccia della riga di comando di Azure.

L’attacco inizia con la visita a un sito web legittimo compromesso, ben indicizzato su Google per le query pertinenti. Sulla pagina appare un finto widget Cloudflare Turnstile, che richiede un indirizzo email valido. Lo script degli aggressori confronta l’indirizzo inserito con un elenco predefinito di obiettivi ed esclude bot, analisti e visitatori casuali. Solo alle vittime selezionate viene presentato il passaggio successivo, strutturato come un tipico script ClickFix con passaggi di verifica apparentemente innocui.
Alla vittima viene chiesto di cliccare sul pulsante di accesso, dopodiché il vero dominio Microsoft si apre in una scheda separata. Tuttavia, invece del consueto modulo di accesso, utilizza una pagina di autorizzazione di Azure che genera un codice OAuth specifico per l’interfaccia a riga di comando di Azure. Se l’utente ha effettuato l’accesso a un account Microsoft, è sufficiente selezionarlo; in caso contrario, l’accesso avviene normalmente tramite il modulo autentico.

Dopo l’autorizzazione, il browser viene reindirizzato a localhost e nella barra degli indirizzi viene visualizzato un URL con il codice di autorizzazione dell’interfaccia della riga di comando di Azure associato all’account. Il passaggio finale dell’inganno consiste nell’incollare nuovamente questo indirizzo nella pagina dannosa, come indicato. A questo punto, l’aggressore può scambiare il codice con un token di accesso e gestire l’account tramite l’interfaccia della riga di comando di Azure senza conoscere la password o completare l’autenticazione a più fattori . Durante una sessione attiva, l’accesso non viene effettivamente richiesto. Per ridurre il rischio di divulgazione, lo script viene eseguito una sola volta da ciascun indirizzo IP.
Gli esperti di Push Security consigliano ai team addetti alla sicurezza di monitorare le attività insolite dell’interfaccia della riga di comando di Azure, inclusi gli accessi da indirizzi IP insoliti, e di monitorare l’utilizzo delle autorizzazioni Graph legacy, su cui questo schema si basa per eludere gli strumenti di rilevamento standard.
L'articolo Copia e Incolla e hai perso l’account di Microsoft 365! Arriva ConsentFix e la MFA è a rischio proviene da Red Hot Cyber.
, “accompagnare e fare rete” - AgenSIR")
STATI UNITI. L’ICE perseguita i lavoratori. Datori di lavoro e sindacati reagiscono
@Notizie dall'Italia e dal mondo
Quali sono le tattiche che aziende agricole, fabbriche, ristoranti e altri luoghi di lavoro utilizzano per proteggere i dipendenti immigrati dalle incursioni dell'ICE?
L'articolo STATI UNITI. L’ICE perseguita i lavoratori. Datori di lavoro e

Ministero dell'Istruzione
Ieri, al #MIM, con l’accensione dell’albero di #Natale, alla presenza del Ministro Giuseppe Valditara e del Sottosegretario Paola Frassinetti, si sono conclusi i laboratori di #NextGenArt.Telegram
Aumento di stipendio? Tranquillo, l’unico che riceve i soldi è l’hacker per la tua negligenza
Emerge da un recente studio condotto da Datadog Security Labs un’operazione attualmente in corso, mirata a organizzazioni che utilizzano Microsoft 365 e Okta per l’autenticazione Single Sign-On (SSO). Questa operazione, avvalendosi di tecniche sofisticate, aggira i controlli di sicurezza con l’obiettivo di sottrarre token di sessione.
Mentre le valutazioni delle prestazioni di fine anno stanno per essere comunicate ai dipendenti, questa complessa truffa di phishing ha iniziato a diffondersi, trasformando quello che sembrava un aumento salariale in una minaccia per la sicurezza informatica.
Dall’inizio di dicembre 2025, questa campagna sfrutta senza scrupoli i benefit offerti dalle aziende. I destinatari ignari ricevono messaggi di posta elettronica dissimulati da comunicazioni ufficiali dei reparti risorse umane o di servizi di gestione stipendi, tra cui ADP o Salesforce.

Gli oggetti sono progettati per suscitare urgenza e curiosità immediate, utilizzando frasi come “Azione richiesta: rivedere le informazioni su stipendio e bonus del 2026” o “Riservato: aggiornamento sulla retribuzione”.
Secondo il rapporto , i ricercatori di sicurezza riportano che “gli URL di phishing includono un parametro URL che indica il tenant Okta preso di mira. Inoltra qualsiasi richiesta al dominio .okta.com originale, garantendo che tutte le personalizzazioni alla pagina di autenticazione Okta vengano preservate, rendendo la pagina di phishing più legittima”.
Alcuni attacchi utilizzano allegati PDF crittografati con la password fornita nel corpo dell’e-mail: una tattica classica per aggirare gli scanner di sicurezza della posta elettronica.
La minaccia risulta essere ancora più subdola nel caso in cui la vittima faccia accesso a una pagina di login contraffatta di Microsoft 365. Il codice maligno esamina il traffico del browser in modo occulto. Rilevato che l’utente sta effettuando l’autenticazione tramite Okta, tramite un campo JSON specifico chiamato FederationRedirectUrl, il traffico viene immediatamente intercettato.
Una volta che l’utente inserisce le proprie credenziali, uno script lato client chiamato inject.js entra in funzione. Traccia le sequenze di tasti premuti per acquisire nomi utente e password, ma il suo obiettivo principale è il dirottamento della sessione.
L’infrastruttura alla base di questi attacchi è in rapida evoluzione.
Gli autori delle minacce utilizzano Cloudflare per nascondere i loro siti dannosi ai bot di sicurezza e perfezionano costantemente il loro codice.
L'articolo Aumento di stipendio? Tranquillo, l’unico che riceve i soldi è l’hacker per la tua negligenza proviene da Red Hot Cyber.
, “maturare una sensibilità piena nei nostri ambienti” - AgenSIR")
Non solo Starlink, American Airlines punta ad Amazon Leo per il Wi-Fi a bordo
Per vedere altri post come questo, segui la comunità @Informatica (Italy e non Italy 😁)
Se la rivale Starlink ha già accordi con diverse compagnie aeree per fornire servizi Internet in volo, anche Amazon Leo potrebbe mettere a segno il primo accordo con il vettore American Airlines. Tutti i
CheGuevaraRoma reshared this.
DIY Synth Takes Inspiration From Fretted Instruments

There are a million and one MIDI controllers and synths on the market, but sometimes it’s just more satisfying to make your own. [Turi Scandurra] very much went his own way when he put together his Diapasonix instrument.
Right away, the build is somewhat reminiscent of a stringed instrument, what with its buttons laid out in four “strings” of six “frets” each. Only, they’re not so much buttons, as individual sections of a capacitive touch controller. A Raspberry Pi Pico 2 is responsible for reading the 24 pads, with the aid of two MPR121 capacitive touch ICs.
The Diapasonix can be played as an instrument in its own right, using the AMY synthesis engine. This provides a huge range of patches from the Juno 6 and DX7 synthesizers of old. Onboard effects like delay and reverb can be used to alter the sound. Alternatively, it can be used as a MIDI controller, feeding its data to a PC attached over USB. It can be played in multiple modes, with either direct note triggers or with a “strumming” method instead.
We’ve featured a great many MIDI controllers over the years, from the artistic to the compact. Video after the break.
youtube.com/embed/DMDRZ1dwdG4?…
React Server: Nuovi bug critici portano a DoS e alla divulgazione del codice sorgente
La saga sulla sicurezza dei componenti di React Server continua questa settimana.
Successivamente alla correzione di una vulnerabilità critica relativa all’esecuzione di codice remoto (RCE) che ha portato a React2shell, sono state individuate dai ricercatori due nuove vulnerabilità. Queste ultime, pur essendo meno gravi delle precedenti, comportano rischi significativi, tra cui la possibilità di attacchi Denial of Service (DoS) che possono causare il crash del server e l’esposizione di codice sorgente sensibile.
Le versioni interessate includono la versione da 19.0.0 a 19.0.2, la versione da 19.1.0 a 19.1.2 e la versione da 19.2.0 a 19.2.2. Si consiglia pertanto agli sviluppatori di aggiornare alle versioni corrette appena rilasciate:
- 19.0.3
- 19.1.4
- 19.2.3
Fondamentalmente, queste vulnerabilità hanno un ampio raggio d’azione.
Basta che l’applicazione sia vulnerabile a certe funzioni del server per essere esposta a potenziali rischi, senza doverle necessariamente utilizzare. “Anche se la tua app non implementa alcun endpoint di React Server Function, potrebbe comunque essere vulnerabile se supporta i React Server Components”, avverteono i ricercatori di sicurezza.
Il problema più urgente, ha una severity CVSS di 7.5, e riguarda una vulnerabilità che può mettere in ginocchio un server. Identificata come CVE-2025-55184 e CVE-2025-67779, questa falla consente a un aggressore di innescare un loop infinito sul server inviando una specifica richiesta HTTP dannosa. Secondo l’avviso, il loop consuma la CPU del server, bloccandone di fatto le risorse.
La seconda vulnerabilità, il CVE-2025-55183 ha una severity CVSS 5.3, è un problema di gravità media che colpisce la riservatezza del codice dell’applicazione. E’ stato rilevato che in specifiche circostanze, una richiesta nociva è in grado di convincere una funzione del server a fornire all’attaccante il proprio codice sorgente. Secondo quanto riportato nell’avviso, un esperto di sicurezza ha riscontrato che l’invio di una richiesta HTTP dannosa a una funzione del server suscettibile di vulnerabilità potrebbe comportare la restituzione non sicura del codice sorgente di qualsiasi funzione del server.
Per eseguire l’attacco, è necessario un particolare modello di codifica, nel quale una funzione lato server esplicitamente o implicitamente espone un parametro come stringa. Qualora venisse sfruttata, potrebbe portare alla scoperta di informazioni cruciali a livello logico o di chiavi del database internamente allegate al codice della funzione.
Il team di React ha confermato esplicitamente che questi nuovi bug non riapriranno la porta al controllo totale del server. “Queste nuove vulnerabilità non consentono l’esecuzione di codice remoto. La patch per React2Shell rimane efficace nel mitigare l’exploit di esecuzione di codice remoto”.
Il team esorta a procedere con urgenza all’aggiornamento, dato che le vulnerabilità scoperte di recente sono di notevole gravità.
L'articolo React Server: Nuovi bug critici portano a DoS e alla divulgazione del codice sorgente proviene da Red Hot Cyber.