 - Collegamento all'originale")
NanoRemote: il malware che trasforma il cloud in un centro di comando e controllo
Un nuovo trojan multifunzionale per Windows chiamato NANOREMOTE utilizza un servizio di archiviazione file su cloud come centro di comando, rendendo la minaccia più difficile da rilevare e offrendo agli aggressori un canale persistente per rubare dati e fornire download aggiuntivi.
La minaccia è stata segnalata da Elastic Security Labs, che ha confrontato il malware con il già noto impianto FINALDRAFT, noto anche come Squidoor, che si basa su Microsoft Graph per comunicare con gli operatori.
Entrambi gli strumenti sono associati al cluster REF7707, segnalato come CL-STA-0049, Earth Alux e Jewelbug, e attribuiti ad attività di spionaggio cinese contro agenzie governative, appaltatori della difesa, società di telecomunicazioni, istituti scolastici e organizzazioni aeronautiche nel Sud-est asiatico e in Sud America.
Secondo Symantec, questo gruppo sta conducendo campagne segrete a lungo termine almeno dal 2023, tra cui un’infiltrazione durata cinque mesi in un’azienda IT in Russia. Il metodo esatto dell’infiltrazione iniziale di NANOREMOTE non è ancora stato determinato. La catena di attacco documentata utilizza il downloader WMLOADER, mascherato da componente di gestione degli arresti anomali dell’antivirus Bitdefender “BDReinit.exe“. Questo modulo decrittografa lo shellcode e lancia il payload principale: il trojan stesso.
NANOREMOTE è scritto in C++ e può raccogliere informazioni di sistema, eseguire comandi e file e trasferire dati tra il dispositivo infetto e l’infrastruttura dell’operatore tramite Google Drive . È inoltre configurato per comunicare tramite HTTP con un indirizzo IP hardcoded e non instradabile, attraverso il quale riceve attività e invia risultati. Gli scambi vengono effettuati tramite richieste POST con dati JSON, compressi tramite Zlib e crittografati in modalità AES-CBC con una chiave a 16 byte. Le richieste utilizzano un singolo percorso, “/api/client”, e la stringa di identificazione del client, “NanoRemote/1.0”.
Le principali funzionalità del Trojan sono implementate tramite un set di 22 gestori di comandi. Questi gestori gli consentono di raccogliere e trasmettere informazioni sull’host, gestire file e directory, svuotare la cache, avviare file eseguibili PE già presenti sul disco, terminare la propria operazione e caricare e scaricare file sul cloud, con la possibilità di mettere in coda, mettere in pausa, riprendere o annullare i trasferimenti.
Elastic Security Labs ha anche scoperto l’artefatto “wmsetup.log”, caricato su VirusTotal dalle Filippine il 3 ottobre 2025 e decifrato con successo dal modulo WMLOADER utilizzando la stessa chiave di crittografia.
Conteneva un impianto FINALDRAFT, a indicare uno sviluppo comune. Secondo il ricercatore principale Daniel Stepanic, l’identico loader e l’approccio unificato alla protezione del traffico sono ulteriori indicazioni di una base di codice e di un processo di build unificati per FINALDRAFT e NANOREMOTE, progettati per gestire payload diversi.
L'articolo NanoRemote: il malware che trasforma il cloud in un centro di comando e controllo proviene da Red Hot Cyber.
Following the digital trail: what happens to data stolen in a phishing attack

Introduction
A typical phishing attack involves a user clicking a fraudulent link and entering their credentials on a scam website. However, the attack is far from over at that point. The moment the confidential information falls into the hands of cybercriminals, it immediately transforms into a commodity and enters the shadow market conveyor belt.
In this article, we trace the path of the stolen data, starting from its collection through various tools – such as Telegram bots and advanced administration panels – to the sale of that data and its subsequent reuse in new attacks. We examine how a once leaked username and password become part of a massive digital dossier and why cybercriminals can leverage even old leaks for targeted attacks, sometimes years after the initial data breach.
Data harvesting mechanisms in phishing attacks
Before we trace the subsequent fate of the stolen data, we need to understand exactly how it leaves the phishing page and reaches the cybercriminals.
By analyzing real-world phishing pages, we have identified the most common methods for data transmission:
- Send to an email address.
- Send to a Telegram bot.
- Upload to an administration panel.
It also bears mentioning that attackers may use legitimate services for data harvesting to make their server harder to detect. Examples include online form services like Google Forms, Microsoft Forms, etc. Stolen data repositories can also be set up on GitHub, Discord servers, and other websites. For the purposes of this analysis, however, we will focus on the primary methods of data harvesting.
Data entered into an HTML form on a phishing page is sent to the cybercriminal’s server via a PHP script, which then forwards it to an email address controlled by the attacker. However, this method is becoming less common due to several limitations of email services, such as delivery delays, the risk of the hosting provider blocking the sending server, and the inconvenience of processing large volumes of data.
As an example, let’s look at a phishing kit targeting DHL users.
Phishing kit contents

The index.php file contains the phishing form designed to harvest user data – in this case, an email address and a password.
Phishing form imitating the DHL website

The data that the victim enters into this form is then sent via a script in the next.php file to the email address specified within the mail.php file.
Contents of the PHP scripts

Telegram bots
Unlike the previous method, the script used to send stolen data specifies a Telegram API URL with a bot token and the corresponding Chat ID, rather than an email address. In some cases, the link is hard-coded directly into the phishing HTML form. Attackers create a detailed message template that is sent to the bot after a successful attack. Here is what this looks like in the code:
Code snippet for data submission

Compared to sending data via email, using Telegram bots provides phishers with enhanced functionality, which is why they are increasingly adopting this method. Data arrives in the bot in real time, with instant notification to the operator. Attackers often use disposable bots, which are harder to track and block. Furthermore, their performance does not depend on the quality of phishing page hosting.
Automated administration panels
More sophisticated cybercriminals use specialized software, including commercial frameworks like BulletProofLink and Caffeine, often as a Platform as a Service (PaaS). These frameworks provide a web interface (dashboard) for managing phishing campaigns.
Data harvested from all phishing pages controlled by the attacker is fed into a unified database that can be viewed and managed through their account.
Sending data to the administration panel

These admin panels are used for analyzing and processing victim data. The features of a specific panel depend on the available customization options, but most dashboards typically have the following capabilities:
- Sorting of real-time statistics: the ability to view the number of successful attacks by time and country, along with data filtering options
- Automatic verification: some systems can automatically check the validity of the stolen data like credit cards and login credentials
- Data export: the ability to download the data in various formats for future use or sale
Example of an administration panel

Admin panels are a vital tool for organized cybercriminals.
One campaign often employs several of these data harvesting methods simultaneously.
Sending stolen data to both an email address and a Telegram bot

The data cybercriminals want
The data harvested during a phishing attack varies in value and purpose. In the hands of cybercriminals, it becomes a method of profit and a tool for complex, multi-stage attacks.
Stolen data can be divided into the following categories, based on its intended purpose:
- Immediate monetization: the direct sale of large volumes of raw data or the immediate withdrawal of funds from a victim’s bank account or online wallet.
- Banking details: card number, expiration date, cardholder name, and CVV/CVC.
- Access to online banking accounts and digital wallets: logins, passwords, and one-time 2FA codes.
- Accounts with linked banking details: logins and passwords for accounts that contain bank card details, such as online stores, subscription services, or payment systems like Apple Pay or Google Pay.
- Subsequent attacks for further monetization: using the stolen data to conduct new attacks and generate further profit.
- Credentials for various online accounts: logins and passwords. Importantly, email addresses or phone numbers, which are often used as logins, can hold value for attackers even without the accompanying passwords.
- Phone numbers, used for phone scams, including attempts to obtain 2FA codes, and for phishing via messaging apps.
- Personal data: full name, date of birth, and address, abused in social engineering attacks
- Targeted attacks, blackmail, identity theft, and deepfakes.
- Biometric data: voice and facial projections.
- Scans and numbers of personal documents: passports, driver’s licenses, social security cards, and taxpayer IDs.
- Selfies with documents, used for online loan applications and identity verification.
- Corporate accounts, used for targeted attacks on businesses.
We analyzed phishing and scam attacks conducted from January through September 2025 to determine which data was most frequently targeted by cybercriminals. We found that 88.5% of attacks aimed to steal credentials for various online accounts, 9.5% targeted personal data (name, address, and date of birth), and 2% focused on stealing bank card details.
Distribution of attacks by target data type, January–September 2025 (download)
Selling data on dark web markets
Except for real-time attacks or those aimed at immediate monetization, stolen data is typically not used instantly. Let’s take a closer look at the route it takes.
- Sale of data dumps
Data is consolidated and put up for sale on dark web markets in the form of dumps: archives that contain millions of records obtained from various phishing attacks and data breaches. A dump can be offered for as little as $50. The primary buyers are often not active scammers but rather dark market analysts, the next link in the supply chain. - Sorting and verification
Dark market analysts filter the data by type (email accounts, phone numbers, banking details, etc.) and then run automated scripts to verify it. This checks validity and reuse potential, for example, whether a Facebook login and password can be used to sign in to Steam or Gmail. Data stolen from one service several years ago can still be relevant for another service today because people tend to use identical passwords across multiple websites. Verified accounts with an active login and password command a higher price at the point of sale.
Analysts also focus on combining user data from different attacks. Thus, an old password from a compromised social media site, a login and password from a phishing form mimicking an e-government portal, and a phone number left on a scam site can all be compiled into a single digital dossier on a specific user. - Selling on specialized markets
Stolen data is typically sold on dark web forums and via Telegram. The instant messaging app is often used as a storefront to display prices, buyer reviews, and other details.
Offers of social media data, as displayed in TelegramThe prices of accounts can vary significantly and depend on many factors, such as account age, balance, linked payment methods (bank cards, online wallets), 2FA authentication, and service popularity. Thus, an online store account may be more expensive if it is linked to an email, has 2FA enabled, and has a long history, with a large number of completed orders. For gaming accounts, such as Steam, expensive game purchases are a factor. Online banking data sells at a premium if the victim has a high account balance and the bank itself has a good reputation.
The table below shows prices for various types of accounts found on dark web forums as of 2025*.
Category Price Average price Crypto platforms $60–$400 $105 Banks $70–$2000 $350 E-government portals $15–$2000 $82.5 Social media $0.4–$279 $3 Messaging apps $0.065–$150 $2.5 Online stores $10–$50 $20 Games and gaming platforms $1–$50 $6 Global internet portals $0.2–$2 $0.9 Personal documents $0.5–$125 $15 *Data provided by Kaspersky Digital Footprint Intelligence
- High-value target selection and targeted attacks
Cybercriminals take particular interest in valuable targets. These are users who have access to important information: senior executives, accountants, or IT systems administrators.
Let’s break down a possible scenario for a targeted whaling attack. A breach at Company A exposes data associated with a user who was once employed there but now holds an executive position at Company B. The attackers analyze open-source intelligence (OSINT) to determine the user’s current employer (Company B). Next, they craft a sophisticated phishing email to the target, purportedly from the CEO of Company B. To build trust, the email references some facts from the target’s old job – though other scenarios exist too. By disarming the user’s vigilance, cybercriminals gain the ability to compromise Company B for a further attack.Importantly, these targeted attacks are not limited to the corporate sector. Attackers may also be drawn to an individual with a large bank account balance or someone who possesses important personal documents, such as those required for a microloan application.

Takeaways
The journey of stolen data is like a well-oiled conveyor belt, where every piece of information becomes a commodity with a specific price tag. Today, phishing attacks leverage diverse systems for harvesting and analyzing confidential information. Data flows instantly into Telegram bots and attackers’ administration panels, where it is then sorted, verified, and monetized.
It is crucial to understand that data, once lost, does not simply vanish. It is accumulated, consolidated, and can be used against the victim months or even years later, transforming into a tool for targeted attacks, blackmail, or identity theft. In the modern cyber-environment, caution, the use of unique passwords, multi-factor authentication, and regular monitoring of your digital footprint are no longer just recommendations – they are a necessity.
What to do if you become a victim of phishing
- If a bank card you hold has been compromised, call your bank as soon as possible and have the card blocked.
- If your credentials have been stolen, immediately change the password for the compromised account and any online services where you may have used the same or a similar password. Set a unique password for every account.
- Enable multi-factor authentication in all accounts that support this.
- Check the sign-in history for your accounts and terminate any suspicious sessions.
- If your messaging service or social media account has been compromised, alert your family and friends about potential fraudulent messages sent in your name.
- Use specialized services to check if your data has been found in known data breaches.
- Treat any unexpected emails, calls, or offers with extreme vigilance – they may appear credible because attackers are using your compromised data.
securelist.com/what-happens-to…


OSINT nell'Indagine sull'assalto al Campidoglio degli Stati Uniti
@Privacy Pride
Il post completo di Christian Bernieri è sul suo blog: garantepiracy.it/blog/osint-ca…
Dopo il grande pezzo sugli ecoceronti, Claudia torna a noi per regalarci una nuova perla dedicata all'OSINT. Non è roba da nerd, anzi, è qualcosa che ci appartiene culturalmente e che abbiamo imparato fin dai tempi dell'asilo.

freezonemagazine.com/articoli/…
Quando il talento incontra lo studio e la passione, allora nascono percorsi artistici dall’alto potenziale di sviluppo. Questo è il caso di Sara Gioielli, pianista e diplomata in canto jazz in quel Sancta Sanctorum che è il conservatorio di San Pietro a Majella di Napoli, straordinaria fucina di artisti e compositori fin dalla sua fondazione […]
L'articolo Sara Gioielli – Gioielli neri proviene da
la guerra è per veri duri, non per stracchini... che ormai significa non riconoscere che la guerra, come ogni attività, è tecnologica, e basata sulle competenze. ma loro pensano che basti stuprare un po' di civili per vincere.
qr.ae/pCgtXz
"Lo storico ha avvertito che se il Cremlino considerasse la sua campagna in Ucraina un successo, gli Stati baltici potrebbero essere il prossimo obiettivo. Ha ricordato le lezioni del passato: dopo la Prima Guerra Mondiale, inglesi e francesi non potevano credere che qualcuno volesse un'altra guerra, e quindi sottovalutarono Hitler.
"Abbiamo assistito a una cosa simile negli anni 2000 <...> Nessuno credeva che qualcuno avrebbe voluto un'altra guerra di terra sul territorio europeo. [Sotto Putin], la pura brutalità del metodo di guerra russo potrebbe benissimo essere riapplicata sul territorio europeo", ha concluso Beevor."

Avvento: p. Pasolini, “l’unità non si costruisce eliminando le differenze”, “gli algoritmi creano bolle”, no a “pensiero unico” - AgenSIR
"Ogni volta che l'unità si costruisce eliminando le differenze il risultato non è la comunione, è la morte".M.Michela Nicolais (AgenSIR)
Archeologia cristiana: lettera apostolica Leone XIV. Stasolla (Sapienza), “archeologo non è un custode del passato, ma un interprete del presente”
“La nostra disciplina è fatta di memoria, soprattutto di memoria collettiva, quella che unisce persone di cui ignoriamo le storie individuali e che permette di costruire identità condivise che è molto più della somma delle memorie personali”.
Consider This Pocket Machine For Your iPhone Backups

What if you find yourself as an iPhone owner, desiring a local backup solution — no wireless tech involved, no sending off data to someone else’s server, just an automatic device-to-device file sync? Check out [Giovanni]’s ios-backup-machine project, a small Linux-powered device with an e-ink screen that backs up your iPhone whenever you plug the two together with a USB cable.
The system relies on libimobiledevice, and is written to make simple no-interaction automatic backups work seamlessly. The backup status is displayed on the e-ink screen, and at boot, it shows up owner’s information of your choice, say, a phone number — helpful if the device is ever lost. For preventing data loss, [Giovanni] recommends a small uninterruptible power supply, and the GitHub-described system is married to a PiSugar board, though you could go without or add a different one, for sure. Backups are encrypted through iPhone internal mechanisms, so while it appears you might not be able to dig into one, they are perfectly usable for restoring your device should it get corrupted or should you need to provision a new phone to replace the one you just lost.
Easy to set up, fully open, and straightforward to use — what’s not to like? Just put a few off-the-shelf boards together, print the case, and run the setup instructions, you’ll have a pocket backup machine ready to go. Now, if you’re considering this as a way to decrease your iTunes dependency, you might as well check out this nifty tool that helps you get out the metadata for the music you’ve bought on iTunes.
, “andare oltre lo scivolo, raccontare un’Italia che lavora insieme” - AgenSIR")
Turn me on, turn me off: Zigbee assessment in industrial environments

We all encounter IoT and home automation in some form or another, from smart speakers to automated sensors that control water pumps. These services appear simple and straightforward to us, but many devices and protocols work together under the hood to deliver them.
One of those protocols is Zigbee. Zigbee is a low-power wireless protocol (based on IEEE 802.15.4) used by many smart devices to talk to each other. It’s common in homes, but is also used in industrial environments where hundreds or thousands of sensors may coordinate to support a process.
There are many guides online about performing security assessments of Zigbee. Most focus on the Zigbee you see in home setups. They often skip the Zigbee used at industrial sites, what I call ‘non-public’ or ‘industrial’ Zigbee.
In this blog, I will take you on a journey through Zigbee assessments. I’ll explain the basics of the protocol and map the attack surface likely to be found in deployments. I’ll also walk you through two realistic attack vectors that you might see in facilities, covering the technical details and common problems that show up in assessments. Finally, I will present practical ways to address these problems.
Zigbee introduction
Protocol overview
Zigbee is a wireless communication protocol designed for low-power applications in wireless sensor networks. Based on the IEEE 802.15.4 standard, it was created for short-range and low-power communication. Zigbee supports mesh networking, meaning devices can connect through each other to extend the network range. It operates on the 2.4 GHz frequency band and is widely used in smart homes, industrial automation, energy monitoring, and many other applications.
You may be wondering why there’s a need for Zigbee when Wi-Fi is everywhere? The answer depends on the application. In most home setups, Wi-Fi works well for connecting devices. But imagine you have a battery-powered sensor that isn’t connected to your home’s electricity. If it used Wi-Fi, its battery would drain quickly – maybe in just a few days – because Wi-Fi consumes much more power. In contrast, the Zigbee protocol allows for months or even years of uninterrupted work.
Now imagine an even more extreme case. You need to place sensors in a radiation zone where humans can’t go. You drop the sensors from a helicopter and they need to operate for months without a battery replacement. In this situation, power consumption becomes the top priority. Wi-Fi wouldn’t work, but Zigbee is built exactly for this kind of scenario.
Also, Zigbee has a big advantage if the area is very large, covering thousands of square meters and requiring thousands of sensors: it supports thousands of nodes in a mesh network, while Wi-Fi is usually limited to hundreds at most.
There are lots more ins and outs, but these are the main reasons Zigbee is preferred for large-scale, low-power sensor networks.
Since both Zigbee and IEEE 802.15.4 define wireless communication, many people confuse the two. The difference between them, to put it simply, concerns the layers they support. IEEE 802.15.4 defines the physical (PHY) and media access control (MAC) layers, which basically determine how devices send and receive data over the air. Zigbee (as well as other protocols like Thread, WirelessHART, 6LoWPAN, and MiWi) builds on IEEE 802.15.4 by adding the network and application layers that define how devices form a network and communicate.
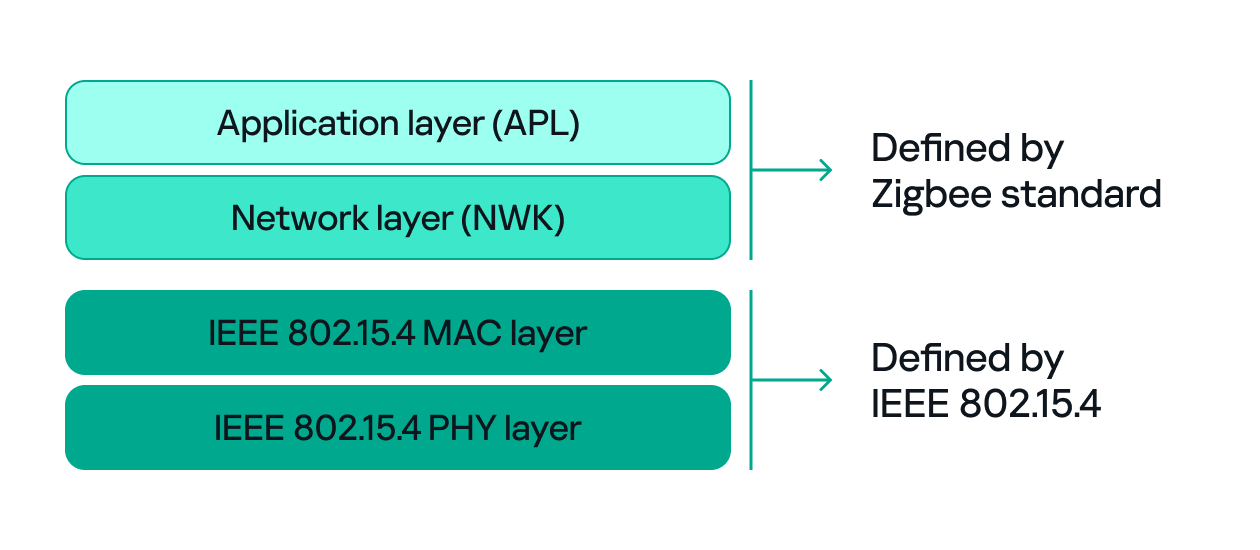
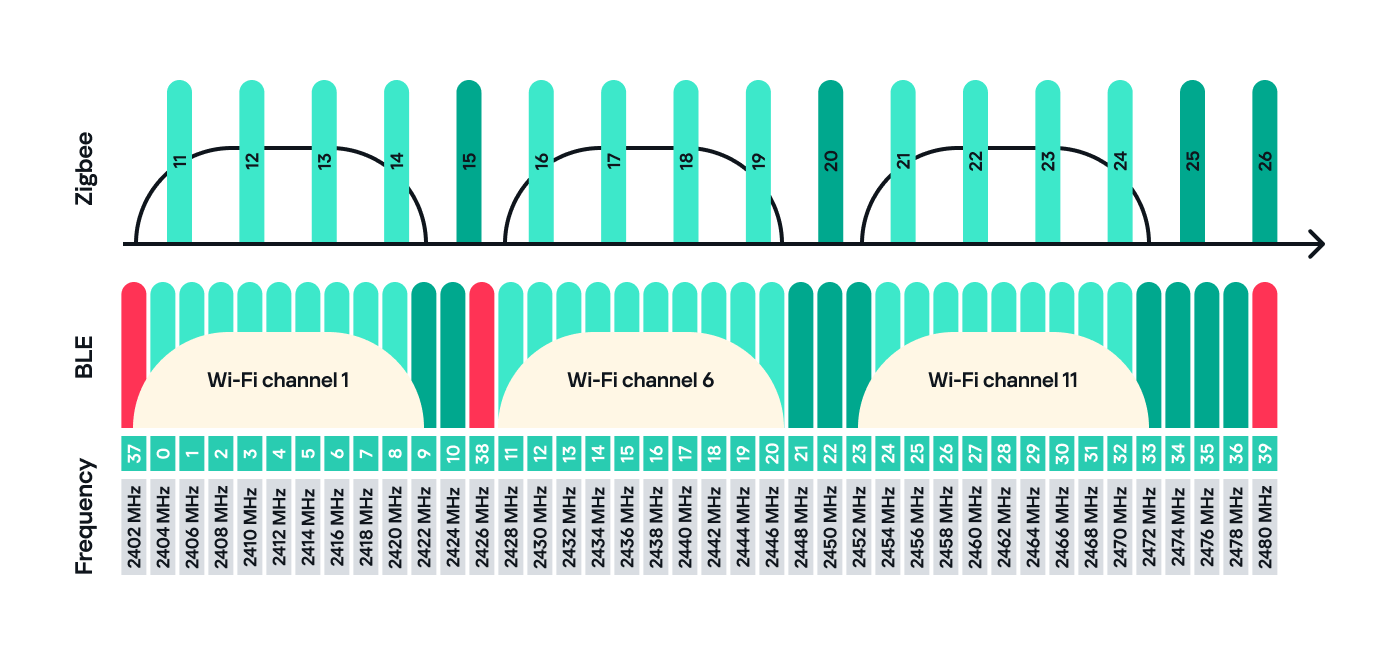
Zigbee operates in the 2.4 GHz wireless band, which it shares with Wi-Fi and Bluetooth. The Zigbee band includes 16 channels, each with a 2 MHz bandwidth and a 5 MHz gap between channels.
This shared frequency means Zigbee networks can sometimes face interference from Wi-Fi or Bluetooth devices. However, Zigbee’s low power and adaptive channel selection help minimize these conflicts.
Devices and network
There are three main types of Zigbee devices, each of which plays a different role in the network.
- Zigbee coordinator
The coordinator is the brain of the Zigbee network. A Zigbee network is always started by a coordinator and can only contain one coordinator, which has the fixed address 0x0000.
It performs several key tasks:- Starts and manages the Zigbee network.
- Chooses the Zigbee channel.
- Assigns addresses to other devices.
- Stores network information.
- Chooses the PAN ID: a 2-byte identifier (for example, 0x1234) that uniquely identifies the network.
- Sets the Extended PAN ID: an 8-byte value, often an ASCII name representing the network.
The coordinator can have child devices, which can be either Zigbee routers or Zigbee end devices.
- Zigbee router
The router works just like a router in a traditional network: it forwards data between devices, extends the network range and can also accept child devices, which are usually Zigbee end devices.
Routers are crucial for building large mesh networks because they enable communication between distant nodes by passing data through multiple hops. - Zigbee end device
The end device, also referred to as a Zigbee endpoint, is the simplest and most power-efficient type of Zigbee device. It only communicates with its parent, either a coordinator or router, and sleeps most of the time to conserve power. Common examples include sensors, remotes, and buttons.
Zigbee end devices do not accept child devices unless they are configured as both a router and an endpoint simultaneously.
Each of these device types, also known as Zigbee nodes, has two types of address:
- Short address: two bytes long, similar to an IP address in a TCP/IP network.
- Extended address: eight bytes long, similar to a MAC address.
Both addresses can be used in the MAC and network layers, unlike in TCP/IP, where the MAC address is used only in Layer 2 and the IP address in Layer 3.
Zigbee setup
Zigbee has many attack surfaces, such as protocol fuzzing and low-level radio attacks. In this post, however, I’ll focus on application-level attacks. Our test setup uses two attack vectors and is intentionally small to make the concepts clear.
In our setup, a Zigbee coordinator is connected to a single device that functions as both a Zigbee endpoint and a router. The coordinator also has other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE), while the endpoint has a relay attached that the coordinator can switch on or off over Zigbee. This relay can be triggered by events coming from any interface, for example, a Bluetooth command or an Ethernet message.
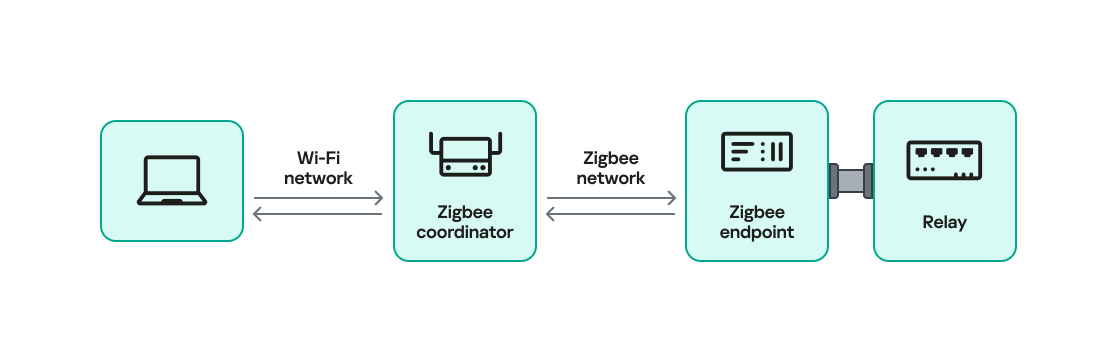
Our goal will be to take control of the relay and toggle its state (turn it off and on) using only the Zigbee interface. Because the other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE) are out of scope, the attack must work by hijacking Zigbee communication.
For the purposes of this research, we will attempt to hijack the communication between the endpoint and the coordinator. The two attack vectors we will test are:
- Spoofed packet injection: sending forged Zigbee commands made to look like they come from the coordinator to trigger the relay.
- Coordinator impersonation (rejoin attack): impersonating the legitimate coordinator to trick the endpoint into joining the attacker-controlled coordinator and controlling it directly.
Spoofed packet injection
In this scenario, we assume the Zigbee network is already up and running and that both the coordinator and endpoint nodes are working normally. The coordinator has additional interfaces, such as Ethernet, and the system uses those interfaces to trigger the relay. For instance, a command comes in over Ethernet and the coordinator sends a Zigbee command to the endpoint to toggle the relay. Our goal is to toggle the relay by injecting simulated legitimate Zigbee packets, using only the Zigbee link.
Sniffing
The first step in any radio assessment is to sniff the wireless traffic so we can learn how the devices talk. For Zigbee, a common and simple tool is the nRF52840 USB dongle by Nordic Semiconductor. With the official nRF Sniffer for 802.15.4 firmware, the dongle can run in promiscuous mode to capture all 802.15.4/Zigbee traffic. Those captures can be opened in Wireshark with the appropriate dissector to inspect the frames.
How do you find the channel that’s in use?
Zigbee runs on one of the 16 channels that we mentioned earlier, so we must set the sniffer to the same channel that the network uses. One practical way to scan the channels is to change the sniffer channel manually in Wireshark and watch for Zigbee traffic. When we see traffic, we know we’ve found the right channel.
After selecting the channel, we will be able to see the communication between the endpoint and the coordinator, though it will most likely be encrypted:
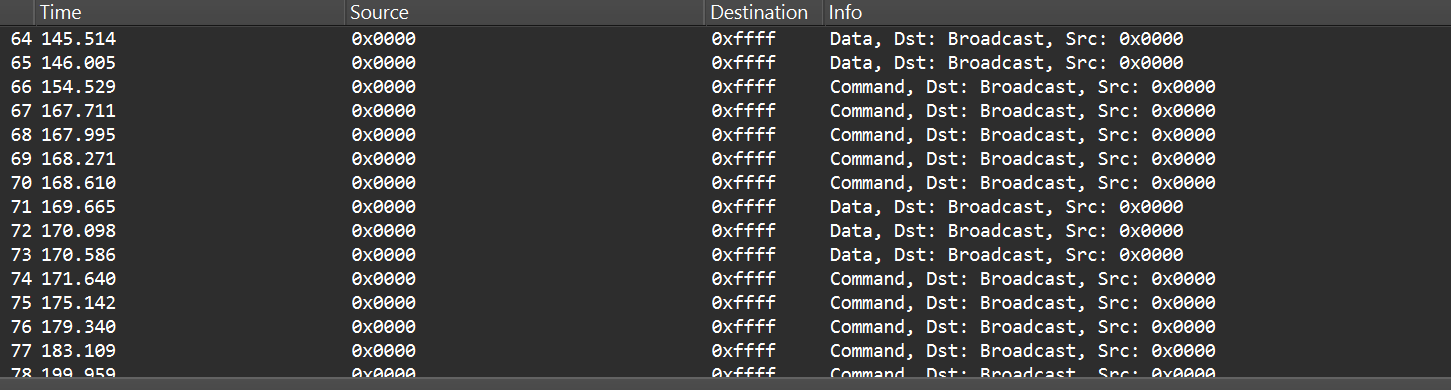
In the “Info” column, we can see that Wireshark only identifies packets as Data or Command without specifying their exact type, and that’s because the traffic is encrypted.
Even when Zigbee payloads are encrypted, the network and MAC headers remain visible. That means we can usually read things like source and destination addresses, PAN ID, short and extended MAC addresses, and frame control fields. The application payload (i.e., the actual command to toggle the relay) is typically encrypted at the Zigbee network/application layer, so we won’t see it in clear text without encryption keys. Nevertheless, we can still learn enough from the headers.
Decryption
Zigbee supports several key types and encryption models. In this post, we’ll keep it simple and look at a case involving only two security-related devices: a Zigbee coordinator and a device that is both an endpoint and a router. That way, we’ll only use a network encryption model, whereas with, say, mesh networks there can be various encryption models in use.
The network encryption model is a common concept. The traffic that we sniffed earlier is typically encrypted using the network key. This key is a symmetric AES-128 key shared by all devices in a Zigbee network. It protects network-layer packets (hop-by-hop) such as routing and broadcast packets. Because every router on the path shares the network key, this encryption method is not considered end-to-end.
Depending on the specific implementation, Zigbee can use two approaches for application payloads:
- Network-layer encryption (hop-by-hop): the network key encrypts the Application Support Sublayer (APS) data, the sublayer of the application layer in Zigbee. In this case, each router along the route can decrypt the APS payload. This is not end-to-end encryption, so it is not recommended for transmitting sensitive data.
- Link key (end-to-end) encryption: a link key, which is also an AES-128 key, is shared between two devices (for example, the coordinator and an endpoint).
The link key provides end-to-end protection of the APS payload between the two devices.
Because the network key could allow an attacker to read and forge many types of network traffic, it must be random and protected. Exposing the key effectively compromises the entire network.
When a new device joins, the coordinator (Trust Center) delivers the network key using a Transport Key command. That transport packet must be protected by a link key so the network key is not exposed in clear text. The link key authenticates the joining device and protects the key delivery.
The image below shows the transport packet:

There are two common ways link keys are provided:
- Pre-installed: the device ships with an installation code or link key already set.
- Key establishment: the device runs a key-establishment protocol.
A common historical problem is the global default Trust Center link key, “ZigBeeAlliance09”. It was included in early versions of Zigbee (pre-3.0) to facilitate testing and interoperability. However, many vendors left it enabled on consumer devices, and that has caused major security issues. If an attacker knows this key, they can join devices and read or steal the network key.
Newer versions – Zigbee 3.0 and later – introduced installation codes and procedures to derive unique link keys for each device. An installation code is usually a factory-assigned secret (often encoded on the device label) that the Trust Center uses to derive a unique link key for the device in question. This helps avoid the problems caused by a single hard-coded global key.
Unfortunately, many manufacturers still ignore these best practices. During real assessments, we often encounter devices that use default or hard-coded keys.
How can these keys be obtained?
If an endpoint has already joined the network and communicates with the coordinator using the network key, there are two main options for decrypting traffic:
- Guess or brute-force the network key. This is usually impractical because a properly generated network key is a random AES-128 key.
- Force the device to rejoin and capture the transport key. If we can make the endpoint leave the network and then rejoin, the coordinator will send the transport key. Capturing that packet can reveal the network key, but the transport key itself is protected by the link key. Therefore, we still need the link key.
To obtain the network and link keys, many approaches can be used:
- The well-known default link key, ZigBeeAlliance09. Many legacy devices still use it.
- Identify the device manufacturer and search for the default keys used by that vendor. We can find the manufacturer by:
- Checking the device MAC/OUI (the first three bytes of the 64-bit extended address often map to a vendor).
- Physically inspecting the device (label, model, chip markings).
- Extract the firmware from the coordinator or device if we have physical access and search for hard-coded keys inside the firmware images.
Once we have the relevant keys, the decryption process is straightforward:
- Open the capture in Wireshark.
- Go to Edit -> Preferences -> Protocols -> Zigbee.
- Add the network key and any link keys in our possession.
- Wireshark will then show decrypted APS payloads and higher-level Zigbee packets.
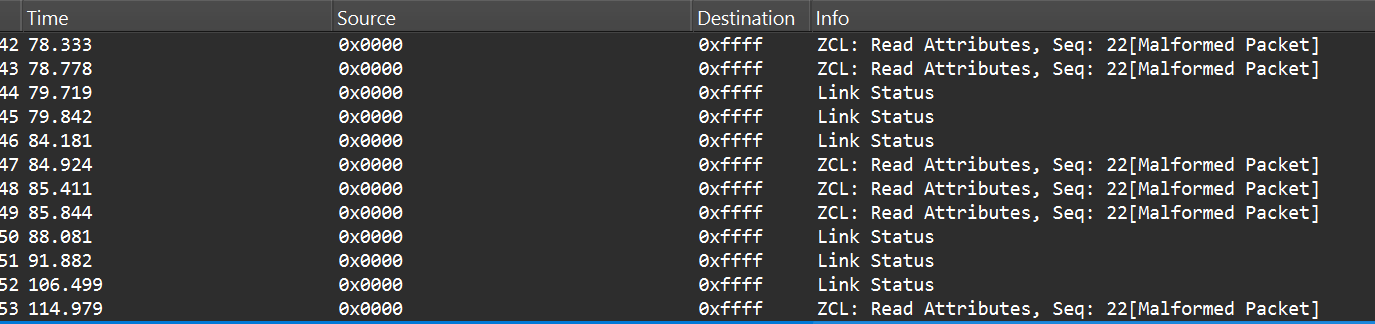
After successful decryption, packet types and readable application commands will be visible, such as Link Status or on/off cluster commands:
Choose your gadget
Now that we can read and potentially decrypt traffic, we need hardware and software to inject packets over the Zigbee link between the coordinator and the endpoint. To keep this practical and simple, I opted for cheap, widely available tools that are easy to set up.
For the hardware, I used the nRF52840 USB dongle, the same device we used for sniffing. It’s inexpensive, easy to find, and supports IEEE 802.15.4/Zigbee, so it can sniff and transmit.
The dongle runs the firmware we can use. A good firmware platform is Zephyr RTOS. Zephyr has an IEEE 802.15.4 radio API that enables the device to receive raw frames, essentially enabling sniffer mode, as well as send raw frames as seen in the snippets below.
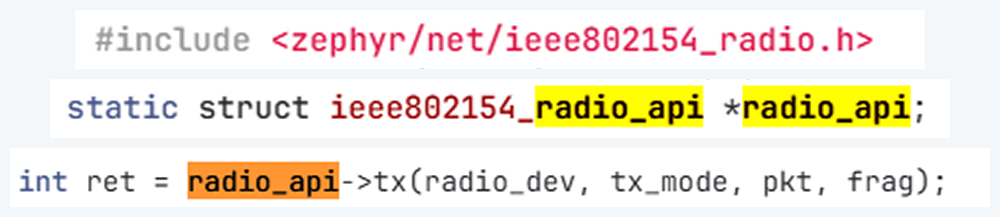
Using this API and other components, we created a transceiver implementation written in C, compiled it to firmware, and flashed it to the dongle. The firmware can expose a simple runtime interface, such as a USB serial port, which allows us to control the radio from a laptop.
At runtime, the dongle listens on the serial port (for example, /dev/ttyACM1). Using a script, we can send it raw bytes, which the firmware will pass to the radio API and transmit to the channel. The following is an example of a tiny Python script to open the serial port:
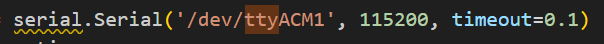
I used the Scapy tool with the 802.15.4/Zigbee extensions to build Zigbee packets. Scapy lets us assemble packets layer-by-layer – MAC → NWK → APS → ZCL – and then convert them to raw bytes to send to the dongle. We will talk about APS and ZCL in more detail later.
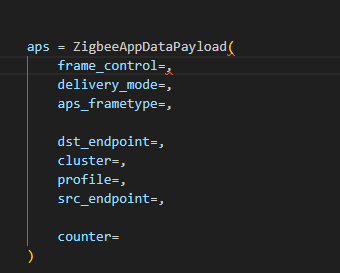
Here is an example of how we can use Scapy to craft an APS layer packet:
from scapy.layers.dot15d4 import Dot15d4, Dot15d4FCS, Dot15d4Data, Dot15d4Cmd, Dot15d4Beacon, Dot15d4CmdAssocResp
from scapy.layers.zigbee import ZigbeeNWK, ZigbeeAppDataPayload, ZigbeeSecurityHeader, ZigBeeBeacon, ZigbeeAppCommandPayload
Before sending, the packet must be properly encrypted and signed so the endpoint accepts it. That means applying AES-CCM (AES-128 with MIC) using the network key (or the correct link key) and adhering to Zigbee’s rules for packet encryption and MIC calculation. This is how we implemented the encryption and MIC in Python (using a cryptographic library) after building the Scapy packet. We then sent the final bytes to the dongle.
This is how we implemented the encryption and MIC:
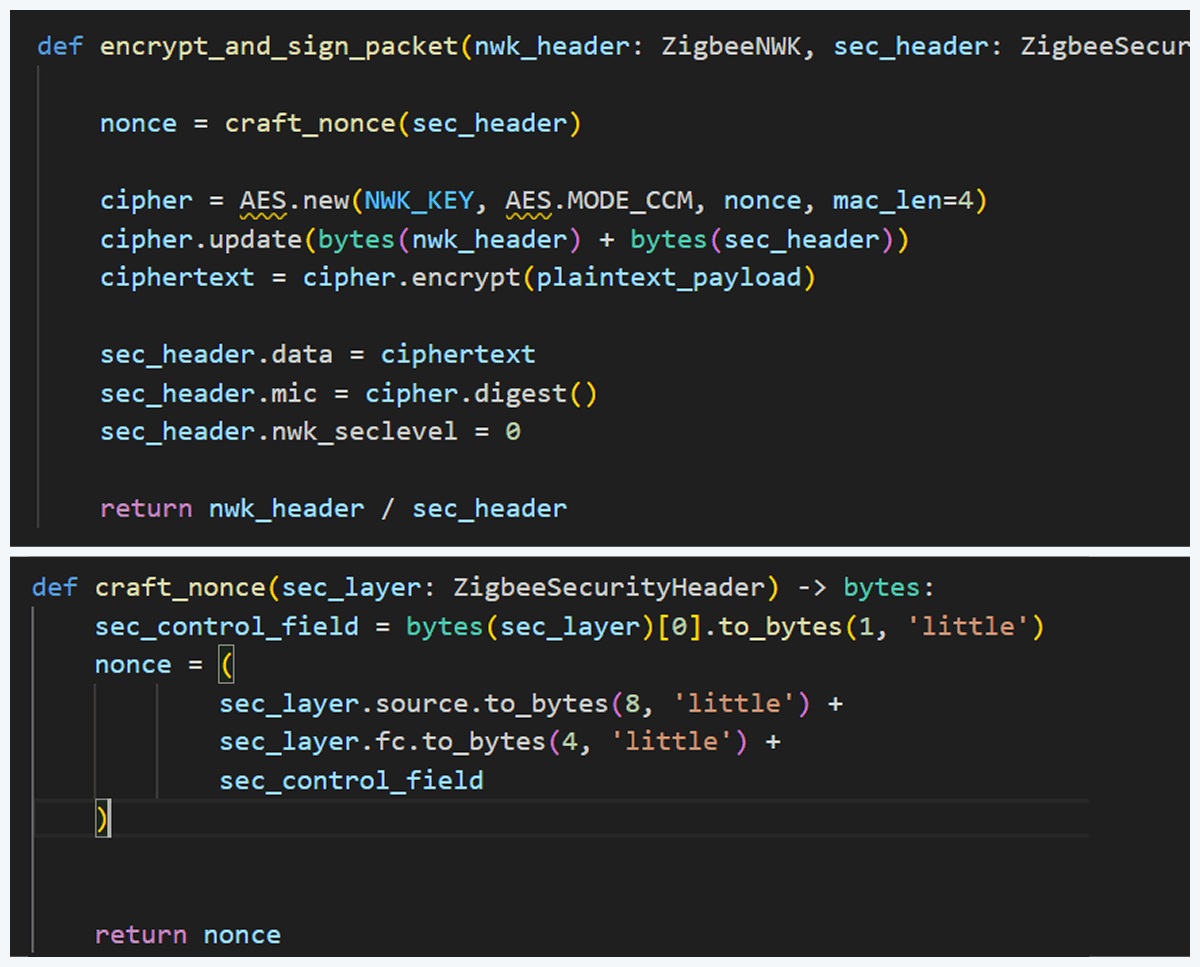
Crafting the packet
Now that we know how to inject packets, the next question is what to inject. To toggle the relay, we simply need to send the same type of command that the coordinator already sends. The easiest way to find that command is to sniff the traffic and read the application payload. However, when we look at captures in Wireshark, we can see many packets under ZCL marked [Malformed Packet].
A “malformed” ZCL packet usually means Wireshark could not fully interpret the packet because the application layer is non-standard or lacks details Wireshark expects. To understand why this happens, let’s look at the Zigbee application layer.
The Zigbee application layer consists of four parts:
- Application Support Sublayer (APS): routes messages to the correct profile, endpoint, and cluster, and provides application-level security.
- Application Framework (AF): contains the application objects that implement device functionality. These objects reside on endpoints (logical addresses 1–240) and expose clusters (sets of attributes and commands).
- Zigbee Cluster Library (ZCL): defines standard clusters and commands so devices can interoperate.
- Zigbee Device Object (ZDO): handles device discovery and management (out of scope for this post).
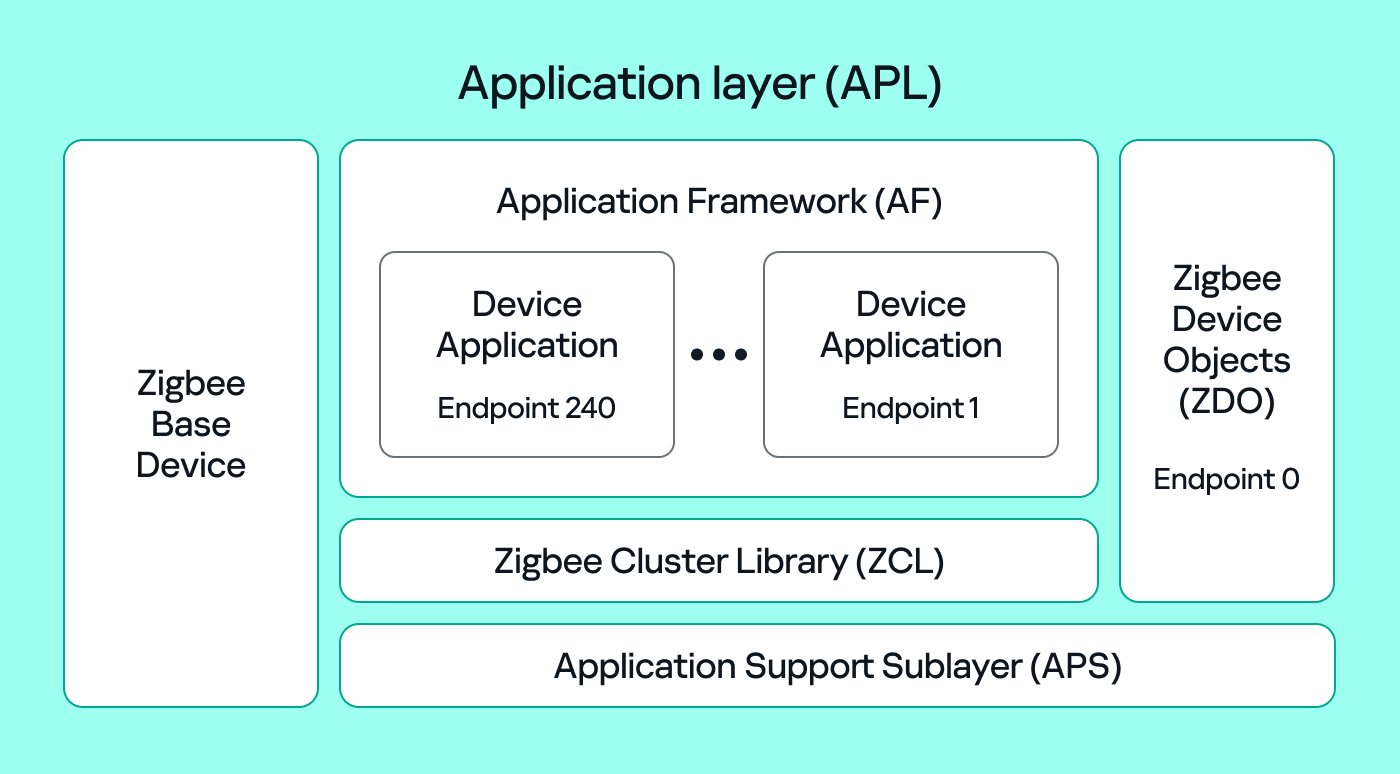
To make sense of application traffic, we must introduce three concepts:
- Profile: a rulebook for how devices should behave for a specific use case. Public (standard) profiles are managed by the Connectivity Standards Alliance (CSA). Vendors can also create private profiles for proprietary features.
- Cluster: a set of attributes and commands for a particular function. For example, the On/Off cluster contains On and Off commands and an OnOff attribute that displays the current state.
- Endpoint: a logical “port” on the device where a profile and clusters reside. A device can host multiple endpoints for different functions.
Putting all this together, in the standard home automation traffic we see APS pointing to the home automation profile, the On/Off cluster, and a destination endpoint (for example, endpoint 1). In ZCL, the byte 0x00 often means “Off”.
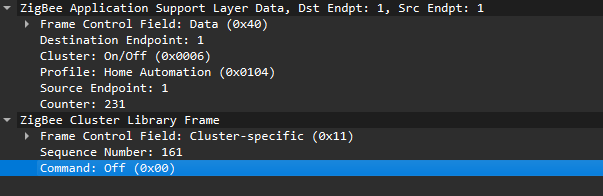
In many industrial setups, vendors use private profiles or custom application frameworks. That’s why Wireshark can’t decode the packets; the AF payload is custom, so the dissector doesn’t know the format.
So how do we find the right bytes to toggle the switch when the application is private? Our strategy has two phases.
- Passive phase
Sniff traffic while the system is driven legitimately. For example, trigger the relay from another interface (Ethernet or Bluetooth) and capture the Zigbee packets used to toggle the relay. If we can decrypt the captures, we can extract the application payload that correlates with the on/off action. - Active phaseWith the legitimate payload at hand, we can now turn to creating our own packet. There are two ways to do that. First, we need to replay or duplicate the captured application payload exactly as it is. This works if there are no freshness checks like sequence numbers. Otherwise, we have to reverse-engineer the payload and adjust any counters or fields that prevent replay. For instance, many applications include an application-level counter. If the device ignores packets with a lower application counter, we must locate and increment that counter when we craft our packet.

Another important protective measure is the frame counter inside the Zigbee security header (in the network header security fields). The frame counter prevents replay attacks; the receiver expects the frame counter to increase with each new packet, and will reject packets with a lower or repeated counter.
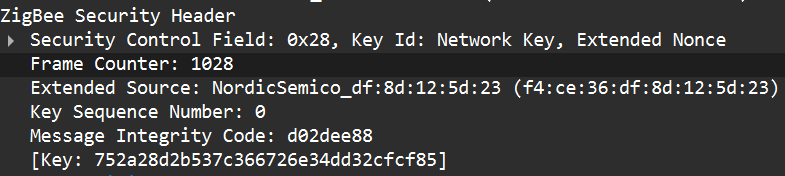
So, in the active phase, we must:
- Sniff the traffic until the coordinator sends a valid packet to the endpoint.
- Decrypt the packet, extract the counters and increase them by one.
- Build a packet with the correct APS/AF fields (profile, endpoint, cluster).
- Include a valid ZCL command or the vendor-specific payload that we identified in the passive phase.
- Encrypt and sign the packet with the correct network or link key.
- Make sure both the application counter (if used) and the Zigbee frame counter are modified so the packet is accepted.
The whole strategy for this phase will look like this:
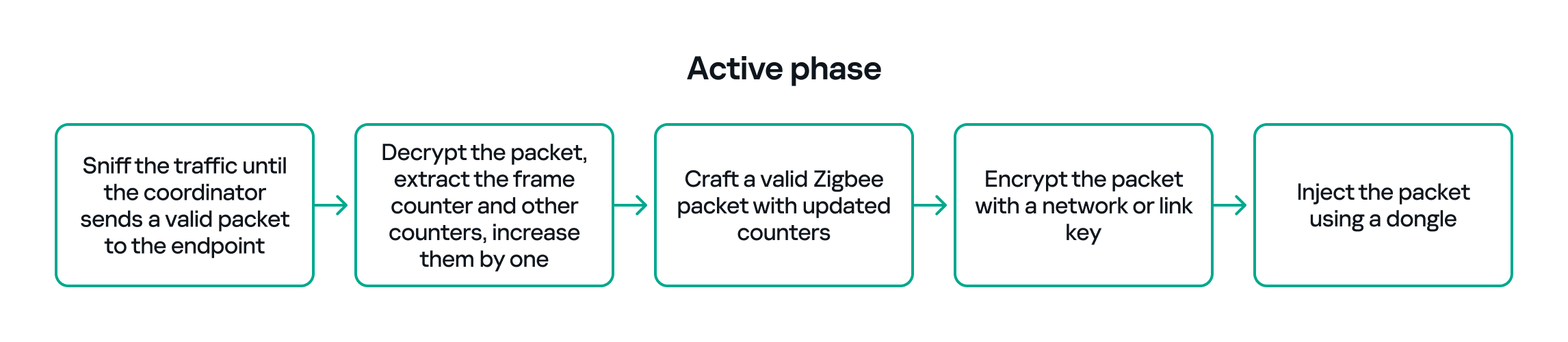
If all of the above are handled correctly, we will be able to hijack the Zigbee communication and toggle the relay (turn it off and on) using only the Zigbee link.
Coordinator impersonation (rejoin attack)
The goal of this attack vector is to force the Zigbee endpoint to leave its original coordinator’s network and join our spoofed network so that we can take control of the device. To do this, we must achieve two things:
- Force the endpoint to leave the original network.
- Spoof the original coordinator and trick the node into joining our fake coordinator.
Force leaving
To better understand how to manipulate endpoint connections, let’s first describe the concept of a beacon frame. Beacon frames are periodic announcements sent by a coordinator and by routers. They advertise the presence of a network and provide join information, such as:
- PAN ID and Extended PAN ID
- Coordinator address
- Stack/profile information
- Device capacity (for example, whether the coordinator can accept child devices)
When a device wants to join, it sends a beacon request across Zigbee channels and waits for beacon replies from nearby coordinators/routers. Even if the network is not beacon-enabled for regular synchronization, beacon frames are still used during the join/discovery process, so they are mandatory when a node tries to discover networks.
Note that beacon frames exist at both the Zigbee and IEEE 802.15.4 levels. The MAC layer carries the basic beacon structure that Zigbee then extends with network-specific fields.

Now, we can force the endpoint to leave its network by abusing how Zigbee handles PAN conflicts. If a coordinator sees beacons from another coordinator using the same PAN ID and the same channel, it may trigger a PAN ID conflict resolution. When that happens, the coordinator can instruct its nodes to change PAN ID and rejoin, which causes them to leave and then attempt to join again. That rejoin window gives us an opportunity to advertise a spoofed coordinator and capture the joining node.
In the capture shown below, packet 7 is a beacon generated by our spoofed coordinator using the same PAN ID as the real network. As a result, the endpoint with the address 0xe8fa leaves the network (see packets 14–16).

Choose me
After forcing the endpoint to leave its original network by sending a fake beacon, the next step is to make the endpoint choose our spoofed coordinator. At this point, we assume we already have the necessary keys (network and link keys) and understand how the application behaves.
To impersonate the original coordinator, our spoofed coordinator must reply to any beacon request the endpoint sends. The beacon response must include the same Extended PAN ID (and other fields) that the endpoint expects. If the endpoint deems our beacon acceptable, it may attempt to join us.
I can think of two ways to make the endpoint prefer our coordinator.
- Jam the real coordinator
Use a device that reduces the real coordinator’s signal at the endpoint so that it appears weaker, forcing the endpoint to prefer our beacon. This requires extra hardware. - Exploit undefined or vendor-specific behavior
Zigbee stacks sometimes behave slightly differently across vendors. One useful field in a beacon is the Update ID field. It increments when a coordinator changes network configuration.
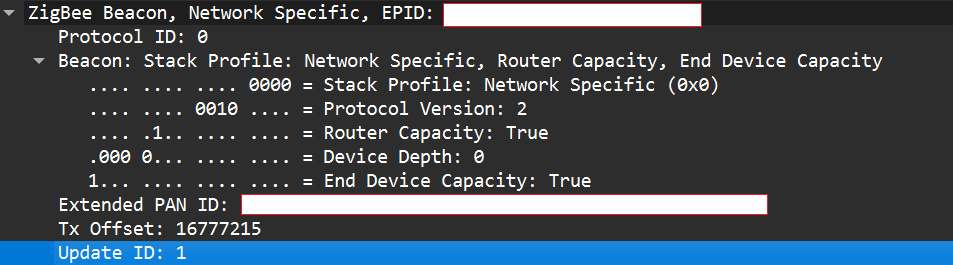
If two coordinators advertise the same Extended PAN ID but one has a higher Update ID, some stacks will prefer the beacon with the higher Update ID. This is undefined behavior across implementations; it works on some stacks but not on others. In my experience, sometimes it works and sometimes it fails. There are lots of other similar quirks we can try during an assessment.
Even if the endpoint chooses our fake coordinator, the connection may be unstable. One main reason for that is the timing. The endpoint expects ACKs for the frames it sends to the coordinator, as well as fast responses regarding connection initiation packets. If our responder is implemented in Python on a laptop that receives packets, builds responses, and forwards them to a dongle, the round trip will be too slow. The endpoint will not receive timely ACKs or packets and will drop the connection.
In short, we’re not just faking a few packets; we’re trying to reimplement parts of Zigbee and IEEE 802.15.4 that must run quickly and reliably. This is usually too slow for production stacks when done in high-level, interpreted code.
A practical fix is to run a real Zigbee coordinator stack directly on the dongle. For example, the nRF52840 dongle can act as a coordinator if flashed with the right Nordic SDK firmware (see Nordic’s network coordinator sample). That provides the correct timing and ACK behavior needed for a stable connection.
However, that simple solution has one significant disadvantage. In industrial deployments we often run into incompatibilities. In my tests I compared beacons from the real coordinator and the Nordic coordinator firmware. Notable differences were visible in stack profile headers:
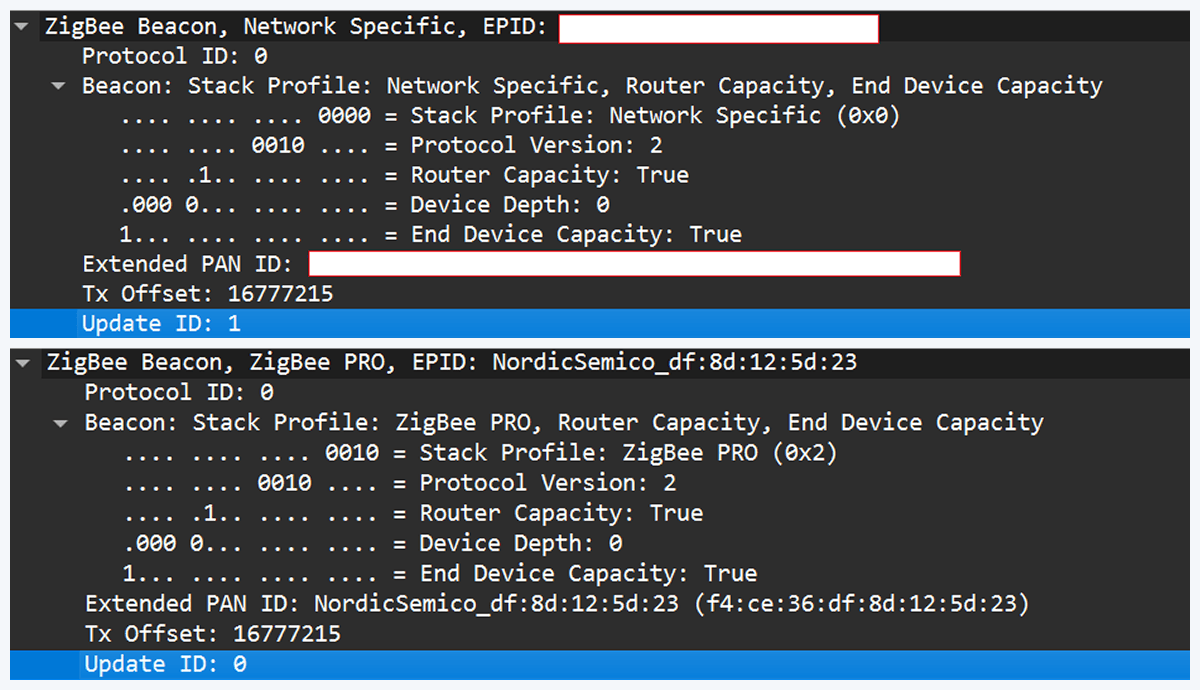
The stack profile identifies the network profile type. Common values include 0x00, which is a network-specific (private) profile, and 0x02, which is a Zigbee Pro (public) profile.
If the endpoint expects a network-specific profile (i.e., it uses a private vendor profile) and we provide Zigbee Pro, the endpoint will refuse to join. Devices that only understand private profiles will not join public-profile networks, and vice versa. In my case, I could not change the Nordic firmware to match the proprietary stack profile, so the endpoint refused to join.
Because of this discrepancy, the “flash a coordinator firmware on the dongle” fix was ineffective in that environment. This is why the standard off-the-shelf tools and firmware often fail in industrial cases, forcing us to continue working with and optimizing our custom setup instead.
Back to the roots
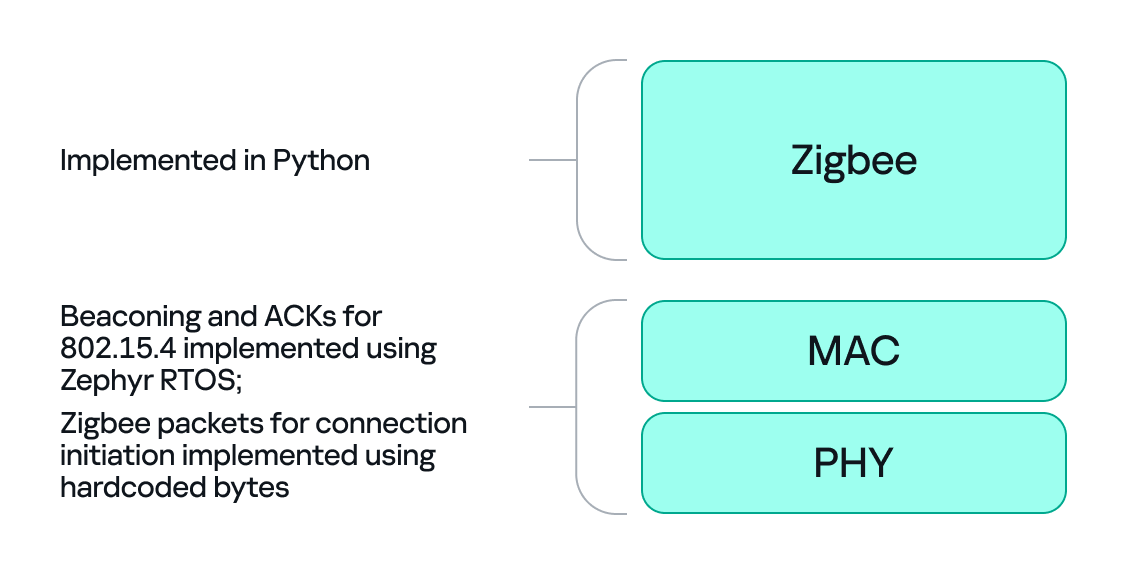
In our previous test setup we used a sniffer in promiscuous mode, which receives every frame on the air regardless of destination. Real Zigbee (IEEE 802.15.4) nodes do not work like that. At the MAC/802.15.4 layer, a node filters frames by PAN ID and destination address. A frame is only passed to upper layers if the PAN ID matches and the destination address is the node’s address or a broadcast address.
We can mimic that real behavior on the dongle by running Zephyr RTOS and making the dongle act as a basic 802.15.4 coordinator. In that role, we set a PAN ID and short network address on the dongle so that the radio only accepts frames that match those criteria. This is important because it allows the dongle to handle auto-ACKs and MAC-level timing: the dongle will immediately send ACKs at the MAC level.
With the dongle doing MAC-level work (sending ACKs and PAN filtering), we can implement the Zigbee logic in Python. Scapy helps a lot with packet construction: we can create our own beacons with the headers matching those of the original coordinator, which solves the incompatibility problem. However, we must still implement the higher-level Zigbee state machine in our code, including connection initiation, association, network key handling, APS/AF behavior, and application payload handling. That’s the hardest part.
There is one timing problem that we cannot solve in Python: the very first steps of initiating a connection require immediate packet responses. To handle this issue, we implemented the time-critical parts in C on the dongle firmware. For example, we can statically generate the packets for connection initiation in Python and hard-code them in the firmware. Then, using “if” statements, we can determine how to respond to each packet from the endpoint.
So, we let the dongle (C/Zephyr) handle MAC-level ACKs and the initial association handshake, but let Python build higher-level packets and instruct the dongle what to send next when dealing with the application level. This hybrid model reduces latency and maintains a stable connection. The final architecture looks like this:
Deliver the key
Here’s a quick recap of how joining works: a Zigbee endpoint broadcasts beacon requests across channels, waits for beacon responses, chooses a coordinator, and sends an association request, followed by a data request to identify its short address. The coordinator then sends a transport key packet containing the network key. If the endpoint has the correct link key, it can decrypt the transport key packet and obtain the network key, meaning it has now been authenticated. From that point on, network traffic is encrypted with the network key. The entire process looks like this:

The sticking point is the transport key packet. This packet is protected using the link key, a per-device key shared between the coordinator (Trust Center) and the joining endpoint. Before the link key can be used for encryption, it often needs to be processed (hashed/derived) according to Zigbee’s key derivation rules. Since there is no trivial Python implementation that implements this hashing algorithm, we may need to implement the algorithm ourselves.
I implemented the required key derivation; the code is available on our GitHub.
Now that we’ve managed to obtain the hashed link key and deliver it to the endpoint, we can successfully mimic a coordinator.
The final success
If we follow the steps above, we can get the endpoint to join our spoofed coordinator. Once the endpoint joins, it will often remain associated with our coordinator, even after we power it down (until another event causes it to re-evaluate its connection). From that point on, we can interact with the device at the application layer using Python. Getting access as a coordinator allowed us to switch the relay on and off as intended, but also provided much more functionality and control over the node.
Conclusion
In conclusion, this study demonstrates why private vendor profiles in industrial environments complicate assessments: common tools and frameworks often fail, necessitating the development of custom tools and firmware. We tested a simple two-node scenario, but with multiple nodes the attack surface changes drastically and new attack vectors emerge (for example, attacks against routing protocols).
As we saw, a misconfigured Zigbee setup can lead to a complete network compromise. To improve Zigbee security, use the latest specification’s security features, such as using installation codes to derive unique link keys for each device. Also, avoid using hard-coded or default keys. Finally, it is not recommended to use the network key encryption model. Add another layer of security in addition to the network level protection by using end-to-end encryption at the application level.
Copia e Incolla e hai perso l’account di Microsoft 365! Arriva ConsentFix e la MFA è a rischio
Un nuovo schema chiamato “ConsentFix” amplia le capacità del già noto attacco social ClickFix e consente di dirottare gli account Microsoft senza password o autenticazione a più fattori. Per farlo, gli aggressori sfruttano un’applicazione Azure CLI legittima e le funzionalità di autenticazione OAuth , trasformando il processo di accesso standard in uno strumento di dirottamento.
ClickFix si basa sulla visualizzazione di istruzioni pseudo-sistema all’utente, chiedendogli di eseguire comandi o eseguire diversi passaggi, presumibilmente per correggere un errore o dimostrare la propria identità.
La variante “ConsentFix”, descritta dal team di Push Security, mantiene lo scenario generale dell’inganno, ma invece di installare malware, mira a rubare un codice di autorizzazione OAuth 2.0, che viene poi utilizzato per ottenere un token di accesso all’interfaccia della riga di comando di Azure.

L’attacco inizia con la visita a un sito web legittimo compromesso, ben indicizzato su Google per le query pertinenti. Sulla pagina appare un finto widget Cloudflare Turnstile, che richiede un indirizzo email valido. Lo script degli aggressori confronta l’indirizzo inserito con un elenco predefinito di obiettivi ed esclude bot, analisti e visitatori casuali. Solo alle vittime selezionate viene presentato il passaggio successivo, strutturato come un tipico script ClickFix con passaggi di verifica apparentemente innocui.
Alla vittima viene chiesto di cliccare sul pulsante di accesso, dopodiché il vero dominio Microsoft si apre in una scheda separata. Tuttavia, invece del consueto modulo di accesso, utilizza una pagina di autorizzazione di Azure che genera un codice OAuth specifico per l’interfaccia a riga di comando di Azure. Se l’utente ha effettuato l’accesso a un account Microsoft, è sufficiente selezionarlo; in caso contrario, l’accesso avviene normalmente tramite il modulo autentico.

Dopo l’autorizzazione, il browser viene reindirizzato a localhost e nella barra degli indirizzi viene visualizzato un URL con il codice di autorizzazione dell’interfaccia della riga di comando di Azure associato all’account. Il passaggio finale dell’inganno consiste nell’incollare nuovamente questo indirizzo nella pagina dannosa, come indicato. A questo punto, l’aggressore può scambiare il codice con un token di accesso e gestire l’account tramite l’interfaccia della riga di comando di Azure senza conoscere la password o completare l’autenticazione a più fattori . Durante una sessione attiva, l’accesso non viene effettivamente richiesto. Per ridurre il rischio di divulgazione, lo script viene eseguito una sola volta da ciascun indirizzo IP.
Gli esperti di Push Security consigliano ai team addetti alla sicurezza di monitorare le attività insolite dell’interfaccia della riga di comando di Azure, inclusi gli accessi da indirizzi IP insoliti, e di monitorare l’utilizzo delle autorizzazioni Graph legacy, su cui questo schema si basa per eludere gli strumenti di rilevamento standard.
L'articolo Copia e Incolla e hai perso l’account di Microsoft 365! Arriva ConsentFix e la MFA è a rischio proviene da Red Hot Cyber.
, “accompagnare e fare rete” - AgenSIR")
STATI UNITI. L’ICE perseguita i lavoratori. Datori di lavoro e sindacati reagiscono
@Notizie dall'Italia e dal mondo
Quali sono le tattiche che aziende agricole, fabbriche, ristoranti e altri luoghi di lavoro utilizzano per proteggere i dipendenti immigrati dalle incursioni dell'ICE?
L'articolo STATI UNITI. L’ICE perseguita i lavoratori. Datori di lavoro e

Ministero dell'Istruzione
Ieri, al #MIM, con l’accensione dell’albero di #Natale, alla presenza del Ministro Giuseppe Valditara e del Sottosegretario Paola Frassinetti, si sono conclusi i laboratori di #NextGenArt.Telegram
Aumento di stipendio? Tranquillo, l’unico che riceve i soldi è l’hacker per la tua negligenza
Emerge da un recente studio condotto da Datadog Security Labs un’operazione attualmente in corso, mirata a organizzazioni che utilizzano Microsoft 365 e Okta per l’autenticazione Single Sign-On (SSO). Questa operazione, avvalendosi di tecniche sofisticate, aggira i controlli di sicurezza con l’obiettivo di sottrarre token di sessione.
Mentre le valutazioni delle prestazioni di fine anno stanno per essere comunicate ai dipendenti, questa complessa truffa di phishing ha iniziato a diffondersi, trasformando quello che sembrava un aumento salariale in una minaccia per la sicurezza informatica.
Dall’inizio di dicembre 2025, questa campagna sfrutta senza scrupoli i benefit offerti dalle aziende. I destinatari ignari ricevono messaggi di posta elettronica dissimulati da comunicazioni ufficiali dei reparti risorse umane o di servizi di gestione stipendi, tra cui ADP o Salesforce.

Gli oggetti sono progettati per suscitare urgenza e curiosità immediate, utilizzando frasi come “Azione richiesta: rivedere le informazioni su stipendio e bonus del 2026” o “Riservato: aggiornamento sulla retribuzione”.
Secondo il rapporto , i ricercatori di sicurezza riportano che “gli URL di phishing includono un parametro URL che indica il tenant Okta preso di mira. Inoltra qualsiasi richiesta al dominio .okta.com originale, garantendo che tutte le personalizzazioni alla pagina di autenticazione Okta vengano preservate, rendendo la pagina di phishing più legittima”.
Alcuni attacchi utilizzano allegati PDF crittografati con la password fornita nel corpo dell’e-mail: una tattica classica per aggirare gli scanner di sicurezza della posta elettronica.
La minaccia risulta essere ancora più subdola nel caso in cui la vittima faccia accesso a una pagina di login contraffatta di Microsoft 365. Il codice maligno esamina il traffico del browser in modo occulto. Rilevato che l’utente sta effettuando l’autenticazione tramite Okta, tramite un campo JSON specifico chiamato FederationRedirectUrl, il traffico viene immediatamente intercettato.
Una volta che l’utente inserisce le proprie credenziali, uno script lato client chiamato inject.js entra in funzione. Traccia le sequenze di tasti premuti per acquisire nomi utente e password, ma il suo obiettivo principale è il dirottamento della sessione.
L’infrastruttura alla base di questi attacchi è in rapida evoluzione.
Gli autori delle minacce utilizzano Cloudflare per nascondere i loro siti dannosi ai bot di sicurezza e perfezionano costantemente il loro codice.
L'articolo Aumento di stipendio? Tranquillo, l’unico che riceve i soldi è l’hacker per la tua negligenza proviene da Red Hot Cyber.
, “maturare una sensibilità piena nei nostri ambienti” - AgenSIR")
Non solo Starlink, American Airlines punta ad Amazon Leo per il Wi-Fi a bordo
Per vedere altri post come questo, segui la comunità @Informatica (Italy e non Italy 😁)
Se la rivale Starlink ha già accordi con diverse compagnie aeree per fornire servizi Internet in volo, anche Amazon Leo potrebbe mettere a segno il primo accordo con il vettore American Airlines. Tutti i
CheGuevaraRoma reshared this.
DIY Synth Takes Inspiration From Fretted Instruments

There are a million and one MIDI controllers and synths on the market, but sometimes it’s just more satisfying to make your own. [Turi Scandurra] very much went his own way when he put together his Diapasonix instrument.
Right away, the build is somewhat reminiscent of a stringed instrument, what with its buttons laid out in four “strings” of six “frets” each. Only, they’re not so much buttons, as individual sections of a capacitive touch controller. A Raspberry Pi Pico 2 is responsible for reading the 24 pads, with the aid of two MPR121 capacitive touch ICs.
The Diapasonix can be played as an instrument in its own right, using the AMY synthesis engine. This provides a huge range of patches from the Juno 6 and DX7 synthesizers of old. Onboard effects like delay and reverb can be used to alter the sound. Alternatively, it can be used as a MIDI controller, feeding its data to a PC attached over USB. It can be played in multiple modes, with either direct note triggers or with a “strumming” method instead.
We’ve featured a great many MIDI controllers over the years, from the artistic to the compact. Video after the break.
youtube.com/embed/DMDRZ1dwdG4?…
React Server: Nuovi bug critici portano a DoS e alla divulgazione del codice sorgente
La saga sulla sicurezza dei componenti di React Server continua questa settimana.
Successivamente alla correzione di una vulnerabilità critica relativa all’esecuzione di codice remoto (RCE) che ha portato a React2shell, sono state individuate dai ricercatori due nuove vulnerabilità. Queste ultime, pur essendo meno gravi delle precedenti, comportano rischi significativi, tra cui la possibilità di attacchi Denial of Service (DoS) che possono causare il crash del server e l’esposizione di codice sorgente sensibile.
Le versioni interessate includono la versione da 19.0.0 a 19.0.2, la versione da 19.1.0 a 19.1.2 e la versione da 19.2.0 a 19.2.2. Si consiglia pertanto agli sviluppatori di aggiornare alle versioni corrette appena rilasciate:
- 19.0.3
- 19.1.4
- 19.2.3
Fondamentalmente, queste vulnerabilità hanno un ampio raggio d’azione.
Basta che l’applicazione sia vulnerabile a certe funzioni del server per essere esposta a potenziali rischi, senza doverle necessariamente utilizzare. “Anche se la tua app non implementa alcun endpoint di React Server Function, potrebbe comunque essere vulnerabile se supporta i React Server Components”, avverteono i ricercatori di sicurezza.
Il problema più urgente, ha una severity CVSS di 7.5, e riguarda una vulnerabilità che può mettere in ginocchio un server. Identificata come CVE-2025-55184 e CVE-2025-67779, questa falla consente a un aggressore di innescare un loop infinito sul server inviando una specifica richiesta HTTP dannosa. Secondo l’avviso, il loop consuma la CPU del server, bloccandone di fatto le risorse.
La seconda vulnerabilità, il CVE-2025-55183 ha una severity CVSS 5.3, è un problema di gravità media che colpisce la riservatezza del codice dell’applicazione. E’ stato rilevato che in specifiche circostanze, una richiesta nociva è in grado di convincere una funzione del server a fornire all’attaccante il proprio codice sorgente. Secondo quanto riportato nell’avviso, un esperto di sicurezza ha riscontrato che l’invio di una richiesta HTTP dannosa a una funzione del server suscettibile di vulnerabilità potrebbe comportare la restituzione non sicura del codice sorgente di qualsiasi funzione del server.
Per eseguire l’attacco, è necessario un particolare modello di codifica, nel quale una funzione lato server esplicitamente o implicitamente espone un parametro come stringa. Qualora venisse sfruttata, potrebbe portare alla scoperta di informazioni cruciali a livello logico o di chiavi del database internamente allegate al codice della funzione.
Il team di React ha confermato esplicitamente che questi nuovi bug non riapriranno la porta al controllo totale del server. “Queste nuove vulnerabilità non consentono l’esecuzione di codice remoto. La patch per React2Shell rimane efficace nel mitigare l’exploit di esecuzione di codice remoto”.
Il team esorta a procedere con urgenza all’aggiornamento, dato che le vulnerabilità scoperte di recente sono di notevole gravità.
L'articolo React Server: Nuovi bug critici portano a DoS e alla divulgazione del codice sorgente proviene da Red Hot Cyber.
Vulnerabilità di sicurezza in PowerShell: Una nuova Command Injection su Windows
Un aggiornamento di sicurezza urgente è stato rilasciato per risolvere una vulnerabilità critica in Windows PowerShell, che permette agli aggressori di eseguire codice malevolo sui sistemi colpiti. Questa falla di sicurezza, catalogata come CVE-2025-54100, è stata divulgata il 9 dicembre 2025 e costituisce una minaccia considerevole per l’integrità dei sistemi informatici a livello globale.
Microsoft classifica la vulnerabilità come importante, con un punteggio di gravità CVSS di 7,8. La debolezza, identificata come CWE-77, si riferisce alla neutralizzazione impropria di elementi speciali impiegati negli attacchi di iniezione di comandi.
Microsoft considera remota la possibilità che questa vulnerabilità venga sfruttata in attacchi reali. La vulnerabilità è stata già divulgata pubblicamente. Gli aggressori devono disporre di accesso locale e dell’intervento dell’utente per eseguire l’attacco, pertanto sono costretti a cercare di indurre gli utenti ad aprire file dannosi o eseguire comandi sospetti.

Patch di sicurezza sono state rilasciate da Microsoft su diverse piattaforme. È fondamentale che le organizzazioni che operano con Windows Server 2025, Windows 11 nelle versioni 24H2 e 25H2, e Windows Server 2022, procedano con l’applicazione delle patch mediante KB5072033 o KB5074204, dando priorità all’aggiornamento.
Il difetto si verifica quando elementi speciali in Windows PowerShell vengono neutralizzati in modo improprio durante gli attacchi di iniezione di comandi. Ciò permette ad aggressori non autorizzati di eseguire codice arbitrario localmente tramite comandi appositamente predisposti.
Microsoft consiglia di utilizzare l’opzione UseBasicParsing per impedire l’esecuzione di codice script dal contenuto Web. Inoltre, le organizzazioni dovrebbero implementare le linee guida contenute nell’articolo KB5074596 in merito alle misure di sicurezza di PowerShell 5.1 per mitigare i rischi legati all’esecuzione degli script.
La vulnerabilità colpisce un’ampia gamma di sistemi operativi Windows, tra cui Windows 10, Windows 11, Windows Server 2008 fino alla versione 2025 e varie configurazioni di sistema. Gli utenti che utilizzano Windows 10 e versioni precedenti necessitano di aggiornamenti separati, come KB5071546 o KB5071544.
L'articolo Vulnerabilità di sicurezza in PowerShell: Una nuova Command Injection su Windows proviene da Red Hot Cyber.
Telegram perde il suo status di piattaforma comoda per i criminali informatici
Telegram, che nel corso della sua storia è diventata una delle app di messaggistica più popolari al mondo, sta gradualmente perdendo il suo status di piattaforma comoda per i criminali informatici.
Gli analisti di Kaspersky Lab hanno monitorato il ciclo di vita di centinaia di canali underground e hanno concluso che la moderazione più severa stanno letteralmente estromettendo l’underground dall’app di messaggistica.
Gli esperti sottolineano che Telegram è inferiore alle app di messaggistica sicura dedicate in termini di protezione della privacy: le chat non utilizzano la crittografia end-to-end di default, l’intera infrastruttura è centralizzata e il codice del server è chiuso.
Sebbene questo probabilmente non rappresenti un problema significativo per l’utente medio, implica la dipendenza da terze parti e il rischio di deanonimizzazione per i criminali. Non è un caso che le proposte di vietare completamente Telegram per motivi di lavoro siano sempre più frequenti sui forum underground.

Tuttavia, sono proprio le funzionalità integrate del servizio a renderlo una piattaforma aziendale conveniente per i criminali.
I bot gestiscono l’accettazione e il pagamento degli ordini, vendono log di infostealer , abbonamenti MaaS, servizi di doxxing, frodi con carte di credito e altre frodi online minori. Questa attività criminale “snella” e altamente automatizzata si adatta perfettamente al modello di Telegram: il proprietario è in gran parte estraneo alle operazioni e i file pubblicati sui canali vengono archiviati a tempo indeterminato.
Tuttavia, prodotti esclusivi – accesso alle reti aziendali, exploit zero-day– rimangono sui forum darknet tradizionali con sistemi di reputazione, depositi e garanzie sulle transazioni.
Una sezione separata dello studio è dedicata alla durata di vita dei canali underground. Sulla base dei dati di oltre 800 risorse bloccate, gli analisti hanno stimato la loro durata media in circa sette mesi. Tuttavia, la mediana è aumentata: mentre nel 2021-2022 un canale durava in media cinque mesi, nel 2023-2024 ha raggiunto i nove. Ciò non significa che la persecuzione sia diminuita: il grafico dei blocchi mostra un forte picco nel 2022, legato all’attività degli hacktivisti, e livelli costantemente elevati fino a metà del 2025. Anche i minimi di fine 2024 sono paragonabili ai picchi del 2023.
I criminali informatici stanno cercando di adattarsi: cambiano canale in modalità “on-demand”, pubblicano messaggi “innocui” per camuffare la propria identità e annotano i post con disclaimer e dichiarazioni sulla legalità del contenuto. Tuttavia, un’analisi di risorse di lunga data mostra che queste misure vengono applicate sporadicamente e generalmente non riescono a impedire il blocco.
Di conseguenza, grandi comunità stanno iniziando a cercare alternative. Ad esempio, nel 2025, uno dei gruppi più grandi, BFRepo, con quasi 9.000 iscritti, ha annunciato il suo passaggio al messenger decentralizzato SimpleX dopo una serie di ban su Telegram. Un altro gruppo ben noto, Angel Drainer, si è spinto ancora oltre e ha lanciato il proprio messenger chiuso con il presunto supporto per i moderni protocolli crittografici, raccomandando allo stesso tempo agli utenti di abbandonare Telegram.
Gli autori del rapporto concludono in modo inequivocabile: Telegram un tempo sembrava un rifugio relativamente sicuro per i criminali, ma quell’era sta finendo. La crescente moderazione e la pressione da parte di vari attori, dai detentori di copyright ai gruppi di hacktivisti, stanno rendendo l’infrastruttura underground del messenger sempre più instabile.
Tuttavia, la scomparsa dei canali underground da Telegram non significa una riduzione delle minacce informatiche: le comunità criminali stanno semplicemente migrando verso altri servizi o sviluppando soluzioni proprie. Gli analisti esortano le aziende e gli specialisti della sicurezza informatica a monitorare attentamente la migrazione delle piattaforme e ad adattare i propri sistemi di monitoraggio ai nuovi focolai di attività criminale informatica.
L'articolo Telegram perde il suo status di piattaforma comoda per i criminali informatici proviene da Red Hot Cyber.
Digital Fights: Digital Lights: Wir kämpfen gegen Handydurchsuchungen bei Geflüchteten
netzpolitik.org/2025/digital-f…

Step into my Particle Accelerator

If you get a chance to visit a computer history museum and see some of the very old computers, you’ll think they took up a full room. But if you ask, you’ll often find that the power supply was in another room and the cooling system was in yet another. So when you get a computer that fit on, say, a large desk and maybe have a few tape drives all together in a normal-sized office, people thought of it as “small.” We’re seeing a similar evolution in particle accelerators, which, a new startup company says, can be room-sized according to a post by [Charles Q. Choi] over at IEEE Spectrum.
Usually, when you think of a particle accelerator, you think of a giant housing like the 3.2-kilometer-long SLAC accelerator. That’s because these machines use magnets to accelerate the particles, and just like a car needs a certain distance to get to a particular speed, you have to have room for the particle to accelerate to the desired velocity.
A relatively new technique, though, doesn’t use magnets. Instead, very powerful (but very short) laser pulses create plasma from gas. The plasma oscillates in the wake of the laser, accelerating electrons to relativistic speeds. These so-called wakefield accelerators can, in theory, produce very high-energy electrons and don’t need much space to do it.
The startup company, TAU Systems, is about to roll out a commercial system that can generate 60 to 100 MeV at 100 Hz. They also intend to increase the output over time. For reference, SLAC generates 50,000 MeV. But, then again, it takes two miles of raceway to do it.
The initial market is likely to be radiation testing for space electronics. Higher energies will open the door to next-generation X-ray lithography for IC production, and more. There are likely applications for accelerated electrons that we don’t see today because it isn’t feasible to generate them without a massive facility.
On the other hand, don’t get your checkbook out yet. The units will cost about $10 million at the bottom end. Still a bargain compared to the alternatives.
You can do some of this now on a chip. Particle accelerators have come a long way.
Photo from Tau Systems.
Ma com'è sta storia che il petrolio scende di prezzo e i carburanti aumentano? 🤨🧐😠
Il petrolio chiude in calo a New York a 57,60 dollari al barile - Ultima ora - Ansa.it
ansa.it/sito/notizie/topnews/2…
Designing a Simpler Cycloidal Drive

Cycloidal drives have an entrancing motion, as well as a few other advantages – high torque and efficiency, low backlash, and compactness among them. However, much as [Sergei Mishin] likes them, it can be difficult to 3D-print high-torque drives, and it’s sometimes inconvenient to have the input and output shafts in-line. When, therefore, he came across a video of an industrial three-ring reducing drive, which works on a similar principle, he naturally designed his own 3D-printable drive.
The main issue with 3D-printing a normal cycloidal drive is with the eccentrically-mounted cycloidal plate, since the pins which run through its holes need bearings to keep them from quickly wearing out the plastic plate at high torque. This puts some unfortunate constraints on the size of the drive. A three-ring drive also uses an eccentric drive shaft to cause cycloidal plates to oscillate around a set of pins, but the input and output shafts are offset so that the plates encompass both the pins and the eccentric driveshaft. This simplifies construction significantly, and also makes it possible to add more than one input or output shaft.
As the name indicates, these drives use three plates 120 degrees out of phase with each other; [Sergei] tried a design with only two plates 180 degrees out of phase, but since there was a point at which the plates could rotate just as easily in either direction, it jammed easily. Unlike standard cycloidal gears, these plates use epicycloidal rather than hypocycloidal profiles, since they move around the outside of the pins. [Sergei] helpfully wrote a Python script that can generate profiles, animate them, and export to DXF. The final performance of these drives will depend on their design parameters and printing material, but [Sergei] tested a 20:1 drive and reached a respectable 9.8 Newton-meters before it started skipping.
Even without this design’s advantages, it’s still possible to 3D-print a cycloidal drive, its cousin the harmonic drive, or even more exotic drive configurations.
youtube.com/embed/WMgny-yDjvs?…

Amiibo Emulator Becomes Pocket 2.4 GHz Spectrum Analyzer

As technology marches on, gear that once required expensive lab equipment is now showing up in devices you can buy for less than a nice dinner. A case in point: those tiny displays originally sold as Nintendo amiibo emulators. Thanks to [ATC1441], one of these pocket-sized gadgets has been transformed into 2.4 GHz spectrum analyzer.
These emulators are built around the Nordic nRF52832 SoC, the same chip found in tons of low-power Bluetooth devices, and most versions come with either a small LCD or OLED screen plus a coin cell or rechargeable LiPo. Because they all share the same core silicon, [ATC1441]’s hack works across a wide range of models. Don’t expect lab-grade performance; the analyzer only covers the range the Bluetooth chip inside supports. But that’s exactly where Wi-Fi, Bluetooth, Zigbee, and a dozen other protocols fight for bandwidth, so it’s perfect for spotting crowded channels and picking the least congested one.
Flashing the custom firmware is dead simple: put the device into DFU mode, drag over the .zip file, and you’re done. All the files, instructions, and source are up on [ATC1441]’s PixlAnlyzer GitHub repo. Check out some of the other amiibo hacks we’ve featured as well.
youtube.com/embed/kgrsfGIeL9w?…
Extremely Rare Electric Piano Restoration

Not only are pianos beautiful musical instruments that have stood the test of many centuries of time, they’re also incredible machines. Unfortunately, all machines wear out over time, which means it’s often not feasible to restore every old piano we might come across. But a few are worth the trouble, and [Emma] had just such a unique machine roll into her shop recently.
What makes this instrument so unique is that it’s among the first electric pianos to be created, and one of only three known of this particular model that survive to the present day. This is a Vivi-Tone Clavier piano which dates to the early 1930s. In an earlier video she discusses more details of its inner workings, but essentially it uses electromagnetic pickups like a guitar to detect vibrations in plucked metal reeds.
To begin the restoration, [Emma] removes the action and then lifts out all of the keys from the key bed. This instrument is almost a century old so it was quite dirty and needed to be cleaned. The key pins are lubricated, then the keys are adjusted so that they all return after being pressed. From there the keys are all adjusted so that they are square and even with each other. With the keys mostly in order, her attention turns to the action where all of the plucking mechanisms can be filed, and other adjustments made. The last step was perhaps the most tedious, which is “tuning” the piano by adjusting the pluckers so that all of the keys produce a similar amount or volume of sound, and then adding some solder to the reeds that were slightly out of tune.
With all of those steps completed, the piano is back in working order, although [Emma] notes that since these machines were so rare and produced so long ago there’s no real way to know if the restoration sounds like what it would have when it was new. This is actually a similar problem we’ve seen before on this build that hoped to model the sound of another electric instrument from this era called the Luminaphone.
youtube.com/embed/cEG7hD28dW4?…
Thanks to [Eluke] for the tip!
Andre123 🐧 reshared this.
CSRA: Perché serve un nuovo modo di percepire ciò che non riusciamo più a controllare
La cybersecurity vive oggi in una contraddizione quasi paradossale: più aumentano i dati, più diminuisce la nostra capacità di capire cosa sta accadendo. I SOC traboccano di log, alert, metriche e pannelli di controllo, eppure gli attacchi più gravi — dai ransomware alle campagne stealth di spionaggio — continuano a sfuggire alla vista proprio nel momento decisivo: quando tutto sta per cominciare.
Il problema non è l’informazione. Il problema è lo sguardo: la capacità di visualizzare ciò che conta!
Esistono strumenti perfetti per contare, classificare, correlare; molti meno per percepire.
Così, mentre la superficie digitale cresce in complessità e velocità, continuiamo a osservare il cyberspace come un inventario di oggetti — server, IP, pacchetti — quando in realtà è un ambiente vivo, dinamico, pulsante, fatto di relazioni che cambiano forma.
Per provare a cambiare le cose nasce il Cyber Situational-Relational Awareness (CSRA): un modello che mette al centro la percezione.
1. Il vero problema non è tecnico: è percettivo.
Viviamo in un ecosistema digitale dove tutto produce segnali. Ogni servizio, applicazione, sensore, utente, processo automatico lascia una o più tracce. Non c’è mai stata così tanta “visibilità” a disposizione dei difensori. Eppure il paradosso persiste: gli attacchi vanno a segno, gli indicatori non bastano, la complessità ci sovrasta.
Il motivo è semplice: abbiamo un’enorme quantità di dati e di informazioni, ma pochissima consapevolezza del loro significato nel momento in cui cambia.
Gli strumenti tradizionali ci dicono cosa è successo, a volte cosa sta succedendo al momento, quasi mai cosa sta per accadere.
Manca la percezione del mutamento, di quella variazione sottile che precede l’incidente.
Il CSRA, concettualmente, nasce proprio per cogliere queste trasformazioni minime, che oggi si perdono nei rumori di fondo.
2. Il cyberspace non è un inventario di oggetti, ma un ecosistema di relazioni
Per trent’anni abbiamo sentito descrivere il cyberspace come un insieme di entità isolate: host, server, IP, router. Abbiamo costruito strumenti pensati per monitorare questi oggetti, ciascuno con i propri attributi e comportamenti misurabili. Ma la realtà degli attacchi moderni mostra un quadro completamente diverso.
Quando una minaccia si manifesta, non è l’oggetto a tradirla, ma la relazione tra oggetti.
Non è il server anomalo a dirci che sta succedendo qualcosa: è il modo in cui sta comunicando con altri nodi.
Non è un singolo pacchetto strano: è il ritmo delle sue interazioni.
Non è un evento isolato: è il cambiamento di una costellazione di micro-eventi.
Ecco la prima grande intuizione del CSRA: il nodo cyber non è un dispositivo, ma un piccolo ecosistema composto da un’entità — umana o automatica — e dalla tecnologia che usa per comunicare. Per comprenderlo occorre osservare come evolve nel tempo, non cosa è staticamente.
3. Comprendere un attacco significa ascoltare il ritmo della rete.
Ogni rete possiede un suo proprio ritmo: qualcuna presenta un alternarsi di picchi e quiete, altre una regolarità nelle connessioni, e poi ci sono le reti di lavoro con un andamento che si ripete giorno dopo giorno.
È proprio quando questo ritmo naturale si spezza — anche in maniera quasi impercettibile — che qualcosa comincia a muoversi.
Il CSRA si concentra su questo: sulla capacità di percepire un cambiamento di ritmo prima che diventi un incidente conclamato. Naturalmente non ogni deviazione implica un attacco: a volte si tratta di un malfunzionamento o di un cambio di abitudini. Ma è sempre meglio verificare.
Un attacco nelle prime fasi è quasi invisibile. Modifica una sequenza di azioni, altera un’abitudine, crea una piccola vibrazione nella rete. Una procedura automatica che diventa più attiva del solito; un nodo che stabilisce collegamenti imprevisti; un cluster che sembra muoversi in modo più irrequieto.
Queste vibrazioni sono i segnali precoci dell’incidente. Il CSRA è progettato per ascoltarli.
4. Lo “spazio locale”: dove la rete ci dice di guardare.
La rete è troppo vasta per essere osservata tutta allo stesso modo.
E qui nasce la seconda intuizione del CSRA: non tutto merita attenzione, almeno non nello stesso momento. Ogni trasformazione significativa parte da un punto preciso della rete. È lì, in quella piccola regione, che il ritmo si altera. Il CSRA identifica questa regione emergente e la trasforma in un “spazio locale”: una sorta di lente dinamica che si concentra proprio dove sta avvenendo il cambiamento.
Lo spazio locale non è predefinito: viene generato dalla rete stessa. È lei a segnalare dove posare lo sguardo. È questo meccanismo che permette a un sistema CSRA di non affogare nei dati e, allo stesso tempo, di accorgersi dei segnali giusti nel momento giusto.
5. La rete come paesaggio: quando ciò che era invisibile diventa evidente
Uno dei punti più affascinanti del CSRA è la sua capacità di trasformare la rete in un paesaggio visivo. Non una dashboard piena di numeri, ma una rappresentazione quasi geografica delle attività: alture che indicano intensità, valli che rivelano stabilità, creste che segnalano turbolenze.
Per la prima volta, l’analista può “vedere” l’incidente come si vede una perturbazione meteorologica: una zona che si scalda, si deforma, si muove. È un modo più naturale, quasi intuitivo, di percepire il cyberspace, che consente di cogliere immediatamente ciò che non torna, anche senza sapere in anticipo di cosa si tratti.
Questa rappresentazione non è un vezzo grafico: è una forma di consapevolezza.
Ciò che era nascosto diventa visibile.
6. Perché il CSRA potenzialmente potrebbe vedere ciò che gli altri strumenti non vedono.
La ragione è semplice e, allo stesso tempo, rivoluzionaria: il CSRA non cerca ciò che conosce, osserva ciò che cambia. Gli strumenti basati su firme, regole e pattern riconoscono solo ciò che è già stato codificato. Funzionano benissimo contro minacce note, molto meno contro tecniche nuove, attacchi creativi o comportamenti deliberatamente irregolari.
Il CSRA, invece, affronta il cyberspace come un organismo in continuo mutamento.
Quando un nodo inizia a comportarsi in modo inusuale, quando due sistemi improvvisano un dialogo imprevisto, quando una parte della rete si anima in modo anomalo, il CSRA lo percepisce immediatamente.
È un’attenzione simile a quella umana: istintiva, sensibile al movimento, orientata alla variazione. Dietro questa capacità percettiva c’è una matematica precisa: quella delle variazioni, dell’entropia e dei cambiamenti tra nodi connessi. Non servono formule per capirlo: conta il principio, quello di misurare come la rete si trasforma nel tempo.
7. Il CSRA è prima di tutto un nuovo modo di pensare.
Non è un software da aggiungere, né un modulo da integrare. È una nuova mentalità per affrontare la sicurezza in un mondo che cambia troppo velocemente. Il CSRA porta con sé un messaggio chiaro: non possiamo più limitarci a raccogliere dati. Dobbiamo imparare a percepire le trasformazioni.
Una rete osservata con il CSRA non è una collezione di oggetti tecnici, ma un ambiente vivo. Il SOC smette di essere un centro di allarmi e diventa un luogo di interpretazione, in cui la difesa non è una reazione tardiva ma un esercizio continuo di comprensione.
Conclusione: il CSRA è la percezione cyber del XXI secolo.
Il CSRA non introduce un altro strumento nell’infinita collezione già esistente. Introduce qualcosa di più importante: un nuovo modo di guardare il cyberspace.
Non come un elenco di entità isolate, ma come un tessuto di relazioni che respira, cambia e ci parla — se sappiamo ascoltarlo.
In un’epoca in cui gli attacchi si trasformano più rapidamente dei nostri modelli di difesa, percepire il cambiamento diventa una necessità strategica. E il CSRA rappresenta il primo passo verso questa nuova forma di consapevolezza.
Non è solo tecnologia. È una nuova capacità umana: vedere ciò che prima era invisibile.
L'articolo CSRA: Perché serve un nuovo modo di percepire ciò che non riusciamo più a controllare proviene da Red Hot Cyber.


Journalists warn of silenced sources
From national outlets to college newspapers, reporters are running into the same troubling trend: sources who are afraid to speak to journalists because they worry about retaliation from the federal government.
This fear, and how journalists can respond to it, was the focus of a recent panel discussion hosted by Freedom of the Press Foundation (FPF), the Association of Health Care Journalists, and the Society of Environmental Journalists. Reporters from a range of beats described how the second Trump administration has changed the way people talk to the press, and what journalists do to reassure sources and keep them safe.
youtube.com/embed/rIyRDQFEl4k?…
For journalist Grace Hussain, a solutions correspondent at Sentient Media, this shift became unmistakable when sources who relied on federal funding suddenly backed out of participating in her reporting. “Their concerns were very legitimate,” Hussain said, “It was possible that their funding could get retracted or withdrawn” for speaking to the press.
When Hussain reached out to other reporters, she found that sources’ reluctance to speak to the press for fear of federal retaliation is an increasingly widespread issue that’s already harming news coverage. “There are a lot of stories that are under-covered, and it’s just getting more difficult at this point to do that sort of coverage with the climate that we’re in,” she said.
Lizzy Lawrence, who covers the Food and Drug Administration for Stat, has seen a different but equally unsettling pattern. Lawrence has found that more government sources want to talk about what’s happening in their agencies, but often only if they’re not named. Since Trump returned to office, she said, many sources “would request only to speak on the condition of anonymity, because of fears of being fired.” As a result, her newsroom is relying more on confidential sources, with strict guardrails, like requiring multiple sources to corroborate information.
For ProPublica reporter Sharon Lerner, who’s covered health and the environment across multiple administrations, the heightened fear is impossible to miss. Some longtime sources have cut off communication with her, including one who told her they were falsely suspected of leaking.
And yet, she added, speaking to the press may be one of the last options left for employees trying to expose wrongdoing. “So many of the avenues for federal employees to seek justice or address retaliation have been shut down,” Lerner said.
This chilling effect extends beyond federal agencies. Emily Spatz, editor-in-chief of Northeastern’s independent student newspaper The Huntington News, described how fear spread among international students after federal agents detained Mahmoud Kahlil and Rümeysa Öztürk. Visa revocations of students at Northeastern only deepened the concern.
Students started asking the newspaper to take down previously published op-eds they worried could put them at risk, a step Spatz took after careful consideration. The newsroom ultimately removed six op-eds but posted a public website documenting each removal to preserve transparency.
Even as the paper worked hard to protect sources, many became reluctant to participate in their reporting. One student, for instance, insisted the newspaper remove a photo showing the back of their head, a method the paper had used specifically to avoid identifying sources.
Harlo Holmes, the chief information security officer and director of digital security at FPF, said these patterns mirror what journalists usually experience under authoritarian regimes, but — until now — have not been seen in the United States. Whistleblowing is a “humongously heroic act,” Holmes said, “and it is not always without its repercussions.”
She urged reporters to adopt rigorous threat-modeling practices and to be transparent with sources about the tools and techniques they use to keep them safe. Whether using SecureDrop, Signal, or other encrypted channels, she said journalists should make it easy for sources to find out how to contact them securely. “A little bit of education goes a long way,” she said.
For more on how journalists are working harder than ever to protect vulnerable sources, watch the full event recording here.
Covering immigration in a climate of fear
As the federal government ramps up immigration enforcement, sweeping through cities, detaining citizens and noncitizens, separating families, and carrying out deportations, journalists covering immigration have had to step up their work, too.
Journalists on the immigration beat today are tasked with everything from uncovering government falsehoods to figuring out what their communities need to know and protecting their sources. Recently, Freedom of the Press Foundation (FPF) hosted a conversation with journalists Maritza Félix, the founder and director of Conecta Arizona; Arelis Hernández, a reporter for The Washington Post; and Lam Thuy Vo, an investigative reporter with Documented. They discussed the challenges they face and shared how they report on immigration with humanity and accuracy, while keeping their sources and themselves safe.
youtube.com/embed/OPPo0YzKfnA?…
Immigration reporting has grown a lot more difficult, explained Hernández, as sources increasingly fear retaliation from the government. “I spend a lot of time at the front end explaining, ‘Where will this go? What will it look like?’” Hernández said, describing her process of working with sources to ensure they participate in reporting knowingly and safely. She also outlined her own precautions, from using encrypted devices to carrying protective gear, highlighting just how unsafe conditions have become, even for U.S.-born reporters.
Like Hernández, Félix also emphasized the intense fear and uncertainty many immigrant sources experience. Other sources, however, may be unaware of the possible consequences of speaking to reporters and need to be protected as well. “I think when we’re talking about sources, particularly with immigration, we’re talking about people who are sharing their most vulnerable moments in their life, and I think the way that we treat it is going to be very decisive on their future,” she said.
Journalists who are themselves immigrants must also manage personal risk, Félix said, “but the risk is always going to be there just because of who we are and what we represent in this country.” She pointed to the arrest and deportation of journalist Mario Guevara in Georgia, saying it “made me think that could have been me” before she became a U.S. citizen. She recommended that newsrooms provide security training, mental health resources, and operational protocols for both staff and freelancers.
Both Félix and Vo, who work in newsrooms by and for immigrant communities, emphasized the need for journalists to actively listen to the people they cover. “If you’re trying to serve immigrants, build a listening mechanism, some kind of way of continuing to listen to both leaders in the community, service providers, but also community members,” Vo advised. She also recommended that journalists use risk assessments and threat modeling to plan how to protect themselves and their sources.
Watch the full discussion here.
Tempesta e freddo su 850mila sfollati vittime dello stato genocida di israele.
Rahaf, bimba di otto mesi, morta di freddo a Kahn Younis
differx.noblogs.org/2025/12/11…
reshared this
gli USA intendono passare ai raggi x i social di chiunque entri nel loro territorio
differx.noblogs.org/2025/12/11…
reshared this
un'opera di Leonora Carrington
March Sunday / Leonora Carrington. 1990
differx.noblogs.org/2025/12/10…
reshared this